



A Deep Learning-Based Multi-Signal Radio Spectrum Monitoring Method for UAV Communication


Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- A method of multi-signal modulation recognition based on a one-dimensional neural network is proposed. The network structure is relatively simple, and multiple communication signals can be considered.
- A multi-node joint decision-making model is considered under a distributed architecture. Only the decision results of each node need to be transmitted for fusion, which effectively reduces the data transmission cost. The method requires little calculation and can quickly detect whether a signal is in the target frequency band. Thus, applying this method in nodes will not incur excessive computational pressure and delays.
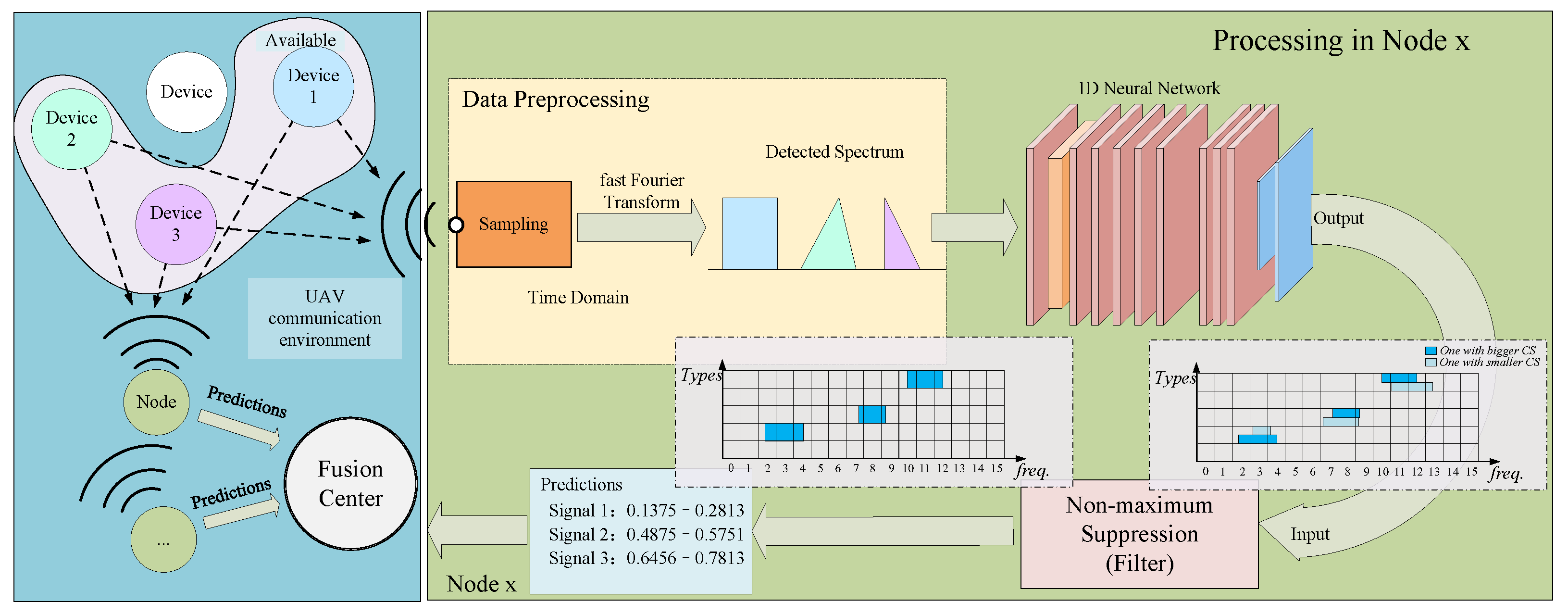
2. System Architecture
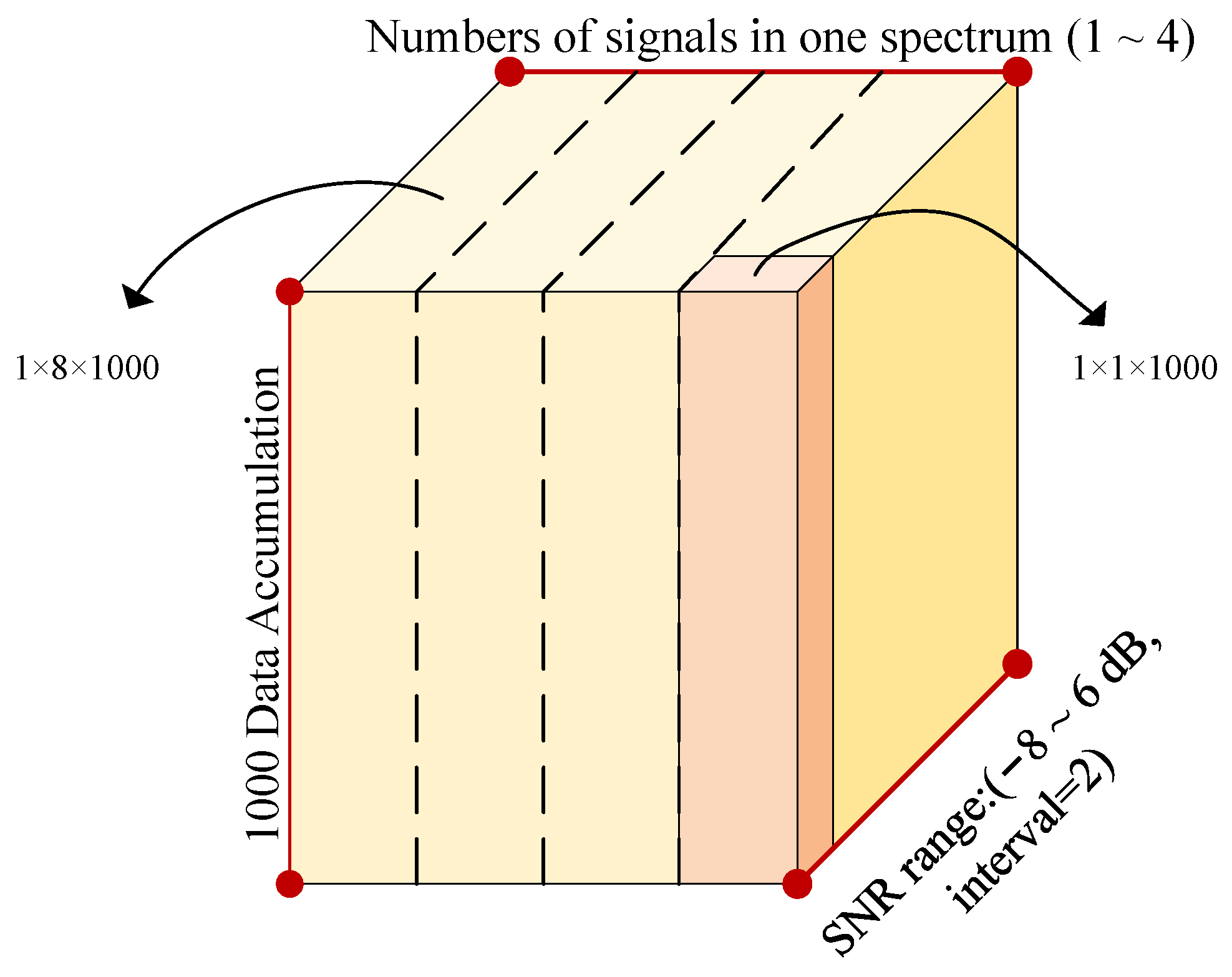
2.1. Multi-Signal Spectrum Dataset
2.2. Processing in the Single Node
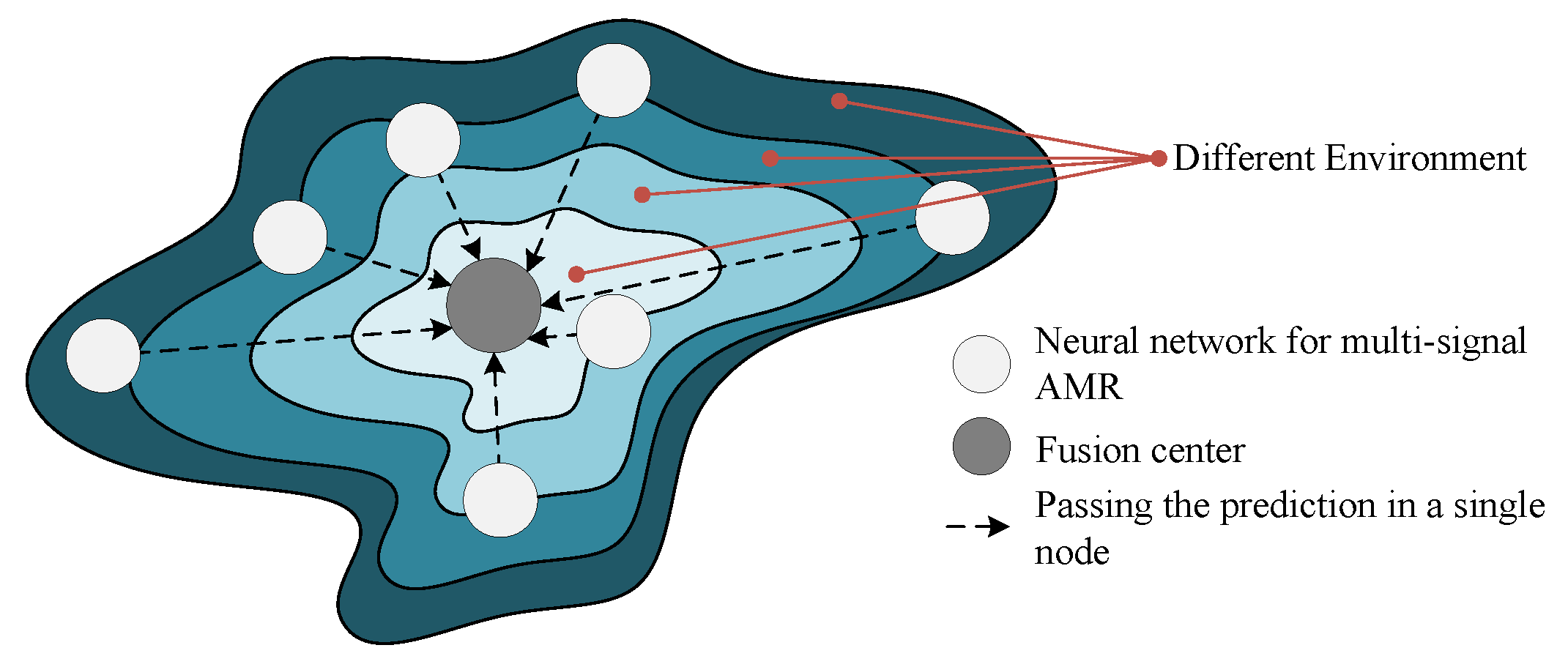
2.3. Multi-Node Fusion Process Structure
3. Proposed Approach
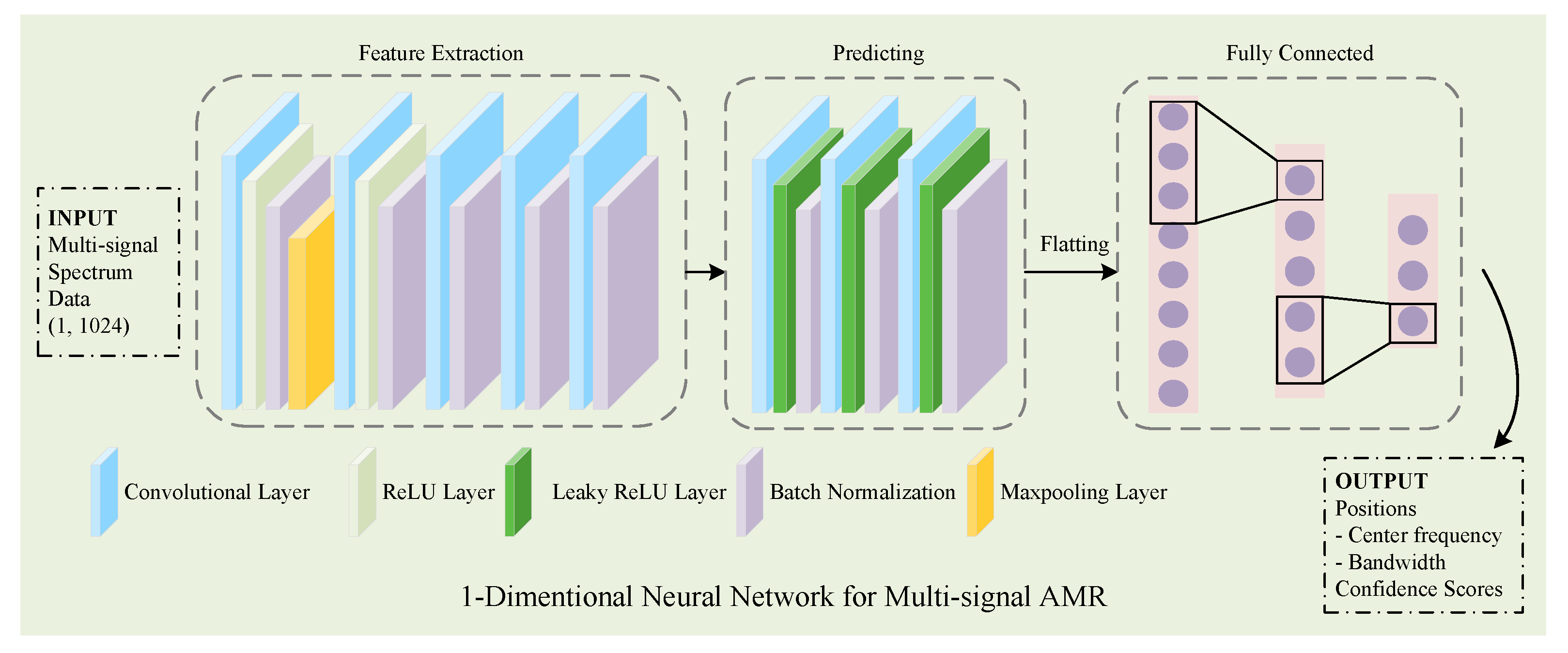
3.1. Using Neural Networks in Multi-Signal AMR
3.2. Data Preprocessing for the Dataset
3.3. Training and Testing Method
3.3.1. Pretraining of the Feature Extraction Network
3.3.2. Overall Training
| Algorithm 1 Training the recognition networks |
| Input: Feature Extraction Dataset (or Subset) , Multi-signal Dataset (or Subset) ; |
| Output: Neural Network Parameters |
|
3.3.3. Loss Function for Recognition Networks
3.3.4. Testing Method
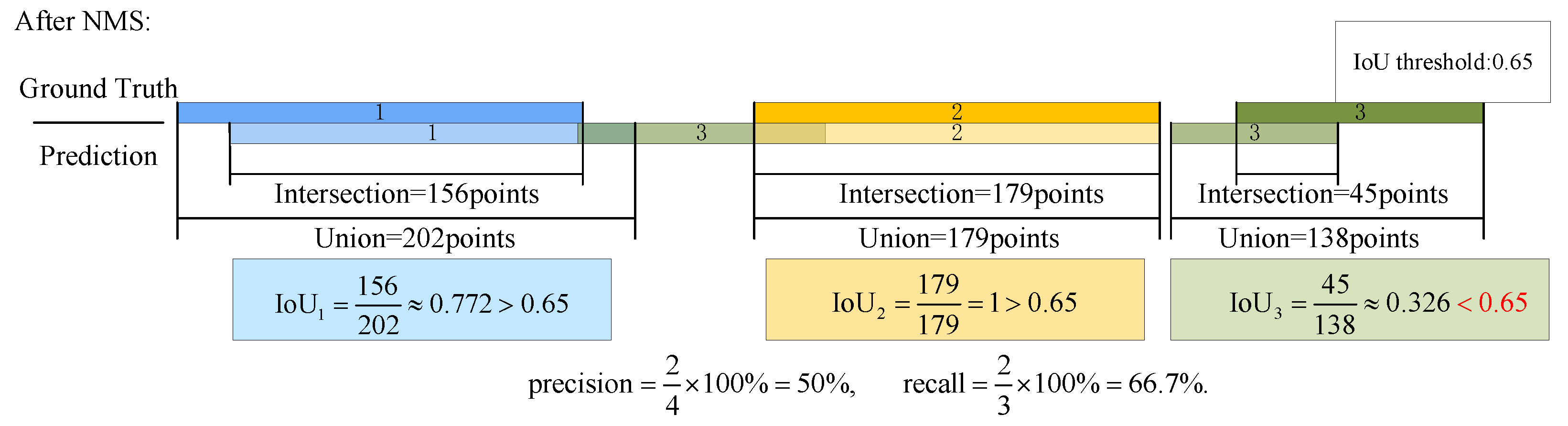
3.3.5. Evaluation Method
3.4. Decision Fusion
| Algorithm 2 Training the weak networks |
| Input: N Multi-signal Training Samples in Dataset ; |
| Output: Weak Networks Group Parameters |
|
| Algorithm 3 Judging the joint decision results |
| Input: Prediction subsections, voting threshold ; |
| Output: Joint decision results; |
|
- Find all predictions of all single nodes and store them in the same section of spectrum.
- Divide the synthesized spectrum into 16 sections.
- Accumulate the number of center frequency points in each section. If the C category is higher than the certain voting threshold, it is counted as a joint decision result.
- Return to the original predictions, identify those that match the joint decision results, count their start and end positions in the spectrum data, and average them.
4. Experiments and Results
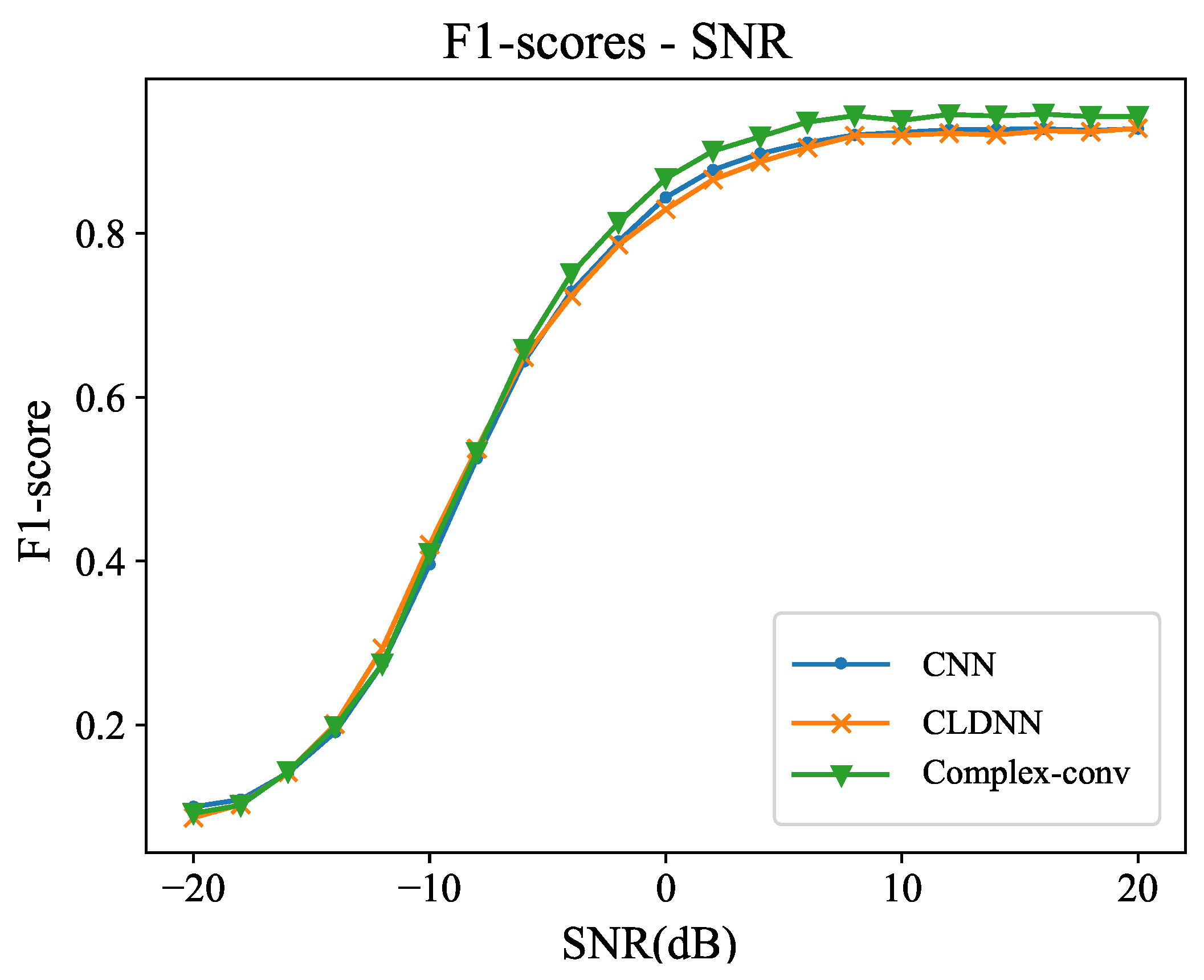
4.1. Performance under Different SNRs
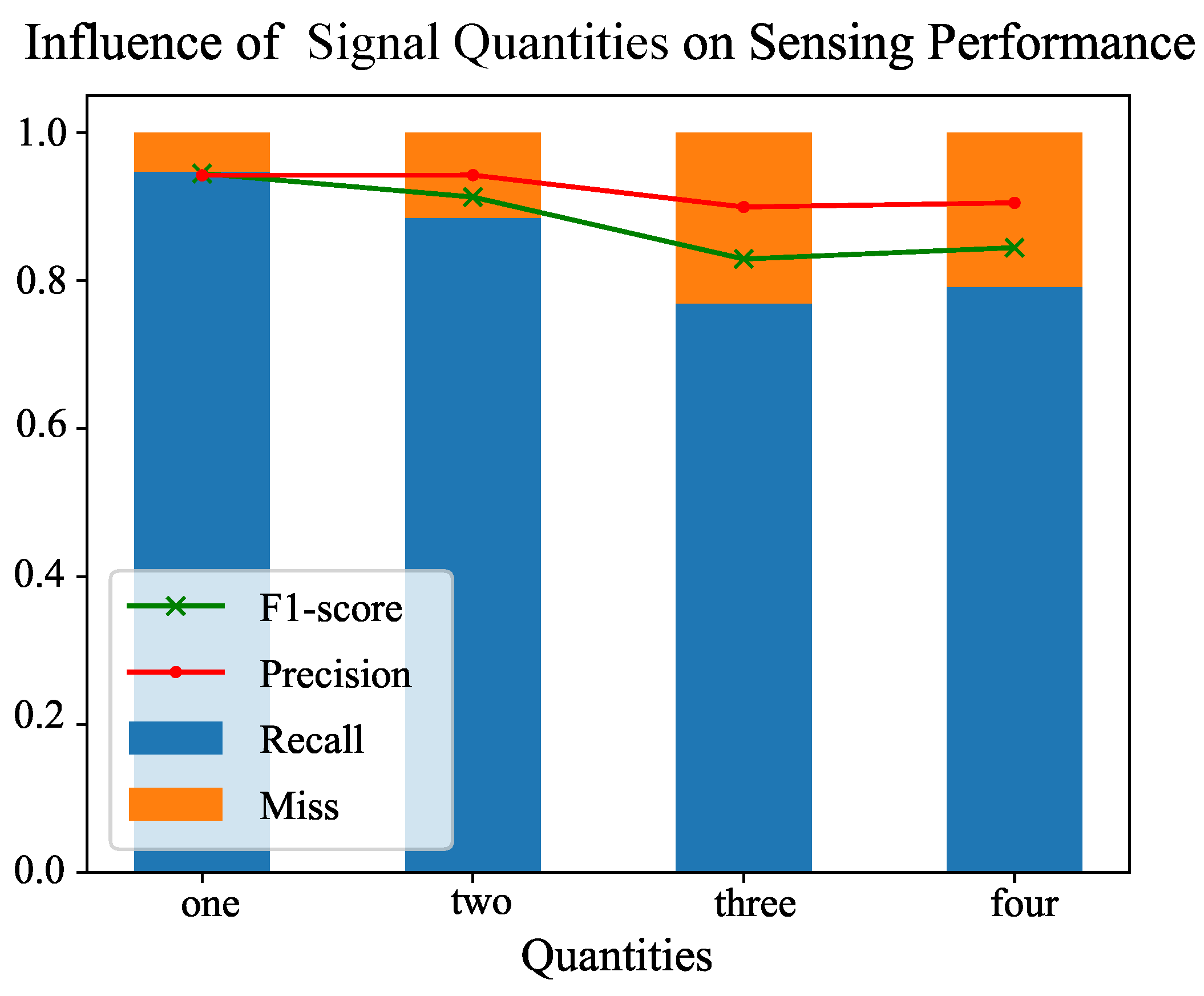
4.2. Performance under Different Quantities of Signals
4.3. Performance under Different Types of Signals
4.4. Performance of the Fusion Method
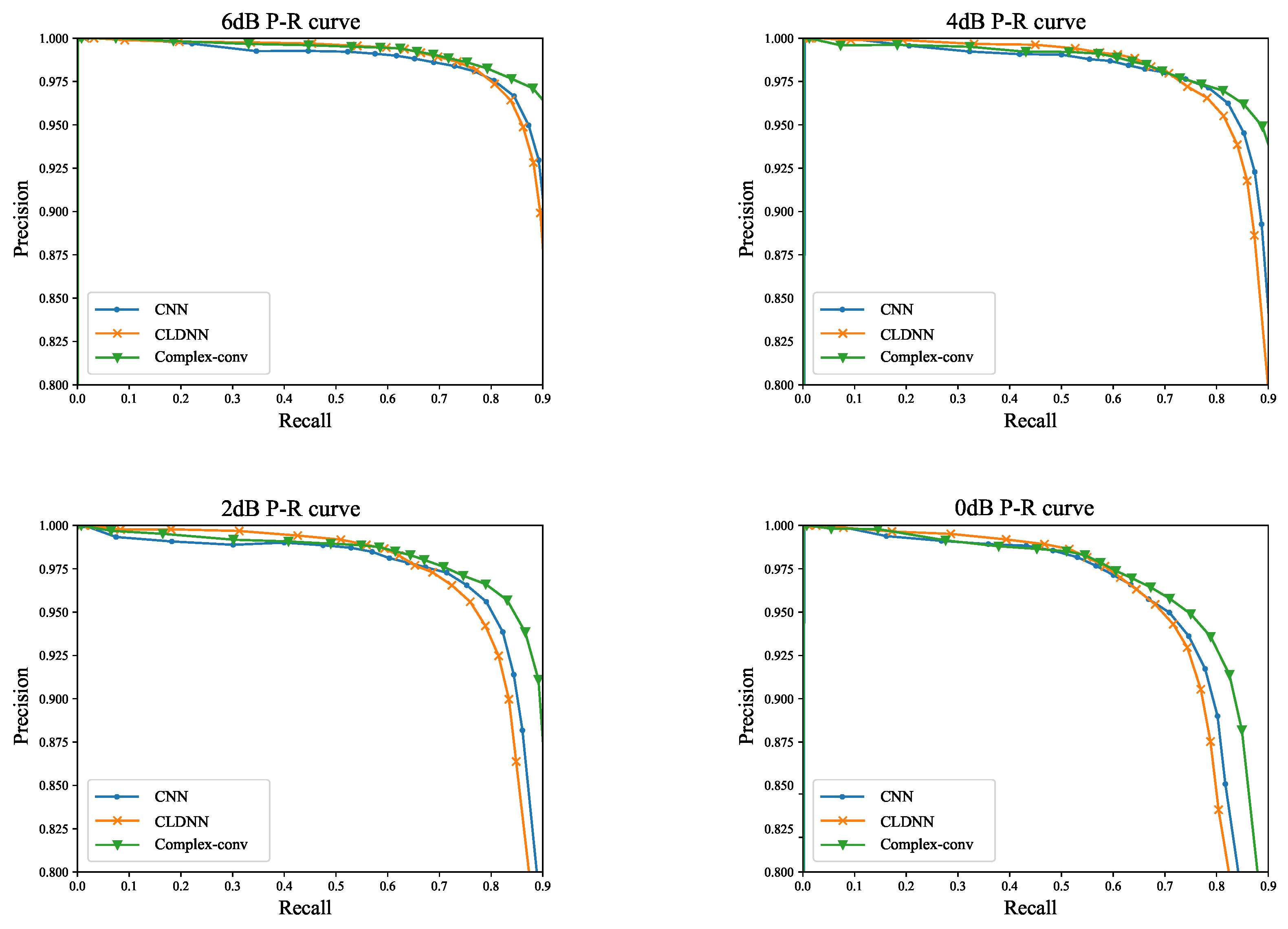
4.5. Precision-Recall Curves
4.6. Model Runtime Duration
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ding, G.; Wu, Q.; Zhang, L.; Lin, Y.; Tsiftsis, T.A.; Yao, Y.D. An amateur drone surveillance system based on the cognitive Internet of Things. IEEE Commun. Mag. 2018, 56, 29–35. [Google Scholar] [CrossRef] [Green Version]
- Ayamga, M.; Akaba, S.; Nyaaba, A.A. Multifaceted applicability of drones: A review. Technol. Forecast. Soc. Chang. 2021, 167, 120677. [Google Scholar] [CrossRef]
- Sun, J.; Wang, W.; Kou, L.; Lin, Y.; Zhang, L.; Da, Q.; Chen, L. A data authentication scheme for UAV ad hoc network communication. J. Supercomput. 2020, 76, 4041–4056. [Google Scholar] [CrossRef]
- Tian, Q.; Zhang, S.; Mao, S.; Lin, Y. Adversarial attacks and defenses for digital communication signals identification. Digit. Commun. Netw. 2022, in press. [Google Scholar] [CrossRef]
- Jdid, B.; Hassan, K.; Dayoub, I.; Lim, W.H.; Mokayef, M. Machine learning based automatic modulation recognition for wireless communications: A comprehensive survey. IEEE Access 2021, 9, 57851–57873. [Google Scholar] [CrossRef]
- Hadi, H.J.; Cao, Y.; Nisa, K.U.; Jamil, A.M.; Ni, Q. A comprehensive survey on security, privacy issues and emerging defence technologies for UAVs. J. Netw. Comput. Appl. 2023, 213, 103607. [Google Scholar] [CrossRef]
- Adil, M.; Jan, M.A.; Liu, Y.; Abulkasim, H.; Farouk, A.; Song, H. A Systematic Survey: Security Threats to UAV-Aided IoT Applications, Taxonomy, Current Challenges and Requirements With Future Research Directions. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1437–1455. [Google Scholar] [CrossRef]
- Ly, B.; Ly, R. Cybersecurity in unmanned aerial vehicles (UAVs). J. Cyber Secur. Technol. 2021, 5, 120–137. [Google Scholar] [CrossRef]
- Xiao, W.; Luo, Z.; Hu, Q. A Review of Research on Signal Modulation Recognition Based on Deep Learning. Electronics 2022, 11, 2764. [Google Scholar] [CrossRef]
- Shahali, A.H.; Miry, A.H.; Salman, T.M. Automatic Modulation Classification Based Deep Learning: A Review. In Proceedings of the 2022 International Conference for Natural and Applied Sciences (ICNAS), Baghdad, Iraq, 14–15 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 29–34. [Google Scholar]
- Ya, T.; Yun, L.; Haoran, Z.; Zhang, J.; Yu, W.; Guan, G.; Shiwen, M. Large-scale real-world radio signal recognition with deep learning. Chin. J. Aeronaut. 2022, 35, 35–48. [Google Scholar]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Lv, Y. Likelihood-based automatic modulation classification in OFDM with index modulation. IEEE Trans. Veh. Technol. 2018, 67, 8192–8204. [Google Scholar] [CrossRef]
- Ghauri, S.A.; Qureshi, I.M.; Malik, A.N. A novel approach for automatic modulation classification via hidden Markov models and Gabor features. Wirel. Pers. Commun. 2017, 96, 4199–4216. [Google Scholar] [CrossRef]
- Punith Kumar, H.L.; Shrinivasan, L. Automatic digital modulation recognition using minimum feature extraction. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 772–775. [Google Scholar]
- Abu-Romoh, M.; Aboutaleb, A.; Rezki, Z. Automatic modulation classification using moments and likelihood maximization. IEEE Commun. Lett. 2018, 22, 938–941. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Zhang, W.; Yang, J.; Gui, G. Deep learning-based cooperative automatic modulation classification method for MIMO systems. IEEE Trans. Veh. Technol. 2020, 69, 4575–4579. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, J.; Yin, Y.; Wang, J.; Sun, J.; Gui, G.; Gacanin, H.; Sari, H.; Adachi, F. Automatic modulation classification for MIMO systems via deep learning and zero-forcing equalization. IEEE Trans. Veh. Technol. 2020, 69, 5688–5692. [Google Scholar] [CrossRef]
- Bouchenak, S.; Merzougui, R.; Harrou, F.; Dairi, A.; Sun, Y. A semi-supervised modulation identification in MIMO systems: A deep learning strategy. IEEE Access 2022, 10, 76622–76635. [Google Scholar] [CrossRef]
- Shi, J.; Hong, S.; Cai, C.; Wang, Y.; Huang, H.; Gui, G. Deep learning-based automatic modulation recognition method in the presence of phase offset. IEEE Access 2020, 8, 42841–42847. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Yang, J.; Gui, G. Data-driven deep learning for automatic modulation recognition in cognitive radios. IEEE Trans. Veh. Technol. 2019, 68, 4074–4077. [Google Scholar] [CrossRef]
- Xue, Y.; Chang, Y.; Zhang, Y.; Ma, J.; Li, G.; Zhan, Q.; Wu, D.; Zuo, J. UAV signal recognition technology. In Proceedings of the 5th International Conference on Computer Science and Software Engineering, Guilin China, 21–23 October 2022; pp. 681–685. [Google Scholar]
- Emad, A.; Mohamed, H.; Farid, A.; Hassan, M.; Sayed, R.; Aboushady, H.; Mostafa, H. Deep learning modulation recognition for RF spectrum monitoring. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Liu, X.; Song, Y.; Chen, K.; Yan, S.; Chen, S.; Shi, B. Modulation Recognition of Low-SNR UAV Radar Signals Based on Bispectral Slices and GA-BP Neural Network. Drones 2023, 7, 472. [Google Scholar] [CrossRef]
- Hou, C.; Liu, G.; Tian, Q.; Zhou, Z.; Hua, L.; Lin, Y. Multi-signal Modulation Classification Using Sliding Window Detection and Complex Convolutional Network in Frequency Domain. IEEE Internet Things J. 2022, 9, 19438–19449. [Google Scholar] [CrossRef]
- Chen, R.; Park, J.M.; Bian, K. Robust distributed spectrum sensing in cognitive radio networks. In Proceedings of the IEEE INFOCOM 2008—The 27th Conference on Computer Communications, Phoenix, AZ, USA, 13–18 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1876–1884. [Google Scholar]
- Ghasemi, A.; Sousa, E.S. Collaborative spectrum sensing for opportunistic access in fading environments. In Proceedings of the First IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks, Baltimore, MD, USA, 8–11 November 2005; DySPAN 2005. IEEE: Piscataway, NJ, USA, 2005; pp. 131–136. [Google Scholar]
- Wang, M.; Lin, Y.; Tian, Q.; Si, G. Transfer learning promotes 6G wireless communications: Recent advances and future challenges. IEEE Trans. Reliab. 2021, 70, 790–807. [Google Scholar] [CrossRef]
- Tu, Y.; Lin, Y.; Wang, J.; Kim, J.U. Semi-supervised learning with generative adversarial networks on digital signal modulation classification. Comput. Mater. Contin. 2018, 55, 243–254. [Google Scholar]
- Liao, F.; Wei, S.; Zou, S. Deep learning methods in communication systems: A review. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1617, p. 012024. [Google Scholar]
- Lin, Y.; Zhu, X.; Zheng, Z.; Dou, Z.; Zhou, R. The individual identification method of wireless device based on dimensionality reduction and machine learning. J. Supercomput. 2019, 75, 3010–3027. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, G.; Lin, Y.; Wu, H.C.; Yuen, C.; Adachi, F. Few-shot specific emitter identification via deep metric ensemble learning. IEEE Internet Things J. 2022, 9, 24980–24994. [Google Scholar] [CrossRef]
- Fu, X.; Peng, Y.; Liu, Y.; Lin, Y.; Gui, G.; Gacanin, H.; Adachi, F. Semi-supervised specific emitter identification method using metric-adversarial training. IEEE Internet Things J. 2023, 10, 10778–10789. [Google Scholar] [CrossRef]
- Fu, X.; Shi, S.; Wang, Y.; Lin, Y.; Gui, G.; Dobre, O.A.; Mao, S. Semi-Supervised Specific Emitter Identification via Dual Consistency Regularization. IEEE Internet Things J. 2023. Early Access. [Google Scholar] [CrossRef]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y.; Serdyuk, D.; Subramanian, S.; Santos, J.F.; Mehri, S.; Rostamzadeh, N.; Bengio, Y.; Pal, C.J. Deep complex networks. arXiv 2017, arXiv:1705.09792. [Google Scholar]
- Shi, Z.; Gao, W.; Zhang, S.; Liu, J.; Kato, N. AI-enhanced cooperative spectrum sensing for non-orthogonal multiple access. IEEE Wirel. Commun. 2019, 27, 173–179. [Google Scholar] [CrossRef]
- Lin, Y.; Zhao, H.; Ma, X.; Tu, Y.; Wang, M. Adversarial attacks in modulation recognition with convolutional neural networks. IEEE Trans. Reliab. 2020, 70, 389–401. [Google Scholar] [CrossRef]
- Bao, Z.; Lin, Y.; Zhang, S.; Li, Z.; Mao, S. Threat of adversarial attacks on DL-based IoT device identification. IEEE Internet Things J. 2021, 9, 9012–9024. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Works | Method | Strength | Weakness |
|---|---|---|---|
| Zheng et al. [13] | Likelihood-Based | Both known channel state information and blind recognition scenarios are discussed. | Restricted to OFDM. |
| Ghauri et al. [14] | HMM and genetic algorithms | Higher recognition accuracy than other traditional methods. | Few types of recognition, and only one can exist at the same time. |
| Punith Kumar H.L et al. [15] | Decision theoretic approach | Based on the minimum feature extraction, quickly performed through the decision tree. | Compared with the accuracy of using a more complex deep learning model, the recognition accuracy is still not high; still limited to only one signal at one time. |
| M. Abu-Romoh et al. [16] | likelihood-based and feature-based | Achieved 100% accuracy in classifying QAM and PSK at 18dB. | Exhibited a significant decrease in accuracy at low SNR; still limited to only one signal at one time. |
| Y. Wang et al. [21] | CNN (DrCNN and MaxCNN) | Various digital communication signals including 16QAM and 64QAM can be distinguished. | Requires multiple data set inputs; only one signal can be resolved in data at a time. |
| Emad et al. [23] | CNN | Have been implemented on a GPU and an FPGA; modulation types up to 11 kinds. | Recognition accuracy is slightly lower; still only single signal modulation recognition. |
| Liu et al. [24] | GA-BP neural network | Good performance on radar signals recognition under the low SNR conditions. | Common communication modulations are not covered and still only for single signal modulation recognition. |
| Hou et al. [25] | Complex-ResNet and sliding window | High detection accuracy, multi-signal covered. | Not end-to-end, leading to a reduction in detection speed. |
| Type | Parameters | Range |
|---|---|---|
| M-ASK | Carrier Frequency | (0.07–0.43)* |
| Symbol Width | (1/25–1/10)*N/ | |
| M | [10,15,20,25] | |
| 2FSK | Carrier Frequency , | (0.07–0.43)*, |
| (1/25–1/10)*N/ | ||
| 16QAM | (1/25–1/10)*N/ | |
| DSB-SC | (0.07–0.43)* | |
| Baseband | (0.005–0.007)* | |
| SSB | (0.07–0.43)* | |
| (0.005–0.007)* |
| Feature Extraction Parts | CNN | CLDNN | Complex-Conv |
|---|---|---|---|
| Total Parameters | 39.0 M | 41.1 M | 77.3 M |
| Precision | Recall | F1-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SNR(dB) | Complex-conv | CLDNN | CNN | Complex-conv | CLDNN | CNN | Complex-conv | CLDNN | CNN |
| 10 | 0.96205 | 0.93756 | 0.93991 | 0.91481 | 0.90221 | 0.90711 | 0.93784 | 0.91954 | 0.92322 |
| 6 | 0.95905 | 0.92890 | 0.93511 | 0.91091 | 0.88041 | 0.89481 | 0.93436 | 0.90400 | 0.91452 |
| 0 | 0.91343 | 0.89534 | 0.87564 | 0.81551 | 0.78221 | 0.79981 | 0.86170 | 0.82629 | 0.84488 |
| −6 | 0.74680 | 0.70079 | 0.72603 | 0.59871 | 0.58831 | 0.59371 | 0.66461 | 0.64996 | 0.64282 |
| −10 | 0.44593 | 0.45719 | 0.39159 | 0.37851 | 0.38861 | 0.40071 | 0.40946 | 0.42012 | 0.39610 |
| −18 | 0.09940 | 0.10380 | 0.08841 | 0.10501 | 0.10211 | 0.14161 | 0.10213 | 0.10295 | 0.10885 |
| Fusion and Conditions | Node = 1, Complex-conv with 20 Epochs, 60% Dataset | Node = 1, Complex-conv with 30 Epochs, 100% Dataset | Node = 6, Complex-conv with 20 Epochs, 60% Dataset | Node = 6, DAG-SVM [36] with Obtained Training Data Size |
|---|---|---|---|---|
| F1-score (Sensing Accuracy) | 0.8405 | 0.8678 | 0.8933 | 0.8343 |
| Feature Extraction Parts | Single | Fusion | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 20 Epochs, 60% Dataset | 30 Epochs, 100% Dataset | 6 Nodes, 20 Epochs, 60% Dataset | |||||||
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| CNN | 0.79664 | 0.69881 | 0.74452 | 0.89661 | 0.80121 | 0.84623 | 0.91542 | 0.85281 | 0.88301 |
| CLDNN | 0.73912 | 0.61761 | 0.67292 | 0.88575 | 0.80001 | 0.84070 | 0.92616 | 0.86281 | 0.89336 |
| Complex-conv | 0.88570 | 0.79961 | 0.84046 | 0.91790 | 0.82281 | 0.86776 | 0.92503 | 0.86361 | 0.89327 |
| Feature Extraction Parts | CNN | CLDNN | Complex-Conv |
|---|---|---|---|
| Runtime (ms) | 4.0298 | 21.0138 | 13.9534 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, C.; Fu, D.; Zhou, Z.; Wu, X. A Deep Learning-Based Multi-Signal Radio Spectrum Monitoring Method for UAV Communication. Drones 2023, 7, 511. https://doi.org/10.3390/drones7080511
Hou C, Fu D, Zhou Z, Wu X. A Deep Learning-Based Multi-Signal Radio Spectrum Monitoring Method for UAV Communication. Drones. 2023; 7(8):511. https://doi.org/10.3390/drones7080511
Chicago/Turabian StyleHou, Changbo, Dingyi Fu, Zhichao Zhou, and Xiangyu Wu. 2023. "A Deep Learning-Based Multi-Signal Radio Spectrum Monitoring Method for UAV Communication" Drones 7, no. 8: 511. https://doi.org/10.3390/drones7080511
APA StyleHou, C., Fu, D., Zhou, Z., & Wu, X. (2023). A Deep Learning-Based Multi-Signal Radio Spectrum Monitoring Method for UAV Communication. Drones, 7(8), 511. https://doi.org/10.3390/drones7080511