
Development of Unmanned Aerial Vehicle Navigation and Warehouse Inventory System Based on Reinforcement Learning


Abstract
:1. Introduction
2. Related Works
2.1. Indoor Localization and Path Planning
2.2. Warehouse Inventory Inspection
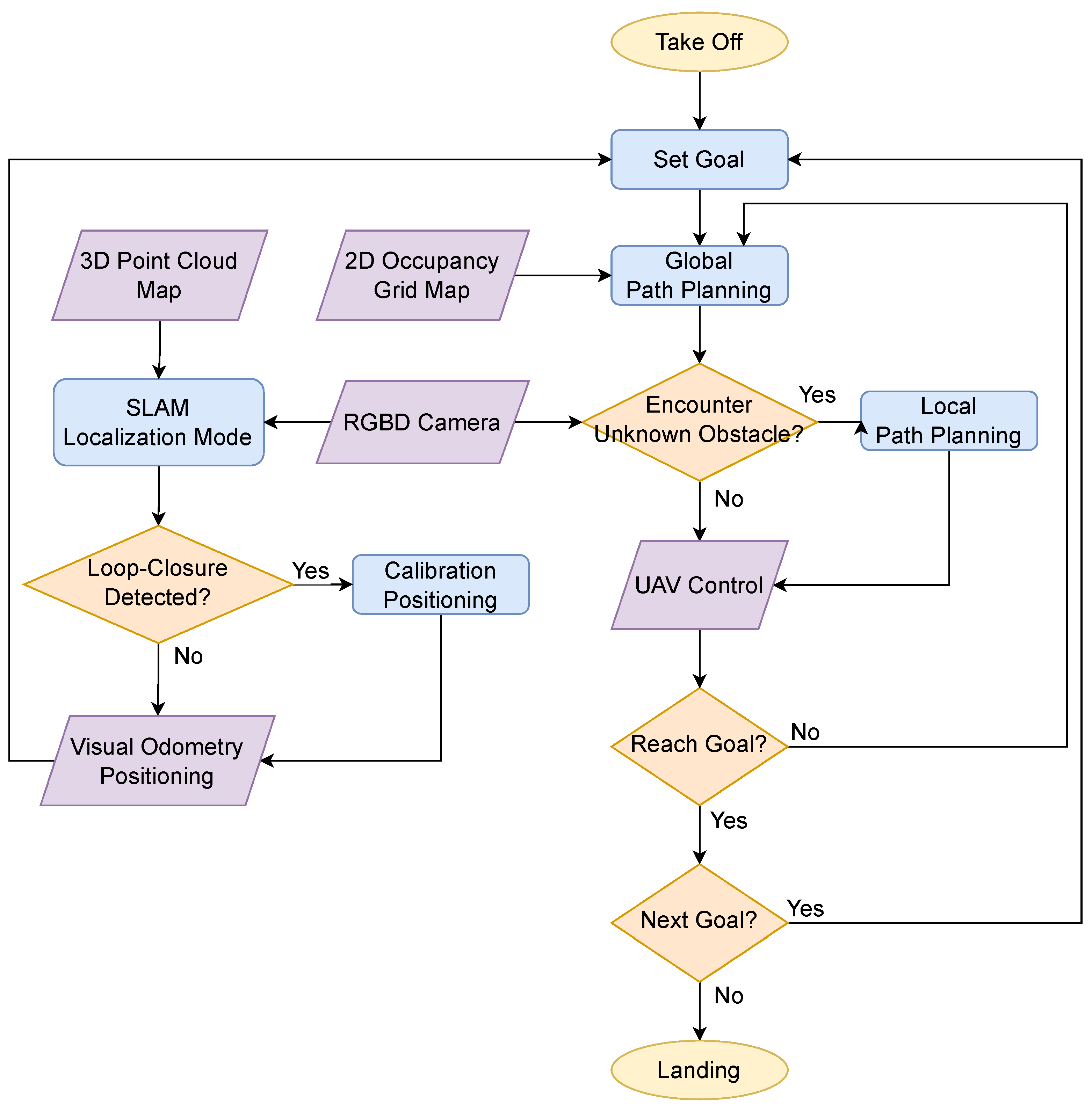
3. Localization and Navigation
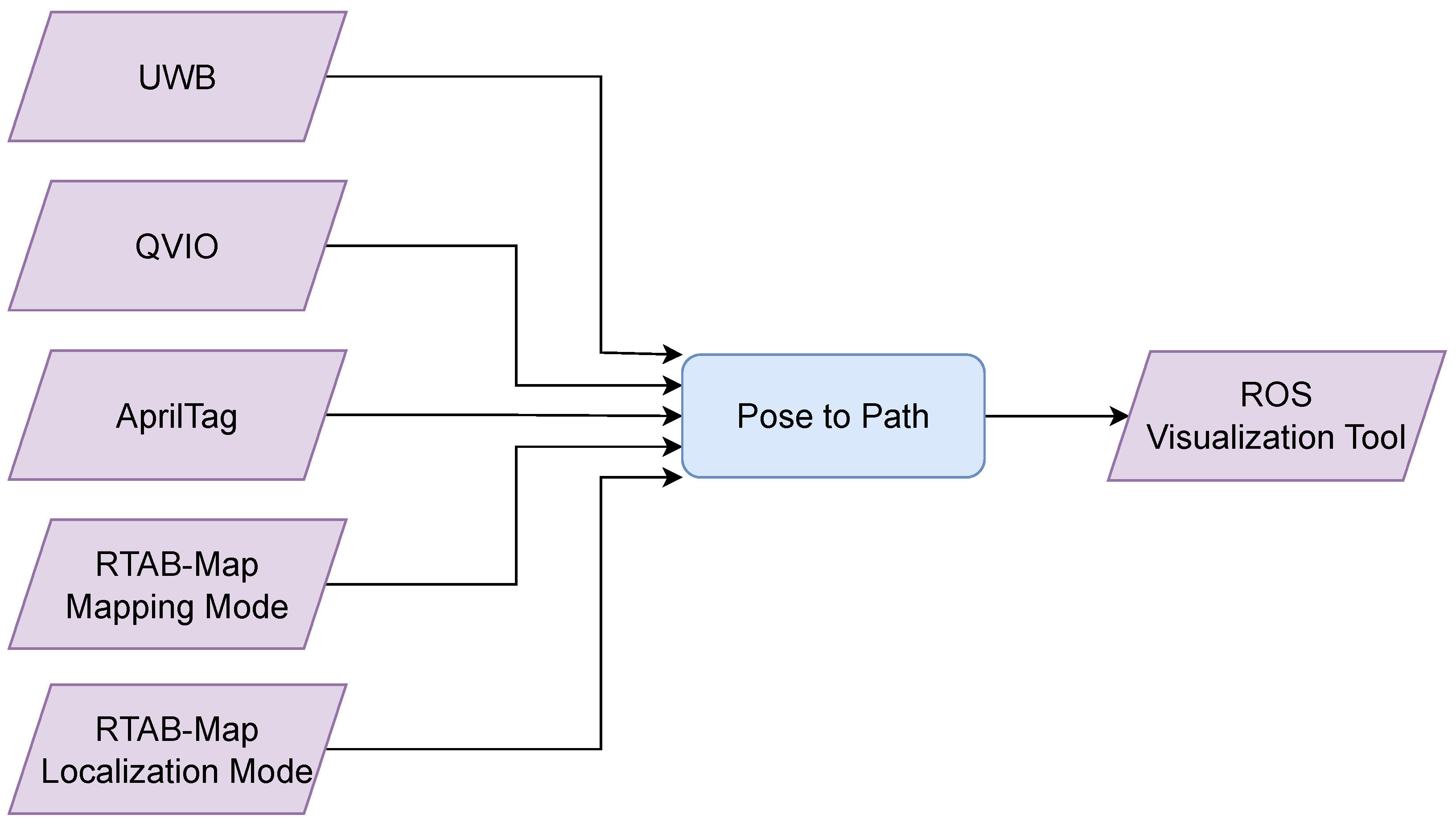
3.1. Indoor Mapping and Positioning
3.2. Path Planning with Obstacle Avoidance
4. Warehouse Inventory Inspection
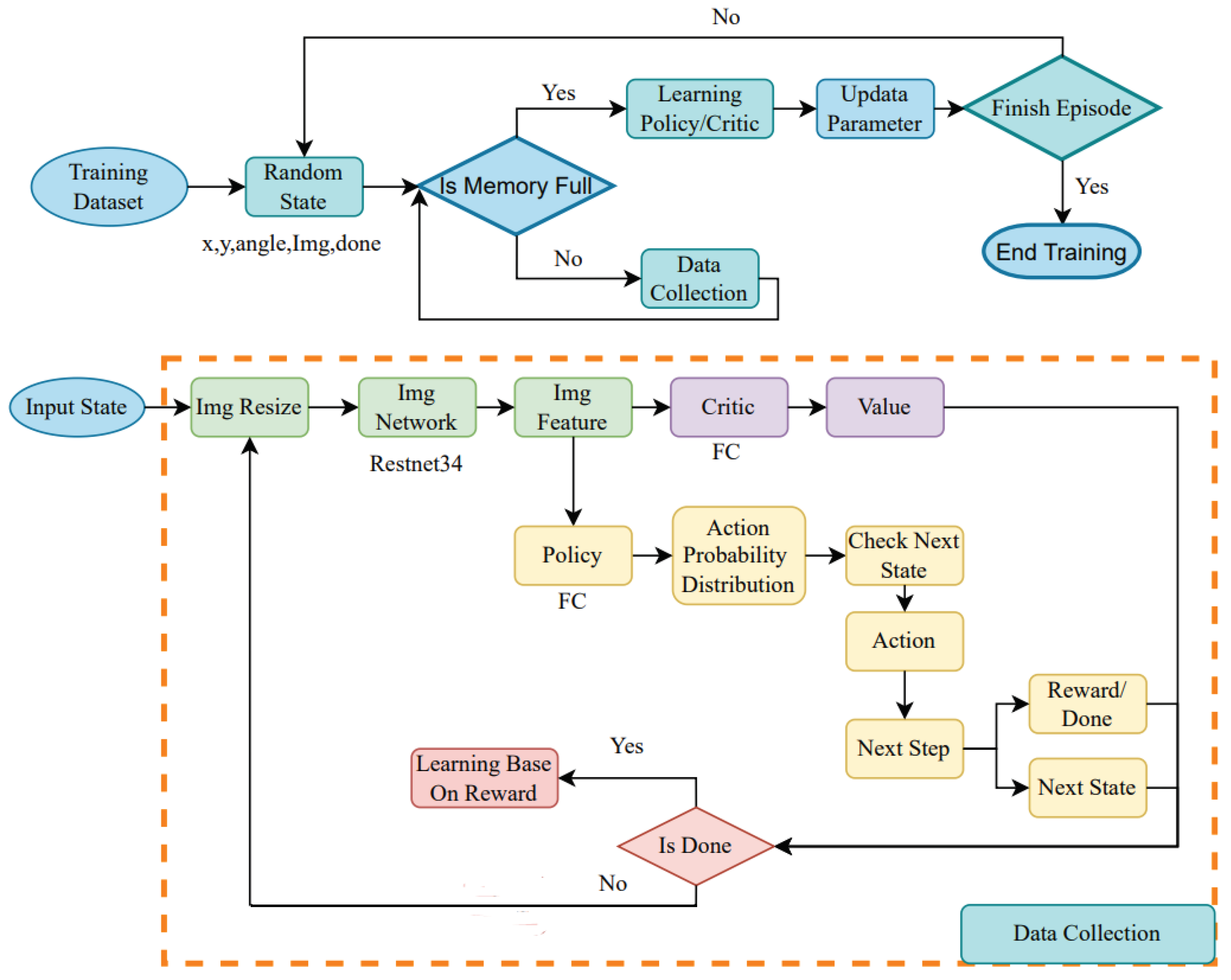
4.1. Proposed Reinforcement Learning Framework
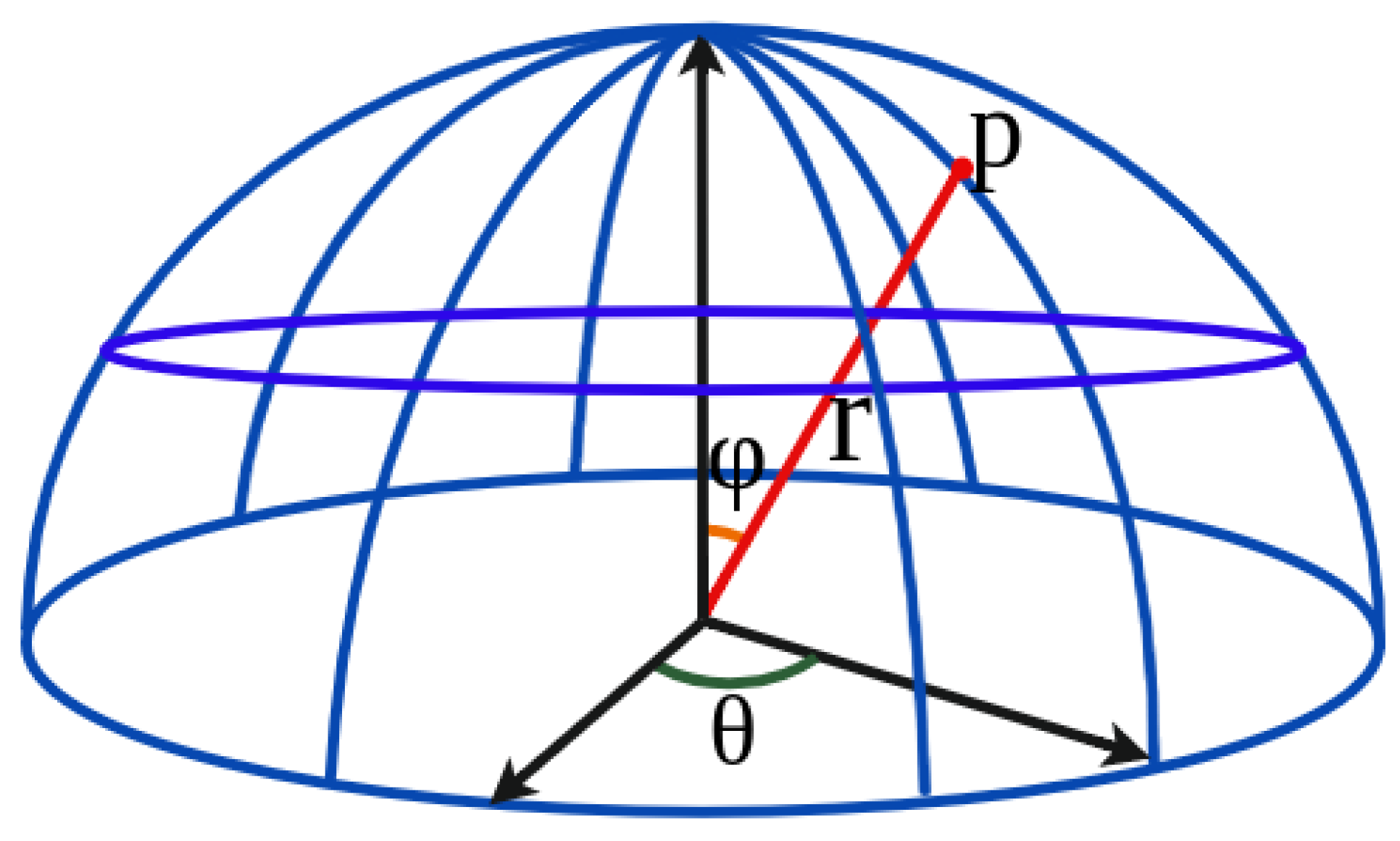
4.2. Action Selection
4.3. Reward Function
4.4. Network
4.4.1. PPO (Proximal Policy Optimization)
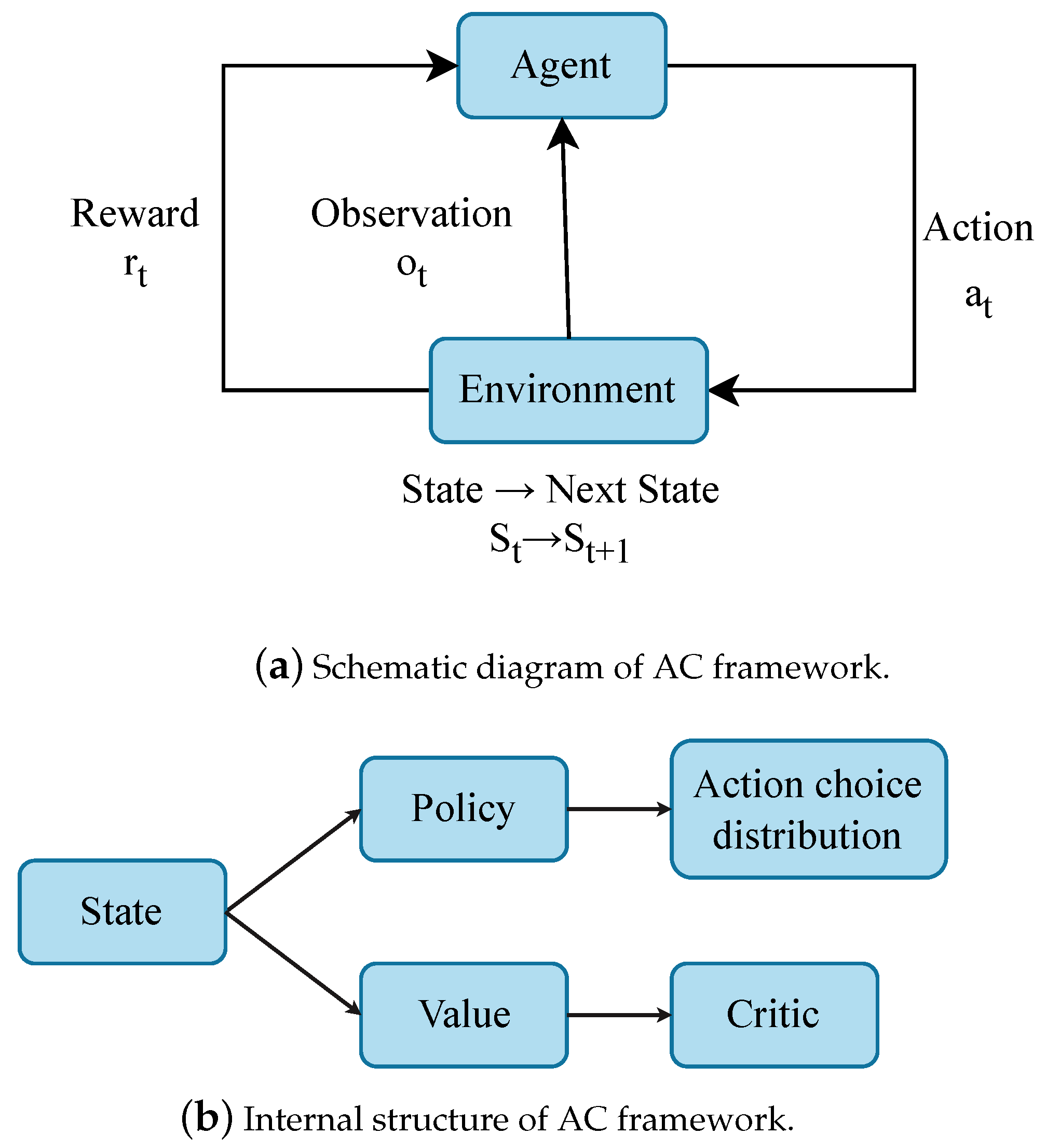
4.4.2. AC (Actor–Critic)
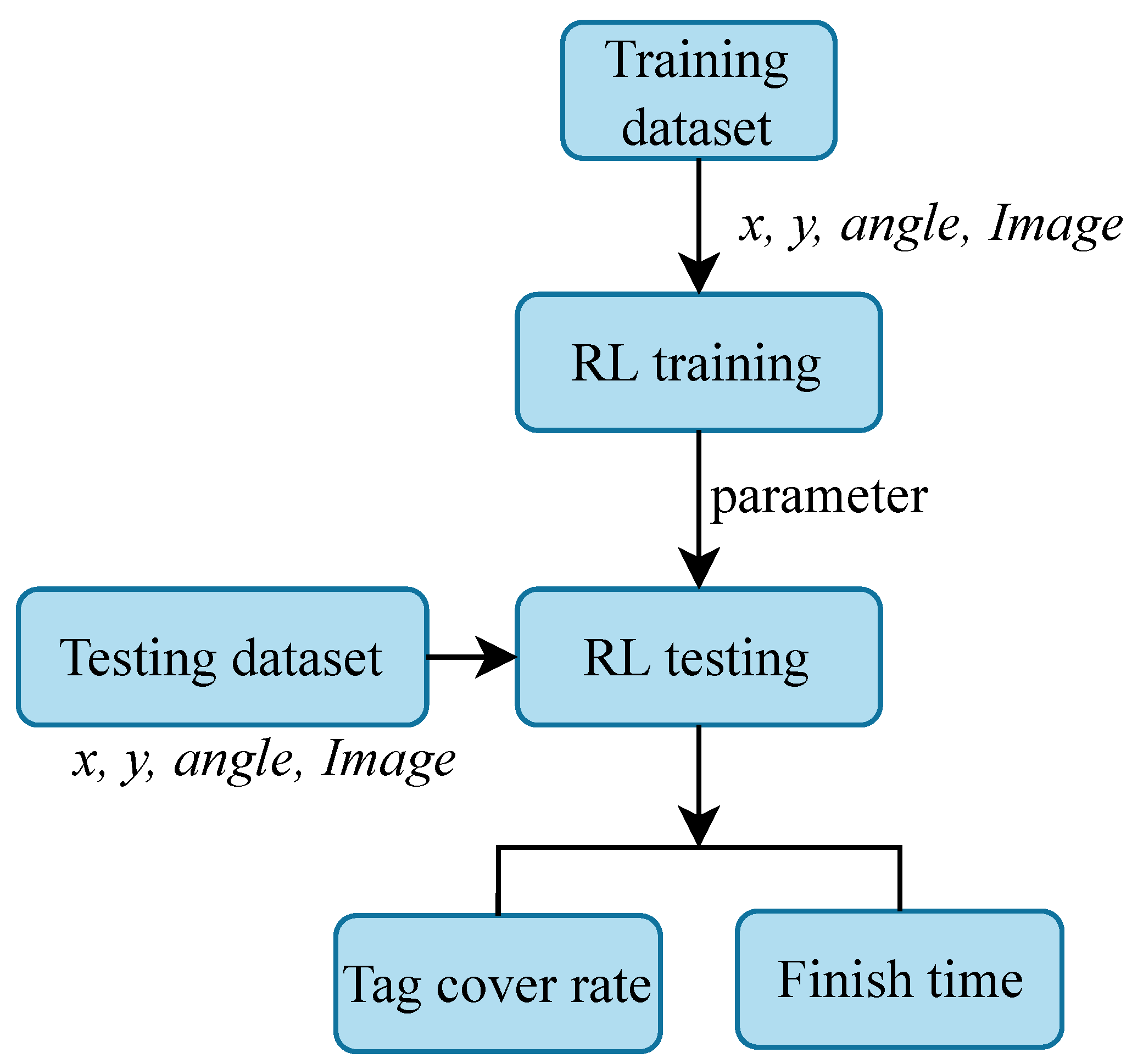
4.5. Dataset
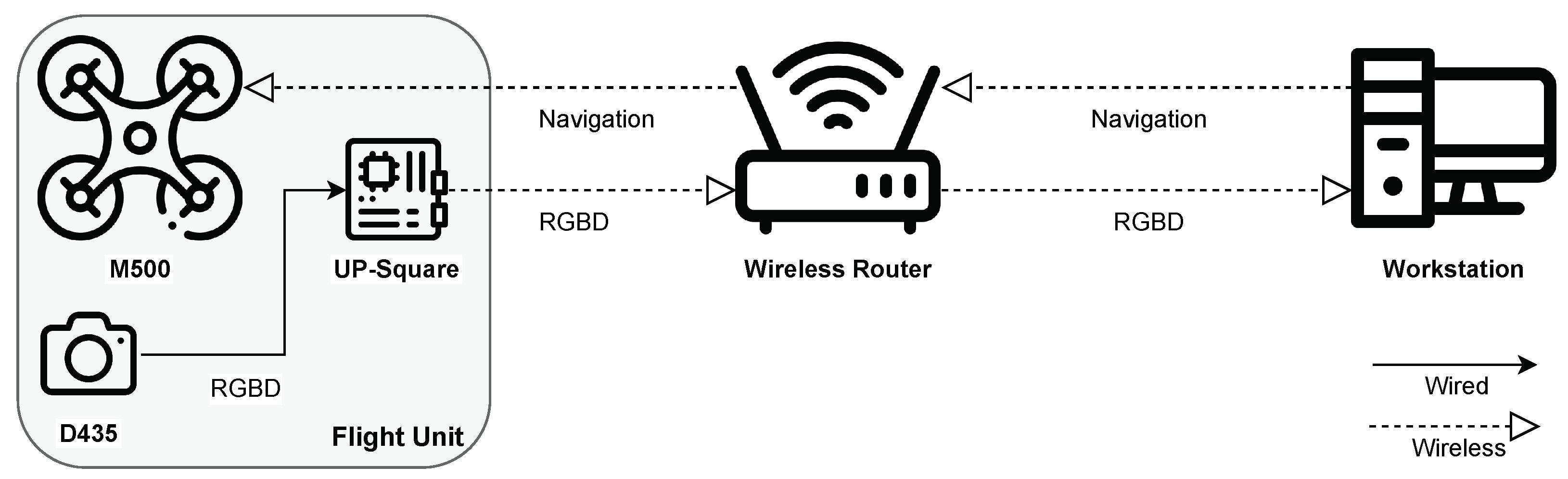
5. Experiments
5.1. Indoor Mapping and Positioning
- Scenario 1: When the drone images detects a loop closure in the previously constructed map, it corrects the accumulated drift error of the visual odometry, achieving global indoor localization.
- Scenario 2: When the loop closure is undetected, the drone relies solely on visual odometry and extracts visual features for local indoor localization.
- Scenario 3: When loop closure is rejected, this indicates that loop closure is detected but does not exceed the pre-set threshold for acceptance. This typically occurs when the drone’s position is correct, but there is some slight deviation in the orientation.
- Scenario 4: When odometry is lost, this means the drone’s visual odometry is unable to maintain continuity with the previous frame, due to significant and rapid image motion in a short period. This often happens if the drone rotates in place, resulting in an instantaneous angular velocity.
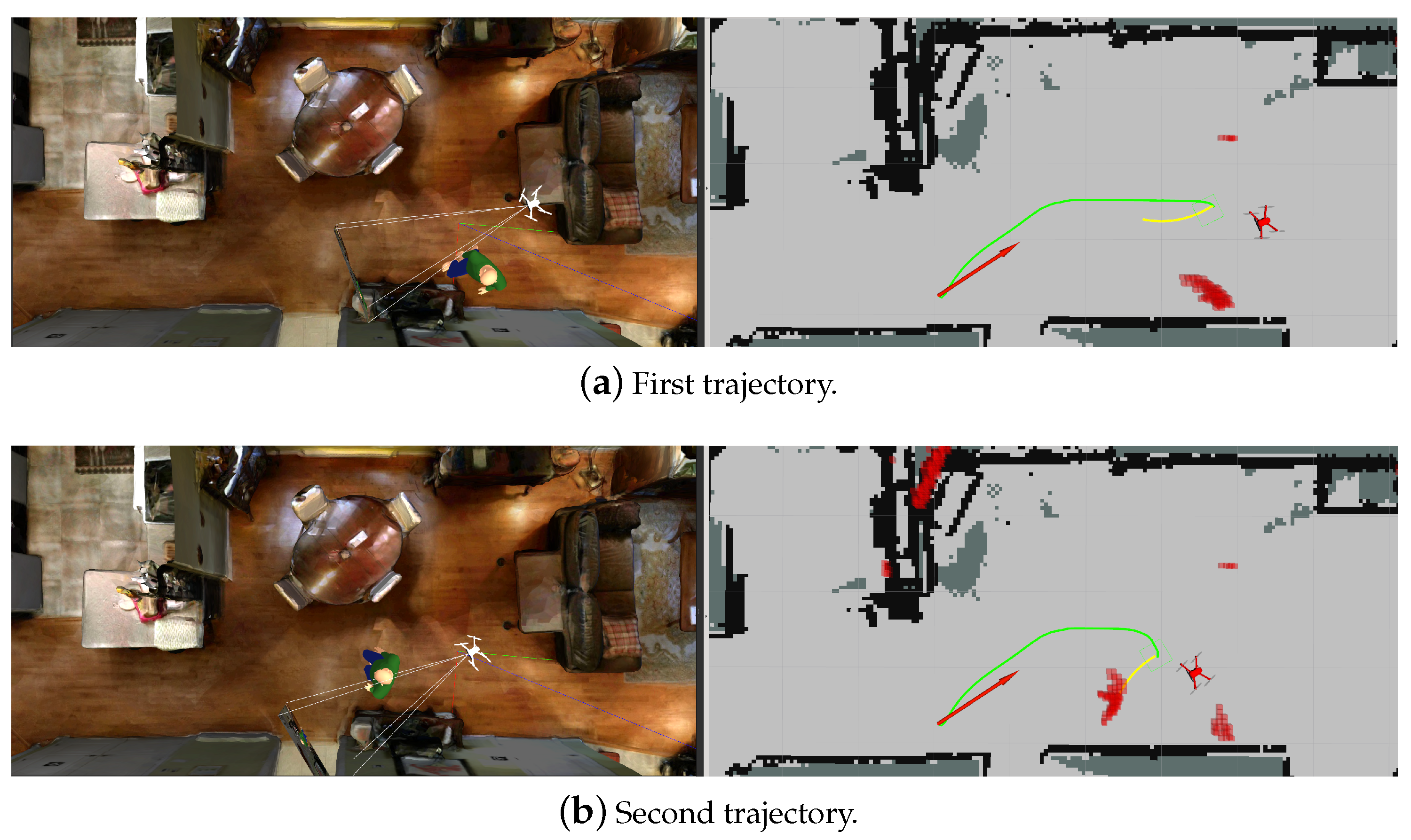
5.2. Path Planning with Obstacle Avoidance
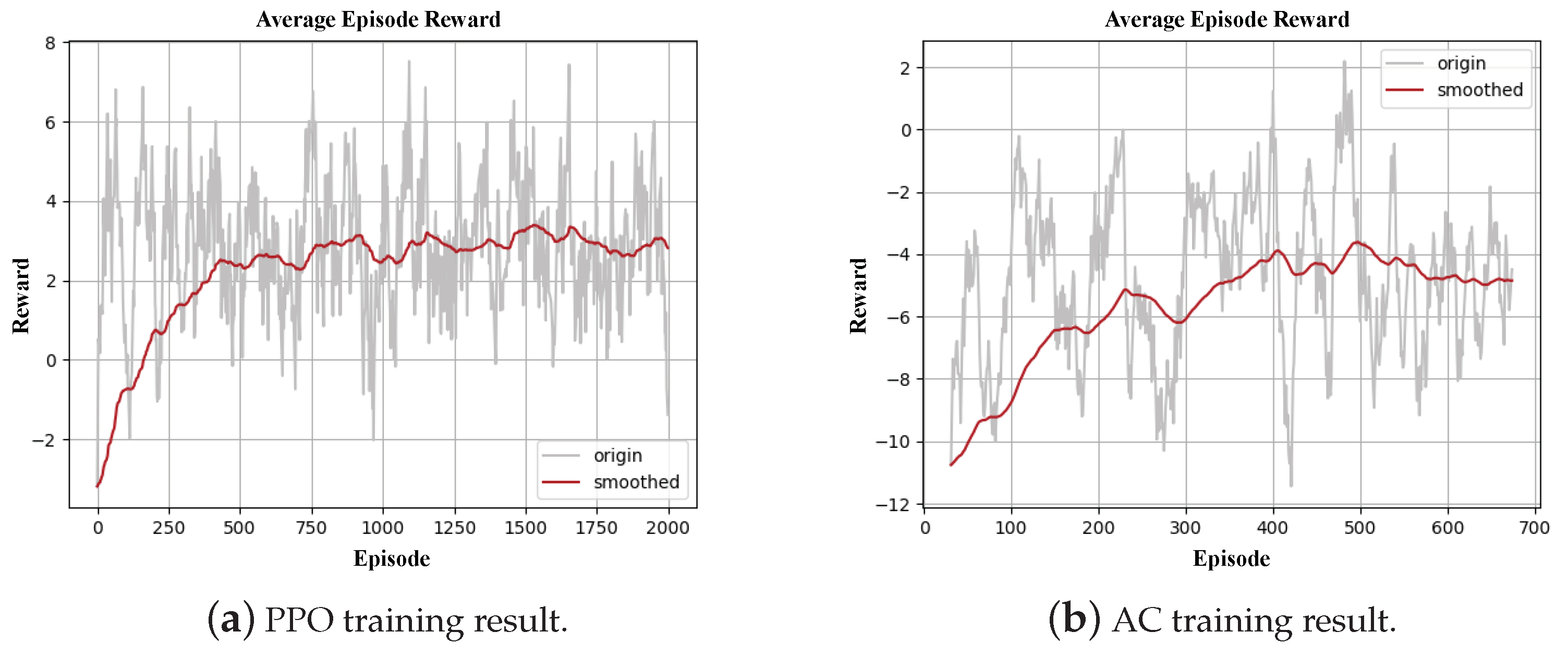
5.3. Inventory Inspection
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, H.Y.; Peng, X.Z. Autonomous quadrotor navigation with vision based obstacle avoidance and path planning. IEEE Access 2021, 9, 102450–102459. [Google Scholar] [CrossRef]
- de Jesus, J.C.; Kich, V.A.; Kolling, A.H.; Grando, R.B.; Guerra, R.S.; Drews, P.L.J. Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 10579–10586. [Google Scholar] [CrossRef]
- Moura, A.; Antunes, J.; Dias, A.; Martins, A.; Almeida, J. Graph-SLAM Approach for Indoor UAV Localization in Warehouse Logistics Applications. In Proceedings of the 2021 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Santa Maria da Feira, Portugal, 28–29 April 2021; pp. 4–11. [Google Scholar] [CrossRef]
- Awate, Y.P. Policy-Gradient Based Actor-Critic Algorithms. In Proceedings of the 2009 WRI Global Congress on Intelligent Systems, Xiamen, China, 19–21 May 2009; Volume 3, pp. 505–509. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Xia, J.; Li, S.; Wang, Y.; Jiang, B. Research on uwb/ble-based fusion indoor positioning algorithm and system application. In Proceedings of the 2021 International Symposium on Computer Technology and Information Science (ISCTIS), Guilin, China, 4–6 June 2021; pp. 50–54. [Google Scholar]
- Xia, J.; Wu, Y.; Du, X. Indoor Positioning Technology Based on the Fusion of UWB and BLE. In Proceedings of the Security, Privacy, and Anonymity in Computation, Communication, and Storage: SpaCCS 2020 International Workshops, Nanjing, China, 18–20 December 2020; Springer: Cham, Switzerland, 2021; pp. 209–221. [Google Scholar]
- Shang, S.; Wang, L. Overview of WiFi fingerprinting-based indoor positioning. IET Commun. 2022, 16, 725–733. [Google Scholar] [CrossRef]
- Deng, W.; Li, J.; Tang, Y.; Zhang, X. Low-Complexity Joint Angle of Arrival and Time of Arrival Estimation of Multipath Signal in UWB System. Sensors 2023, 23, 6363. [Google Scholar] [CrossRef] [PubMed]
- Krogius, M.; Haggenmiller, A.; Olson, E. Flexible layouts for fiducial tags. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 1898–1903. [Google Scholar]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.J.; Marín-Jiménez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Kato, H.; Billinghurst, M. Marker tracking and hmd calibration for a video-based augmented reality conferencing system. In Proceedings of the 2nd IEEE and ACM International Workshop on Augmented Reality (IWAR’99), San Francisco, CA, USA, 20–21 October 1999; pp. 85–94. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Mourikis, A.I.; Roumeliotis, S.I. A multi-state constraint Kalman filter for vision-aided inertial navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Labbé, M.; Michaud, F. RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J. Field Robot. 2019, 36, 416–446. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Lin, H.Y.; Tu, K.C.; Li, C.Y. Vaid: An aerial image dataset for vehicle detection and classification. IEEE Access 2020, 8, 212209–212219. [Google Scholar] [CrossRef]
- Ghosh, S.K. Visibility Algorithms in the Plane; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Chaari, I.; Koubaa, A.; Bennaceur, H.; Ammar, A.; Alajlan, M.; Youssef, H. Design and performance analysis of global path planning techniques for autonomous mobile robots in grid environments. Int. J. Adv. Robot. Syst. 2017, 14, 1729881416663663. [Google Scholar] [CrossRef]
- Tsardoulias, E.G.; Iliakopoulou, A.; Kargakos, A.; Petrou, L. A review of global path planning methods for occupancy grid maps regardless of obstacle density. J. Intell. Robot. Syst. 2016, 84, 829–858. [Google Scholar] [CrossRef]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. Int. J. Robot. Res. 1986, 5, 90–98. [Google Scholar] [CrossRef]
- Kobayashi, M.; Motoi, N. Local path planning: Dynamic window approach with virtual manipulators considering dynamic obstacles. IEEE Access 2022, 10, 17018–17029. [Google Scholar] [CrossRef]
- Kalinov, I.; Petrovsky, A.; Ilin, V.; Pristanskiy, E.; Kurenkov, M.; Ramzhaev, V.; Idrisov, I.; Tsetserukou, D. WareVision: CNN Barcode Detection-Based UAV Trajectory Optimization for Autonomous Warehouse Stocktaking. IEEE Robot. Autom. Lett. 2020, 5, 6647–6653. [Google Scholar] [CrossRef]
- Yang, S.Y.; Jan, H.C.; Chen, C.Y.; Wang, M.S. CNN-Based QR Code Reading of Package for Unmanned Aerial Vehicle. Sensors 2023, 23, 4707. [Google Scholar] [CrossRef]
- Babu, S.; Markose, S. IoT enabled Robots with QR Code based localization. In Proceedings of the 2018 International Conference on Emerging Trends and Innovations In Engineering And Technological Research (ICETIETR), Ernakulam, India, 11–13 July 2018; pp. 1–5. [Google Scholar]
- Cho, H.; Kim, D.; Park, J.; Roh, K.; Hwang, W. 2D barcode detection using images for drone-assisted inventory management. In Proceedings of the 2018 15th International Conference on Ubiquitous Robots (UR), Honolulu, HI, USA, 26–30 June 2018; pp. 461–465. [Google Scholar]
- Cristiani, D.; Bottonelli, F.; Trotta, A.; Di Felice, M. Inventory Management through Mini-Drones: Architecture and Proof-of-Concept Implementation. In Proceedings of the 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Cork, Ireland, 31 August–3 September 2020; pp. 317–322. [Google Scholar] [CrossRef]
- Yoon, B.; Kim, H.; Youn, G.; Rhee, J. 3D position estimation of drone and object based on QR code segmentation model for inventory management automation. In Proceedings of the 2021 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), New York, NY, USA, 25–27 October 2021; pp. 223–229. [Google Scholar]
- Rhiat, A.; Chalal, L.; Saadane, A. A Smart Warehouse Using Robots and Drone to Optimize Inventory Management. In Proceedings of the Future Technologies Conference (FTC), Virtual, 28–29 October 2021; Springer: Cham, Switzerland, 2022; Volume 1, pp. 475–483. [Google Scholar]
- Manjrekar, A.; Jha, D.S.; Jagtap, P.; Yadav, V. Warehouse inventory management with cycle counting using drones. In Proceedings of the 4th International Conference on Advances in Science & Technology (ICAST2021), Bahir Dar, Ethiopia, 27–29 August 2021. [Google Scholar]
- Vamsi, A.M.; Deepalakshmi, P.; Nagaraj, P.; Awasthi, A.; Raj, A. IOT based autonomous inventory management for warehouses. In Proceedings of the EAI International Conference on Big Data Innovation for Sustainable Cognitive Computing: BDCC, Coimbatore, India, 13–15 December 2018; Springer: Cham, Switzerland, 2020; pp. 371–376. [Google Scholar]
- Kalaitzakis, M.; Cain, B.; Carroll, S.; Ambrosi, A.; Whitehead, C.; Vitzilaios, N. Fiducial markers for pose estimation: Overview, applications and experimental comparison of the artag, apriltag, aruco and stag markers. J. Intell. Robot. Syst. 2021, 101, 71. [Google Scholar] [CrossRef]
- Wang, J.; Olson, E. AprilTag 2: Efficient and robust fiducial detection. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4193–4198. [Google Scholar] [CrossRef]
- Brock, O.; Khatib, O. High-speed navigation using the global dynamic window approach. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No. 99CH36288C), Detroit, MI, USA, 10–15 May 1999; Volume 1, pp. 341–346. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. In Edsger Wybe Dijkstra: His Life, Work, and Legacy; Association for Computing Machinery: New York, NY, USA, 2022; pp. 287–290. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Koonce, B.; Koonce, B. ResNet 34. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 51–61. [Google Scholar]
- Shani, L.; Efroni, Y.; Mannor, S. Adaptive trust region policy optimization: Global convergence and faster rates for regularized mdps. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5668–5675. [Google Scholar]
- Zhong, H.; Zhang, T. A theoretical analysis of optimistic proximal policy optimization in linear markov decision processes. Adv. Neural Inf. Process. Syst. 2024, 36, 1–25. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)(IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar]
- Malang, C.; Charoenkwan, P.; Wudhikarn, R. Implementation and critical factors of unmanned aerial vehicle (UAV) in warehouse management: A systematic literature review. Drones 2023, 7, 80. [Google Scholar] [CrossRef]
- Guérin, F.; Guinand, F.; Brethé, J.F.; Pelvillain, H. Towards an autonomous warehouse inventory scheme. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Kwon, W.; Park, J.H.; Lee, M.; Her, J.; Kim, S.H.; Seo, J.W. Robust autonomous navigation of unmanned aerial vehicles (UAVs) for warehouses’ inventory application. IEEE Robot. Autom. Lett. 2019, 5, 243–249. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Number | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Action Direction |
| State | Unavailable Actions | Available Actions |
|---|---|---|
| 0, 4, 6 | 1, 2, 3, 5, 7 | |
| 2, 5, 7 | 0, 1, 3, 4, 6 | |
| 1, 4, 5 | 0, 2, 3, 6, 7 | |
| 3, 6, 7 | 0, 1, 2, 4, 5 |
| Max Movement | Episode Update | Learning Rate | ||
|---|---|---|---|---|
| PPO | 50 | 20 | 0.02 | 0.2 |
| AC | 100 | 24 | 0.0002 | 0.2 |
| Exp. | No. | Step | Coverage | Exp. | No. | Step | Coverage |
|---|---|---|---|---|---|---|---|
| 1 | 16 | 19 | 100% | 1 | 14 | 50 | 87.5% |
| 2 | 16 | 11 | 100% | 2 | 16 | 40 | 100% |
| 3 | 15 | 50 | 92.31% | 3 | 16 | 19 | 100% |
| 4 | 16 | 17 | 100% | 4 | 16 | 37 | 100% |
| 5 | 16 | 13 | 100% | 5 | 16 | 44 | 100% |
| 6 | 16 | 15 | 100% | 6 | 15 | 50 | 93.75% |
| 7 | 16 | 10 | 100% | 7 | 16 | 31 | 100% |
| 8 | 16 | 13 | 100% | 8 | 16 | 28 | 100% |
| 9 | 16 | 14 | 100% | 9 | 16 | 19 | 100% |
| 10 | 16 | 16 | 100% | 10 | 16 | 38 | 100% |
| Average | 15.9 | 16.2 | 99.38% | Average | 15.7 | 36.4 | 98.13% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.-Y.; Chang, K.-L.; Huang, H.-Y. Development of Unmanned Aerial Vehicle Navigation and Warehouse Inventory System Based on Reinforcement Learning. Drones 2024, 8, 220. https://doi.org/10.3390/drones8060220
Lin H-Y, Chang K-L, Huang H-Y. Development of Unmanned Aerial Vehicle Navigation and Warehouse Inventory System Based on Reinforcement Learning. Drones. 2024; 8(6):220. https://doi.org/10.3390/drones8060220
Chicago/Turabian StyleLin, Huei-Yung, Kai-Lun Chang, and Hsin-Ying Huang. 2024. "Development of Unmanned Aerial Vehicle Navigation and Warehouse Inventory System Based on Reinforcement Learning" Drones 8, no. 6: 220. https://doi.org/10.3390/drones8060220
APA StyleLin, H.-Y., Chang, K.-L., & Huang, H.-Y. (2024). Development of Unmanned Aerial Vehicle Navigation and Warehouse Inventory System Based on Reinforcement Learning. Drones, 8(6), 220. https://doi.org/10.3390/drones8060220