
A Lightweight Neural Network for the Real-Time Dehazing of Tidal Flat UAV Images Using a Contrastive Learning Strategy


Abstract
1. Introduction
- In current dehazing network research, there is often a trade-off between efficiency and performance. Traditional models primarily use single-scale convolutional kernels, which limit their ability to capture multi-scale features within images. This paper introduces a method employing multi-scale convolution, enabling the network to recognize different scale features more comprehensively in the image, thereby enhancing the in-depth understanding of image semantics. At the same time, to address the deficiencies of traditional dehazing networks in information transmission and reuse, this study incorporates dense and residual connections, which optimize the flow of information, reduce parameter redundancy, and accelerate training speed. Through this approach, we ensure that the model can significantly enhance the dehazing performance for tidal flat images while maintaining real-time image processing capabilities.
- Due to the vast shooting range of UAVs, remote sensing images captured by drones often cover a complex and diverse range of scenes and changes. Traditional dehazing networks rely on fixed attention distributions or simple regional weighting. To enhance the network’s processing capability for tidal flat terrain remote sensing images, the attention mechanism was improved in the presented study. The improved mechanism is able to adaptively adjust the network’s focus based on the differences in feature information across various regions in the tidal flat images, guiding the network to focus on critical areas that are crucial to the dehazing effect. Through this, it not only preserves the texture details of the image more effectively, improving visual quality, but also enhances the stability and reliability of the dehazing process.
- The design of a loss function typically relies on simple loss functions such as mean squared error (MSE). However, the contribution of the present study lies in the design of a new composite loss function that combines contrastive learning strategies. This loss function, compared to a single loss function, is able to avoid the overfitting phenomenon of the network model and more effectively reduce the differences between the generated image and the clear image, thereby achieving more realistic color restoration while removing fog. The above provides a foundation for the subsequent effective monitoring of tidal flat terrain.
2. Preparation Knowledge
2.1. Atmospheric Scattering Physics Model and Conversion Formula
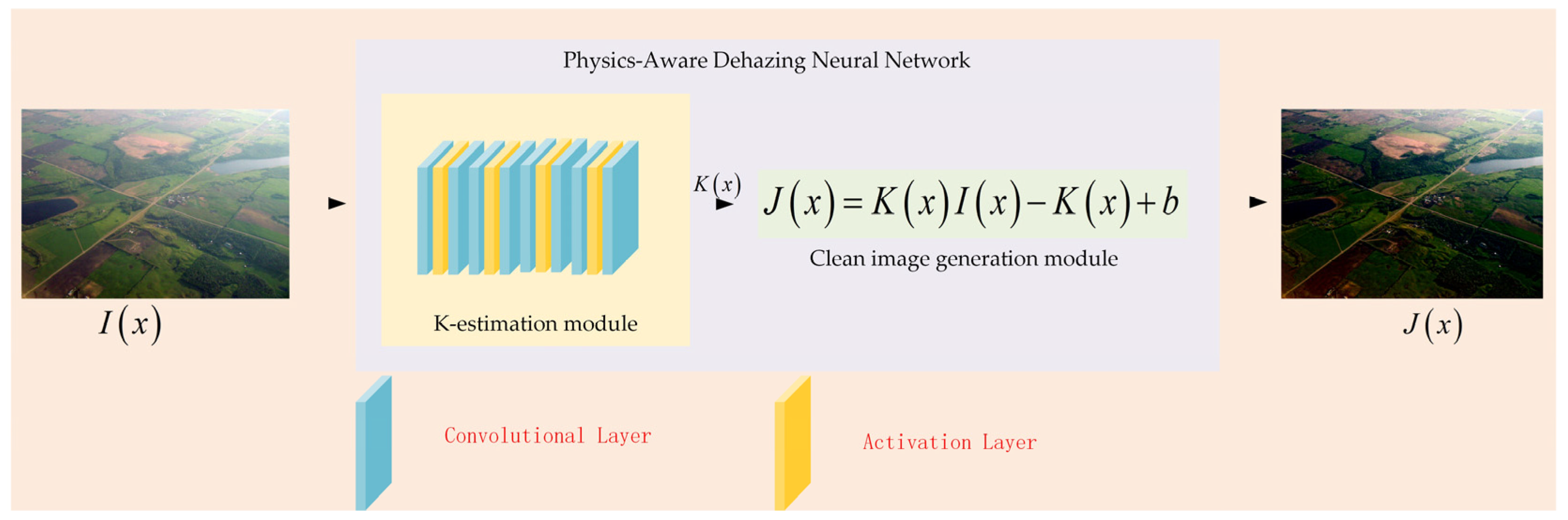
2.2. Physics-Aware Dehazing Neural Network
3. Modeling and Extension
3.1. Overall Structure of Multi-Scale Dense Residual Convolution Networks
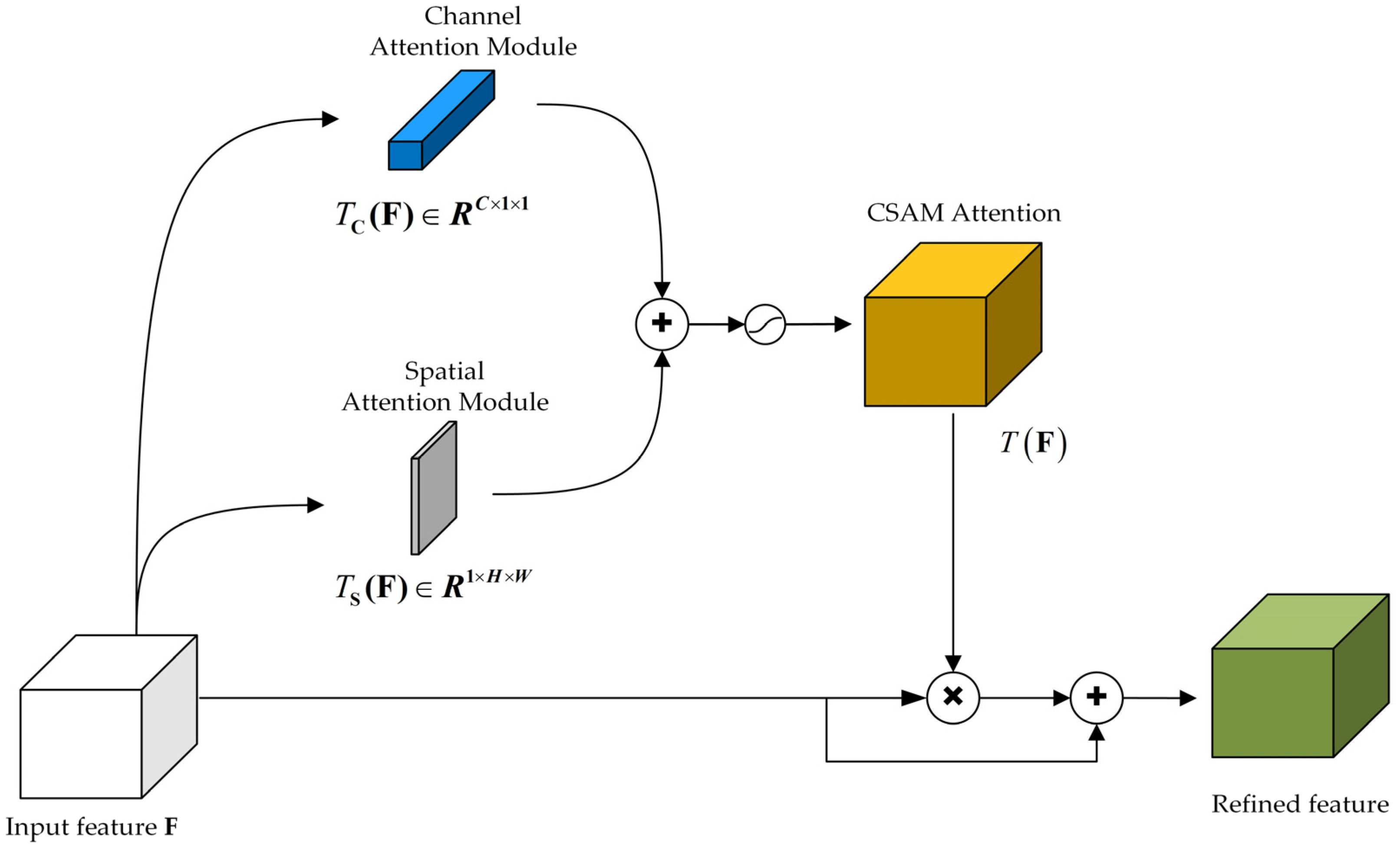
3.2. Channel and Spatial Attention Module (CSAM)
3.2.1. Improved Channel Attention Module (CAM)
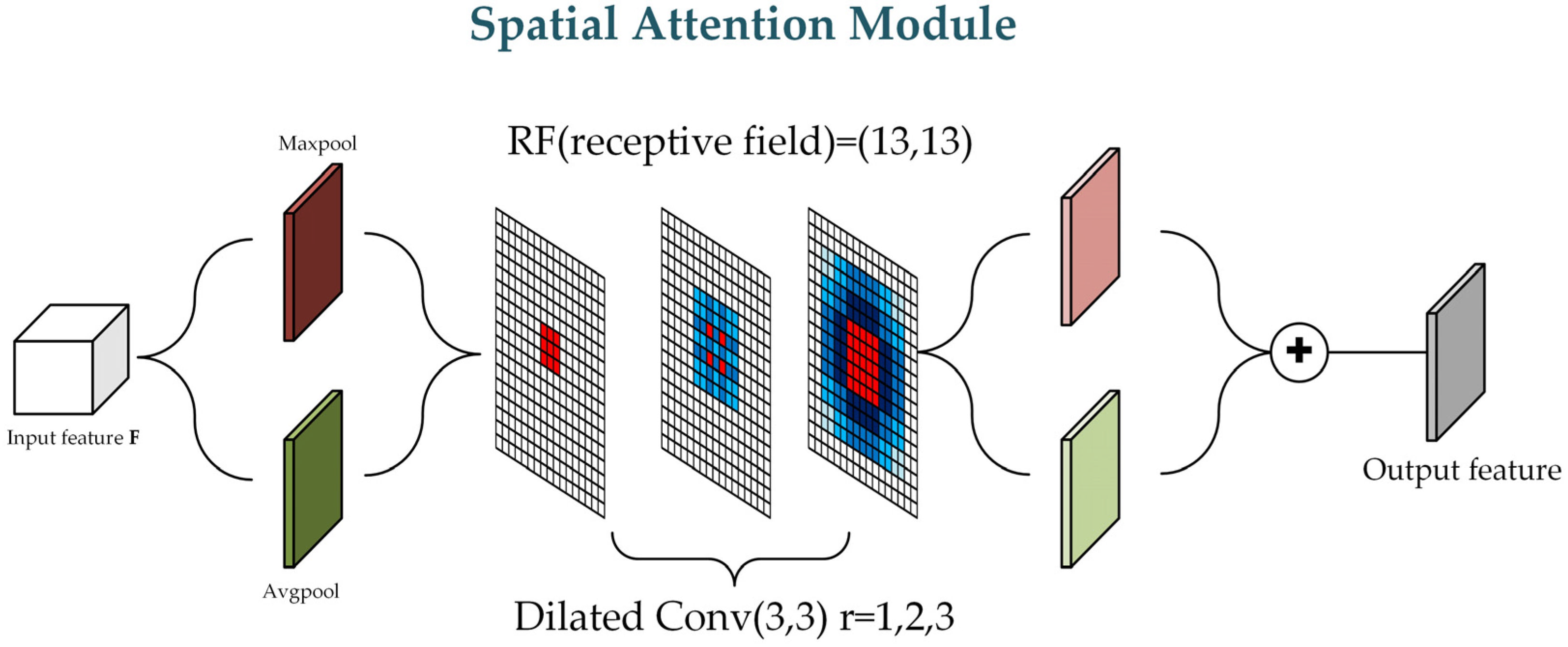
3.2.2. Spatial Attention Module (SAM)
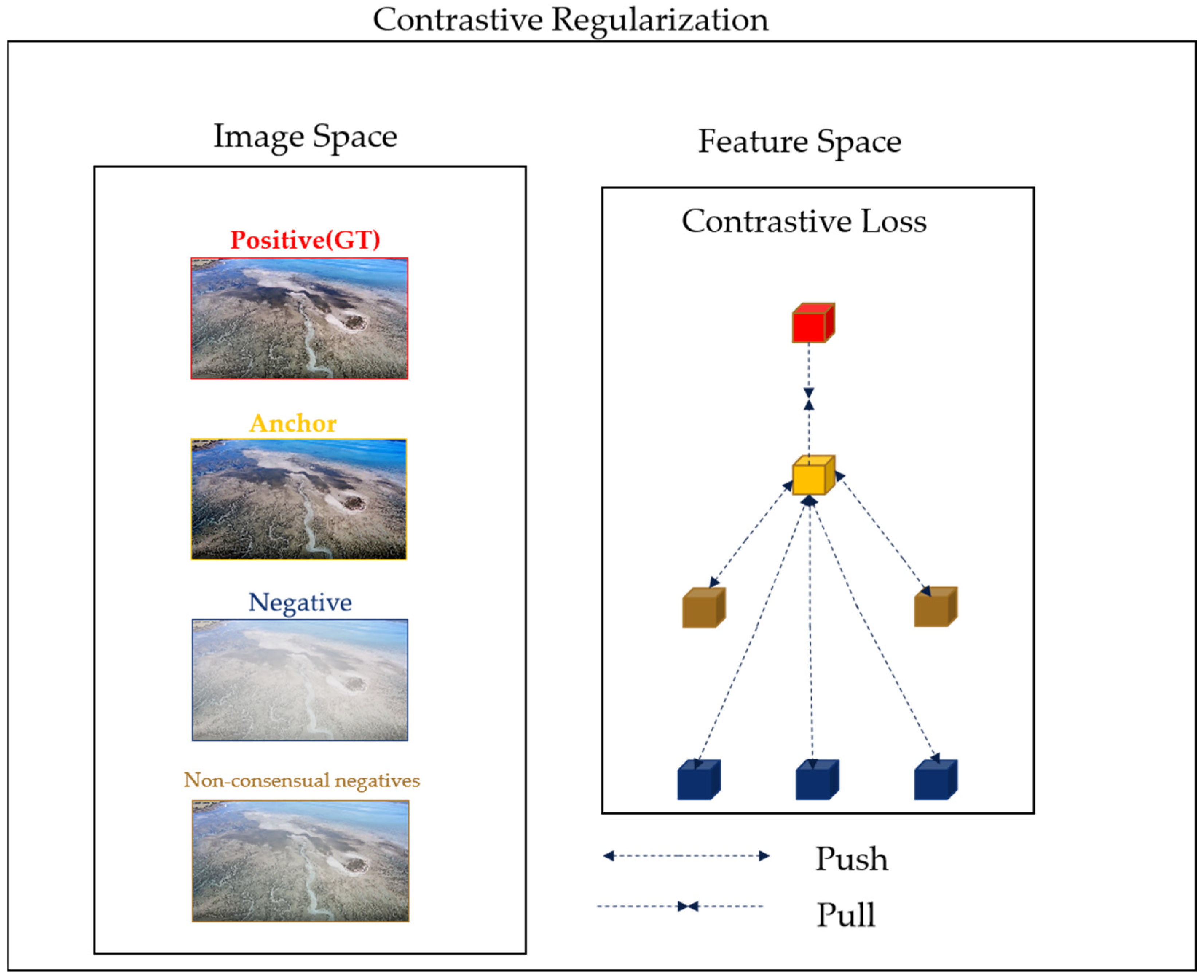
3.3. The Loss Function Improved through Comparison with Regularization
4. Experimental Results and Analysis
4.1. Experimental Environment Configuration and Dataset
4.2. Comparison of Experimental Results Using Publicly Tested Datasets
4.3. A Comparison of Experimental Results for the Aerial Tidal Flats Dataset
4.4. A Comparison of the Algorithms’ Model Parameters
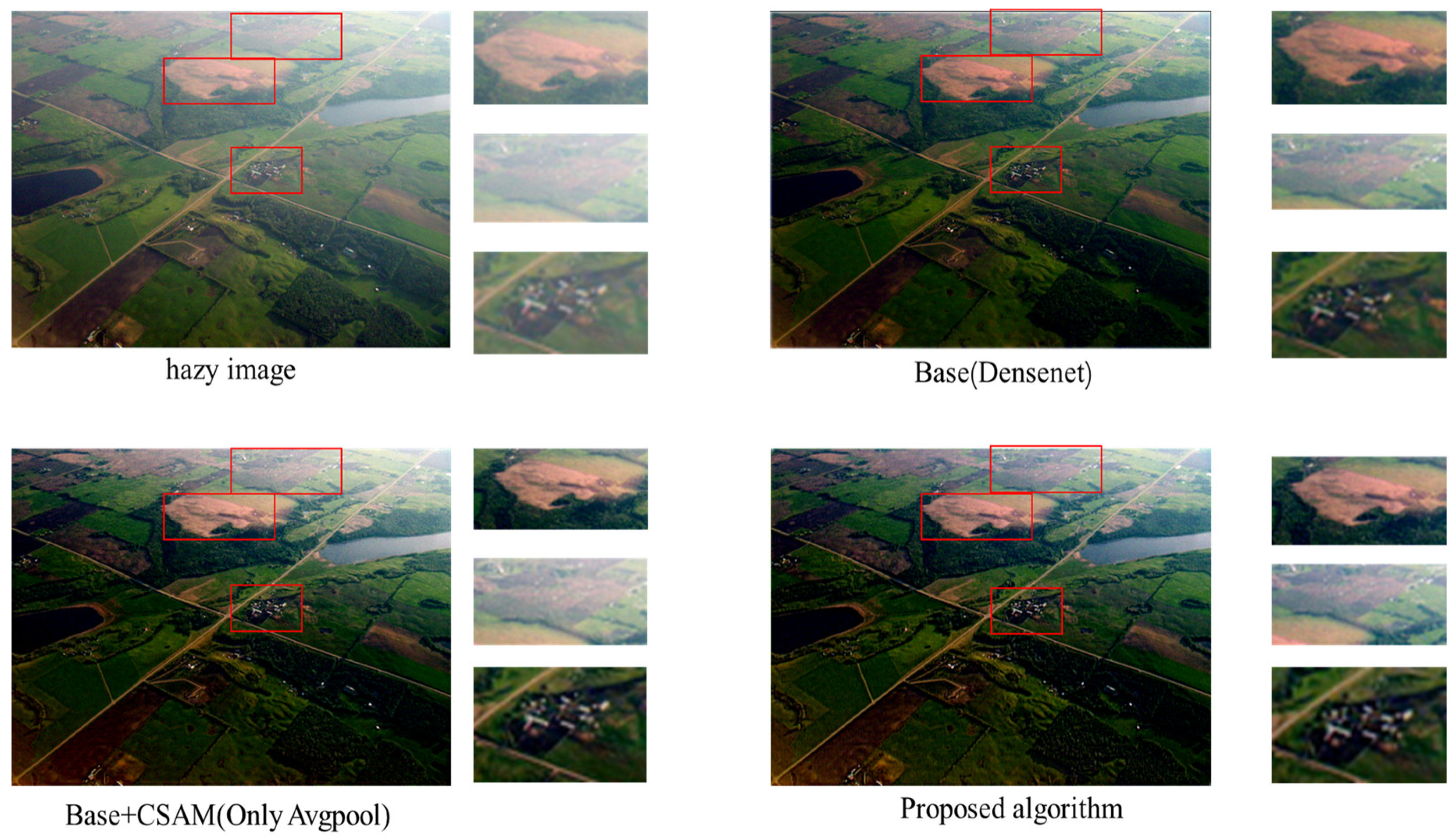
4.5. Comparison of Ablation Experiments
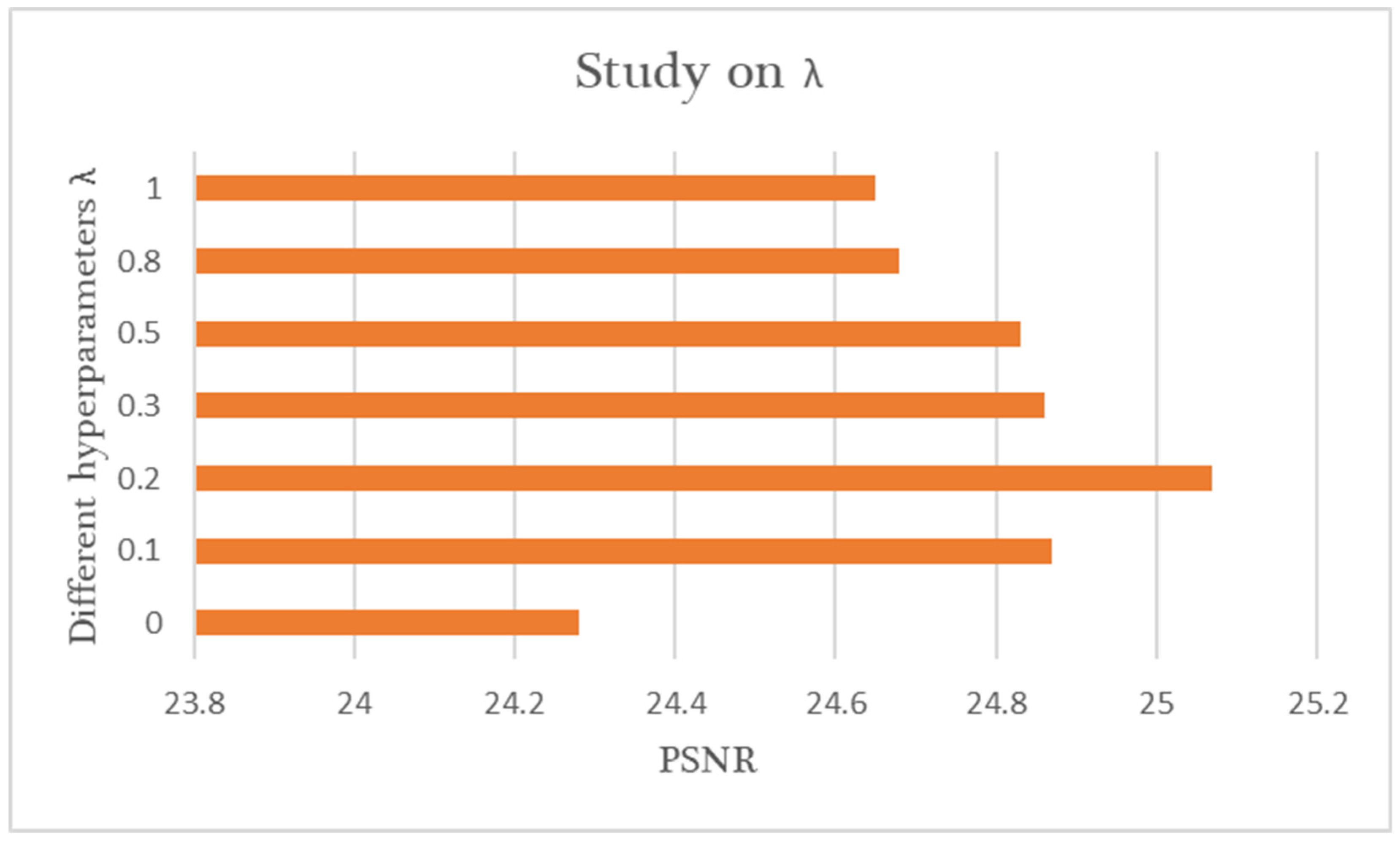
4.6. Effectiveness of λ in Loss Function
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Murray, N.J.; Phinn, S.R.; DeWitt, M.; Ferrari, R.; Johnston, R.; Lyons, M.B.; Clinton, N.; Thau, D.; Fuller, R.A. The global distribution and trajectory of tidal flats. Nature 2019, 565, 222–225. [Google Scholar] [CrossRef] [PubMed]
- Dai, W.; Li, H.; Gong, Z.; Zhang, C.; Zhou, Z. applications of UAV technology in the evolution of tidal beach landform. Prog. Water Sci. 2019, 30, 359–372. [Google Scholar]
- Kim, K.L.; Woo, H.J.; Jou, H.T.; Jung, H.C.; Lee, S.K.; Ryu, J.H. Surface sediment classification using a deep learning model and unmanned aerial vehicle data of tidal flats. Mar. Pollut. Bull. 2024, 198, 115823. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.-T. Study on the control of Spartina alterniflora by UAV application-taking the tidal flat along Northern Chongming as an example. J. Anhui Agric. Sci. 2023, 51, 57–60. [Google Scholar]
- Fan, Y.; Chen, S.; Zhao, B.; Yu, S.; Ji, H.; Jiang, C. Monitoring tidal flat dynamics affected by human activities along an eroded coast in the Yellow River Delta, China. Environ. Monit. Assess. 2018, 190, 396. [Google Scholar] [CrossRef] [PubMed]
- Chandran, I.; Kizheppatt, V. Multi-UAV Networks for Disaster Monitoring: Challenges and Opportunities from a Network Perspective. Drone Syst. Appl. JA 2024, 12, 1–28. [Google Scholar]
- Bashir, M.H.; Ahmad, M.; Rizvi, D.R.; El-Latif, A.A.A. Efficient CNN-based disaster events classification using UAV-aided images for emergency response application. Neural Comput. Appl. 2024, 36, 10599–10612. [Google Scholar] [CrossRef]
- Bhatia, D.; Dhillon, A.S.; Hesse, H. Preliminary Design of an UAV Based System for Wildlife Monitoring and Conserva-tion. In Proceedings of the International Conference on Aeronautical Sciences, Engineering and Technology, Muscat, Oman, 3–5 October 2023; Springer Nature: Singapore, 2023; pp. 51–63. [Google Scholar]
- Haq, B.; Jamshed, M.; Ali, K.; Kasi, B.; Arshad, S.; Kasi, M.; Ali, I.; Shabbir, A.; Abbasi, Q.; Ur Rehman, M. Tech-Driven Forest Conservation: Combating Deforestation With Internet of Things, Artificial Intelligence, and Remote Sensing. IEEE Internet Things J. 2024, 11, 24551–24568. [Google Scholar] [CrossRef]
- Ahmed, Z.E.; Hashim AH, A.; Saeed, R.A.; Saeed, M.M. Monitoring of Wildlife Using Unmanned Aerial Vehicle (UAV) with Machine Learning. In Applications of Machine Learning in UAV Networks; IGI Global: Hershey, PA, USA, 2024; pp. 97–120. [Google Scholar]
- Iheaturu, C.; Okolie, C.; Ayodele, E.; Egogo-Stanley, A.; Musa, S.; Speranza, C.I. Combining Google Earth historical imagery and UAV photogrammetry for urban development analysis. MethodsX 2024, 12, 102785. [Google Scholar] [CrossRef]
- Wang, C.; Pavelsky, T.M.; Kyzivat, E.D.; Garcia-Tigreros, F.; Podest, E.; Yao, F.; Yang, X.; Zhang, S.; Song, C.; Langhorst, T.; et al. Quantification of wetland vegetation communities features with airborne AVIRIS-NG, UAVSAR, and UAV LiDAR data in Peace-Athabasca Delta. Remote Sens. Environ. 2023, 294, 113646. [Google Scholar] [CrossRef]
- Zhuang, W.; Xing, F.; Lu, Y. Task Offloading Strategy for Unmanned Aerial Vehicle Power Inspection Based on Deep Rein-forcement Learning. Sensors 2024, 24, 2070. [Google Scholar] [CrossRef] [PubMed]
- Shamta, I.; Batıkan, E.D. Development of a deep learning-based surveillance system for forest fire detection and monitoring using UAV. PLoS ONE 2024, 19, e0299058. [Google Scholar] [CrossRef] [PubMed]
- Yuan, S.; Li, Y.; Bao, F.; Xu, H.; Yang, Y.; Yan, Q.; Zhong, S.; Yin, H.; Xu, J.; Huang, Z.; et al. Marine environmental monitoring with unmanned vehicle platforms: Present applications and future prospects. Sci. Total Environ. 2023, 858, 159741. [Google Scholar] [CrossRef]
- An, S.; Huang, X.; Cao, L.; Wang, L. A comprehensive survey on image dehazing for different atmospheric scattering models. Multimed. Tools Appl. 2024, 83, 40963–40993. [Google Scholar] [CrossRef]
- Gui, J.; Cong, X.; Cao, Y.; Ren, W.; Zhang, J.; Zhang, J.; Cao, J.; Tao, D. A comprehensive survey and taxonomy on single image dehazing based on deep learning. ACM Comput. Surv. 2023, 55, 279. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, A.; Xiong, Y.; Liu, Y. Survey of Transformer-Based Single Image Dehazing Methods. J. Front. Comput. Sci. Technol. 2024, 18, 1182. [Google Scholar]
- Zheng, F.; Wang, X.; He, D.; Fu, Y.Y.; Yuan, S.X. Review of single image dehazing algorithm research. Comput. Eng. Appl. 2022, 58, 1–14. [Google Scholar]
- He, K.M.; Sun, J.; Tang, X.O. Single image haze removal usingdark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2011, 33, 2341–2353. [Google Scholar]
- Zhu, Q.S.; Mai, J.M.; Shao, L. A fast single image haze removal al-gorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Ren, W.Q.; Liu, S.; Zhang, H.; Pan, J.S. Single image dehazing viamulti-scale convolutional neural networks. In Proceedings of the2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–169. [Google Scholar]
- Cai, B.L.; Xu, X.M.; Jia, K.; Qing, C.M.; Tao, D.C. DehazeNet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Li, B.Y.; Peng, X.L.; Wang, Z.Y.; Xu, J.Z.; Feng, D. AOD-Net: All-in-one dehazing network. In Proceedings of the 2017 IEEE In-ternational Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4780–4788. [Google Scholar]
- Chen, D.D.; He, M.M.; Fan, Q.N.; Liao, J.; Zhang, L.H.; Hou, D.D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conferenceon Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Qin, X.; Wang, Z.L.; Bai, Y.C.; Xie, X.D.; Jia, H.Z. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the Association for the Advance of Artificial Intelligence, Hilton Midtown, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Zheng, Y.; Zhan, J.; He, S.; Dong, J.; Du, Y. Curricular contrastive regularization for physics-aware single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5785–5794. [Google Scholar]
- Ye, T.; Jiang, M.; Zhang, Y.; Chen, L.; Chen, E.; Chen, P.; Lu, Z. Perceiving and Modeling Density is All You Need for Image Dehazing. arXiv 2021, arXiv:2111.09733. [Google Scholar] [CrossRef]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated Fusion Network for Single Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Cui, Y.; Ren, W.; Cao, X.; Knoll, A. Image restoration via frequency selection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 1093–1108. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual represen-tation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10551–10560. [Google Scholar]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976; 421p. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SOTS—Indoor | SOTS—Outdoor | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| DCP [20] | 16.61 | 0.8546 | 19.14 | 0.8605 |
| CAP [21] | 16.95 | 0.7942 | 19.82 | 0.8255 |
| MSCNN [22] | 16.89 | 0.7796 | 19.01 | 0.7931 |
| DehazeNet [23] | 19.82 | 0.8209 | 22.46 | 0.8514 |
| AOD-Net [24] | 20.51 | 0.8162 | 24.14 | 0.9198 |
| GFN [29] | 22.30 | 0.880 | 21.55 | 0.844 |
| GCANet [25] | 23.34 | 0.9025 | 26.14 | 0.8582 |
| FFA-Net [26] | 36.39 | 0.9886 | 33.57 | 0.9840 |
| PMNet [28] | 38.41 | 0.990 | 34.74 | 0.985 |
| C2PNet [27] | 42.56 | 0.9954 | 36.68 | 0.9900 |
| Proposed algorithm | 32.24 | 0.9422 | 31.09 | 0.9723 |
| Method | Tidal Flats | |||
|---|---|---|---|---|
| PSNR | RGB-SSIM | Gray-SSIM | MSE | |
| DCP [20] | 19.73 | 0.9857 | 0.9356 | 95.27 |
| CAP [21] | 22.32 | 0.9864 | 0.9462 | 85.42 |
| MSCNN [22] | 19.99 | 0.9858 | 0.9167 | 93.83 |
| DehazeNet [23] | 19.02 | 0.9693 | 0.8662 | 93.19 |
| AOD-Net [24] | 22.02 | 0.9814 | 0.9064 | 86.40 |
| GFN [29] | 21.33 | 0.9764 | 0.8973 | 94.18 |
| GCANet [25] | 17.86 | 0.9784 | 0.8343 | 99.43 |
| FFA-Net [26] | 20.39 | 0.9776 | 0.8807 | 88.47 |
| PMNet [28] | 19.18 | 0.9624 | 0.8785 | 95.84 |
| C2PNet [27] | 20.94 | 0.9521 | 0.9096 | 107.26 |
| FSNet [30] | 19.19 | 0.9150 | 0.8530 | 118.32 |
| Proposed algorithm | 25.07 | 0.9893 | 0.9618 | 75.80 |
| Method | Param. (M) | FLOPs (G) | Latency (Ms) |
|---|---|---|---|
| DCP [20] | -- | -- | -- |
| CAP [21] | -- | -- | -- |
| MSCNN [22] | 0.008 | 0.525 | 0.619 |
| DehazeNet [23] | 0.009 | 0.581 | 0.919 |
| AOD-Net [24] | 0.002 | 0.115 | 0.390 |
| GFN [29] | 0.499 | 14.94 | 3.849 |
| GCANet [25] | 0.702 | 18.41 | 3.695 |
| FFA-Net [26] | 4.456 | 287.8 | 55.91 |
| PMNet [28] | 18.9 | 81.13 | 27.16 |
| C2PNet [27] | 7.17 | 461.7 | 73.13 |
| FSNet [30] | 4.72 | 39.67 | 18.75 |
| Proposed algorithm | 0.005 | 0.351 | 0.523 |
| Base (Densenet) | √ | √ | √ | √ |
| CSAM (Avgpool) | √ | √ | √ | |
| Avgpool and Maxpool | √ | √ | ||
| Dilated rate | √ | |||
| PSNR | 26.97 | 29.36 | 29.84 | 31.09 |
| SSIM | 0.9247 | 0.94 | 0.9571 | 0.9723 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Zhu, Z.; Ge, H.; Qiu, H.; Wang, H.; Xu, C. A Lightweight Neural Network for the Real-Time Dehazing of Tidal Flat UAV Images Using a Contrastive Learning Strategy. Drones 2024, 8, 314. https://doi.org/10.3390/drones8070314
Yang D, Zhu Z, Ge H, Qiu H, Wang H, Xu C. A Lightweight Neural Network for the Real-Time Dehazing of Tidal Flat UAV Images Using a Contrastive Learning Strategy. Drones. 2024; 8(7):314. https://doi.org/10.3390/drones8070314
Chicago/Turabian StyleYang, Denghao, Zhiyu Zhu, Huilin Ge, Haiyang Qiu, Hui Wang, and Cheng Xu. 2024. "A Lightweight Neural Network for the Real-Time Dehazing of Tidal Flat UAV Images Using a Contrastive Learning Strategy" Drones 8, no. 7: 314. https://doi.org/10.3390/drones8070314
APA StyleYang, D., Zhu, Z., Ge, H., Qiu, H., Wang, H., & Xu, C. (2024). A Lightweight Neural Network for the Real-Time Dehazing of Tidal Flat UAV Images Using a Contrastive Learning Strategy. Drones, 8(7), 314. https://doi.org/10.3390/drones8070314