Abstract
This paper applies federated reinforcement learning (FRL) in cellular vehicle-to-everything (C-V2X) communication to enable vehicles to learn communication parameters in collaboration with a parameter server that is embedded in an unmanned aerial vehicle (UAV). Different sensors in vehicles capture different types of data, contributing to data heterogeneity. C-V2X communication networks impose additional communication overhead in order to converge to a global model when the sensor data are not independent-and-identically-distributed (non-i.i.d.). Consequently, the training time for local model updates also varies considerably. Using FRL, we accelerated this convergence by minimizing communication rounds, and we delayed it by exploring the correlation between the data captured by various vehicles in subsequent time steps. Additionally, as UAVs have limited battery power, processing of the collected information locally at the vehicles and then transmitting the model hyper-parameters to the UAVs can optimize the available power consumption pattern. The proposed FRL algorithm updates the global model through adaptive weighing of Q-values at each training round. By measuring the local gradients at the vehicle and the global gradient at the UAV, the contribution of the local models is determined. We quantify these Q-values using nonlinear mappings to reinforce positive rewards such that the contribution of local models is dynamically measured. Moreover, minimizing the number of communication rounds between the UAVs and vehicles is investigated as a viable approach for minimizing delay. A performance evaluation revealed that the FRL approach can yield up to a 40% reduction in the number of communication rounds between vehicles and UAVs when compared to gross data offloading.
1. Introduction
The paradigm of cellular vehicle-to-everything (C-V2X) communication allows vehicles to exchange data over radio channels for improved traffic management and autonomous transportation [1]. Moreover, unmanned aerial vehicles (UAVs) have found applications as a promising solution to complement the performance of these C-V2X communications. Recently, machine learning techniques are being incorporated into sixth-generation (6G) (UAV)-assisted C-V2X communications [2]. Vehicular mobile edge computing (MEC) has also been used to enhance intelligent C-V2X communications to meet stringent latency requirements [3]. By leveraging federated learning (FL), MEC servers can facilitate collaborative data sharing in scenarios where it is computationally intensive to offload data to the UAV [4]. Frequent communication between sensors and the UAVs also increases delay, congestion, and power consumption [5].
The existing centralized machine learning models, when applied to UAV-assisted C-V2X communications with geographically-scattered vehicles, typically have slow convergence, high resource consumption, and privacy concerns [6]. In contrast, FL is decentralized learning that can optimize the communication requirement between the cloud and the edge [7]. By storing sensitive and excess data in the vehicles, FL allows MEC servers to aggregate only the locally learned features [8]. FL allows vehicles to communicate with a parameter server embedded in a UAV via decentralized learning. In addition to addressing latency issues, FL enables UAVs to serve multiple vehicles without gross data offloading, avoid congestion, and enable joint decision making from massive sensor data [9].
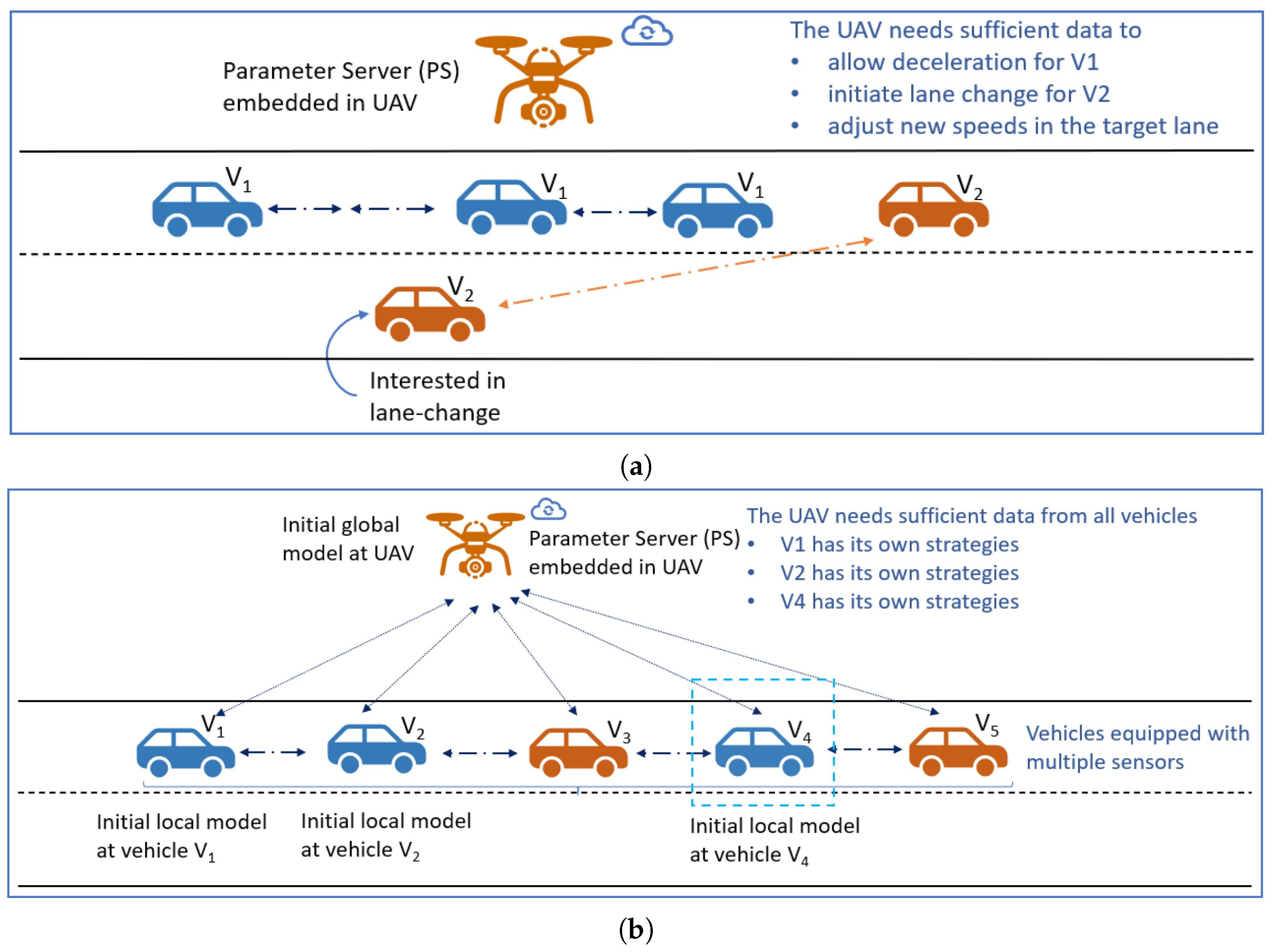
Recent applications of FL have shown that it can aid in minimizing communication delay as the vehicles and the UAVs train their models simultaneously. Instead of transmitting raw data, only local model hyper-parameters and learning policy updates are communicated to the UAV [10]. Subsequently, an aggregated global model is generated using the sensor data from the vehicles at the UAV. In synchronization with the current state of the C-V2X network and learning policy rules, the UAVs are trained to drop redundant local model hyper-parameters [4]. Furthermore, federated reinforcement learning (FRL) can be used to establish an efficient and optimal local learning policy based on a Q-learning approach for vehicles and UAVs. In vehicular edge computing, reduction in computation overhead is expected using FRL, which can significantly enhance the UAV-assisted C-V2X network performance by learning complex data transmission patterns and statistics [9]. An example scenario with an application of FRL to C-V2X communication is depicted in Figure 1. There, a lane change scenario is depicted where, using FRL, the UAVs must communicate with different vehicles for model parameter updates and aggregation. To facilitate a lane merge for vehicle , the UAVs need to process local models from vehicles and . In addition, from the three vehicles of , , and , the UAVs must not repeatedly select the same vehicle for model parameter updates and aggregation.
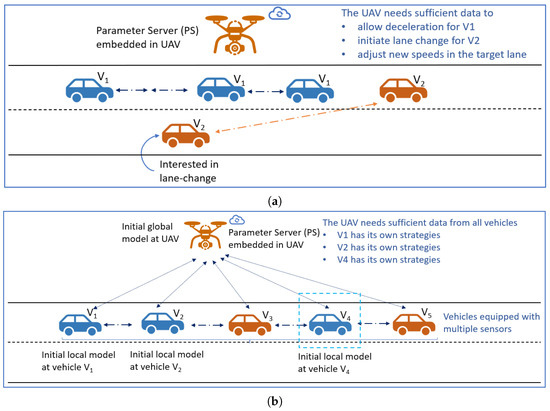
Figure 1.
An illustrative lane change scenario where, using FRL, the UAVs must communicate with different vehicles for model parameter updates and aggregation. (a) To facilitate a lane merge for vehicle , the UAVs need to process local models from vehicles and . (b) From the three vehicles of , , and , the UAVs must not repeatedly select the same vehicle for model parameter updates and aggregation.
1.1. Contributions
The objective of this paper is to demonstrate the effectiveness of FRL for UAV-assisted C-V2X communications. This effectiveness is measured by observing the achieved enhancements in the average throughput and reduction in communication latency. This paper is a significant extension of our earlier work in [11], where we analyzed FRL model convergence based on updates using federated averaging (FedAvg). We attempted to reduce the communication overhead incurred in the data transmission between vehicles and UAVs by propagating the model updates and hyper-parameters. Furthermore, we investigated the performance characteristics of FedAvg and federated stochastic gradient descent (FedSGD) when used with deep Q-networks (DQN) and duellingDQN to reduce ttransmission of hyper-parameters during yjr aggregation of local and global model parameter updates. We utilized the V2X-Sim dataset to verify the convergence characteristics and performance trade-offs [12]. As FRL agents update the -vector in a communication round (), the UAV learning rate and the step size of aggregated updates play a critical role in optimizing the parameter-weighting strategies. Moreover, during communication rounds, the learning strategy takes into account different clients using an -greedy approach for vehicle selection [13].
Specifically, this paper applied FRL in UAV-assisted C-V2X communications to achieve the following:
- Enhance throughput and reduce the number of communication rounds between the vehicles and the UAV.
- Develop effective model learning and sharing strategies between the vehicles and the UAV to minimize the required number of communication rounds [14].
- Examine the impact of transmitting model parameter updates between the vehicles and UAVs on data traffic, number of hyper-parameters, and the overall decision making in UAV-assisted C-V2X communications [15].
- Implement DQN and duellingDQN for collaborative data sharing to minimize processing and queuing delay, as well as to optimize the convergence time of FRL models.
The main contributions of this paper are as follows:
- We plot the FRL model convergence characteristics for UAV-assisted C-V2X communications where each agent is trained using a random 10% slice of the V2X-Sim dataset.
- We evaluate the proposed FRL algorithm based on the number of communication rounds () between the vehicles and the UAVs in a single sub frame of C-V2X mode 4 communications [16].
- We study the variation in average throughput vs. the number of communication rounds () for a varying number of vehicles. To monitor the model convergence characteristics with an increasing number of vehicles, we plot the variation in the mean square error against a varying number of vehicles.
- We plot the variation in optimal FRL model training time and convergence time for FedAvg and FedSGD with a varying discount factor (). Then, we identify some optimal values of () to analyze the losses. We also vary the learning rate () with respect to the number of global aggregations, as well as the number of training episodes.
In this work, we assumed realistic UAV behavior, especially concerning the UAV power consumption and practicality of storing and processing all the local model hyper-parameters on the UAV. The experimental evaluation of power consumption provides insights on the computational complexity of the computed global model hyper-parameters and the learned FRL policy executed on the UAV-embedded server. The local model hyper-parameters are computed at the in-vehicle edge servers.
We also assume that the UAV’s decision to select a vehicle for local model hyper-parameters in a TTI is fair and includes all vehicles during model convergence. Ideally, the fair selection of vehicles is a significant and critical research area, and we have discussed this in detail using a Markovian game-theoretic approach in our other work in [17]. We also discussed the strategies that UAVs utilize to broadcast global model weights to selected vehicles in a transmission time interval (TTI) in [17].
Lastly, we assumed that the computing delay and model training delay are significantly reduced when vehicles and the UAVs train their model updates simultaneously.
1.2. Organization
The remainder of this paper is organized as follows. Section 2 discusses some of the recent literature that has applied machine learning (ML) and deep reinforcement learning (DRL) techniques to achieve performance improvements in vehicular communications. The section also identifies the challenges and opportunities for performance enhancements of UAV-assisted C-V2X communications using FRL [18]. Section 3 illustrates our system model and discusses the UAV–vehicle communication architecture used in this work. Section 4 presents our problem formulation, where we formulate the problem of communication round minimization in UAV-assisted C-V2X as a Markov decision process (MDP). By minimizing the number of communication rounds, we aim to achieve latency minimization in UAV-assisted C-V2X communications. Section 5 outlines our proposed FRL solution approach where Q-learning and policy gradient learning are applied at each vehicle to generate the local model parameters. We also discuss some mechanisms where the UAVs deal with the issues of vehicle selection based on an -greedy approach. Section 6 discusses the findings of this work and investigates the impact of a discount factor and model learning rate on the number of communication rounds between the UAVs and vehicles. Section 7 concludes this paper and discusses some avenues for future research.
2. Related Works
2.1. Reinforcement Learning Applications in C-V2X
In the earlier applications of reinforcement learning (RL), Q-learning was combined with temporal-difference learning and exploration and exploitation strategies to optimize edge server performance [10]. Each edge server and the associated vehicles optimized their learning parameters based on Q-learning [10]. The RL framework based on Q-learning selected an optimal number of edge servers based on the current queue length and the duration of the transmission-time interval (TTI) [19]. Other approaches include the intelligent selection of transmission windows to avoid packet collisions. The transmission window size () and the duration of the TTI are adapted based on network traffic and packet characteristics. The learning agent selectively adjusts the size each time it encounters a non-busy server until it reaches a maximum TTI [20]. In the next iteration, the TTI and the size are reset. The reward function is the network performance; for example, resetting the TTI and should not increase packet collisions and congestion.
In other approaches, various probabilistic techniques and MDPs have been applied to enhance the performance of C-V2X networks [21]. A demand prediction model was trained using a long short-term memory (LSTM) network that utilized the local historical data collected at the agents [22]. While probabilistic approaches have been shown to improve network performance and communication reliability, there are still some significant challenges in terms of reducing the packet loss probabilities for large queues and in adequately improving channel access probabilities. Moreover, probabilistic methods may lack samples that include all the events in a communication link [23]. The network performance is also degraded by the volatile delays experienced by some vehicles [24].
Recently, DRL techniques such as advantage actor critic (A2C) and multi-agent DRL (MADRL) have found applications in vehicular communication scenarios. These techniques have been employed to solve some pressing problems in multi-agent vehicular communication scenarios. The problems pertain to resource allocation, resource sharing, traffic routing, as well as automated signal scheduling, transmission, and control [25]. Furthermore, the MADRL techniques enable multiple vehicular agents to interact with the other agents, as well as their operating environments. In recent applications, the MADRL techniques have been shown to enable agents to learn without the need for external critic networks [26]. Other performance enhancements such as complexity reduction and smooth traffic flow have been achieved in vehicular communications using MADRL [27]. In multi-agent vehicular communications, MADRL techniques have also led to improved quality of service (QoS). A detailed survey of MADRL models applied to multi-agent domains can be found in [28].
2.2. Applications of Federated Learning in Vehicular Communications
In C-V2X communication, each agent in RL can observe partial features that may not be enough to make appropriate decisions that are relevant to the context [1]. The large action space and state space also result in inconsistent performances in conventional RL [29]. An alternate solution to improving UAV-assisted C-V2X network performance is to explore the applicability of FL at the edge computing layer [30]. FL applications use cloud computing and in-vehicle resources to process data from a variety of sensors locally [31]. FL collaboration involves UAVs exchanging model updates with all the vehicles in the environment to gather rewards and local perceptions. Several studies have found that distributed approaches to C-V2X communications speed up convergence rates and improve performance [32].
The authors in [32] investigated joint power optimization and communication resource allocation in vehicular networks to achieve low latency. The queuing delays were minimized in order to minimize vehicle power consumption. Using FL, the tail distributions of queue lengths were estimated assuming independent-and-identically-distributed (i.i.d.) queuing events. The model performance was evaluated based on the communication delay incurred in FL for the Manhattan mobility model. The authors concluded that, using FL, it was possible to estimate the queue occupancy with high accuracy, with up to 79% reductions in the amount of data exchanged. Additionally, the proposed method resulted in a queue length reduction of up to 60% and a significant reduction in the average energy consumption. The authors in [19] proposed a full-duplex semi-persistent scheduling (FD-SPS) protocol for low-latency vehicular communications. The FD-SPS was proposed as an advancement on the sensing-based semi-persistent scheduling (SB-SPS) protocol that enhances the collision resolution capability by re-transmitting dropped messages using a prioritized re-broadcast mechanism. The authors evaluated the FD-SPS protocol and reported improved latency compared to the SB-SPS protocol.
The authors in [33] proposed an integrated edge–cloud paradigm, where a hierarchical action space was introduced to distinguish the nodes on the edge and in the cloud. To efficiently address the complex workflow scheduling, a hybrid actor–critic scheduling was proposed in conjunction with proximal policy-optimization techniques [33]. The proposed framework was compared with baseline algorithms on parameters such as task execution time, energy consumption, task completion percentage, and the percentage of jobs queued. The proposed DRL technique was reported to show performance enhancements of 56% in energy consumption and was 46% better in execution time.
The authors in [34] applied a reputation update policy based on the Dempster–Shafer theory to combine feedback from multiple vehicles. The vehicles transmitted the feedback in accordance with an optimal reputation update policy. To further improve this scheme, a federated deep reinforcement learning (F-DRL) framework was proposed that comprised multiple fog access points (FAPs) with caching strategies controlled by a central server. For timely model updates, the authors proposed a partially collaborative caching (PCC) algorithm. Pertaining to the non-i.i.d. data distribution across different FAPs, FL suffered performance degradation, but F-DRL and PCC outperformed FL and maintained full collaboration and a high switching factor among the FAPs. The authors in [35] revealed improvements in throughput and queuing delay for the single-agent, multi-agent, and FL-based methods. However, unlike the single-agent approach, the FL approach was effective for a large number of vehicles and when the servers were densely populated. Also, the FL-based dual deterministic policy gradient (FL-DDPG) method provided the best performance as the number of VEC agents increased. In VEC, FL-based DDPG has also been applied to channel management and task scheduling.
The authors in [31] studied the convergence time of an FL approach in a wireless setting. The authors formulated an optimization problem to minimize the FL convergence time and training losses. The proposed approach reduced the FL model convergence time by up to 56%, and it improved the accuracy of handwritten digit identification by 3% on the MNIST dataset. In [18], using a Gaussian mixture model (GMM) as a non-convex optimization problem, existing FL frameworks were implemented. The authors extended the GMM approach based on an adaptive distributed expectation maximization (DEM) algorithm to address the limitations of gradient descent, and they also analyzed the convergence bounds. In recent attempts to formulate FL as a multi-objective optimization problem, the convergence of to Pareto stationary solutions produced fewer hyper-parameters and improved coordination among the participating agents [36]. The paradigm of FL has been broadly classified into the following three categories [37].
Horizontalfederatedlearning. In this context, all of the vehicles use data with the same feature space. The types of sensors embedded in Vehicle and Vehicle lead to similar local models. However, data heterogeneity is not negligible because of the diversity in various sensors and the resulting multi-modal sensor fusion [38].
Verticalfederatedlearning. In this context, the data from a vast, varying feature space are used to jointly train a global model. The vehicles can learn to make better decisions by combining the sensor data from different domains [38].
Federatedtransferlearning. In this context, an algorithm trained on one dataset is applied to a new dataset [38]. For instance, this learning can be used to predict driving trajectories based on past driving behavior.
FRL is the amalgamation of FL and RL. FRL is a distributed implementation of RL that learns an environment across multiple vehicles without sharing raw data [39]. FRL can minimize communication overhead by enabling vehicles to share their local learning information [12]. FRL attempts to find an optimal policy by using the accumulated Q-values, which are updated at each TTI [12]. A consensus is formed between the vehicles’ locally computed machine learning models and the UAV’s global model for a finite number of iterations, and the local models are updated and aggregated [40]. An agent identifies the optimal actions that yield a high Q-value based on the reward pattern at various time steps [1].
2.3. Challenges in Applying FRL to C-V2X Communication
FRL requires a central UAV to coordinate multiple vehicles, which introduces a set of challenges [40]. Some of them are as follows:
2.3.1. Vehicle Selection
Each vehicle receives an initial model from the UAV. The local sensor data are processed to form a local model that fine tunes this global model. The UAVs receive the updated model parameters via gradient descent updates that occur at vehicular nodes [41]. Since, it is not feasible to update all vehicle models on the UAV in a single TTI, vehicles are randomly selected to upload their hyper-parameters. The latest update of the global model from the UAVs are communicated to all the vehicles during the next training iteration. The challenges in this approach are as follows:
- (i)
- Communication overhead: The UAVs may experience an increase in traffic due to model updates. Moreover, a vehicle’s communication may be several orders of magnitude slower than the local computation speed [42]. Even if a subset of randomly selected vehicles transmit the local model, the statistical heterogeneity is not addressed [42].
- (ii)
- Communication rounds: Reducing the number of iterations is another approach to minimize the number of communication rounds. Rather than updating the UAVs with each batch of local updates, more iterations of local updates can be performed at the vehicle edge network, as depicted in Figure 2. The local updates are facilitated by iterations involving multiple mini-batches, which result in fewer communication rounds [43]. A trade-off may arise, with local updates deviating significantly from global updates that impact meaningful driving decisions [43].
- (iii)
- Statistical heterogeneity: The training data in conventional machine learning are assumed to be i.i.d., whereas model updates are typically biased or non-i.i.d. due to multiple sensors [44].
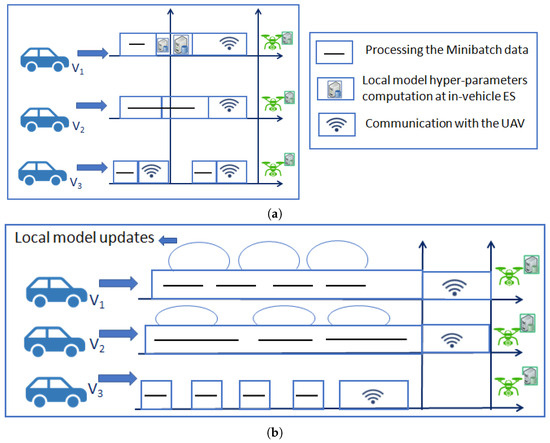
Figure 2.
Minimization of computation and communication rounds was conducted with more local updates before transmission to the UAVs. Model hyper-parameter computation and communication at each vehicle was a set of random process. (a) Local model computation with the mini-batch data of a specific size were processed in each TTI and communicated to the UAV. (b) Mini-batch computation was completed before local model hyper-parameter transmission to the UAVs. This reduces frequent communications between the vehicles and UAVs, and it preserves the UAV battery power.
Figure 2.
Minimization of computation and communication rounds was conducted with more local updates before transmission to the UAVs. Model hyper-parameter computation and communication at each vehicle was a set of random process. (a) Local model computation with the mini-batch data of a specific size were processed in each TTI and communicated to the UAV. (b) Mini-batch computation was completed before local model hyper-parameter transmission to the UAVs. This reduces frequent communications between the vehicles and UAVs, and it preserves the UAV battery power.
2.3.2. Vehicle Selection and Local Model Averaging
Conventionally, FedAvg and its variants, such as FedProx, FedMa, FedOpt, and Scaffold, have been used for federated averaging [41]. FedAvg is used to minimize the weighted average of the local vehicle loss at each iteration. To minimize loss functions, the vehicles run stochastic gradient descent (SGD) before transmitting the model to the UAVs for aggregation [45]. This cycle of updating the global model is repeated after averaging and aggregating the local models [46]. To improve the model’s performance, the UAVs must ensure it does not repeatedly select the same vehicle. Fair and intermittent selection of vehicles is a broad area of research and has been discussed in detail using a Markovian game-theoretic approach in [17].
2.3.3. System Heterogeneity and Statistical Heterogeneity
Statistical heterogeneity refers to the constraints imposed by vehicle sensors on model convergence speed [41]. Vehicle may capture data using the inertial measurement unit (IMU) and gyro-metric sensors while Vehicle may capture light detection and ranging (LiDAR) data and vehicle speed [42]. Moreover, storing sensor data and queue data is useful when a vehicle passes a given location frequently. There may be incomplete local gradients or parameters in the model when it is sent to the UAVs for aggregation, thus leading to invalid gradients learned by the global model [43]. Also, communication bottlenecks in one vehicle may adversely affect the overall federated training [47]. Along with model compression and quantization, communication bottlenecks have been addressed by dropping stragglers, i.e., vehicles that do not complete local training models within the specified time frame [44]. However, if the same vehicle is rejected repeatedly, it will impact the system heterogeneity. The variations in communication delay and queuing delay will also impact the system performance [35].
3. System Model
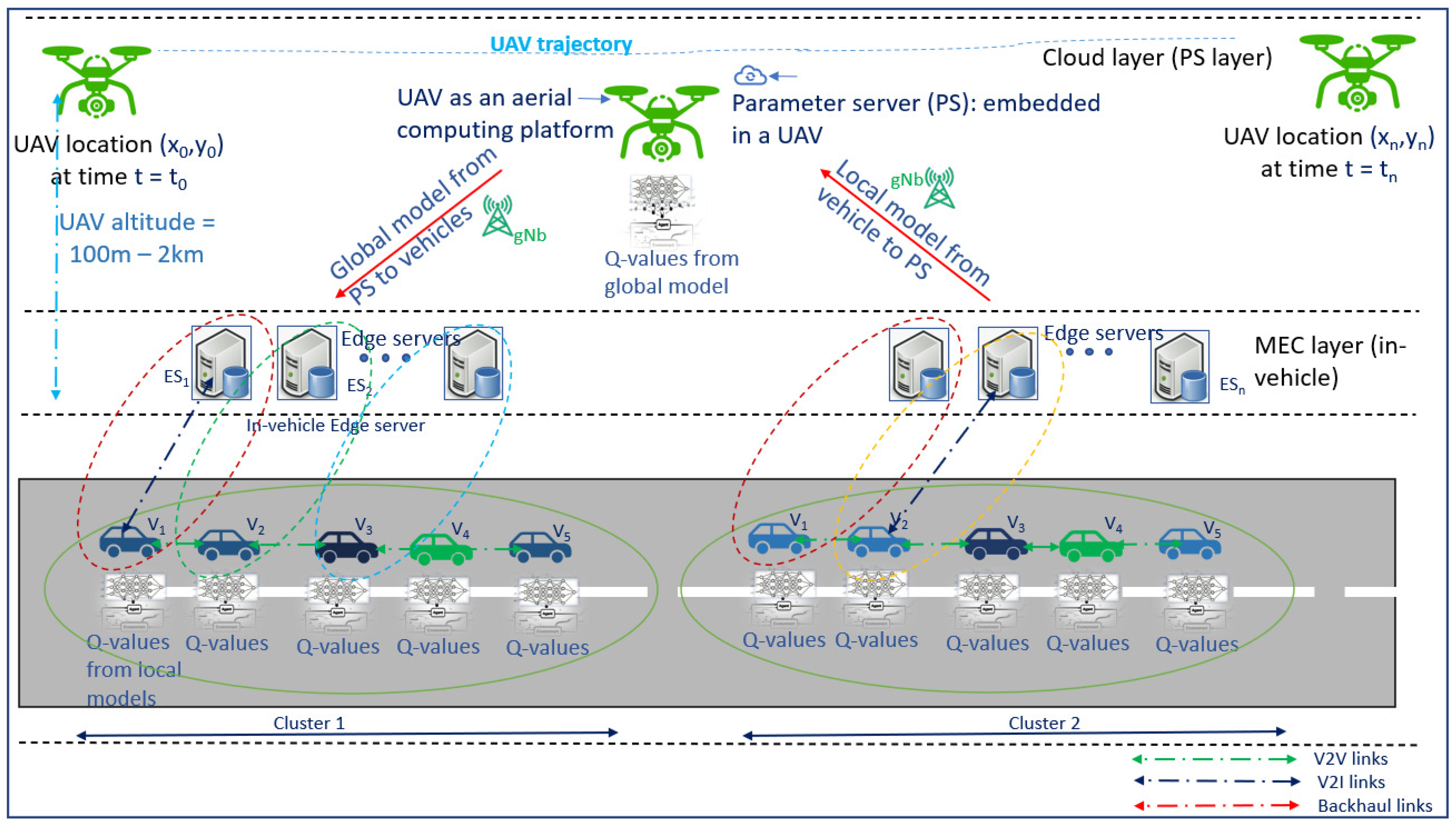
Figure 3 illustrates the vehicular communication architecture, where the bottom layer is the MEC layer where local models are created, and the top layer is the UAV layer that generates the global model. The set of vehicles that generate data is grouped into a cluster denoted by . Each cluster will have vehicles denoted by , …, . As the vehicles are moving in a horizontal direction, and the UAVs move in all directions, and this adds to Doppler spread [48]. The cluster size is limited to ensure that, at a given time and given velocity, the UAVs serve the maximum number of vehicles with minimum impact of Doppler spread [48]. A vehicle (V) captures the sensor data, locally processes them at the vehicular edge servers, and generates a local model quantified through an associated Q-value for each iteration, which also takes into consideration the model losses. The in-vehicle MEC layer contains edge servers denoted by . The UAVs serve as aerial computing platforms with the limited available battery power.
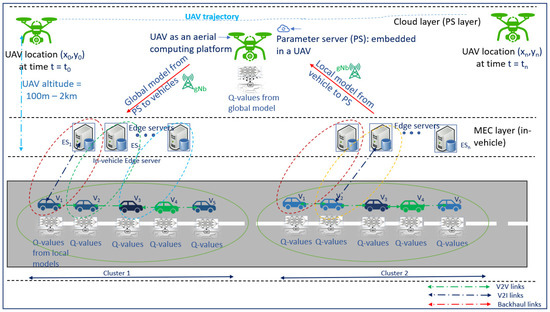
Figure 3.
System model: The vehicles communicate their accumulated local model parameters to the UAVs. The UAVs transmit the global model parameters to the vehicles. The UAVs must not repeatedly select the same vehicle for model parameter updates and aggregation.
The edge server communicates the local model to the UAVs when requested by the UAVs. In a given TTI, the packets containing local models are processed at the UAVs or are queued. We assume that the UAVs have sufficient storage to store local models. An initial global model from the UAVs is communicated to the edge servers. The typical packet arrival at the UAVs and the resulting queuing scheme is depicted in Figure 4. Using accumulated Q-values, which are updated at every TTI, FRL learns a policy () over time. In order to minimize the number of communication rounds () between the UAVs and the vehicles, policy () is optimized using FRL. In this paper, the FRL agents are the vehicles and the UAVs. A vehicle aims to maximize its rewards by frequently communicating with the UAVs, thus causing a diminished reward for other competing vehicles. A vehicle’s reward accumulates when it establishes communication with the UAV in each TTI. However, this prevents other vehicles from accessing the UAV’s resources, thus leading to reduced rewards for those vehicles. The UAVs’ objectives are to impartially and fairly select a subset of vehicles in each TTI. Moreover, the UAVs aim to identify vehicles that have not completed their local model parameter updates to avoid squandering the available resources. The proposed FRL model’s cost functions include UAV battery power availability, delay profiles, and the FRL model convergence characteristics. The action set of a vehicle comprises capturing the sensor data and processing the data locally. This generates a set of local model parameters. Ideally, each vehicle must collaborate with other vehicles to compute the updated Global model, but most vehicles may not be able to complete this action due to resource and time constraints. In this case, the UAVs can communicate with all the vehicles to generate the Global model. The selected vehicles transmit the local model parameters to the UAVs, which will compute the Global model.
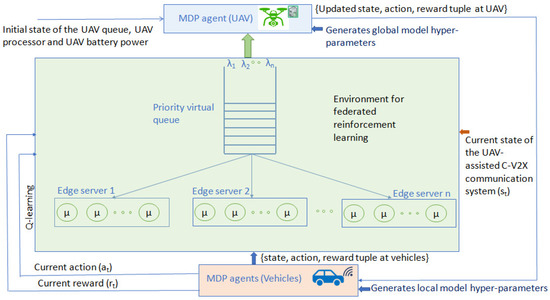
Figure 4.
The packet queuing mechanism for performance analyses of UAV-assisted C-V2X communications in a federated reinforcement learning environment.
4. Problem Formulation
We formulated the communication rounds minimization problem in UAV-assisted C-V2X as a Markov decision process (MDP). Based on the 3GPP standards and guidelines in Release 16, the aim was to achieve efficient vehicular communication with minimum latency by transmitting model updates between the vehicles and UAVs instead of raw sensor data. Consequently, Equation (1) defines a policy () for achieving communication between the vehicles and the UAV with the lowest number of parameters () in the model updates from all vehicles while also maximizing the cumulative reward of local and global model transmissions. The problem of delay () minimization with a maximum probability of transmitting a local model to the UAVs within () communication rounds is subject to the following constraints, which are defined as follows:
where is a multi-objective optimization problem. The model weights () are communicated from the vehicle to the UAVs in each communication round (), which are characterized by the reward function . Problem P1 aims to optimize the model transmission and convergence duration, communication rounds, and throughput, and it is a mixed-integer nonlinear optimization problem. Constraint C1 avoids excessive model updates by limiting the transmission probability of a vehicle (i) to be lower than a pre-assigned value (). The queuing probability is limited by the number of model hyper-parameters () in the model weights ( − ). It also prevents queue overflow at the ith and at the UAV. The constraint limits the parameter () between a vehicle and UAV to prevent the average latency from exceeding a threshold value.
Constraint C2 maintains system stability as the utilization of each processing device is set below 100%. In C3, the number of parameters () from (v) vehicles, denoted as (), transmitted to UAVs in a communication round (K) vary significantly. To solve the () minimization problem, we defined the optimal number of active that satisfy the model queuing probability constraints defined in C1 and C2. In C4, a model utility operator () was introduced. The model convergence time significantly depends on the available processing power and the large number of model updates, which can lead to delay if the UAV capacity is exceeded. Also, allocating UAV resources to one vehicle affects the resources allocated to other vehicles. Since local models arrive randomly, it is possible that a queue builds up at the UAV. Insufficient buffer space will lead to dropped packets and impact the subsequent transmission sessions, eventually reducing throughput. Moreover, dropped packets also indicate a congestion. Constraint C5 implies that the model weights converge within () iterations while processing the vehicle data from () TTIs. Constraints C6 and C7 impose an upper limit on UAV speed () so that the Doppler spread in the communication between vehicles and UAVs is within 6G specifications [49].
Therefore, to minimize model collisions, the UAVs do not broadcast global model weights to all vehicles at each iteration. Each vehicle collects local data samples, computes the local stochastic gradient descent (SGD), and transmits the gradient update to the UAVs so that the UAVs update their weight vectors. During the next iteration, a new SGD is computed and the process repeats to avoid constant updates at the UAVs. We modeled the packet sojourn time as an unbiased random Poisson arrival process. The packet arrival at the queue was modeled as a set of Gaussian distributed random variables for all . For an arbitrary sequence of packets, represented as random variables (), the number of packets in each individual TTI is modeled as follows:
Note that, at each (), the parameter () is random, whether the event is a packet arrival, departure, or both. In transmission time T, a random time interval for all . A time interval () represents a time window when a packet is transmitted or queued. For a finite subset such that , we have
for packet arrival rate () and service rate (). Here, the packet arrival rate () is modeled as a Poisson process, with varied between 1000–2000 packets/s. The packet service rate () is modeled as an exponential process, with varied between 500–2500 packets/s. The left hand side of Equation (10) indicates that the transmission window () is large enough for all processed packets to leave the queue. The right hand side indicates that the window is sufficiently small so that a limited number of packets arrive to the queue. This ensures that the UAVs do not become overloaded; hence, the packet drop ratio is restricted to a minimal lower bound.
Note that the in-vehicle MEC servers manage the model updates, local storage, and transmissions to the UAVs. It is computationally intensive and incurs communication overhead to calculate the probability distribution of each data object with multiple sensors. Here, we used Bayesian ensemble learning, in which each object-type approximates the value function with optimal policies through continuous evaluation and improvement to reduce the upper bound on the value function in a communication round, which is represented by (). The upper bound for the Q-function is defined in Equation (11). The parameters () and () represent the accumulated Q-values and the reward at each vehicle and UAV. The delay () is the time taken to complete local model updates, transmit them to the UAVs, and arrive at a global model with minimal hyper-parameters.
Dataset Description
This paper trains agents using the V2X-Sim dataset, which is a multimodal and multiview dataset for C-V2X communications and autonomous driving. The V2X-Sim dataset simulates multi-agent perception based on V2X. Multiple sensors from roadside units (RSUs) and vehicles are used in V2X-Sim to allow many agents to perceive an event at the same time [50]. Training the vehicles and the UAVs involves randomly selecting 10% slices of the dataset. Using this approach, each agent generates both local and global models based on a different environment. The main symbols used in this paper are described in Table 1.

Table 1.
Definition of some of the key symbols and parameters used in this paper.
5. Proposed FRL Solution
5.1. Federated Reinforcement Learning for Minimizing Communication Rounds () between Vehicles (V) and UAVs
A challenge in FRL is to select model updates from different vehicles to reduce the bias introduced by non-i.i.d. data. Note, the patterns in global model aggregation impact the vehicle selection strategy of the UAVs. Vehicles with similar update times and hyper-parameter characteristics have different selection probabilities at different intervals. As all vehicles compute their local models, if is a column vector, then we have the following:
where the vector f is the federated learning function. The row vector values are the stochastic gradients, where . Also, each is a scalar function of and
In Equation (13), an matrix, is derived from the transpose of Equation (12) over the vector function . Equation (14) represents the reinforcement learning approach where parameters () are aggregated from all the participating agents and are processed centrally.
where the objective function is non-convex and solved using gradient descent methods [33]. The training in Equation (14) is computationally intensive if the local updates are large. The proposed FRL approach distributes the computational load to collaborating vehicles. Each vehicle shares its local model with the UAVs at a fixed time interval, which is calculated using sensing-based semi-persistent scheduling. Equation (15) aims to optimize latency, where the UAV monitors (K) vehicles based on Q-values to select local models.
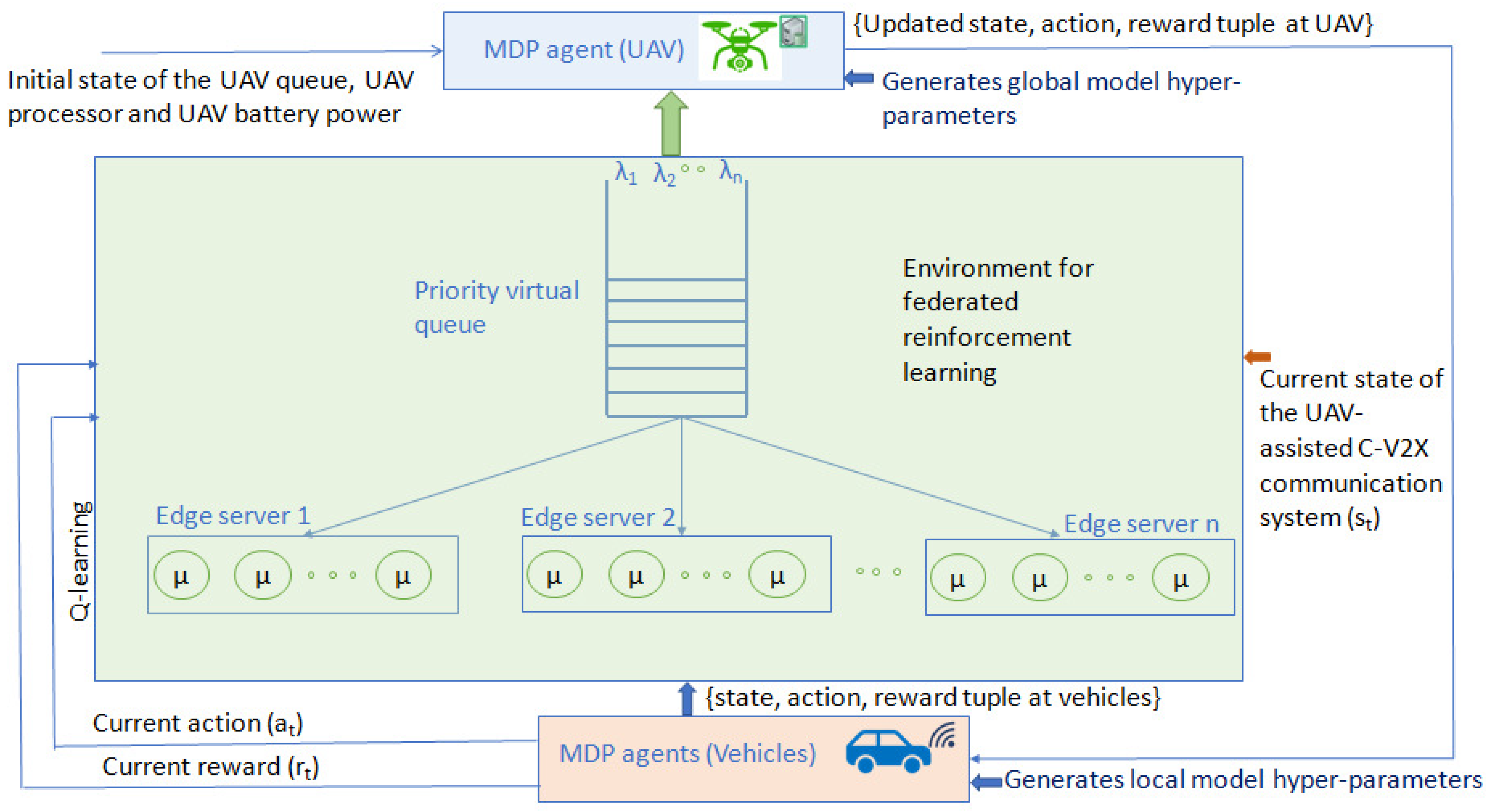
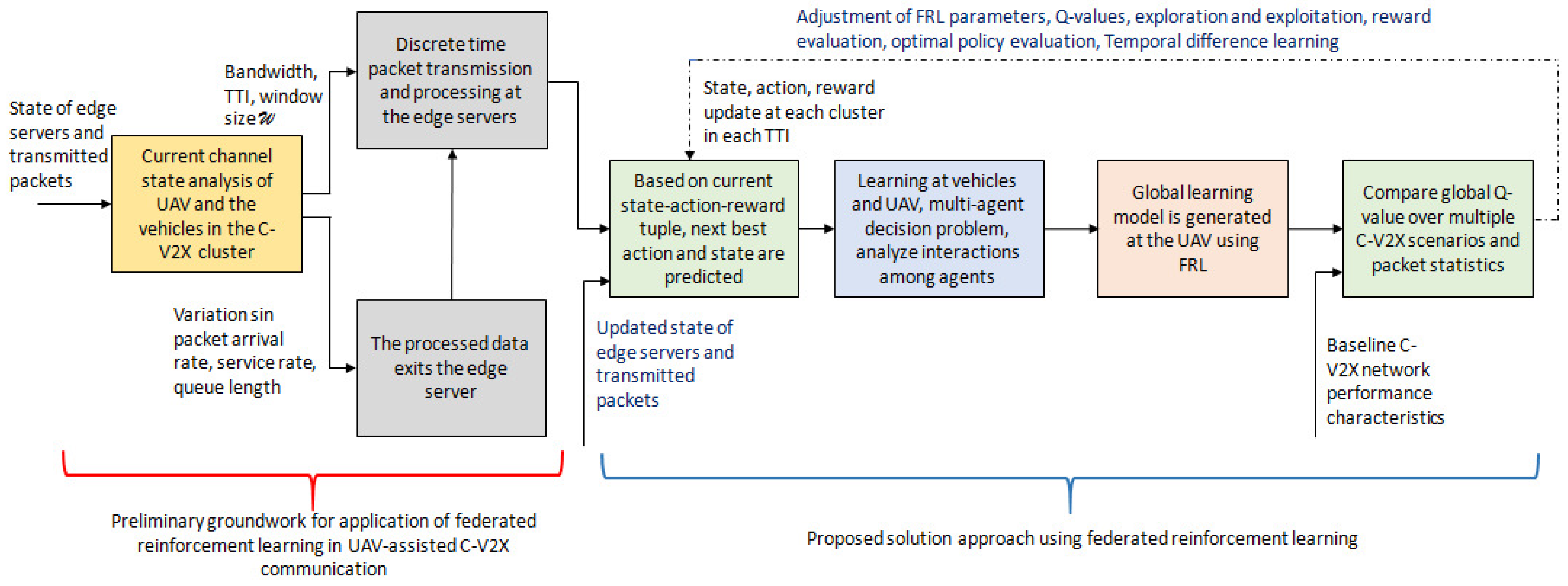
By federating the Q-values stored in a vector (), the reward () can be accumulated by the vehicles’ local model. Consequently, () is a random vector that results from varying arrival rates, queuing delay, and the parameter vector . The UAVs find , which maximizes . The likelihood function of capturing model parameters that lead to vector is , which is defined as . Figure 5 illustrates the proposed FRL-based solution approach.
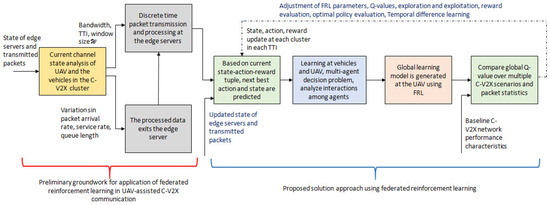
Figure 5.
An illustration of the proposed federated reinforcement learning-based solution approach for performance analyses of UAV-assisted C-V2X communication.
5.2. Q-Value Accumulation and Reward Function in FRL
The reward function () in Equation (16) is generated by an agent, which indicates an action, and the Q-value indicates the optimal state–action pair [51].
Note, excessive estimator variance results in unstable learning as the trade-off between exploration and exploitation leads to significant error variance in the agents’ models. As per Equation (17), the agents learn their policies by collaborating locally and accumulating rewards. All of the agents’ learned models are used to formulate FRL decision policies.
The discounted reward … is calculated from the reward (), where is the policy and discount factor tunes the agent behavior. An agent with a discount factor maximizes its expected reward for the next transition, while a reinforces patterns that maximize long-term rewards [52]. The conventional method of solving MDPs uses Q-functions based on the parameterized function , where p is the number of parameters. In Q-learning, SGD is used to calculate updated parameters as follows:
where is the learning rate. The weights from local updates at vehicles are as follows:
At convergence, the mean squared error (MSE) loss was found to be minimal. The Q-values evaluate a state–action pair for an agent as the optimal function for an update, which incurs the loss of . Varying the number of episodes and the discount factor avoids local minima [52]. Therefore, the deep Q-network (DQN) architecture uses the loss function for stable learning. Here, DQN samples a state transition from an array of previous transitions rather than using just the last transition. As a result, multiple participating agents in FRL correlate the Q-values [52]. Each episode begins with a random initialization of the kth vehicle’s model parameter weights (). After processing a batch of data, the gradients are updated. Upon computing the gradients for m samples, the local weights on vehicle k are updated using the gradient descent algorithm, and the parameter comprises the model losses. Weights for the next epoch of vehicle (k) training will be based on these updated values. With FedAvg and FedSGD, multiple vehicles train a local DQN by iterating over (m) samples and sharing updates with the UAVs. In FedAvg, the model updates from each vehicle are averaged, but in FedSGD, the model updates are added together and the SGD is calculated.
FedAvg learns a central Q-network, which is shared among all participating agents, when it is combined with DQN. An episode involves the agents training their Q-networks and communicating weight updates to the UAVs. In the next iteration, the UAVs broadcast the updated Q-network weights so that multiple vehicles can learn the Q-network. By analyzing the local data distribution, FedSGD ensures the updates from each vehicle are appropriately weighted during the aggregation process, thus preventing the global Q-network from overfitting or underfitting. In FedSGD, only the gradients are communicated to the UAVs when updating the model, rather than the whole model update. SGD updates are computed by each vehicle using a mini-batch of local data as a basis for each SGD update. The UAVs average these local updates to update the global model. Additionally, DQN estimates the action-value function using a single neural network. The DQN input is the network state and the output is a Q-value. The optimal action is the one with the highest Q-value. In DuellingDQN, the action-value function is decomposed into a state-value function () to compute the relative advantage () of taking an action. The advantage of taking an action in the current state is quantified using the Q-value as .
5.3. -Greedy Approach for Vehicle Selection by the UAVs
A low encourages exploitation over a wider estimation of , where is the probability that an agent will generate a reward. Choosing a high does not lead to an agent converging optimally as it may not gather sufficient knowledge about the environment [13]. The UAVs’ policy learns the best possible strategy over several episodes of an update with minimum communication rounds [53]. The UAVs maximize their expected reward across all local updates to select a vehicle in fewer episodes and to estimate the parameters for faster global update. The -greedy strategy maintains an average reward for each vehicle and selects the next action as follows:
A high allows an agent to explore the environment, and a low leads to exploitation of the agent’s knowledge of the environment. As an agent explores the environment or exploits the information to maximize the reward, it adds to processing delay. -greedy selects a vehicle by sampling a policy distribution rather than by taking the action with the highest probability [29]. The loss incurred by an agents is as follows:
where is the value loss, is the policy loss, and is the entropy loss for all . The parameters are initially set to , , and , and they are varied linearly over multiple iterations. We updated the policy gradient using an estimate of the , which compares the reward to .
6. Simulation Results and Discussion
6.1. Federated Model Training
We used the Amazon elastic compute-2 (EC-2) instance to process the V2X-Sim dataset, the TensorFlow, and the TensorFlow Federated frameworks to construct the FRL collaborators. We initially split the V2X-Sim dataset into training and testing data at a ratio of 6:4. The federated client agents were initially composed of one vehicle and one UAV, and the number of vehicles (V) was varied from 1 to 100. Using DQN and duellingDQN, each agent developed a local initial environment and local model using the randomly chosen 10% data slice from the dataset. A dictionary containing each client’s name and its data slice was created. We shuffled the order of data slices used to train a client to ensure a random distribution. During training, we updated the parameter vector for each client and initialized the weights of the global parameters. We added scaled local weights and updated the global model to implement FedAvg and FedSGD. In the UAVs, models are generated using Equations (18) and (19) based on the updates received from various vehicles. Table 2 lists the main parameters used in the simulations. The simulation results for ‘FedAvg + DQN’, ‘FedAvg + duellingDQN’, ‘FedSGD + DQN’, and ‘FedSGD + duellingDQN’ were compared. Note, to avoid over-fitting in the training data, we used dropout, where the dropout ratio was varied between 0.2 and 0.9. In the test set, we normalized the DQN weights by multiplying the weights by the dropout ratio used for the training set.
Table 2.
Simulation parameters.
6.2. Model Convergence Characteristics
During training, the hyper-parameters comprised individual weight vectors () and a bias vector for each vehicle. For an initial learning rate () of 0.0001, the weights were learned using an Adam optimizer to optimize the loss function (). For training, an -greedy policy was used, the batch size was set to 64, and () was reduced from 0.8 to 0.002. The FRL models were trained with a varying discount factor () that varies from 0.99 to 0.50. The results are summarized in Table 3.
Table 3.
Performance characteristics of the proposed FRL algorithm. The accumulated Q-values refer to the average cumulative reward over 400 test episodes. The last column is the number of episodes required for convergence.
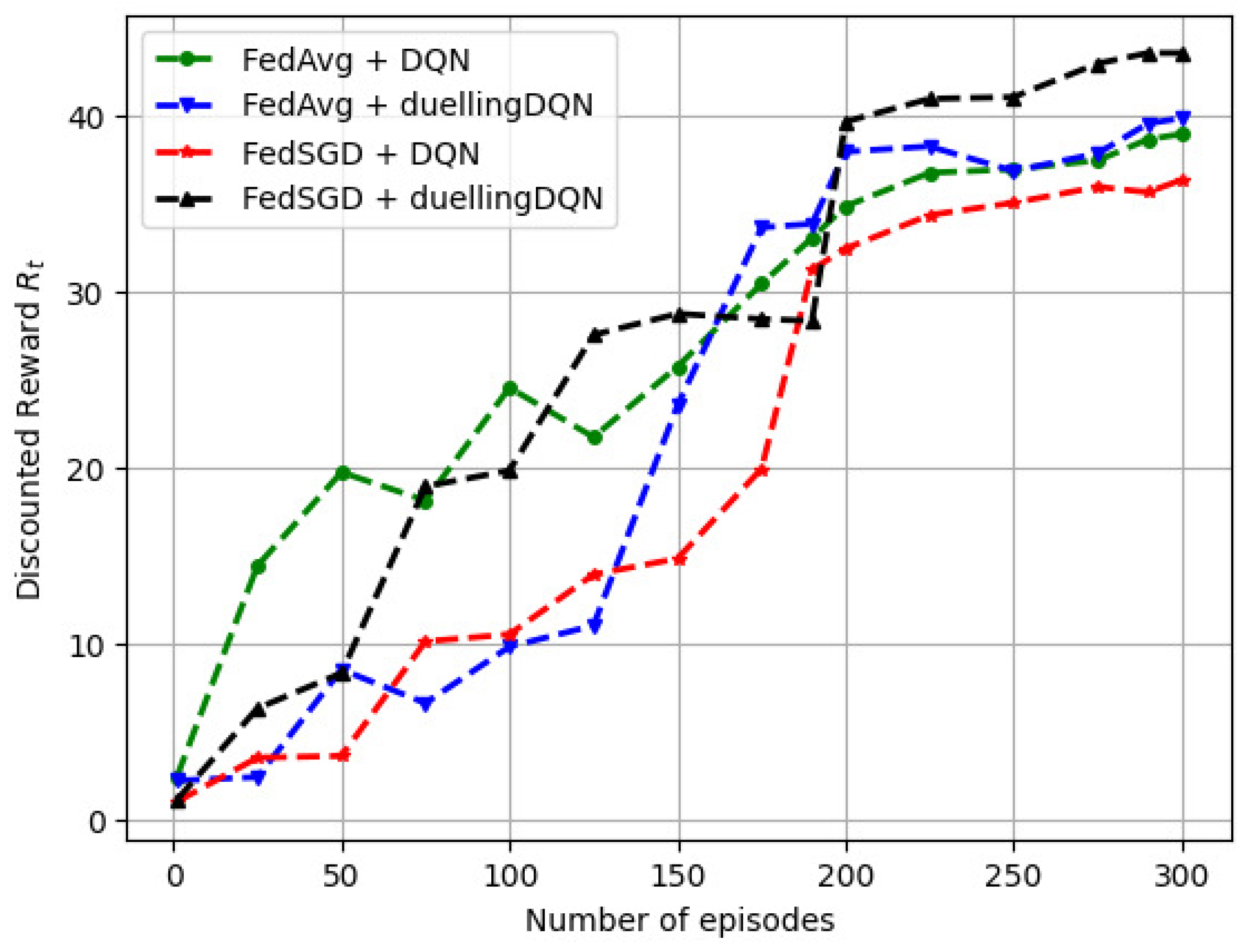
6.2.1. Variation in the Discounted Reward () with the Number of Training Episodes
Figure 6 depicts the variation in the discounted expected reward () with the number of training episodes. It was found that UAV rewards initially increased due to convergence with a local model, and these then gradually steadied after over 200 iterations. According to Figure 6, initially, it was possible for the UAVs to reset the global model by selecting the same vehicle for consecutive training episodes. In the FRL model, a vehicle’s failure to complete a local update during an episode resulted in a gradual loss of reward. In contrast, vehicles with higher reward functions maintained their local features, while those with lower reward functions updated their models more frequently.
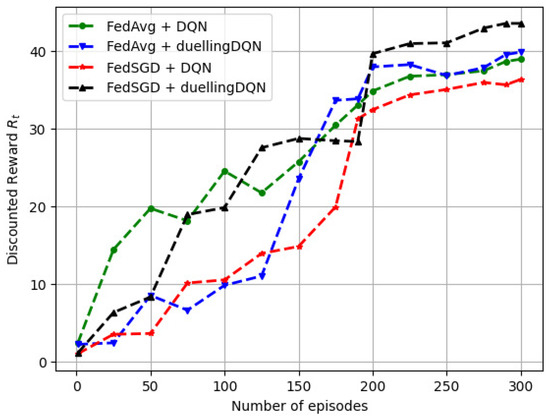
Figure 6.
Variation of the discounted reward () with the number of training episodes.
It was also observed that both FedAvg and FedSGD resulted in stable after approximately 200 training episodes. Moreover, ‘FedSGD + DQN’ resulted in the lowest discounted reward for 300 episodes. The reward stability for DQN was comparable to that of duellingDQN for both FedAvg and FedSGD. During the previous episode, the UAVs maintained a track of all global model updates. In an episode, a random policy was initialized, followed by a finite number of time steps for the vehicles to learn the global model. Learning the optimal policy was performed recursively by propagating the gradient of the loss function () back to the local model.
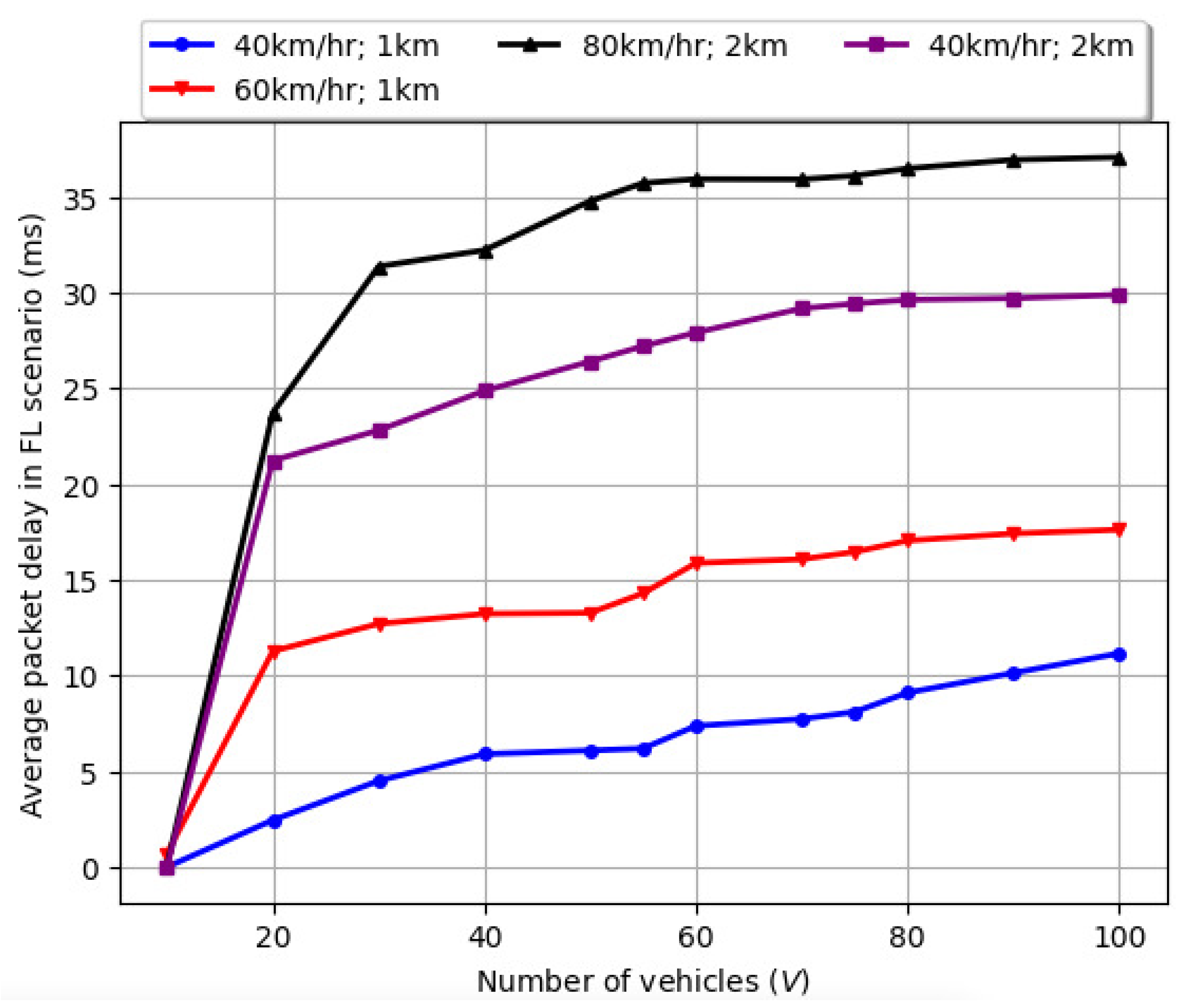
The delay profile for the proposed FRL scenario comprising the average delay experienced by a packet is illustrated in Figure 7. We varied the vehicle velocity at 40 km/h, 60 km/h, and 80 km/h. The number of vehicles (V) varied from 1–100, and the road length () was selected as 1 km and 2 km. It was noted that, when the vehicle velocity is 40 km/h over of 1 km, the maximum average packet delay for 100 vehicles is around 10 ms. When the is increased to 2 km, the maximum average packet delay for 100 vehicles is around 30 ms. When the vehicle velocity is increased to 60 km/h over of 1 km, the maximum average packet delay for 100 vehicles is around ms. When the vehicle velocity is further increased to 80 km/h over of 2 km, the maximum average packet delay for 100 vehicles is around ms. It is also evident that, for the number of vehicles (V) varied from 1–20, there is a steep increase in the maximum average packet delay experienced by a packet. However, as the number of vehicles (V) varied from 20–100, the maximum average packet delay experienced by a packet continued to gradually increase with increases in the number of vehicles (V) and the road length ().
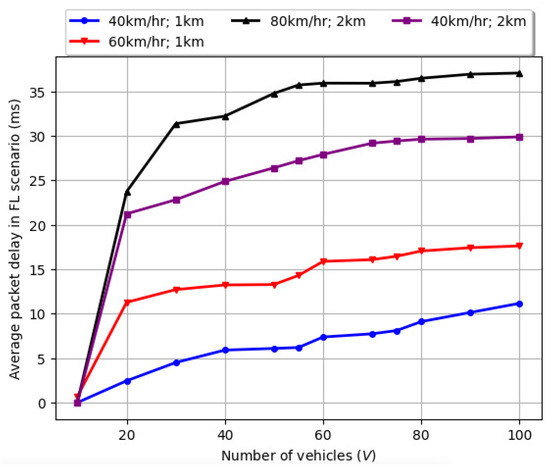
Figure 7.
The delay profile for federated learning and the average delay experienced by a packet.
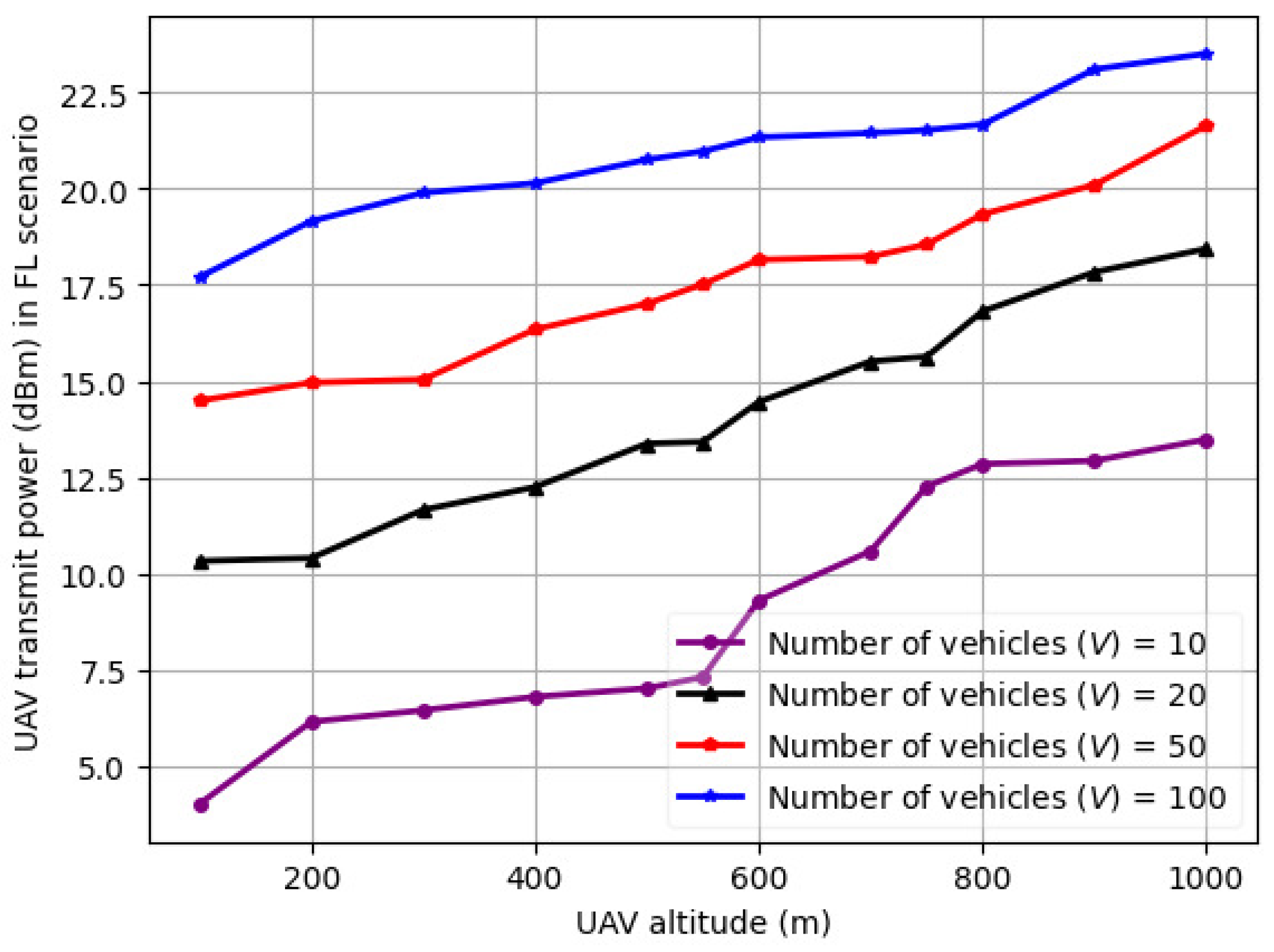
The variation in UAV transmit power (dBm) in the FRL scenario with UAV altitude for a varying number of vehicles (V) is illustrated in Figure 8. It is noted from Figure 8 that the UAV power consumption in the FRL was around 22.5 dBm, as some of the data processing occurred at the vehicle level. Furthermore, it is evident from Figure 8 that the power consumption of the UAVs showed a progressive increase with the number of vehicles, as well as the UAV altitude. The positive slope of the graphs supports this trend, which implies a continuous increase instead of a plateau. Considering this delay profile and UAV power consumption, we will next discuss and illustrate the variation in the FRL model convergence characteristics and the variation in the mean square error.
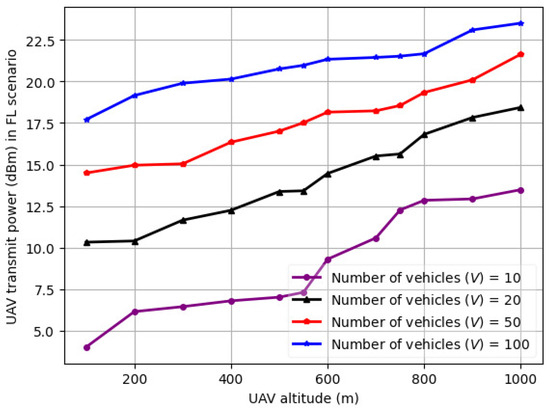
Figure 8.
Variation in the UAV transmit power (dBm) in the FRL scenario with UAV altitude for a varying number of vehicles (V).
6.2.2. Variation in the System Throughput with the Number of Communication Rounds ()
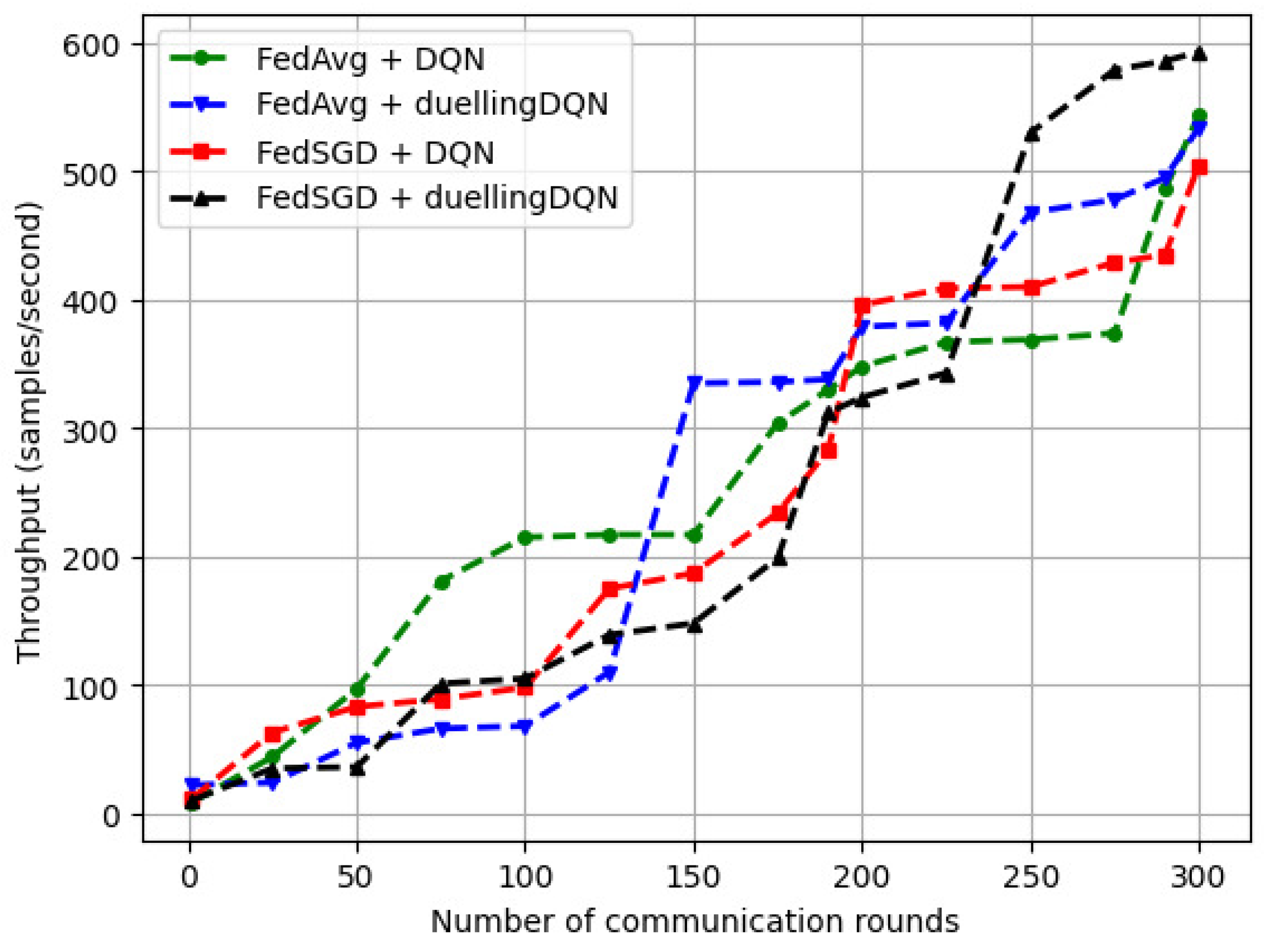
Figure 9 depicts the variation in the system throughput with varying number of communication rounds (). For an initial , we varied the discount factor () between 0.99 and 0.50. We observe that, for ‘FedSGD + duellingDQN’, increasing the number of communication rounds () between the vehicles and UAVs resulted in a correspondingly higher increase in throughput. For ‘FedAvg + duellingDQN’, a steep variation in the rate of increase occurred at around 125 communication rounds. The throughput of ‘FedAvg + DQN’ increased gradually with . Using FedSGD, we performed more training iterations on each vehicle and then performed continuous averaging of the model parameters to reduce the communication rounds () between the vehicles and the UAVs.
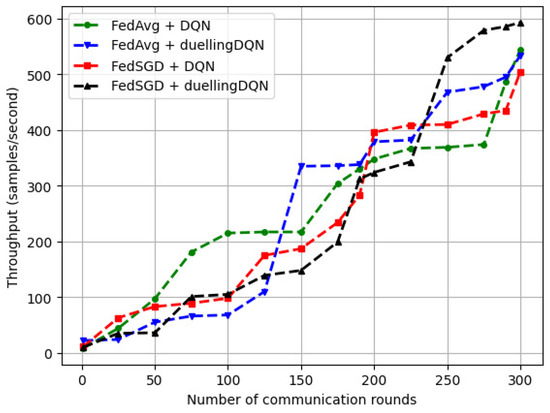
Figure 9.
Variations in the FRL model throughput with ().
We calculated throughput as the number of local updates processed per unit of time. We used (batch size × number of vehicles × number of communication rounds)/total time. In this case, the batch size was the number of training samples processed in the local update, and the communication rounds were the number of times the vehicles communicated with the UAVs. The time taken to complete the training was considered as the total time. For 100 communication rounds over a period of 10 min for V = 10, each instance of processing included a batch of 32 samples per local update, and the throughput was samples/s. For 200 communication rounds over a period of 10 min for V = 20, each instance of processing included a batch of 64 samples per local update, and the throughput was samples/s.
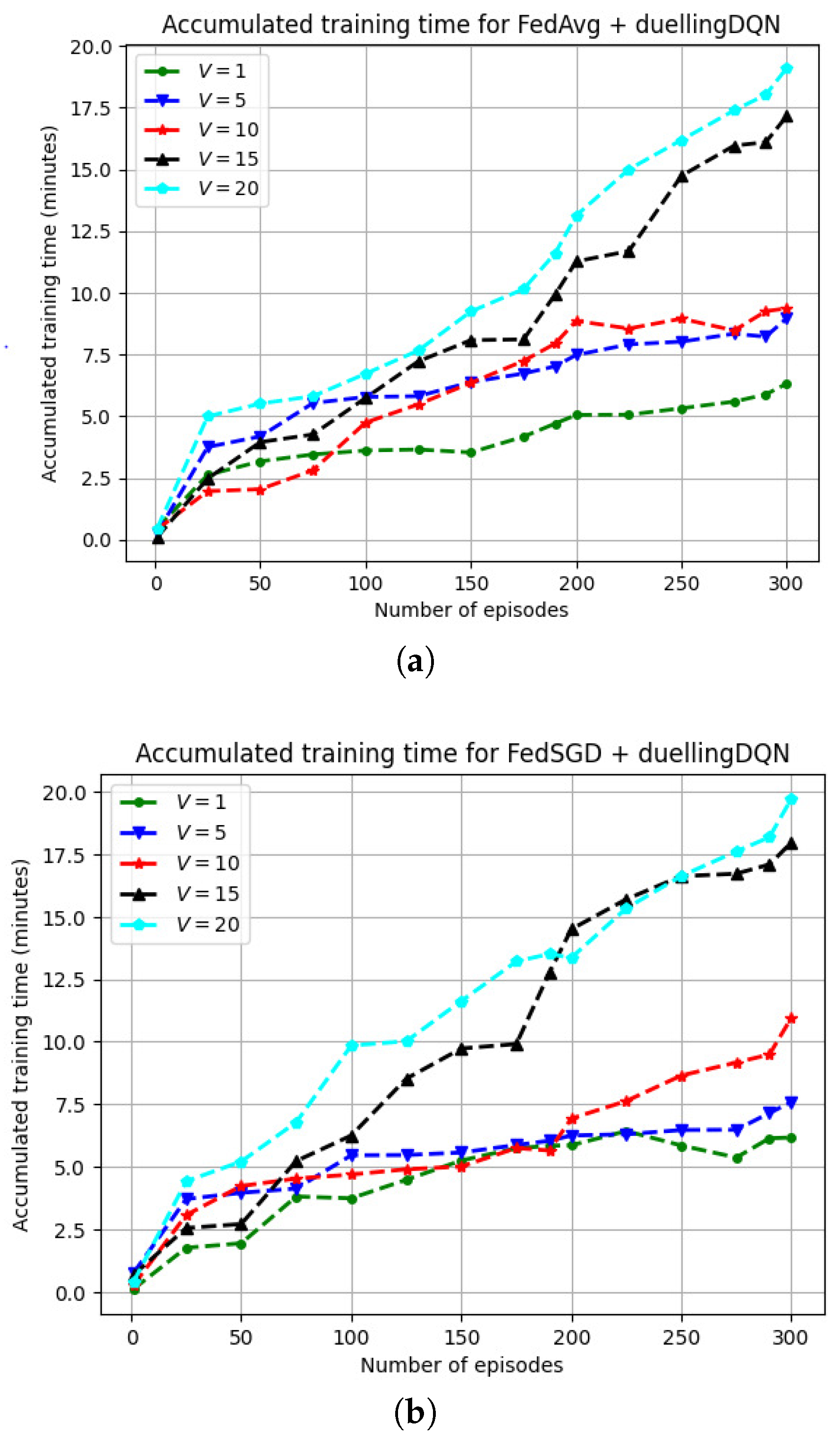
Figure 10 depicts the variation in the FRL model training time for a varying number of vehicles (V). More training episodes and fewer communication rounds () resulted in greater throughput in FedSGD. When = 0.82 and when the UAVs are serving only one vehicle (V = 1), the model training was executed for approximately 6 min for 300 episodes. As the number of vehicles increased to (V = 5) and (V = 10), the model training was executed for approximately 10 min for 300 episodes. With further increases in the number of vehicles on the specified road segment, i.e., (V = 15) and (V = 20), model training converged at approximately 20 min for both FedAvg and FedSGD. When = 0.94, for V = 1 and V = 5, the model training converged at approximately 6 min for 300 episodes. For (V = 20), the model training converged at approximately 20 min for 300 episodes. In the case of updating the global model with a local model, the training time for the global model reduced as () increased initially. A slightly faster model training time (when the agents had the same training characteristics) was observed when () was set to 0.94 in comparison to () = 0.82.
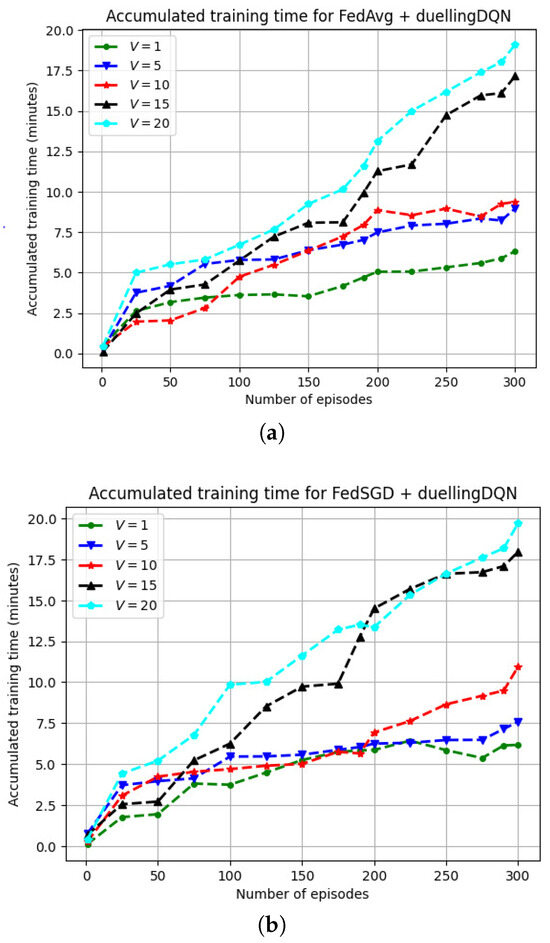
Figure 10.
Variations in the FRL model training and convergence times for FedAvg and FedSGD with a varying discount factor (). (a) Variations in the FRL model training and convergence time for FedAvg and FedSGD when . (b) Variations in the FRL model training and convergence time for FedAvg and FedSGD when .
6.2.3. Variation in the MSE Losses with Discount Factor ()
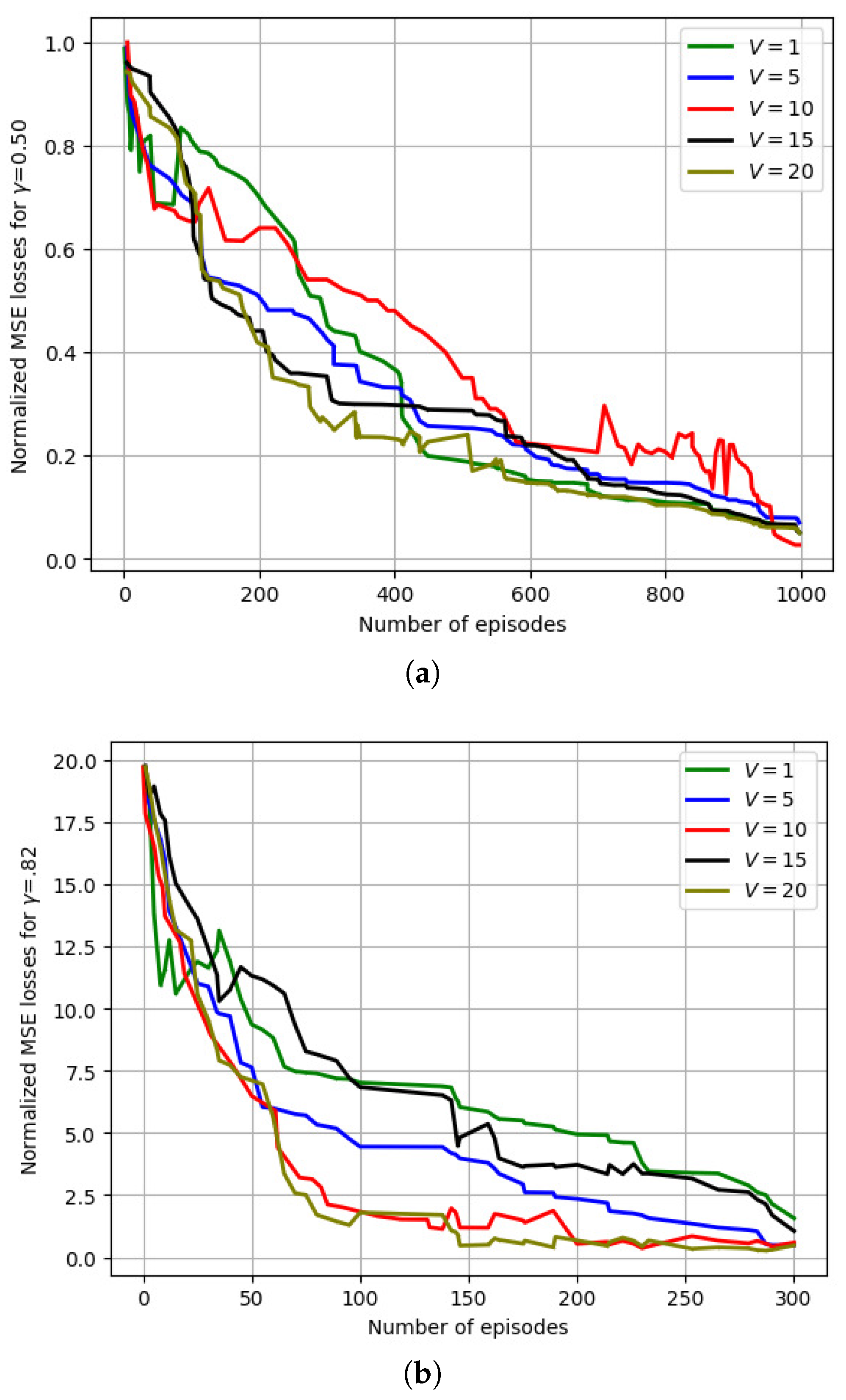
Figure 11 depicts the variation in the normalized MSE losses with the number of training episodes for a varying number of vehicles (V). For ( = 0.50), more communication rounds () were needed to aggregate the model updates due to a slower convergence time. Initially, all vehicles contributed equally in the global model computation, whereas in the following iterations, the UAV assigned higher weights to vehicles with slower convergence times to minimize the loss function. To analyze the losses, we reduced the learning rate () with respect to the number of global aggregations, as well as the number of training episodes.
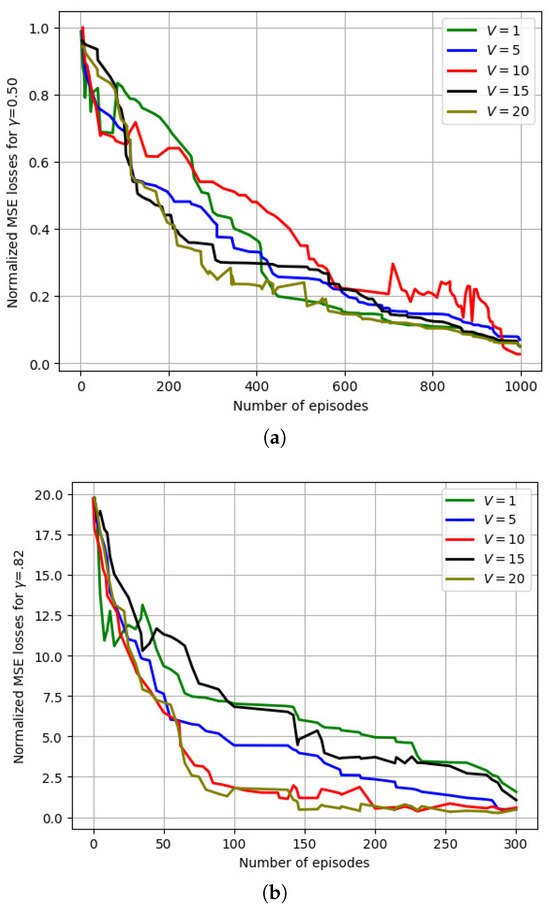
Figure 11.
Variation in the normalized MSE losses with varying (V) for a varying discount factor (). (a) Variation in the normalized MSE losses with a varying (V) for . (b) Variation in the normalized MSE losses with a varying (V) for .
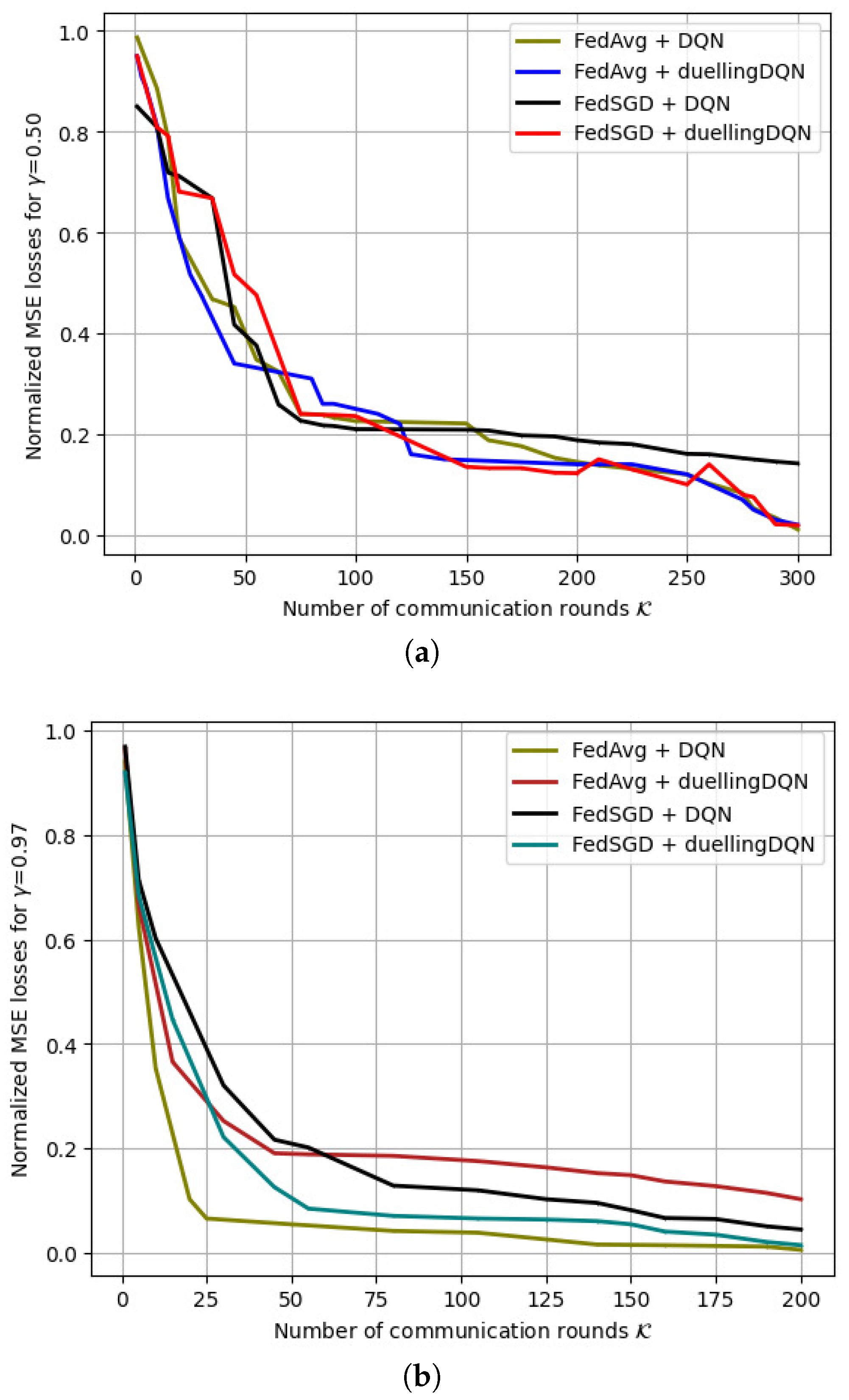
Figure 12 depicts the variation in the normalized MSE losses with the number of communication rounds () for FRL model training. A variety of hyper-parameter vectors were generated for FRL training with varying batch sizes. At the same time, the UAVs took into account the convergence time and loss function of each vehicle in order to average the local models from each vehicle and keep track of the number of incomplete local models. The FedSGD model’s MSE losses are comparable to the FedAvg model losses when trained on the same data. A study of vehicle selection policy changes over time and their impact on global UAV model convergence was conducted using long-term Q-value accumulation. From a random policy at the start of an episode, the UAV policy evolves to select a vehicle with different losses during subsequent episodes based on the -greedy method.
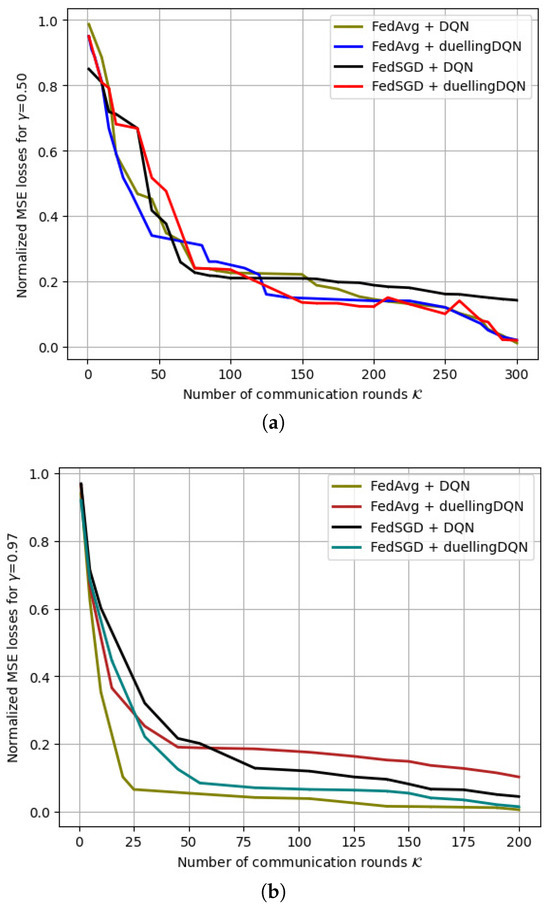
Figure 12.
Variations in the normalized MSE losses for FedAvg and FedSGD when () = 0.50 and 0.97. (a) Variations in the normalized MSE losses for FedAvg and FedSGD when . (b) Variations in the normalized MSE losses for FedAvg and FedSGD when .
6.3. Discussion and Comparison with Existing Works
As shown in Table 4, compared with the previous DRL and FL methods (whose results were reported as a 56% reduction in FL convergence time), our method achieved a reduction in the hyper-parameters by 40% in a similar convergence time. The proposed FRL approach also reduces the number of communication rounds () between the vehicles (V) and UAVs. Moreover, in DRL, a two-stream actor–critic network was used to analyze the power consumption and communication delays while we used a single DQN and a duellingDQN. In most of the existing FL approaches, learning from multiple datasets jointly was effective in producing generic vehicular communication. An interesting phenomenon observed was that the throughput and model convergence performance on FedAvg decreased slightly in comparison to FedSGD, which was attributed to non-i.i.d. training data. Utilizing FedSGD consistently improved the performance on all the agents by 1.5–3.7%. To achieve the best possible performance of our model, we fine tuned the individual agents with FedSGD and adapted the DQN to specific discount factors.
Table 4.
Comparisons of the different deep learning methods in vehicular communications.
7. Conclusions
In this paper, FRL was used to perform active vehicle selection as a means of minimizing the communication rounds in UAV-assisted C-V2X communication. Based on the number of vehicles and the time it takes for the model to converge, the proposed FRL approach provides improved throughput. Adaptive weight transmission with variable arrival rates was used for model aggregation to minimize delay. The FRL model losses were investigated to reduce delay and communication rounds while accelerating the convergence of the model when maximizing system throughput. However, at the UAVs, the time spent per iteration and model aggregation can have adverse effects on communication costs and model computations. To optimize the UAV energy consumption, a lower and upper bound on each episode prevents intermittent captures of the local SGD. Compared to state-of-the-art methods, FRL performs better in terms of model convergence speed, hyper-parameters exchanged, and communication rounds between vehicles and UAVs. As a future work, we aim to extend this FRL approach to the communication scenarios with multiple UAVs. The objective will be to optimize the available resource allocation such that only one UAV serves a vehicle in a given TTI. The FRL approach will be used to develop optimal policies, where other UAVs can either stay idle to preserve battery power or serve remaining vehicles. Moreover, as an extended future work, we aim to study the impact of various path loss models on the communication’s performance. Here, we intended to significantly increase the UAV altitude so that it frequently ventures beyond the LoS of the vehicles.
Author Contributions
Conceptualization, A.G. and X.F.; methodology, A.G.; writing—original draft preparation, A.G.; writing—review and editing, X.F.; supervision, X.F.; funding acquisition, X.F. All authors have read and agreed to the published version of the manuscript.
Funding
This project is funded by Natural Sciences and Engineering Research Council (NSERC) of Canada. Grant number: RGPIN-2024-04924.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 3GPP | Third-generation partnership project |
| 5GAA | Fifth-generation automotive association |
| 6G | Sixth generation (communication networks) |
| A2C | Advantage actor critic |
| AWGN | Additive white Gaussian noise |
| BS | Base station |
| C-ITS | Cooperative intelligent transport systems |
| C-V2X | Cellular vehicle-to-everything |
| DEM | Distributed expectation maximization |
| DNN | Deep neural network |
| DQN | Deep Q-network |
| DRL | Deep reinforcement learning |
| E2E | End-to-end |
| ES | Edge server |
| FAP | Fog access point |
| FD-SPS | Full duplex semi-persistent scheduling |
| FDRL | Federated deep reinforcement learning |
| FedAvg | Federated averaging |
| FedSGD | Federated stochastic gradient descent |
| FL | Federated learning |
| FL-DDPG | FL-based dual deterministic policy gradient |
| FRL | Federated reinforcement learning |
| GMM | Gaussian mixture model |
| HAP | High-altitude platform |
| i.i.d. | Independent-and-identically-distributed |
| IMU | Inertial measurement unit |
| LAP | Low-altitude platform |
| LiDAR | Light detection and ranging |
| LoS | Line of sight |
| MAB | Multi-armed bandit |
| MAC | Medium access control |
| MADRL | Multi-agent deep reinforcement learning |
| MEC | Mobile edge computing |
| ML | Machine learning |
| MSE | Mean square error |
| NOMA | Non-orthogonal multiple access |
| NLoS | Non line of sight |
| NR-V2X | New-radio vehicle-to-everything |
| OTFS | Orthogonal time frequency space |
| PCC | Partially collaborative caching |
| PDR | Packet delivery ratio |
| QoS | Quality of service |
| RL | Reinforcement learning |
| RSU | Road side unit |
| RTT | Round trip time |
| SAE | Society of Automotive Engineers |
| SINR | Signal-to-interference-plus-noise ratio |
| SB-SPS | Sensing-based semi persistent scheduling |
| TTI | Transmission time interval |
| UAV | Unmanned aerial vehicle |
| VEC | Vehicular edge computing |
References
- Shah, G.; Saifuddin, M.; Fallah, Y.P.; Gupta, S.D. RVE-CV2X: A Scalable Emulation Framework for Real-Time Evaluation of C-V2X based Connected Vehicle Applications. In Proceedings of the 2020 IEEE Vehicular Networking Conference (VNC), New York, NY, USA, 16–18 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Amadeo, M.; Campolo, C.; Molinaro, A.; Harri, J.; Rothenberg, C.E.; Vinel, A. Enhancing the 3GPP V2X Architecture with Information-Centric Networking. Future Internet 2019, 11, 199. [Google Scholar] [CrossRef]
- Park, H.; Lim, Y. Deep Reinforcement Learning Based Resource Allocation with Radio Remote Head Grouping and Vehicle Clustering in 5G Vehicular Networks. Electronics 2021, 10, 3015. [Google Scholar] [CrossRef]
- Manias, D.M.; Shami, A. Making a Case for Federated Learning in the Internet of Vehicles and Intelligent Transportation Systems. IEEE Netw. 2021, 35, 88–94. [Google Scholar] [CrossRef]
- Zang, J.; Shikh-Bahaei, M. Full Duplex-Based Scheduling Protocol for Latency Enhancement in 5G C-V2X VANETs. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Farokhi, F.; Wu, N.; Smith, D.; Kaafar, M.A. The Cost of Privacy in Asynchronous Differentially-Private Machine Learning. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2118–2129. [Google Scholar] [CrossRef]
- Javed, M.A.; Zeadally, S. AI-Empowered Content Caching in Vehicular Edge Computing: Opportunities and Challenges. IEEE Netw. 2021, 35, 109–115. [Google Scholar] [CrossRef]
- Sabeeh, S.; Wesołowski, K.; Sroka, P. C-V2X Centralized Resource Allocation with Spectrum Re-Partitioning in Highway Scenario. Electronics 2022, 11, 279. [Google Scholar] [CrossRef]
- Li, X.; Cheng, L.; Sun, C.; Lam, K.Y.; Wang, X.; Li, F. Federated Learning Empowered Collaborative Data Sharing for Vehicular Edge Networks. IEEE Netw. 2021, 35, 116–124. [Google Scholar] [CrossRef]
- Nie, L.; Wang, X.; Sun, W.; Li, Y.; Li, S.; Zhang, P. Imitation-Learning-Enabled Vehicular Edge Computing: Toward Online Task Scheduling. IEEE Netw. 2021, 35, 102–108. [Google Scholar] [CrossRef]
- Gupta, A.; Fernando, X. Co-operative Edge Intelligence for C-V2X Communication using Federated Reinforcement Learning. In Proceedings of the 2023 IEEE 34th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Toronto, ON, Canada, 5–8 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Wei, W.; Gu, H.; Li, B. Congestion Control: A Renaissance with Machine Learning. IEEE Netw. 2021, 35, 262–269. [Google Scholar] [CrossRef]
- Li, J.; Ryzhov, I.O. Convergence Rates of Epsilon-Greedy Global Optimization Under Radial Basis Function Interpolation. Stoch. Syst. 2022, 13, 1–180. [Google Scholar] [CrossRef]
- Zhao, L.; Xu, H.; Wang, Z.; Chen, X.; Zhou, A. Joint Channel Estimation and Feedback for mm-Wave System Using Federated Learning. IEEE Commun. Lett. 2022, 26, 1819–1823. [Google Scholar] [CrossRef]
- Amiri, M.M.; Gunduz, D. Federated Learning Over Wireless Fading Channels. IEEE Trans. Wirel. Commun. 2020, 19, 3546–3557. [Google Scholar] [CrossRef]
- Sempere-García, D.; Sepulcre, M.; Gozalvez, J. LTE-V2X Mode 3 scheduling based on adaptive spatial reuse of radio resources. Ad Hoc Netw. 2021, 113, 102351. [Google Scholar] [CrossRef]
- Gupta, A.; Fernando, X. Analysis of Unmanned Aerial Vehicle-Assisted Cellular Vehicle-to-Everything Communication Using Markovian Game in a Federated Learning Environment. Drones 2024, 8, 238. [Google Scholar] [CrossRef]
- Qiao, D.; Liu, G.; Guo, S.; He, J. Adaptive Federated Learning for Non-Convex Optimization Problems in Edge Computing Environment. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3478–3491. [Google Scholar] [CrossRef]
- Roshdi, M.; Bhadauria, S.; Hassan, K.; Fischer, G. Deep Reinforcement Learning based Congestion Control for V2X Communication. In Proceedings of the 2021 IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 13–16 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Kang, B.; Yang, J.; Paek, J.; Bahk, S. ATOMIC: Adaptive Transmission Power and Message Interval Control for C-V2X Mode 4. IEEE Access 2021, 9, 12309–12321. [Google Scholar] [CrossRef]
- Ali, Z.; Lagen, S.; Giupponi, L.; Rouil, R. 3GPP NR-V2X Mode 2: Overview, Models and System-Level Evaluation. IEEE Access 2021, 9, 89554–89579. [Google Scholar] [CrossRef] [PubMed]
- Cao, L.; Yin, H.; Wei, R.; Zhang, L. Optimize Semi-Persistent Scheduling in NR-V2X: An Age-of-Information Perspective. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2053–2058. [Google Scholar]
- Dogahe, B.M.; Murthi, M.N.; Fan, X.; Premaratne, K. A distributed congestion and power control algorithm to achieve bounded average queuing delay in wireless networks. Telecommun. Syst. 2010, 44, 307–320. [Google Scholar] [CrossRef]
- Gemici, O.F.; Hokelek, I.; Crpan, H.A. Modeling Queuing Delay of 5G NR with NOMA Under SINR Outage Constraint. IEEE Trans. Veh. Technol. 2021, 70, 2389–2403. [Google Scholar] [CrossRef]
- Kumar, A.S.; Zhao, L.; Fernando, X. Multi-Agent Deep Reinforcement Learning-Empowered Channel Allocation in Vehicular Networks. IEEE Trans. Veh. Technol. 2022, 71, 1726–1736. [Google Scholar] [CrossRef]
- Kumar, A.S.; Zhao, L.; Fernando, X. Task Offloading and Resource Allocation in Vehicular Networks: A Lyapunov-based Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2023, 72, 13360–13373. [Google Scholar] [CrossRef]
- Kumar, A.S.; Zhao, L.; Fernando, X. Mobility Aware Channel Allocation for 5G Vehicular Networks using Multi-Agent Reinforcement Learning. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Ibrahim, A.M.; Yau, K.L.A.; Chong, Y.W.; Wu, C. Applications of Multi-Agent Deep Reinforcement Learning: Models and Algorithms. Appl. Sci. 2021, 11, 10870. [Google Scholar] [CrossRef]
- Raff, E. Inside Deep Learning: Math, Algorithms, Models; Manning Publications: New York, NY, USA, 2022. [Google Scholar]
- Fan, B.; He, Z.; Wu, Y.; He, J.; Chen, Y.; Jiang, L. Deep Learning Empowered Traffic Offloading in Intelligent Software Defined Cellular V2X Networks. IEEE Trans. Veh. Technol. 2020, 69, 13328–13340. [Google Scholar] [CrossRef]
- Chen, M.; Poor, H.V.; Saad, W.; Cui, S. Convergence Time Optimization for Federated Learning Over Wireless Networks. IEEE Trans. Wirel. Commun. 2021, 20, 2457–2471. [Google Scholar] [CrossRef]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Distributed Federated Learning for Ultra-Reliable Low-Latency Vehicular Communications. IEEE Trans. Commun. 2020, 68, 1146–1159. [Google Scholar] [CrossRef]
- Jayanetti, A.; Halgamuge, S.; Buyya, R. Deep reinforcement learning for energy and time optimized scheduling of precedence-constrained tasks in edge–cloud computing environments. Future Gener. Comput. Syst. 2022, 137, 14–30. [Google Scholar] [CrossRef]
- Gyawali, S.; Qian, Y.; Hu, R. Deep Reinforcement Learning Based Dynamic Reputation Policy in 5G Based Vehicular Communication Networks. IEEE Trans. Veh. Technol. 2021, 70, 6136–6146. [Google Scholar] [CrossRef]
- Sial, M.N.; Deng, Y.; Ahmed, J.; Nallanathan, A.; Dohler, M. Stochastic Geometry Modeling of Cellular V2X Communication Over Shared Channels. IEEE Trans. Veh. Technol. 2019, 68, 11873–11887. [Google Scholar] [CrossRef]
- Li, Y. Model Training Method and Device Based on FedMGDA + and Federated Learning. CN202211060911.4, 31 August 2022. [Google Scholar]
- Zhan, Y.; Li, P.; Guo, S.; Qu, Z. Incentive Mechanism Design for Federated Learning: Challenges and Opportunities. IEEE Netw. 2021, 35, 310–317. [Google Scholar] [CrossRef]
- Liu, S.; Yu, J.; Deng, X.; Wan, S. FedCPF: An Efficient Communication Federated Learning Approach for Vehicular Edge Computing in 6G Communication Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1616–1629. [Google Scholar] [CrossRef]
- Xu, C.; Liu, S.; Yang, Z.; Huang, Y.; Wong, K.K. Learning Rate Optimization for Federated Learning Exploiting Over-the-Air Computation. IEEE J. Sel. Areas Commun. 2021, 39, 3742–3756. [Google Scholar] [CrossRef]
- He, J.; Yang, K.; Chen, H.H. 6G Cellular Networks and Connected Autonomous Vehicles. IEEE Netw. 2021, 35, 255–261. [Google Scholar] [CrossRef]
- Xia, Q.; Ye, W.; Tao, Z.; Wu, J.; Li, Q. A survey of federated learning for edge computing: Research problems and solutions. High-Confid. Comput. 2021, 1, 100008. [Google Scholar] [CrossRef]
- Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated Learning in Edge Computing: A Systematic Survey. Sensors 2022, 22, 450. [Google Scholar] [CrossRef] [PubMed]
- Brecko, A.; Kajati, E.; Koziorek, J.; Zolotova, I. Federated Learning for Edge Computing: A Survey. Appl. Sci. 2022, 12, 9124. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhai, R.; Wang, Y.; Wang, X. Survey on challenges of federated learning in edge computing scenarios. In Proceedings of the International Conference on Internet of Things and Machine Learning (IOTML 2021), Shanghai, China, 17–19 December 2021; SPIE: Bellingham, WA, USA, 2022; Volume 12174, p. 121740C. [Google Scholar]
- Moon, S.; Lim, Y. Federated Deep Reinforcement Learning Based Task Offloading with Power Control in Vehicular Edge Computing. Sensors 2022, 22, 9595. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.T.; Sehwag, V.; Hosseinalipour, S.; Brinton, C.G.; Chiang, M.; Vincent Poor, H. Fast-Convergent Federated Learning. IEEE J. Sel. Areas Commun. 2021, 39, 201–218. [Google Scholar] [CrossRef]
- Ma, Z.; Chen, X.; Ma, T.; Chen, Y. Deep Deterministic Policy Gradient Based Resource Allocation in Internet of Vehicles. In Parallel Architectures, Algorithmsand Programming, Proceedings of the 11th International Symposium, PAAP 2020, Shenzhen, China, 28–30 December 2020; Springer: Singapore, 2021; pp. 295–306. [Google Scholar]
- Zhu, Q.; Liu, R.; Wang, Z.; Liu, Q.; Chen, C. Sensing-Communication Co-Design for UAV Swarm-Assisted Vehicular Network in Perspective of Doppler. IEEE Trans. Veh. Technol. 2023, 73, 2578–2592. [Google Scholar] [CrossRef]
- Qu, G.; Xie, A.; Liu, S.; Zhou, J.; Sheng, Z. Reliable Data Transmission Scheduling for UAV-Assisted Air-to-Ground Communications. IEEE Trans. Veh. Technol. 2023, 72, 13787–13792. [Google Scholar] [CrossRef]
- Li, Y.; Ma, D.; An, Z.; Wang, Z.; Zhong, Y.; Chen, S.; Feng, C. V2X-Sim: Multi-Agent Collaborative Perception Dataset and Benchmark for Autonomous Driving. IEEE Robot. Autom. Lett. 2022, 7, 10914–10921. [Google Scholar] [CrossRef]
- Sun, G.; Boateng, G.O.; Ayepah-Mensah, D.; Liu, G.; Wei, J. Autonomous Resource Slicing for Virtualized Vehicular Networks With D2D Communications Based on Deep Reinforcement Learning. IEEE Syst. J. 2020, 14, 4694–4705. [Google Scholar] [CrossRef]
- Morales, E.F.; Murrieta-Cid, R.; Becerra, I.; Esquivel-Basaldua, M.A. A survey on deep learning and deep reinforcement learning in robotics with a tutorial on deep reinforcement learning. Intell. Serv. Robot. 2021, 14, 773–805. [Google Scholar] [CrossRef]
- Ali, R.; Zikria, Y.B.; Garg, S.; Bashir, A.K.; Obaidat, M.S.; Kim, H.S. A Federated Reinforcement Learning Framework for Incumbent Technologies in Beyond 5G Networks. IEEE Netw. 2021, 35, 152–159. [Google Scholar] [CrossRef]
- Arani, A.H.; Hu, P.; Zhu, Y. Re-envisioning Space-Air-Ground Integrated Networks: Reinforcement Learning for Link Optimization. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).