2.1. UAVs-CJ Scenario and Decision-Making Process
Two UAV swarms are assumed to engage in confrontation within a certain area (
Figure 1). Our swarm is denoted by Red, and the enemy swarm is denoted by Blue. Swarm Red consists of
UAVs, denoted as
; swarm Blue is composed of
UAVs, denoted as
. Both Red and Blue adopt a centralized networking architecture that relies on a cluster head node to manage the UAVs within the swarm, collect situational information, and send control commands to achieve information exchange between the swarms.
Swarm Red is tasked with interfering with and suppressing the nodes within swarm Blue through electronic jamming methods [
21]. Its aim is to weaken or disrupt the signal detection and reception processes of their electronic systems, thereby terminating or disrupting the execution of swarm Blue’s tasks, or inhibiting their autonomous coordination and intelligent emergence, effectively reducing their effectiveness. Swarm Blue, conversely, is dedicated to maintaining the connectivity of its own communication network to sustain effectiveness, thereby effectively executing tasks such as detection, search, and attack.
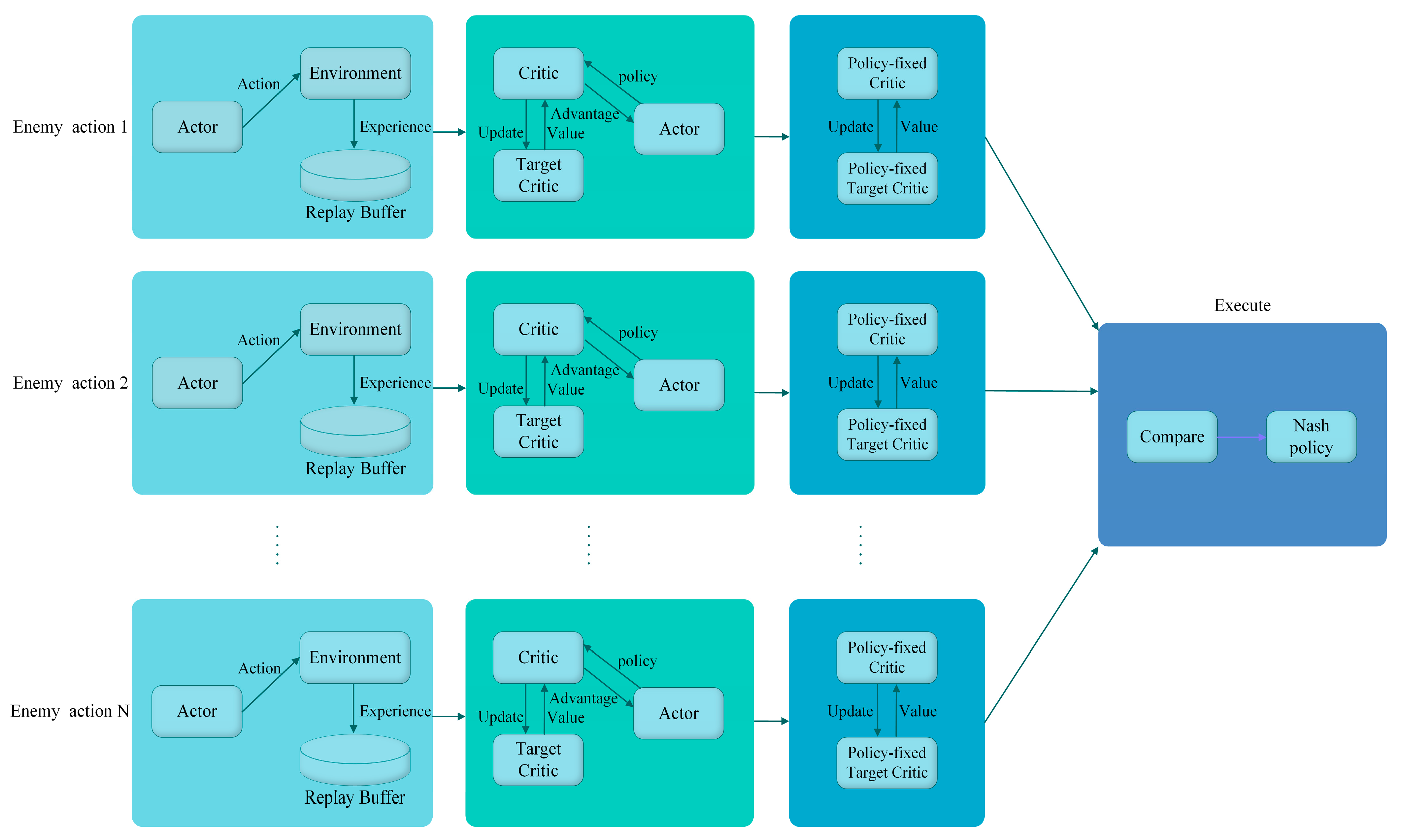
During the entire process, swarm Red continuously specifies the corresponding electronic jamming schemes based on the previous state of swarm Blue. Meanwhile, swarm Blue dynamically adjusts its network structure by re-selecting the cluster head node according to the jamming behavior of swarm Red. There is an information barrier between the two swarms, which prevents swarm Red from accurately obtaining the networking scheme generated by swarm Blue for the next moment. Thus, it is necessary to include the possible schemes of swarm Blue in the decision loop. The entire confrontation process continues for several rounds, during which swarm Red is committed to maximizing the cumulative gains within the time period.
2.2. Intelligent Mathematical Decision-Making Model Based on MGs
As stated in the introduction, this study utilizes an MG to construct a mathematical model for intelligent decision-making in UAV swarms. The model uses a six-tuple and MPE, with the meanings and settings of each element as follows:
represents the state space. A state describes the scene, with any element in the state space mapping to a specific scene at a given time. For this purpose, and considering the characteristics of confrontation jamming scenarios, the state is defined by the spatial positions of swarm Red and swarm Blue, as well as the communication network structures of both swarms. The expression is , where represents the position of the -th UAV in both swarms, with being the coordinates on the two-dimensional plane. is the connectivity matrix of the -th UAV for the two swarms, where each element indicates the connectivity status between the -th UAV and the -th UAV in the swarm. A value of 1 denotes that they can communicate with each other, while a value of 0 denotes no established communication link.
represents the action space of swarm Red, which denotes swarm Red’s electronic jamming scheme, setting the central element
as the jamming power allocated to each UAV node of swarm Blue. The expression is
, and
is the jamming power from swarm Red’s
-th UAV to swarm Blue’s
-th UAV;
represents the action space of swarm Blue. As described in
Section 2.1,
is equivalent to all alternative communication network structures in swarm Blue, and the elements
in the set map are equivalent to a particular communication network. The expression of
is
, which holds the same meaning in
.
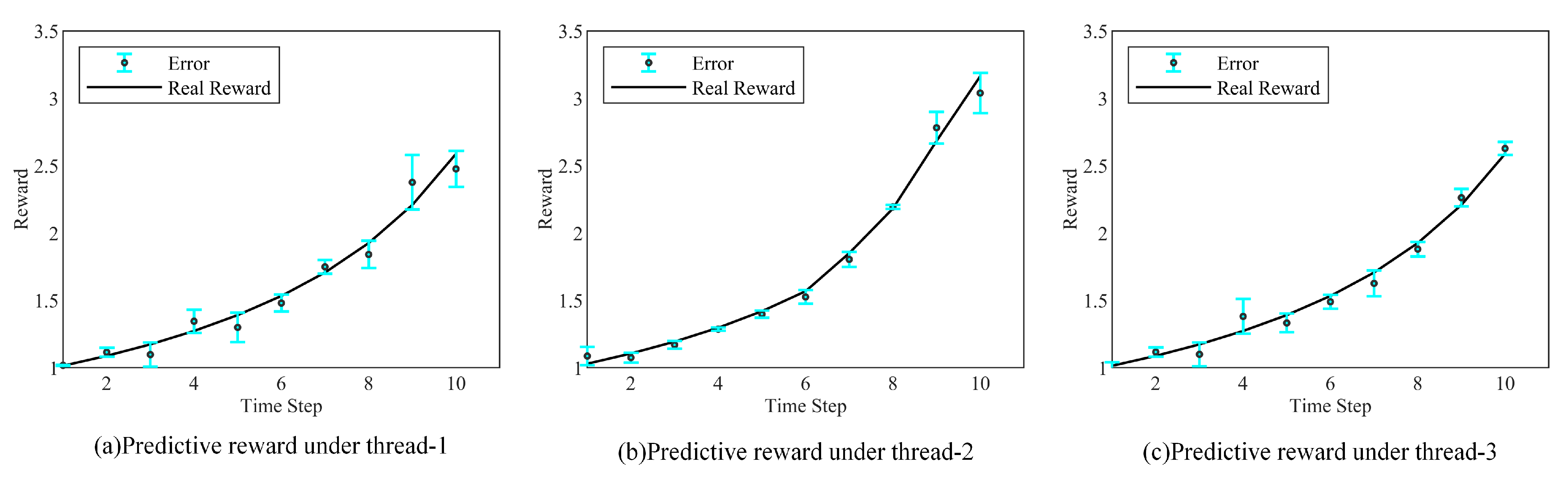
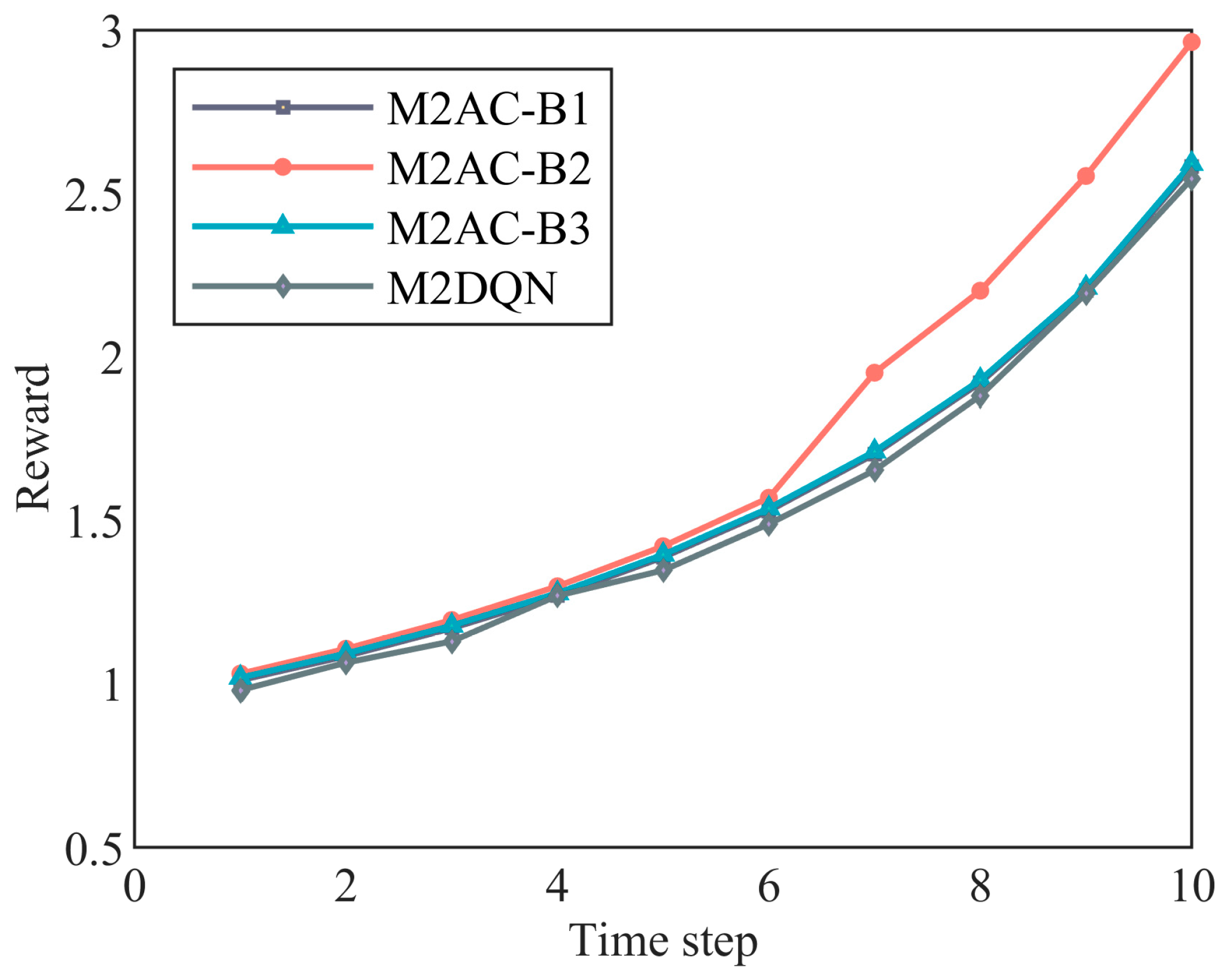
represents the state transition probability; the specific expression is , which represents the probability distribution of state at the moment after the two swarms perform actions and . After executing the actions, both swarms continue to navigate at their original speeds, i.e., , where represents the velocity vector of the UAVs.
represents the reward function with the specific expression
; this expression denotes the function of the reward values for both swarms after executing their respective actions at time
and in state, typically denoted by
. For swarm Red, the reward is positively correlated with the degree of disturbance to the adversary. Considering that the jamming-to-signal ratio (JSR) is the most commonly used metric for evaluating interference suppression [
22], the calculation formula for the profit function is as follows:
where
represents the JSR of the enemy node
, while
represents the node weight, signifying the importance of node
in swarm Blue’s communication network. The two swarms are in an adversarial relationship; hence, this constitutes a zero-sum game issue in which the payoff for swarm Blue can be set as the negative of the payoff for swarm
.
The parameter
represents the discount factor that determines the present value of future rewards as reflected in the cumulative reward calculation process. For swarm Red, the cumulative reward is defined by Equation (2) [
23], which is equivalent to the expected weighted cumulative reward from the starting state
to the end, denoted by
. The rewards for both swarms are opposite in sign; hence, the cumulative reward for swarm
is
.
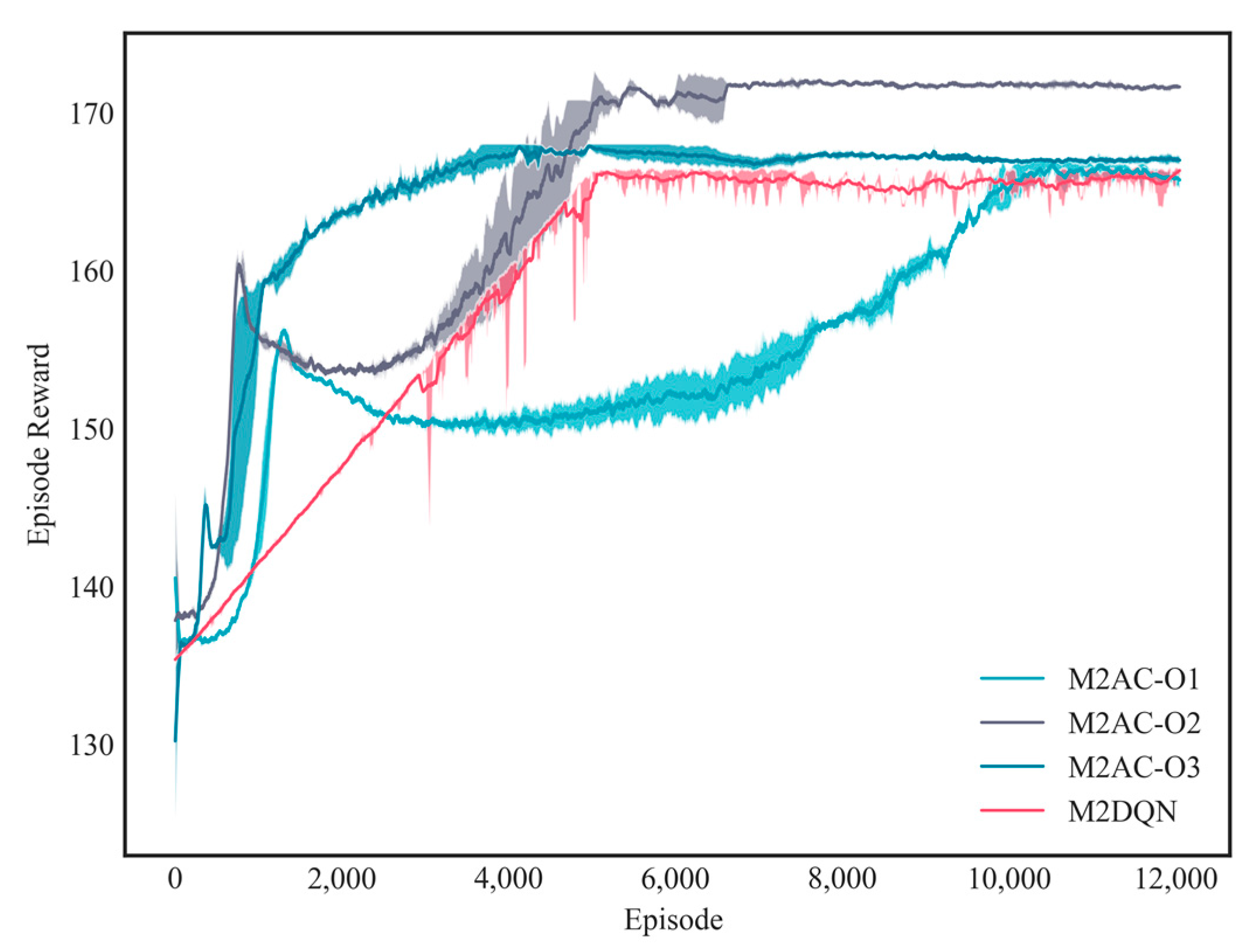
The goal of the MG model is to obtain the MPE. MPE is divided into two types: pure- and mixed-strategy games [
7]. In pure-strategy games, MPE does not exist universally; hence, we chose MPE in mixed-strategy games as the goal of the MG model in this study. In this setting, both swarms make decisions based on probabilities, which is the probability distribution for executing specific actions. The strategies of the two sides are represented by
and
, respectively, where
represents the probability of swarm
choosing action
in a certain state, and
represents the same for swarm Blue.
Based on this, the definition of the MPE is provided. A strategy pair that satisfies Equation (3) is referred to as the MPE strategy for the entire MG model.
where
limit the strategies of both sides based on Equation (2). The equation implies that when swarm Red chooses a particular strategy
, regardless of the strategy adopted by swarm Blue, the cumulative reward will not be less than
. This is meaningful in guiding situations where there is an information gap between the two parties.





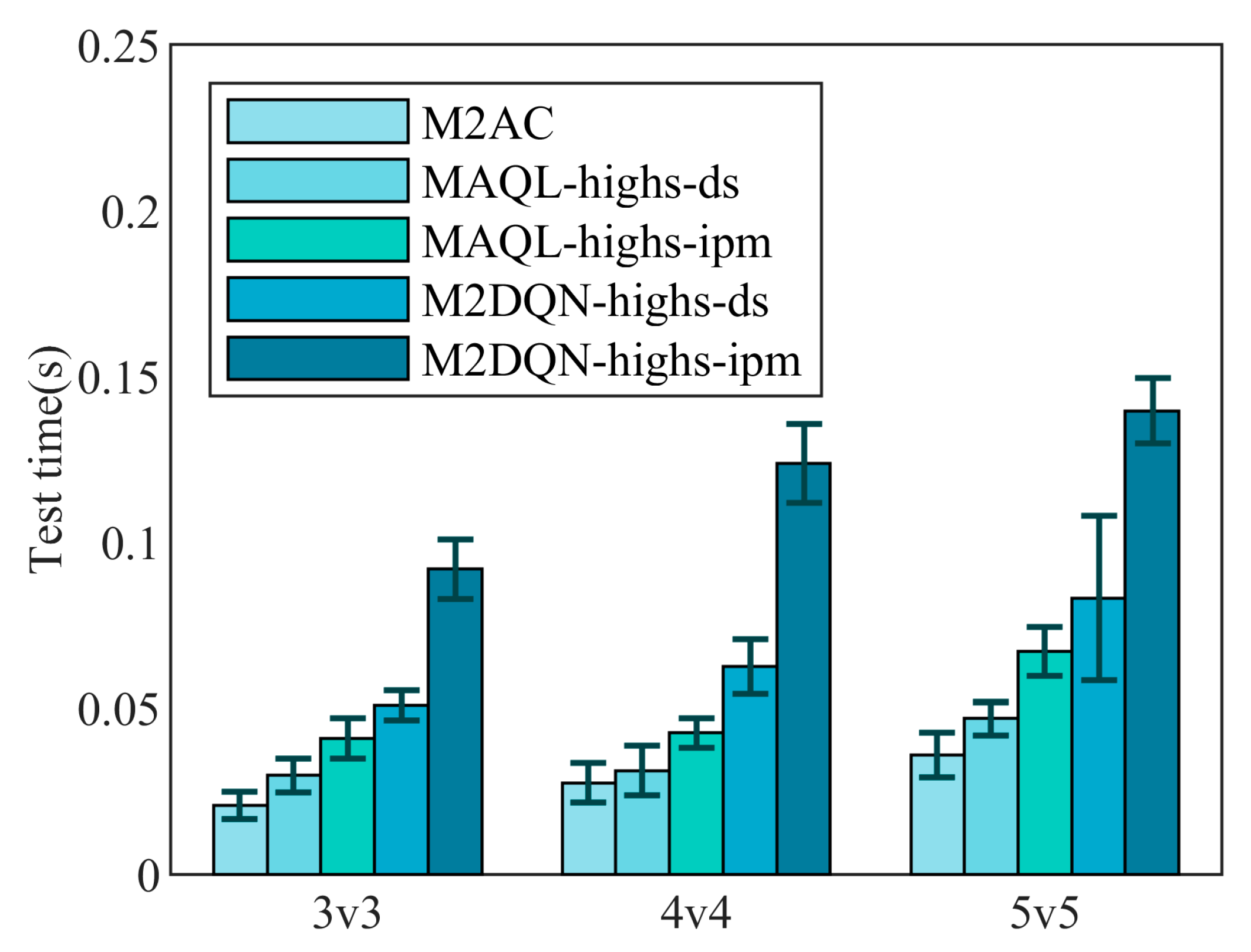

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}