
YOLO-SMUG: An Efficient and Lightweight Infrared Object Detection Model for Unmanned Aerial Vehicles


Abstract
:1. Introduction
2. Model and Training
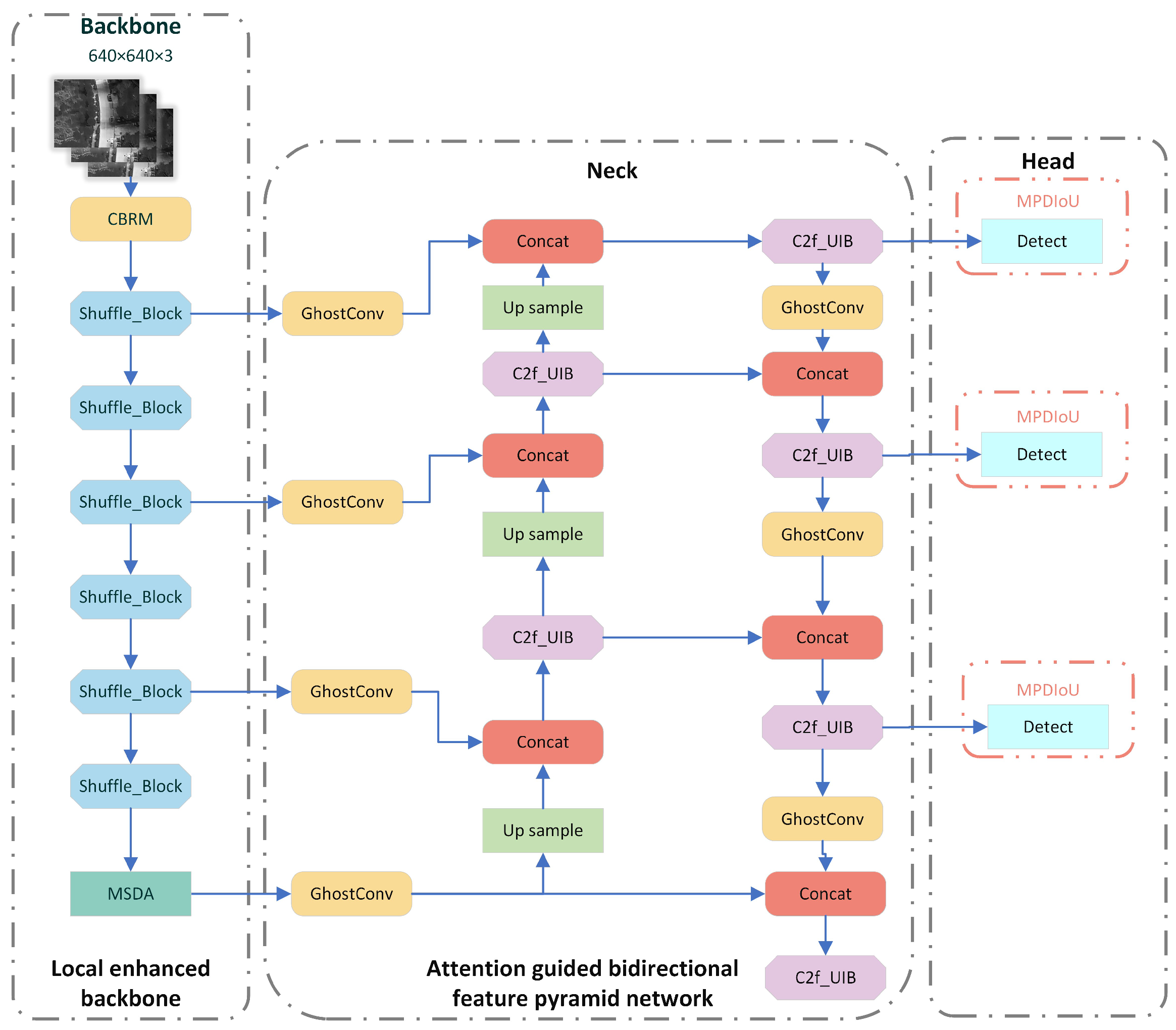
2.1. YOLO-SMUG Model Network Structure
- Backbone Optimization: A novel backbone network based on ShuffleNetV2 is integrated with a Multi-Scale Dilated Attention (MSDA) mechanism to improve the model’s ability to extract essential features from infrared environments with complex, cluttered backgrounds and variations in object scale and size. This modification significantly reduces the number of parameters and computational complexity while maintaining high detection accuracy, ensuring that the model remains suitable for efficient processing on UAVs with limited onboard computing resources.
- Neck Component Enhancement: The conventional C2f and convolutional layers are replaced with a lightweight inverted bottleneck structure, C2f_UIB, and GhostConv, effectively minimizing computational overhead and parameter size without compromising the model’s feature extraction capabilities. This structural refinement enhances processing efficiency, enabling the UAV to better address issues such as insufficient color characteristics, blurred edges, and low resolution in infrared images.
- Improved Loss Function: The original loss function is substituted with MPDIoU, which enhances object localization accuracy by refining bounding box regression. This improvement is crucial for practical applications, as it ensures precise object identification and tracking in real-world scenarios, while also minimizing detection errors caused by the higher noise levels in infrared images.
2.2. Designing a Lightweight Feature Extraction Network with an Integrated Attention Mechanism
2.2.1. ShuffleNetv2 Model
2.2.2. Multi-Scale Dilated Attention Mechanism
2.2.3. Improved Feature Extraction Network
2.3. Designing a Enhanced Feature Fusion Network
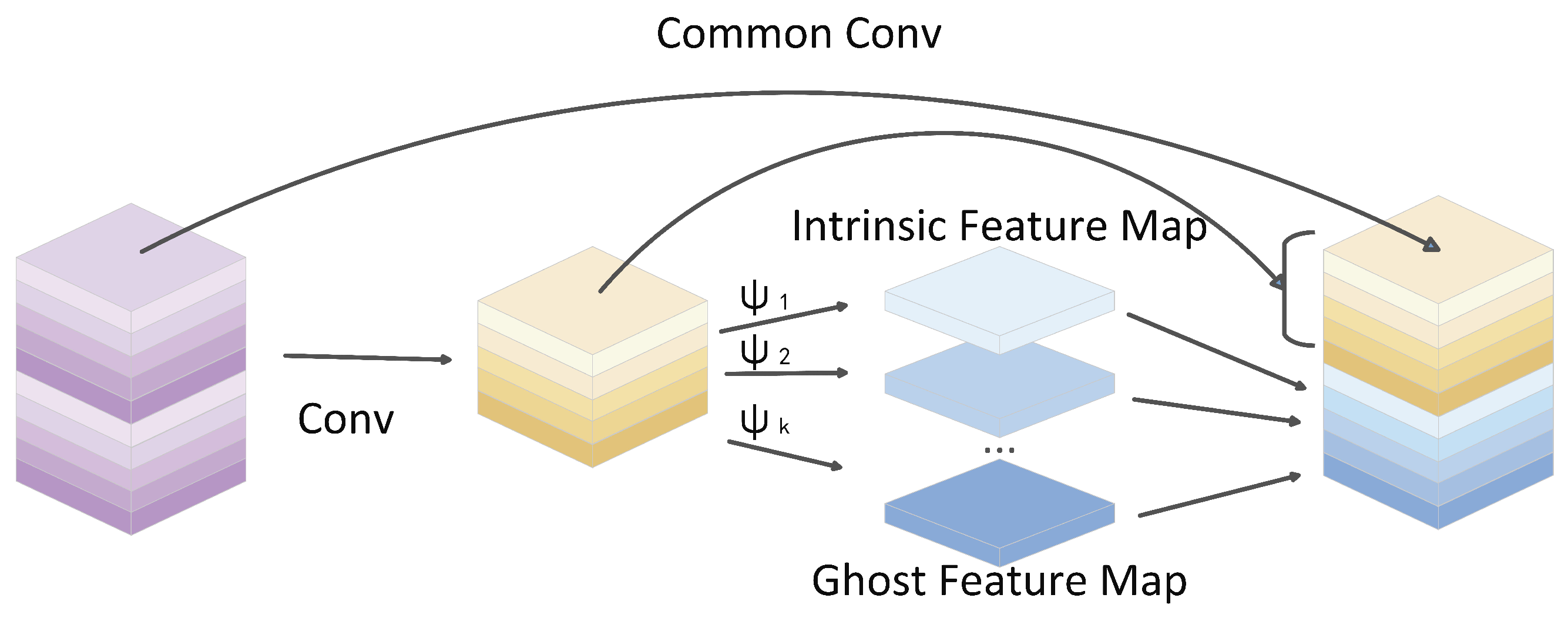
2.3.1. Introducing the Lightweight Ghost Convolution Module
- When is much larger than : That is, when the number of linear transformations is much greater than the number of input channels . In this case, the term in the denominator dominates; hence, .
- When is relatively small: That is, when the number of input channels is small, and is relatively large. At this point, the term in the denominator has a minimal impact on the overall result, and the approximation still holds.
- In lightweight networks: Lightweight networks are typically designed with a larger and a smaller to meet the requirements for computational efficiency. Therefore, this assumption has practical significance in the design of lightweight networks.
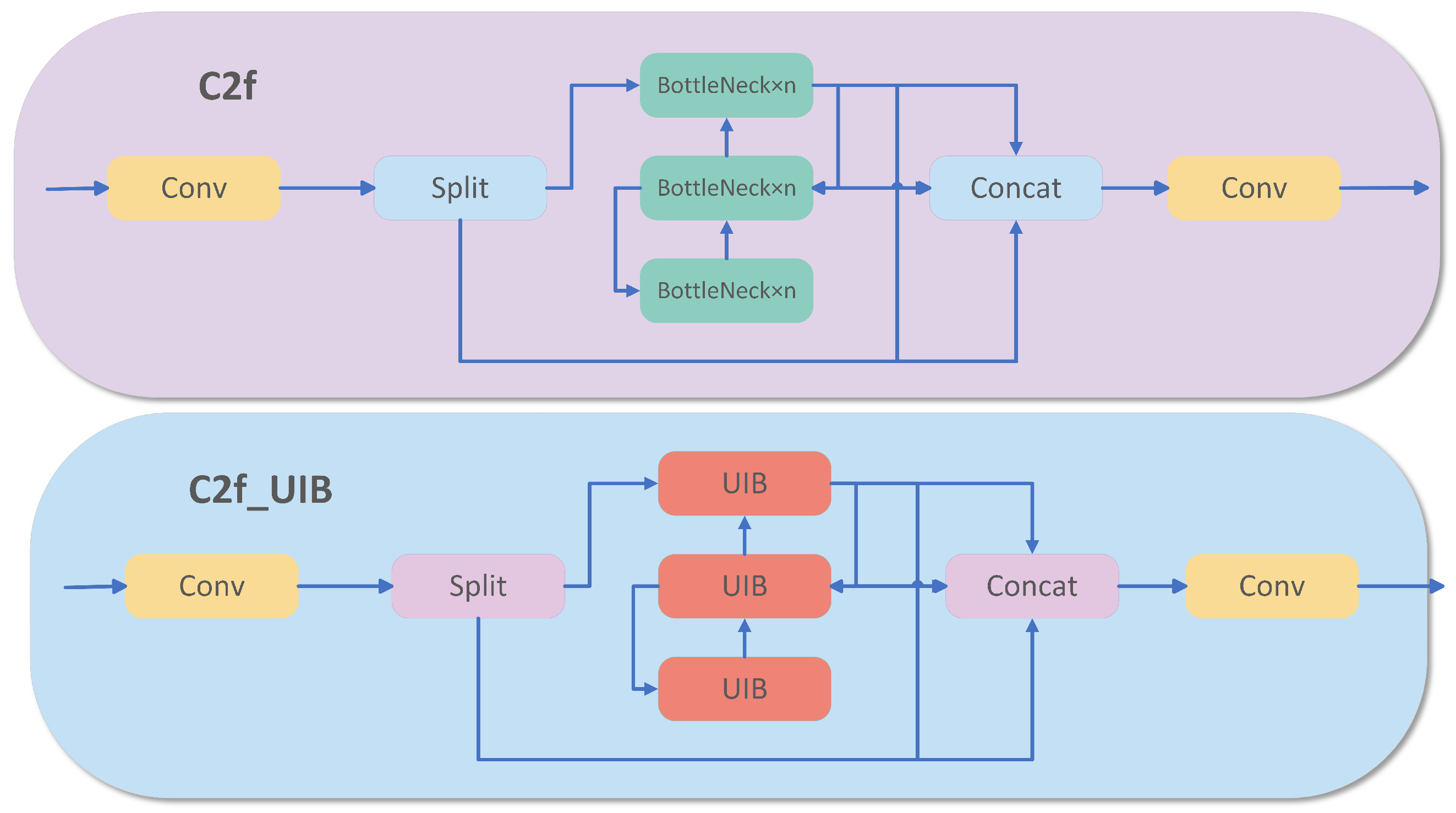
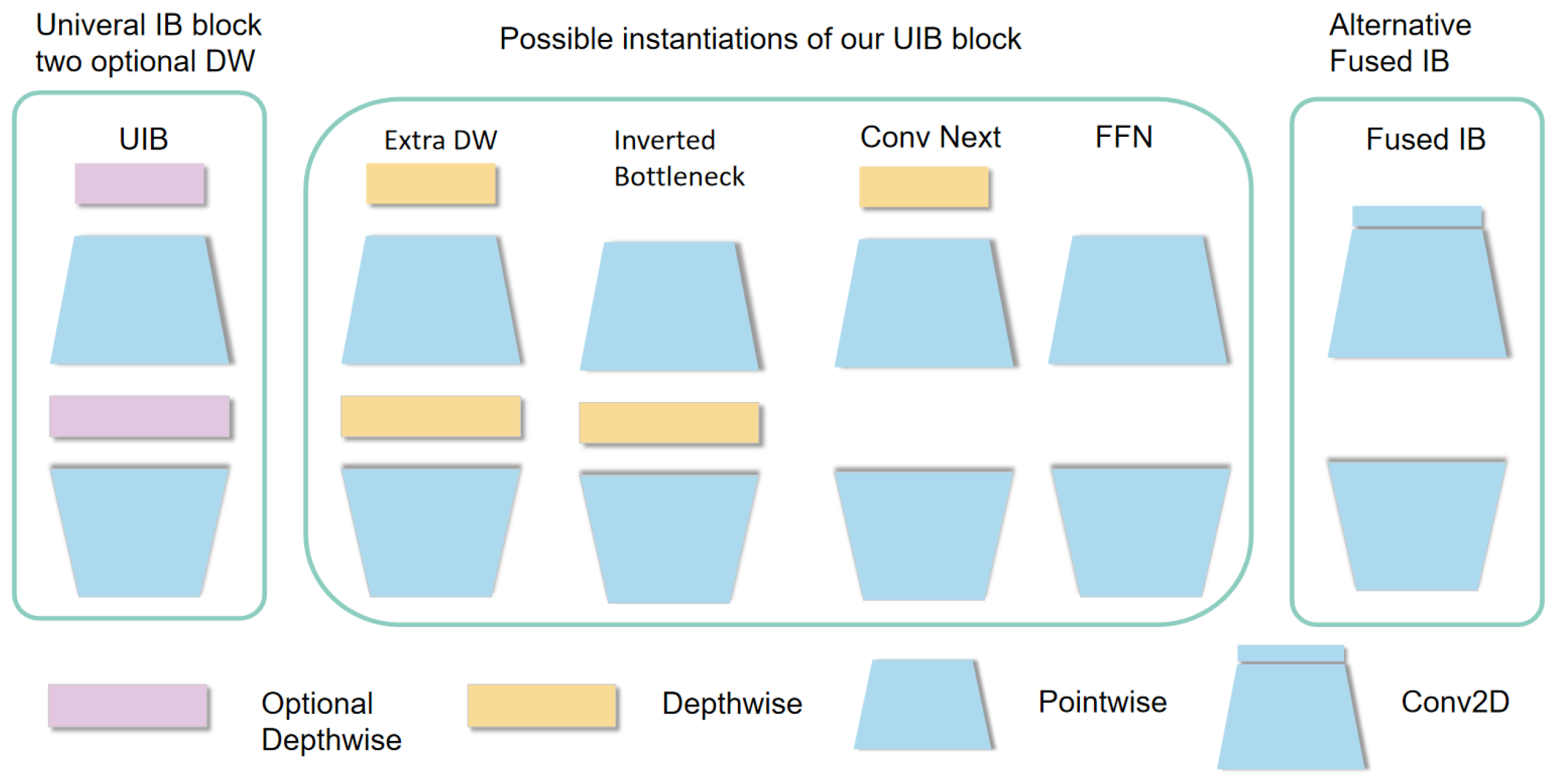
2.3.2. Introducing of the Lightweight Module C2f_UIB
2.3.3. Improved Feature Fusion Networks
2.4. Designing of MPDIoU-Based Loss Function
3. Model Training and Evaluation Metrics
3.1. Datasets
3.2. Assessment Indicators
3.3. Experimental Platform
3.4. Experimental Results
3.4.1. Comparative Analysis of the Incorporation of Different Attention Mechanisms
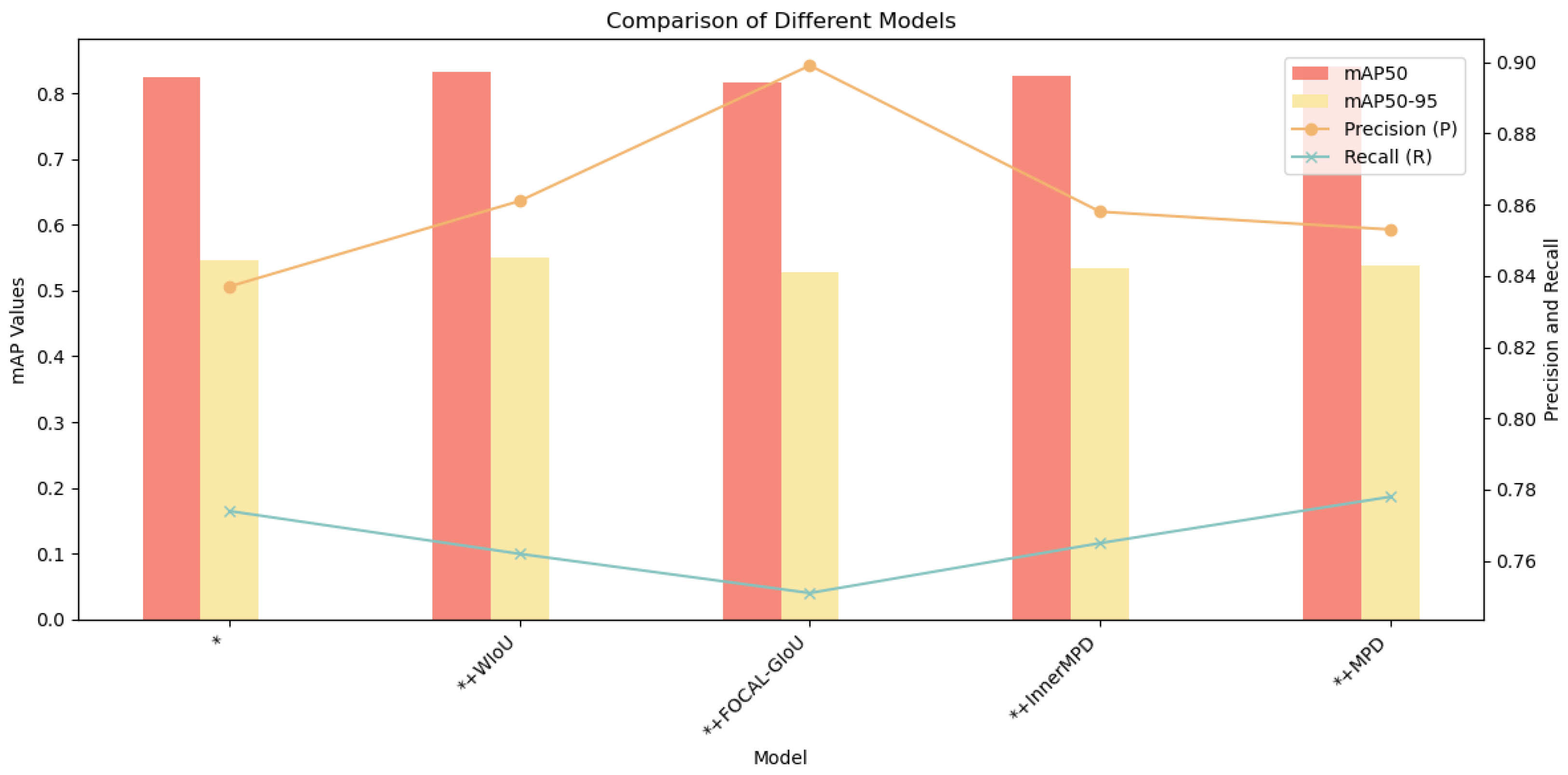
3.4.2. Comparative Analysis of the Incorporation of Varied Loss Function
3.4.3. Ablation Experiment
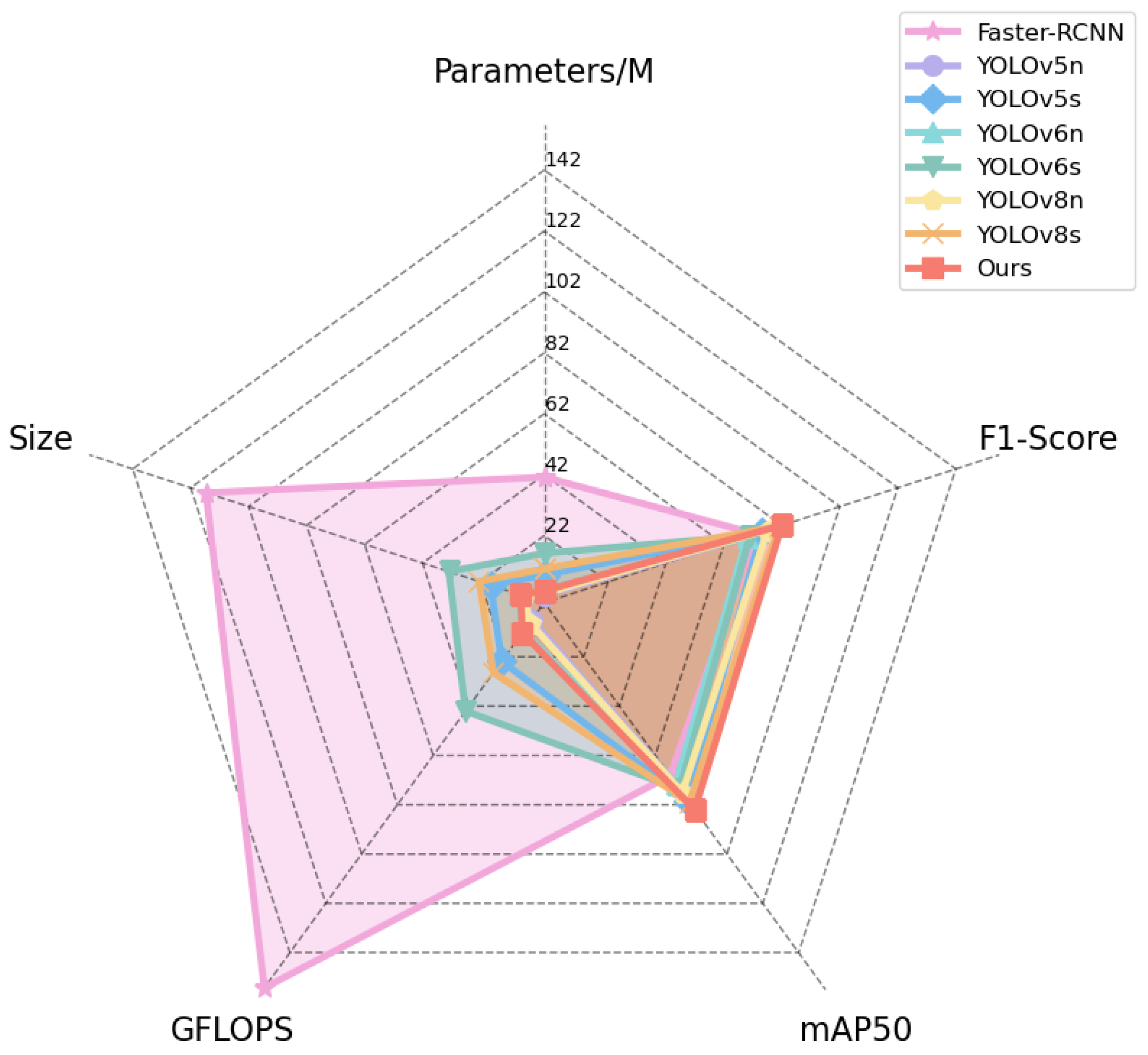
3.4.4. Model Comparison Experiment
3.4.5. Visual Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Thiels, C.A.; Aho, J.M.; Zietlow, S.P.; Jenkins, D.H. Use of unmanned aerial vehicles for medical product transport. Air Med. J. 2015, 34, 104–108. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Alpiste, I.; Golcarenarenji, G.; Wang, Q.; Alcaraz-Calero, J.M. Search and rescue operation using UAVs: A case study. Expert Syst. Appl. 2021, 178, 114937. [Google Scholar] [CrossRef]
- Lu, L.; Chen, Z.; Wang, R.; Liu, L.; Chi, H. Yolo-inspection: Defect detection method for power transmission lines based on enhanced YOLOv5s. J. Real-Time Image Process. 2023, 20, 104. [Google Scholar] [CrossRef]
- Ollero, A.; Merino, L. Unmanned aerial vehicles as tools for forest-fire fighting. For. Ecol. Manag. 2006, 234, S263. [Google Scholar] [CrossRef]
- Velusamy, P.; Rajendran, S.; Mahendran, R.K.; Naseer, S.; Shafiq, M.; Choi, J.G. Unmanned Aerial Vehicles (UAV) in precision agriculture: Applications and challenges. Energies 2021, 15, 217. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhu, L. A Review on Unmanned Aerial Vehicle Remote Sensing: Platforms, Sensors, Data Processing Methods, and Applications. Drones 2023, 7, 398. [Google Scholar] [CrossRef]
- Kotlinski, M.; Calkowska, J.K. U-Space and UTM deployment as an opportunity for more complex UAV operations including UAV medical transport. J. Intell. Robot. Syst. 2022, 106, 12. [Google Scholar] [CrossRef]
- Polukhin, A.; Gordienko, Y.; Jervan, G.; Stirenko, S. Object detection for rescue operations by high-altitude infrared thermal imaging collected by unmanned aerial vehicles. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Alicante, Spain, 27–30 June 2023; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 490–504. [Google Scholar]
- Liao, K.C.; Lu, J.H. Using UAV to detect solar module fault conditions of a solar power farm with IR and visual image analysis. Appl. Sci. 2021, 11, 1835. [Google Scholar] [CrossRef]
- Ma, Y.; Wei, K.; Liu, F. Research on Visual Algorithm for Fire Detection of Firefighting UAVs Based on Infrared Imaging. In Proceedings of the International Conference on the Efficiency and Performance Engineering Network, Qingdao, China, 8–11 May 2024; Springer Nature: Cham, Switzerland, 2024; pp. 121–131. [Google Scholar]
- Messina, G.; Modica, G. Applications of UAV thermal imagery in precision agriculture: State of the art and future research outlook. Remote Sens. 2020, 12, 1491. [Google Scholar] [CrossRef]
- Christnacher, F.; Hengy, S.; Laurenzis, M.; Matwyschuk, A.; Naz, P.; Schertzer, S.; Schmitt, G. Optical and acoustical UAV detection. In Proceedings of the Electro-Optical Remote Sensing X, Edinburgh, UK, 26–29 September 2016; Volume 9988, pp. 83–95. [Google Scholar]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-based R-CNNs for fine-grained category detection. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Solimani, F.; Cardellicchio, A.; Dimauro, G.; Petrozza, A.; Summerer, S.; Cellini, F.; Renò, V. Optimizing tomato plant phenotyping detection: Boosting YOLOv8 architecture to tackle data complexity. Comput. Electron. Agric. 2024, 218, 108728. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ma, G.; Li, W.; Bao, H.; Roberts, N.J.; Li, Y.; Zhang, W.; Yang, K.; Jiang, G. UAV equipped with infrared imaging for Cervidae monitoring: Improving detection accuracy by eliminating background information interference. Ecol. Inform. 2024, 81, 102651. [Google Scholar] [CrossRef]
- Yang, Z.; Lian, J.; Liu, J. Infrared UAV target detection based on continuous-coupled neural network. Micromachines 2023, 14, 2113. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; Ding, L.; Wang, L.; Chang, Y.; Yan, L.; Han, J. Infrared small UAV target detection based on depthwise separable residual dense network and multiscale feature fusion. IEEE Trans. Instrum. Meas. 2022, 71, 1–20. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhou, L.; An, J. Real-time recognition algorithm of small target for UAV infrared detection. Sensors 2024, 24, 3075. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Song, C.; Xie, Y.; Pan, L.; Gan, X.; Huang, G. RMT-YOLOv9s: An Infrared Small Target Detection Method Based on UAV Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar]
- Niu, K.; Wang, C.; Xu, J.; Yang, C.; Zhou, X.; Yang, X. An improved YOLOv5s-Seg detection and segmentation model for the accurate identification of forest fires based on UAV infrared image. Remote Sens. 2023, 15, 4694. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-yolo: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef]
- Pan, L.; Liu, T.; Cheng, J.; Cheng, B.; Cai, Y. AIMED-Net: An enhancing infrared small target detection net in UAVs with multi-layer feature enhancement for edge computing. Remote Sens. 2024, 16, 1776. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, Z. CE-RetinaNet: A channel enhancement method for infrared wildlife detection in UAV images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar]
- Wang, Y.; Lu, Q.; Ren, B. Wind Turbine Crack Inspection Using a Quadrotor with Image Motion Blur Avoided. IEEE Robot. Autom. Lett. 2023, 8, 1069–1076. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhang, M.; Wang, Z.; Song, W.; Zhao, D.; Zhao, H. Efficient Small-Object Detection in Underwater Images Using the Enhanced YOLOv8 Network. Appl. Sci. 2024, 14, 1095. [Google Scholar] [CrossRef]
- Jiao, J.; Tang, Y.M.; Lin, K.Y.; Gao, Y.; Ma, A.J.; Wang, Y.; Zheng, W.S. DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition. IEEE Trans. Multimed. 2023, 25, 8906–8919. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. arXiv 2022, arXiv:2206.02424v3. [Google Scholar]
- Zhang, X.Y.; Hu, G.R.; Li, P.H.; Cao, X.Y.; Zhang, H.; Chen, J.; Zhang, L.L. Lightweight Safflower Recognition Method Based on Improved YOLOv8n. Acta Agric. Eng. 2024, 40, 163–170. [Google Scholar]
- Cao, J.; Bao, W.; Shang, H.; Yuan, M.; Cheng, Q. GCL-YOLO: A GhostConv-based lightweight yolo network for UAV small object detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Liu, L.; Huang, K.; Li, Y.; Zhang, C.; Zhang, S.; Hu, Z. Real-time pedestrian recognition model on edge device using infrared vision system. J. Real-Time Image Process. 2025, 22, 1–11. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4—Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Zhao, X.; Zhang, W.; Zhang, H.; Zheng, C.; Ma, J.; Zhang, Z. ITD-YOLOv8: An infrared target detection model based on YOLOv8 for unmanned aerial vehicles. Drones 2024, 8, 161. [Google Scholar] [CrossRef]
- Liu, S.; Cao, L.; Li, Y. Lightweight pedestrian detection network for UAV remote sensing images based on strideless pooling. Remote Sens. 2024, 16, 2331. [Google Scholar] [CrossRef]
- Zhang, H.; Li, G.; Wan, D.; Wang, Z.; Dong, J.; Lin, S.; Deng, L.; Liu, H. DS-YOLO: A dense small object detection algorithm based on inverted bottleneck and multi-scale fusion network. Biomim. Intell. Robot. 2024, 4, 100190. [Google Scholar] [CrossRef]
- Song, K.; Wen, H.; Ji, Y.; Xue, X.; Huang, L.; Yan, Y.; Meng, Q. SIA: RGB-T salient object detection network with salient-illumination awareness. Opt. Lasers Eng. 2024, 172, 107842. [Google Scholar] [CrossRef]
- Yang, W.; He, Q.; Li, Z. A lightweight multidimensional feature network for small object detection on UAVs. Pattern Anal. Appl. 2025, 28, 29. [Google Scholar] [CrossRef]
- Liu, L.; Li, P.; Wang, D.; Zhu, S. A wind turbine damage detection algorithm designed based on YOLOv8. Appl. Soft Comput. 2024, 154, 111364. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, H.; Huang, Q.; Han, Y.; Zhao, M. DsP-YOLO: An anchor-free network with DsPAN for small object detection of multiscale defects. Expert Syst. Appl. 2024, 241, 122669. [Google Scholar] [CrossRef]
- Aibibu, T.; Lan, J.; Zeng, Y.; Lu, W.; Gu, N. Feature-enhanced attention and dual-gelan net (feadg-net) for uav infrared small object detection in traffic surveillance. Drones 2024, 8, 304. [Google Scholar] [CrossRef]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A High-Altitude Infrared Thermal Dataset for Unmanned Aerial Vehicle-Based Object Detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Li, Z.; Yang, J.; Ma, X.; Chen, J.; Tang, X. Phsi-rtdetr: A lightweight infrared small target detection algorithm based on UAV aerial photography. Drones 2024, 8, 240. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-based method for unmanned aerial vehicle infrared vehicle target detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Related Configurations |
|---|---|
| CPU | 12 vCPU Intel(R) Xeon(R) Silver 4214R |
| GPU | RTX 3080 Ti (12 GB) |
| RAM | 30 GB |
| Language | Python 3.8 (Ubuntu 20.04) |
| Framework | PyTorch 1.11.0 |
| CUDA Version | CUDA 11.3 |
| epoch | 280 |
| Model | P | R | mAP50 | mAP50–95 | GFLOPS | Parameters/ |
|---|---|---|---|---|---|---|
| * | 0.837 | 0.774 | 0.818 | 0.525 | 12.1 | 3.165578 |
| *+SE | 0.807 | 0.756 | 0.803 | 0.527 | 12.3 | 3.987487 |
| *+GAM | 0.810 | 0.734 | 0.801 | 0.525 | 13.7 | 5.628703 |
| *+iRMB | 0.811 | 0.726 | 0.803 | 0.512 | 20.1 | 4.254495 |
| *+ECA | 0.881 | 0.734 | 0.813 | 0.523 | 12.3 | 3.987490 |
| *+CA | 0.801 | 0.719 | 0.810 | 0.501 | 13.3 | 4.037180 |
| *+MSDA | 0.837 | 0.774 | 0.825 | 0.546 | 12.2 | 3.954719 |
| Model | P | R | mAP50 | mAP50–95 |
|---|---|---|---|---|
| Shuffle+MSDA+UIB+GhostConv(*) | 0.837 | 0.774 | 0.825 | 0.546 |
| *+WIOU | 0.861 | 0.762 | 0.833 | 0.551 |
| *+FOCAL-GIOU | 0.899 | 0.751 | 0.817 | 0.527 |
| *+InnerMPD | 0.858 | 0.765 | 0.827 | 0.534 |
| *+MPD | 0.853 | 0.778 | 0.84 | 0.538 |
| Experimental ID | ShufflenetV2 | MSDA | C2f_UIB | GhostConv | MPDIoU | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ✓ | |||||
| 3 | ✓ | ✓ | ||||
| 4 | ✓ | ✓ | ✓ | |||
| 5 | ✓ | ✓ | ✓ | ✓ | ||
| 6 | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Experimental ID | P | R | mAP50 | GFLOPS | Parameters/ | F1 |
| 1 | 0.820 | 0.784 | 0.811 | 28.4 | 11.127519 | 81 |
| 2 | 0.866 | 0.749 | 0.810 | 15.9 | 5.755798 | 77 |
| 3 | 0.877 | 0.751 | 0.813 | 16.0 | 5.945807 | 79 |
| 4 | 0.816 | 0.769 | 0.817 | 12.7 | 3.185590 | 79 |
| 5 | 0.837 | 0.774 | 0.825 | 12.2 | 3.954719 | 81 |
| 6 | 0.853 | 0.778 | 0.840 | 12.2 | 3.954719 | 82 |
| Model | Parameters/M | Size | GFLOPS | mAP50 | F1 |
|---|---|---|---|---|---|
| Faster R-CNN | 41.2 | 116.7 | 156.3 | 70.21 | 73 |
| YOLOv5n | 2.5 | 6.6 | 7.1 | 75.0 | 71 |
| YOLOv5s | 9.1 | 18.5 | 23.8 | 80.3 | 75 |
| YOLOv6n | 4.2 | 8.7 | 11.8 | 73.5 | 70 |
| YOLOv6s | 16.2 | 32.9 | 44.0 | 75.6 | 71 |
| YOLOv8n | 3.0 | 6.7 | 8.1 | 77.1 | 77 |
| YOLOv8s | 11.1 | 22.5 | 28.4 | 81.1 | 81 |
| Ours | 3.9 | 8.2 | 12.2 | 84.0 | 82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Zhu, X. YOLO-SMUG: An Efficient and Lightweight Infrared Object Detection Model for Unmanned Aerial Vehicles. Drones 2025, 9, 245. https://doi.org/10.3390/drones9040245
Luo X, Zhu X. YOLO-SMUG: An Efficient and Lightweight Infrared Object Detection Model for Unmanned Aerial Vehicles. Drones. 2025; 9(4):245. https://doi.org/10.3390/drones9040245
Chicago/Turabian StyleLuo, Xinzhe, and Xiaogang Zhu. 2025. "YOLO-SMUG: An Efficient and Lightweight Infrared Object Detection Model for Unmanned Aerial Vehicles" Drones 9, no. 4: 245. https://doi.org/10.3390/drones9040245
APA StyleLuo, X., & Zhu, X. (2025). YOLO-SMUG: An Efficient and Lightweight Infrared Object Detection Model for Unmanned Aerial Vehicles. Drones, 9(4), 245. https://doi.org/10.3390/drones9040245