


Joint Optimization of Task Completion Time and Energy Consumption in UAV-Enabled Mobile Edge Computing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We present a novel online optimization framework to help users complete tasks quickly and provide them with more durable services. The framework integrates Lyapunov optimization and Mixed Integer Nonlinear Programming (MINLP), which dynamically adapts to real-time task arrivals while jointly optimizing task response time (by minimizing makespan) and energy consumption. Through Lyapunov optimization, we ensure a uniform energy distribution across the UAV, thereby effectively mitigating energy consumption fluctuations caused by bursty tasks while responding in a timely manner in the absence of a priori knowledge of the data.
- We introduce Lyapunov virtual energy queues, decompose the problem into a real-time optimization problem (PROP) for each time slot via Lyapunov drift, and design the reinforcement learning-based algorithm LyraRD. LyraRD uniquely combines Lyapunov-induced stability constraints with adaptive decision making to reduce the computational complexity to millisecond response times.
- We investigate the performance of our method under different parameter settings. With extensive experiments, we demonstrate that our method performs better than the benchmarks.
2. Related Work
2.1. Real-Time Task Arrival
2.2. UAV Energy Management
2.3. Differences of Our Work
3. System Model and Problem Formulation
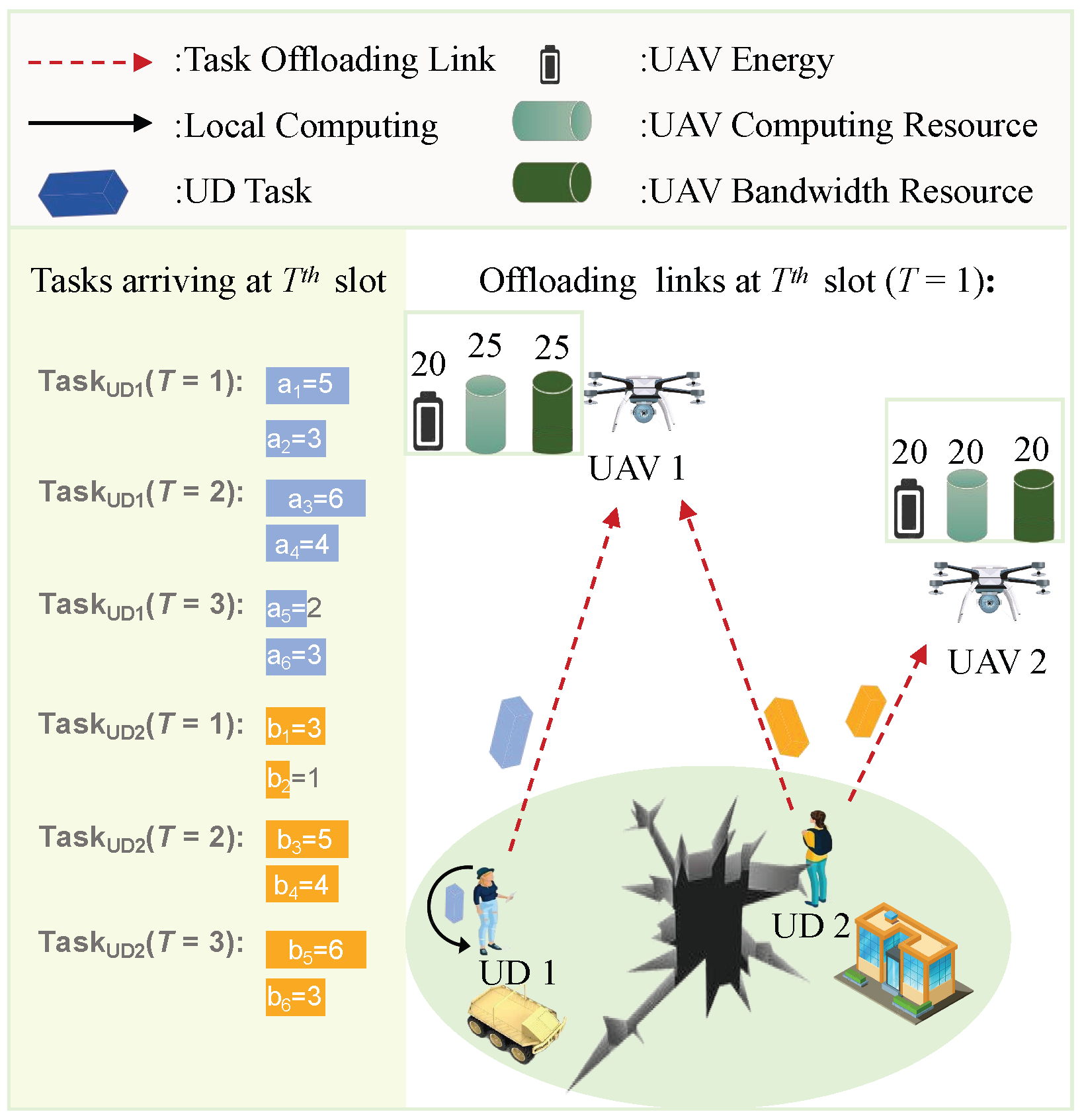
3.1. System Overview
3.2. Communication Model
3.3. Computation Model
3.4. Cost Model
3.5. Data Queue Model
3.6. Problem Formulation
4. Lyapunov-Based Decoupling of the Multi-Slot MINLP
5. Joint Optimization Algorithm
5.1. Optimal Resource Allocation Algorithm
| Algorithm 1: Algorithm for optimal resource allocation of (). |
 |
5.2. LyraRD Algorithm Description
| Algorithm 2: The online LyraRD algorithm for solving (P4’). |
 |
6. Simulation Results
6.1. Platforms and Tasks Data
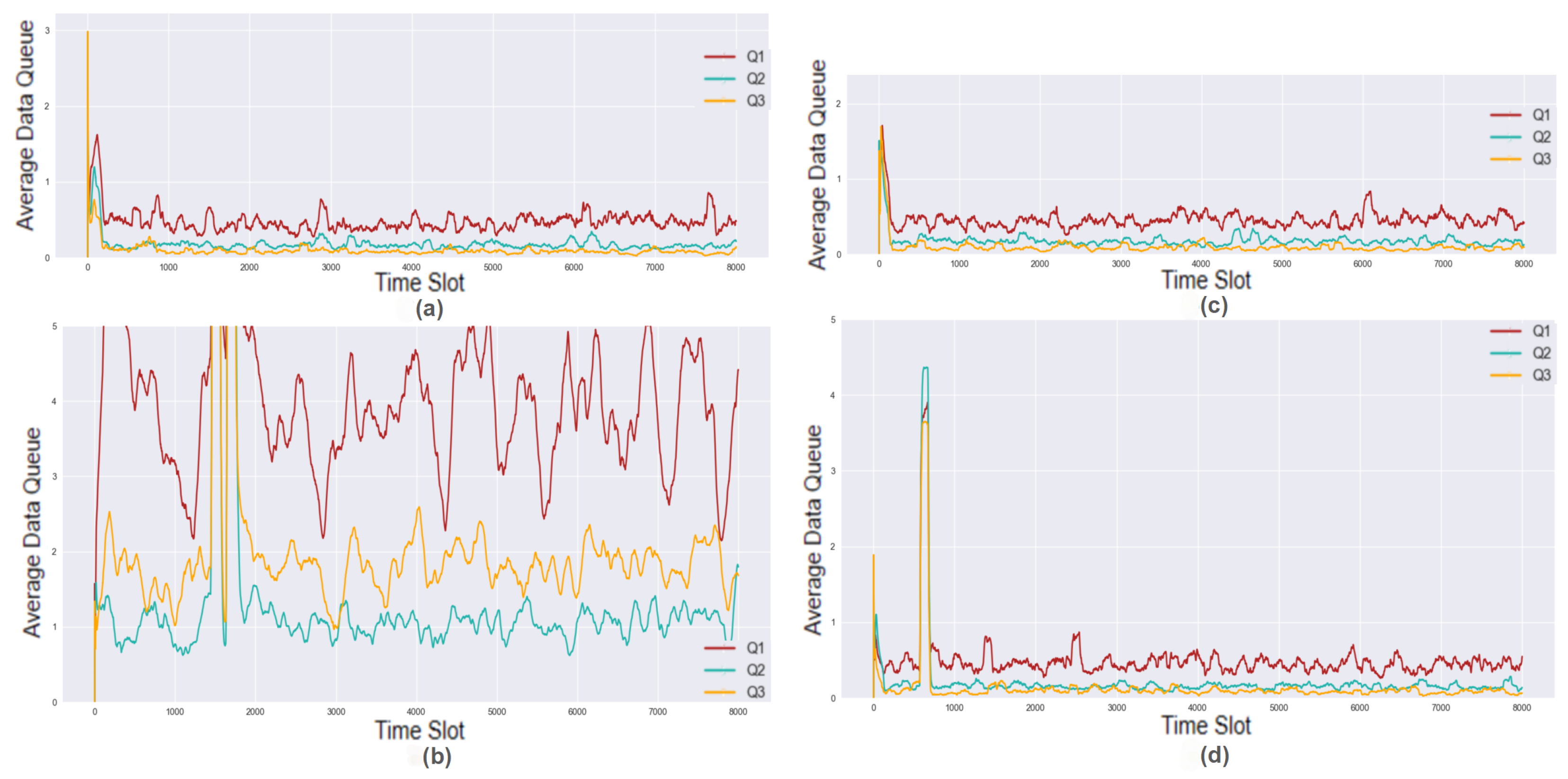
6.2. Overall Performance Analysis
6.3. Baseline Methods
- Average latency of tasks (): The optimization goal is the linear sum of the average task completion delay.
- Equal resource allocation (): The UAV allocates computing and communication resources equally.
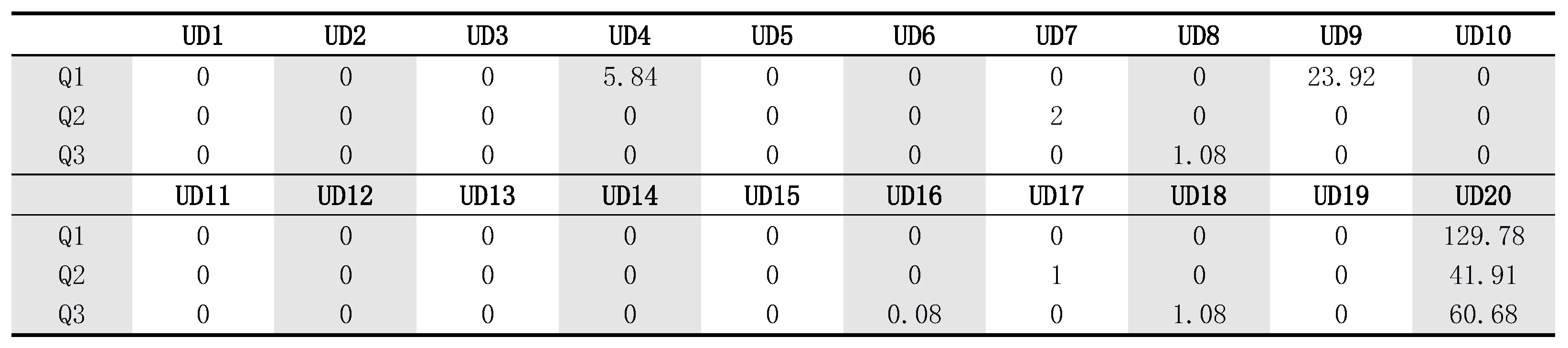
6.4. Evaluation Result
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of the First Zonklar Equation
Appendix B. Parameter Settings

References
- Dash, S.; Ahmad, M.; Iqbal, T. Mobile cloud computing: A green perspective. In Intelligent Systems: Proceedings of ICMIB 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 523–533. [Google Scholar]
- Xu, Y.; Zhang, T.; Liu, Y.; Yang, D.; Xiao, L.; Tao, M. UAV-assisted MEC networks with aerial and ground cooperation. IEEE Trans. Wirel. Commun. 2021, 20, 7712–7727. [Google Scholar] [CrossRef]
- Ranaweera, P.; Jurcut, A.; Liyanage, M. MEC-enabled 5G use cases: A survey on security vulnerabilities and countermeasures. ACM Comput. Surv. (CSUR) 2021, 54, 186. [Google Scholar]
- Zhao, R.; Fan, C.; Ou, J.; Fan, D.; Ou, J.; Tang, M. Impact of direct links on intelligent reflect surface-aided MEC networks. Phys. Commun. 2022, 55, 101905. [Google Scholar]
- Dai, P.; Song, F.; Liu, K.; Dai, Y.; Zhou, P.; Guo, S. Edge intelligence for adaptive multimedia streaming in heterogeneous internet of vehicles. IEEE Trans. Mob. Comput. 2021, 22, 1464–1478. [Google Scholar]
- Khan, M.A.; Baccour, E.; Chkirbene, Z.; Erbad, A.; Hamila, R.; Hamdi, M.; Gabbouj, M. A survey on mobile edge computing for video streaming: Opportunities and challenges. IEEE Access 2022, 10, 120514–120550. [Google Scholar]
- Yang, C.; Xu, X.; Zhou, X.; Qi, L. Deep Q network–driven task offloading for efficient multimedia data analysis in edge computing–assisted IoV. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 124. [Google Scholar] [CrossRef]
- Pervez, F.; Sultana, A.; Yang, C.; Zhao, L. Energy and latency efficient joint communication and computation optimization in a multi-UAV assisted MEC network. IEEE Trans. Wirel. Commun. 2023, 23, 1728–1741. [Google Scholar]
- Du, J.; Wang, J.; Sun, A.; Qu, J.; Zhang, J.; Wu, C.; Niyato, D. Joint optimization in blockchain and mec enabled space-air-ground integrated networks. IEEE Internet Things J. 2024, 11, 31862–31877. [Google Scholar]
- Zhan, C.; Hu, H.; Sui, X.; Liu, Z.; Niyato, D. Completion time and energy optimization in the UAV-enabled mobile-edge computing system. IEEE Internet Things J. 2020, 7, 7808–7822. [Google Scholar] [CrossRef]
- Zeng, Y.; Chen, S.; Cui, Y.; Yang, J.; Fu, Y. Joint resource allocation and trajectory optimization in UAV-enabled wirelessly powered MEC for large area. IEEE Internet Things J. 2023, 10, 15705–15722. [Google Scholar] [CrossRef]
- Jiang, F.; Wang, K.; Dong, L.; Pan, C.; Xu, W.; Yang, K. AI driven heterogeneous MEC system with UAV assistance for dynamic environment: Challenges and solutions. IEEE Netw. 2020, 35, 400–408. [Google Scholar] [CrossRef]
- Yang, Z.; Bi, S.; Zhang, Y.J.A. Dynamic offloading and trajectory control for UAV-enabled mobile edge computing system with energy harvesting devices. IEEE Trans. Wirel. Commun. 2022, 21, 10515–10528. [Google Scholar] [CrossRef]
- Wan, S.; Lu, J.; Fan, P.; Letaief, K.B. Toward big data processing in IoT: Path planning and resource management of UAV base stations in mobile-edge computing system. IEEE Internet Things J. 2019, 7, 5995–6009. [Google Scholar] [CrossRef]
- Yang, Z.; Bi, S.; Zhang, Y.J.A. Online trajectory and resource optimization for stochastic UAV-enabled MEC systems. IEEE Trans. Wirel. Commun. 2022, 21, 5629–5643. [Google Scholar] [CrossRef]
- Yan, P.; Cao, Z.; Duan, W.; Li, B.; Zou, Y.; Li, C.; Wang, J. Securing UAV-Aided NOMA Wireless Powered Communications via Artificial Noise. IEEE Trans. Wirel. Commun. 2025. [Google Scholar] [CrossRef]
- AL-Bakhrani, A.A.; Li, M.; Obaidat, M.S.; Amran, G.A. MOALF-UAV-MEC: Adaptive Multi-Objective Optimization for UAV-Assisted Mobile Edge Computing in Dynamic IoT Environments. IEEE Internet Things J. 2025, 1. [Google Scholar] [CrossRef]
- Sheng, Z.; Hu, H.; Nasir, A.A.; Fang, Y.; da Costa, D.B. Online Trajectory Planning and Resource Allocation of UAV-Enabled MEC Networks Empowered by RIS. IEEE Trans. Green Commun. Netw. 2024, 1. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.Y.; Min, L.; Tang, C.; Zhang, H.Y.; Wang, Y.H.; Cai, P. Task Offloading and Trajectory Control for UAV-Assisted Mobile Edge Computing Using Deep Reinforcement Learning. IEEE Access 2021, 9, 53708–53719. [Google Scholar] [CrossRef]
- Yuan, H.; Wang, M.; Bi, J.; Shi, S.; Yang, J.; Zhang, J.; Zhou, M.; Buyya, R. Cost-Efficient Task Offloading in Mobile Edge Computing With Layered Unmanned Aerial Vehicles. IEEE Internet Things J. 2024, 11, 30496–30509. [Google Scholar] [CrossRef]
- Michailidis, E.T.; Volakaki, M.G.; Miridakis, N.I.; Vouyioukas, D. Optimization of Secure Computation Efficiency in UAV-Enabled RIS-Assisted MEC-IoT Networks With Aerial and Ground Eavesdroppers. IEEE Trans. Commun. 2024, 72, 3994–4009. [Google Scholar] [CrossRef]
- Lakew, D.S.; Tran, A.T.; Dao, N.N.; Cho, S. Intelligent Self-Optimization for Task Offloading in LEO-MEC-Assisted Energy-Harvesting-UAV Systems. IEEE Trans. Netw. Sci. Eng. 2024, 11, 5135–5148. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L.; Zhu, K.; Dai, P. Lyapunov-Based Joint Flight Trajectory and Computation Offloading Optimization for UAV-Assisted Vehicular Networks. IEEE Internet Things J. 2024, 11, 22243–22256. [Google Scholar] [CrossRef]
- Qin, P.; Wu, X.; Fu, M.; Ding, R.; Fu, Y. Latency Minimization Resource Allocation and Trajectory Optimization for UAV-Assisted Cache-Computing Network with Energy Recharging. IEEE Trans. Commun. 2025, 1. [Google Scholar] [CrossRef]
- Li, J.; Sun, G.; Wu, Q.; Niyato, D.; Kang, J.; Jamalipour, A.; Leung, V.C. Collaborative ground-space communications via evolutionary multi-objective deep reinforcement learning. IEEE J. Sel. Areas Commun. 2024, 42, 3395–3411. [Google Scholar]
- Consul, P.; Budhiraja, I.; Garg, D.; Garg, S.; Kaddoum, G.; Hassan, M.M. SFL-TUM: Energy efficient SFRL method for large scale AI model’s task offloading in UAV-assisted MEC networks. Veh. Commun. 2024, 48, 100790. [Google Scholar] [CrossRef]
- Wu, X.; Zhu, Q.; Chen, W.N.; Lin, Q.; Li, J.; Coello, C.A.C. Evolutionary reinforcement learning with action sequence search for imperfect information games. Inf. Sci. 2024, 676, 120804. [Google Scholar]
- Qu, Y.; Dai, H.; Wang, H.; Dong, C.; Wu, F.; Guo, S.; Wu, Q. Service provisioning for UAV-enabled mobile edge computing. IEEE J. Sel. Areas Commun. 2021, 39, 3287–3305. [Google Scholar]
- Jiang, H.; Dai, X.; Xiao, Z.; Iyengar, A. Joint task offloading and resource allocation for energy-constrained mobile edge computing. IEEE Trans. Mob. Comput. 2022, 22, 4000–4015. [Google Scholar] [CrossRef]
- He, L.; Sun, G.; Sun, Z.; Wang, P.; Li, J.; Liang, S.; Niyato, D. An Online Joint Optimization Approach for QoE Maximization in UAV-Enabled Mobile Edge Computing. arXiv 2024, arXiv:2404.02166. [Google Scholar]
- Sun, G.; Zheng, X.; Sun, Z.; Wu, Q.; Li, J.; Liu, Y.; Leung, V.C. UAV-enabled secure communications via collaborative beamforming with imperfect eavesdropper information. IEEE Trans. Mob. Comput. 2023, 23, 3291–3308. [Google Scholar] [CrossRef]
- Ndikumana, A.; Tran, N.; Ho, T.; Han, Z.; Saad, W.; Niyato, D.; Hong, C. Joint Communication, Computation, Caching, and Control in Big Data Multi-access Edge Computing. IEEE Trans. Mob. Comput. 2018, 19, 1359–1374. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, J.; Xiong, J.; Zhou, L.; Wei, J. Energy-Efficient Multi-UAV-Enabled Multiaccess Edge Computing Incorporating NOMA. IEEE Internet Things J. 2020, 7, 5613–5627. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, J.; Wu, Y.; Huang, J.; Shen, X. QoE-Aware Decentralized Task Offloading and Resource Allocation for End-Edge-Cloud Systems: A Game-Theoretical Approach. IEEE Trans. Mob. Comput. 2024, 23, 769–784. [Google Scholar] [CrossRef]
- Ding, Y.; Li, K.; Liu, C.; Li, K. A Potential Game Theoretic Approach to Computation Offloading Strategy Optimization in End-Edge-Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 1503–1519. [Google Scholar] [CrossRef]
- Xu, B.; Kuang, Z.; Gao, J.; Zhao, L.; Wu, C. Joint offloading decision and trajectory design for UAV-enabled edge computing with task dependency. IEEE Trans. Wirel. Commun. 2022, 22, 5043–5055. [Google Scholar] [CrossRef]
- Neely, M. Stochastic Network Optimization with Application to Communication and Queueing Systems; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press eBooks; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Marsland, S. Machine Learning: An Algorithmic Perspective; Chapman and Hall/CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Bi, S.; Huang, L.; Wang, H.; Zhang, Y.J.A. Lyapunov-guided deep reinforcement learning for stable online computation offloading in mobile-edge computing networks. IEEE Trans. Wirel. Commun. 2021, 20, 7519–7537. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Nallanathan, A. Deep Reinforcement Learning Based Dynamic Trajectory Control for UAV-assisted Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022, 21, 3536–3550. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Chen, T.; Ren, B.; Li, R.; Yuan, H. Joint Optimization of Task Completion Time and Energy Consumption in UAV-Enabled Mobile Edge Computing. Drones 2025, 9, 274. https://doi.org/10.3390/drones9040274
Zhang H, Chen T, Ren B, Li R, Yuan H. Joint Optimization of Task Completion Time and Energy Consumption in UAV-Enabled Mobile Edge Computing. Drones. 2025; 9(4):274. https://doi.org/10.3390/drones9040274
Chicago/Turabian StyleZhang, Hanwen, Tao Chen, Bangbang Ren, Ruozhe Li, and Hao Yuan. 2025. "Joint Optimization of Task Completion Time and Energy Consumption in UAV-Enabled Mobile Edge Computing" Drones 9, no. 4: 274. https://doi.org/10.3390/drones9040274
APA StyleZhang, H., Chen, T., Ren, B., Li, R., & Yuan, H. (2025). Joint Optimization of Task Completion Time and Energy Consumption in UAV-Enabled Mobile Edge Computing. Drones, 9(4), 274. https://doi.org/10.3390/drones9040274