
Robust Tracking Control of Underactuated UAVs Based on Zero-Sum Differential Games


Abstract
1. Introduction
- (1)
- Compared with the method in [19], which requires a known prior disturbance bound, our approach considers the coupling of nonlinear uncertainty and time-varying external disturbance as adversarial players by formulating the UAV robust optimal tracking control problem as two zero-sum differential games.
- (2)
- A data-driven IRL algorithm is presented to approximately achieve the Nash equilibrium strategies and the value functions without using the knowledge of the UAV dynamics. We develop an improved actor-critic-disturbance NN weights update law by using the recursive Ridge regression with the forgetting factor () estimator, which is more computationally efficient than the least-squares (LS) method adopted in [11,27,28,29,30,31]. The results also show that the weight parameter estimation converges exponentially to a small neighborhood of the true value.
- (3)
- In order to generate the learning dataset for the off-policy IRL algorithm, we introduce a novel behavior policy that is different from the conventional one used in [19,23,27,28]. Instead of using an initially admissible exploratory control law, the selected behavior policy exploits a stabilizing linear state feedback controller for the nominal position and attitude tracking error subsystems, which is generally easier to design and implement than the conventional policy
2. Preliminaries
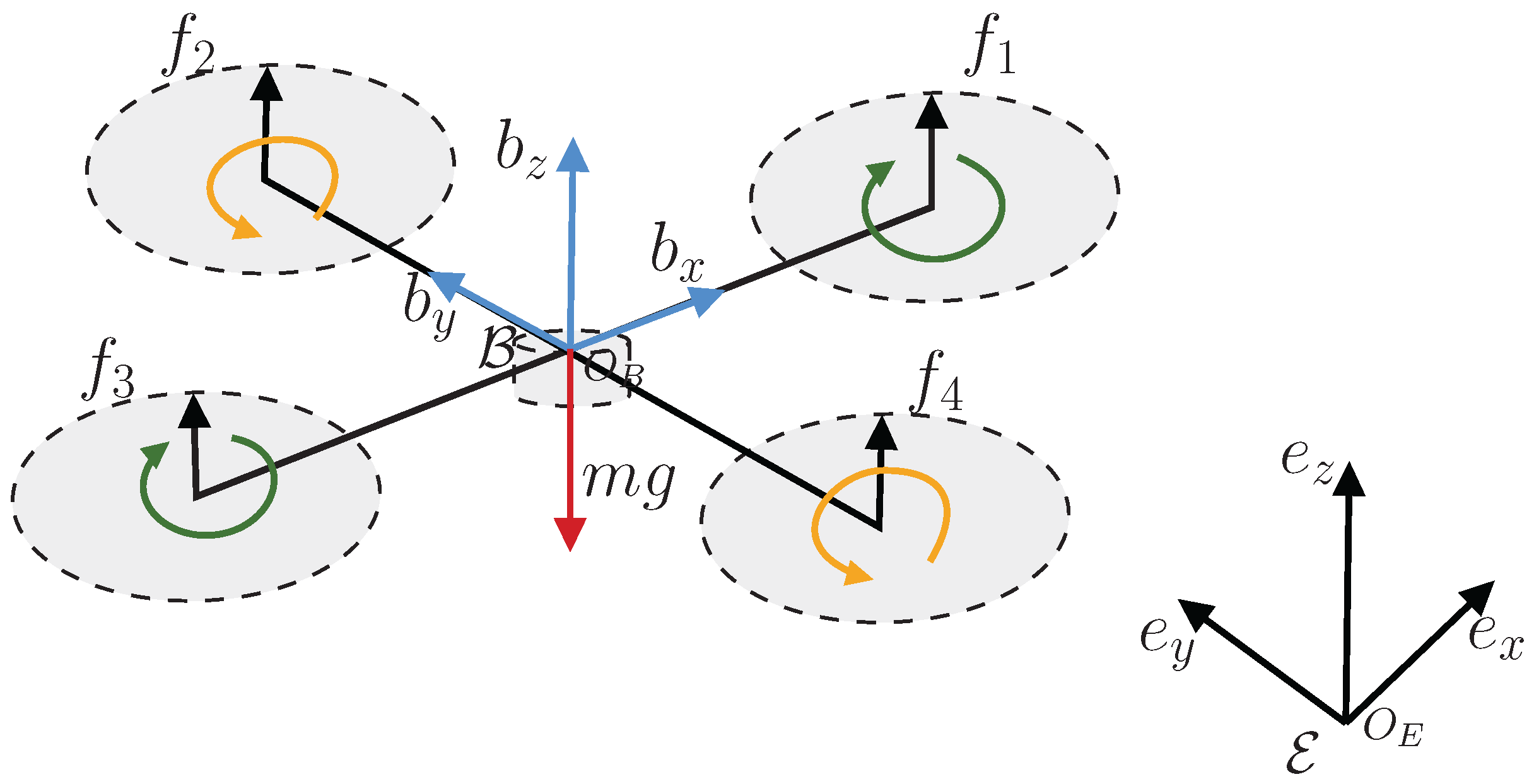
2.1. The UAV Dynamics
2.2. Problem Formulation
3. Game-Based Robust Optimal Control Law Design and Stability Analysis
3.1. Zero-Sum Differential Games
3.2. Stability and Nash Equilibria for Zero-Sum Differential Games
4. -Based IRL Approach
4.1. A Framework of -Based IRL for Zero-Sum Differential Games
- (1)
- The activation functions of actor-critic-disturbance NNs and their derivatives are bounded, i.e., , , , , , and , where , , , , , and are positive constants.
- (2)
- The ideal actor-critic-disturbance NN weights satisfy , , and , where , and are positive constants.
- (3)
- and , where and are positive constants.
| Algorithm 1: -based IRL for zero-sum differential games |
 |
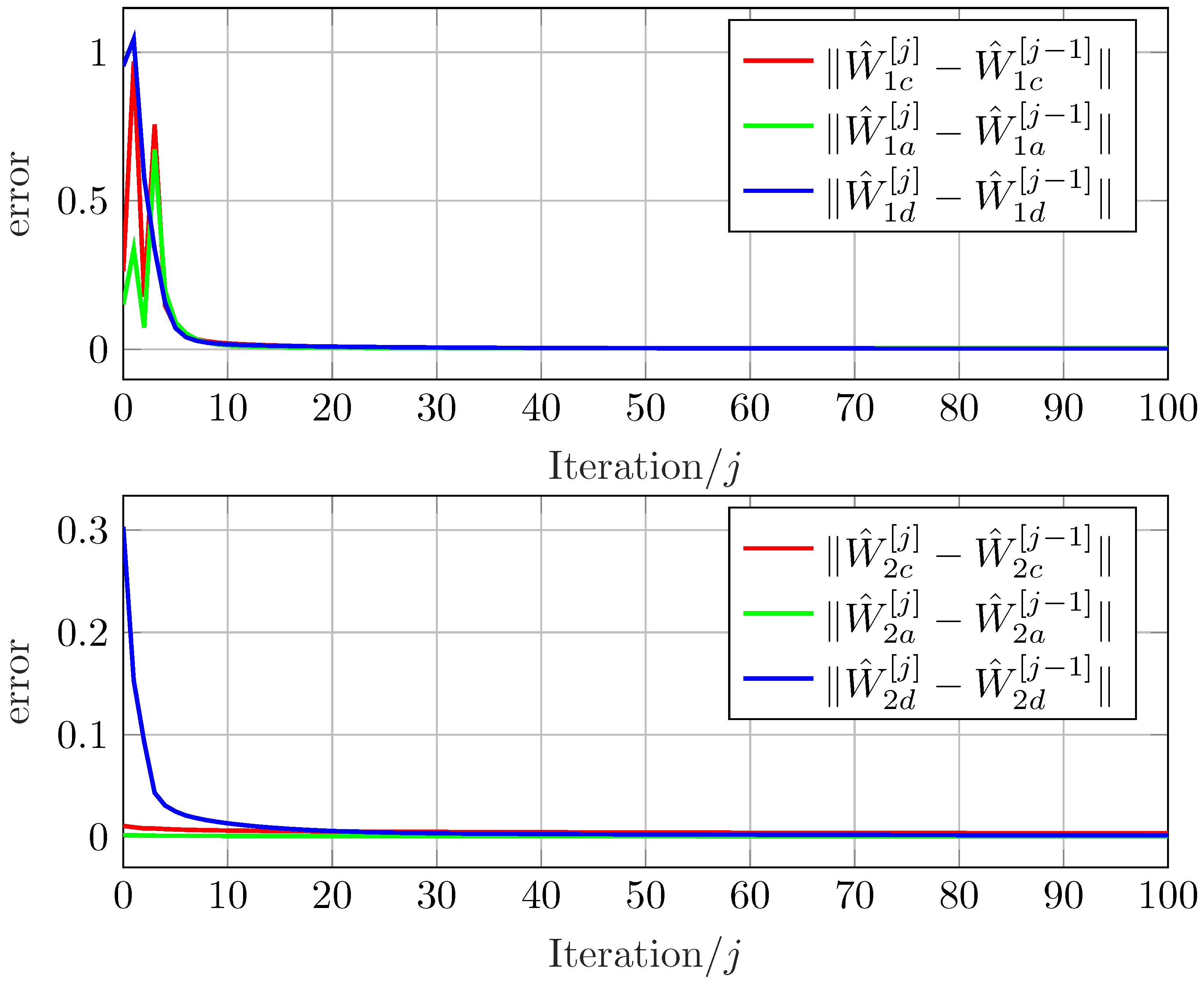
4.2. Convergence and Stability Analysis
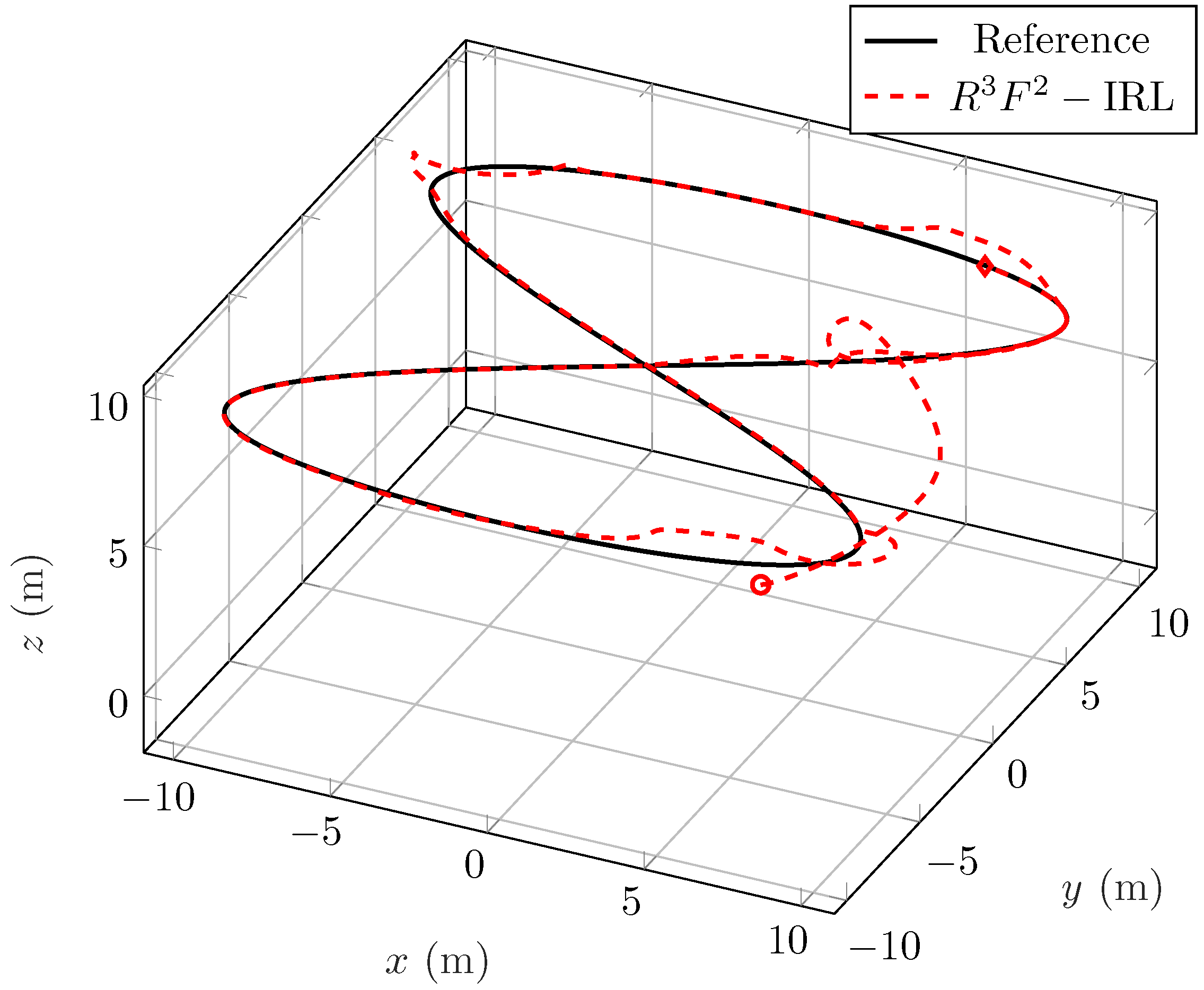
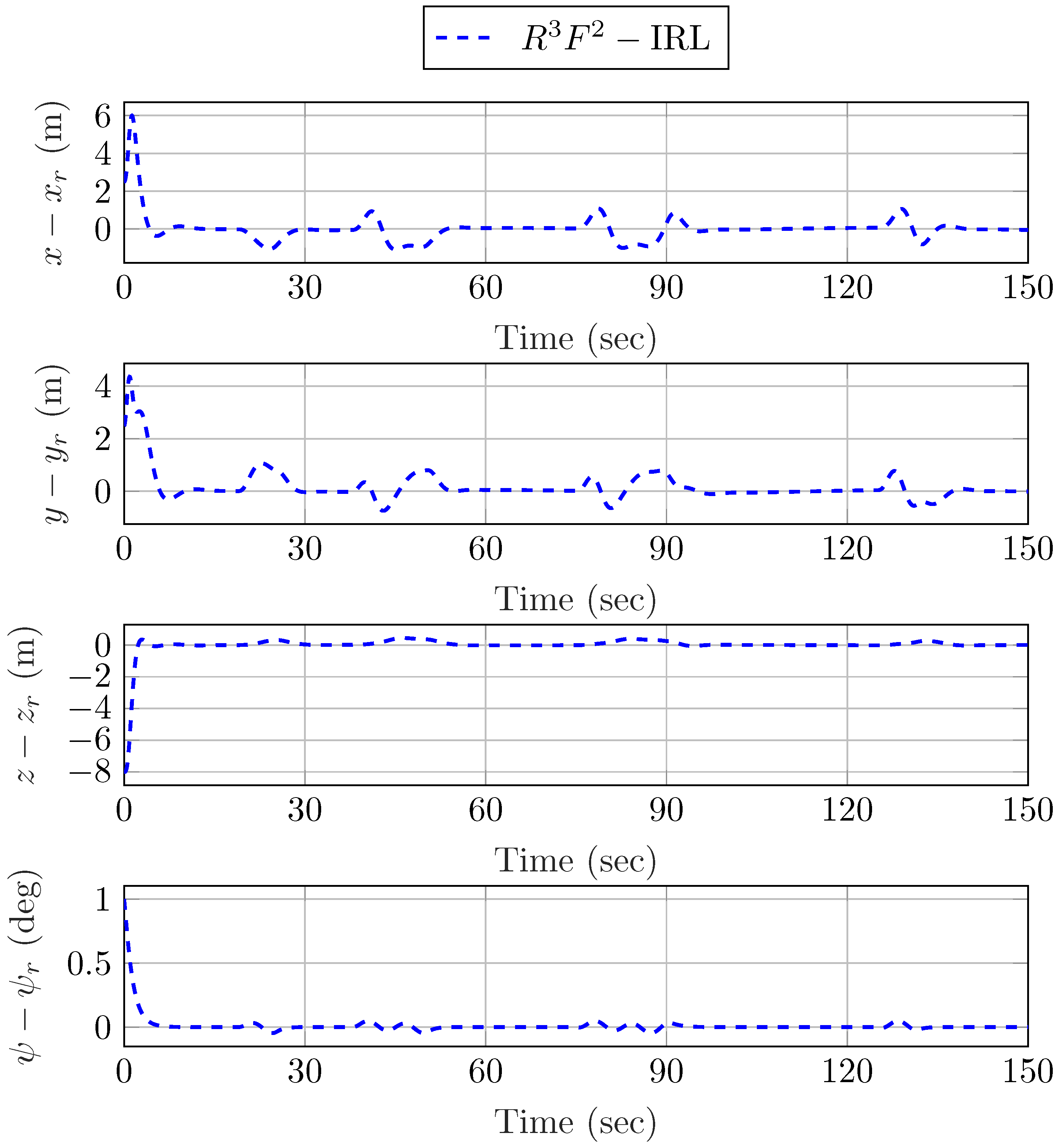
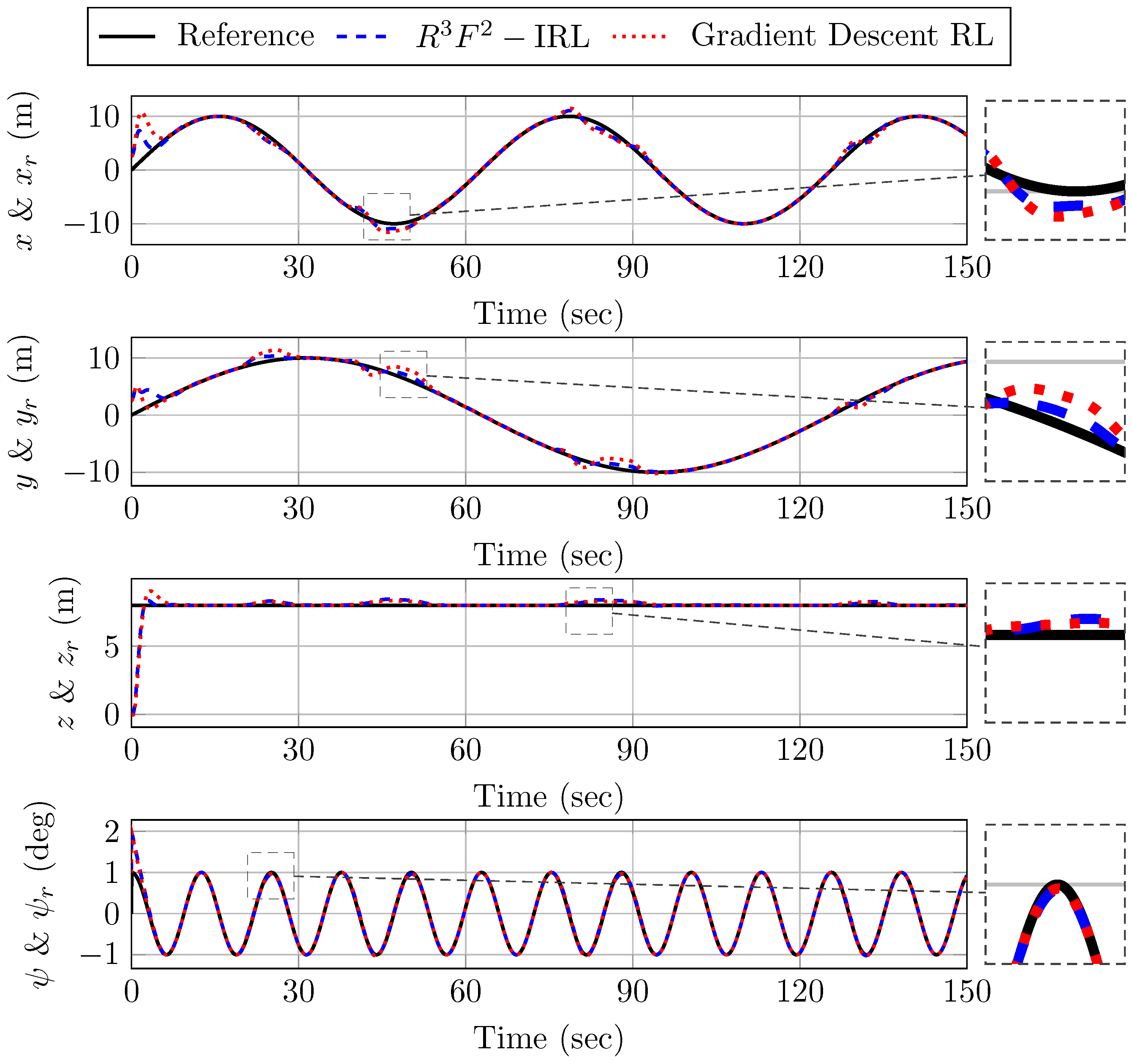
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Wen, X.; Wang, Z.; Gao, Y.; Li, H.; Wang, Q.; Yang, T.; Lu, H.; Cao, Y.; Xu, C.; et al. Swarm of micro flying robots in the wild. Sci. Robot. 2022, 7, eabm5954. [Google Scholar] [CrossRef]
- Hua, H.; Fang, Y. A novel reinforcement learning-based robust control strategy for a quadrotor. IEEE Trans. Ind. Electron. 2022, 70, 2812–2821. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, Q.; Ren, B. Wind turbine crack inspection using a quadrotor with image motion blur avoided. IEEE Robot. Autom. Lett. 2023, 8, 1069–1076. [Google Scholar] [CrossRef]
- Ma, Q.; Jin, P.; Lewis, F.L. Guaranteed cost attitude tracking control for uncertain quadrotor unmanned aerial vehicle under safety constraints. IEEE/CAA J. Autom. Sin. 2024, 11, 1447–1457. [Google Scholar] [CrossRef]
- Wei, Q.; Yang, Z.; Su, H.; Wang, L. Online Adaptive Dynamic Programming for Optimal Self-Learning Control of VTOL Aircraft Systems With Disturbances. IEEE Trans. Automat. Sci. Eng. 2024, 21, 343–352. [Google Scholar] [CrossRef]
- Tonan, M.; Bottin, M.; Doria, A.; Rosati, G. Analysis and design of a 3-DOF spatial underactuated differentially flat robot. In Proceedings of the 2025 11th International Conference on Mechatronics and Robotics Engineering (ICMRE), Milan, Italy, 27–29 February 2024; IEEE: New York, NY, USA, 2025; pp. 202–207. [Google Scholar]
- Wang, L.; Su, J. Robust disturbance rejection control for attitude tracking of an aircraft. IEEE Trans. Control Syst. Technol. 2015, 23, 2361–2368. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, M.; Jiang, C. Robust tracking control of uncertain mimo nonlinear systems with application to UAVs. IEEE/CAA J. Autom. Sin. 2015, 2, 25–32. [Google Scholar] [CrossRef]
- Dydek, Z.T.; Annaswamy, A.M.; Lavretsky, E. Adaptive control of quadrotor UAVs: A design trade study with flight evaluations. IEEE Trans. Control Syst. Technol. 2012, 21, 1400–1406. [Google Scholar] [CrossRef]
- Sun, S.; Romero, A.; Foehn, P.; Kaufmann, E.; Scaramuzza, D. A comparative study of nonlinear MPC and differential-flatness-based control for quadrotor agile flight. IEEE Trans. Robot. 2022, 38, 3357–3373. [Google Scholar] [CrossRef]
- Jiao, Q.; Modares, H.; Xu, S.; Lewis, F.L.; Vamvoudakis, K.G. Multi-agent zero-sum differential graphical games for disturbance rejection in distributed control. Automatica 2016, 69, 24–34. [Google Scholar] [CrossRef]
- Smolyanskiy, N.; Kamenev, A.; Smith, J.; Birchfield, S. Toward low-flying autonomous mav trail navigation using deep neural networks for environmental awareness. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 4241–4247. [Google Scholar]
- Wang, Y.; Sun, J.; He, H.; Sun, C. Deterministic policy gradient with integral compensator for robust quadrotor control. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 50, 3713–3725. [Google Scholar] [CrossRef]
- Petrlík, M.; Báča, T.; Heřt, D.; Vrba, M.; Krajník, T.; Saska, M. A robust uav system for operations in a constrained environment. IEEE Robot. Autom. Lett. 2020, 5, 2169–2176. [Google Scholar] [CrossRef]
- Guo, Y.; Sun, Q.; Wang, Y.; Pan, Q. Differential graphical game-based multi-agent tracking control using integral reinforcement learning. IET Control Theory Appl. 2024, 18, 2766–2776. [Google Scholar] [CrossRef]
- Rubí, B.; Morcego, B.; Pérez, R. A deep reinforcement learning approach for path following on a quadrotor. In Proceedings of the 2020 European Control Conference (ECC), Saint Petersburg, Russia, 12–15 May 2020; IEEE: New York, NY, USA, 2020; pp. 1092–1098. [Google Scholar]
- Ma, H.-J.; Xu, L.-X.; Yang, G.-H. Multiple environment integral reinforcement learning-based fault-tolerant control for affine nonlinear systems. IEEE Trans. Cybern. 2021, 51, 1913–1928. [Google Scholar] [CrossRef]
- Greatwood, C.; Richards, A.G. Reinforcement learning and model predictive control for robust embedded quadrotor guidance and control. Auton. Robot. 2019, 43, 1681–1693. [Google Scholar] [CrossRef]
- Mu, C.; Zhang, Y. Learning-based robust tracking control of quadrotor with time-varying and coupling uncertainties. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 259–273. [Google Scholar] [CrossRef]
- Vrabie, D.; Pastravanu, O.; Abu-Khalaf, M.; Lewis, F.L. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica 2009, 45, 477–484. [Google Scholar] [CrossRef]
- Wang, D.; He, H.; Mu, C.; Liu, D. Intelligent critic control with disturbance attenuation for affine dynamics including an application to a microgrid system. IEEE Trans. Ind. Electron. 2017, 64, 4935–4944. [Google Scholar] [CrossRef]
- Zhao, B.; Shi, G.; Wang, D. Asymptotically stable critic designs for approximate optimal stabilization of nonlinear systems subject to mismatched external disturbances. Neurocomputing 2020, 396, 201–208. [Google Scholar] [CrossRef]
- Mohammadi, M.; Arefi, M.M.; Setoodeh, P.; Kaynak, O. Optimal tracking control based on reinforcement learning value iteration algorithm for time-delayed nonlinear systems with external disturbances and input constraints. Inform. Sci. 2021, 554, 84–98. [Google Scholar] [CrossRef]
- Yang, X.; Gao, Z.; Zhang, J. Event-driven H∞ control with critic learning for nonlinear systems. Neural Netw. 2020, 132, 30–42. [Google Scholar] [CrossRef]
- Song, R.; Lewis, F.L.; Wei, Q.; Zhang, H. Off-policy actor-critic structure for optimal control of unknown systems with disturbances. IEEE Trans. Cybern. 2015, 46, 1041–1050. [Google Scholar] [CrossRef]
- Yang, X.; Liu, D.; Luo, B.; Li, C. Data-based robust adaptive control for a class of unknown nonlinear constrained-input systems via integral reinforcement learning. Inform. Sci. 2016, 369, 731–747. [Google Scholar] [CrossRef]
- Modares, H.; Lewis, F.L.; Jiang, Z. H∞ tracking control of completely unknown continuous-time systems via off-policy reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2550–2562. [Google Scholar] [CrossRef] [PubMed]
- Luo, B.; Wu, H.; Huang, T. Off-policy reinforcement learning for H∞ control design. IEEE Trans. Cybern. 2015, 45, 65–76. [Google Scholar] [CrossRef] [PubMed]
- Cui, X.; Zhang, H.; Luo, Y.; Jiang, H. Adaptive dynamic programming for tracking design of uncertain nonlinear systems with disturbances and input constraints. Int. J. Adapt. Control 2017, 31, 1567–1583. [Google Scholar] [CrossRef]
- Xiao, G.; Zhang, H.; Zhang, K.; Wen, Y. Value iteration based integral reinforcement learning approach for H∞ controller design of continuous-time nonlinear systems. Neurocomputing 2018, 285, 51–59. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, H.; Lewis, F.L. Robust formation control for cooperative underactuated quadrotors via reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4577–4587. [Google Scholar] [CrossRef]
- Zhao, B.; Xian, B.; Zhang, Y.; Zhang, X. Nonlinear robust adaptive tracking control of a quadrotor UAV via immersion and invariance methodology. IEEE Trans. Ind. Electron. 2015, 62, 2891–2902. [Google Scholar] [CrossRef]
- Lee, T.; Leok, M.; McClamroch, N.H. Geometric tracking control of a quadrotor UAV on SE (3). In Proceedings of the 49th IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010; pp. 5420–5425. [Google Scholar] [CrossRef]
- Cooke, R.D. Unmanned Aerial Vehicles: Design, Development and Deployment; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Wong, J.Y. Theory of Ground Vehicles; John Wiley & Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Spong, M.W.; Hutchinson, S.; Vidyasagar, M. Robot Modeling and Control; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Corke, P. Robotics, Vision and Control: Fundamental Algorithms in MATLAB; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Song, R.; Lewis, F.L. Robust optimal control for a class of nonlinear systems with unknown disturbances based on disturbance observer and policy iteration. Neurocomputing 2020, 390, 185–195. [Google Scholar] [CrossRef]
- Stone, M.H. The generalized weierstrass approximation theorem. Math. Mag. 1948, 21, 167–184. [Google Scholar] [CrossRef]
- Gao, W.; Jiang, Z.P. Adaptive dynamic programming and adaptive optimal output regulation of linear systems. IEEE Trans. Autom. Control 2016, 61, 4164–4169. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | m | l | g | |||
|---|---|---|---|---|---|---|
| Values | ||||||
| Units |
| Average Cost | Gradient Descent RL | -IRL |
|---|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Sun, Q.; Pan, Q. Robust Tracking Control of Underactuated UAVs Based on Zero-Sum Differential Games. Drones 2025, 9, 477. https://doi.org/10.3390/drones9070477
Guo Y, Sun Q, Pan Q. Robust Tracking Control of Underactuated UAVs Based on Zero-Sum Differential Games. Drones. 2025; 9(7):477. https://doi.org/10.3390/drones9070477
Chicago/Turabian StyleGuo, Yaning, Qi Sun, and Quan Pan. 2025. "Robust Tracking Control of Underactuated UAVs Based on Zero-Sum Differential Games" Drones 9, no. 7: 477. https://doi.org/10.3390/drones9070477
APA StyleGuo, Y., Sun, Q., & Pan, Q. (2025). Robust Tracking Control of Underactuated UAVs Based on Zero-Sum Differential Games. Drones, 9(7), 477. https://doi.org/10.3390/drones9070477