
ChatGPT vs. Gemini: Which Provides Better Information on Bladder Cancer?

 , and
, and
Abstract
1. Introduction
2. Materials and Methods
Statistical Analysis
3. Results
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kirkali, Z.; Chan, T.; Manoharan, M.; Algaba, F.; Busch, C.; Cheng, L.; Kiemeney, L.; Kriegmair, M.; Montironi, R.; Murphy, W.M.; et al. Bladder cancer: Epidemiology, staging and grading, and diagnosis. Urology 2005, 66 (Suppl. 1), 4–34. [Google Scholar] [CrossRef] [PubMed]
- Alghafees, M.A.; Alqahtani, M.A.; Musalli, Z.F.; Alasker, A. Bladder cancer in Saudi Arabia: A registry-based nationwide descriptive epidemiological and survival analysis. Ann. Saudi Med. 2022, 42, 17–28. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Althubiti, M.A.; Nour Eldein, M.M. Trends in the incidence and mortality of cancer in Saudi Arabia. Saudi Med. J. 2018, 39, 1259–1262. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Lenis, A.T.; Lec, P.M.; Chamie, K.; Mshs, M.D. Bladder Cancer: A Review. JAMA 2020, 324, 1980–1991. [Google Scholar] [CrossRef] [PubMed]
- Stein, J.P.; Lieskovsky, G.; Cote, R.; Groshen, S.; Feng, A.C.; Boyd, S.; Skinner, E.; Bochner, B.; Thangathurai, D.; Mikhail, M.; et al. Radical cystectomy in the treatment of invasive bladder cancer: Long-term results in 1054 patients. J. Clin. Oncol. 2001, 19, 666–675. [Google Scholar] [CrossRef]
- Quale, D.Z.; Bangs, R.; Smith, M.; Guttman, D.; Northam, T.; Winterbottom, A.; Necchi, A.; Fiorini, E.; Demkiw, S. Bladder Cancer Patient Advocacy: A Global Perspective. Bladder Cancer 2015, 1, 117–122. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Miner, A.S.; Laranjo, L.; Kocaballi, A.B. Chatbots in the fight against the COVID-19 pandemic. NPJ Digit. Med. 2020, 3, 65. [Google Scholar] [CrossRef] [PubMed]
- Calixte, R.; Rivera, A.; Oridota, O.; Beauchamp, W.; Camacho-Rivera, M. Social and demographic patterns of health-related Internet use among adults in the United States: A secondary data analysis of the health information national trends survey. Int. J. Environ. Res. Public Health 2020, 17, 6856. [Google Scholar] [CrossRef]
- Johnson, S.B.; King, A.J.; Warner, E.L.; Aneja, S.; Kann, B.H.; Bylund, C.L. Using ChatGPT to evaluate cancer myths and misconceptions: Artificial intelligence and cancer information. JNCI Cancer Spectr. 2023, 7, pkad015. [Google Scholar] [CrossRef]
- Corfield, J.M.; Abouassaly, R.; Lawrentschuk, N. Health information quality on the internet for bladder cancer and urinary diversion: A multi-lingual analysis. Minerva Urol. E Nefrol.=Ital. J. Urol. Nephrol. 2017, 70, 137–143. [Google Scholar] [CrossRef]
- Shahsavar, Y.; Choudhury, A. User Intentions to Use ChatGPT for Self-Diagnosis and Health-Related Purposes: Cross-sectional Survey Study. JMIR Human Factors 2023, 10, e47564. [Google Scholar] [CrossRef] [PubMed]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- King, M.R. Can Bard, Google’s Experimental Chatbot Based on the LaMDA Large Language Model, Help to Analyze the Gender and Racial Diversity of Authors in Your Cited Scientific References? Cell. Mol. Bioeng. 2023, 16, 175–179. [Google Scholar] [CrossRef]
- Koski, E.; Murphy, J. AI in Healthcare. In Nurses and Midwives in the Digital Age; IOS Press: Bristol, UK, 2021. [Google Scholar]
- American Urological Association [Internet]. Available online: https://www.auanet.org/guidelines-and-quality/guidelines (accessed on 28 February 2025).
- Canadian Urological Association [Internet]. Available online: https://www.cua.org/guidelines (accessed on 28 February 2025).
- NCCN Guidelines. Available online: https://www.nccn.org/guidelines/guidelines-detail?category=1&id=1459 (accessed on 28 February 2025).
- European Association of Urology [Internet]. Available online: https://uroweb.org/guidelines (accessed on 28 February 2025).
- Ozgor, F.; Caglar, U.; Halis, A.; Cakir, H.; Aksu, U.C.; Ayranci, A.; Sarilar, O. Urological Cancers and ChatGPT: Assessing the Quality of Information and Possible Risks for Patients. Clin. Genitourin. Cancer 2024, 22, 454–457.e4. [Google Scholar] [CrossRef] [PubMed]
- Szczesniewski, J.J.; Tellez Fouz, C.; Ramos Alba, A.; Diaz Goizueta, F.J.; García Tello, A.; Llanes González, L. ChatGPT and most frequent urological diseases: Analysing the quality of information and potential risks for patients. World J. Urol. 2023, 41, 3149–3153. [Google Scholar] [CrossRef] [PubMed]
- Musheyev, D.; Pan, A.; Loeb, S.; Kabarriti, A.E. How Well Do Artificial Intelligence Chatbots Respond to the Top Search Queries About Urological Malignancies? Eur. Urol. 2024, 85, 13–16. [Google Scholar] [CrossRef] [PubMed]
- Davis, R.; Eppler, M.; Ayo-Ajibola, O.; Loh-Doyle, J.C.; Nabhani, J.; Samplaski, M.; Gill, I.; Cacciamani, G.E. Evaluating the Effectiveness of Artificial Intelligence-powered Large Language Models Application in Disseminating Appropriate and Readable Health Information in Urology. J. Urol. 2023, 210, 688–694. [Google Scholar] [CrossRef] [PubMed]
- Momenaei, B.; Wakabayashi, T.; Shahlaee, A.; Durrani, A.F.; Pandit, S.A.; Wang, K.; Mansour, H.A.; Abishek, R.M.; Xu, D.; Sridhar, J.; et al. Appropriateness and Readability of ChatGPT-4-Generated Responses for Surgical Treatment of Retinal Diseases. Ophthalmol. Retin. 2023, 7, 862–868. [Google Scholar] [CrossRef] [PubMed]
- Robinson, M.A.; Belzberg, M.; Thakker, S.; Bibee, K.; Merkel, E.; MacFarlane, D.F.; Lim, J.; Scott, J.F.; Deng, M.; Lewin, J.; et al. Assessing the accuracy, usefulness, and readability of artificial-intelligence-generated responses to common dermatologic surgery questions for patient education: A double-blinded comparative study of ChatGPT and Google Bard. J. Am. Acad. Dermatol. 2024, 90, 1078–1080. [Google Scholar] [CrossRef] [PubMed]
- Hershenhouse, J.S.; Mokhtar, D.; Eppler, M.B.; Rodler, S.; Storino Ramacciotti, L.; Ganjavi, C.; Hom, B.; Davis, R.J.; Tran, J.; Russo, G.I.; et al. Accuracy, readability, and understandability of large language models for prostate cancer information to the public. Prostate Cancer Prostatic Dis. 2024, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Zaleski, A.L.; Berkowsky, R.; Craig, K.J.T.; Pescatello, L.S. Comprehensiveness, Accuracy, and Readability of Exercise Recommendations Provided by an AI-Based Chatbot: Mixed Methods Study. JMIR Med. Educ. 2024, 10, e51308. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Abou-Abdallah, M.; Dar, T.; Mahmudzade, Y.; Michaels, J.; Talwar, R.; Tornari, C. The quality and readability of patient information provided by ChatGPT: Can AI reliably explain common ENT operations? Eur. Arch Otorhinolaryngol. 2024, 281, 6147–6153. [Google Scholar] [CrossRef] [PubMed]
- Ömür Arça, D.; Erdemir, İ.; Kara, F.; Shermatov, N.; Odacioğlu, M.; İbişoğlu, E.; Hanci, F.B.; Sağiroğlu, G.; Hanci, V. Assessing the readability, reliability, and quality of artificial intelligence chatbot responses to the 100 most searched queries about cardiopulmonary resuscitation: An observational study. Medicine 2024, 103, e38352. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| Characteristic | Missing | ChatGPT | ChatGPT Plus | Gemini | p-Value |
|---|---|---|---|---|---|
| Overall (n = 53) | 2 (1.3%) | 0.011 | |||
| Very inadequate | 5 (9.4%) | 3 (5.7%) | 5 (9.8%) | ||
| Inadequate | 1 (1.9%) | 1 (1.9%) | 4 (7.8%) | ||
| Neither comprehensive nor inadequate | 7 (13.2%) | 5 (9.4%) | 7 (13.7%) | ||
| Comprehensive | 35 (66.0%) | 22 (41.5%) | 22 (43.1%) | ||
| Very comprehensive | 5 (9.4%) | 22 (41.5%) | 13 (25.5%) | ||
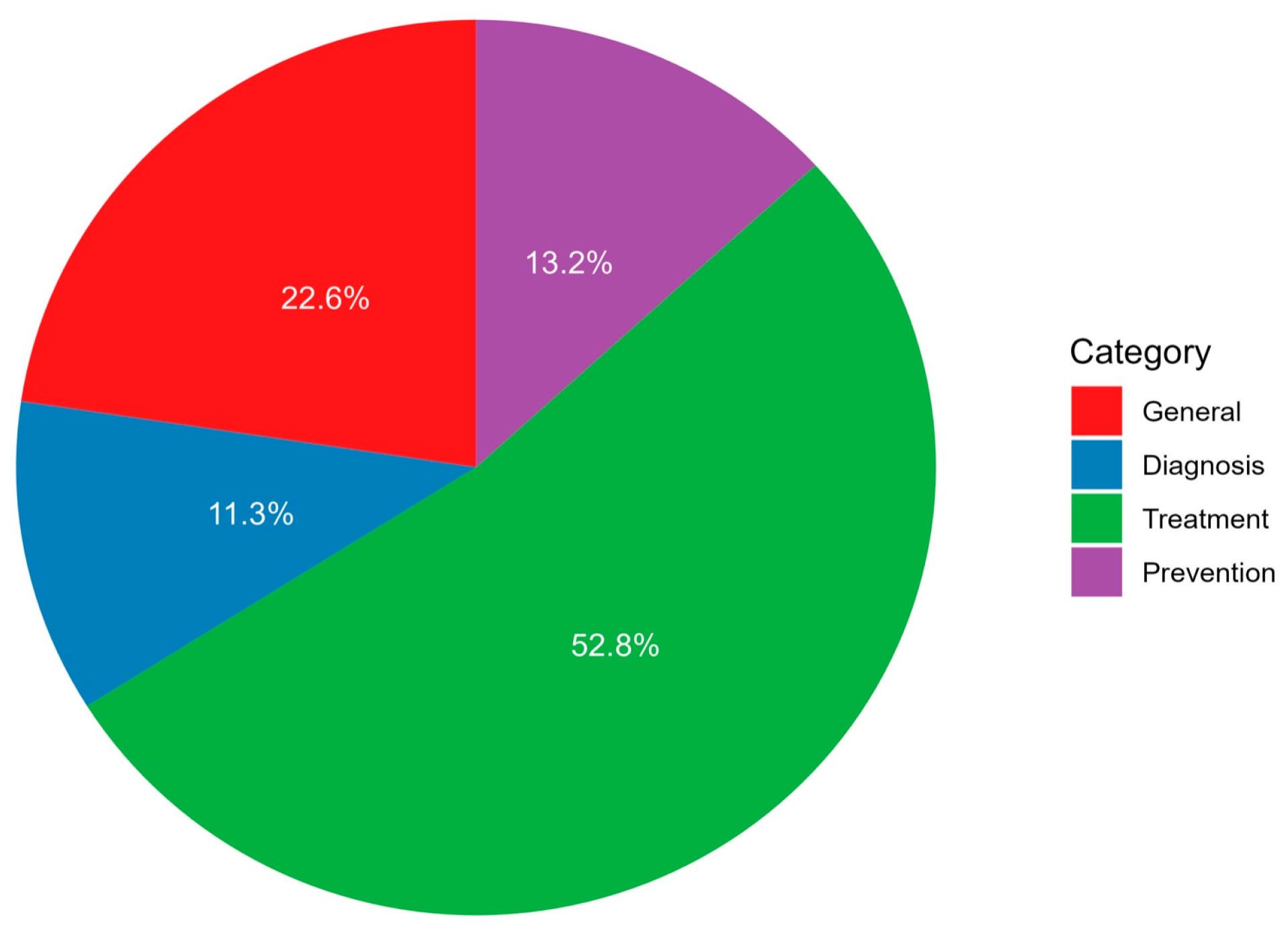
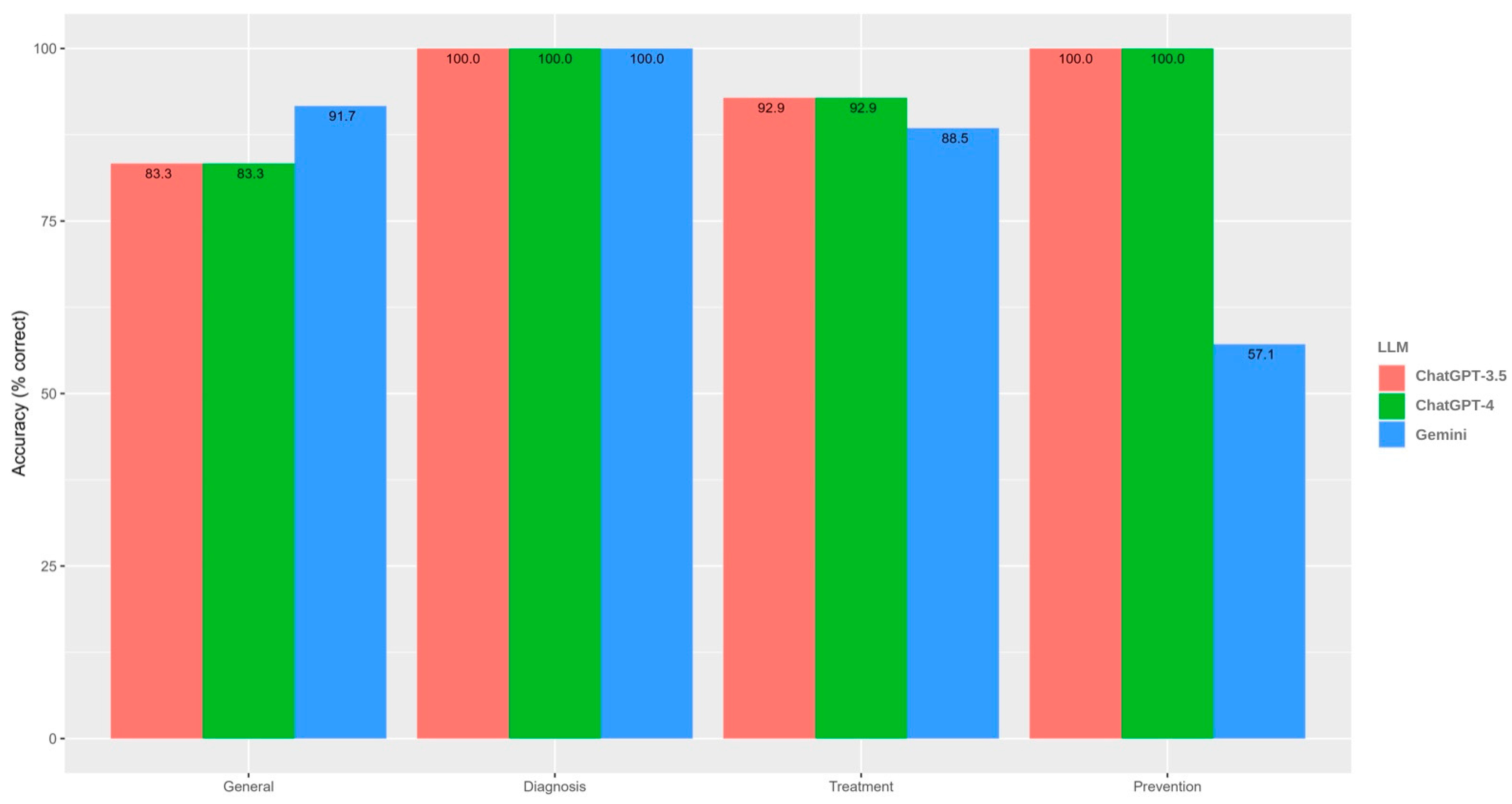
| General (n = 12) | 0 (0%) | 0.291 | |||
| Very inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Inadequate | 1 (8.3%) | 0 (0.0%) | 0 (0.0%) | ||
| Neither comprehensive nor inadequate | 3 (25.0%) | 0 (0.0%) | 2 (16.7%) | ||
| Comprehensive | 7 (58.3%) | 8 (66.7%) | 6 (50.0%) | ||
| Very comprehensive | 1 (8.3%) | 4 (33.3%) | 4 (33.3%) | ||
| Diagnosis (n = 6) | 0 (0%) | >0.999 | |||
| Very inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Inadequate | 0 (0.0%) | 0 (0.0%) | 1 (16.7%) | ||
| Neither comprehensive nor inadequate | 1 (16.7%) | 1 (16.7%) | 1 (16.7%) | ||
| Comprehensive | 2 (33.3%) | 2 (33.3%) | 1 (16.7%) | ||
| Very comprehensive | 3 (50.0%) | 3 (50.0%) | 3 (50.0%) | ||
| Treatment (n = 28) | 2 (2.4%) | 0.007 | |||
| Very inadequate | 5 (17.9%) | 3 (10.7%) | 5 (19.2%) | ||
| Inadequate | 0 (0.0%) | 1 (3.6%) | 3 (11.5%) | ||
| Neither comprehensive nor inadequate | 2 (7.1%) | 2 (7.1%) | 3 (11.5%) | ||
| Comprehensive | 20 (71.4%) | 10 (35.7%) | 10 (38.5%) | ||
| Very comprehensive | 1 (3.6%) | 12 (42.9%) | 5 (19.2%) | ||
| Prevention (n = 7) | 0 (0%) | 0.205 | |||
| Very inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Neither comprehensive nor inadequate | 1 (14.3%) | 2 (28.6%) | 1 (14.3%) | ||
| Comprehensive | 6 (85.7%) | 2 (28.6%) | 5 (71.4%) | ||
| Very comprehensive | 0 (0.0%) | 3 (42.9%) | 1 (14.3%) |
| Characteristic | Missing | ChatGPT | ChatGPT Plus | Gemini | p-Value |
|---|---|---|---|---|---|
| Overall (n = 53) | 0 (0%) | <0.001 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 1 (1.9%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 4 (7.5%) | ||
| 8th & 9th grade | 2 (3.8%) | 1 (1.9%) | 13 (24.5%) | ||
| 10th to 12th grade | 8 (15.1%) | 4 (7.5%) | 17 (32.1%) | ||
| College | 37 (69.8%) | 40 (75.5%) | 18 (34.0%) | ||
| College graduate | 6 (11.3%) | 7 (13.2%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 1 (1.9%) | 0 (0.0%) | ||
| General (n = 12) | 0 (0%) | 0.016 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 2 (16.7%) | ||
| 8th & 9th grade | 1 (8.3%) | 1 (8.3%) | 3 (25.0%) | ||
| 10th to 12th grade | 3 (25.0%) | 1 (8.3%) | 5 (41.7%) | ||
| College | 8 (66.7%) | 10 (83.3%) | 2 (16.7%) | ||
| College graduate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Diagnosis (n = 6) | 0 (0%) | 0.050 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 8th & 9th grade | 0 (0.0%) | 0 (0.0%) | 2 (33.3%) | ||
| 10th to 12th grade | 1 (16.7%) | 0 (0.0%) | 3 (50.0%) | ||
| College | 4 (66.7%) | 5 (83.3%) | 1 (16.7%) | ||
| College graduate | 1 (16.7%) | 1 (16.7%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Treatment (n = 28) | 0 (0%) | <0.001 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 1 (3.6%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 2 (7.1%) | ||
| 8th & 9th grade | 1 (3.6%) | 0 (0.0%) | 7 (25.0%) | ||
| 10th to 12th grade | 2 (7.1%) | 2 (7.1%) | 7 (25.0%) | ||
| College | 20 (71.4%) | 21 (75.0%) | 11 (39.3%) | ||
| College graduate | 5 (17.9%) | 4 (14.3%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 1 (3.6%) | 0 (0.0%) | ||
| Prevention (n = 7) | 0 (0%) | 0.561 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 8th & 9th grade | 0 (0.0%) | 0 (0.0%) | 1 (14.3%) | ||
| 10th to 12th grade | 2 (28.6%) | 1 (14.3%) | 2 (28.6%) | ||
| College | 5 (71.4%) | 4 (57.1%) | 4 (57.1%) | ||
| College graduate | 0 (0.0%) | 2 (28.6%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
| Characteristic | Missing | ChatGPT | ChatGPT Plus | Gemini | p-Value |
|---|---|---|---|---|---|
| Overall (n = 53) | 0 (0%) | <0.001 | |||
| Plain English | 2 (3.8%) | 1 (1.9%) | 13 (24.5%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 4 (7.5%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 1 (1.9%) | ||
| Difficult to read | 37 (69.8%) | 40 (75.5%) | 18 (34.0%) | ||
| Fairly difficult to read | 8 (15.1%) | 4 (7.5%) | 17 (32.1%) | ||
| Very difficult to read | 6 (11.3%) | 7 (13.2%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 1 (1.9%) | 0 (0.0%) | ||
| General (n = 12) | 0 (0%) | 0.019 | |||
| Plain English | 1 (8.3%) | 1 (8.3%) | 3 (25.0%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 2 (16.7%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Difficult to read | 8 (66.7%) | 10 (83.3%) | 2 (16.7%) | ||
| Fairly difficult to read | 3 (25.0%) | 1 (8.3%) | 5 (41.7%) | ||
| Very difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Diagnosis (n = 6) | 0 (0%) | 0.055 | |||
| Plain English | 0 (0.0%) | 0 (0.0%) | 2 (33.3%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Difficult to read | 4 (66.7%) | 5 (83.3%) | 1 (16.7%) | ||
| Fairly difficult to read | 1 (16.7%) | 0 (0.0%) | 3 (50.0%) | ||
| Very difficult to read | 1 (16.7%) | 1 (16.7%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Treatment (n = 28) | 0 (0%) | <0.001 | |||
| Plain English | 1 (3.6%) | 0 (0.0%) | 7 (25.0%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 2 (7.1%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 1 (3.6%) | ||
| Difficult to read | 20 (71.4%) | 21 (75.0%) | 11 (39.3%) | ||
| Fairly difficult to read | 2 (7.1%) | 2 (7.1%) | 7 (25.0%) | ||
| Very difficult to read | 5 (17.9%) | 4 (14.3%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 1 (3.6%) | 0 (0.0%) | ||
| Prevention (n = 7) | 0 (0%) | 0.562 | |||
| Plain English | 0 (0.0%) | 0 (0.0%) | 1 (14.3%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Difficult to read | 5 (71.4%) | 4 (57.1%) | 4 (57.1%) | ||
| Fairly difficult to read | 2 (28.6%) | 1 (14.3%) | 2 (28.6%) | ||
| Very difficult to read | 0 (0.0%) | 2 (28.6%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
| Characteristic | Missing | ChatGPT | ChatGPT Plus | Gemini | p-Value |
|---|---|---|---|---|---|
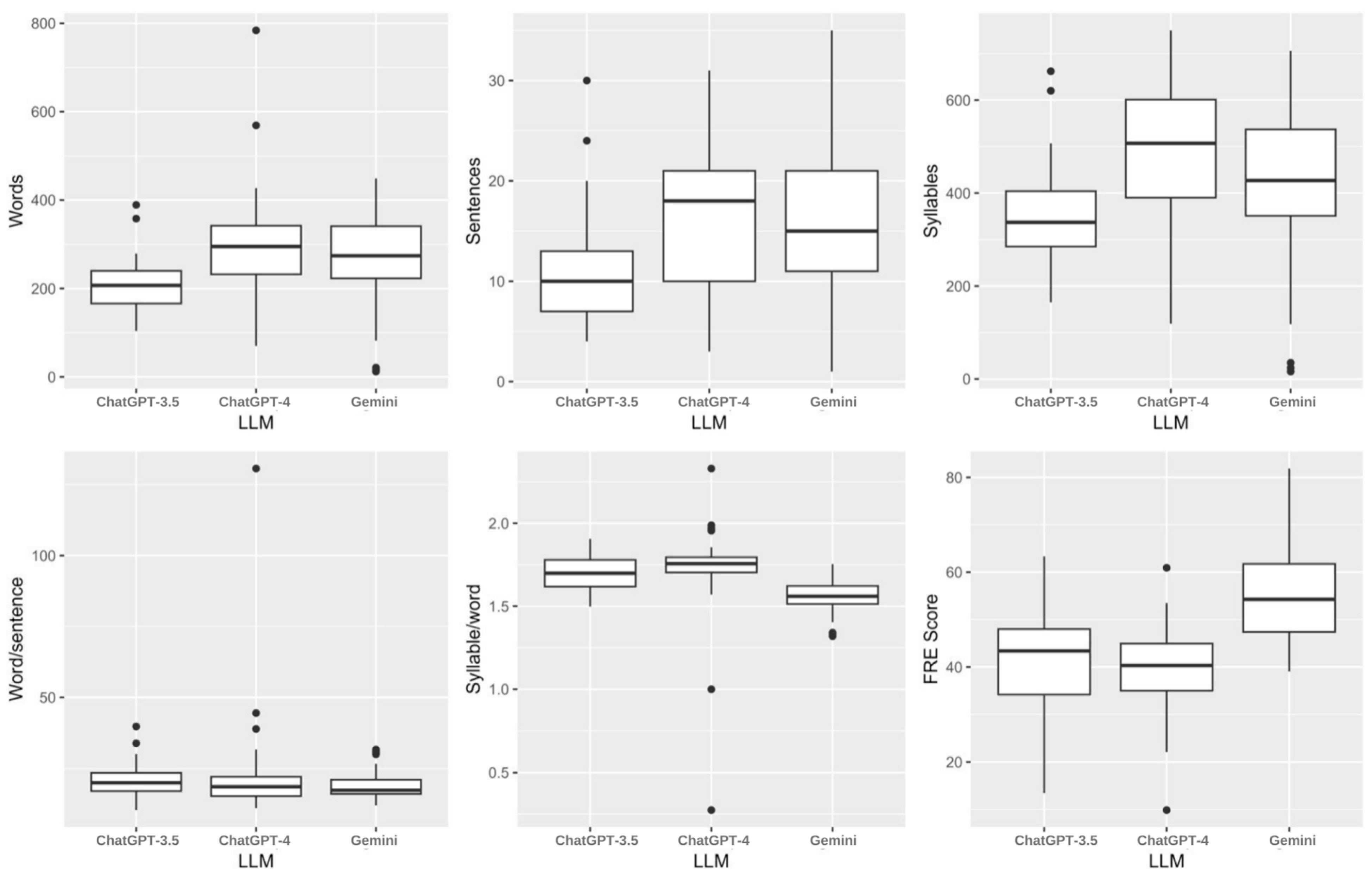
| Words | 0 (0%) | 207.0 (166.0–240.0) | 295.0 (232.0–342.0) | 274.0 (223.0–341.0) | <0.001 |
| Sentences | 0 (0%) | 10.0 (7.0–13.0) | 18.0 (10.0–21.0) | 15.0 (11.0–21.0) | <0.001 |
| Syllables | 0 (0%) | 337.0 (285.0–404.0) | 507.0 (390.0–601.0) | 427.0 (351.0–537.0) | <0.001 |
| Word/sentence | 0 (0%) | 20.0 (17.1–23.5) | 18.6 (15.3–22.1) | 17.3 (16.1–21.1) | 0.099 |
| Syllable/word | 0 (0%) | 1.7 (1.6–1.8) | 1.8 (1.7–1.8) | 1.6 (1.5–1.6) | <0.001 |
| FRE Score | 0 (0%) | 43.4 (34.2–48.0) | 40.3 (35.0–44.9) | 54.3 (47.4–61.7) | <0.001 |
| FK Reading Level | 0 (0%) | 13.6 (11.7–15.4) | 12.6 (11.5–13.8) | 11.0 (9.4–45,116.0) | 0.093 |
| Characteristic | ChatGPT | ChatGPT Plus | Gemini | p-Value |
|---|---|---|---|---|
| Overall (n = 10) | >0.999 | |||
| Consistent | 9 (90.0%) | 9 (90.0%) | 8 (80.0%) | |
| Inconsistent | 1 (10.0%) | 1 (10.0%) | 2 (20.0%) | |
| Diagnosis (n = 3) | 0.671 | |||
| Consistent | 3 (100.0%) | 2 (66.7%) | 1 (33.3%) | |
| Inconsistent | 0 (0.0%) | 1 (33.3%) | 2 (66.7%) | |
| Treatment (n = 3) | >0.999 | |||
| Consistent | 2 (66.7%) | 3 (100.0%) | 3 (100.0%) | |
| Inconsistent | 1 (33.3%) | 0 (0.0%) | 0 (0.0%) | |
| Prevention (n = 4) | ||||
| Consistent | 4 (100.0%) | 4 (100.0%) | 4 (100.0%) | NA |
| Inconsistent | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the Société Internationale d’Urologie. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alasker, A.; Alshathri, N.; Alsalamah, S.; Almansour, N.; Alsalamah, F.; Alghafees, M.; AlKhamees, M.; Alsaikhan, B. ChatGPT vs. Gemini: Which Provides Better Information on Bladder Cancer? Soc. Int. Urol. J. 2025, 6, 34. https://doi.org/10.3390/siuj6020034
Alasker A, Alshathri N, Alsalamah S, Almansour N, Alsalamah F, Alghafees M, AlKhamees M, Alsaikhan B. ChatGPT vs. Gemini: Which Provides Better Information on Bladder Cancer? Société Internationale d’Urologie Journal. 2025; 6(2):34. https://doi.org/10.3390/siuj6020034
Chicago/Turabian StyleAlasker, Ahmed, Nada Alshathri, Seham Alsalamah, Nura Almansour, Faris Alsalamah, Mohammad Alghafees, Mohammad AlKhamees, and Bader Alsaikhan. 2025. "ChatGPT vs. Gemini: Which Provides Better Information on Bladder Cancer?" Société Internationale d’Urologie Journal 6, no. 2: 34. https://doi.org/10.3390/siuj6020034
APA StyleAlasker, A., Alshathri, N., Alsalamah, S., Almansour, N., Alsalamah, F., Alghafees, M., AlKhamees, M., & Alsaikhan, B. (2025). ChatGPT vs. Gemini: Which Provides Better Information on Bladder Cancer? Société Internationale d’Urologie Journal, 6(2), 34. https://doi.org/10.3390/siuj6020034