1. Introduction
Optimization of sequential decision-making under uncertainty arises in different fields, such as finance, economics, robotics, manufacturing, and telecommunication. These problems are frequently discussed under the framework of real options, as applications of optimal stochastic control. Therefore, the real options viewpoint (see [
1,
2]) highlights a freedom in the choice of decisions and consistently uses the operational flexibility for strategy optimization. The classical contributions [
3,
4] were among the first, placing sequential decision optimization into
real option context, with applications in manufacturing [
5], investment planning [
6], mining [
7], and commodities [
8]. Therefore, a formulation of decision problems in continuous time was preferred: using a jump-diffusion setting and its well-established stochastic control toolbox, the so-called Hamilton-Jacobi Bellman (HJB) equations, (see [
9]) and the Backward Stochastic Differential Equations (BSDE) (see [
10]) became applicable [
11,
12,
13]. However, also using discrete-time modeling, sequential decision problems have been routinely treated in terms of the
Markov Decision Theory [
14,
15] whose approximate techniques are known as
Approximate Dynamic Programming, (see [
16], which comprises diverse heuristic numerical approaches).
In this paper we discuss a specific class of discrete-time stochastic control problems from the viewpoint of real options, and use a certain managerial flexibility which can be expressed in terms of a virtual reserve price. We show that in the optimal regime at any time, the actions are connected to each other (in a certain sense) via virtual reserve price. This observation can be used to significantly reduce the range of actions available for decision choice by excluding at each step those which cannot be optimal. More specifically, we consider an abstract but generic situation which frequently arises in sequential decision-making, when a certain activity (production plan) must be optimally chosen to meet the right balance between the current costs of the activity and the consumption of some resource. While all activity costs have an immediate effect, the impact of resource consumption is uncertain and becomes relevant in the future. In practice, one is frequently confronted with a huge range of possibilities to choose activities, and their combinations form a complex space whose structure is usually determined by numerous inter-relations. Although a solution to such sequential decision problem can be theoretically obtained in terms of the standard backward induction, its practical implementation is virtually infeasible due to the high complexity of decisions.
It turns out that a certain transformation can be of great help in such situations. In particular, under specific but natural assumptions, we show how the decision variables space can be reduced to a simple one-parameter family. Such reduction is achieved by a solution to a separate deterministic optimization problem which is usually easily obtainable. Using such re-formulation, diverse numerical techniques for backward induction can be applied. In this context, in our particular situations, the Bellman’s optimality principle turns out to be equivalent to certain fixed-point equations, which might lead to alternative ways to further simplify computational efforts in the backward induction.
The paper is organized as follows.
Section 2 reviews dynamical Bellman principle underlying the classical and stochastic dynamic programing and explains how our method is placed within this context and its use in practice.
Section 3 presents the problem and our approach to variables reduction within a general framework.
Section 4 introduces an application to battery control which is reviewed in
Section 5 to obtain a variables reduction for battery storages.
Section 6 is devoted to formal justification of our techniques, while
Section 7 concludes.
2. Dynamic Principle for Optimal Switching and Reduction of Decision Variables
In applications, sequential decision-making is usually addressed under the framework of discrete-time
Stochastic Control. The theory of
Markov Decision Processes/Dynamic Programming provides a variety of methods to deal with such questions. In generic situations, approaching analytical solutions for even some simplest decision processes may be a cumbersome process ([
10,
14,
16]) Furthermore, since closed-form solutions to practically important control problems are usually unavailable, numerical approximations became popular among practitioners to obtain approximately optimal control policies. Although a huge variety of computational methods have been developed therefore, typical real-world problems are usually too complex for the existing solution techniques, in particular if the state dimension of the underlying controlled evolution is high. Let us review the finite-horizon Markov decision theory following [
17].
Controlled Markov processes: Consider a random dynamics on a finite time horizon
whose state
x evolves in
E and is controlled by actions
a from an action set
A. For each
, we assume that
is a stochastic transition kernel on
E. A mapping
which describes the action that the controller takes at time
t is called a
decision rule. A sequence of decision rules
is called a
policy. For each initial point
and each policy
, there exists a probability measure
and a stochastic process
satisfying the initial condition
such that
holds for each
at all times
, i.e., given that system is in state
at time
t, the action
is used to pick the transition probability
which randomly drives the system from
to
with the distribution
. Let us use
to denote the one-step transition operator associated with the transition kernel
when the action
is chosen. In other words, for each action
the operator
acts on functions
v by
whenever the above integrals are well-defined.
Costs of control: For each time
t, we are given the
t-step reward function , where
represents the reward for applying an action
when the state of the system is
at time
t. At the end of the time horizon, at time
T, it is assumed that no action can be taken. Here, if the system is in a state
x, a
scrap value , which is described by a pre-specified
scrap function , is collected. Given an initial point
, the goal is to maximize the expected finite-horizon total reward, in other words to find the argument
such that
where
A is the set of all policies, and
denotes the expectation over the controlled Markov chain defined by (
1).
Decision optimization: The maximization (
3) is well-defined under diverse additional assumptions (see [
14], p. 199). The calculation of the optimal policy is addressed in the following setting. For
, introduce the
Bellman operator
which acts on each measurable function
where the integrals
for all
exist. Furthermore, consider the
Bellman recursion
Under appropriate assumptions, there exists a recursive solution
to the Bellman recursion, which gives the so-called
value functions and determines an optimal policy
via
Stochastic switching: Consider now a Markov decision model whose state evolution consists of one controllable and one uncontrollable component. To be more specific, we assume that the state space
is the product of a space
P (operation modes) and a set
(states of environment) being a subset
of the Euclidean space. We suppose that at each time
the mode component
is driven by actions
in terms of a deterministic function
where
stands for the new mode from if the action
was taken at time
in the state
. In this setting, the transition operators are given by
for
, and
.
Variables reduction: In the above context of stochastic switching, the application of Bellman operator
may cause numerical difficulties, particularly if the action space
A is high-dimensional and fragmented. Unfortunately, this situation appears frequently in practice, where high-dimensional vectors of decision variables usually subject to numerous feasibility inter-dependencies. In such framework, the problem may become unsolvable due to difficulty of maximization over a complex action set
A. The main contribution of our paper is to provide a significant reduction of set of actions, which are relevant for maximization. Under specific assumptions described in this paper, we show there exists a one-parameter family (curve)
which depends on the recent time
and state
such that the domain of maximization reduces from
A to
which yields instead of the infeasible maximization (
7) a new problem
which is significantly simpler and usually admits a (numerical) solution. To determine the curve
of relevant actions, a separate deterministic optimization problem must be solved. Its solution is usually obtained explicitly and provides interesting economic insights.
Contribution of this work: Using a standard Bellman principle, we explore an abstract, but natural framework to reduce a potentially very large space of decision variables (actions) to a single one-parameter family. Although our technique is entirely placed within the traditional Bellman principle of stochastic/classic dynamic programming and addresses a relatively narrow problem class, a wide range of application is covered, including mining operations, pension fund management, and emission control. This approach can serve efficient numerical algorithms for notoriously difficult and important problems from practice.
3. Optimal Control via Virtual Resource Price
Let us introduce the required framework more precisely. Consider an agent who is confronted with the following problem. At the beginning of each decision epoch, an activity plan (work schedule) is to be determined. Therefore, all costs of this work plan must be optimally balanced against their resource consumption/generation. Suppose that the limited resources are described in terms of the state variable which stands for the current resource shortage and can vary within a certain interval . For instance, if the resource under consideration is a commodity in the storage, then stands for the amount of commodity required to fill the storage to its maximal capacity. The other state variable is supposed to represent the situation in the surrounding environment. Let us agree that this environmental state variable z is relevant for decisions, but cannot be influenced by agent’s actions. For instance, for commodity storage, z may comprise the driving market factors of the commodity price evolution. We furtherly assume that the environment state occurs at any time as a realization of an -valued Markov process whose dynamics carries all information, relevant for decisions.
Having observed at time
the resource level
and the realization of the environmental state variable
, the agent selects a plan
from the set
of all feasible activity plans. This choice yields an immediate cost
and causes an immediate resource consumption
via pre-specified functions
,
on
which may depend on the recent state
. While all costs are accumulated, the resource level is carried over to the next decision time
as
and will influence the decision at this time. The availability of resources becomes crucial at the end
of the planning horizon, when a certain terminal costs
must be paid, which depend on the total resource level
and on the state
of the environment. Under additional assumptions, such control problems are solved in terms of the so-called value functions
which are obtained via Bellman recursions as
for all arguments
representing the current situation at decision time. Please note that we implicitly agreed to penalize the violation of the admissible resource level in (10) by infinity, gaining the freedom to interpret the value function for all arguments
with possible values
in order to avoid watching restriction
in (11).
The idea underlying our variable reduction scheme is based on the realization that if the resources had a market price, then an agent would minimize all activity costs taking into account the monetary value of the consumed resources. To realize this concept, we suppose that some entity (a regulatory body) could charge a resources price
at any time
t, depending on the situation
. In the presence of such virtual price
, each the decision-maker would examine the virtual charges for the resource consumption and chose an activity accordingly, by obtaining
Obviously, such mapping
represents an optimal activity depending on the current state
, time
, given the resource price
. To some degree, this mapping can be interpreted as the willingness to save resources by following a less profitable strategy in response to an increased value of the resource. For ease of understanding, let us postpone the discussion concerning the existence of the minimizer in (
12) and the properties of the relation
which are crucial for the targeted results. The important assumption for now is that for each state
there exists a bounded interval
such that the one-parameter family of activities
contains only the “best candidates” (for the purpose of minimization in (11)). They can be used in the Bellman recursion, replacing the minimization in (11) by (16) as follows
Please note that now the minimization in (16) must be performed merely over a curve (
13) instead of over the whole space
as in (11). In practical applications, such reduction can provide a reasonable (numerical) approach to a virtually unsolvable problem. The main question here is whether
In the following, we work out all conditions required therefore. Before we turn to the illustration of our technique by battery storage management in
Section 4 and
Section 5, followed by proofs in
Section 6, let us present all required assumptions which ensure the validity of the assertion (
17).
Suppose that all information, relevant for decision-making, is carried by
-valued Markov process
which is realized on a filtered probability space
. As introduced above, we assume that the resource level can vary within a certain bounded interval
. Having selected an activity
from the set
of all feasible activity plans at time
in the state
, the costs
and resource consumption
are determined via pre-specified functions
while the terminal costs are determined by
All our considerations rely on additional assumptions on the functions (
18) which we formulate next. To ensure that the minimization in (11) is well-defined, let us agree that there exists an
idle activity which does not consume any resources:
To ease our argumentation, we suppose that
Furthermore, let us propose a mild technical assumption
To determine the desired minimizer
to (11), we rely on the following natural technical assumption
Finally, we require some convexity properties in the sense that
As mentioned above, the advantage of our approach is that a simpler form (
14)–(16) of Bellman recursion occurs, whose efficient (numerical) treatment may be easily possible, unlike that of the original problem (9)–(11). Indeed, it turns out that such simplification solves the original problem in the following sense:
Theorem 1. Under the assumptions (20)–(24) consider and defined by (9)–(11) and (14)–(16) respectively. If a solution to (14)–(16) exists, then In view of the above result, the practical solution now requires obtaining for each
the optimal decision
via minimization in the simplified Bellman recursion where the virtual price for the optimal regime is obtained via
as a minimizer
Remark 1. We also prove that the optimal decision can be obtained as a solution to the fixed-point equationmeaning that must be a sub-gradient of the expected value function, i.e., in the optimal regime, the virtual resource price must always be equal to the marginal change rate of the value function with respect to the resource level. The economic interpretation of this insight is natural: when choosing an activity plan, the agent increases the resource consumption to a level where the value loss caused by this consumption starts taking over the instant revenue of the activity. 4. Battery Storage Control
To illustrate our variables reduction technique, we introduce a model for battery storage installation operated within a deregulated electricity market. First, let us introduce some technical characteristics. The battery
capacity stands for the maximal energy stored (measured in MWh), whereas the battery power is the amount of
electrical power (measured in MW) the installation can provide at any moment (see [
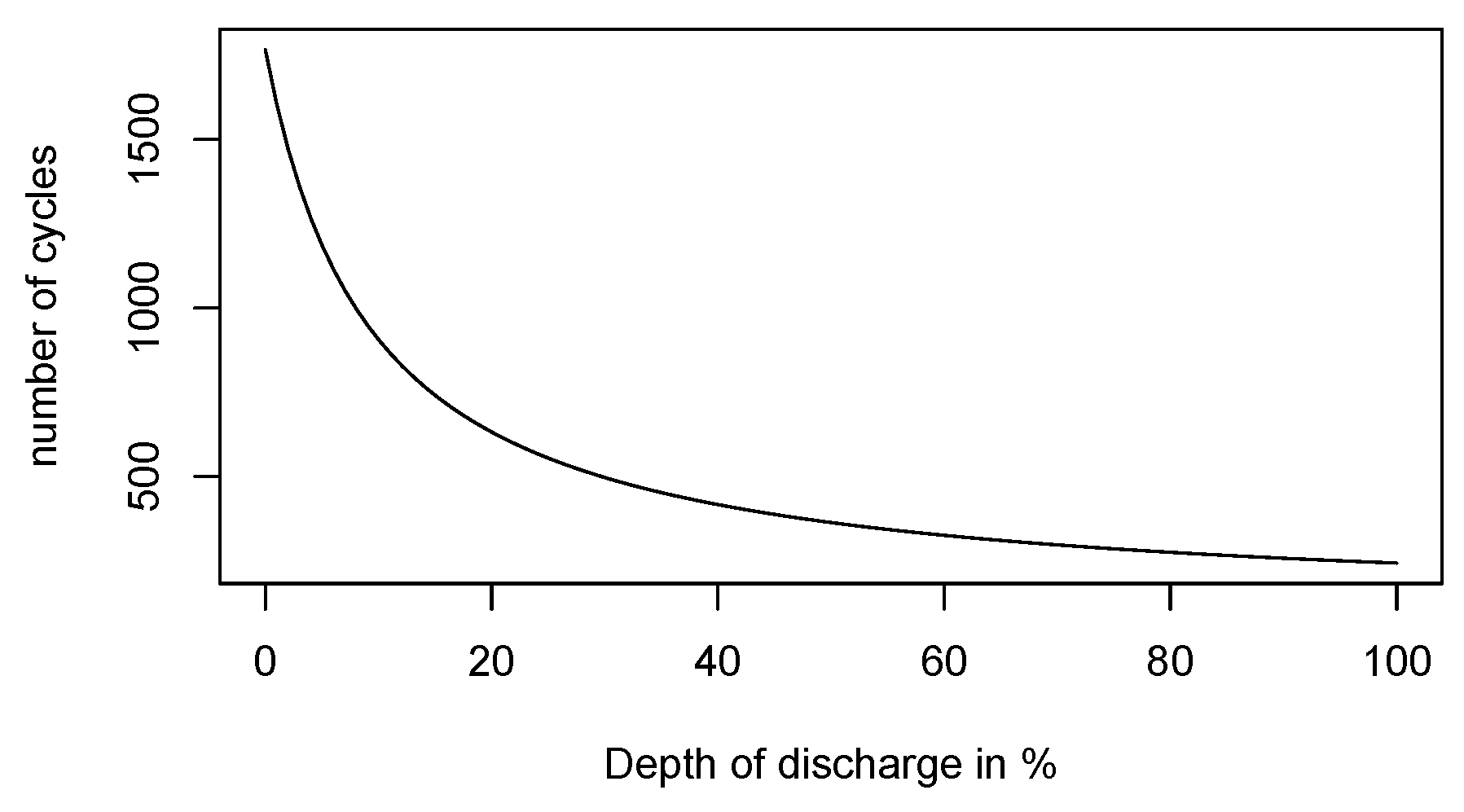
18]). The conditions under which batteries are operated affect their performance in terms of the so-called
cycle life, which can be defined as the number of cycles completed before the effective battery capacity falls below than
of its nominal capacity. Therefore, the Depth of Discharge (DoD) is essential. To give the reader a quantitative understanding of this phenomena, let us consider an example of a
lithium ion battery. Assuming that each charge/discharge cycle causes a battery deterioration, one would assume that emptying completely a battery (which corresponds to
DoD) 200 times is roughly equivalent (in terms of performance decline) to 400 cycles at
DoD and 600 cycles at
DoD. However, the actual behavior is different. Usually, a lithium-type battery serves longer than 400 cycles at
DoD and significantly longer than 600 cycles at
DoD, (see [
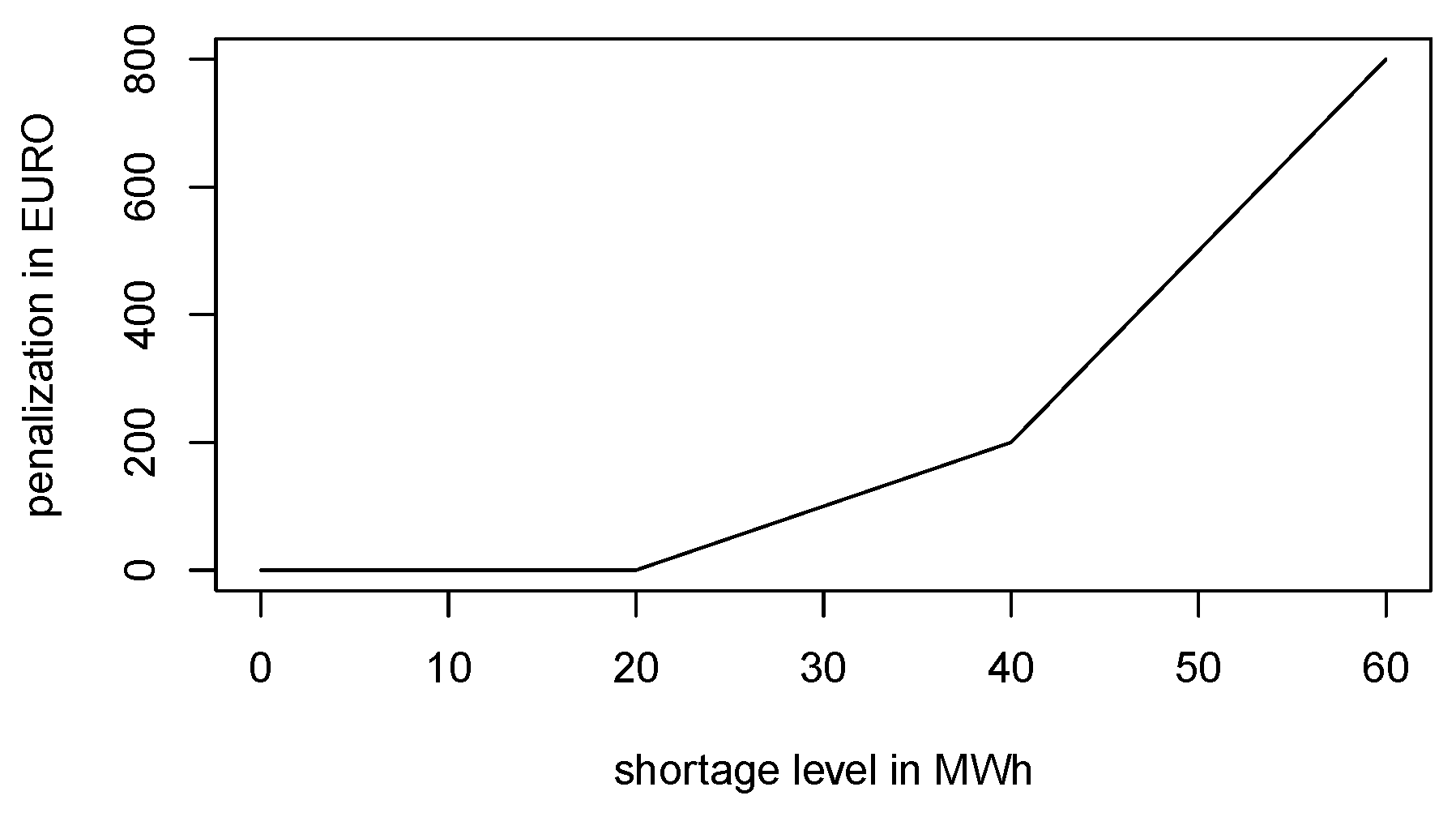
19]) In our model, we suppose that visiting deep discharge states is costly since it affects battery life. For this reason, we suggest including a user-defined function which penalizes deep discharge states accordingly.
Figure 1 illustrates its dependence measured in charge cycles and dependence on depth of discharge. We include such effects into our model by a cost penalization of deep discharge states.
Beyond preventing deep discharge, further operational improvements encompass avoiding that the battery is fully charged (by reducing voltage when charging) and diminishing the so-called charge/discharge rate, which stands for the maximal electric flow during charging/discharging.
We assume that the agent attempts to optimally manage an electricity storage by sequential decisions on the amount of energy procured/purchased through the intraday market and on the optimal charge/discharge of batteries. Obviously, these decisions must take into account the current electricity price, market state, storage level, and all costs and technical restrictions.
Consider an energy retailer facing the obligation to satisfy an unknown energy demand of its customers at times , while renewable energy sources produce a random electricity amount given a certain battery storage. To manage a potential energy imbalance, appropriate forward positions are taken in advance and decisions are made to drive the battery storage. This is a typical dynamic control problem, since at any time an action must be chosen (encompassing a simultaneous energy trade and battery control) which immediately causes some costs but also determines a transition to the next system state (future battery level and market conditions). Clearly, one needs to optimally balance the recent costs against those incurred in the future, based on the current situation. The problems of this type are naturally formulated and solved in terms of dynamic programming.
Remark 2. Please note that we investigate the problem of electricity storage management within an abstract context which is applicable to most of the deregulated electricity markets, possibly with minor adaptation. Namely we consider energy trading on two time scales. The longer-term trading is realized by forwards or futures or by energy delivery contracts, for instance from the day-ahead trading. In practice, these long-term positions are constantly adjusted on a short-term scale using intraday trading or balancing procedures. This two-scale structure is universal and inherent to any deregulated electricity market and we usually observe significant differences between both scales considering their prices, liquidity, and spread.
Consider an agent who serves an energy consumer whose random demand is (partially) covered from a renewable energy generation facility whose energy output is also random. We denote by
the cumulative electricity demand of such facility (which stands for demand if
and surplus if
) for the delivery period
t. Assume that the time point
corresponds to the beginning of the period
t and agree that the demand
is observed after
t, at the end of the delivery period
t. Let us agree to model
, with a zero-mean random variable
standing for the deviation of the realized demand
from its prediction
, which is observable at time
t. Moreover, assume that at each time
, the producer can take a forward position which attempts to cover
. Let us describe such position as
where
stands for the deviation of the total amount traded forward from the prediction
. In generic situations, the quantity
can be considered to be a “safety margin” which must be purchased on the top of predicted demand
to avoid a potential energy shortage during delivery interval. However, we do not assume that
or
must always be positive. Moreover, introduce the control variable
, standing for the decision to transfer the energy amount
from/to the battery, where
and
represent discharging and charging actions, respectively. Here, we agree that these control actions must be decided at time
t (immediately before the delivery period
t starts). With these assumptions, the energy to be balanced during delivery period
using electricity grid is
Please note that on the right-hand side of this equation, the quantities and must be chosen at t whereas becomes observable after time t.
Now we turn to storage control costs and introduce electricity prices
with the interpretation that for delivery period
t,
stands for the forward price, whereas
and
are the so-called upper and the lower balancing prices.
Remark 3. Please note that stands for the price of energy from long-term market. In the sense of the above remark, this price can represent a forward, futures, or day-ahead price of electrical energy in front of delivery, depending on modeling.
While the forward price
is listed prior to the delivery period
t and applies to energy traded in advance, the balancing prices
,
are determined during delivery period
t and apply for purchase and procurement of the grid energy. Usually, it holds that
In practice, the price range
can be wide, meaning that
is significantly lower than
which is lower than
. This issue makes any balancing using grid energy potentially unfavorable. For this reason, the agent attempts to meet the demand as precisely as possible using a combination of the energy from the forward position and from the battery. More specifically, we suppose that the costs, associated with taking forward position, are given by
where
is a coefficient, representing the elasticity of the forward price with respect to contract volume. The total costs associated with energy balancing during the period
is given by
Please note that this quantity is observable after t and is controlled by the variables and which must be chosen at t.
Let us precisely formulate the assumptions on random variables observables, concerning the time of their observation. Suppose that the processes
,
,
are given on a filtered probability space
where
represents the information available at time point
t, just before the start of the delivery period
t. According to the above modeling, we suppose that for
Let us suppose that
and denote by
the expectation, conditioned on
for
. Applying such conditional expectation
to (
32), we use the conditional independence (4) to obtain
In this equation, the prices expected in front of delivery, are denoted by
To simplify our energy storage management, we furtherer agree that the distribution of prediction errors does not depend on recent information in the sense that
This natural assumption yields a compact form for the expected costs (
34):
with functions
and
explicitly computable from
In view of (
34)–(
37), the expected costs of (
32) depend on the energy control variables
f and
b as
Please note that these costs are expected at time t and can be changed by appropriate adjustment of decision variables .
For an agent concerned with the minimization of all costs accumulated within the decision period ranging from to , the dynamical aspects are important. Specifically, the decision at time t to use energy b from the storage changes the storage level, which has a distinct impact on the availability of energy in the future, influencing all following decisions.
To formulate our storage control as a dynamic programming problem, we assume that a Markov dynamics
on
carries all relevant information. Therefore, we suppose that
is a Markovian process which takes values in
. This process describes the evolution of all relevant state variables of the environment. In particular, we assume that the expected prices are represented by function
of state variables, whose components
determine the prices as follows:
In accordance to (30), we require for
that
Furthermore, we suppose that at any time
, the conditional expectation of the next period’s demand is described in terms of a deterministic function
Besides the state of the environment
, the other important state variable is the current storage level
. Having denoted the minimal and the maximal energy amounts of the battery by
and
respectively, we suppose that the storage level
e represents by the amount
e of energy, which is
needed to fully charge the battery. With this interpretation, our variable is the
In view of (
34)–(
39), the expected costs of (
32) are now written in terms of a function
of the resource level
, the state variable
, and the control variables
for
. Please note that in (
42) we include the costs
of deep discharge corresponding to the resource level
, modeled by an
Remark 4. Ideally, an understanding of the chemistry of a particular battery will suggest some generic penalization function. However, in practice, there are diverse approaches to assess (in economic terms) how the battery life is affected by visiting a deep discharge state. Here, the usual cycle life graph (as in Figure 1), does not detail all aspects required by our approach. The point is that the cycle life is determined by charge/discharge periods oscillating linearly between the minimal and the maximal capacity, rather by a certain strategy run within a random environment. Such life cycle diagrams do not provide any information whether it could be worth visiting a deep discharge state for a short period of time in order to catch an electricity price spike. Given diverse battery storage technologies, there is no simple way of determining an appropriate penalization function. For this reason, the authors suggest a pragmatic approach: For a pre-specified penalization as depicted in Figure 2, the user will calculate the corresponding optimal strategy which must be examined and assessed in simulations. If required by simulation results, the penalty function can be altered, followed by another round of optimization and simulations. Such attempts can be repeated until satisfactory results (considering battery life expectation, peak load response, and total revenue) are reached. Now, let us propose Bellman recursion for our battery control problem. Recall that in our modeling, the state variables at time
comprise a market situation described by the realization
of the environment state process and the current resource level
. Having supposed that at the final date
, in the environment state
the entire battery storage content
can be sold at the market price
, we agree that the terminal costs function is
This quantity determines the value function
at the final time
T by
Prior to the terminal time
, the backward induction yields the value functions
recursively by
where the minimum must be taken over the set
of all admissible controls
due to restriction that the energy transfer from/to the storage is limited by the storage capacity. However, in our approach, many arguments rely on the assumption that the set of admissible decisions does not depend on the current situation. To replace the minimization over admissible controls
in (11) by a minimization over an unrestricted set
we introduce a penalization for violation
, having in mind that for a sufficiently strong penalization it will be never optimal to violate the restriction
. This concept is realized by the following recursions:
Please note that with this definition, the functions
satisfy (
45)–(
48) if and only if they fulfill (
49)–(51).


{kind=link}
{kind=link}

