SMOTE-ENC: A Novel SMOTE-Based Method to Generate Synthetic Data for Nominal and Continuous Features



Abstract
:1. Introduction
2. Materials and Methods
| Algorithm 1. SMOTE-ENC algorithm |
| Input: t = number of minority class samples in training set; n% = amount of oversampling; k = number of nearest neighbors to be considered, s = total number of instances in training set, c = number of continous variables in the dataset, m = median of standard deviation of continuous features when c > 0 ir = t/s for each categorical feature, do for each “l” in distinct labels, do e = total number of “l” labeled instances in training set e′ = ; o = number of “l” labeled minority class instances in training set χ = ; if c > 0, l = χ * m; else, l = χ; end end Apply SMOTE (t, n, k) For the synthetic data points, the categorical attribute’s value is decided as the value in the majority of its nearest neighbors. Inverse-encode categorical values to their original labels. |
3. Results
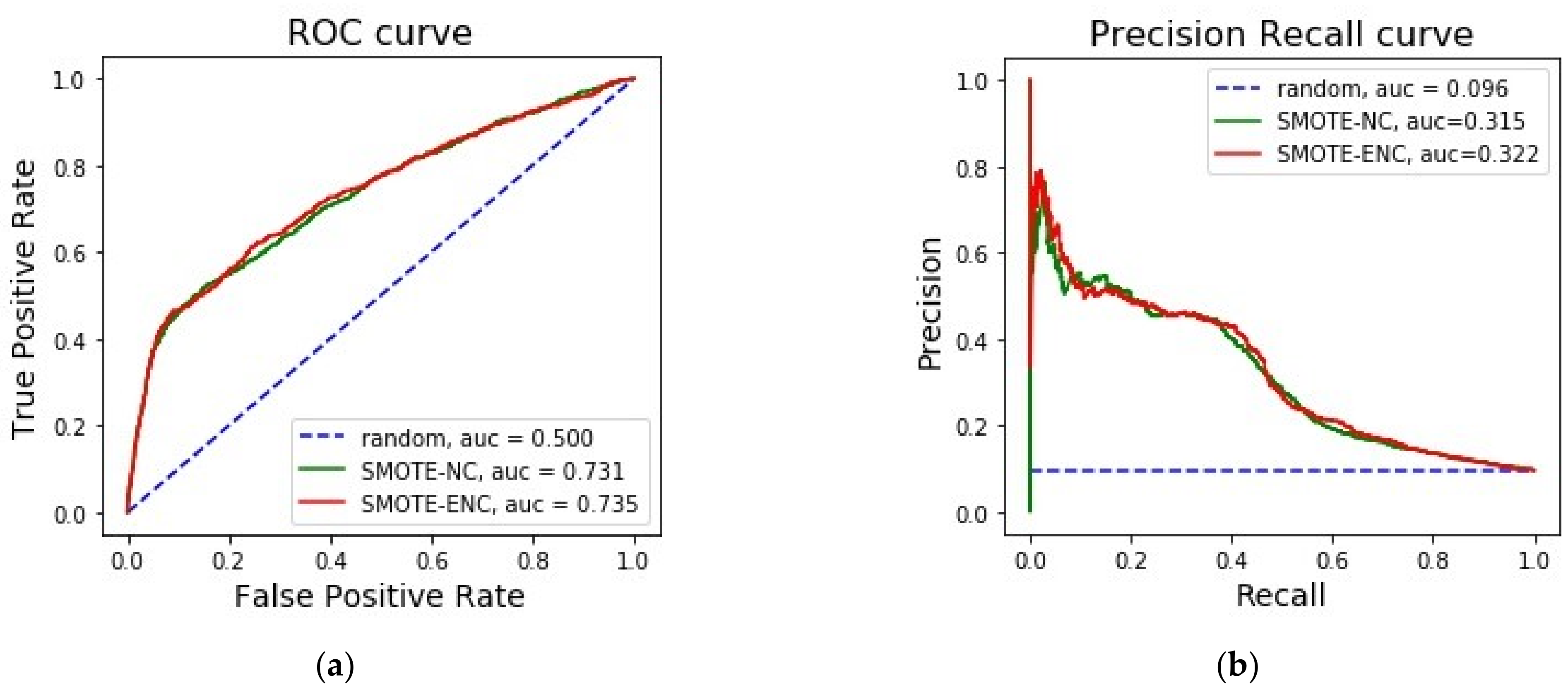
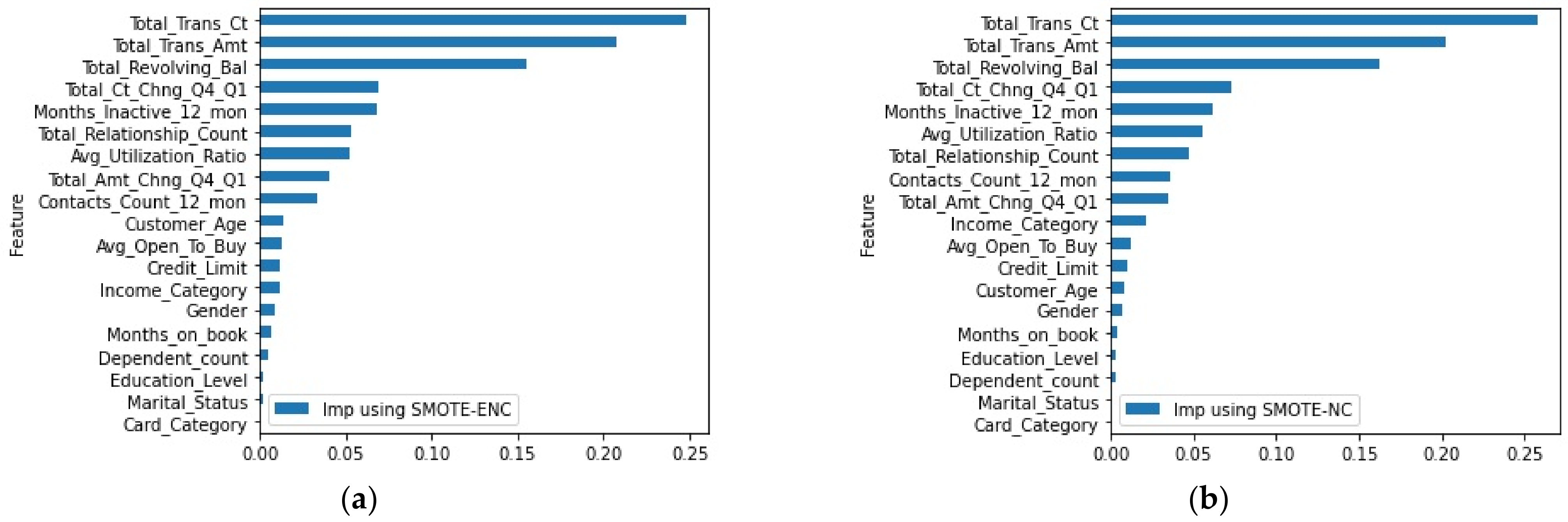
3.1. Evaluation on Banking Telemarketing Dataset
3.2. Evaluation on Credit Card Dataset
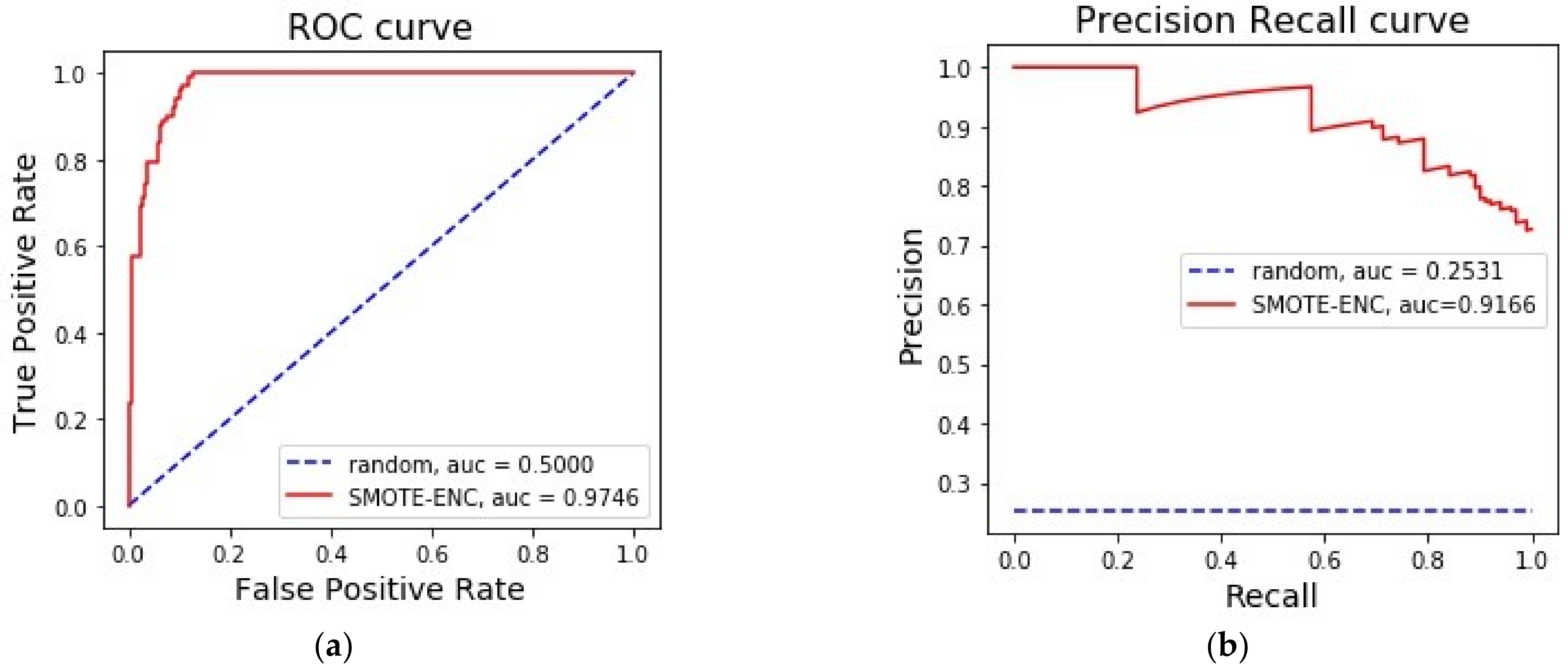
3.3. Evaluation on Car Dataset
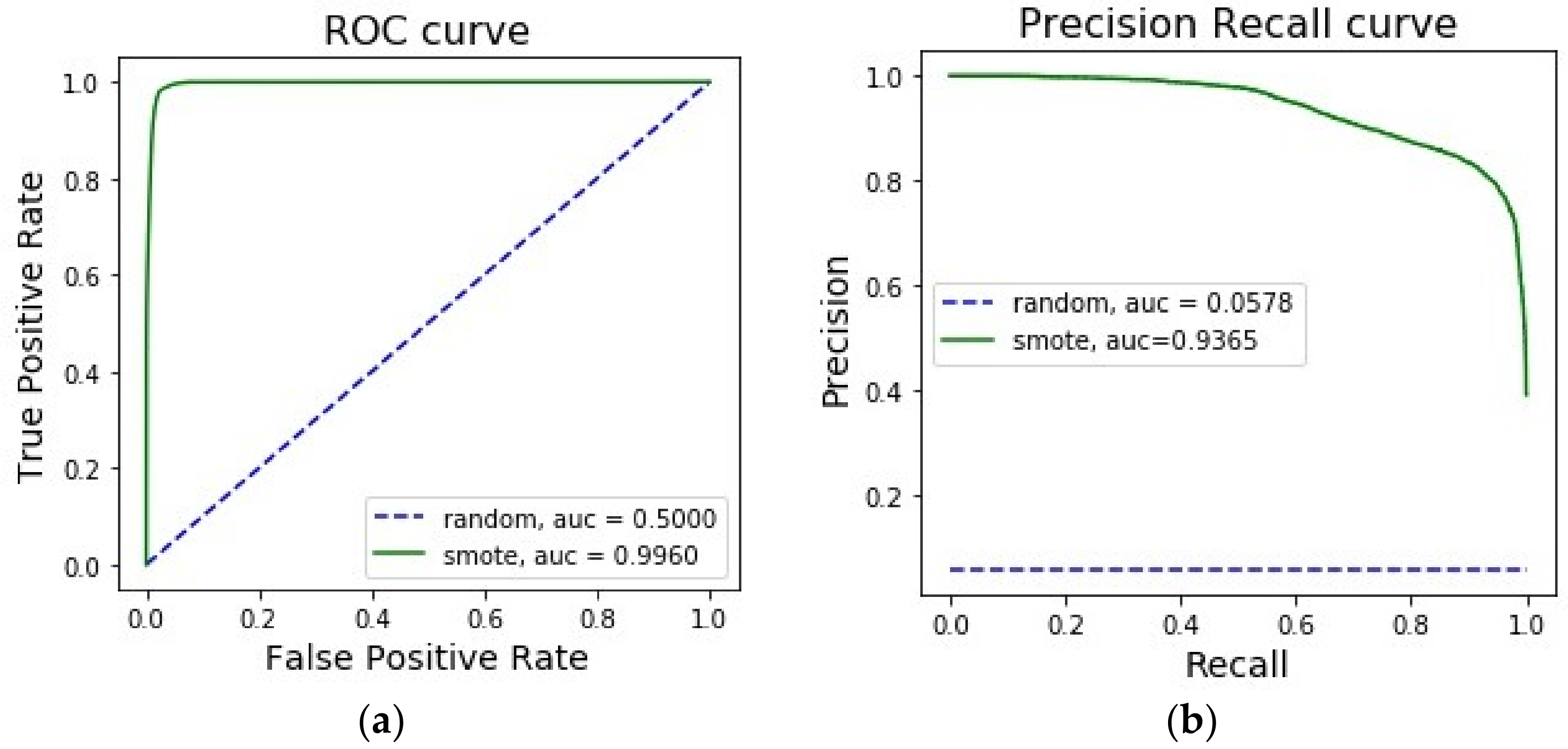
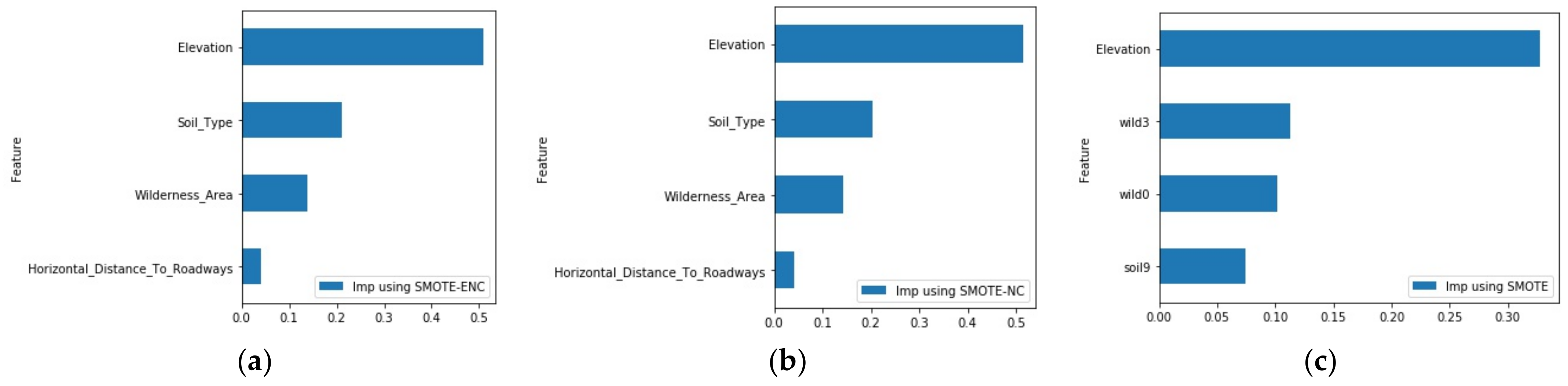
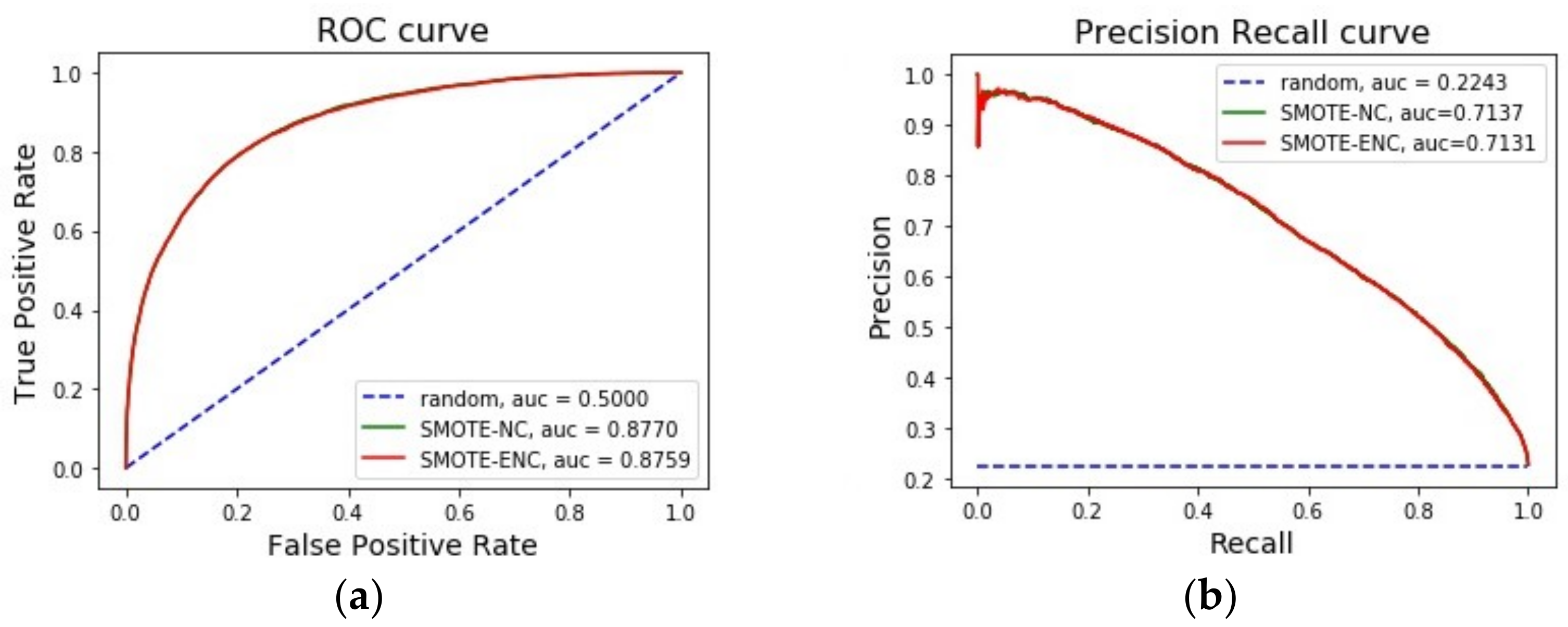
3.4. Evaluation on Forest Cover Dataset with Class 2 and 6
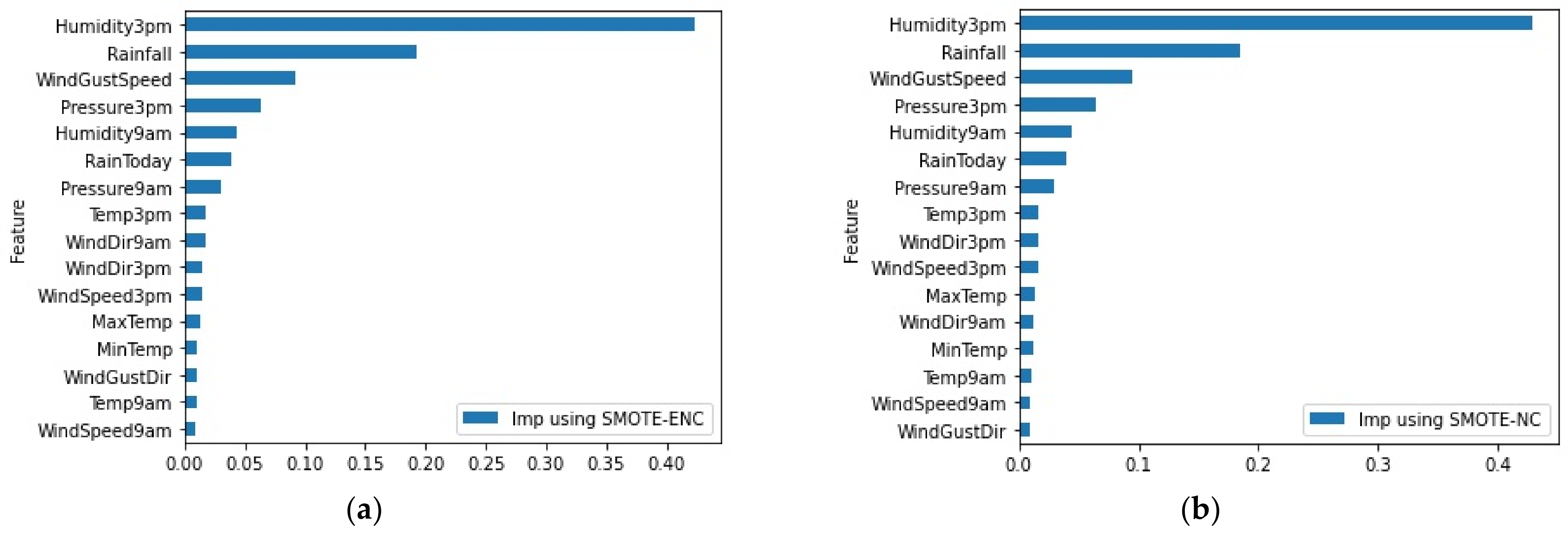
3.5. Evaluation on Rain Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naseem, U.; Khushi, M.; Khan, S.K.; Waheed, N.; Mir, A.; Qazi, A.; Alshammari, B.; Poon, S.K. Diabetic Retinopathy Detection Using Multi-layer Neural Networks and Split Attention with Focal Loss. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; Springer: Cham, Switzerland, 2020; pp. 26–37. [Google Scholar]
- Panta, A.; Khushi, M.; Naseem, U.; Kennedy, P.; Catchpoole, D. Classification of Neuroblastoma Histopathological Images Using Machine Learning. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; Springer: Cham, Switzerland, 2020; pp. 3–14. [Google Scholar]
- Huang, X.; Khushi, M.; Latt, M.; Loy, C.; Poon, S.K. Machine Learning Based Method for Huntington’s Disease Gait Pattern Recognition. In Proceedings of the International Conference on Neural Information Processing, Sydney, NSW, Australia, 12–15 December 2019; Springer: Cham, Switzerland, 2019; pp. 607–614. [Google Scholar]
- Khushi, M.; Choudhury, N.; Arthur, J.W.; Clarke, C.L.; Graham, J.D. Predicting Functional Interactions Among DNA-Binding Proteins. In Proceedings of the International Conference on Neural Information Processing, Siam Reap, Cambodia, 13–16 December 2018; Springer: Cham, Switzerland, 2018; pp. 70–80. [Google Scholar]
- Khushi, M.; Clarke, C.L.; Graham, J.D. Bioinformatic analysis of cis-regulatory interactions between progesterone and estrogen receptors in breast cancer. PeerJ 2014, 2, e654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khushi, M.; Napier, C.E.; Smyth, C.M.; Reddel, R.R.; Arthur, J.W. MatCol: A tool to measure fluorescence signal colocalisation in biological systems. Sci. Rep. 2017, 7, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barlow, H.; Mao, S.; Khushi, M. Predicting High-Risk Prostate Cancer Using Machine Learning Methods. Data 2019, 4, 129. [Google Scholar] [CrossRef] [Green Version]
- Alam, T.M.; Shaukat, K.; Mushtaq, M.; Ali, Y.; Khushi, M.; Luo, S.; Wahab, A. Corporate Bankruptcy Prediction: An Approach Towards Better Corporate World. Comput. J. 2020. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Luo, S.; Sarwar, M.U.; Shabbir, S.; Li, J.; Khushi, M. An Investigation of Credit Card Default Prediction in the Imbalanced Datasets. IEEE Access 2020, 8, 201173–201198. [Google Scholar] [CrossRef]
- Sun, Y.; Kamel, M.S.; Wong, A.K.; Wang, Y.J.P.R. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Zadrozny, B.; Elkan, C. Learning and making decisions when costs and probabilities are both unknown. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Miningn, San Diego, CA, USA, 26–29 August 2001; pp. 204–213. [Google Scholar]
- Yen, S.-J.; Lee, Y.-S. Under-sampling approaches for improving prediction of the minority class in an imbalanced dataset. In Intelligent Control and Automation; Springer: Berlin/Heidelberg, Germany, 2006; pp. 731–740. [Google Scholar] [CrossRef]
- Ganganwar, V. An overview of classification algorithms for imbalanced datasets. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 42–47. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- O’Brien, R.; Ishwaran, H. A random forests quantile classifier for class imbalanced data. Pattern Recognit. 2019, 90, 232–249. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S.; Bellinger, C.; Krawczyk, B.; Zaiane, O.; Japkowicz, N. Synthetic oversampling with the majority class: A new perspective on handling extreme imbalance. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 447–456. [Google Scholar]
- Katuwal, R.; Suganthan, P.N.; Zhang, L. Heterogeneous oblique random forest. Pattern Recognit. 2020, 99, 107078. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, D.; Nie, T.; Kou, Y. A hybrid sampling algorithm combining M-SMOTE and ENN based on Random Forest for medical imbalanced data. J. Biomed. Inform. 2020, 107, 103465. [Google Scholar] [CrossRef] [PubMed]
- Mullick, S.S.; Datta, S.; Das, S. Generative adversarial minority oversampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1695–1704. [Google Scholar]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Torres, F.R.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. SMOTE-D a deterministic version of SMOTE. In Proceedings of the Mexican Conference on Pattern Recognition, Guanajuato, Mexico, 22–25 June 2016; Springer: Cham, Switzerland, 2016; pp. 177–188. [Google Scholar]
- Rao, C. Karl Pearson chi-square test the dawn of statistical inference. In Goodness-of-Fit Tests and Model Validity; Birkhäuser: Boston, MA, USA, 2002; pp. 9–24. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Santos, M.S.; Soares, J.P.; Abreu, P.H.; Araujo, H.; Santos, J. Cross-Validation for Imbalanced Datasets: Avoiding Overoptimistic and Overfitting Approaches [Research Frontier]. IEEE Comput. Intell. Mag. 2018, 13, 59–76. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Sakshi, G. Credit Card Customers-Predict Churning Customers. Available online: https://www.kaggle.com/sakshigoyal7/credit-card-customers/ (accessed on 26 February 2021).
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/car+evaluation/ (accessed on 5 January 2021).
- Asuncion, A.; Newman, D. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/covertype/ (accessed on 11 January 2021).
- Young, J.; Adamyoung. Rain Dataset: Commonwealth of Australia 2010, Bureau of Meteorology. 2018. Available online: https://www.kaggle.com/jsphyg/weather-dataset-rattle-package/ (accessed on 26 February 2019).
- Bellman, R.J.N.J. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957; p. 95. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C1 | C2 | C3 | N | Target | |
|---|---|---|---|---|---|
| Instance 1 (i1) | 100 | 20 | 85 | a | min |
| Instance 2 (i2) | 200 | 65 | 54 | b | min |
| Instance 3 (i3) | 166 | 24 | 38 | a | maj |
| Instance 4 (i4) | 344 | 67 | 89 | b | maj |
| Instance 5 (i5) | 200 | 30 | 75 | b | maj |
| Dataset | IR 1 | N 2 | C 3 | Sampling Method | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|
| Banking telemarketing dataset [28] | 9:1 | 12 | 5 | SMOTE-ENC | 31.95 | 46.84 | 37.99 |
| SMOTE-NC | 27.33 | 50.40 | 35.45 | ||||
| Credit card dataset [29] | 12:1 | 5 | 14 | SMOTE-ENC | 65.61 | 81.75 | 72.79 |
| SMOTE-NC | 59.78 | 84.92 | 70.16 | ||||
| Car dataset [30] | 3:1 | 6 | 0 | SMOTE-ENC | 87.91 | 79.21 | 83.33 |
| SMOTE-NC | NA 4 | NA4 | NA 4 | ||||
| Forest cover dataset (class 2 and 6) [31] | 17:1 | 2 | 12 | SMOTE-ENC | 74.76 | 99.84 | 85.50 |
| SMOTE-NC | 74.76 | 99.82 | 85.49 | ||||
| Rain in Australia dataset [32] | 4:1 | 3 | 13 | SMOTE-ENC | 58.45 | 72.24 | 64.62 |
| SMOTE-NC | 58.30 | 72.51 | 64.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukherjee, M.; Khushi, M. SMOTE-ENC: A Novel SMOTE-Based Method to Generate Synthetic Data for Nominal and Continuous Features. Appl. Syst. Innov. 2021, 4, 18. https://doi.org/10.3390/asi4010018
Mukherjee M, Khushi M. SMOTE-ENC: A Novel SMOTE-Based Method to Generate Synthetic Data for Nominal and Continuous Features. Applied System Innovation. 2021; 4(1):18. https://doi.org/10.3390/asi4010018
Chicago/Turabian StyleMukherjee, Mimi, and Matloob Khushi. 2021. "SMOTE-ENC: A Novel SMOTE-Based Method to Generate Synthetic Data for Nominal and Continuous Features" Applied System Innovation 4, no. 1: 18. https://doi.org/10.3390/asi4010018
APA StyleMukherjee, M., & Khushi, M. (2021). SMOTE-ENC: A Novel SMOTE-Based Method to Generate Synthetic Data for Nominal and Continuous Features. Applied System Innovation, 4(1), 18. https://doi.org/10.3390/asi4010018