
Credibility Analysis of User-Designed Content Using Machine Learning Techniques

 ,
,  , ,
, ,  ,
,
Abstract
:1. Introduction
2. Literature Survey
3. Materials and Methods
3.1. Data Set Collection
3.2. Feature Analysis
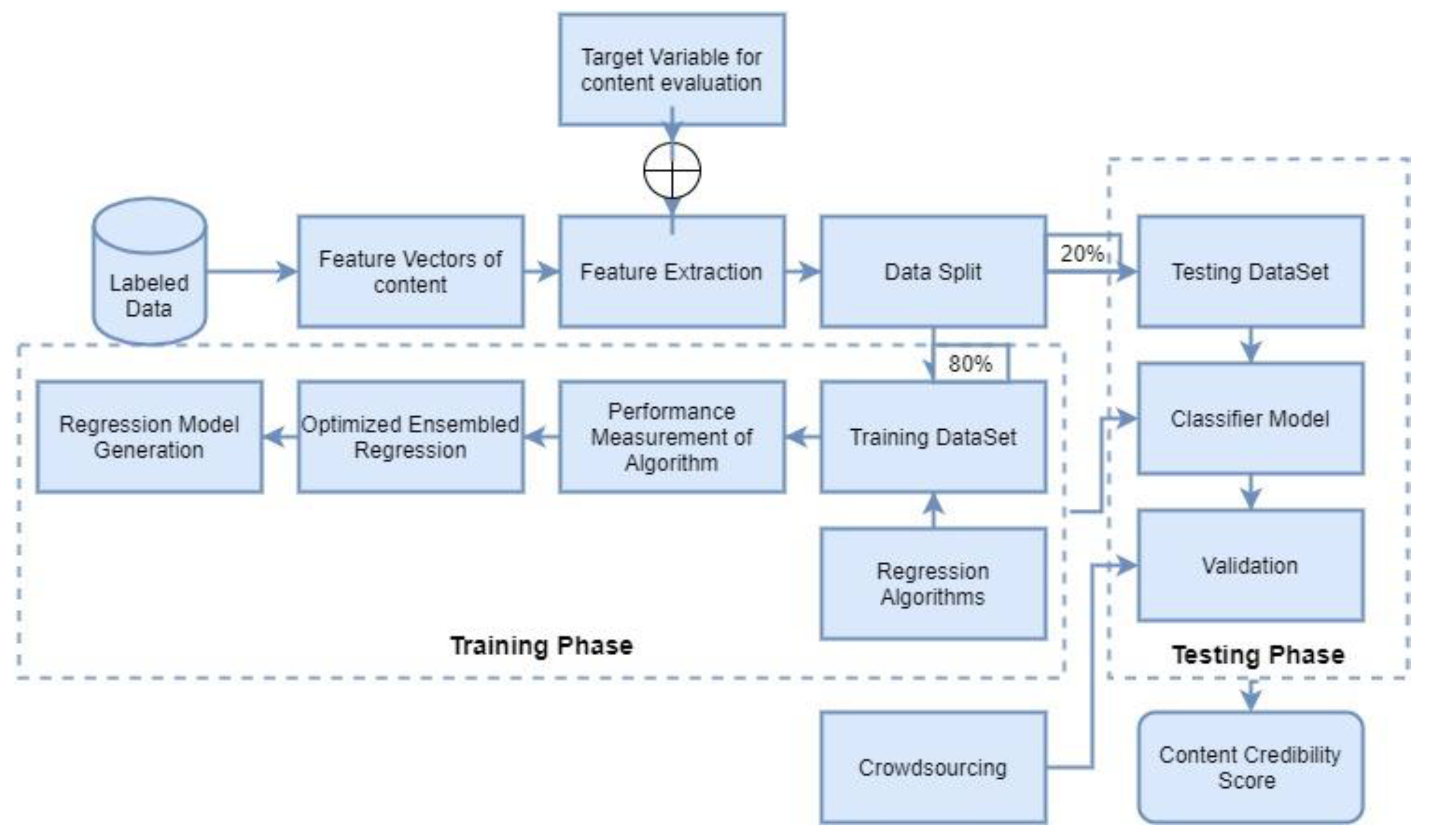
3.3. Regression Algorithm
3.4. Ensemble Regression
3.5. Error Loss Calculation
3.6. Optimization
3.7. Credibility Score
4. Methodology
4.1. Problem Formulation
- Let x [ … ] be the feature vector
- Where n is the total number of features
- Let y be the target variable
- Let D = (X, Y) be the dataset, where X = []
- Where i is sample number and j is feature index. i ∈ [1, m] j ∈ [1, n]
- m is equal to the number of samples and n is equal to the number of features
- Here, is the value of the jth feature in the ith sample.
- Y = []
- Where i is the sample number. i ∈ [1, m].
- m is equal to the number of samples and n is equal to the number of features
- Here, is the value of target variable y for ith sample
4.2. Explanation about Stacking in the Ensemble
4.3. Algorithm
| Algorithm 1: Content credibility using Fair Ensemble Regression with Optimization (FERMO) |
| Step 1: Training Models—Train k base regression models (M = M1, M2, …, Mk) using training sets X and Target Output Y |
| Sample. |
| Step 2: Error Calculation—Objective Function is defined as follows
|
| is a regularization parameter used to control the selected value of by an optimization algorithm. |
| Step 3: Minimization Optimization problem can be defined as follows
|
| To obtain the values of by solving the equation mentioned above |
| Step 4: Testing the dataset |
| For test dataset [ …] predicted value of as follows
|
| where is the predicted value for sample by base model |
5. Regression Loss
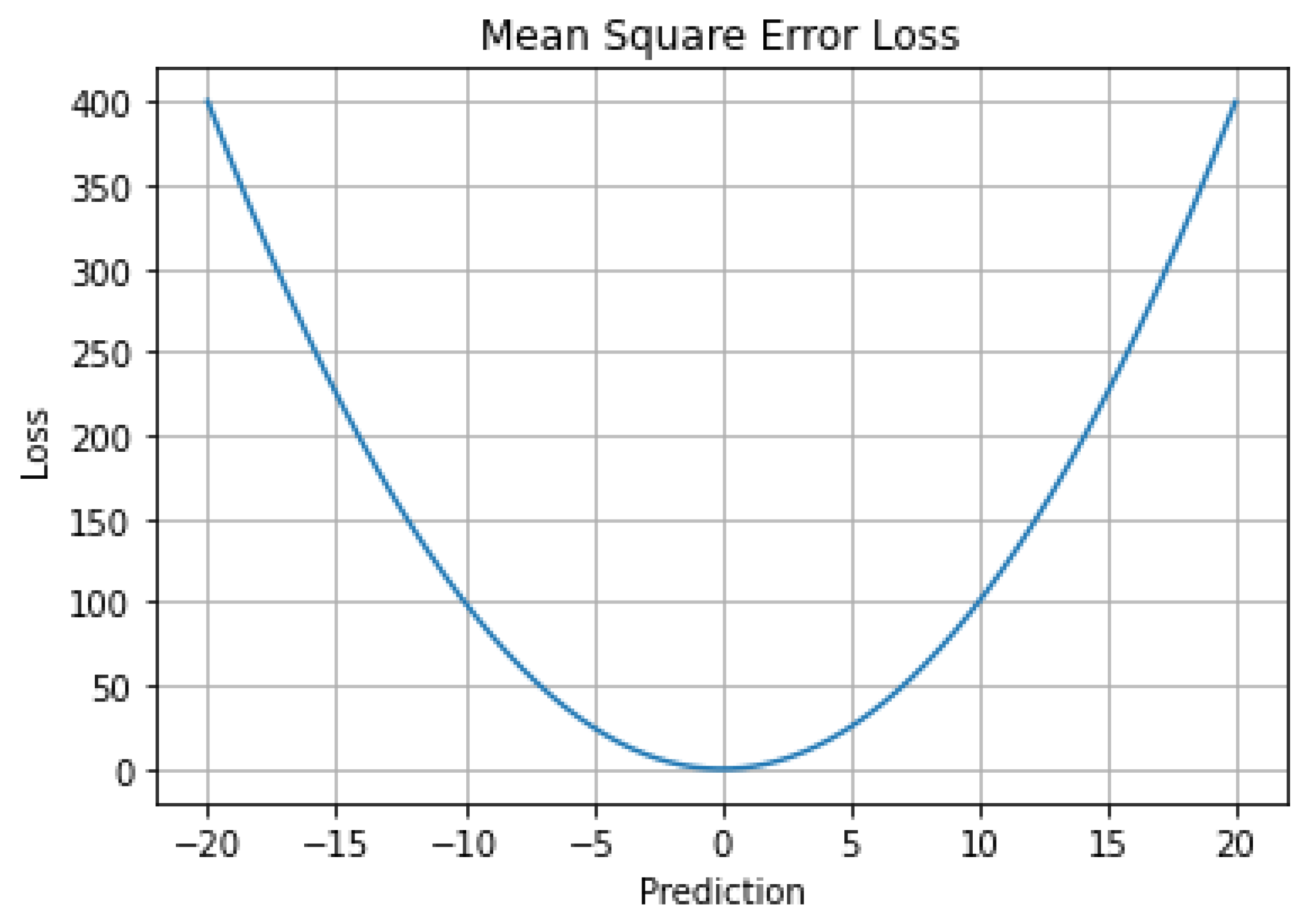
5.1. Mean Squared Error (MSE) L2 Loss, Quadratic Loss
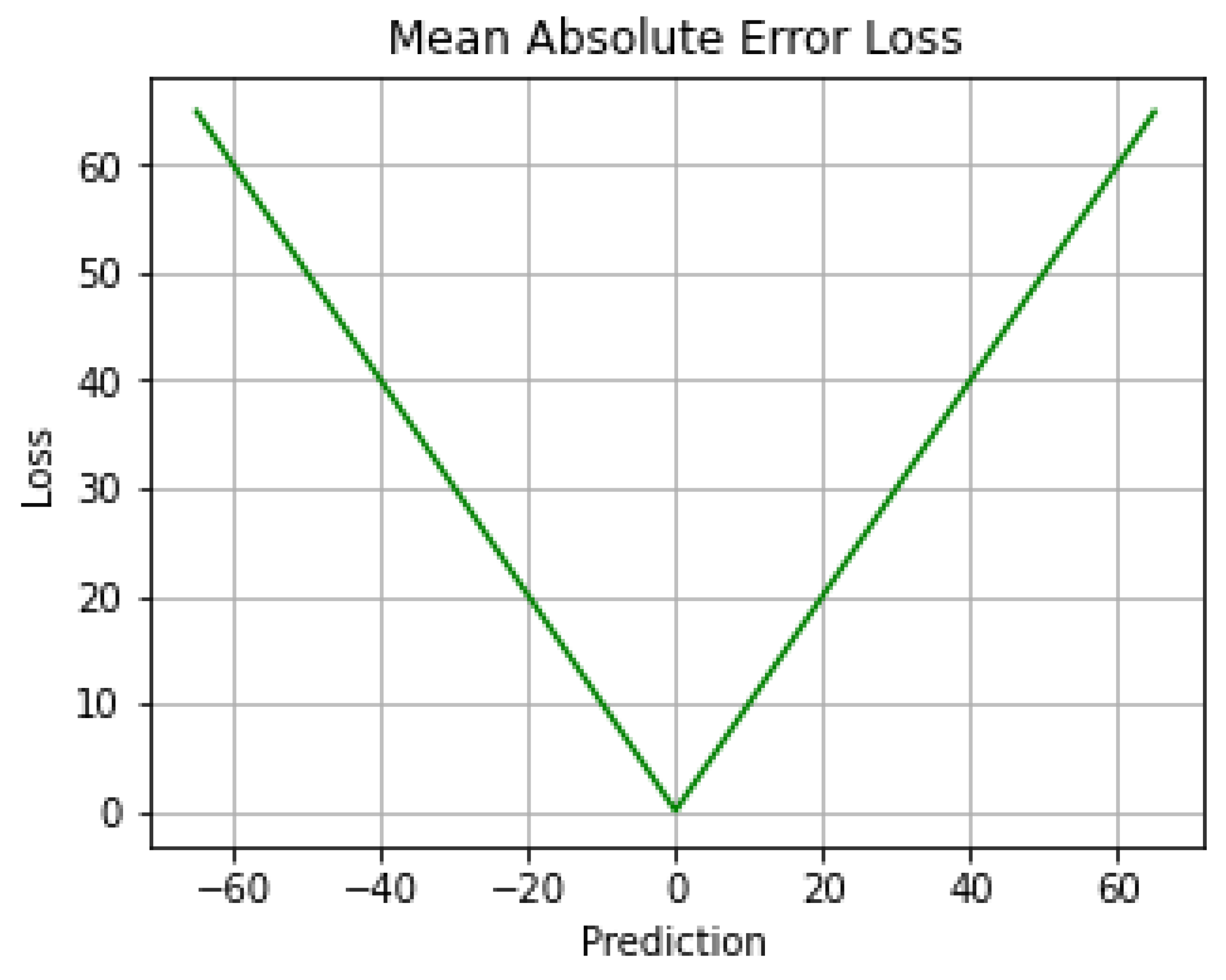
5.2. Mean Absolute Error (MAE)
5.3. Huber Loss Function, Smooth Mean Absolute Error
5.4. LogCosh Loss
5.5. Quantile Loss
6. Results
6.1. Mean Squared Error (MSE)
6.2. Mean Absolute Error (MAE)
6.3. Huber Loss Function
6.4. Mean Square Error Loss & Mean Absolute Error Loss
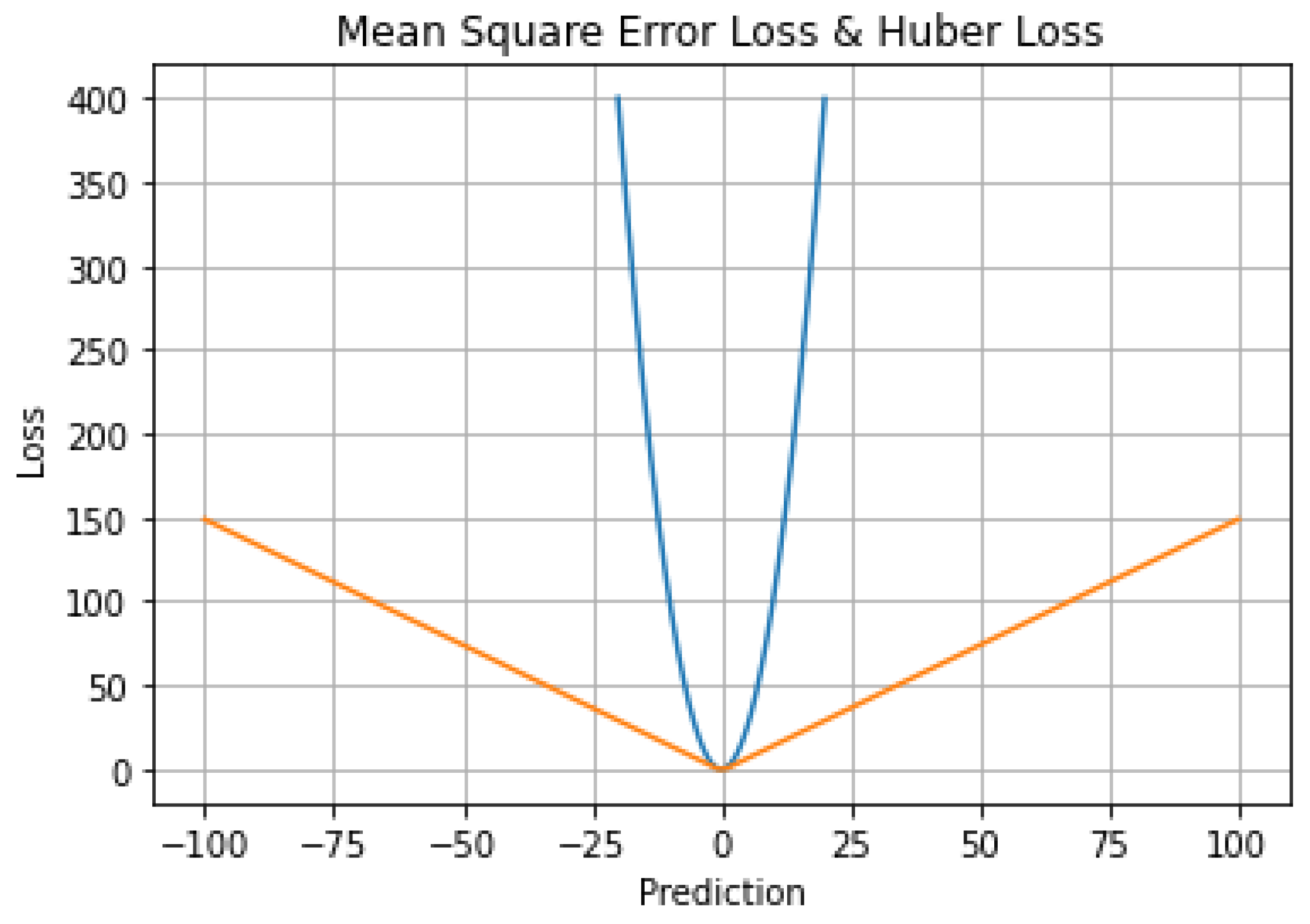
6.5. Mean Square Error Loss & Huber Loss
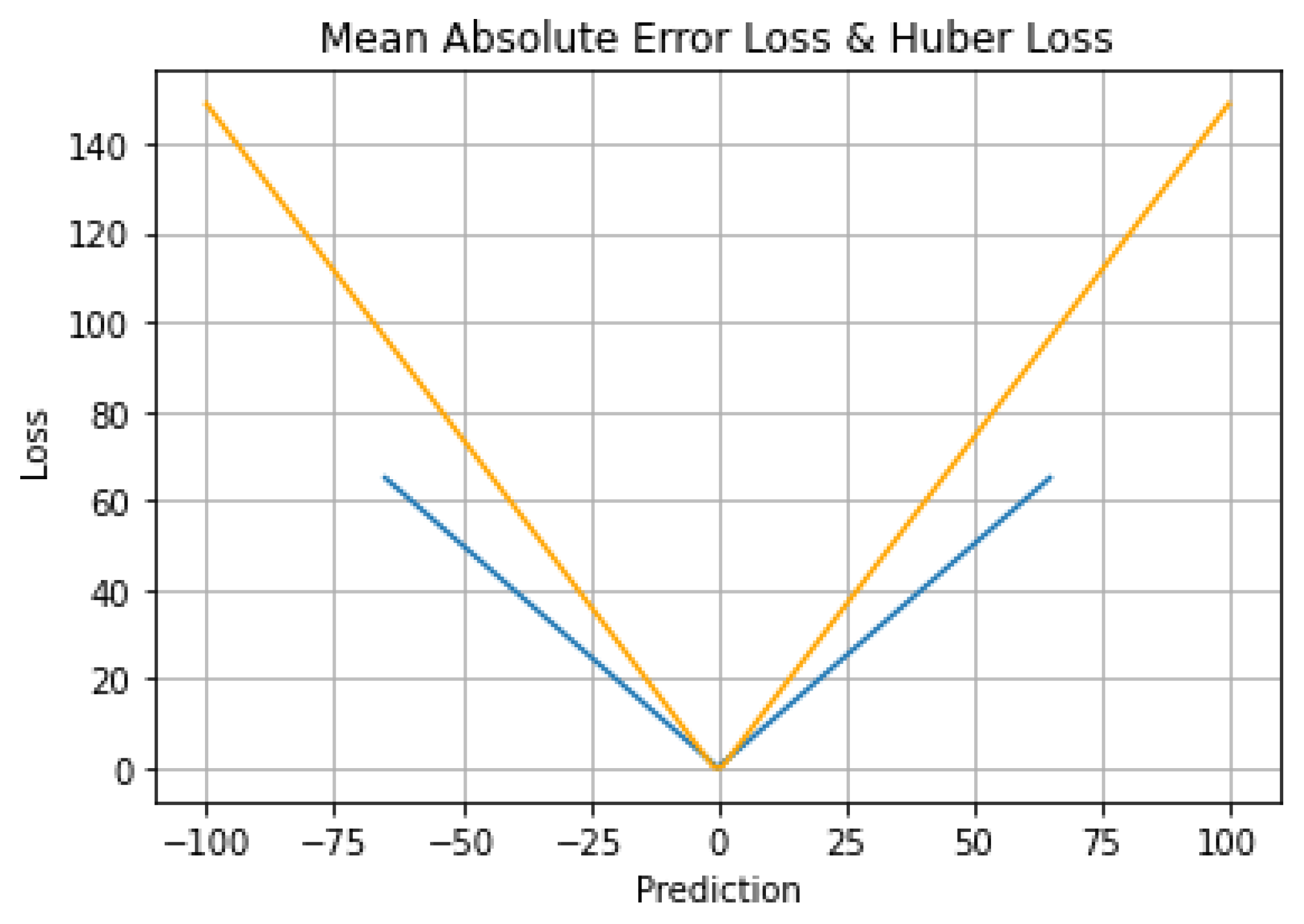
6.6. Mean Absolute Error Loss & Huber Loss
6.7. Mean Square Error Loss, Mean Absolute Error Loss & Huber Loss
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Verma, P.K.; Agrawal, P.; Amorim, I.; Prodan, R. WELFake: Word Embedding Over Linguistic Features for Fake News Detection. IEEE Trans. Comput. Soc. Syst. 2021, 8, 881–893. [Google Scholar] [CrossRef]
- Kaushal, V.; Vemuri, K. Clickbait—Trust and Credibility of Digital News. IEEE Trans. Technol. Soc. 2021, 2, 146–154. [Google Scholar] [CrossRef]
- Zhou, C.; Li, K.; Lu, Y. Linguistic characteristics and the dissemination of misinformation in social media: The moderating effect of information richness. Inf. Process. Manag. 2021, 58, 102679. [Google Scholar] [CrossRef]
- Gehrau, V.; Fujarski, S.; Lorenz, H.; Schieb, C.; Blöbaum, B. The Impact of Health Information Exposure and Source Credibility on COVID-19 Vaccination Intention in Germany. Int. J. Environ. Res. Public Health 2021, 18, 4678. [Google Scholar] [CrossRef] [PubMed]
- Purba, K.R.; Asirvatham, D.; Murugesan, R.K. Instagram Post Popularity Trend Analysis and Prediction using Hashtag, Image Assessment, and User History Features. Int. Arab. J. Inf. Technol. 2021, 18, 85–94. [Google Scholar]
- Daowd, A.; Hasan, R.; Eldabi, T.; Rafiul-Shan, P.M.; Cao, D.; Kasemsarn, N. Factors affecting eWOM credibility, information adoption and purchase intention on Generation Y: A case from Thailand. J. Enterp. Inf. Manag. 2021, 34, 838–859. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- Zheng, Q.; Qu, S. Credibility Assessment of Mobile Social Networking Users Based on Relationship and Information Interactions: Evidence From China. IEEE Access 2020, 8, 99519–99527. [Google Scholar] [CrossRef]
- Flanagin, A.J.; Winter, S.; Metzger, M.J. Making sense of credibility in complex information environments: The role of message sidedness, information source, and thinking styles in credibility evaluation online. Inf. Commun. Soc. 2020, 23, 1038–1056. [Google Scholar] [CrossRef]
- Tully, M.; Vraga, E.K.; Bode, L. Designing and Testing News Literacy Messages for Social Media. Mass Commun. Soc. 2019, 23, 22–46. [Google Scholar] [CrossRef]
- Liu, B.F.; Austin, L.; Lee, Y.-I.; Jin, Y.; Kim, S. Telling the tale: The role of narratives in helping people respond to crises. J. Appl. Commun. Res. 2020, 48, 328–349. [Google Scholar] [CrossRef]
- Wu, H.C.; Greer, A.; Murphy, H. Perceived Stakeholder Information Credibility and Hazard Adjustments: A Case of Induced Seismic Activities in Oklahoma Information credibility, disaster risk perception and evacuation willingness of rural households in China. Nat. Hazards 2020, 103, 2865–2882. [Google Scholar]
- Setiawan, E.B.; Widyantoro, D.H.; Surendro, K. Participation and Information Credibility Assessment Measuring information credibility in social media using a combination of user profile and message content dimensions. Int. J. Electr. Comput. Eng. (IJECE) 2020, 10, 3537–3549. [Google Scholar] [CrossRef]
- Hu, S.; Kumar, A.; Al-Turjman, F.; Gupta, S.; Seth, S. Reviewer Credibility and Sentiment Analysis Based User Profile Modelling for Online Product Recommendation. Special Section on Cloud-Fog-edge computing in cyber-physical-social systems (CPSS). IEEE Access 2020, 8, 26172–26189. [Google Scholar] [CrossRef]
- Alsmadi, I.; O’Brien, M.J. How Many Bots in Russian Troll Tweets? Inf. Process. Manag. 2020, 57, 102303. [Google Scholar] [CrossRef]
- Li, H. Communication for Coproduction: Increasing Information Credibility to Fight the Coronavirus. Am. Rev. Public Adm. 2020, 50, 692–697. [Google Scholar] [CrossRef]
- Karande, H.; Walambe, R.; Benjamin, V.; Kotecha, K.; Raghu, T.S. Stance detection with BERT embeddings for credibility analysis of information on social media. PeerJ Comput. Sci. 2021, 7, e467. [Google Scholar] [CrossRef]
- Beldar, K.K.; Gayakwad, M.D.; Beldar, M.K. Optimizing Analytical Queries on Probabilistic Databases with Unmerged Duplicates Using MapReduce. Int. J. Innov. Res. Comput. Commun. Eng. 2016, 4, 9651–9659. [Google Scholar]
- Shah, A.A.; Ravana, S.D.; Hamid, S.; Ismail, M.A. Web Pages Credibility Scores for Improving Accuracy of Answers in Web-Based Question Answering Systems. IEEE Access 2020, 8, 141456–141471. [Google Scholar] [CrossRef]
- Gayakwad, M. VLAN implementation using IP over ATM. J. Eng. Res. Stud. 2011, 186–192. [Google Scholar]
- Shevale, K.; Bhole, G. Probabilistic Threshold Query on Uncertain Data using SVM. Int. J. Adv. Res. Comput. Sci. 2017, 8, 1967–1969. [Google Scholar]
- Keshavarz, H. Evaluating credibility of social media information: Current challenges, research directions and practical criteria. Inf. Discov. Deliv. 2020, 49, 269–279. [Google Scholar] [CrossRef]
- Faraon, M.; Jaff, A.; Nepomuceno, L.P.; Villavicencio, V. Fake News and Aggregated Credibility: Conceptualizing a Co-Creative Medium for Evaluation of Sources Online. Int. J. Ambient. Comput. Intell. 2020, 11, 93–117. [Google Scholar] [CrossRef]
- Yan, W.; Huang, J. Microblogging reposting mechanism: An information adoption perspective. Tsinghua Sci. Technol. 2014, 19, 531–542. [Google Scholar] [CrossRef]
- Mahmood, S.; Ghani, A.; Daud, A.; Shamshirband, S. Reputation-Based Approach Toward Web Content Credibility Analysis. IEEE Access 2019, 7, 139957–139969. [Google Scholar] [CrossRef]
- Liu, B.; Terlecky, P.; Bar-Noy, A.; Govindan, R.; Neely, M.J.; Rawitz, D. Optimizing information credibility in social swarming applications. IEEE Trans. Parallel Distrib. Syst. 2011, 23, 1147–1158. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Fan, L.; Zhang, C.; Wang, H.; Wang, R. Dynamical Credibility Assessment of Privacy-Preserving Strategy for Opportunistic Mobile Crowd Sensing. Transl. Content Min. 2018, 6, 37430–37443. [Google Scholar] [CrossRef]
- Khan, J.; Lee, S. Implicit User Trust Modeling Based on User Attributes and Behavior in Online Social Networks. IEEE Access 2019, 7, 142826–142842. [Google Scholar] [CrossRef]
- Gayakwad, M.D.; Phulpagar, B.D. Research Article Review on Various Searching Methodologies and Comparative Analysis for Re-Ranking the Searched Results. Int. J. Recent Sci. Res. 2013, 4, 1817–1820. [Google Scholar]
- Liu, Y.; Xu, S. Detecting Rumors Through Modeling, Information Propagation Networks in a Social Media Environment. IEEE Trans. Comput. Soc. Syst. 2016, 3, 46–62. [Google Scholar] [CrossRef] [Green Version]
- Weng, J.; Shen, Z.; Miao, C.; Goh, A.; Leung, C. Credibility: How Agents Can Handle Unfair Third-Party Testimonies in Computational Trust Models. IEEE Trans. Knowl. Data Eng. 2009, 22, 1286–1298. [Google Scholar] [CrossRef]
- Alrubaian, M.; Al-Qurishi, M.; Alamri, A.; Al-Rakhami, M.; Hassan, M.M.; Fortino, G. Credibility in Online Social Networks: A Survey. IEEE Access 2018, 7, 2828–2855. [Google Scholar] [CrossRef]
- Beldar, K.K.; Gayakwad, M.D.; Bhattacharyya, D.; Kim, T.H. A Comparative Analysis on Contingence Structured Data Methodologies. Int. J. Softw. Eng. Its Appl. 2016, 10, 13–22. [Google Scholar] [CrossRef]
- Boukhari, M.; Gayakwad, M. An Experimental Technique on Fake News Detection in Online Social Media. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 526–530. [Google Scholar]
- Sato, K.; Wang, J.; Cheng, Z. Credibility Evaluation of Twitter-Based Event Detection by a Mixing Analysis of Heterogeneous Data. IEEE Transl. Content Min. 2019, 7, 1095–1106. [Google Scholar] [CrossRef]
- Das, R.; Kamruzzaman, J.; Karmakar, G. Opinion Formation in Online Social Networks: Exploiting Predisposition, Interaction, and Credibility. IEEE Trans. Comput. Soc. Syst. 2019, 6, 554–566. [Google Scholar] [CrossRef]
- McKnight, H.; Kacmar, C. Factors of Information Credibility for an Internet Advice Site. In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), Kauai, HI, USA, 4–7 January 2006. [Google Scholar]
- Gayakwad, M.; Patil, S. Assessment of Source, Medium, and Intercommunication for Assessing the Credibility of Content. In Proceedings of the 2021 International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Pune, India, 29–30 October 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Kang, B.; Höllerer, H.; Turk, M.; Yan, X.; O’Donovan, J. Analysis of Credibility in Microblogs. Master’s Thesis, University of California, Santa Barbara, CA, USA, 2012. [Google Scholar]
- Gayakwad, M.I.L.I.N.D.; Patil, S. Content Modelling for unbiased information analysis. Libr. Philos. Pract. 2020, 1–17. [Google Scholar]
- Yan, J.; Zhou, Y.; Wang, S.; Li, J. To share or not to Share? Credibility and Dissemination of Electric Vehicle-Related Information on WeChat: A Moderated Dual-Process Model. IEEE Access 2019, 7, 46808–46821. [Google Scholar] [CrossRef]
- Organic Content Design. Available online: http://www.webxpedition.com/ (accessed on 9 November 2021).
- Gayakwad, M. Requirement Specific Search BDP. IJARCSSE 2013, 3, 121. [Google Scholar]
- Cai, Y.; Zhang, S.; Xia, H.; Fan, Y.; Zhang, H. A Privacy-Preserving Scheme for Interactive Messaging Over Online Social Networks. IEEE Internet Things J. 2020, 7, 6817–6827. [Google Scholar] [CrossRef]
- Topf, J. Introduction: Social Media and Medical Education Come of Age. Semin. Nephrol. 2020, 40, 247–248. [Google Scholar] [CrossRef]
- Mackiewicz, J.; Yeats, D. Product Review Users’ Perceptions of Review Quality: The Role of Credibility, Informativeness, and Readability. IEEE Trans. Dependable Secur. Comput. 2014, 57, 309–324. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Included | Excluded | Total | ||||
|---|---|---|---|---|---|---|
| n | Percent | n | Percent | n | Percent | |
| Review_Score | 1,130,017 | 100% | 0 | 0% | 1,130,017 | 100% |
| Variables | Cases | Values | |
|---|---|---|---|
| Incomplete Data | 0 | 0 | 0 |
| Complete Data | 100 | 1,130,017 | 3,390,051 |
| Features | Data Type | Categorical | Numerical Direct | Derived |
|---|---|---|---|---|
| LINK | String | No | No | No |
| REVIEW | String | No | No | No |
| TOP_CRITIQUE | Boolean | Yes | Yes | No |
| PUBLISHER | String | No | No | No |
| REVIEW_TYPE | Boolean | Yes | No | Yes |
| REVIEW_DATE | Date | No | No | No |
| REVIEW_SCORE | Float | Yes | Yes | Yes |
| CRITIQUE_NAME | String | No | No | No |
| Features | Min | Max | Mean | Std Dev |
|---|---|---|---|---|
| LINK | 556 | 17,992 | 445 | 167 |
| REVIEW | 0 | 1 | 0.688 | 0.233 |
| TOP_CRITIQUE | 2 | 12 | 0.661 | 0.365 |
| PUBLISHER | 0 | 1 | 0.598 | 0.457 |
| REVIEW_TYPE | 252 | 316 | 227 | 123 |
| REVIEW_DATE | 1 | 1 | 0.856 | 0.036 |
| REVIEW_SCORE | 1 | 1 | 1 | Yes |
| CRITIQUE_NAME | 1 | 1 | 0.775 | No |
| Sr. No. | Algorithm | Accuracy in % |
|---|---|---|
| 1 | Linear Regression | 65 |
| 2 | Lasso Regression | 67 |
| 3 | Ridge Regression | 66 |
| 4 | Decision Tree | 71 |
| Sr. No. | Algorithm | Accuracy in % |
|---|---|---|
| 1 | XGBoost | 86 |
| 2 | Gradient Boost | 84.22 |
| 3 | Adaboost Regressor | 79 |
| 4 | Random Forest | 81 |
| 5 | Bagging Regressor | 83.52 |
| 6 | FERMO | 96.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gayakwad, M.; Patil, S.; Kadam, A.; Joshi, S.; Kotecha, K.; Joshi, R.; Pandya, S.; Gonge, S.; Rathod, S.; Kadam, K.; et al. Credibility Analysis of User-Designed Content Using Machine Learning Techniques. Appl. Syst. Innov. 2022, 5, 43. https://doi.org/10.3390/asi5020043
Gayakwad M, Patil S, Kadam A, Joshi S, Kotecha K, Joshi R, Pandya S, Gonge S, Rathod S, Kadam K, et al. Credibility Analysis of User-Designed Content Using Machine Learning Techniques. Applied System Innovation. 2022; 5(2):43. https://doi.org/10.3390/asi5020043
Chicago/Turabian StyleGayakwad, Milind, Suhas Patil, Amol Kadam, Shashank Joshi, Ketan Kotecha, Rahul Joshi, Sharnil Pandya, Sudhanshu Gonge, Suresh Rathod, Kalyani Kadam, and et al. 2022. "Credibility Analysis of User-Designed Content Using Machine Learning Techniques" Applied System Innovation 5, no. 2: 43. https://doi.org/10.3390/asi5020043
APA StyleGayakwad, M., Patil, S., Kadam, A., Joshi, S., Kotecha, K., Joshi, R., Pandya, S., Gonge, S., Rathod, S., Kadam, K., & Shelke, M. (2022). Credibility Analysis of User-Designed Content Using Machine Learning Techniques. Applied System Innovation, 5(2), 43. https://doi.org/10.3390/asi5020043