
ViTFER: Facial Emotion Recognition with Vision Transformers



Abstract
:1. Introduction
2. Related Work
2.1. Emotion Recognition Methodologies Based on Machine Learning
2.2. Emotion Recognition Methodologies Based on Deep Learning
3. Data Integration/Augmentation and Analysis
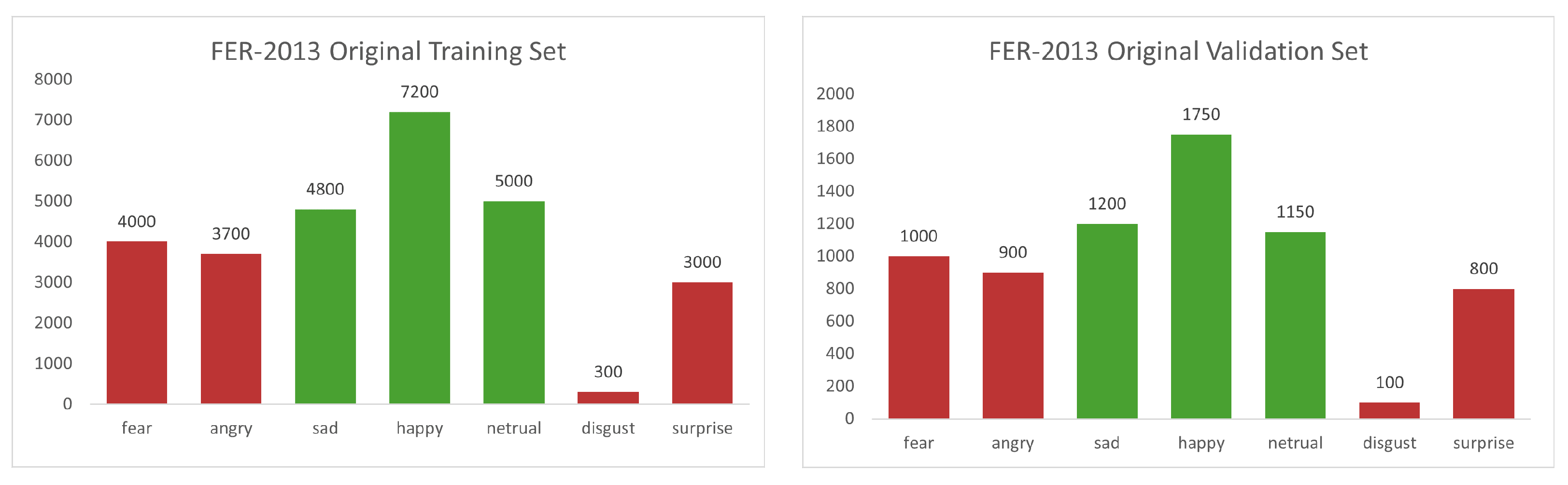
Datasets
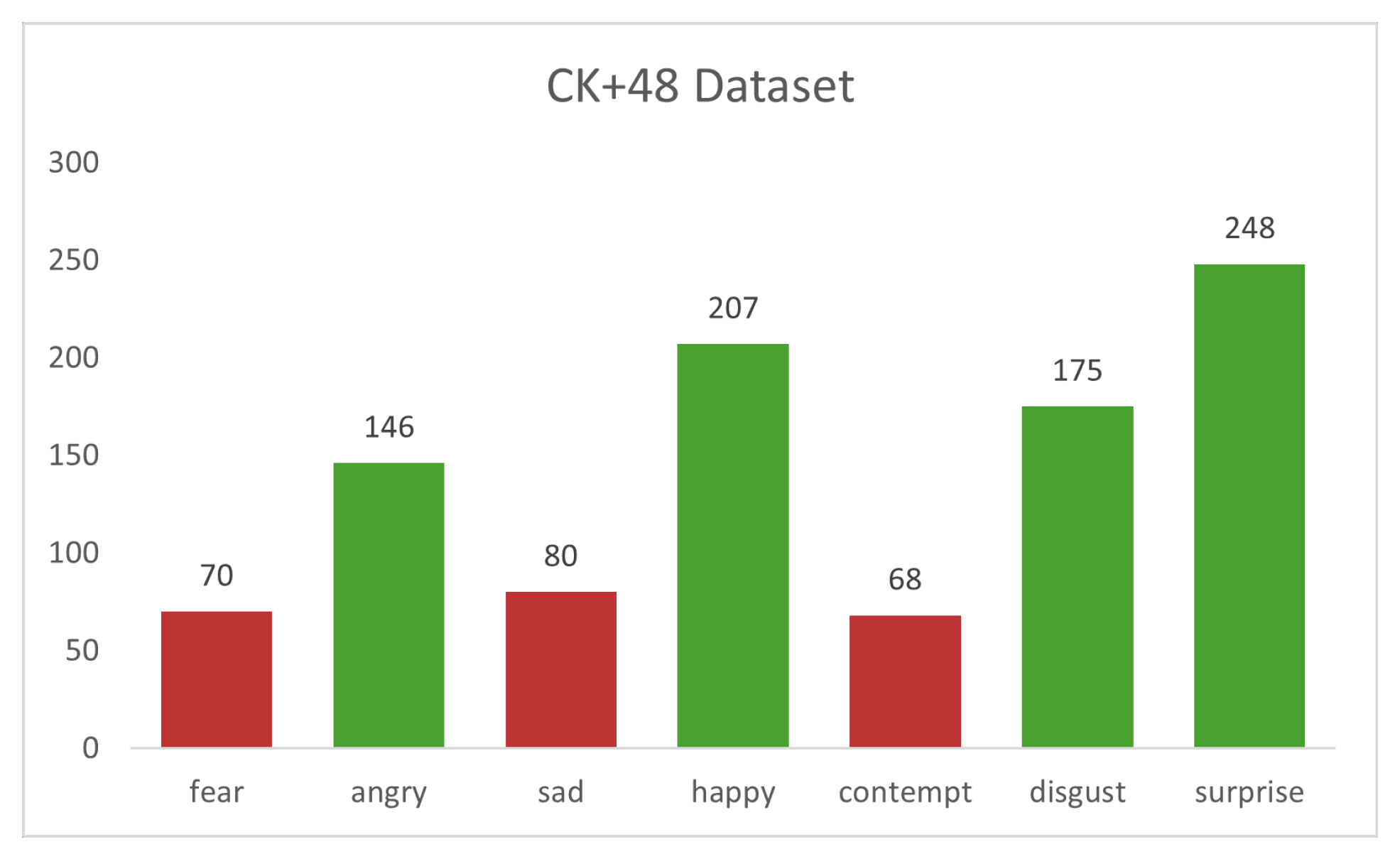
- CK+48: CK+48 is a small dataset composed of 981 images in seven classes (fear, disgust, sad, happy, neutral, surprise, angry). Images are 48 × 48 in size with a grey-scaled color palette as shown in Figure 3. The classes’ variations and feature distributions are helpful in the merging phase for other classes to obtain a good distribution and normalize the amount of data variation. Generally, images taken from video frames did not have much variation, and the total number of elements is negligible compared to other datasets. Compared with the FER-2013, images are in frontal view with a clean pattern for facial expression.
- AffectNet: The AffectNet dataset [28] has samples of different sizes and high-quality images in gray-scale or color in the RGB range. It has eight different classes (surprise, angry, sad, contempt, disgust, fear, neutral, and happy). As of the FER-2013, there is a division between the validation and training sets, but subfolders are almost balanced. We will exploit this dataset for the training, testing, and validation splitting, given the validation set in the same subfolder for the final set, and balance original training samples between the final testing and training subset for some experiments. In the last experiments, with a hybrid validation set, we will use the original AffectNet validation set in the testing phase.
4. Preprocessing
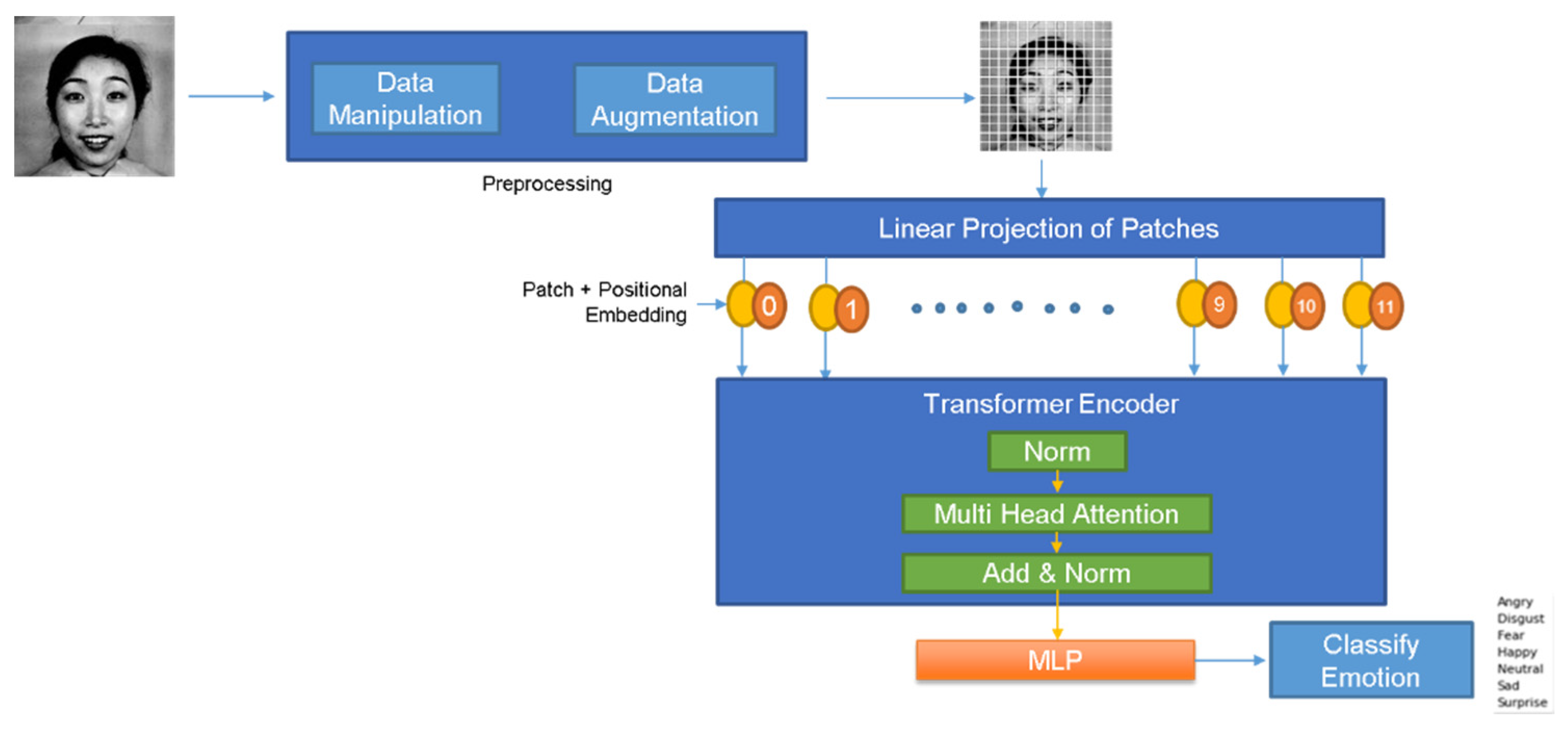
4.1. Data Manipulation
4.2. Data Augmentation
5. Models
5.1. Vision Transformers
5.1.1. Vision Transformer Base Structure
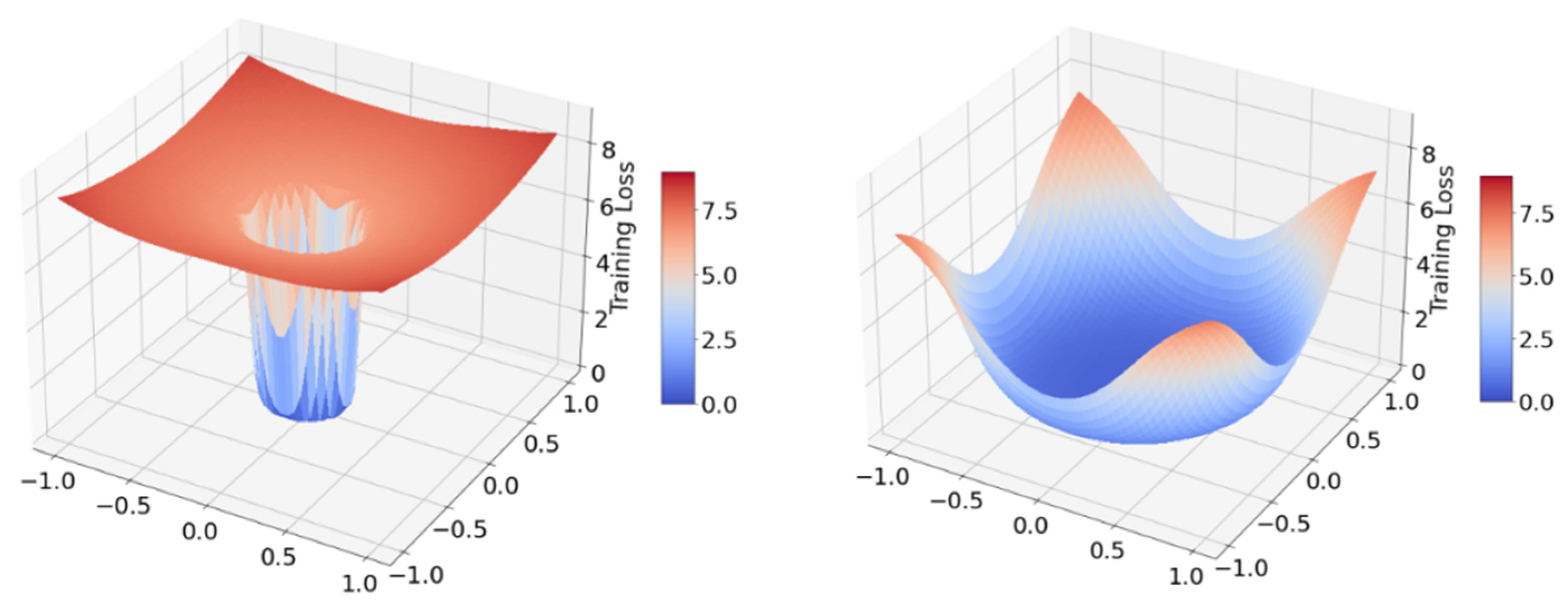
5.1.2. Vision Transformer with Sharpness Minimizer
5.2. Experiments
5.3. Results of Experiments and Evaluation
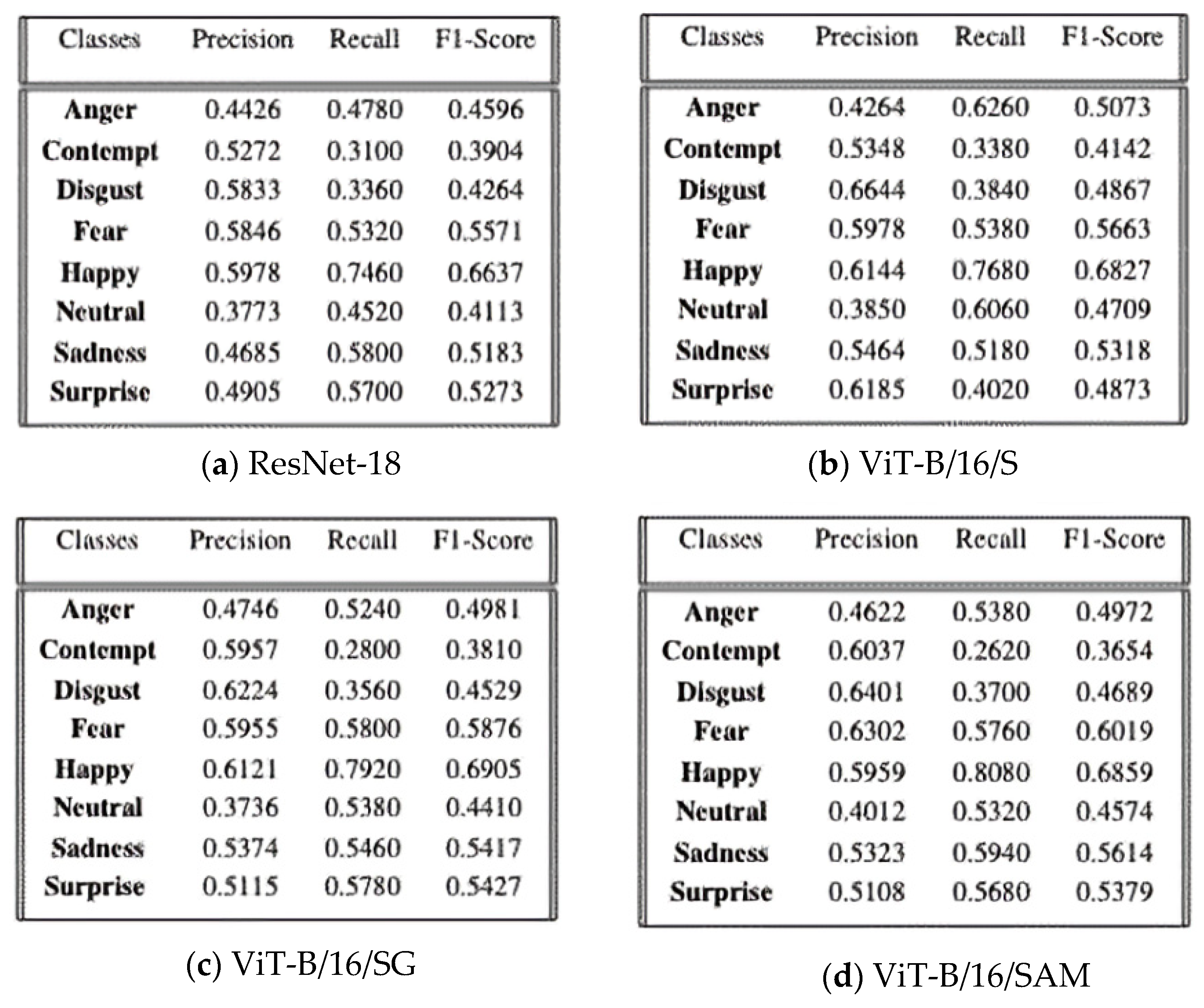
5.3.1. Analysis of Metrics for Various Models
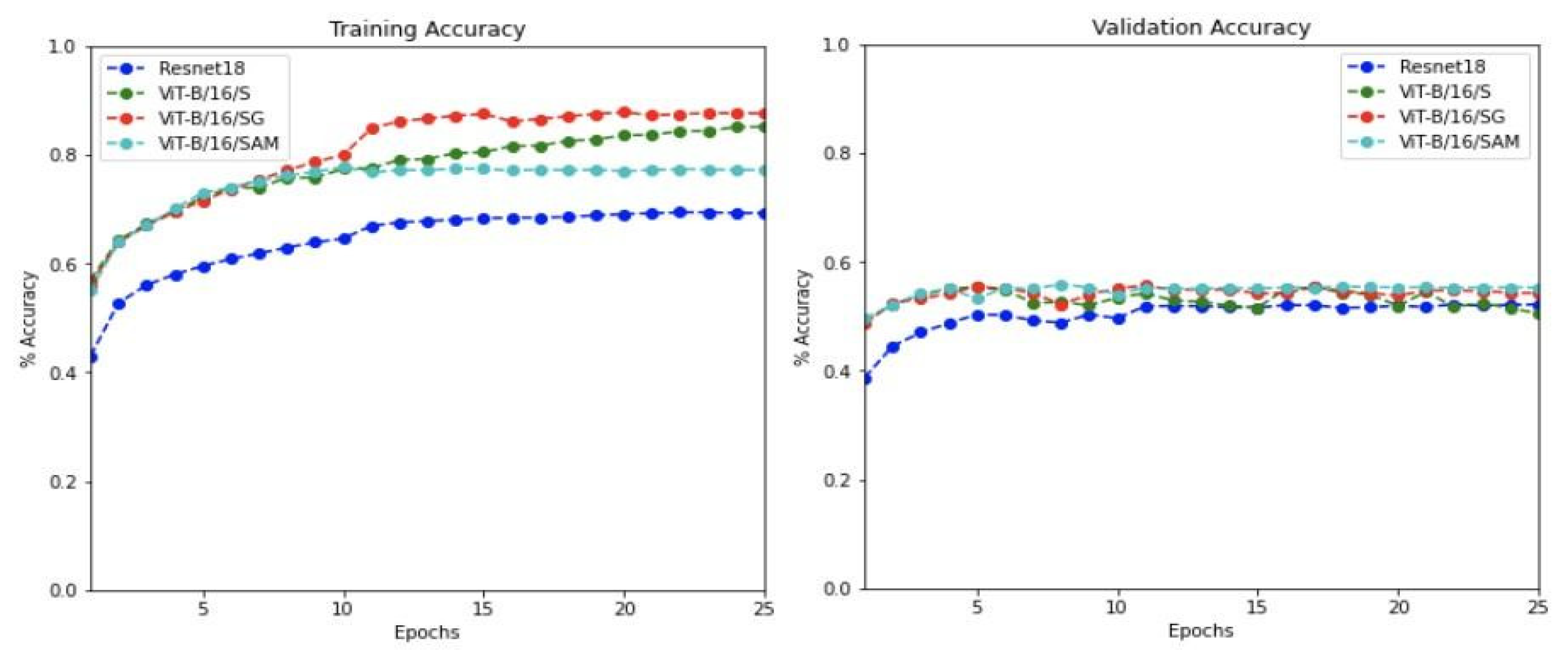
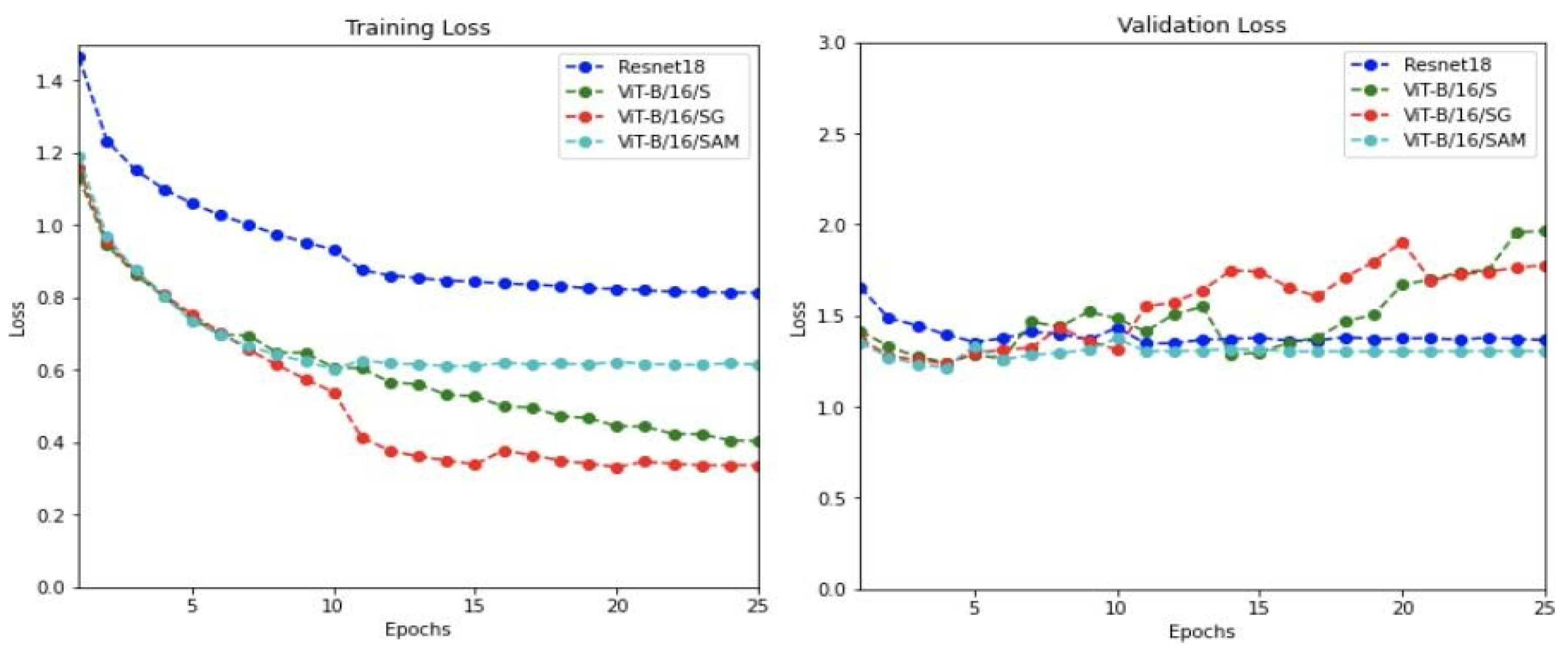
5.3.2. Training and Validation Evaluation
5.3.3. Metric distribution on AVFER testing
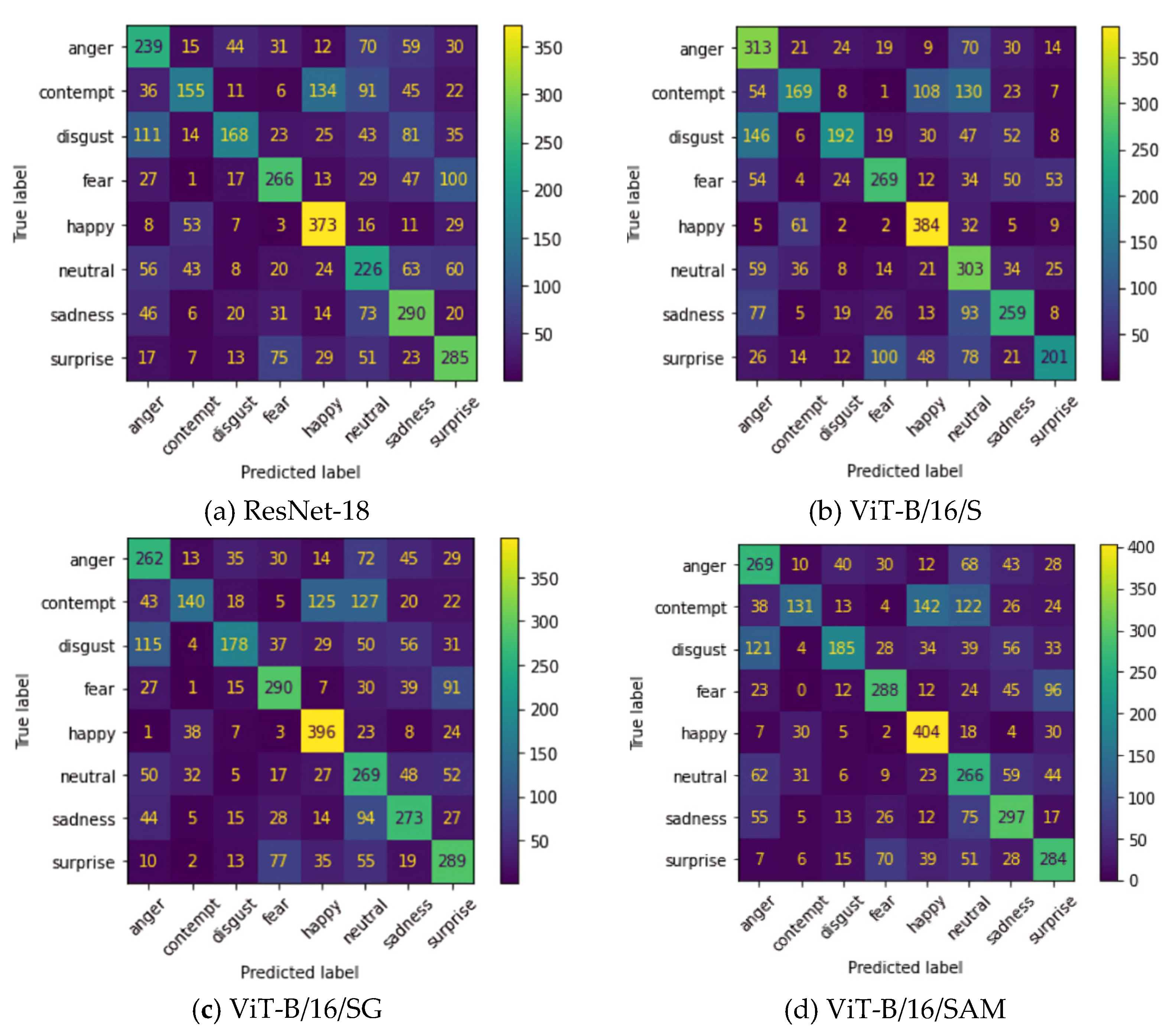
5.3.4. Confusion Matrices in AVFER Testing
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ekman, P. Cross-Cultural Studies of Facial Expression. In Darwin and Facial Expression; Malor Books: Los Altos, CA, USA, 2006; pp. 169–220. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [PubMed]
- Fridlund, A.J. Human facial expression: An evolutionary view. Nature 1995, 373, 569. [Google Scholar]
- Avila, A.R.; Akhtar, Z.; Santos, J.F.; O’Shaughnessy, D.; Falk, T.H. Feature Pooling of Modulation Spectrum Features for Improved Speech Emotion Recognition in the Wild. IEEE Trans. Affect. Comput. 2021, 12, 177–188. [Google Scholar] [CrossRef]
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal Emotion Recognition in Response to Videos. IEEE Trans. Affect. Comput. 2012, 3, 211–223. [Google Scholar] [CrossRef]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-Visual Emotion Recognition in Video Clips. IEEE Trans. Affect. Comput. 2019, 10, 60–75. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System, 2nd ed.; Weidenfeld and Nicolson: London, UK, 1977. [Google Scholar]
- Cohn, F.J.; Zlochower, A. A computerized analysis of facial expression: Feasibility of automated discrimination. Am. Psychol. Soc. 1995, 2, 6. [Google Scholar]
- Liew, C.F.; Yairi, T. Facial Expression Recognition and Analysis: A Comparison Study of Feature Descriptors. IPSJ Trans. Comput. Vis. Appl. 2015, 7, 104–120. [Google Scholar] [CrossRef]
- Ko, B.C. A Brief Review of Facial Emotion Recognition Based on Visual Information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial Expression Recognition: A Survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020, 1–20. [Google Scholar] [CrossRef]
- Feng, X.; Pietikainen, M.; Hadid, A. Facial expression recognition based on local binary patterns. Pattern Recognit. Image Anal. 2007, 17, 592–598. [Google Scholar] [CrossRef]
- Xiao, X.Q.; Wei, J. Application of wavelet energy feature in facial expression recognition. In Proceedings of the 2007 International Workshop on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 16–18 April 2007; pp. 169–174. [Google Scholar]
- Lee, C.-C.; Shih, C.-Y.; Lai, W.-P.; Lin, P.-C. An improved boosting algorithm and its application to facial emotion recognition. J. Ambient Intell. Humaniz. Comput. 2012, 3, 11–17. [Google Scholar] [CrossRef]
- Chang, C.-Y.; Huang, Y.-C. Personalized facial expression recognition in indoor environments. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Alshamsi, H.; Kepuska, V.; Meng, H. Real-time automated facial expression recognition app development on smartphones. In Proceedings of the 2017 8th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 3–5 October 2017; pp. 384–392. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on Local Binary Patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Pranav, E.; Kamal, S.; Chandran, C.S.; Supriya, M. Facial emotion recognition using deep convolutional neural network. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 317–320. [Google Scholar]
- Pons, G.; Masip, D. Supervised Committee of Convolutional Neural Networks in Automated Facial Expression Analysis. IEEE Trans. Affect. Comput. 2018, 9, 343–350. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, S.K.; Chellappa, R. FaceNet2ExpNet: Regularizing a deep face recognition net for expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 118–126. [Google Scholar]
- Li, J.; Huang, S.; Zhang, X.; Fu, X.; Chang, C.-C.; Tang, Z.; Luo, Z. Facial Expression Recognition by Transfer Learning for Small Datasets. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 895, pp. 756–770. [Google Scholar]
- Pandeya, Y.R.; Bhattarai, B.; Lee, J. Deep-Learning-Based Multimodal Emotion Classification for Music Videos. Sensors 2021, 21, 4927. [Google Scholar] [CrossRef]
- Shirian, A.; Tripathi, S.; Guha, T. Dynamic Emotion Modeling with Learnable Graphs and Graph Inception Network. IEEE Trans. Multimed. 2021, 24, 780–790. [Google Scholar] [CrossRef]
- Kosti, R.; Alvarez, J.M.; Recasens, A.; Lapedriza, A. Context-Based Emotion Recognition Using EMOTIC Dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2755–2766. [Google Scholar] [CrossRef]
- Dutta, S.; Ganapathy, S. Multimodal Transformer with Learnable Frontend and Self Attention for Emotion Recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6917–6921. [Google Scholar] [CrossRef]
- Wei, M.; Zheng, W.; Zong, Y.; Jiang, X.; Lu, C.; Liu, J. A Novel Micro-Expression Recognition Approach Using Attention-Based Magnification-Adaptive Networks. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2420–2424. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ma, F.; Sun, B.; Li, S. Facial expression recognition with visual transformers and attentional selective fusion. IEEE Trans. Affect. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Foret, P.; Kleiner, A.; Mobahi, H.; Neyshabur, B. Sharpness-aware Minimization for Efficiently Improving Generalization. arXiv 2022, arXiv:2010.01412. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Models Tested on the AVFER | |||
|---|---|---|---|---|
| ResNet-18 | ViT-B/16/S | ViT-B/16/SG | ViT-B/16/SAM | |
| 8-Class Accuracy | 0.5005 | 0.5225 | 0.5242 | 0.5310 |
| 7-Class Accuracy | 0.5277 | 0.5489 | 0.5591 | 0.5694 |
| Weighted Avg. Precision | 0.5090 | 0.5485 | 0.5404 | 0.5470 |
| Weighted Avg. Recall | 0.6005 | 0.6225 | 0.6242 | 0.6310 |
| Weighted Avg. F1-Score | 0.4943 | 0.5184 | 0.6169 | 0.6220 |
| # Train. Params | 11.7 M | 86.5 M | 86.5 M | 86.5 M |
| # FLOPS | 1.8 G | 17.5 G | 17.5 G | 17.5 G |
| No. of Epochs | Accuracy/Loss | ResNet-18 | ViT-B/16/S | ViT-B/16/SG | ViT-B/16/SAM |
|---|---|---|---|---|---|
| 5 | Training accuracy | 61.38 | 73.99 | 74.41 | 83.88 |
| Validation Accuracy | 50.43 | 55.42 | 55.81 | 55.14 | |
| Training loss | 10.50 | 7.09 | 7.12 | 7.15 | |
| Validation loss | 14.70 | 12.61 | 13.35 | 12.82 | |
| 10 | Training accuracy | 66.57 | 81.42 | 84.01 | 87.72 |
| Validation Accuracy | 52.16 | 55.71 | 56.30 | 55.24 | |
| Training loss | 8.90 | 5.06 | 4.67 | 6.24 | |
| Validation loss | 14.90 | 14.33 | 15.05 | 13.39 | |
| 15 | Training accuracy | 68.01 | 79.07 | 87.79 | 87.88 |
| Validation Accuracy | 52.26 | 56.01 | 54.94 | 55.29 | |
| Training loss | 8.49 | 4.12 | 3.63 | 6.27 | |
| Validation loss | 14.80 | 19.47 | 17.58 | 13.16 | |
| 20 | Training accuracy | 70.01 | 81.14 | 88.37 | 88.18 |
| Validation Accuracy | 53.85 | 54.28 | 54.65 | 55.45 | |
| Training loss | 8.35 | 5.14 | 3.41 | 6.20 | |
| Validation loss | 14.20 | 15.03 | 18.76 | 13.08 | |
| 25 | Training accuracy | 70.02 | 84.28 | 88.66 | 88.64 |
| Validation Accuracy | 53.89 | 53.98 | 55.52 | 56.22 | |
| Training loss | 8.27 | 3.97 | 3.63 | 6.05 | |
| Validation loss | 1.39 | 19.93 | 17.87 | 12.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaudhari, A.; Bhatt, C.; Krishna, A.; Mazzeo, P.L. ViTFER: Facial Emotion Recognition with Vision Transformers. Appl. Syst. Innov. 2022, 5, 80. https://doi.org/10.3390/asi5040080
Chaudhari A, Bhatt C, Krishna A, Mazzeo PL. ViTFER: Facial Emotion Recognition with Vision Transformers. Applied System Innovation. 2022; 5(4):80. https://doi.org/10.3390/asi5040080
Chicago/Turabian StyleChaudhari, Aayushi, Chintan Bhatt, Achyut Krishna, and Pier Luigi Mazzeo. 2022. "ViTFER: Facial Emotion Recognition with Vision Transformers" Applied System Innovation 5, no. 4: 80. https://doi.org/10.3390/asi5040080
APA StyleChaudhari, A., Bhatt, C., Krishna, A., & Mazzeo, P. L. (2022). ViTFER: Facial Emotion Recognition with Vision Transformers. Applied System Innovation, 5(4), 80. https://doi.org/10.3390/asi5040080