

Stock Market Prediction Using Deep Reinforcement Learning


Abstract
:1. Introduction
- The utilization of NLP to preprocess news and media data and discern market sentiments related to stocks. Fine-tuning BERT is employed in conjunction with TF-IDF to achieve maximum accuracy.
- Sourcing historical stock price datasets from reputable platforms such as S&P, Yahoo, NASDAQ, etc.
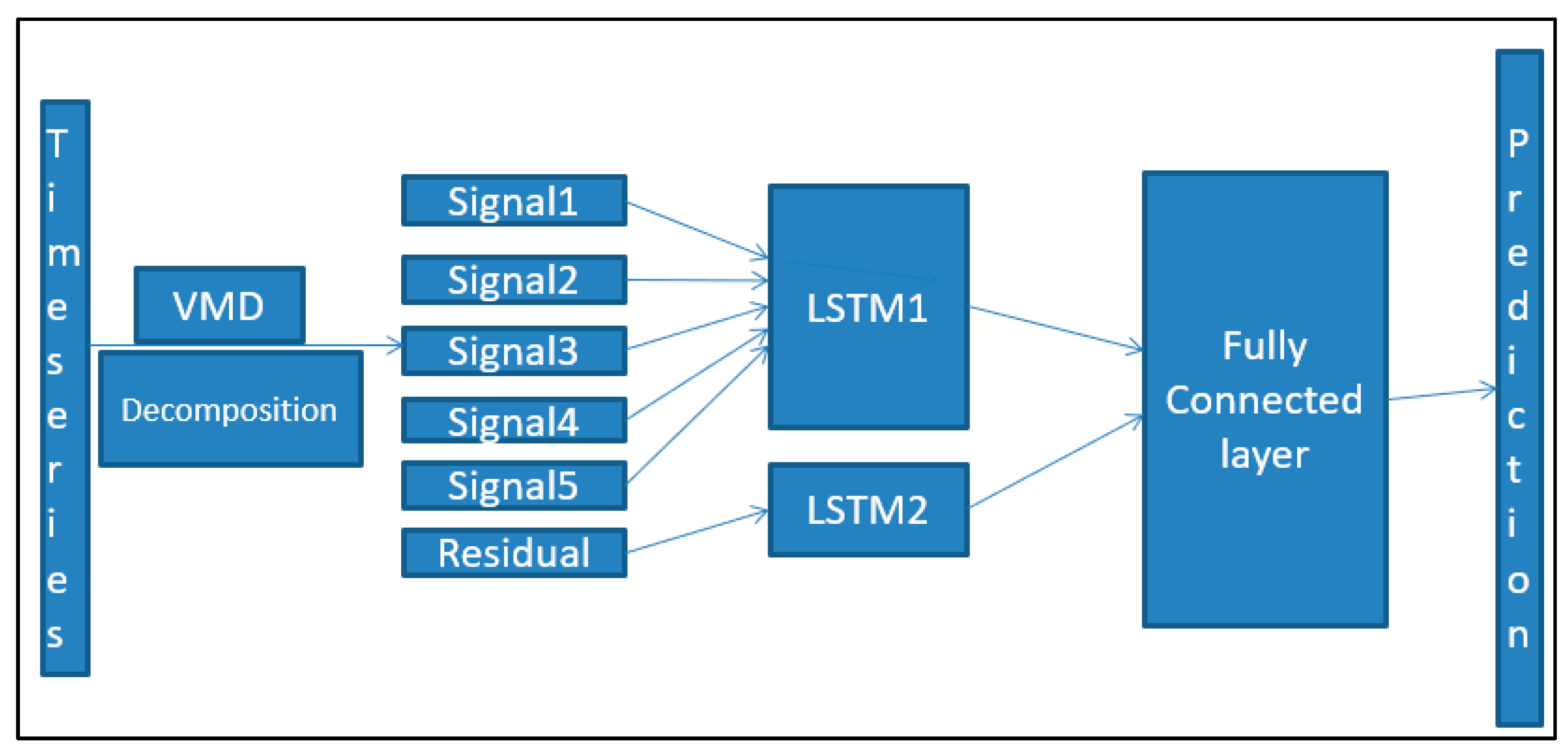
- Application of variation mode decomposition (VMD) for signal decomposition, followed by LSTM implementation to predict prices.
- Implementation of DRL, integrating NLP, historical data, and sentiment analysis from media sources to predict stock market prices for specific businesses based on agents and actions.
2. Related Work
3. Background
3.1. Deep Learning
3.2. Recurrent Neural Network
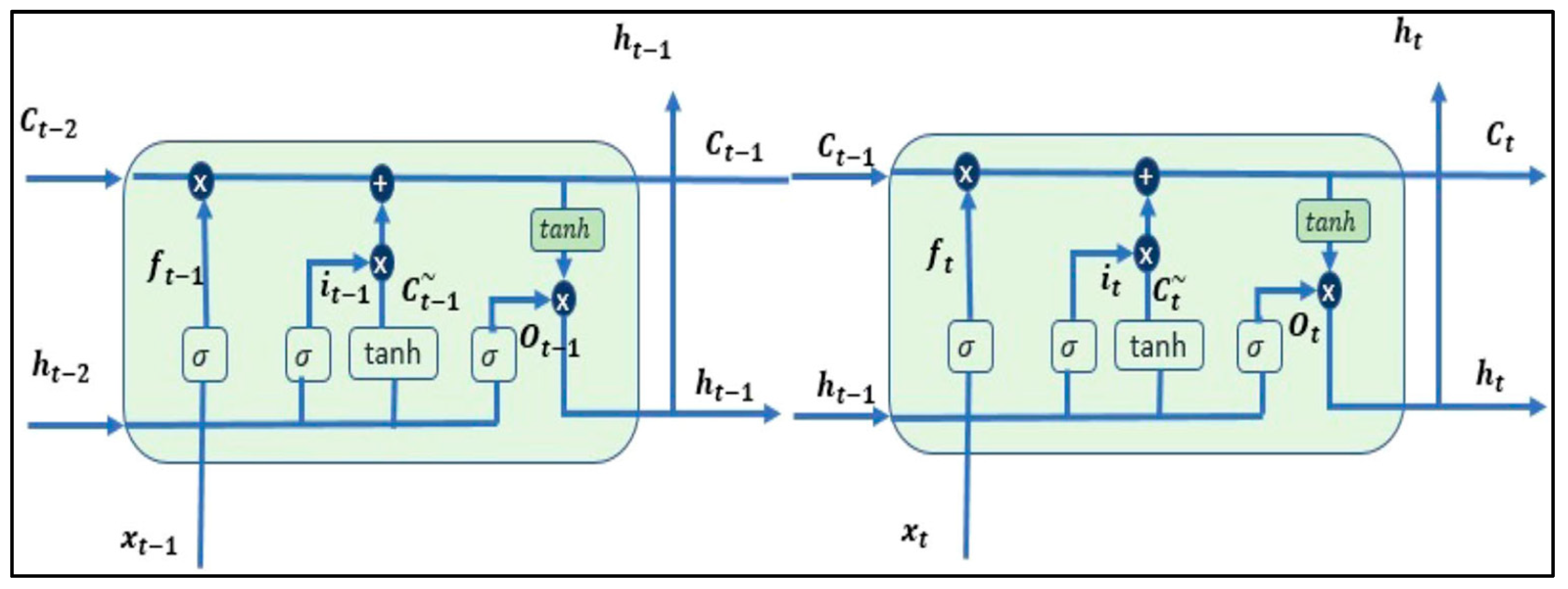
3.3. LSTM
- Input Gate (i): This gate facilitates the addition of new information to the cell state.
- Forget Gate (f): The forget gate selectively discards information that is no longer relevant or required by the model.
- Output Gate (o): Responsible for choosing the information to be presented as the output.
3.4. Reinforcement Learning
- Reward: A scalar value from the environment that evaluates the preceding action. Rewards can be positive or negative, contingent upon the nature of the environment and the agent’s action.
- Policy: This guides the agent in deciding the subsequent action based on the current state, helping the agent navigate its actions effectively.
- Value (V): Represents the long-term return, factoring in discount rates, rather than focusing solely on short-term rewards (R).
- Action Value: Like the reward value, but incorporates additional parameters from the current action. This metric guides the agent in optimizing its actions within the given environment.
3.5. Deep Reinforcement Learning
3.6. Classification of the DRL Algorithms
3.7. Natural Language Processing
3.8. Sentiment Analysis
3.9. TFIDF
3.10. BERT
4. Problem Statement
5. Proposed Novel Architecture for Stock Market Prediction
| Algorithm 1: Stock Price prediction framework |
| Data: Raw news data, historical stock dataset Result: Final trading decision (buy, sell) NLP Module: Input: Raw news data Output: classified sentences to positive or negative Preprocessing: Read the raw news dataset. Tokenize the sentences. Convert words to lowercase. Remove stop words. Stem the sentences. Lemmatize the words. Feature extraction using BERT and TFIDF Utilize BERT and TFIDF to extract features from news data. Sentence classification as positive or negative Prediction Module: Input: Historical stock data Output: Predicted stock prices Steps: Read stock data signal. Signal decomposition using variational mode decomposition. Apply decomposed signal to the LSTM. Predict stock prices for the next days based on decomposed signal by LSTM. Decision-Making Module: Input: Output from NLP Module, output from prediction module Output: Final decision (buy/sell) Steps: Combine sentiment analysis results with the predicted prices. Train deep Q learning network to make trading decisions. Implement DQN. Results Generate the suitable decision—sell or buy. |
5.1. Sentiment Analysis Phase
- Preprocessing: In this phase, the news dataset obtained from media or tweets is preprocessed. The preprocessing involves reading the dataset, tokenizing the sentences, converting words to lowercase, removing stop words, sentences stemmed, and finally, the words with the same meaning are grouped or lemmatized.
- Modeling: This step involves feature extraction for the model and sentiment analysis. Sentiment analysis will first convert the tokens to the dictionary, and the dataset will be split for training and testing the model. The model is built using an artificial neural network classifier.
- Prediction: This step will receive the testing news data and predict if the sentiment is positive or negative. This result is concatenated with the historical dataset.
5.2. Price Prediction Phase
5.3. The Deep Reinforcement Learning Phase
6. Implementation and Discussion of Results
6.1. Sentiment Analysis Phase
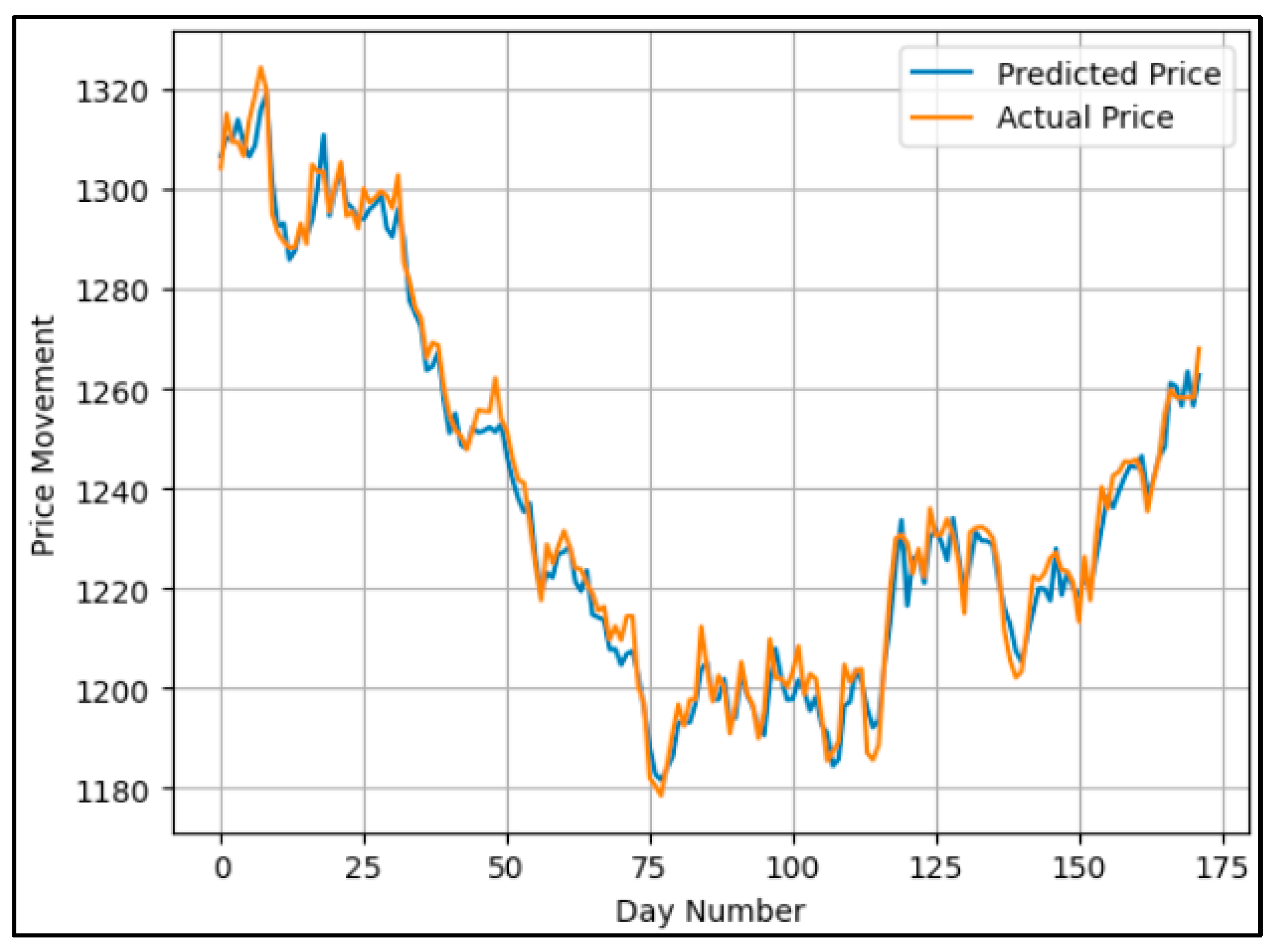
6.2. Stock Prices Prediction Phase
6.3. Final Decision Phase
6.4. Algorithms in Comparison
6.5. Evaluation Metrics
- Accumulated wealth rate
- Average Max drawdown
- Calmar ratio
- Average profit return
- Average Sharpe ratio
- Annualized Return Rate and Annualized Sharpe Ratio
6.6. Technical Indicators
- Relative Strength Index (RSI)
- Momentum
6.7. Reward Calculation
6.8. State Representation
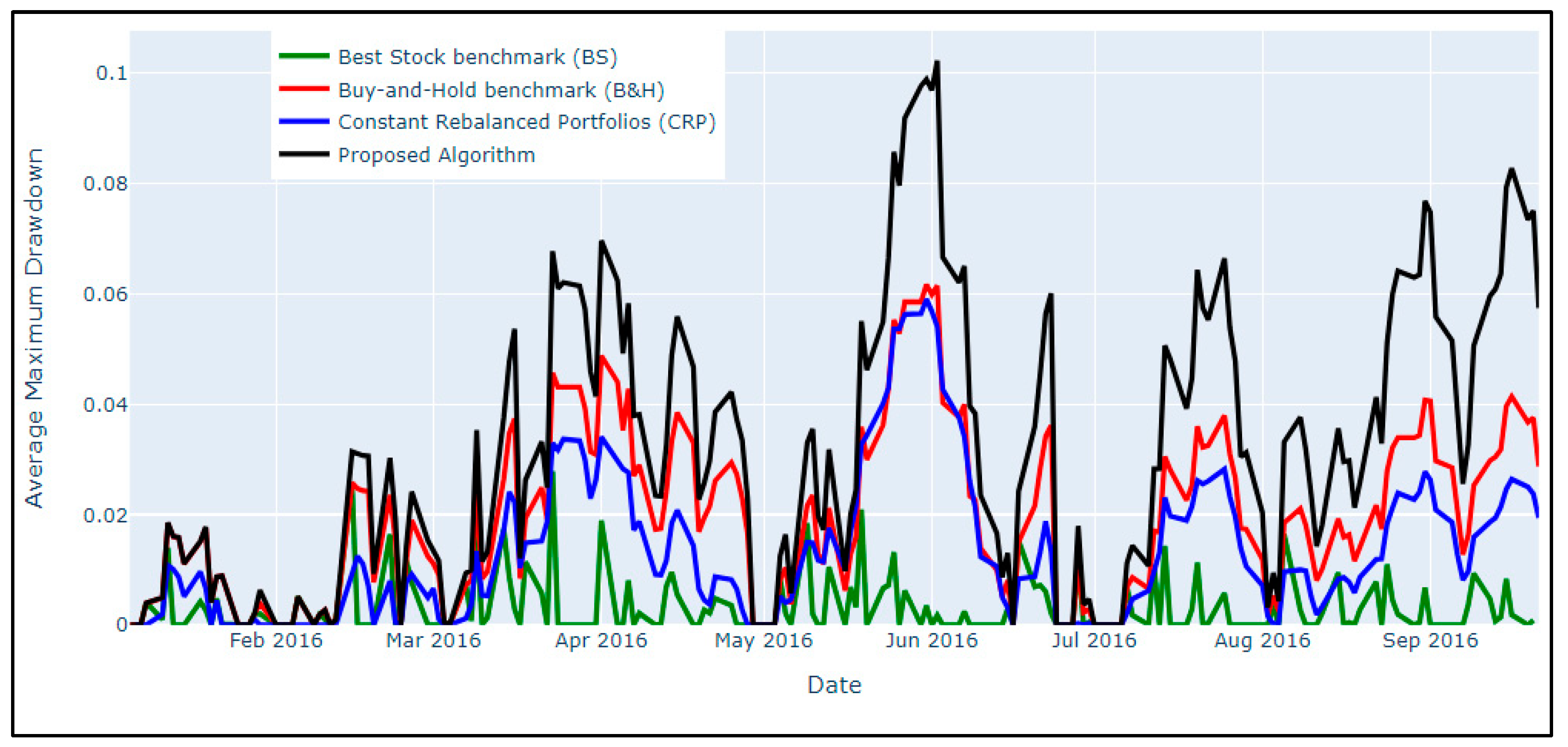
6.9. Proposed Framework Results Comparison
6.10. Ablation Study
6.10.1. Effect of Using the VMD on the Price Prediction Phase
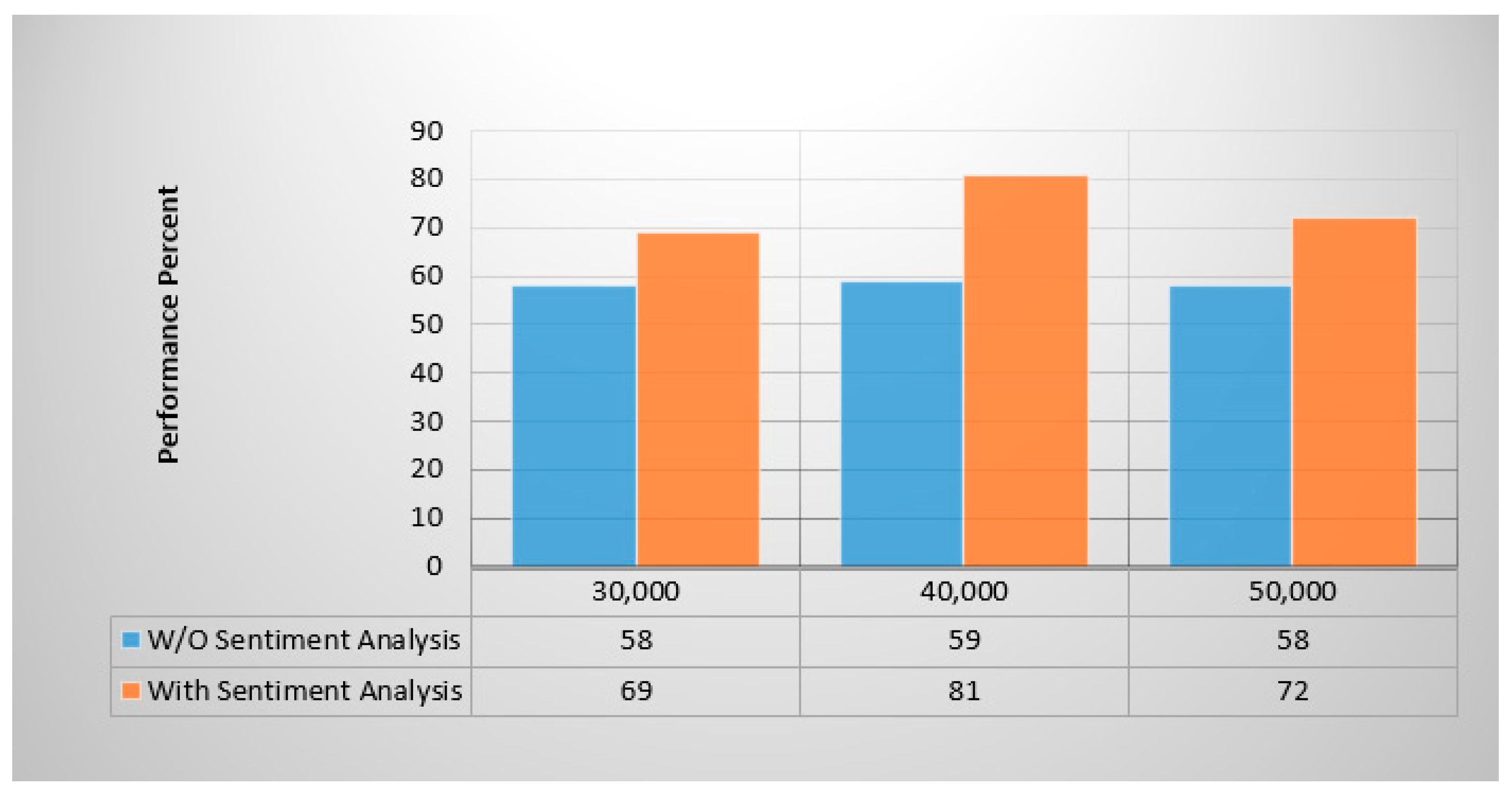
6.10.2. Effect of Using Sentiment Analysis Module on the Framework Performance
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Idrees, S.M.; Alam, M.A.; Agarwal, P. A Prediction Approach for Stock Market Volatility Based on Time Series Data. IEEE Accesss 2019, 7, 17287–17298. [Google Scholar] [CrossRef]
- Bouteska, A.; Regaieg, B. Loss aversion, the overconfidence of investors and their impact on market performance evidence from the US stock markets. J. Econ. Financ. Adm. Sci. 2020, 25, 451–478. [Google Scholar] [CrossRef]
- Feng, F.; He, X.; Wang, X.; Luo, C.; Liu, Y.; Chua, T.S. Temporal Relational Ranking for Stock Prediction|ACM Transactions on Information Systems. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–30. [Google Scholar] [CrossRef]
- Dirman, A. Financial distress: The impacts of profitability, liquidity, leverage, firm size, and free cash flow. Int. J. Bus. Econ. Law 2020, 22, 17–25. [Google Scholar]
- Ghimire, A.; Thapa, S.; Jha, A.K.; Adhikari, S.; Kumar, A. Accelerating Business Growth with Big Data and Artificial Intelligence. In Proceedings of the 2020 Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 7–9 October 2020. [Google Scholar] [CrossRef]
- Kurani, A.; Doshi, P.; Vakharia, A.; Shah, M. A Comprehensive Comparative Study of Artificial Neural Networks (ANN) and Support Vector Machines (SVM) on Stock Forecasting. Ann. Data Sci. 2021, 10, 183–208. [Google Scholar] [CrossRef]
- Beg, M.O.; Awan, M.N.; Ali, S.S. Algorithmic Machine Learning for Prediction of Stock Prices. In FinTech as a Disruptive Technology for Financial Institutions; IGI Global: Hershey, PA, USA, 2019; pp. 142–169. [Google Scholar] [CrossRef]
- Shah, D.; Isah, H.; Zulkernine, F. Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. Int. J. Financ. Stud. 2019, 7, 26. [Google Scholar] [CrossRef]
- Yadav, A.; Chakraborty, A. Investor Sentiment and Stock Market Returns Evidence from the Indian Market. Purushartha-J. Manag. Ethics Spiritual. 2022, 15, 79–93. [Google Scholar] [CrossRef]
- Chauhan, L.; Alberg, J.; Lipton, Z. Uncertainty-Aware Lookahead Factor Models for Quantitative Investing. In Proceedings of the 37th International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; Volume 119, pp. 1489–1499. [Google Scholar]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. A novel multi-source information-fusion predictive framework based on deep neural networks for accuracy enhancement in stock market prediction. J. Big Data 2021, 8, 17. [Google Scholar] [CrossRef]
- Sakhare, N.N.; Imambi, S.S. Performance analysis of regression-based machine learning techniques for prediction of stock market movement. Int. J. Recent Technol. Eng. 2019, 7, 655–662. [Google Scholar]
- Singh, R.; Srivastava, S. Stock prediction using deep learning. Multimed. Tools Appl. 2016, 76, 18569–18584. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Y.; Khushi, M. A Survey of Forex and Stock Price Prediction Using Deep Learning. Appl. Syst. Innov. 2021, 4, 9. [Google Scholar] [CrossRef]
- Hiransha, M.; Gopalakrishnan, E.A.; Menon, V.K.; Soman, K.P. NSE Stock Market Prediction Using Deep-Learning Models. Procedia Comput. Sci. 2018, 132, 1351–1362. [Google Scholar] [CrossRef]
- Patel, R.; Choudhary, V.; Saxena, D.; Singh, A.K. Review of Stock Prediction using machine learning techniques. In Proceedings of the 5th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 3–5 June 2021; pp. 840–847. [Google Scholar]
- Kamath, U.; Liu, J.; Whitaker, J. Deep Learning for NLP and Speech Recognition; Springer: Cham, Switzerland, 2019; pp. 575–613. [Google Scholar]
- Manolakis, D.; Bosowski, N.; Ingle, V.K. Count Time-Series Analysis: A Signal Processing Perspective. IEEE Signal Process. Mag. 2019, 36, 64–81. [Google Scholar] [CrossRef]
- Kabbani, T.; Duman, E. Deep Reinforcement Learning Approach for Trading Automation in the Stock Market. IEEE Access 2022, 10, 93564–93574. [Google Scholar] [CrossRef]
- Moghar, A.; Hamiche, M. Stock Market Prediction Using LSTM Recurrent Neural Network. Procedia Comput. Sci. 2020, 170, 1168–1173. [Google Scholar] [CrossRef]
- Ren, Y.; Liao, F.; Gong, Y. Impact of News on the Trend of Stock Price Change: An Analysis based on the Deep Bidirectional LSTM Model. Procedia Comput. Sci. 2020, 174, 128–140. [Google Scholar] [CrossRef]
- Jin, Z.; Yang, Y.; Liu, Y. Stock closing price prediction based on sentiment analysis and LSTM. Neural Comput. Appl. 2019, 32, 9713–9729. [Google Scholar] [CrossRef]
- Parray, I.R.; Khurana, S.S.; Kumar, M.; Altalbe, A.A. Time series data analysis of stock price movement using machine learning techniques. Soft Comput. 2020, 24, 16509–16517. [Google Scholar] [CrossRef]
- Duan, G.; Lin, M.; Wang, H.; Xu, Z. Deep Neural Networks for Stock Price Prediction. In Proceedings of the 14th International Conference on Computer Research and Development (ICCRD), Shenzhen, China, 7–9 January 2022. [Google Scholar] [CrossRef]
- Huang, J.; Liu, J. Using social media mining technology to improve stock price forecast accuracy. J. Forecast. 2019, 39, 104–116. [Google Scholar] [CrossRef]
- Iqbal, S.; Sha, F. Actor-Attention-Critic for Multi-Agent Reinforcement Learning. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 2961–2970. [Google Scholar]
- Singh, V.; Chen, S.-S.; Singhania, M.; Nanavati, B.; Kar, A.K.; Gupta, A. How are reinforcement learning and deep learning algorithms used for big data-based decision making in financial industries—A review and research agenda. Int. J. Inf. Manag. Data Insights 2022, 2, 100094. [Google Scholar] [CrossRef]
- Padakandla, S. A survey of reinforcement learning algorithms for dynamically varying environments. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Silver, D.; Singh, S.; Precup, D.; Sutton, R.S. A reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Kartal, B.; Hernandez-Leal, P.; Taylor, M.E. Terminal Prediction as an Auxiliary Task for Deep Reinforcement Learning. Proc. AAAI Conf. Artif. Intell. Interact. Digit. Entertain. 2019, 15, 38–44. [Google Scholar] [CrossRef]
- Zhang, Z.; Zohren, S.; Roberts, S. Deep Reinforcement Learning for Trading. J. Financ. Data Sci. 2020, 2, 25–40. [Google Scholar] [CrossRef]
- Sewak, M. Mathematical and Algorithmic Understanding of Reinforcement Learning. In Deep Reinforcement Learning; Springer: Cham, Switzerland, 2019; pp. 19–27. [Google Scholar]
- Xiao, Y.; Lyu, X.; Amato, C. Local Advantage Actor-Critic for Robust Multi-Agent Deep Reinforcement Learning. In Proceedings of the International Symposium on Multi-Robot and Multi-Agent Systems (MRS), Cambridge, UK, 4–5 November 2021. [Google Scholar] [CrossRef]
- Ren, Y.; Duan, J.; Li, S.E.; Guan, Y.; Sun, Q. Improving Generalization of Reinforcement Learning with Minimax Distributional Soft Actor-Critic. In Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar] [CrossRef]
- Yang, H.; Liu, X.Y.; Zhong, S.; Walid, A. Deep reinforcement learning for automated stock trading: An ensemble strategy. In Proceedings of the First ACM International Conference on AI in Finance (ICAIF), New York, NY, USA, 6 October 2020; pp. 1–8. [Google Scholar]
- Zanette, A.; Wainwright, M.J.; Brunskill, E. Provable Benefits of Actor-Critic Methods for Offline Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 13626–13640. [Google Scholar]
- Nguyen, N.D.; Nguyen, T.T.; Vamplew, P.; Dazeley, R.; Nahavandi, S. A Prioritized objective actor-critic method for deep reinforcement learning. Neural Comput. Appl. 2021, 33, 10335–10349. [Google Scholar] [CrossRef]
- Wang, C.; Sandas, P.; Beling, P. Improving Pairs Trading Strategies via Reinforcement Learning. In Proceedings of the 2021 International Conference on Applied Artificial Intelligence (ICAPAI), Halden, Norway, 19–21 May 2021. [Google Scholar] [CrossRef]
- Huang, H.; Zhao, T. Stock Market Prediction by Daily News via Natural Language Processing and Machine Learning. In Proceedings of the 2021 International Conference on Computer, Blockchain and Financial Development (CBFD), Nanjing, China, 23–25 April 2021. [Google Scholar] [CrossRef]
- Gupta, R.; Chen, M. Sentiment Analysis for Stock Price Prediction. In Proceedings of the 2020 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020. [Google Scholar] [CrossRef]
- Huo, H.; Iwaihara, M. Utilizing BERT Pretrained Models with Various Fine-Tune Methods for Subjectivity Detection. Web Big Data 2020, 4, 270–284. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Remarks |
|---|---|---|
| TFIDF + ANN | 85% | Base Model |
| BERT + ANN | 96.2% | 11.2% improvement over the base model |
| TFIDF + BERT + ANN | 96.8% | 0.6% improvement over BERT + ANN |
| Parameter | Description | Value |
|---|---|---|
| α | Moderate bandwidth constraint | 5000 |
| τ | Noise tolerance with no strict fidelity enforced | 0 |
| k | modes | 5 |
| DC | DC part is not imposed | 0 |
| init | Will initialize all omegas uniformly | 1 |
| tol | — | 1 × 10−7 |
| Parameter | Value |
|---|---|
| Learning rate | 0.001 |
| Input size | 5 |
| Hidden size | 200 |
| Number of epochs | 2000 |
| Number of layers | 2 |
| Parameter | Value |
|---|---|
| Discount | 0.99 |
| Epsilon max | 1.0 |
| Epsilon min | 0.01 |
| Epsilon decay | 0.001 |
| Memory capacity | 5000 |
| Learning rate | 1 × 10−3 |
| Action size | 4 |
| Input layer | Input size × 1000 |
| Hidden layer | 1000 × 600 |
| Output layer | 600 × output size |
| Metrics | Best Stock | Buy and Hold | (CRP) | Proposed Algorithm |
|---|---|---|---|---|
| average_profit_return | 0.0011 | 0.0011 | 0.0011 | 0.01 |
| Sharpe ratio | 2.5 | 2.4 | 2.4 | 3 |
| Average maximum drawdown | 0.0031 | 0.02 | 0.01 | 0.03 |
| Calmar ratio | 6.1 | 2.6 | 3 | 3 |
| Annualized return rate (ARR) | 0.5 | 0.5 | 0.5 | 1.1 |
| Annualized Sharpe ratio (ANSR) | 47.8 | 47 | 47 | 57.2 |
| Metric | Training Data | Test Data | ||
|---|---|---|---|---|
| With VMD | W/O VMD | With VMD | W/O VMD | |
| MAE | 3.64 | 4.1 | 4.3 | 5.6 |
| MSE | 20.5 | 26.1 | 31.6 | 56.9 |
| MAPE | 0.29 | 0.33 | 0.33 | 0.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awad, A.L.; Elkaffas, S.M.; Fakhr, M.W. Stock Market Prediction Using Deep Reinforcement Learning. Appl. Syst. Innov. 2023, 6, 106. https://doi.org/10.3390/asi6060106
Awad AL, Elkaffas SM, Fakhr MW. Stock Market Prediction Using Deep Reinforcement Learning. Applied System Innovation. 2023; 6(6):106. https://doi.org/10.3390/asi6060106
Chicago/Turabian StyleAwad, Alamir Labib, Saleh Mesbah Elkaffas, and Mohammed Waleed Fakhr. 2023. "Stock Market Prediction Using Deep Reinforcement Learning" Applied System Innovation 6, no. 6: 106. https://doi.org/10.3390/asi6060106
APA StyleAwad, A. L., Elkaffas, S. M., & Fakhr, M. W. (2023). Stock Market Prediction Using Deep Reinforcement Learning. Applied System Innovation, 6(6), 106. https://doi.org/10.3390/asi6060106