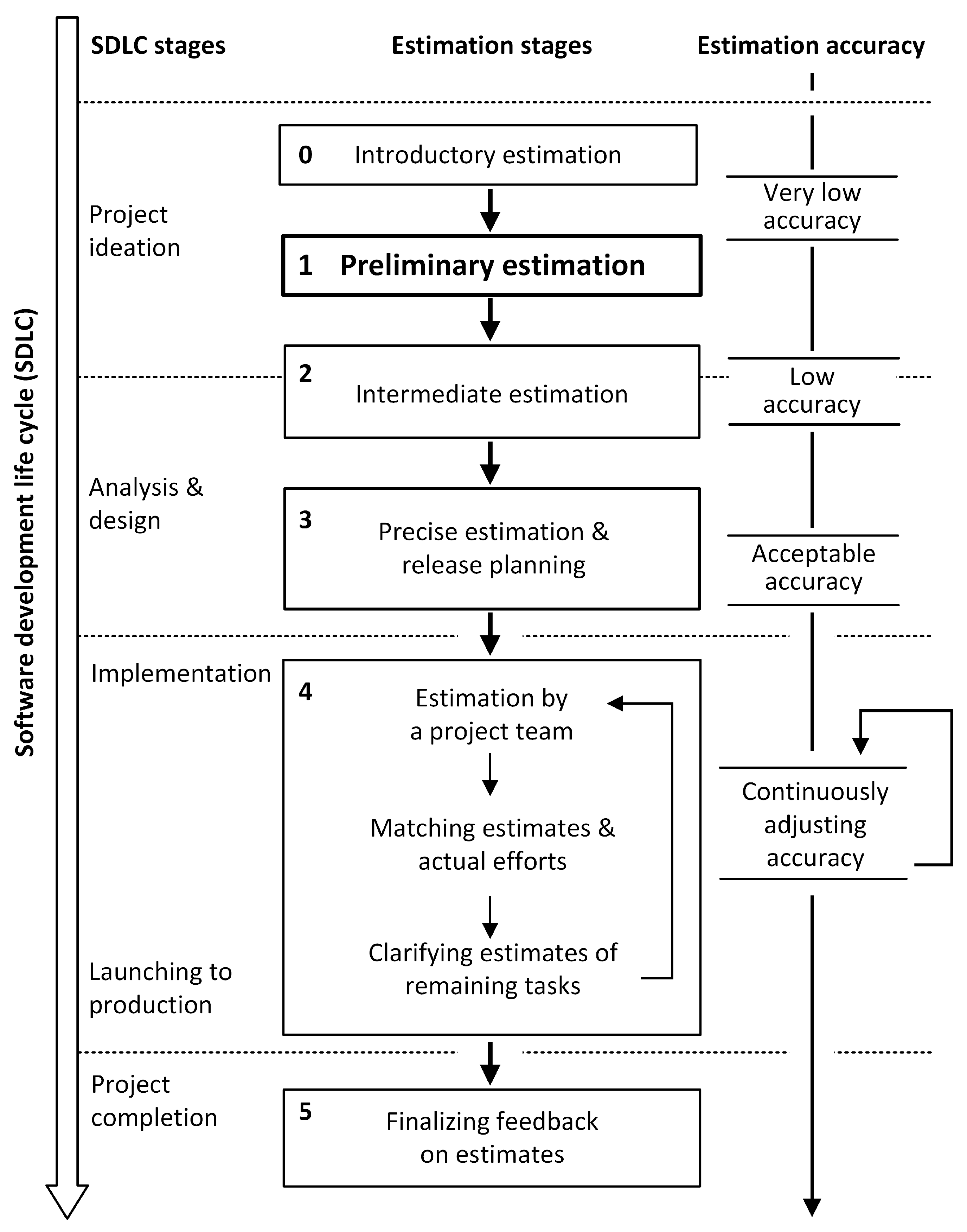
4.1. Preliminary Estimation as a Semistructured Business Process
Before starting a discussion of the preliminary estimation method in detail, it is worth analyzing its usage in practice. Since preliminary estimation heavily relies on the knowledge, experience, and creativity of the involved experts, it makes sense to keep it as a semistructured business process [
11,
12], leaving some level of freedom for the participants. In other words, such a process involves certain steps; however, there are no strict recommendations on the steps’ order (i.e., some of the steps can be interchanged, and some of them can be repeated several times). The preliminary estimation semistructured process is represented in
Figure 2.
The process starts with understanding the essence of a project and getting familiar with the available requirements (step A). An important aspect of the process is identifying the project scenarios (step B). Under a project scenario, a hypothetical way of project implementation is understood. Depending on the circumstances, the criteria of scenario identification might be different, for example, development efforts, scope of work, implementation technologies, architecture design, etc. The “backbone” of the process consists of three steps: D, E, and F. In these steps, the estimation outcomes are produced. The rest of the
Section 4 covers step E and, partially, step D. Importantly, steps D, E, and F are performed for each of the identified scenarios (it is worth noting that optimistic and pessimistic estimates represent an estimate range for a single scenario, not two different scenarios). The final step G is aimed at communication of the estimates to the concerned parties (e.g., to a potential client).
The process involves the following participant roles: a project manager, a technical expert, and a business analyst. The primary responsibility areas of each role are shown in
Figure 2. However, it is worth noting that regardless of the primary responsible role, other roles are also supposed to contribute to a certain process step (e.g., a business analyst is responsible for the project scope decomposition; however, a technical expert can also contribute to this). In practice, a person can combine the duties of more than one role (e.g., a technical expert can also perform the tasks of a business analyst). Or, in the opposite case, the business analyst role can be covered by two people: a business analyst and a business domain expert (or a subject matter expert).
4.2. Estimable-Item Breakdown Structure
To provide reliable estimates, it is necessary to have some representation of the project scope—the object of estimation. Usually, the project scope is decomposed into a treelike construction called a work breakdown structure (WBS) [
32] or into one of its subtypes (e.g., a component-based work breakdown structure, CBWBS [
33]). In practice, such a breakdown structure is received as the result of a combination of several decomposition approaches (e.g., work packages, work items, epics, features, components, use cases, etc.). In order to incorporate a project scope breakdown into the authors’ estimation framework, the terms “estimable item” (EI) and “estimable-item breakdown structure” (EIBS) are introduced.
An
estimable item (IE),
x, is a representation of a project scope portion which can be sized (i.e., assigned with a normalized development estimate, NDE [
9]), decomposed to child estimable items, and analyzed in terms of assumptions, dependencies, risks, etc. An estimable item
x possesses a set of attributes; the value of an attribute can be denoted in squared brackets—
. For example,
is a parent of estimable item
x;
is a set of risks associated with
x. Especially important is
. An item is called a
leaf estimable item (LEI) when it does not have any child items,
. In turn, if
x does have child items,
, it is named a
composite estimable item (CEI).
An estimable-item breakdown structure (EIBS) X is a tree (in terms of graph theory) with estimable items as the vertices, parent–child relationships between the estimable items as the edges, and the root item representing the scope of the whole project.
To show how the preliminary estimation is applied, a software product named “Real-time Business Process Monitoring for Estimation” (RTBPM-E) [
34,
35] is used here and below. In
Table 1 and in
Figure 3, an EIBS is provided for RTBPM-E.
An important part of EIBS creation is assigning attributes to items. Such an attribute is nothing but a piece of information associated with an EI. In
Table 2, attribute types are listed. They, in the authors’ opinion, correspond to the most frequently analyzed aspects of the project scope.
Considering the limit on the preparation time and the high level of uncertainty, as well as not-so-strict accuracy requirements, an EIBS created during the preliminary estimation stage is not supposed to be quite detailed. Even identification of the first-level items might be enough to provide a preliminary estimate.
4.3. Sizing of Estimable Items
As already mentioned in
Section 2, the authors’ estimation framework uses NDE as a measure of development efforts. NDE is a time-based unit expressing the amount of work in man-hours, man-days, etc. Such time-based measuring ensures seamless translation of the estimated efforts into the project schedule. However, it is worth highlighting that the NDE itself is defined in a way that makes it independent from neither the project schedule nor the team composition.
In essence, sizing is aimed at designating each EI as an NDE. For the preliminary estimation, a two-step sizing approach is proposed: (a) designate each LEI using such attributes as an estimable item point (EIP) and an estimable item uncertainty (EIU); (b) then, obtain optimistic and pessimistic NDEs from the corresponding EIP and EIU.
Let be an LEI belonging to EIBS X. The estimable item point (EIP) of x, , is a positive number representing the relative measure of development efforts required to implement x. In turn, the estimable item uncertainty (EIU), , is a non-negative dimensionless number expressing how much is unknown with regard to x; in other words, the bigger the , the less definitive the and vice versa. It is worth emphasizing that EIPs and EIUs are supposed to be designated for LEIs (not CEIs).
EIPs and EIUs are based on experts’ judgment. In
Figure 4, an example is shown of EIP and EIU estimation based on the idea of affinity grouping [
5]: the LEIs are placed on a coordinate plane where the horizontal axis corresponds to the size (EIP), and the vertical axis defines the level of uncertainty (EIU). One of the strengths of the described approach is its visual representation of the project scope on a two-dimensional plain, allowing a relative comparison of EIs’ sizes and uncertainties.
After estimating EIPs and EIUs, it is necessary to transform them into NDEs. Define the relationship between NDE and EIP as follows:
where
is the NDE corresponding to one EIP. In turn, optimistic and pessimistic NDEs are related to the EIU as follows:
where
and
are the optimistic and pessimistic NDEs, respectively;
and
are the coefficients defining deviation of the optimistic and pessimistic estimates from the basic NDE. Values of parameters
p,
,
can be either based on experts’ judgment or defined statistically from past projects. In
Table 3, an example of applying the above approach to RTBPM-E is represented; for calculations, the following values of the parameters were chosen by the authors:
,
,
.
Therefore, the RTBPM-E NDEs are the following:
where the optimistic and pessimistic estimates form the range
(relative to the NDE
basic), which, from authors’ perspective, is acceptable for the preliminary estimation.
4.4. Project Team Composition
Along with the NDE discussed in the previous section, project team composition is one of the key ingredients of an estimate. As can be seen in the sections below, the varying of the project team composition allows to one to obtain estimates with different project durations and costs.
Project team composition means a set of project team member roles, T, and the attributes associated with each role (e.g., a full-time equivalent, FTE). A project team includes roles in two main categories: development, (software engineers), and nondevelopment, (e.g., project managers, test engineers, etc.). The main difference between these categories is that the efforts spent by team members in development roles are estimated in the NDE, while the efforts of the nondevelopment roles are not included in the NDE.
In order to match FTEs of development roles with the NDE, let us extend the estimation framework with a new term—
normalized development full-time equivalent (ND-FTE),
:
where
is the productivity coefficient (PC) defined in [
9];
is the corresponding FTE. Using the introduced term, a team composition with nondifferentiated specializations applicable to RTBPM-E is provided in
Table 4.
In most cases, the simplest type of development team composition—with nondifferentiated specializations—fulfills the preliminary estimation needs. However, in situations where highlighting development specializations is quite important, development teams with differentiated or even mixed specializations can also be applicable at the preliminary estimation stage. Further information about the team composition types is in
Section 5.
4.5. System of Working-Time Balance Equations
The idea of a system of working-time balance equations was introduced in the authors’ past works [
9,
10]. Its purpose is to define the relationships between the key estimate ingredients such as the structure of software developer working time, project team composition, project duration, and NDE.
For the preliminary estimation, a simplified version of the system of working-time balance equations is used. To achieve the simplification, we assume the following:
The project timeline is not split into sprints or phases.
The project team does not change throughout the whole project.
There is no differentiation of the development specializations.
There is a linear relationship between the project working time,
W, and the development working time,
D (in contradiction to (
1), where that relationship is based on the structure of software developer working time):
where
is the
development working time coefficient (DWTC) (again, for simplicity reasons, it is assumed that
does not depend on project role
). Further information about the DWTC is provided in
Section 5.
Therefore, the system of working-time balance equations for the preliminary estimation is as follows:
where
T is the set of project roles;
is the subset of development roles;
is the project working time (PWT) of role
;
is the development working time (DWT) of role
;
is the development working time coefficient (DWTC);
is the full-time equivalent (FTE) of role
;
L is the duration of the project;
E is the normalized development estimate (NDE) of the entire project;
is the productivity coefficient (PC) of development role
.
4.7. Estimation of Project Duration
In the case of the preliminary estimation, the main criterion of estimating project duration is that the project team must have enough NDC to implement the project scope, measured as NDE,
E:
Therefore, project duration,
L, is estimated with the following inequation:
An example of estimating the optimistic and pessimistic durations for RTBPM-E is represented in
Table 5—to implement the project scope from
Table 3 utilizing the project team defined in
Table 4, it will take from
to
months. Due to the high level of uncertainty, the estimated duration range is wide, which is expected for the preliminary estimation.
The duration estimation based on (
15) does not guarantee high accuracy; instead, it allows a roughly evaluation of the duration of the project using relatively simple calculations. Narrowing down the estimate range will be undertaken in the next estimation stages.
4.8. Optimization of Project Duration and Team Composition
As can be seen above, the preliminary estimation operates with these three main ingredients: project scope, team composition, and project duration. Given that the project scope is fixed (i.e., the NDE does not vary), the other two components are interdependent: changes in the team composition imply different project durations and vice versa: depending on the project duration, different team compositions are required. Manual selection of the best combination of these two ingredients requires time spent on calculations. To make this more efficient, a multiobjective optimization is proposed:
where
T is the set of project team roles;
is a particular role belonging to the team;
is the normalized hourly rate of role
;
is the PWT of role
;
is the FTE of role
;
L is the project duration;
C is the NDC of the development team
;
E is the NDE;
I is the development team idle time. It is worth noting that applying normalization to the cost-related variables brings the following benefits: (a) avoiding disclosure of commercially sensitive information; (b) avoiding too-big values of the objective function; (c) currency-independent calculations with further conversion of the normalized costs to a required currency.
One of the main constraints to be satisfied is (
14)—the chosen team composition and project duration have to allow the implementation of the project scope estimated as
E. Also, it is worth applying restrictions on the project duration:
The other group of constraints is applicable to the project role FTEs:
where
is a subteam of project team
T. For example, a team has to include at least one middle software engineer:
(where
is a subset of middle software engineers); or, the size of the whole team,
T, does not have to exceed 25 FTEs:
. The interrelation of FTEs for different project roles is expressed with this type of constraint:
where
and
are a subteams of
T;
and
are constants. For example, 1 project manager cannot lead more than 15 team members:
(where
is a subteam of project managers).
Let us substitute real decision variables
with the corresponding integer variables
:
where
is a whole number of minimum FTEs for role
;
is a minimal possible step of FTE change for role
. Also, let us vary the project duration within a range (
20):
Therefore, for each
, a sequence of integer programming problems with an objective (
16), constraints (
14), (
21), (
22), and decision variables (
23) is received. Solving these optimization tasks produces a sequence of
p alternatives
. Then, the alternatives are ranked using the analytic hierarchy process (AHP) [
36].
In application to the RTBPM-E example, let us solve a sequence of integer programming problems, varying the project duration from
months to
months with the step of 0.5 month for both optimistic and pessimistic estimates. Then, the received alternatives are ranked with AHP according to the criteria from
Table 6. The top alternatives are provided in
Table 7 and
Table 8 for the optimistic and pessimistic estimates, respectively. As a result, for the optimistic estimate, alternative 1 is chosen (as recommended according to the AHP ranking). However, alternative 2 is selected for the pessimistic estimate (in this regard, it is worth emphasizing that the AHP-based alternative ranking is just a decision support tool, while the final conclusion is made by the experts).
Table 9 provides the project team composition corresponding to the chosen alternatives.
The calculations in the current section were performed with a Python script using the following libraries: (a) Pyomo v.6.5.0 (
https://www.pyomo.org/, (accessed on 11 May 2023)) as an optimization model builder; (b) FICO Xpress v.9.1.0 under the community license (
https://www.fico.com/, (accessed on 11 May 2023)) as an optimization task solver; (c) ahpy v.2.0.0 (
https://github.com/PhilipGriffith/AHPy, (accessed on 11 May 2023)) for the AHP-based ranking of the alternatives.
A comparison of the manual (
Table 4 and
Table 5) and optimized (
Table 7,
Table 8 and
Table 9) estimates is given in
Table 10 and
Table 11—the optimized estimate, on the one hand, slightly increases the ND-FTE and, on the other hand, outperforms the manual estimate, reducing the project duration and cost.
The proposed decision support tool set reduces the experts’ time spent on deciding on the team composition and the project duration. However, it requires a specific software implementation and calibration of the parameters.








{kind=link}
{kind=link}
{kind=link}
{kind=link}