
The Method of Restoring Lost Information from Sensors Based on Auto-Associative Neural Networks

 ,
,  , and
, and
Abstract
:1. Introduction
- Image restoration: ANN can be used to restore damaged or incomplete images, such as those with noise, compression artifacts, or blur.
- Denoising algorithms can sometimes smooth out not only noise but also fine details in the data, and other types of denoising can lead to blurring where sharp edges and textures are lost, making the data less accurate. ANNs can be used to remove noise from images or signals.
- Interpolation can create false patterns or structures that do not exist in the original data. ANNs can be used to fill in gaps in data, for example, to create higher-resolution images.
- Super resolution: ANNs can enhance low-quality image fidelity.
- Efficiency: ANNs can be very efficient compared with traditional information restoration methods.
- Flexibility: ANNs can be adapted to different types of data and tasks.
- Training: ANNs can automatically train from examples, making them more robust to noise and other data corruption.
2. Related Work Discussion
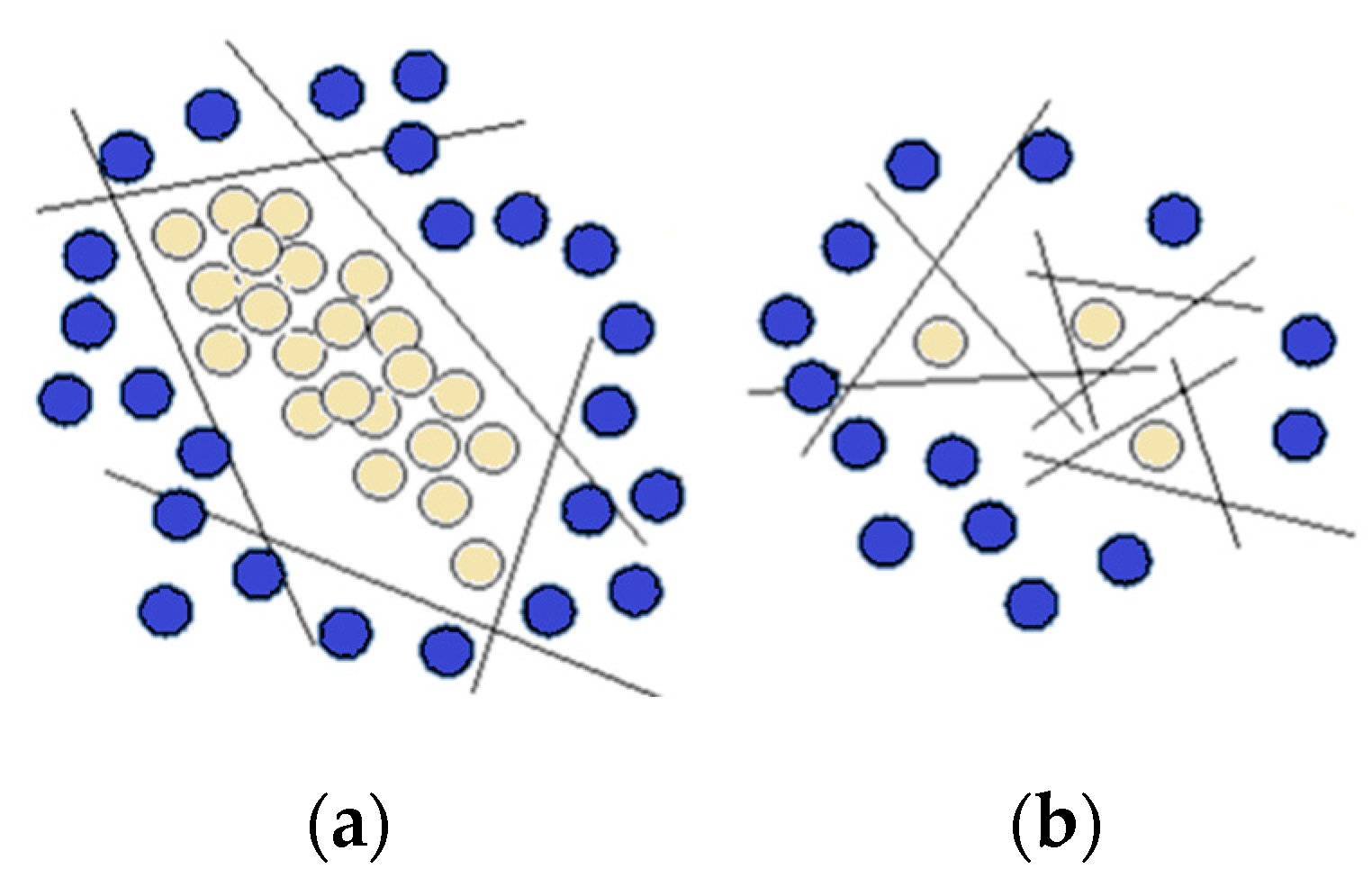
- Choosing an ANN structure to solve for effectively extracting and representing complex feature task in data;
- The traditional ANN training method modification based on gradient descent by adding regularization to reduce the model overtraining risk when it is strongly adapted to the training data and loses the ability to generalize new data;
- Training the ANN on the test set with the loss function analysis at the training and model validation stages;
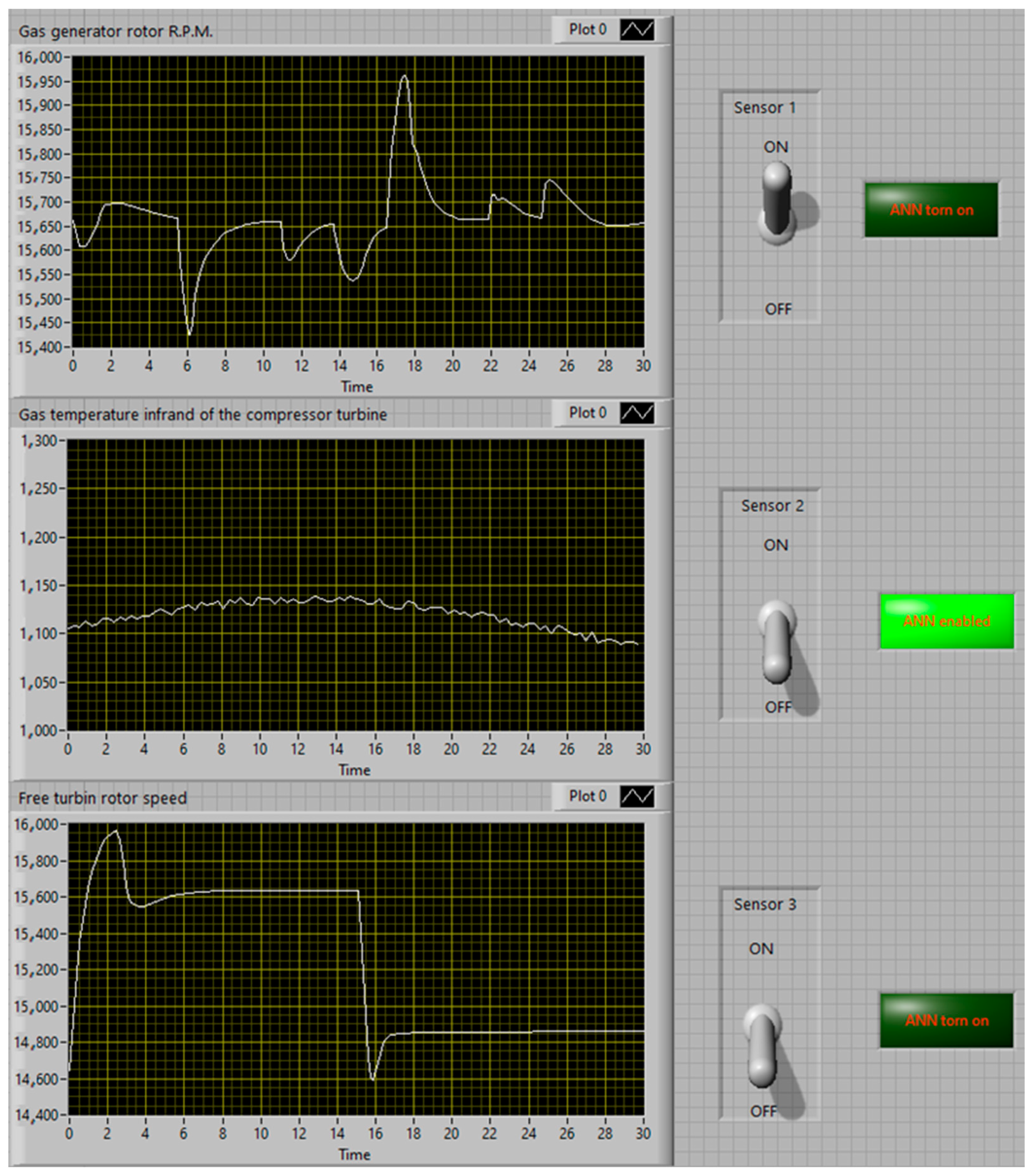
- Carrying out a computer simulation of the failure situation of complex dynamic object sensors (the TV3-117 TE example used).
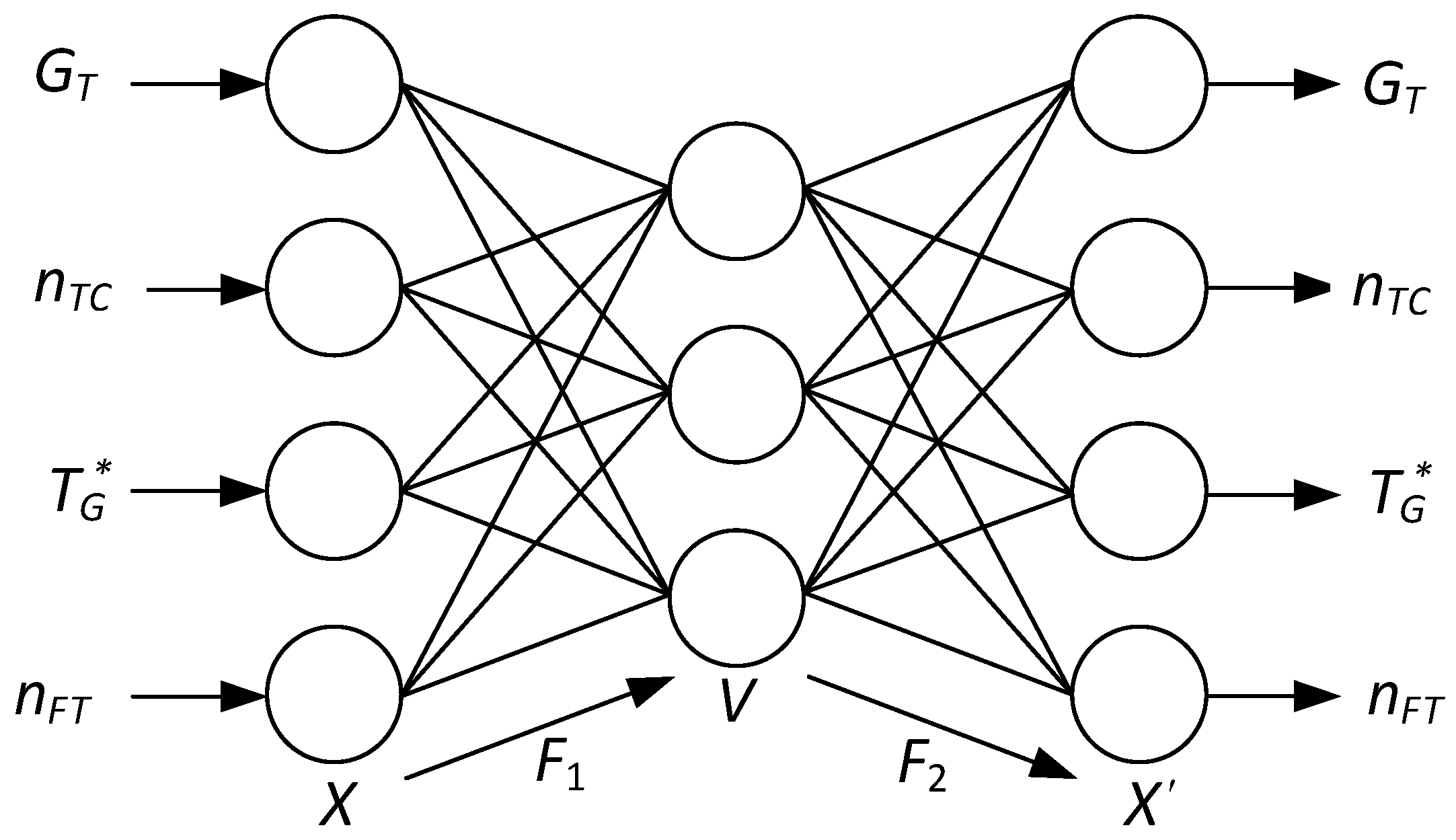
3. Materials and Methods
- Improved adaptability, which implies the algorithm’s ability to adapt to changes in object operating conditions, including operating modes changes and possible abnormal situations;
- Improving generalization ability, which means that the network needs to undergo training not just on data collected during tests but also on possessing the ability to generalize its acquired insights to adapt to unforeseen scenarios encountered in real-world operations;
- Accounting for process dynamics, which requires the training algorithm to take into account the engine state dynamics and the corresponding dynamics data coming from the sensors;
- Improving noise and error tolerance, which requires the network’s ability to operate effectively even in the data noise or errors presence in sensor measurements;
- Training time optimization, refers to reducing the training time required by a network to improve its efficiency and practical applicability.
- The loss function gradient over the weights, which is responsible for correcting the weights taking into account the error between the network output and the input data;
- L1 regularization, which penalizes the absolute value of the weights, helps in reducing the model complexity, and prevents overfitting;
- L2 regularization, which penalizes the square of the weight and, also, helps the control model reduce overfitting and complexity.
- Manually—λ1 and λ2 are selected by the expert or researcher based on their experience and intuition regarding the problem and data. If a more compressed model is required, then λ1 and λ2 can be chosen more strongly; if the model is prone to overfitting, then fewer may be selected.
- Cross-validation is dividing the training data into several parts (folds), training the model on one part, and evaluating its performance on the remaining parts. The process is then repeated for different values of λ1 and λ2. The values that show the best performance on the test data are selected as optimal.
- Optimization methods can used to automatically select the λ1 and λ2 values to minimize some target functionality, for example, the error in the validation set. This process may include optimization techniques such as grid search or surrogate model optimization algorithms.
4. Results
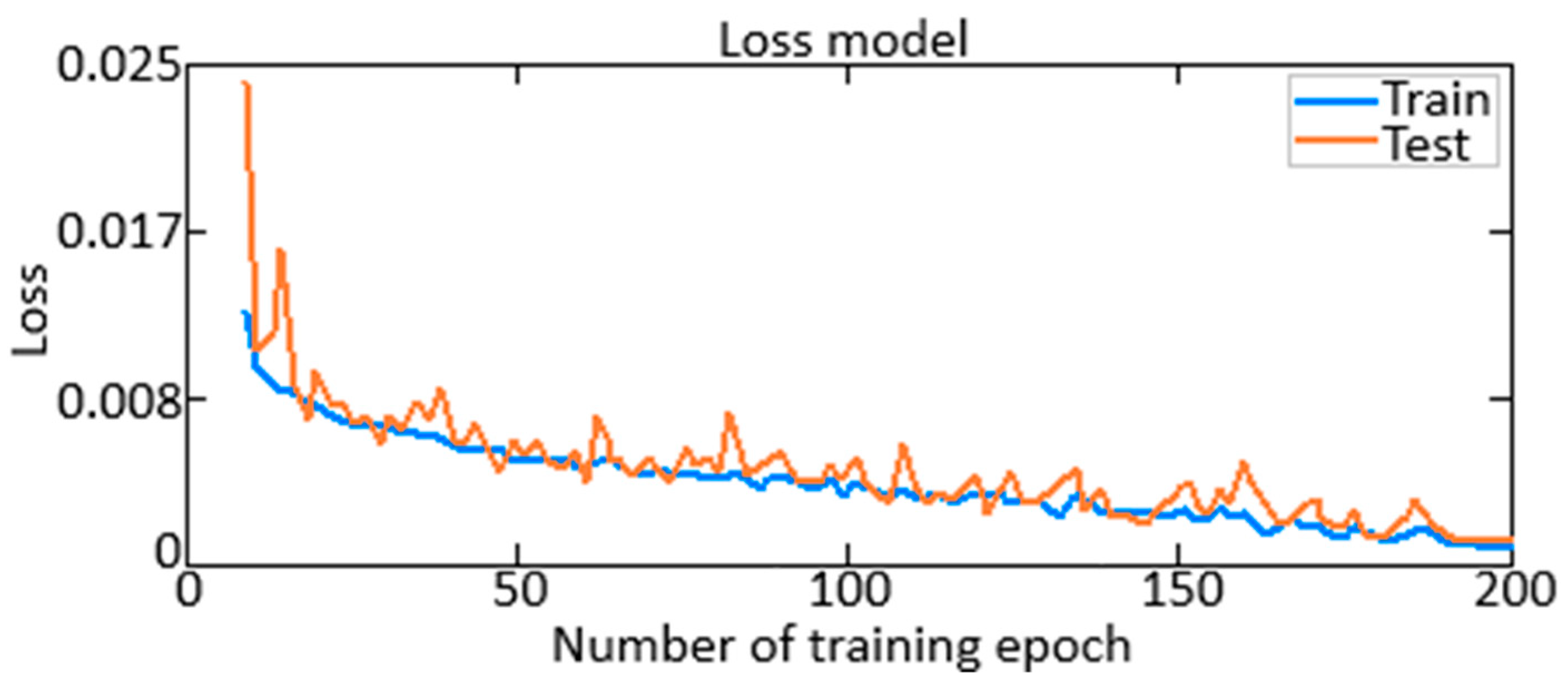
- The loss function dynamics made it possible to evaluate the model training effectiveness. A decrease in the loss function on the training data set indicates that the model is successfully training and identifying patterns in the data. The loss function on the validation data set also decreases at the same time, which indicates the elimination of the overfitting effect.
- The loss function dynamics comparison of the data set validation and training made it possible to assess the model generalization ability. Reducing the loss function on the validation and training data sets is also a pattern in the data. At the same time, the loss function on the validation data set also decreases, which indicates the overfitting effect elimination.
- The loss function dynamics analysis also helped determine whether adjustments to training parameters such as training rates or regularization coefficients were required. Since the loss function is reduced on the training and validation data sets, changes to the training parameters may not be necessary to improve the ANN training process.
5. Discussion
5.1. The Obtained Result Effectiveness Evaluation
- -
- Accuracy (precision);
- -
- Completeness (recall);
- -
- F-measure;
- -
- AUC (area under curve is the area under the ROC curve).
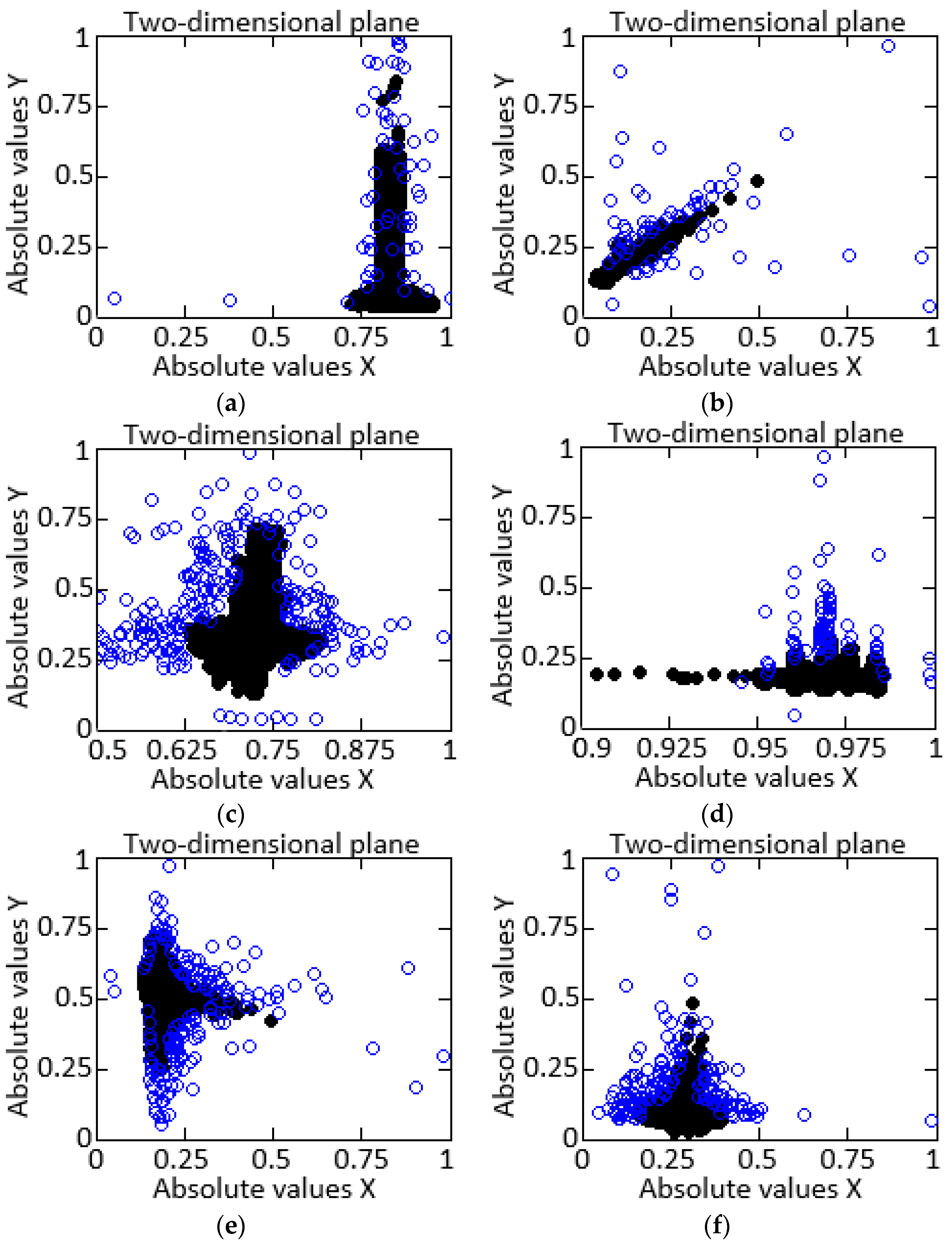
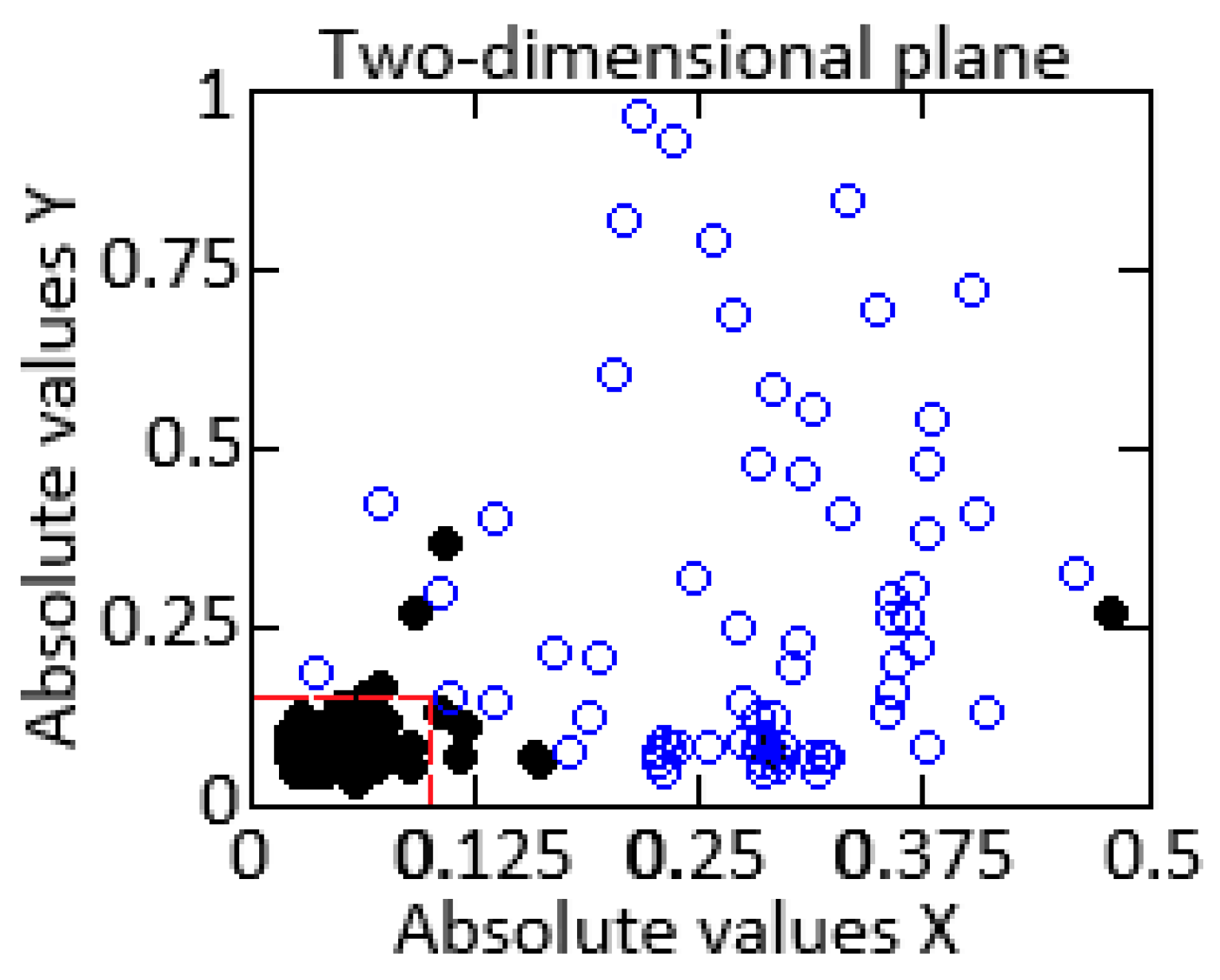
- The ANN recall and precision metrics, taking into account a slight imbalance in the data, are almost the same. Despite a slight imbalance, the support vector machine (SVM) managed to strike a harmony between precision and recall metrics, but it is still inferior to implemented autoencoders.
- For the F-measure metric, a similar situation arises since the F-measure is the harmonic mean between the precision and recall. This metric shows that the linear regression method stands out from other methods in that it was unable to cope with the qualitative classification of both normal and anomalous data.
- Analyzing the AUC-ROC value, it can be seen that the convolutional autoencoder showed the best performance, followed by the proposed ANN with structure 4–3–4. The SVM is only 10% inferior to the convolutional autoencoder due to its complex mathematical implementation and large classification penalties.
- Despite the convolutional autoencoder superiority, this neural network type is much inferior to other algorithms in training time terms. With larger data and more layers in the decoder and encoder, this figure will increase significantly, so this autoencoder applicability may be reduced.
- For anomaly detection, SVMs were optimized for comparison with autoencoders. From the obtained results, it is clear that after SVM optimization, its quality characteristics improved, but the training time increased 5 times.
5.2. The Obtained Results in Comparison with the Most Approximate Analog
5.3. Results Generalizations
- Further advancements have been made in refining the neural network approach for restoring lost data in the sensor failure event in intricate dynamic systems, which, through an auto-associative neural network (autoencoder) use, makes it possible to restore lost data with 99% accuracy. This is evidenced by the metrics of precision, recall, and F-measure, the values of which for normal data are 0.989, 0.987, and 0.988, respectively, and for abnormal data—0.967, 0.967, and 0.968, respectively.
- The basic training algorithm of an auto-associative neural network (autoencoder) has been improved by adding regularization to the loss function and updating the weights, which reduces the model overtraining risk when it adapts too much to the training data and loses the ability for new data generalization. It has been experimentally proven based on an improved training algorithm that an auto-associative neural network (autoencoder) indicates a minimal risk of model overtraining since the maximum value of the resulting loss function does not exceed 0.025 (2.5%).
- For the first time, a hypothesis on updating weights in an auto-associative neural network (autoencoder) using gradient descent with regularization was formulated and proven, which confirms the basic training algorithm improving the feasibility of an auto-associative neural network (autoencoder) and, as a result, the model complexity controlling and reducing its risk of retraining.
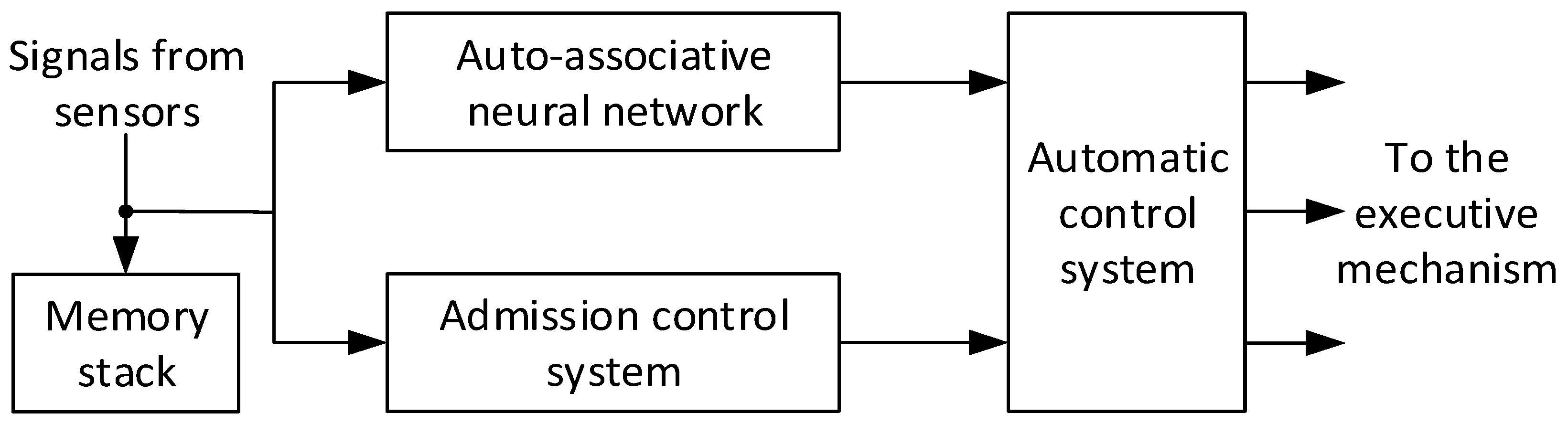
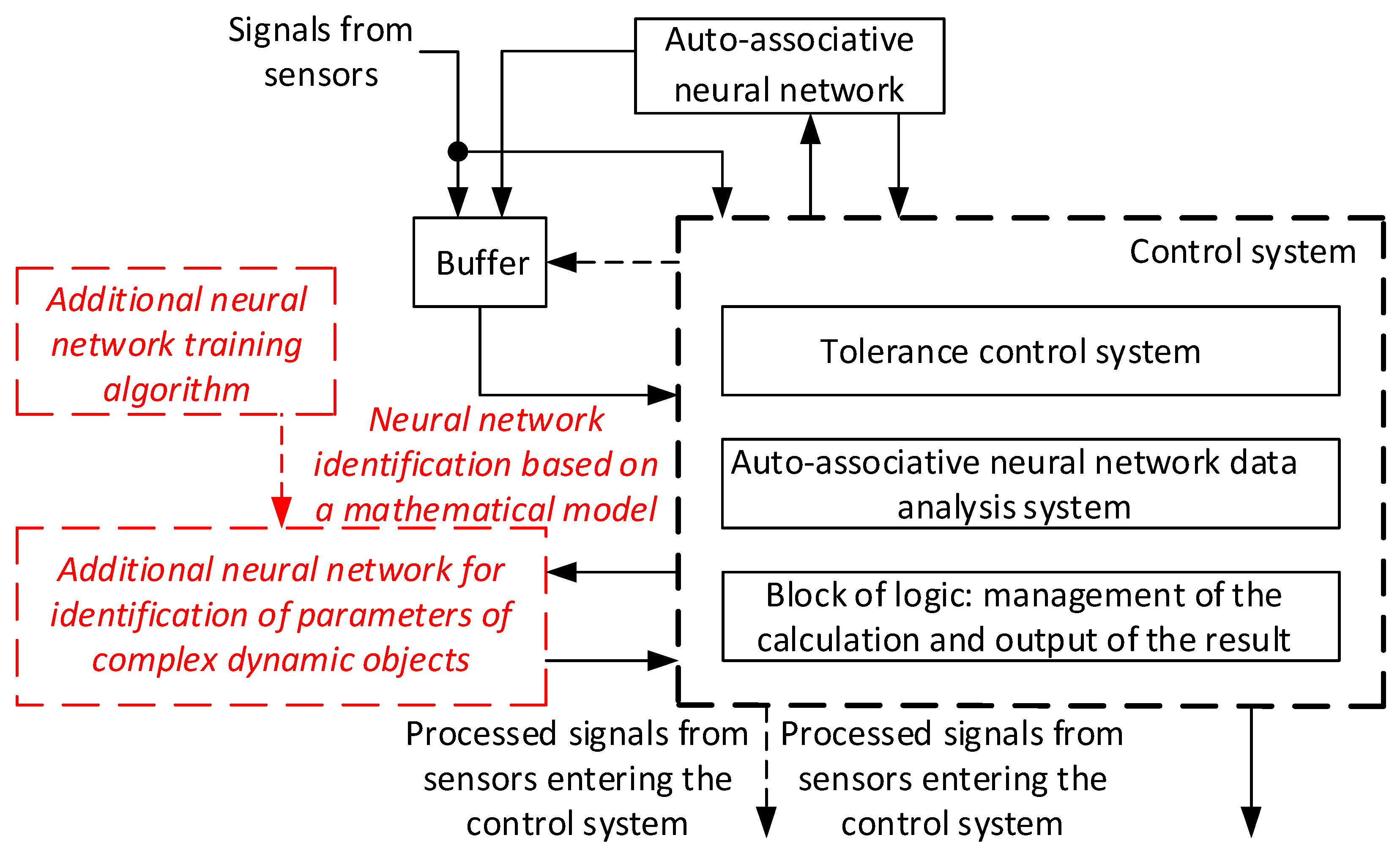
- The functional diagram of the system for restoring lost information has been improved, which is based on an additional neural network to identify the complex dynamic object parameters, and significant accuracy and efficiency of the lost information restoration process in the event of complex dynamic object sensor failures are achieved. This is explained by a decrease in the maximum error values in restoring lost information, namely:
- -
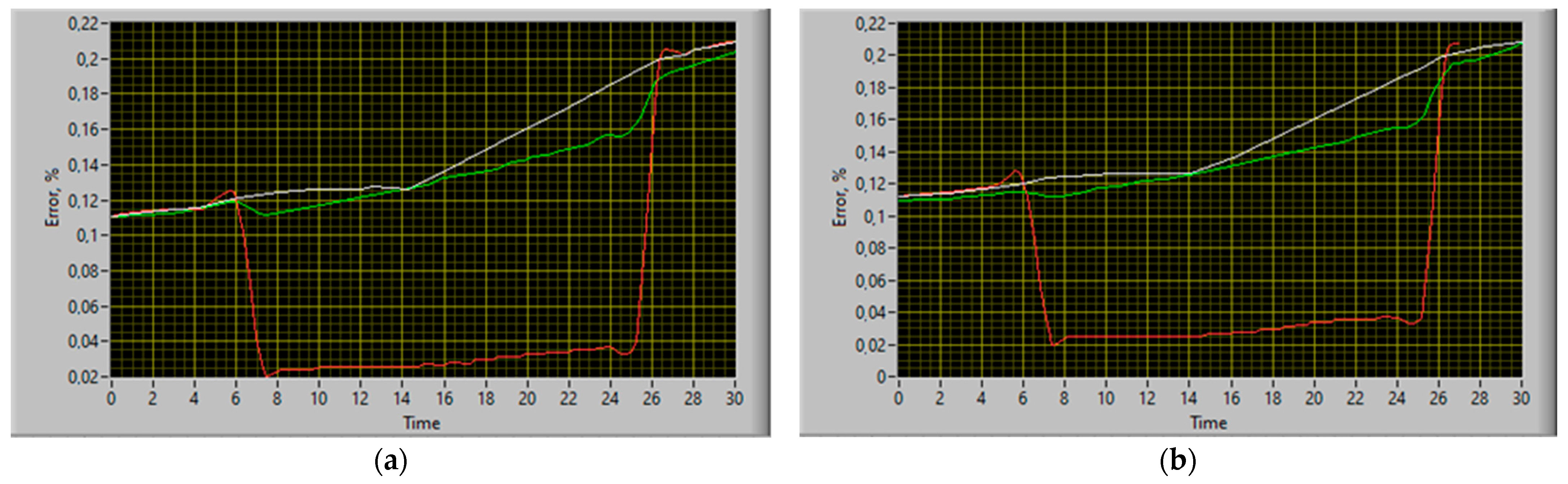
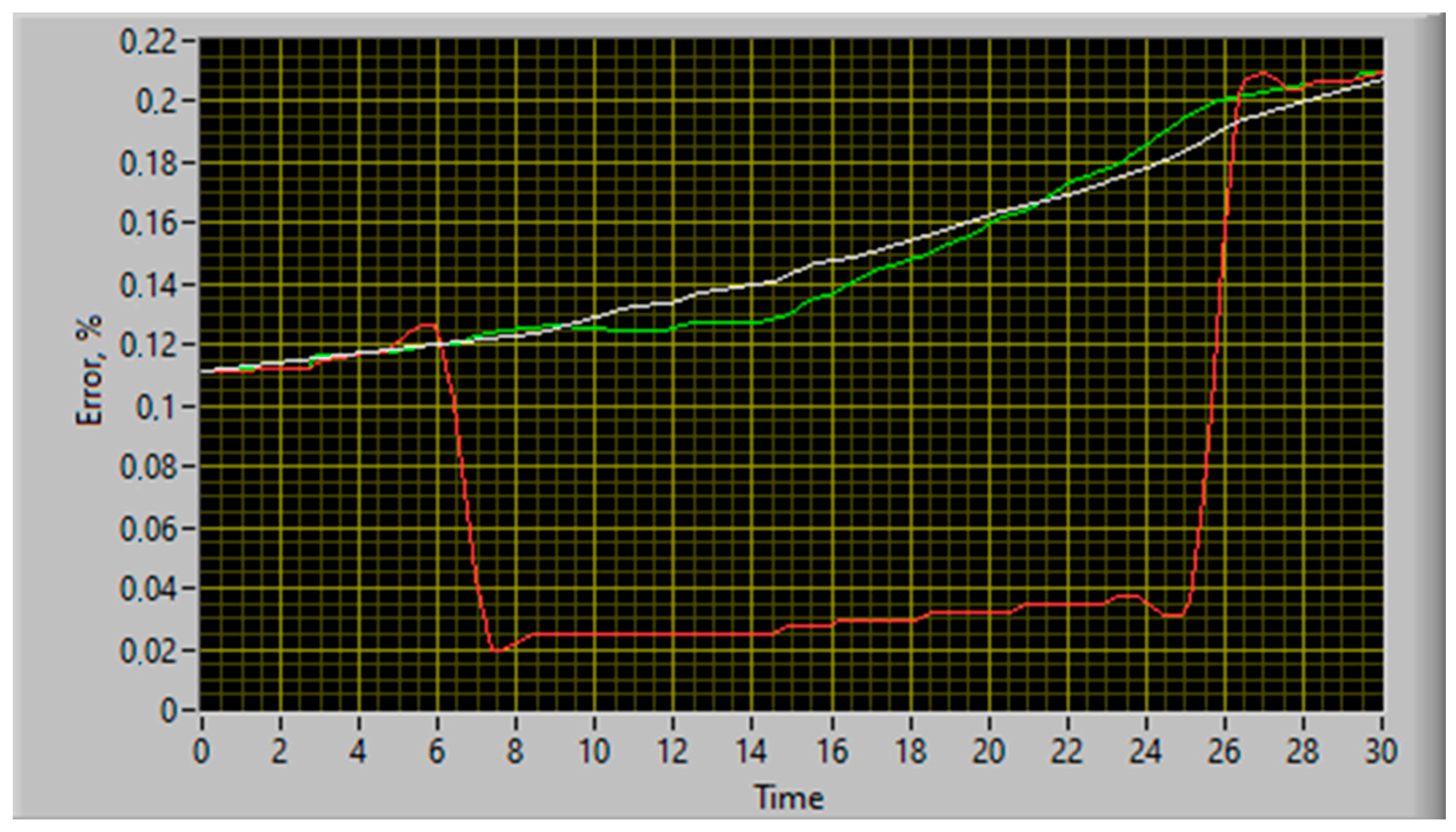
- A single sensor failure (break) example used for the TV3-117 turboshaft engine—it was established that the maximum error in restoring its parameters does not exceed 0.39%, while the maximum error in restoring its parameters using the basic functional diagram of the system for restoring lost information, developed by Zhernakov and Musluhov, is 0.42% [9,10,11], which is almost 10% more and can be critical during the complex dynamic object parameter identification, such as the TV3-117 turboshaft engine, under operating conditions;
- -
- A double (multiple) failure example used for the TV3-117 turboshaft engine sensors (breaks)—it was established that the maximum error in restoring its parameters does not exceed 0.50%, while the maximum error in restoring its parameters using the basic functional diagram of the system for restoring lost information, developed by Zhernakov and Musluhov, is 0.58% [9,10,11], which is almost 14% more and can be critical during the complex dynamic object parameter identification, such as the TV3-117 turboshaft engine, under operating conditions.
- The auto-associative neural network (autoencoder) using effectiveness as part of the functional diagram for lost information restoration system of complex dynamic objects has been experimentally confirmed in comparison with other auto-associative neural network (autoencoder) models (convolutional autoencoder) and classical machine learning methods (linear regression, SVM, optimized SVM) according to these methods evaluation metrics such as precision, recall, F-measure, AUC, as well as training time:
- -
- When using an auto-associative neural network (autoencoder) with an improved basic algorithm for its training, the precision, recall, F-measure, and AUC metric values for normal data are 0.989, 0.987, 0.988, and 0.990, respectively, and for abnormal data—0.967, 0.967, 0.968, and 0.990, accordingly; when using a convolutional autoencoder, for normal data, they are 0.953, 0.949, 0.951, and 0.957, respectively, and for anomalous data—0.903, 0.902, 0.903, and 0.957, respectively, which is almost 3.33 to 6.81% more. At the same time, the training time for the auto-associative neural network (autoencoder) with an improved basic algorithm for its training was 5 min 43 s, and for the convolutional autoencoder—38 min 16 s, which indicates a reduction in training time and, as a consequence, improvement in lost information restoration by 6.69 times.
- -
- When using an auto-associative neural network (autoencoder) with an improved basic algorithm for its training, the precision, recall, F-measure, and AUC metric values for normal data are 0.989, 0.987, 0.988, and 0.990, respectively, and for abnormal data—0.967, 0.967, 0.968, and 0.990, accordingly; when applying a model based on linear regression, for normal data, they are 0.772, 0.622, 0.594, and 0.654, respectively, and for abnormal data—0.685, 0.522, 0.466, and 0.654, respectively, which is almost 21.94 to 51.86% more. At the same time, the training time for an auto-associative neural network (autoencoder) with an improved basic algorithm for its training was 5 min 43 s, and for a model based on linear regression—2 min 11 s. Although models based on linear regression train 2.62 times faster than auto-associative neural network models (autoencoder), their use in lost information restoration tasks for complex dynamic objects reduces accuracy by 21.94 to 51.86%.
- -
- When using an auto-associative neural network (autoencoder) with an improved basic algorithm for its training, the precision, recall, F-measure, and AUC metric values for normal data are 0.989, 0.987, 0.988, and 0.990, respectively, and for abnormal data—0.967, 0.967, 0.968, and 0.990, accordingly; when using a model based on the SVM, for normal data, they are 0.902, 0.903, 0.902, and 0.904, respectively, and for abnormal data—0.788, 0.781, 0.784, and 0.904, respectively, which is almost 8.51 to 19.23% more. At the same time, the training time for an auto-associative neural network (autoencoder) with an improved basic algorithm for its training was 5 min 43 s, and for a model based on the SVM—6 min 11 s, which indicates a reduction in training time and, as a consequence, improvement in restoring lost information by 1.08 times.
- -
- When using an auto-associative neural network (autoencoder) with an improved basic algorithm for its training, the precision, recall, F-measure, and AUC metric values for normal data are 0.989, 0.987, 0.988, and 0.990, respectively, and for abnormal data—0.967, 0.967, 0.968, and 0.990, accordingly; when using a model based on the optimized SVM, for normal data, they are 0.949, 0.943, 0.945, and 0.948, respectively, and for abnormal data—0.795, 0.798, 0.793, and 0.948, respectively, which is almost 4.04 to 18.08% more. At the same time, the training time of the auto-associative neural network (autoencoder) with an improved basic algorithm for its training was 5 min 43 s. The model based on the optimized SVM was 18 min 24 s, which indicates a reduction in training time and, as a consequence, improvement in lost information restoration by 3.22 times.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lutsenko, I.; Mykhailenko, O.; Dmytriieva, O.; Rudkovskyi, O.; Kukharenko, D.; Kolomits, H.; Kuzmenko, A. Development of a method for structural optimization of a neural network based on the criterion of resource utilization efficiency. East.-Eur. J. Enterp. Technol. 2019, 2, 57–65. [Google Scholar] [CrossRef]
- Pang, S.; Li, Q.; Ni, B. Improved nonlinear MPC for aircraft gas turbine engine based on semi-alternative optimization strategy. Aerosp. Sci. Technol. 2021, 118, 106983. [Google Scholar] [CrossRef]
- Kuzin, T.; Borovicka, T. Early Failure Detection for Predictive Maintenance of Sensor Parts. CEUR Workshop Proc. 2016, 1649, 123–130. Available online: https://ceur-ws.org/Vol-1649/123.pdf (accessed on 23 December 2023).
- Li, D.; Wang, Y.; Wang, J.; Wang, C.; Duan, Y. Recent advances in sensor fault diagnosis: A review. Sens. Actuators A Phys. 2020, 309, 111990. [Google Scholar] [CrossRef]
- Ntantis, E.L.; Botsaris, P. Diagnostic methods for an aircraft engine performance. J. Eng. Sci. Technol. 2015, 8, 64–72. [Google Scholar] [CrossRef]
- Krivosheev, I.; Rozhkov, K.; Simonov, N. Complex Diagnostic Index for Technical Condition Assessment for GTE. Procedia Eng. 2017, 206, 176–181. [Google Scholar] [CrossRef]
- Krukowski, M. Majority rule as a unique voting method in elections with multiple candidates. arXiv 2023, arXiv:2310.12983. Available online: https://arxiv.org/pdf/2310.12983.pdf (accessed on 29 December 2023).
- Shen, Y.; Khorasani, K. Hybrid multi-mode machine learning-based fault diagnosis strategies with application to aircraft gas turbine engines. Neural Netw. 2020, 130, 126–142. [Google Scholar] [CrossRef] [PubMed]
- Zhernakov, S.V.; Musluhov, I.I. Neurocomputer for recovering lost information from standard sensors of the on-board monitoring and diagnostic system. Neuroinformatics 2006, 3, 180–188. [Google Scholar]
- Zhernakov, S.V.; Musluhov, I.I. Parrying sensor failures in gas turbine engines using neural networks. Comput. Technol. New Inf. Technol 2003, 1, 35–41. [Google Scholar]
- Vasiliev, V.I.; Zhernakov, S.V.; Musluhov, I.I. Onboard algorithms for control of GTE parameters based on neural network technology. Bull. USATU 2009, 12, 61–74. [Google Scholar]
- Li, B.; Zhao, Y.-P.; Chen, Y.-B. Unilateral alignment transfer neural network for fault diagnosis of aircraft engine. Aerosp. Sci. Technol. 2021, 118, 107031. [Google Scholar] [CrossRef]
- Zocco, F.; McLoone, S. Recovery of linear components: Reduced complexity autoencoder designs. Eng. Appl. Artif. Intell. 2022, 109, 104663. [Google Scholar] [CrossRef]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; van den Hengel, A. Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar] [CrossRef]
- Karpenko, D.; Dolgikh, S.; Prystavka, P.; Cholyshkina, O. Automated object recognition system based on convolutional autoencoder. In Proceedings of the 10th International Conference on Advanced Computer Information Technologies (ACIT-2020), Deggendorf, Germany, 16–18 September 2020. [Google Scholar] [CrossRef]
- Phan, P.H.; Nguyen, A.Q.; Quach, L.-D.; Tran, H.N. Robust Autonomous Driving Control using Auto-Encoder and End-to-End Deep Learning under Rainy Conditions. In Proceedings of the 2023 8th International Conference on Intelligent Information Technology, New York, NY, USA, 24–26 February 2023; pp. 271–278. [Google Scholar] [CrossRef]
- Campo, D.; Slavic, G.; Baydoun, M.; Marcenaro, L.; Regazzoni, C. Continual Learning of Predictive Models In Video Sequences Via Variational Autoencoders. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020. [Google Scholar] [CrossRef]
- Fu, Y.; Yang, B.; Ye, O. Spatiotemporal Masked Autoencoder with Multi-Memory and Skip Connections for Video Anomaly Detection. Electronics 2024, 13, 353. [Google Scholar] [CrossRef]
- Nazarkevych, M.; Dmytruk, S.; Hrytsyk, V.; Vozna, O.; Kuza, A.; Shevchuk, O.; Sheketa, V.; Maslanych, I.; Voznyi, Y. Evaluation of the Effectiveness of Different Image Skeletonization Methods in Biometric Security Systems. Int. J. Sens. Wirel. Commun. Control. 2020, 11, 542–552. [Google Scholar] [CrossRef]
- Baranovskyi, D.; Bulakh, M.; Michajłyszyn, A.; Myamlin, S.; Muradian, L. Determination of the Risk of Failures of Locomotive Diesel Engines in Maintenance. Energies 2023, 16, 4995. [Google Scholar] [CrossRef]
- Baranovskyi, D.; Myamlin, S. The criterion of development of processes of the self organization of subsystems of the second level in tribosystems of diesel engine. Sci. Rep. 2023, 13, 5736. [Google Scholar] [CrossRef]
- Shi, H.; Shi, X.; Dogan, S. Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks. Future Internet 2024, 16, 63. [Google Scholar] [CrossRef]
- Dutta, R.; Kandath, H.; Jayavelu, S.; Xiaoli, L.; Sundaram, S.; Pack, D. A decentralized learning strategy to restore connectivity during multi-agent formation control. Neurocomputing 2023, 520, 33–45. [Google Scholar] [CrossRef]
- Ushakov, N.; Ushakov, V. Statistical analysis of rounded data: Recovering of information lost due to rounding. J. Korean Stat. Soc. 2017, 46, 426–437. [Google Scholar] [CrossRef]
- Lin, R.; Liu, S.; Jiang, J.; Li, S.; Li, C.; Jay Kuo, C.-C. Recovering sign bits of DCT coefficients in digital images as an optimization problem. J. Vis. Commun. Image Represent. 2024, 98, 104045. [Google Scholar] [CrossRef]
- Takada, T.; Hoogland, J.; van Lieshout, C.; Schuit, E.; Collins, G.S.; Moons, K.G.M.; Reitsma, J.B. Accuracy of approximations to recover incompletely reported logistic regression models depended on other available information. J. Clin. Epidemiol. 2022, 143, 81–90. [Google Scholar] [CrossRef]
- Shiroma, Y.; Kinoshita, Y.; Imoto, K.; Shiota, S.; Ono, N.; Kiya, H. Missing data recovery using autoencoder for multi-channel acoustic scene classification. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022. [Google Scholar] [CrossRef]
- Manuel Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Conditional Variational Autoencoder for Prediction and Feature Recovery Applied to Intrusion Detection in IoT. Sensors 2017, 17, 1967. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Li, H.; Zhang, Z.; Gan, C. The Optimally Designed Variational Autoencoder Networks for Clustering and Recovery of Incomplete Multimedia Data. Sensors 2019, 19, 809. [Google Scholar] [CrossRef] [PubMed]
- Abitbul, K.; Dar, Y. Recovery of Training Data from Overparameterized Autoencoders: An Inverse Problem Perspective. arXiv 2023, arXiv:2310.02897. Available online: https://arxiv.org/pdf/2310.02897.pdf (accessed on 10 February 2024). [CrossRef]
- Liu, Y.; Tan, X.; Bao, Y. Machine learning-assisted intelligent interpretation of distributed fiber optic sensor data for automated monitoring of pipeline corrosion. Measurement 2024, 226, 114190. [Google Scholar] [CrossRef]
- Casella, M.; Dolce, P.; Ponticorvo, M.; Marocco, D. Autoencoders as an alternative approach to Principal Component Analysis for dimensionality reduction. An application on simulated data from psychometric models. CEUR Workshop Proc. 2022, 3100. Available online: https://ceur-ws.org/Vol-3100/paper19.pdf (accessed on 15 February 2024).
- Casella, M.; Dolce, P.; Ponticorvo, M.; Marocco, D. From Principal Component Analysis to Autoencoders: A comparison on simulated data from psychometric models. In Proceedings of the 2022 IEEE International Conference on Metrology for Extended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Rome, Italy, 26–28 October 2022. [Google Scholar] [CrossRef]
- Shah, B.; Sarvajith, M.; Sankar, B.; Thennavarajan, S. Multi-Auto Associative Neural Network based sensor validation and estimation for aero-engine. In Proceedings of the 2013 IEEE AUTOTESTCON, Schaumburg, IL, USA, 16–19 September 2013. [Google Scholar] [CrossRef]
- Catana, R.M.; Dediu, G. Analytical Calculation Model of the TV3-117 Turboshaft Working Regimes Based on Experimental Data. Appl. Sci. 2023, 13, 10720. [Google Scholar] [CrossRef]
- Gebrehiwet, L.; Nigussei, Y.; Teklehaymanot, T. A Review-Differentiating TV2 and TV3 Series Turbo Shaft Engines. Int. J. Res. Publ. Rev. 2022, 3, 1822–1838. [Google Scholar] [CrossRef]
- Vladov, S.; Shmelov, Y.; Yakovliev, R.; Petchenko, M. Modified Neural Network Fault-Tolerant Closed Onboard Helicopters Turboshaft Engines Automatic Control System. CEUR Workshop Proc. 2023, 3387, 160–179. Available online: https://ceur-ws.org/Vol-3387/paper13.pdf (accessed on 24 February 2024).
- Vladov, S.; Yakovliev, R.; Hubachov, O.; Rud, J.; Stushchanskyi, Y. Neural Network Modeling of Helicopters Turboshaft Engines at Flight Modes Using an Approach Based on “Black Box” Models. CEUR Workshop Proc. 2024, 3624, 116–135. Available online: https://ceur-ws.org/Vol-3624/Paper_11.pdf (accessed on 24 February 2024).
- Vladov, S.; Yakovliev, R.; Bulakh, M.; Vysotska, V. Neural Network Approximation of Helicopter Turboshaft Engine Parameters for Improved Efficiency. Energies 2024, 17, 2233. [Google Scholar] [CrossRef]
- Corotto, F.S. Appendix C—The method attributed to Neyman and Pearson. In Wise Use of Null Hypothesis Tests; Academic Press: San Diego, CA, USA, 2023; pp. 179–188. [Google Scholar] [CrossRef]
- Motsnyi, F.V. Analysis of Nonparametric and Parametric Criteria for Statistical Hypotheses Testing. Chapter 1. Agreement Criteria of Pearson and Kolmogorov. Stat. Ukr. 2018, 83, 14–24. [Google Scholar] [CrossRef]
- Babichev, S.; Krejci, J.; Bicanek, J.; Lytvynenko, V. Gene expression sequences clustering based on the internal and external clustering quality criteria. In Proceedings of the 2017 12th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 5–8 September 2017. [Google Scholar] [CrossRef]
- Hu, Z.; Kashyap, E.; Tyshchenko, O.K. GEOCLUS: A Fuzzy-Based Learning Algorithm for Clustering Expression Datasets. Lect. Notes Data Eng. Commun. Technol. 2022, 134, 337–349. [Google Scholar] [CrossRef]
- Andresini, G.; Appice, A.; Malerba, D. Autoencoder-based deep metric learning for network intrusion detection. Inf. Sci. 2021, 569, 706–727. [Google Scholar] [CrossRef]
- Gornyi, B.E.; Ryjov, A.P.; Strogalov, A.S.; Zhuravlev, A.D.; Khusaenov, A.A.; Shergin, I.A.; Feshchenko, D.A.; Abdullaev, A.M.; Kontsevaya, A.V. The adverse clinical outcome risk assessment by in-depth data analysis methods. Intell. Syst. Theory Appl. 2021, 25, 23–45. [Google Scholar]
- Khusaenov, A.A. Autoassociative neural networks in a classification problem with truncated dataset. Intell. Syst. Theory Appl. 2022, 26, 33–41. [Google Scholar]
- Dong, X.; Bai, Y.-L.; Wan, W.-D. Kernel functions embed into the autoencoder to identify the sparse models of nonlinear dynamics. Commun. Nonlinear Sci. Numer. Simul. 2024, 131, 107869. [Google Scholar] [CrossRef]
- Kanishima, Y.; Sudo, T.; Yanagihashi, H. Autoencoder with Adaptive Loss Function for Supervised Anomaly Detection. Procedia Comput. Sci. 2022, 207, 563–572. [Google Scholar] [CrossRef]
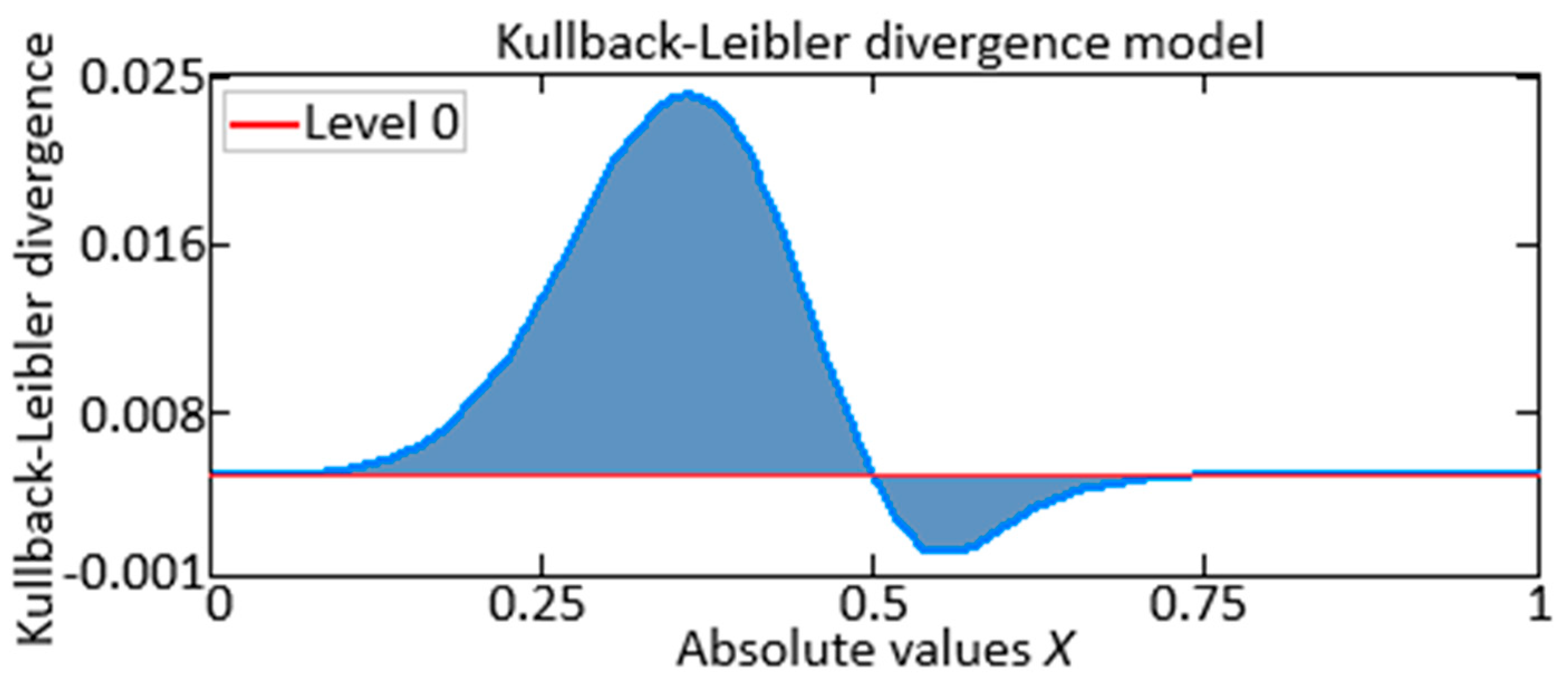
- Impraimakis, M. A Kullback–Leibler divergence method for input–system–state identification. J. Sound Vib. 2024, 569, 117965. [Google Scholar] [CrossRef]
- Vladov, S.I.; Doludarieva, Y.S.; Siora, A.S.; Ponomarenko, A.V.; Yanitskyi, A.A. Neural network computer for recovering lost information from standard sensors of the on-board system for control and diagnosing of TV3-117 aircraft engine. Innov. Technol. Sci. Solut. Ind. 2020, 4, 147–154. [Google Scholar] [CrossRef]
- Safronov, D.A.; Kazer, Y.D.; Zaytsev, K.S. Anomaly detection with autoencoders. Int. J. Open Inf. Technol. 2022, 10, 39–45. [Google Scholar]
- Gus’kov, S.Y.; Lyovin, V.V. Confidence interval estimation for quality factors of binary classifiers–ROC curves, AUC for small samples. Eng. J. Sci. Innov. 2015, 3, 1–15. Available online: http://engjournal.ru/catalog/mesc/idme/1376.html (accessed on 10 March 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Free Turbine Rotor Speed | Gas Generator Rotor r.p.m | Gas Temperature in the Compressor Turbine Front | Fuel Consumption |
|---|---|---|---|---|
| 1 | 0.943 | 0.929 | 0.932 | 0.952 |
| … | … | … | … | … |
| 58 | 0.985 | 0.983 | 0.899 | 0.931 |
| … | … | … | … | … |
| 144 | 0.982 | 0.980 | 0.876 | 0.925 |
| … | … | … | … | … |
| 256 | 0.981 | 0.973 | 0.953 | 0.960 |
| Encoder | Decoder | Epoch | Batch Size | Training Data | Test Data | Optimizer |
|---|---|---|---|---|---|---|
| ReLU | Sigmoid | 200 | 250 | 5 × 10−4 | 1 × 10−4 | Adam |
| Auto-Associative Neural Network Structure | TV3-117 Turboshaft Engine Parameter Restoration Error,% | |||
|---|---|---|---|---|
| GT | nTC | nFT | ||
| 4–3–4 as part of the proposed improved functional diagram (Figure 14) | 0.31 | 0.28 | 0.19 | 0.31 |
| 5–4–5 as part of a basic functional diagram developed by Zhernakov and Musluhov [9,10,11] | 0.33 | 0.31 | 0.24 | 0.42 |
| Auto-Associative Neural Network Structure | TV3-117 Turboshaft Engine Parameter Restoration Error,% | |||
|---|---|---|---|---|
| GT | nTC | nFT | ||
| 4–3–4 as the proposed improved functional diagram part (Figure 14) | 0.42 | 0.39 | 0.40 | 0.43 |
| 5–4–5 as a basic functional diagram part developed by Zhernakov and Musluhov [9,10,11] | 0.56 | 0.45 | 0.44 | 0.58 |
| Algorithm for Restoring Lost Information | Data Types | Metrics for Evaluating Methods | Training Time | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | AUC | |||
| Proposed ANN | Normal | 0.989 | 0.987 | 0.988 | 0.990 | 5 min 43 s |
| Abnormal | 0.967 | 0.967 | 0.968 | |||
| Convolutional autoencoder | Normal | 0.953 | 0.949 | 0.951 | 0.957 | 38 min 16 s |
| Abnormal | 0.902 | 0.903 | 0.902 | |||
| Linear regression | Normal | 0.772 | 0.622 | 0.594 | 0.654 | 2 min 11 s |
| Abnormal | 0.685 | 0.522 | 0.466 | |||
| SVM | Normal | 0.902 | 0.903 | 0.902 | 0.904 | 6 min 11 s |
| Abnormal | 0.788 | 0.781 | 0.784 | |||
| SVM (optimized) | Normal | 0.949 | 0.943 | 0.945 | 0.948 | 18 min 24 s |
| Abnormal | 0.795 | 0.798 | 0.793 | |||
| Criterion | Proposed Method | The Closest Analog [9,10,11] | Proposed Method Advantages |
|---|---|---|---|
| ANN structure choice | ANN structure choice is carried out according to a decrease in the neuron number in the output layer by one. | ANN structure choice is carried out based on the minimum error in reconstructing ANN information from the neurons’ number in the “shaft”. | A simpler criterion for determining the ANN structure without losing its training accuracy (see metrics in Table 5). |
| ANS training method | Modified ANN training method—gradient descent method with regularization. | Traditional ANS training method—gradient descent method. | The model overtraining risk reducing, with its strong adaptation to training data and the ability loss to generalize new data (see the loss function diagram, the maximum value of which does not exceed 2.5%, Figure 10) |
| Restoring lost information | The maximum error in restoring lost information does not exceed 0.50% (see Table 4) in the TV3-117 TE sensor double (multiple) failure situations. | The maximum error in restoring lost information does not exceed 0.58% (see Table 4) in the TV3-117 TE sensor double (multiple) failure situations. | The lost information restoration accuracy increasing by 10 to 14% is of key importance when operating complex dynamic objects such as the TV3-117 TE in helicopter flight mode. |
| Accuracy | The lost ANN information restoration task solving accuracy on the test data set is 0.988 (98.8%). | The lost ANN information restoration task solving accuracy on the test data set is 0.901 (90.1%). | The lost ANN information restoration task solving accuracy increase on a test data set by 8.8% is critical when operating complex dynamic objects such as the TV3-117 TE in helicopter flight mode. |
| Training rate | The ANN training time using the proposed method of training was 5 min 43 s–343 s (AMD Ryzen 5 5600 processor, 32 KB third-level cache, Zen 3 architecture, 6 cores, 12 threads, 3.5 GHz, RAM—32 GB DDR-4). | The ANN training time using the traditional method of training was 5 min 34 s–334 s (AMD Ryzen 5 5600 processor, 32 KB third-level cache, Zen 3 architecture, 6 cores, 12 threads, 3.5 GHz, RAM—32 GB DDR-4). | During the ANN training using the proposed method, the speed practically does not decrease compared with the classical method of training (the decrease is by 9 s, which is insignificant), while the regularization introduction into the classical method of training reduces the risk of overtraining the model. |
| Generalization ability | The determination coefficient was 0.996. | The determination coefficient was 0.850. | An increase in the determination coefficient by 14.7% indicates a 14.7% increase in the ANN efficiency to work on new data that it did not see during training. |
| Resource efficiency | Testing was carried out on an AMD Ryzen 5 5600 processor, 32 KB L3 cache, Zen 3 architecture, 6 cores, 12 threads, 3.5 GHz, 32 GB DDR-4 RAM, with an efficiency metric of 0.00288. | Testing was carried out on an AMD Ryzen 5 5600 processor, 32 KB L3 cache, Zen 3 architecture, 6 cores, 12 threads, 3.5 GHz, 32 GB DDR-4 RAM, with an efficiency metric of 0.00270. | The ANN proposed in this work demonstrates a 6.25% accuracy compared with [9,10,11] by the resources expended, which can be significant when operating complex dynamic objects such as the TV3-117 TE in helicopter flight mode. |
| Robustness | The average deviation was 0.00524. | The average deviation was 0.01148. | A decrease in the average deviation by 45.6% indicates that the ANN proposed in this work is almost two times more robust compared with [9,10,11], which indicates the possibility of maintaining high accuracy on different data sets or under different conditions. |
| Subsample Number | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| Proposed Method (ANN 1) | 0.991 | 0.982 | 0.984 | 0.981 | 0.985 | 0.994 | 0.995 | 0.992 | 0.988 |
| The closest Analog [9,10,11] (ANN 2) | 0.914 | 0.913 | 0.906 | 0.889 | 0.893 | 0.888 | 0.915 | 0.889 | 0.901 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vladov, S.; Yakovliev, R.; Vysotska, V.; Nazarkevych, M.; Lytvyn, V. The Method of Restoring Lost Information from Sensors Based on Auto-Associative Neural Networks. Appl. Syst. Innov. 2024, 7, 53. https://doi.org/10.3390/asi7030053
Vladov S, Yakovliev R, Vysotska V, Nazarkevych M, Lytvyn V. The Method of Restoring Lost Information from Sensors Based on Auto-Associative Neural Networks. Applied System Innovation. 2024; 7(3):53. https://doi.org/10.3390/asi7030053
Chicago/Turabian StyleVladov, Serhii, Ruslan Yakovliev, Victoria Vysotska, Mariia Nazarkevych, and Vasyl Lytvyn. 2024. "The Method of Restoring Lost Information from Sensors Based on Auto-Associative Neural Networks" Applied System Innovation 7, no. 3: 53. https://doi.org/10.3390/asi7030053