
Unsupervised Machine Learning to Detect Impending Anomalies in Testing of Fuel Economy and Emissions of Light-Duty Vehicles

 ,
,  , and
, and
Abstract
:1. Introduction
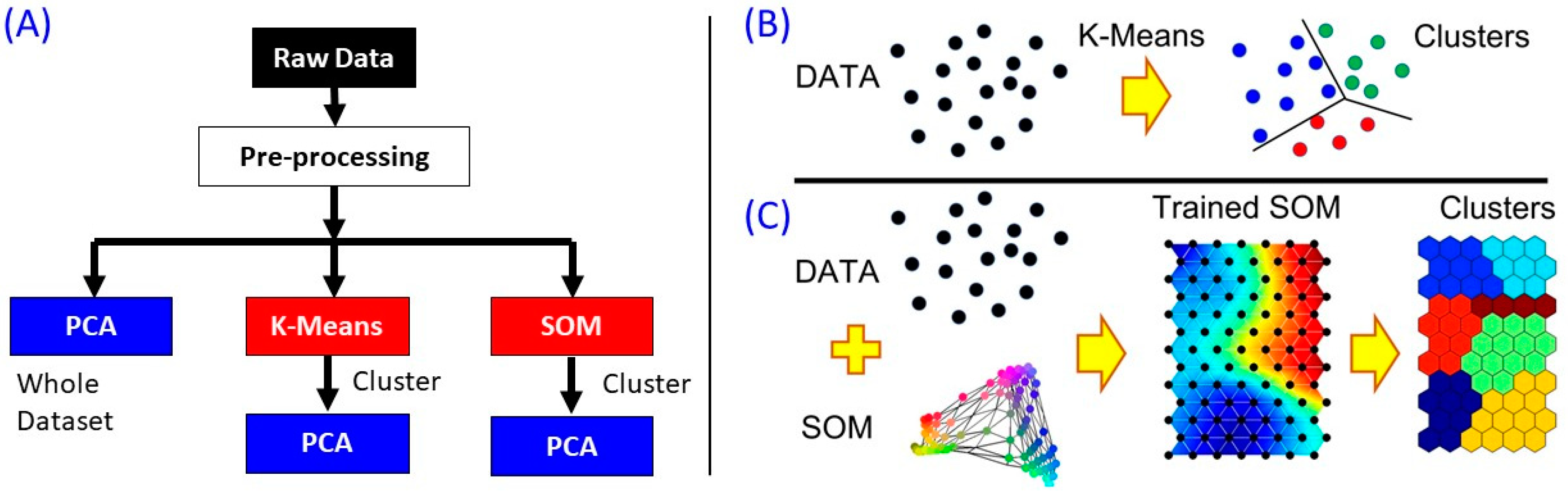
2. Methodology
2.1. Data Source
2.2. Data Preprocessing
2.3. Data Analysis
2.3.1. K-Means Implementation
2.3.2. SOM Implementation
2.3.3. Linear Discriminant Analysis
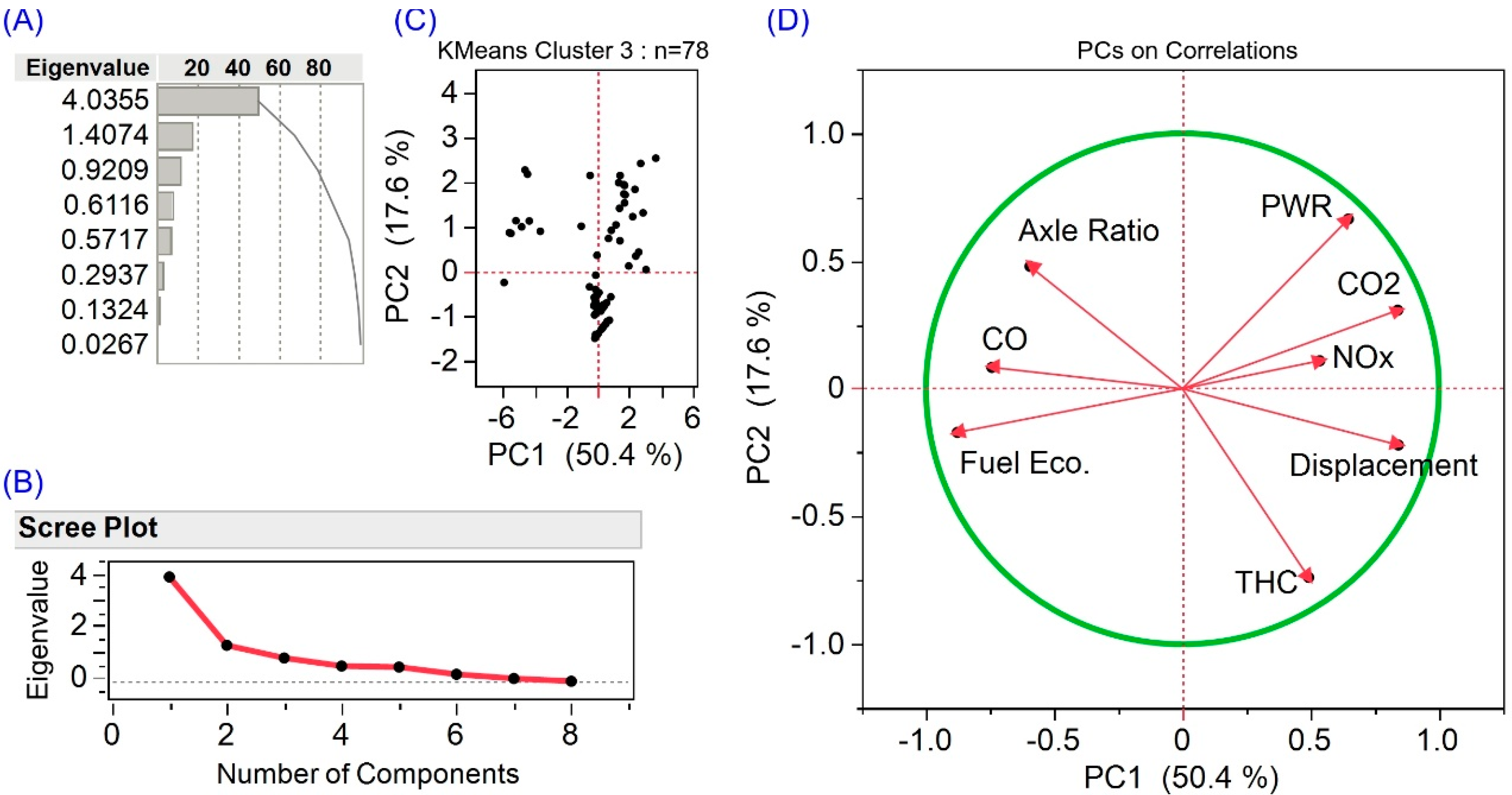
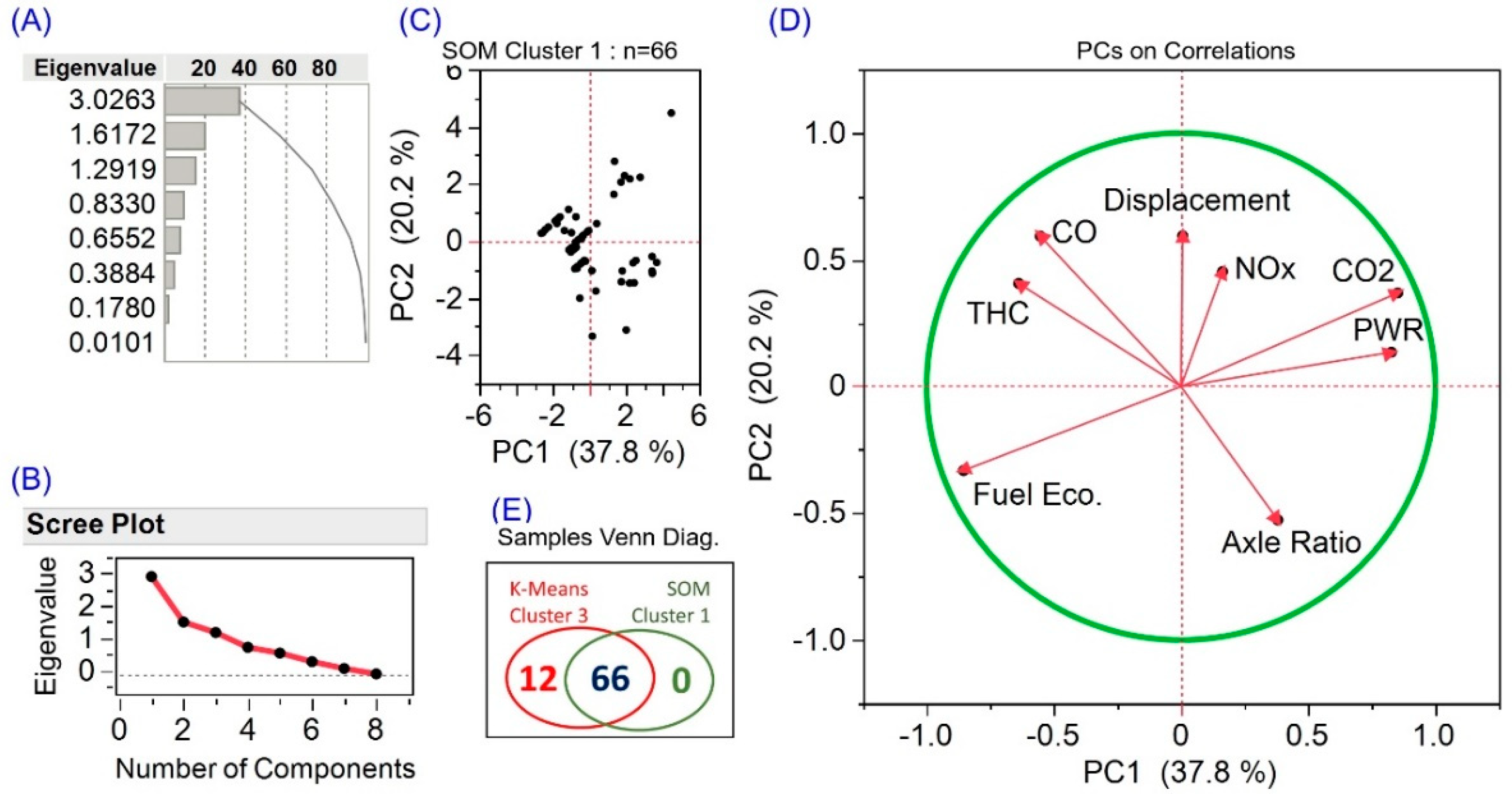
2.3.4. PCA Implementation
3. Results and Discussion
3.1. Whole Dataset Fuel Economy and Emissions
3.2. Clustered Dataset Fuel Economy and Emissions
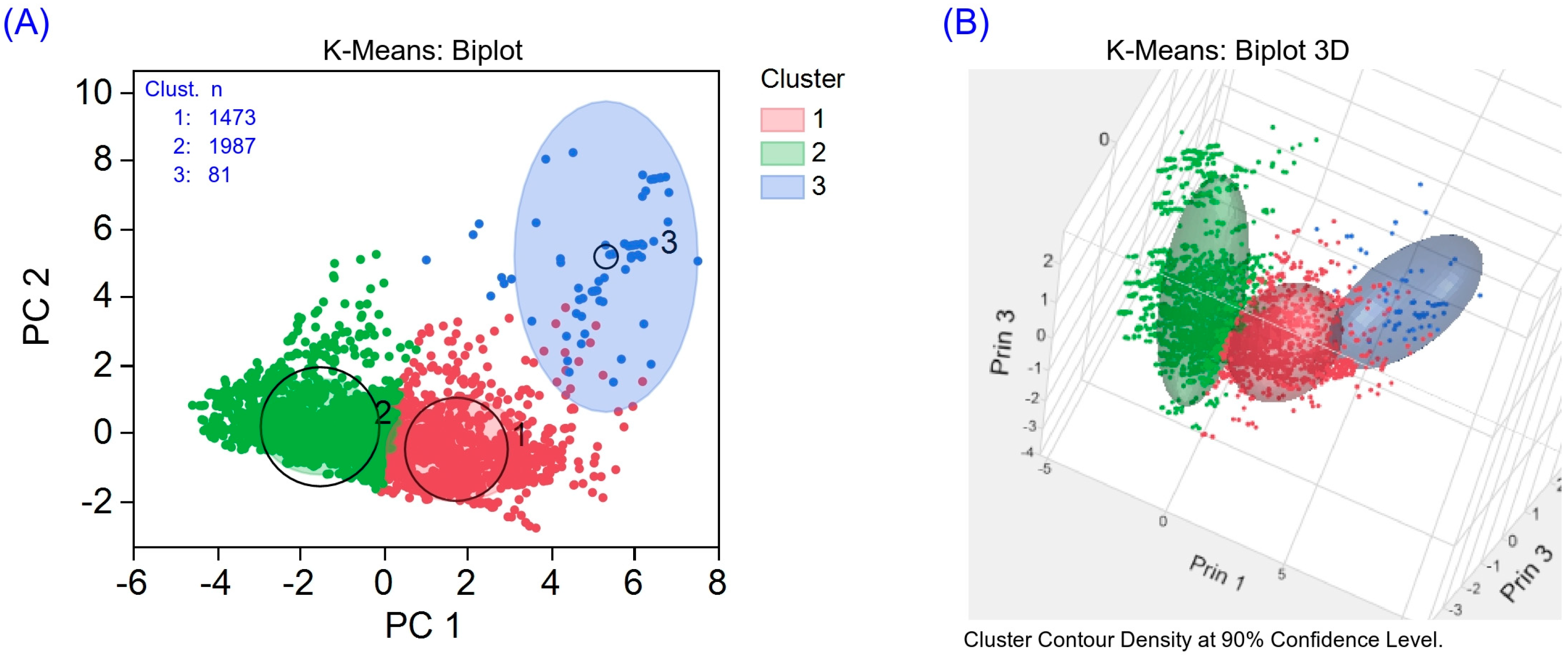
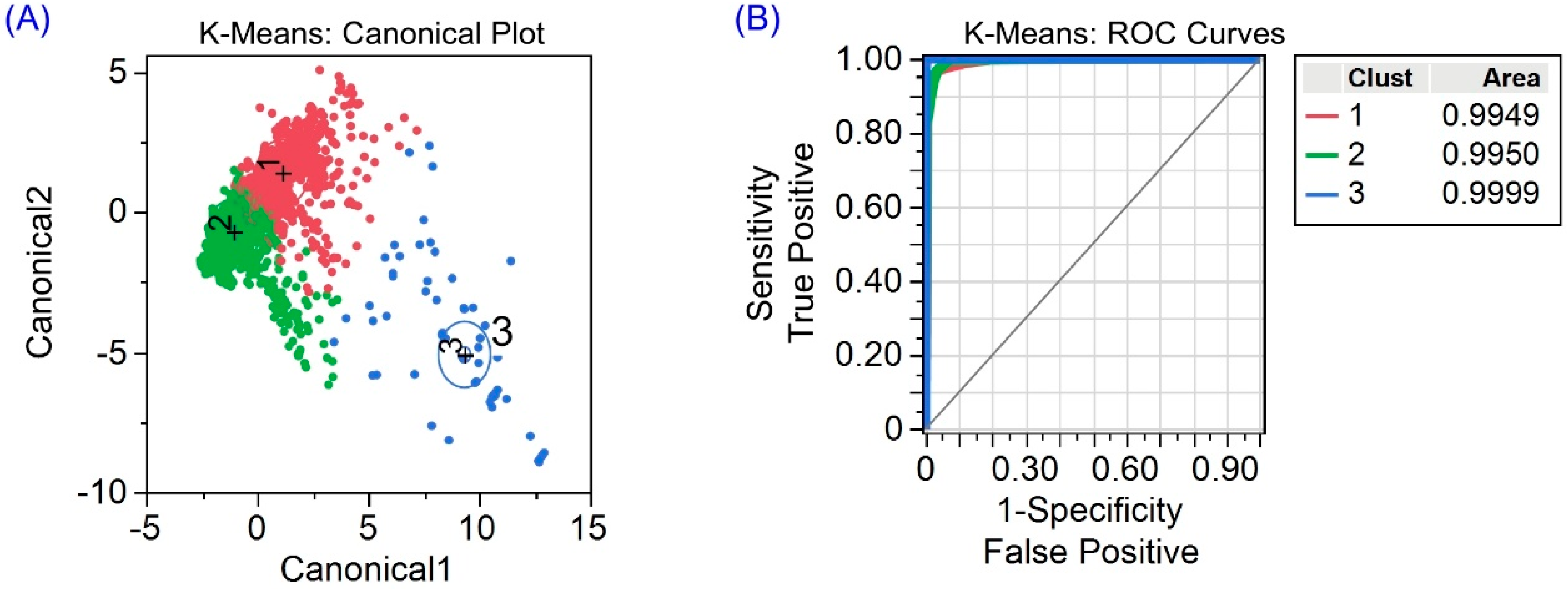
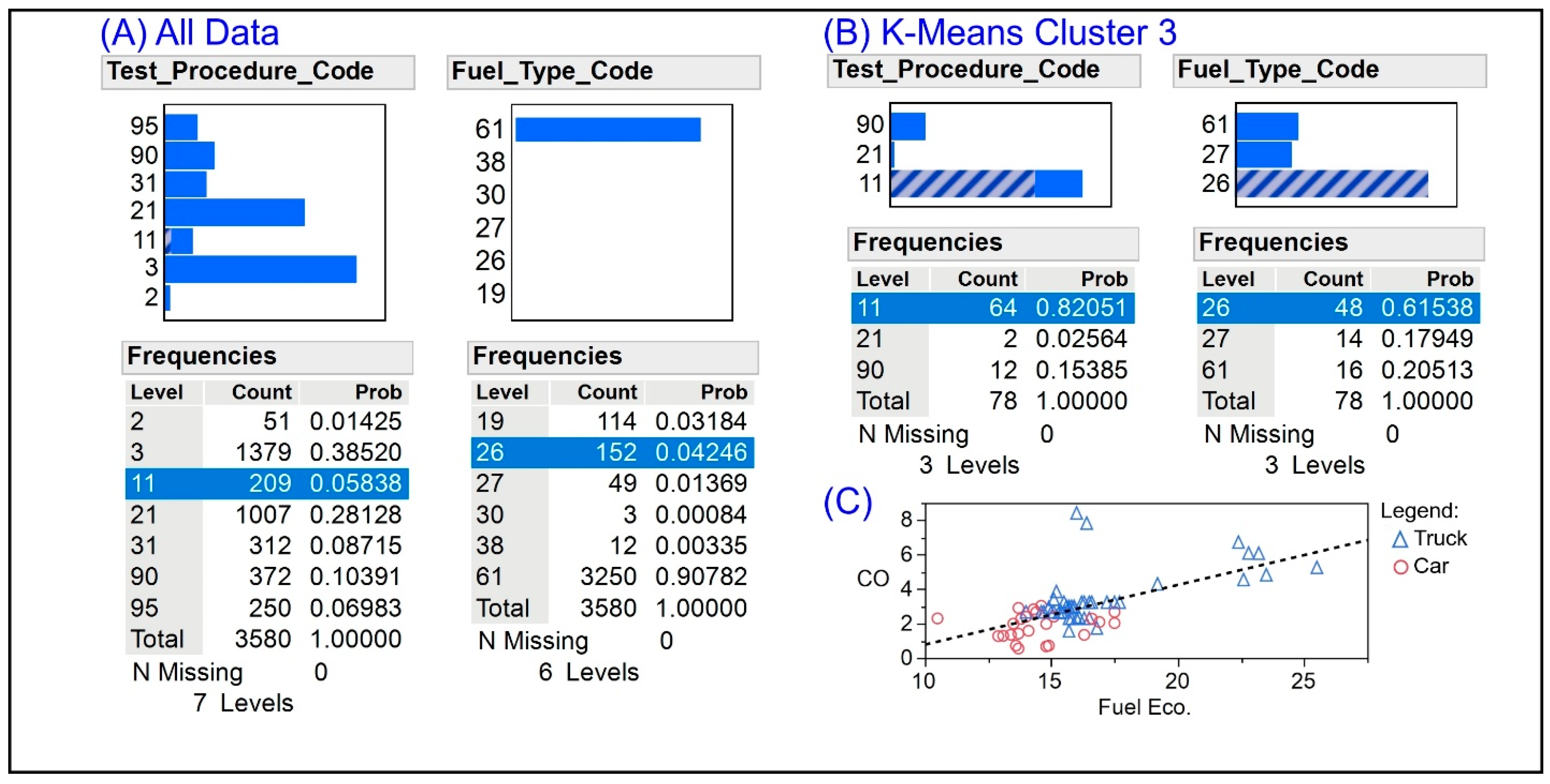
3.2.1. K-Means Clustering
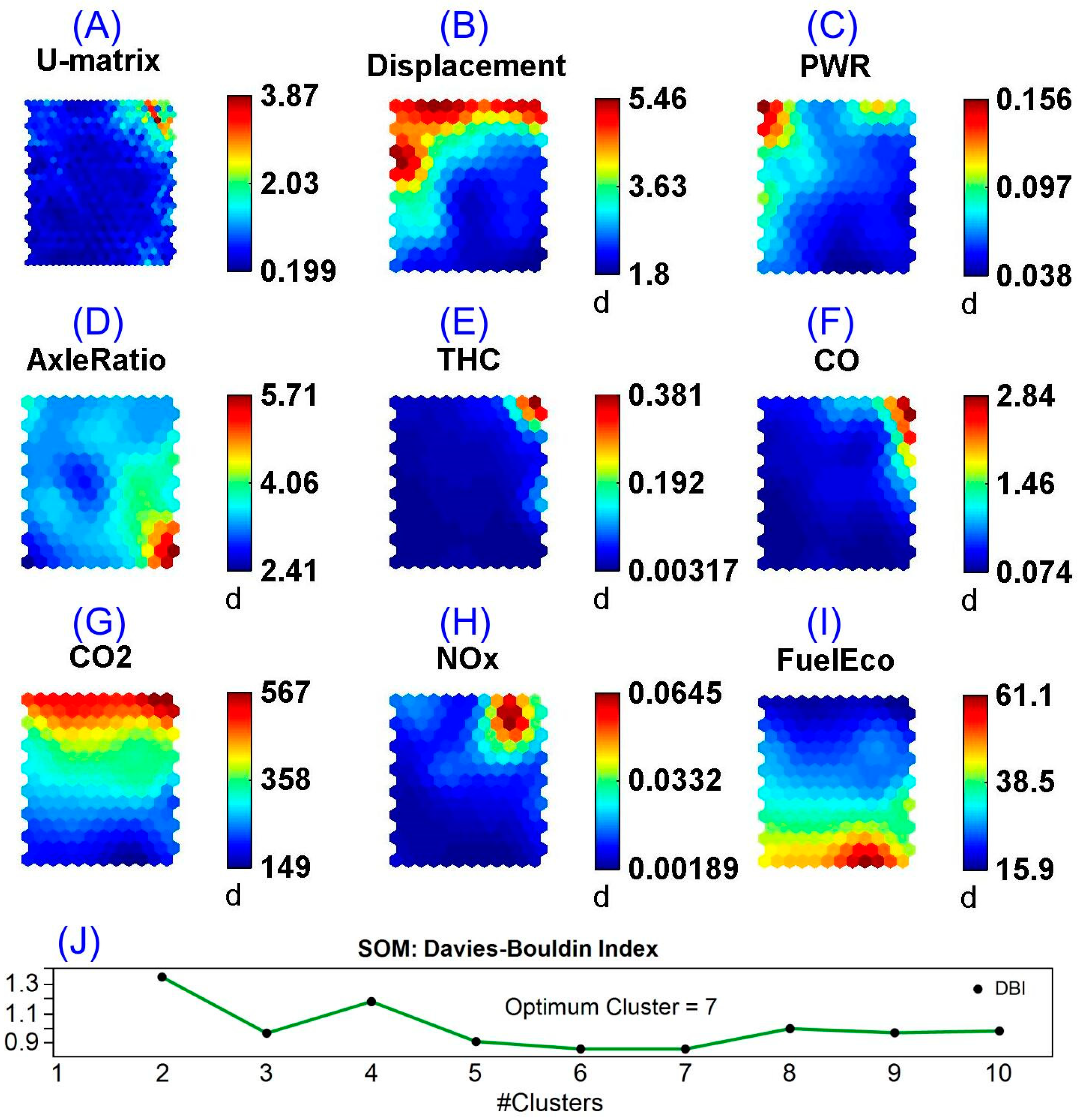
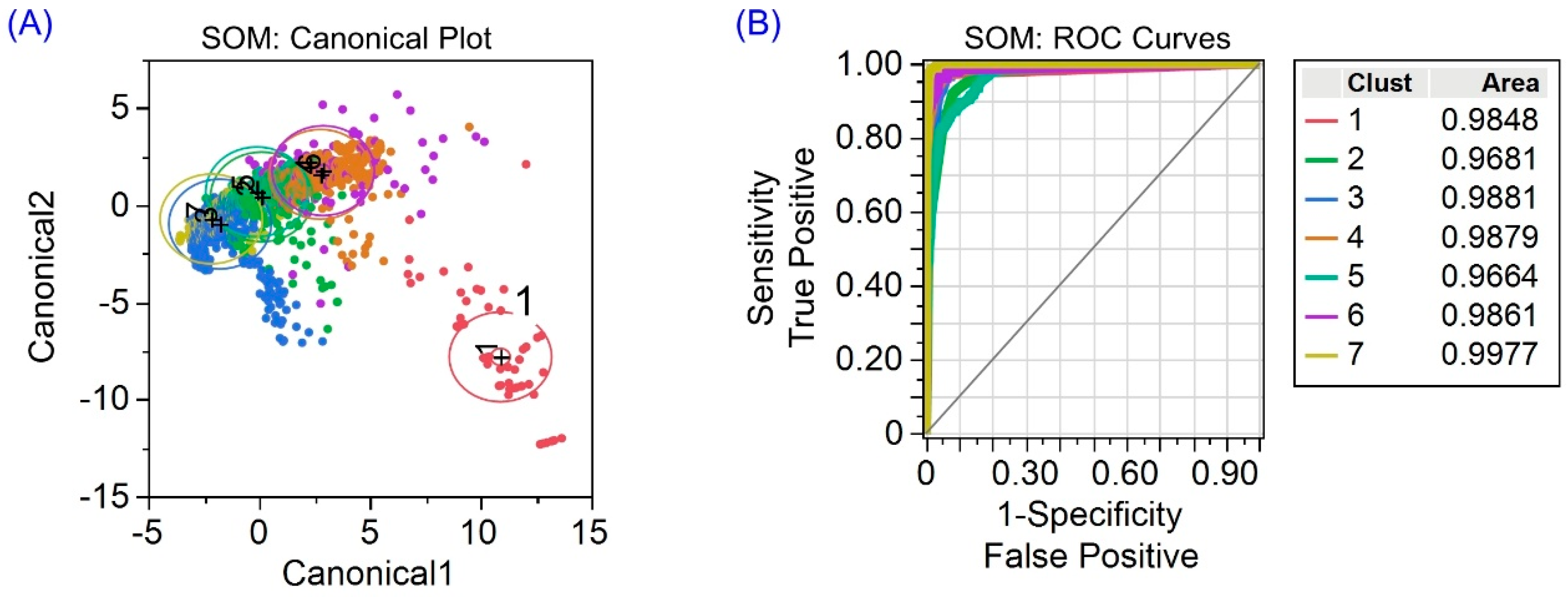
3.2.2. Self-Organizing Maps Clustering
3.3. Performance of K-Means and SOM Clustering
3.4. Bivariate Analysis on CO vs. Fuel Economy
3.5. Other Notable Variable Correlations
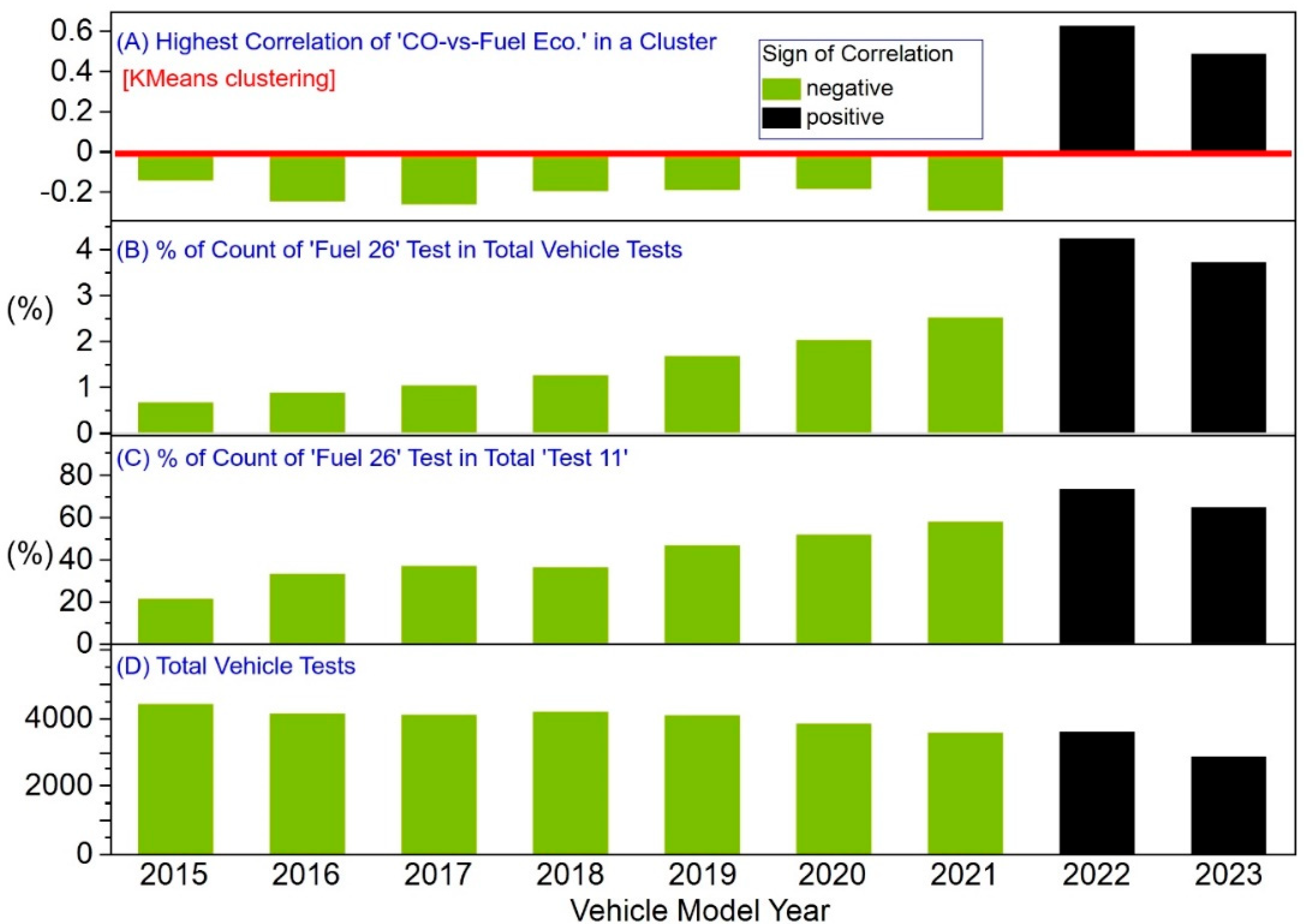
3.6. Unsupervised Learning Uncovers an Impending Anomaly
3.7. CO vs. Fuel Economy Anomaly in the Big Picture of LDVs Market
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- US-EPA. Light-Duty Vehicles and Light-Duty Trucks: Clean Fuel Fleet Exhaust Emission Standards; US-EPA: Washington, DC, USA, 2016; Volume EPA-420-B-16-006. [Google Scholar]
- IEA. World Energy Investment; International Energy Agency (IEA): Paris, France, 2020. [Google Scholar]
- Hui, H.; Jin, L. A Historical Review of the U.S. In Vehicle Emission Compliance Program and Emission Recall Case; The International Council on Clean Transportation (ICCT): Washington, DC, USA, 2017. [Google Scholar]
- US-EPA. Emission Standards Reference Guide: All EPA Emission Standards. Available online: https://www.epa.gov/emission-standards-reference-guide/all-epa-emission-standards (accessed on 9 April 2022).
- US-EPA. Revised 2023 and Later Model Year LightDuty Vehicle GHG Emissions Standards: Regulatory Impact Analysis; US-EPA Assessment and Standards Division Office of Transportation and Air Quality: Washington, DC, USA, 2021. [Google Scholar]
- US-EPA. 2014–2017 Progress Report: Vehicle and Engine Compliance Activities; US-EPA: Washington, DC, USA, 2019; Volume 420R19003, p. 122. [Google Scholar]
- UNECE. Sustainable Development Brief No. 4: Emissions Testing for Cars and Environmental Regulations; United Nations Economic Commission for Europe (UNECE): Geneva, Switzerland, 2016. [Google Scholar]
- US-EPA. Revisions to Test Methods, Performance Specifications, and Testing Regulations for Air Emission Sources; EPA, Ed.; Environmental Protection Agency (EPA): Washington, DC, USA, 2016; Volume EPA-HQ-OAR-2014-0292. [Google Scholar]
- Trunk, G.V. A Problem of Dimensionality: A Simple Example. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 306–307. [Google Scholar] [CrossRef] [PubMed]
- Gareth James, D.W.; Trevor, H.; Robert, T. An Introduction to Statistical Learning, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- SAS. JMP® 16 Documentation Library; SAS Institute Inc.: Cary, NC, USA, 2022. [Google Scholar]
- Fortela, D.L.B.; Crawford, M.; DeLattre, A.; Kowalski, S.; Lissard, M.; Fremin, A.; Sharp, W.; Revellame, E.; Hernandez, R.; Zappi, M. Using Self-Organizing Maps to Elucidate Patterns among Variables in Simulated Syngas Combustion. Clean Technol. 2020, 2, 156–169. [Google Scholar] [CrossRef]
- US-EPA. Data on Cars used for Testing Fuel Economy. Available online: https://www.epa.gov/compliance-and-fuel-economy-data/data-cars-used-testing-fuel-economy (accessed on 9 April 2022).
- Kohonen, T. MATLAB Implementations and Applications of the Self-Organizing Map; Unigrafia Bookstore: Helsinki, Finland, 2014. [Google Scholar]
- MathWorks MATrix LABoratory (MATLAB) R2013a; MathWorks: Natick, MA, USA, 2013.
- Fortela, D.L. GitHub Repo: Unsupervised Learning to Elucidate Trends in Testing Data on Fuel Economy and Emissions of Light-Weight Vehicles. 2022. Available online: https://github.com/dhanfort/Cars22-FEandEmissions.git (accessed on 9 April 2022).
- Henry, D.; Dymnicki, A.B.; Mohatt, N.; Allen, J.; Kelly, J.G. Clustering Methods with Qualitative Data: A Mixed-Methods Approach for Prevention Research with Small Samples. Prev. Sci. Off. J. Soc. Prev. Res. 2015, 16, 1007–1016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- SAS. SAS/STAT 15.2 User’s Guide: The FASTCLUS Procedure; SAS, Ed.; SAS: Singapore, 2020. [Google Scholar]
- Singer, B.C.; Kirchstetter, T.W.; Harley, R.A.; Kendall, G.R.; Hesson, J.M. A Fuel-Based Approach to Estimating Motor Vehicle Cold-Start Emissions. J. Air Waste Manag. Assoc. 1999, 49, 125–135. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, T.; Frey, H.C. Comparison of real-world and certification emission rates for light duty gasoline vehicles. Sci. Total Environ. 2018, 622–623, 790–800. [Google Scholar] [CrossRef] [PubMed]
- Bansal, P.; Dua, R.; Krueger, R.; Graham, D.J. Fuel economy valuation and preferences of Indian two-wheeler buyers. J. Clean. Prod. 2021, 294, 126328. [Google Scholar] [CrossRef]
- Sheldon, T.L.; Dua, R. How responsive is Saudi new vehicle fleet fuel economy to fuel-and vehicle-price policy levers? Energy Econ. 2021, 97, 105026. [Google Scholar] [CrossRef]
- CARB. States That Have Adopted California’s Vehicle Standards under Section 177 of the Federal Clean Air Act; California Air Resources Board (CARB): Sacramento, CA, USA, 2021. [Google Scholar]
- U.S. Congress. Clean Air Act. In United States Code Title 42 Chapter 85; U.S. Congress: Washington, DC, USA, 1990. [Google Scholar]
- Briceno-Garmendia, C.; Qiao, W.; Foste, V. The Economics of Electric Vehicles for Passenger Transportation. In Mobility and Transport Connectivity Series, November 2022 ed.; The World Bank: Washington, DC, USA, 2022. [Google Scholar]
- Frey, H.C. Trends in onroad transportation energy and emissions. J. Air Waste Manag. Assoc. 2018, 68, 514–563. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Data Type |
|---|---|---|
| Fuel Economy | Fuel economy in miles per gallon (MPG) | Numeric, continuous |
| Displacement | Engine volume displacement in liters (L) | Numeric, continuous |
| PWR | Power-to-Weight ratio of the vehicle in horsepower/pound (hp/lb) | Numeric, continuous |
| Axle Ratio | The number of revolutions the output shaft or driveshaft needs to make to spin the axle one complete turn | Numeric, continuous |
| THC | Exhaust total hydrocarbons (THC) in grams/mile (g/mi) | Numeric, continuous |
| CO2 | Exhaust carbon dioxide in grams/mile (g/mi) | Numeric, continuous |
| CO | Exhaust carbon monoxide in grams/mile (g/mi) | Numeric, continuous |
| NOx | Exhaust NOx in grams/mile (g/mi) | Numeric, continuous |
| Actual | Predicted Count | Predicted Rate | ||||
|---|---|---|---|---|---|---|
| Cluster | 1 | 2 | 3 | 1 | 2 | 3 |
| 1 | 1270 | 87 | 0 | 0.936 | 0.064 | 0.000 |
| 2 | 26 | 2115 | 2 | 0.012 | 0.986 | 0.001 |
| 3 | 2 | 0 | 76 | 0.038 | 0.000 | 0.962 |
| Total Count: 3580 | Percent Misclassified: 3.32% | Entropy R-square: 0.848 | ||||
| Actual | Predicted Count | ||||||
| Cluster | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1 | 63 | 0 | 0 | 2 | 0 | 1 | 0 |
| 2 | 0 | 800 | 24 | 7 | 25 | 7 | 15 |
| 3 | 0 | 93 | 913 | 0 | 105 | 1 | 0 |
| 4 | 0 | 45 | 0 | 476 | 47 | 0 | 4 |
| 5 | 0 | 71 | 7 | 0 | 399 | 0 | 1 |
| 6 | 0 | 8 | 0 | 17 | 1 | 100 | 0 |
| 7 | 0 | 3 | 30 | 0 | 13 | 0 | 304 |
| Actual | Predicted Rate | ||||||
| Cluster | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1 | 0.955 | 0.000 | 0.000 | 0.030 | 0.000 | 0.015 | 0.000 |
| 2 | 0.000 | 0.911 | 0.027 | 0.008 | 0.028 | 0.008 | 0.017 |
| 3 | 0.000 | 0.084 | 0.821 | 0.000 | 0.094 | 0.001 | 0.000 |
| 4 | 0.000 | 0.079 | 0.000 | 0.832 | 0.082 | 0.000 | 0.007 |
| 5 | 0.000 | 0.149 | 0.015 | 0.000 | 0.834 | 0.000 | 0.002 |
| 6 | 0.000 | 0.063 | 0.000 | 0.135 | 0.008 | 0.794 | 0.000 |
| 7 | 0.000 | 0.009 | 0.086 | 0.000 | 0.037 | 0.000 | 0.869 |
| Total Count: 3580 | Percent Misclassified: 14.72% | Entropy R-Square: 0.753 | |||||
| Test Procedure Code | Test Procedure Description |
|---|---|
| 2 |
|
| 3 |
|
| 11 |
|
| 21 |
|
| 31 |
|
| 90 |
|
| 95 |
|
| Fuel Type Code | Fuel Type Description |
|---|---|
| 19 |
|
| 26 |
|
| 27 |
|
| 30 |
|
| 38 |
|
| 61 |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fortela, D.L.B.; Fremin, A.C.; Sharp, W.; Mikolajczyk, A.P.; Revellame, E.; Holmes, W.; Hernandez, R.; Zappi, M. Unsupervised Machine Learning to Detect Impending Anomalies in Testing of Fuel Economy and Emissions of Light-Duty Vehicles. Clean Technol. 2023, 5, 418-435. https://doi.org/10.3390/cleantechnol5010021
Fortela DLB, Fremin AC, Sharp W, Mikolajczyk AP, Revellame E, Holmes W, Hernandez R, Zappi M. Unsupervised Machine Learning to Detect Impending Anomalies in Testing of Fuel Economy and Emissions of Light-Duty Vehicles. Clean Technologies. 2023; 5(1):418-435. https://doi.org/10.3390/cleantechnol5010021
Chicago/Turabian StyleFortela, Dhan Lord B., Ashton C. Fremin, Wayne Sharp, Ashley P. Mikolajczyk, Emmanuel Revellame, William Holmes, Rafael Hernandez, and Mark Zappi. 2023. "Unsupervised Machine Learning to Detect Impending Anomalies in Testing of Fuel Economy and Emissions of Light-Duty Vehicles" Clean Technologies 5, no. 1: 418-435. https://doi.org/10.3390/cleantechnol5010021
APA StyleFortela, D. L. B., Fremin, A. C., Sharp, W., Mikolajczyk, A. P., Revellame, E., Holmes, W., Hernandez, R., & Zappi, M. (2023). Unsupervised Machine Learning to Detect Impending Anomalies in Testing of Fuel Economy and Emissions of Light-Duty Vehicles. Clean Technologies, 5(1), 418-435. https://doi.org/10.3390/cleantechnol5010021