A New Biased Estimator to Combat the Multicollinearity of the Gaussian Linear Regression Model



Abstract
:1. Introduction
Some Alternative Biased Estimators and the Proposed Estimator
- -
- The KL is a one-parameter estimator, while the proposed DK is a two-parameter estimator.
- -
- The KL estimator is obtained based on the objective function , while the proposed DK estimator is obtained from a different objective function, which is .
- -
- The KL estimator is a function of the shrinkage estimator , while the proposed DK estimator is a function of and .
- -
- Since the KL estimator has one parameter and the proposed DK estimator has two parameters, their MSEs are different.
- -
- In the KL estimator, shrinkage parameter needs to be estimated, while in the proposed DK estimator, both and need to be estimated.
- -
- The KL estimator is a special case of the proposed DK estimator when , so the proposed DK estimator is the general estimator.
2. Comparison among the Estimators
2.1. Theoretical Comparisons among the Proposed DK Estimator and the OLS, ORR, Liu, KL, TP, and NTP Estimators
2.2. Determination of the Parameters k and d
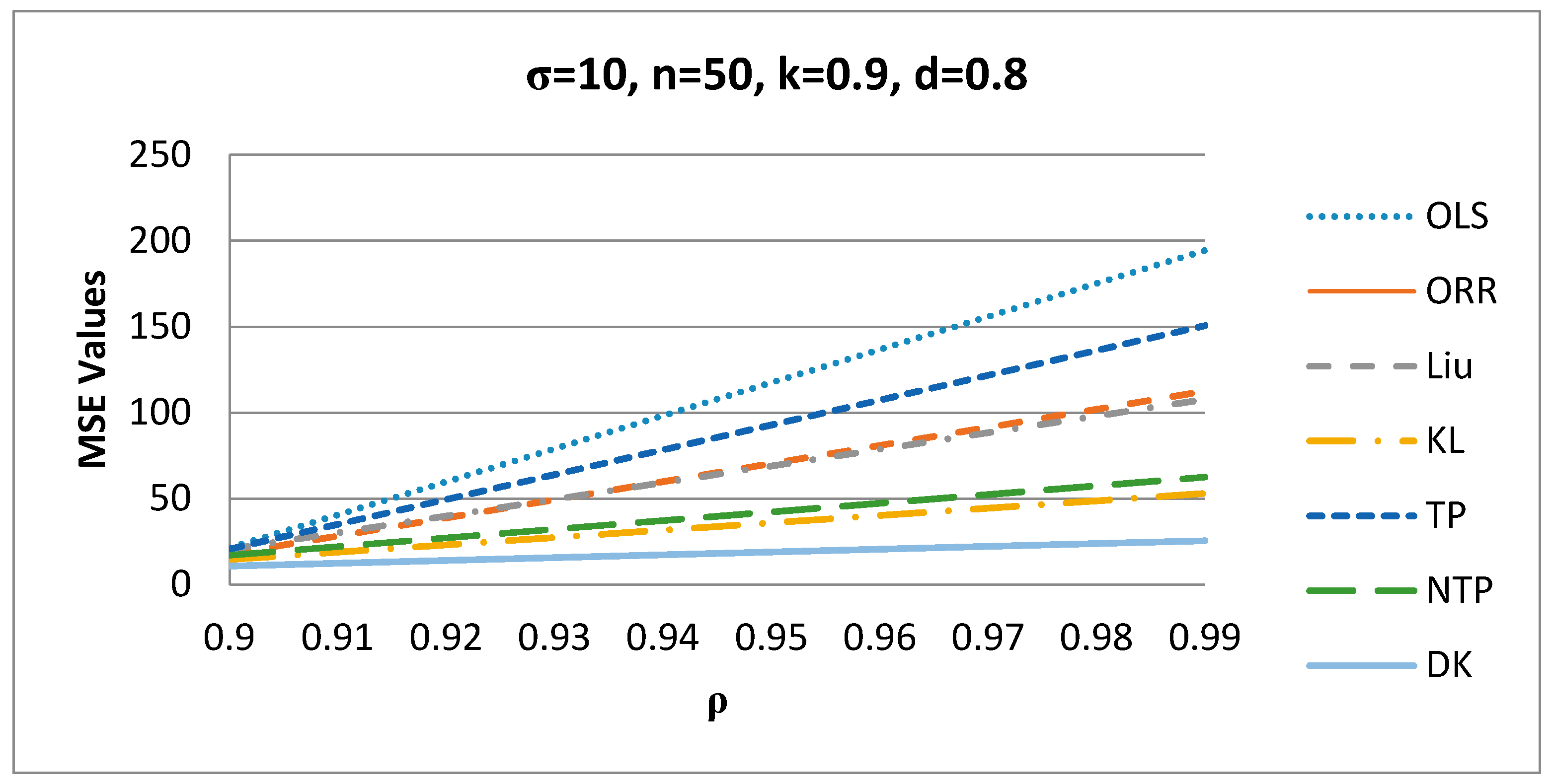
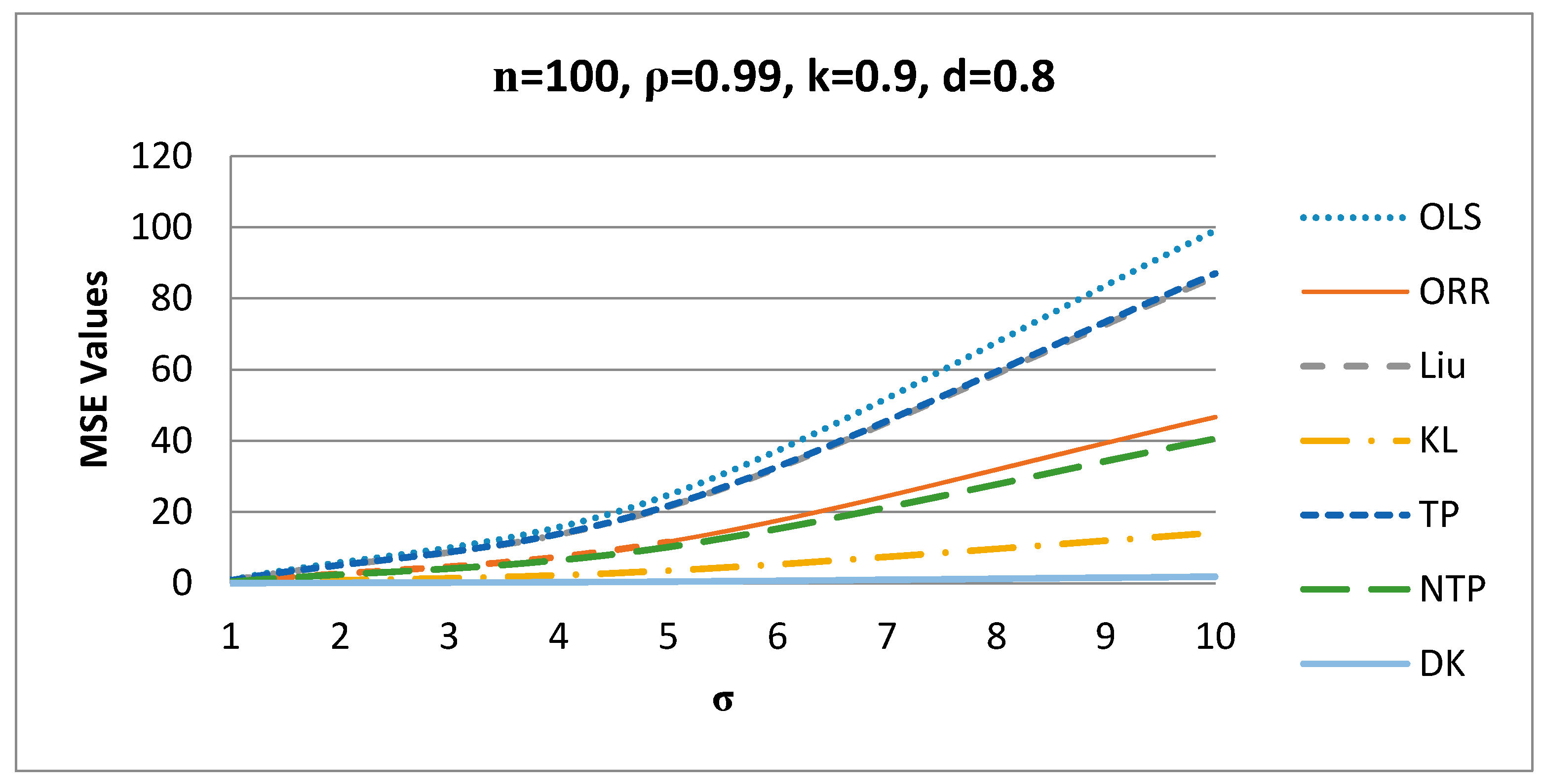
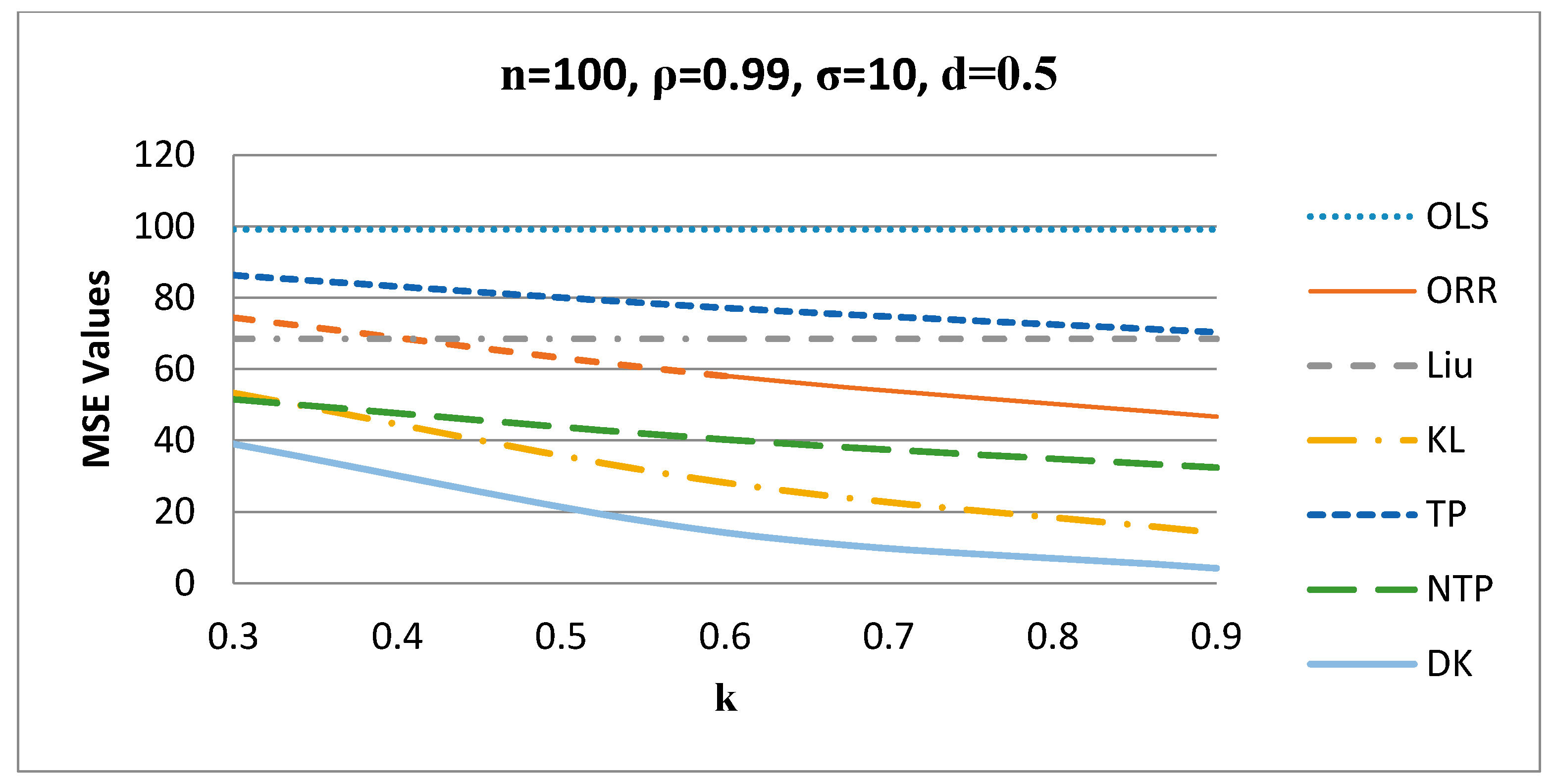
3. Simulation Study
3.1. Simulation Technique
3.2. Simulation Results Discussions
4. Application
4.1. Portland Cement Data
4.2. Longley Data
5. Summary and Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Stein, C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability; MR0084922; University California Press: Berkeley, CA, USA, 1956; Volume 197–206, pp. 1954–1955. [Google Scholar]
- Massy, W.F. Principal components regression in exploratory statistical research. J. Am. Stat. Assoc. 1965, 60, 234–256. [Google Scholar] [CrossRef]
- Mayer, L.S.; Willke, T.A. On biased estimation in linear models. Technometrics 1973, 15, 497–508. [Google Scholar] [CrossRef]
- Swindel, B.F. Good ridge estimators based on prior information. Commun. Stat. Theory Methods 1976, 5, 1065–1075. [Google Scholar] [CrossRef]
- Liu, K. A new class of biased estimate in linear regression. Commun. Stat. Theory Methods 1993, 22, 393–402. [Google Scholar]
- Akdeniz, F.; Kaçiranlar, S. On the almost unbiased generalized liu estimator and unbiased estimation of the bias and mse. Commun. Stat. Theory Methods 1995, 24, 1789–1797. [Google Scholar] [CrossRef]
- Ozkale, M.R.; Kaçiranlar, S. The restricted and unrestricted two-parameter estimators. Commun. Stat. Theory Methods 2007, 36, 2707–2725. [Google Scholar] [CrossRef]
- Sakallıoglu, S.; Kaçıranlar, S. A new biased estimator based on ridge estimation. Stat. Pap. 2008, 49, 669–689. [Google Scholar] [CrossRef]
- Yang, H.; Chang, X. A new two-parameter estimator in linear regression. Commun. Stat. Theory Methods 2010, 39, 923–934. [Google Scholar] [CrossRef]
- Roozbeh, M. Optimal QR-based estimation in partially linear regression models with correlated errors using GCV criterion. Comput. Stat. Data Anal. 2018, 117, 45–61. [Google Scholar] [CrossRef]
- Akdeniz, F.; Roozbeh, M. Generalized difference-based weighted mixed almost unbiased ridge estimator in partially linear models. Stat. Pap. 2019, 60, 1717–1739. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K.; Binuomote, S.; Clement, O.A. Modified ridge-type estimator to combat multicollinearity: Application to chemical data. J. Chemother. 2019, 33, e3125. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K.; Sek, S.K.; Adewuyi, E. A modified new two-parameter estimator in a linear regression model. Model. Eng. Simul. 2019, 2019, 6342702. [Google Scholar] [CrossRef]
- Kibria, B.M.G.; Lukman, A.F. A New Ridge-Type Estimator for the Linear Regression Model: Simulations and Applications. Hindawi Sci. 2020, 2020, 9758378. [Google Scholar] [CrossRef]
- Wang, S.G.; Wu, M.X.; Jia, Z.Z. Matrix Inequalities; Science Chinese Press: Beijing, China, 2006. [Google Scholar]
- Farebrother, R.W. Further results on the mean square error of ridge regression. J. R. Stat. Soc. B 1976, 38, 248–250. [Google Scholar] [CrossRef]
- Trenkler, G.; Toutenburg, H. Mean squared error matrix comparisons between biased estimators-an overview of recent results. Stat. Pap. 1990, 31, 165–179. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kannard, R.W.; Baldwin, K.F. Ridge regression: Some simulations. Commun. Stat. 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Kibria, B.M.G. Performance of some new ridge regression estimators. Commun. Stat. Simul. Comput. 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Kibria, B.M.G.; Banik, S. Some ridge regression estimators and their performances. J. Mod. Appl. Stat. Methods 2016, 15, 206–238. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K. Review and classifications of the ridge parameter estimation techniques. Hacet. J. Math. Stat. 2017, 46, 953–967. [Google Scholar] [CrossRef]
- Månsson, K.; Kibria, B.M.G.; Shukur, G. Performance of some weighted Liu estimators for logit regression model: An application to Swedish accident data. Commun. Stat. Theory Methods 2015, 44, 363–375. [Google Scholar] [CrossRef]
- Khalaf, G.; Shukur, G. Choosing ridge parameter for regression problems. Commun. Stat. Theory Methods 2005, 21, 2227–2246. [Google Scholar] [CrossRef]
- Gibbons, D.G. A simulation study of some ridge estimators. J. Am. Stat. Assoc. 1981, 76, 131–139. [Google Scholar] [CrossRef]
- Newhouse, J.P.; Oman, S.D. An evaluation of ridge estimators. In A Report Prepared for United States Air Force Project; RAND: Santa Monica, CA, USA, 1971. [Google Scholar]
- Wichern, D.W.; Churchill, G.A. A comparison of ridge estimators. Technometrics 1978, 20, 301–311. [Google Scholar] [CrossRef]
- Kan, B.; Alpu, O.; Yazıcı, B. Robust ridge and robust Liu estimator for regression based on the LTS estimator. J. Appl. Stat. 2013, 40, 644–655. [Google Scholar] [CrossRef]
- Woods, H.; Steinour, H.H.; Starke, H.R. Effect of composition of Portland cement on heat evolved during hardening. J. Ind. Eng. Chem. 1932, 24, 1207–1214. [Google Scholar] [CrossRef]
- Kaciranlar, S.; Sakallioglu, S.; Akdeniz, F.; Styan, G.P.H.; Werner, H.J. A new biased estimator in linear regression and a detailed analysis of the widely-analysed dataset on portland cement. Sankhya Indian J. Stat. B 1999, 61, 443–459. [Google Scholar]
- Li, Y.; Yang, H. Anew Liu-type estimator in linear regression model. Stat. Pap. 2012, 53, 427–437. [Google Scholar] [CrossRef]
- Longley, J.W. An appraisal of least squares programs for electronic computer from the point of view of the user. J. Am. Stat. Assoc. 1967, 62, 819–841. [Google Scholar] [CrossRef]
- Yasin, A.; Murat, E. Influence Diagnostics in Two-Parameter Ridge Regression. J. Data Sci. 2016, 14, 33–52. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OLS | ORR | Liu | KL | TP | NTP | DK | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.2 | 1 | 0.2136 | 0.2005 | 0.1821 | 0.1879 | 0.2031 | 0.1711 | 0.1832 |
| 5 | 5.3394 | 5.0135 | 4.5507 | 4.6982 | 5.0778 | 4.2749 | 4.5799 | ||
| 10 | 21.357 | 20.054 | 18.203 | 18.793 | 20.311 | 17.099 | 18.319 | ||
| 0.5 | 1 | 0.2136 | 0.2005 | 0.1936 | 0.1879 | 0.2070 | 0.1818 | 0.1764 | |
| 5 | 5.3394 | 5.0135 | 4.8388 | 4.6982 | 5.1751 | 4.5446 | 4.4080 | ||
| 10 | 21.357 | 20.054 | 19.355 | 18.793 | 20.700 | 18.178 | 17.632 | ||
| 0.8 | 1 | 0.2136 | 0.2005 | 0.2054 | 0.1879 | 0.2109 | 0.1929 | 0.1698 | |
| 5 | 5.3394 | 5.0135 | 5.1361 | 4.6982 | 5.2734 | 4.8231 | 4.2427 | ||
| 10 | 21.357 | 20.054 | 20.544 | 18.793 | 21.093 | 19.292 | 16.970 | ||
| 0.6 | 0.2 | 1 | 0.2136 | 0.1887 | 0.1821 | 0.1655 | 0.1936 | 0.1611 | 0.1574 |
| 5 | 5.3394 | 4.7176 | 4.5507 | 4.1361 | 4.8388 | 4.0245 | 3.9308 | ||
| 10 | 21.357 | 18.870 | 18.203 | 16.544 | 19.355 | 16.098 | 15.723 | ||
| 0.5 | 1 | 0.2136 | 0.1887 | 0.1936 | 0.1655 | 0.2009 | 0.1712 | 0.1459 | |
| 5 | 5.3394 | 4.7176 | 4.8388 | 4.1361 | 5.0235 | 4.2777 | 3.6422 | ||
| 10 | 21.357 | 18.870 | 19.355 | 16.544 | 20.094 | 17.110 | 14.568 | ||
| 0.8 | 1 | 0.2136 | 0.1887 | 0.2054 | 0.1655 | 0.2085 | 0.1816 | 0.1353 | |
| 5 | 5.3394 | 4.7176 | 5.1361 | 4.1361 | 5.2118 | 4.5389 | 3.3748 | ||
| 10 | 21.357 | 18.870 | 20.544 | 16.544 | 20.847 | 18.155 | 13.498 | ||
| 0.9 | 0.2 | 1 | 0.2136 | 0.1780 | 0.1821 | 0.1459 | 0.1848 | 0.1521 | 0.1353 |
| 5 | 5.3394 | 4.4483 | 4.5507 | 3.6422 | 4.6197 | 3.7965 | 3.3748 | ||
| 10 | 21.357 | 17.793 | 18.203 | 14.568 | 18.479 | 15.186 | 13.498 | ||
| 0.5 | 1 | 0.2136 | 0.1780 | 0.1936 | 0.1459 | 0.1953 | 0.1615 | 0.1209 | |
| 5 | 5.3394 | 4.4483 | 4.8388 | 3.6422 | 4.8832 | 4.0346 | 3.0101 | ||
| 10 | 21.357 | 17.793 | 19.355 | 14.568 | 19.533 | 16.138 | 12.039 | ||
| 0.8 | 1 | 0.2136 | 0.1780 | 0.2054 | 0.1459 | 0.2062 | 0.1713 | 0.1081 | |
| 5 | 5.3394 | 4.4483 | 5.1361 | 3.6422 | 5.1544 | 4.2803 | 2.6846 | ||
| 10 | 21.357 | 17.793 | 20.544 | 14.568 | 20.617 | 17.121 | 10.736 | ||
| OLS | ORR | Liu | KL | TP | NTP | DK | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.2 | 1 | 1.9452 | 1.1258 | 1.0786 | 0.6261 | 1.5075 | 0.2548 | 0.5308 |
| 5 | 48.628 | 28.145 | 26.965 | 15.651 | 37.686 | 6.3689 | 13.268 | ||
| 10 | 194.51 | 112.58 | 107.86 | 62.607 | 150.74 | 25.475 | 53.074 | ||
| 0.5 | 1 | 1.9452 | 1.1258 | 1.5679 | 0.5308 | 1.7633 | 0.9083 | 0.1548 | |
| 5 | 48.628 | 28.145 | 39.197 | 13.268 | 44.083 | 22.706 | 3.8693 | ||
| 10 | 194.51 | 112.58 | 156.79 | 53.074 | 176.33 | 90.826 | 15.477 | ||
| 0.8 | 1 | 1.9452 | 0.7349 | 0.6813 | 0.1072 | 0.9304 | 0.2612 | 0.0457 | |
| 5 | 48.628 | 18.372 | 17.031 | 2.6782 | 23.258 | 6.5262 | 1.1386 | ||
| 10 | 194.51 | 73.489 | 68.124 | 10.712 | 93.034 | 26.105 | 4.5545 | ||
| 0.6 | 0.2 | 1 | 1.9452 | 0.7349 | 1.0786 | 0.1072 | 1.2672 | 0.4101 | 0.0109 |
| 5 | 48.628 | 18.372 | 26.965 | 2.6782 | 31.680 | 10.251 | 0.2678 | ||
| 10 | 194.51 | 73.489 | 107.86 | 10.712 | 126.72 | 41.006 | 1.0709 | ||
| 0.5 | 1 | 1.9452 | 0.7349 | 1.5679 | 0.1072 | 1.6565 | 0.5935 | 0.0178 | |
| 5 | 48.628 | 18.372 | 39.197 | 2.6782 | 41.412 | 14.837 | 0.4391 | ||
| 10 | 194.51 | 73.489 | 156.79 | 10.712 | 165.65 | 59.348 | 1.7561 | ||
| 0.8 | 1 | 1.9452 | 0.5184 | 0.6813 | 0.0109 | 0.7302 | 0.1859 | 0.0108 | |
| 5 | 48.628 | 12.958 | 17.031 | 0.2678 | 18.254 | 4.6442 | 0.2391 | ||
| 10 | 194.51 | 51.834 | 68.124 | 1.0709 | 73.017 | 18.576 | 1.0561 | ||
| 0.9 | 0.2 | 1 | 1.9452 | 0.5184 | 1.0786 | 0.0109 | 1.1169 | 0.2905 | 0.0108 |
| 5 | 48.628 | 12.958 | 26.965 | 0.2678 | 27.921 | 7.2590 | 0.2118 | ||
| 10 | 194.51 | 51.834 | 107.86 | 1.0709 | 111.68 | 29.036 | 1.0684 | ||
| 0.5 | 1 | 1.9452 | 0.5184 | 1.5679 | 0.0109 | 1.5863 | 0.4192 | 0.0107 | |
| 5 | 48.628 | 12.958 | 39.197 | 0.2678 | 39.656 | 10.477 | 0.2540 | ||
| 10 | 194.51 | 51.834 | 156.79 | 1.0709 | 158.62 | 41.909 | 1.0611 | ||
| 0.8 | 1 | 1.9452 | 1.1258 | 1.0786 | 0.5308 | 1.5075 | 0.6261 | 0.2548 | |
| 5 | 48.628 | 28.145 | 26.965 | 13.268 | 37.686 | 15.651 | 6.3689 | ||
| 10 | 194.51 | 112.58 | 107.86 | 53.074 | 150.74 | 62.607 | 25.475 | ||
| OLS | ORR | Liu | KL | TP | NTP | DK | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.2 | 1 | 0.1064 | 0.1032 | 0.0982 | 0.1000 | 0.1038 | 0.0952 | 0.0987 |
| 5 | 2.6611 | 2.5793 | 2.4538 | 2.4989 | 2.5956 | 2.3787 | 2.4678 | ||
| 10 | 10.644 | 10.317 | 9.8149 | 9.9956 | 10.382 | 9.5147 | 9.8709 | ||
| 0.5 | 1 | 0.1064 | 0.1032 | 0.1012 | 0.1000 | 0.1048 | 0.0981 | 0.0969 | |
| 5 | 2.6611 | 2.5793 | 2.5305 | 2.4989 | 2.6200 | 2.4529 | 2.4218 | ||
| 10 | 10.644 | 10.317 | 10.121 | 9.9956 | 10.480 | 9.8116 | 9.6869 | ||
| 0.8 | 1 | 0.1064 | 0.1032 | 0.1043 | 0.1000 | 0.1058 | 0.1011 | 0.0951 | |
| 5 | 2.6611 | 2.5793 | 2.6084 | 2.4989 | 2.6446 | 2.5284 | 2.3767 | ||
| 10 | 10.644 | 10.317 | 10.433 | 9.9956 | 10.578 | 10.113 | 9.5065 | ||
| 0.6 | 0.2 | 1 | 0.1064 | 0.1001 | 0.0982 | 0.0939 | 0.1013 | 0.0923 | 0.0916 |
| 5 | 2.6611 | 2.5015 | 2.4538 | 2.3471 | 2.5330 | 2.3072 | 2.2891 | ||
| 10 | 10.644 | 10.005 | 9.8149 | 9.3882 | 10.131 | 9.2287 | 9.1561 | ||
| 0.5 | 1 | 0.1064 | 0.1001 | 0.1012 | 0.0939 | 0.1032 | 0.0952 | 0.0882 | |
| 5 | 2.6611 | 2.5015 | 2.5305 | 2.3471 | 2.5806 | 2.3791 | 2.2048 | ||
| 10 | 10.644 | 10.005 | 10.121 | 9.3882 | 10.322 | 9.5162 | 8.8190 | ||
| 0.8 | 1 | 0.1064 | 0.1001 | 0.1043 | 0.0939 | 0.1052 | 0.0981 | 0.0850 | |
| 5 | 2.6611 | 2.5015 | 2.6084 | 2.3471 | 2.6287 | 2.4521 | 2.1238 | ||
| 10 | 10.644 | 10.005 | 10.433 | 9.3882 | 10.514 | 9.8084 | 8.4947 | ||
| 0.9 | 0.2 | 1 | 0.1064 | 0.0971 | 0.0982 | 0.0882 | 0.0989 | 0.0896 | 0.0850 |
| 5 | 2.6611 | 2.4273 | 2.4538 | 2.2048 | 2.4731 | 2.2391 | 2.1238 | ||
| 10 | 10.644 | 9.7090 | 9.8149 | 8.8190 | 9.8924 | 8.9561 | 8.4947 | ||
| 0.5 | 1 | 0.1064 | 0.0971 | 0.1012 | 0.0882 | 0.1017 | 0.0924 | 0.0804 | |
| 5 | 2.6611 | 2.4273 | 2.5305 | 2.2048 | 2.5428 | 2.3087 | 2.0079 | ||
| 10 | 10.644 | 9.7090 | 10.121 | 8.8190 | 10.171 | 9.2347 | 8.0312 | ||
| 0.8 | 1 | 0.1064 | 0.0971 | 0.1043 | 0.0882 | 0.1045 | 0.0952 | 0.0761 | |
| 5 | 2.6611 | 2.4273 | 2.6084 | 2.2048 | 2.6134 | 2.3795 | 1.8985 | ||
| 10 | 10.644 | 9.7090 | 10.433 | 8.8190 | 10.453 | 9.5178 | 7.5934 | ||
| OLS | ORR | Liu | KL | TP | NTP | DK | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.3 | 0.2 | 1 | 0.9913 | 0.7446 | 0.5288 | 0.5341 | 0.7911 | 0.3990 | 0.4714 |
| 5 | 24.782 | 18.615 | 13.220 | 13.353 | 19.776 | 9.9738 | 11.784 | ||
| 10 | 99.128 | 74.463 | 52.882 | 53.412 | 79.107 | 39.895 | 47.136 | ||
| 0.5 | 1 | 0.9913 | 0.7446 | 0.6850 | 0.5341 | 0.8634 | 0.5158 | 0.3900 | |
| 5 | 24.782 | 18.615 | 17.125 | 13.353 | 21.586 | 12.894 | 9.7508 | ||
| 10 | 99.128 | 74.463 | 68.502 | 53.412 | 86.343 | 51.577 | 39.003 | ||
| 0.8 | 1 | 0.9913 | 0.7446 | 0.8619 | 0.5341 | 0.9391 | 0.6480 | 0.3218 | |
| 5 | 24.782 | 18.615 | 21.547 | 13.353 | 23.476 | 16.199 | 8.0436 | ||
| 10 | 99.128 | 74.463 | 86.188 | 53.412 | 93.905 | 64.796 | 32.174 | ||
| 0.6 | 0.2 | 1 | 0.9913 | 0.5811 | 0.5288 | 0.2824 | 0.6542 | 0.3125 | 0.2162 |
| 5 | 24.782 | 14.526 | 13.220 | 7.0598 | 16.354 | 7.8110 | 5.4042 | ||
| 10 | 99.128 | 58.107 | 52.882 | 28.239 | 65.419 | 31.243 | 21.616 | ||
| 0.5 | 1 | 0.9913 | 0.5811 | 0.6850 | 0.2824 | 0.7722 | 0.4033 | 0.1419 | |
| 5 | 24.782 | 14.526 | 17.125 | 7.0598 | 19.306 | 10.081 | 3.5462 | ||
| 10 | 99.128 | 58.107 | 68.502 | 28.239 | 77.223 | 40.326 | 14.184 | ||
| 0.8 | 1 | 0.9913 | 0.5811 | 0.8619 | 0.2824 | 0.9003 | 0.5060 | 0.0901 | |
| 5 | 24.782 | 14.526 | 21.547 | 7.0598 | 22.508 | 12.649 | 2.2524 | ||
| 10 | 99.128 | 58.107 | 86.188 | 28.239 | 90.031 | 50.598 | 9.0095 | ||
| 0.9 | 0.2 | 1 | 0.9913 | 0.4668 | 0.5288 | 0.1419 | 0.5557 | 0.2518 | 0.0901 |
| 5 | 24.782 | 11.668 | 13.220 | 3.5462 | 13.892 | 6.2937 | 2.2524 | ||
| 10 | 99.128 | 46.674 | 52.882 | 14.184 | 55.568 | 25.174 | 9.0095 | ||
| 0.5 | 1 | 0.9913 | 0.4668 | 0.6850 | 0.1419 | 0.7041 | 0.3245 | 0.0422 | |
| 5 | 24.782 | 11.668 | 17.125 | 3.5462 | 17.601 | 8.1116 | 1.0520 | ||
| 10 | 99.128 | 46.674 | 68.502 | 14.184 | 70.406 | 32.446 | 4.2074 | ||
| 0.8 | 1 | 0.9913 | 0.4668 | 0.8619 | 0.1419 | 0.8704 | 0.4067 | 0.0182 | |
| 5 | 24.782 | 11.668 | 21.547 | 3.5462 | 21.760 | 10.166 | 0.4524 | ||
| 10 | 99.128 | 46.674 | 86.188 | 14.184 | 87.040 | 40.667 | 1.8092 | ||
| Coef. | |||||||
|---|---|---|---|---|---|---|---|
| 62.405 | 8.5871 | 27.665 | 27.627 | 32.386 | 3.8295 | 27.588 | |
| 1.5511 | 2.1046 * | 1.9008 * | 1.9088 * | 1.8598 * | 2.1459 * | 1.9092 * | |
| 0.5101 | 1.0648 * | 0.8699 * | 0.8685 * | 0.8196 * | 1.1157 * | 0.8689 * | |
| 0.1019 | 0.6680 * | 0.4619 | 0.4678 | 0.4177 | 0.7126 * | 0.4682 | |
| −0.1440 | 0.3995 * | 0.2080 | 0.2072 | 0.1592 | 0.4488 * | 0.2076 | |
| ----------- | 0.007676 | - | 0.000471 | 0.007676 | 0.007676 | 0.000471 | |
| ----------- | ----------- | 0.442224 | ----------- | 0.442224 | 0.442224 | 0.001536 | |
| 4912.090 | 2989.820 | 2170.967 | 2170.9604 | 2222.682 | 3450.710 | 2170.9602 |
| Coef. | |||||||
|---|---|---|---|---|---|---|---|
| −52.994 | 1.0931 | −49.641 | −5.0190 | −7.7933 | 1.2529 | −5.0188 | |
| 0.0711 * | 0.0526 * | 0.0704 * | 0.0609 * | 0.0556 * | 0.0525 * | 0.0609 * | |
| −0.4235 | −0.6457 * | −0.4316 | −0.5426 | −0.6092 * | −0.6464 * | −0.5427 | |
| −0.5726 * | −0.5611 | −0.5745 | −0.5985 * | −0.5630 | −0.5610 | −0.5984 * | |
| −0.4142 | −0.2062 | −0.4083 | −0.3266 | −0.2404 | −0.2056 | −0.3267 | |
| 48.418 * | 37.119 * | 48.046 * | 42.918 * | 38.976 * | 37.085 * | 42.918 * | |
| --------- | 262.88 | --------- | 9.5600 | 262.88 | 262.88 | 8.2110 | |
| --------- | --------- | 0.1643 | --------- | 0.1643 | 0.1643 | 0.1643 | |
| 17095 | 3190.6 | 15183 | 2915.1 | 2945.3 | 3204.1 | 2914.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dawoud, I.; Kibria, B.M.G. A New Biased Estimator to Combat the Multicollinearity of the Gaussian Linear Regression Model. Stats 2020, 3, 526-541. https://doi.org/10.3390/stats3040033
Dawoud I, Kibria BMG. A New Biased Estimator to Combat the Multicollinearity of the Gaussian Linear Regression Model. Stats. 2020; 3(4):526-541. https://doi.org/10.3390/stats3040033
Chicago/Turabian StyleDawoud, Issam, and B. M. Golam Kibria. 2020. "A New Biased Estimator to Combat the Multicollinearity of the Gaussian Linear Regression Model" Stats 3, no. 4: 526-541. https://doi.org/10.3390/stats3040033
APA StyleDawoud, I., & Kibria, B. M. G. (2020). A New Biased Estimator to Combat the Multicollinearity of the Gaussian Linear Regression Model. Stats, 3(4), 526-541. https://doi.org/10.3390/stats3040033