
Stylometry and Numerals Usage: Benford’s Law and Beyond

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Benford’s Law and Texts
- Arabic numbers (not spelled out) of consecutive front-page news items of a newspaper. “Dates were barred as not being variable, and the omission of spelled-out numbers restricted the counted digits to numbers 10 and over”;
- The first 342 street addresses given in an American Men of Science edition;
- Numeral usage (except for dates and page numbers) of an issue of the Readers’ Digest.
- (1)
- Possible rounding of numerals starting with digits 8 and 9;
- (2)
- In German, the indefinite article ein coincides with the numeral ein.
- we take into account not only numerals expressed in digits but also those spelled (expressed verbally), both cardinal and ordinal ones—technically, a much more difficult task, especially for texts in languages in which the numerals are declined: Russian, Czech, Lithuanian, etc.;
- the object of our study is coherent literary texts (as well as compilations of such texts), not a random set of texts.
- There are differences between the distributions (especially between the Gospels from Matthew, Mark, Luke on the one hand and that from John, on the other hand)—not very large, but statistically significant, given the amount of analyzed data.
- In general, the distribution of the first significant digit of numerals here also resembles Benford’s one, but the first significant digit 1 is noticeably predominant.
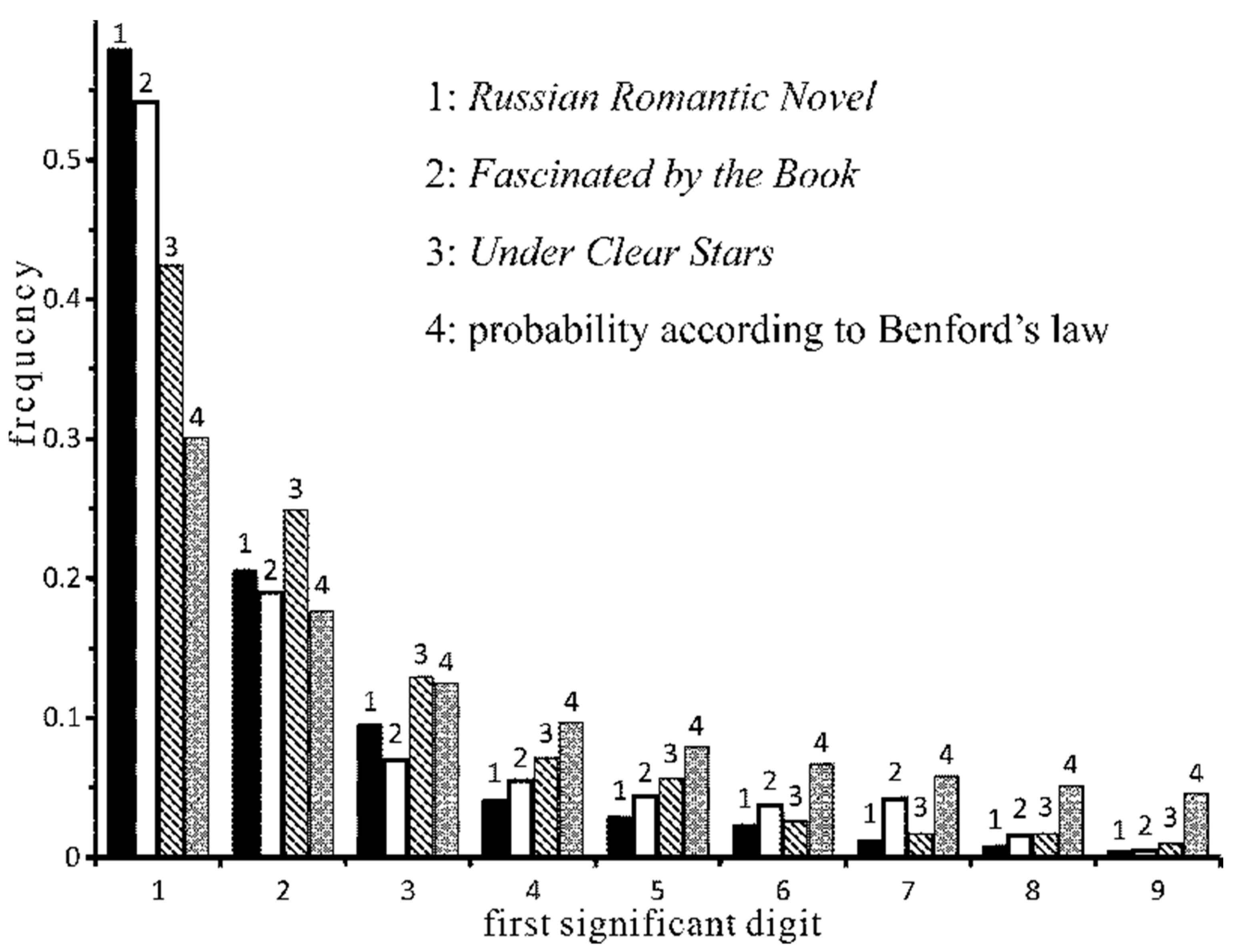
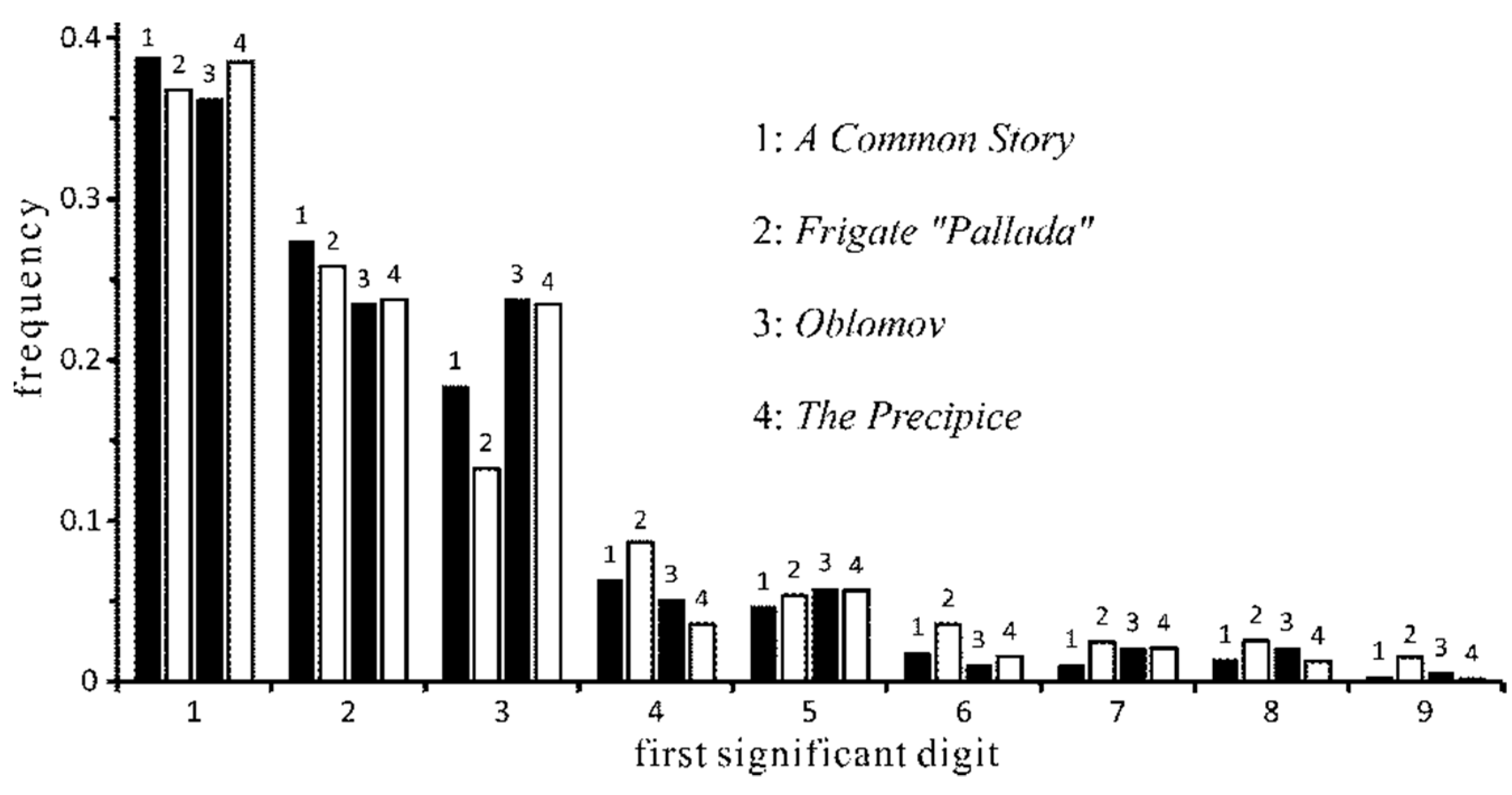
- It turned out that the share of the digit 1 is so much higher than prescribed by Benford’s Law (it varies from 38 to 45 percent instead of Benford’s 30 percent) that the distribution could be called ultra-Benfordian. As we later found out, this is typical for the coherent literary texts of most authors.
- Benford’s Law approximately holds for coherent texts.
- Deviations from Benford’s Law are statistically significant author’s features that allow, under certain conditions, to distinguish between parts of the text with different authorship. The obvious requirements are the sufficient length of the text and the sufficient use of numerals in it, which, for example, is usually satisfied in historical literature.
- The distribution of the first significant digits at the end of the {1, 2,..., 7, 8, 9} row is subject to strong fluctuations (even in texts by the same author) and is not indicative.
- The frequencies of the first significant digits are stabilized for texts larger than 200 KB (the size of the txt file in UTF-8 encoding).
- We confirm the visual similarity/differences in the frequency distributions of the first significant digits by the Pearson chi-squared test; to apply it, we had to develop a special technique (for details, see [21]). Unfortunately, the standard procedure offered by statistical packages is not suitable here.
2.1. Distribution of the First Significant Digits of the Numerals in Compiled Texts
2.2. Coherent Literary Texts: The Author’s Peculiarities
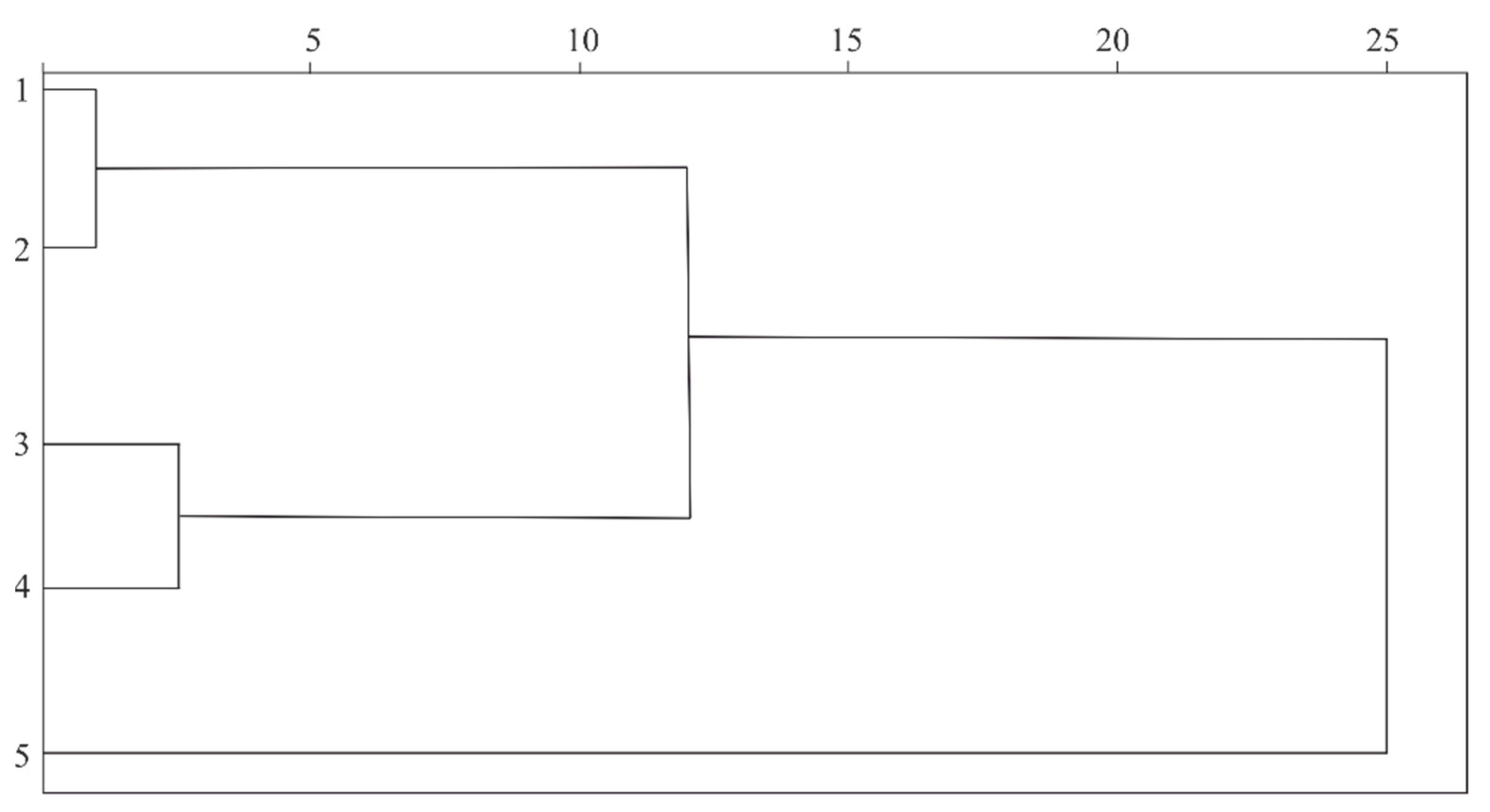
2.3. First Significant Digits and Texts Authorship Attribution
2.4. Statistical Characteristics of Translated Texts
3. Beyond the Benford’s Law
- The analysis of the statistics of the first significant digits is only applicable to the significant digit 1 and (sometimes) 2 and 3 since the occurrence of subsequent digits is subject to strong fluctuations even in the texts of the same author. Thus, only a small part of the statistical information on the numerals contained in the text is available for analysis.
- On the other hand, using the first significant digits is advantageous since the information here is presented in a generalized form: it can minimize the influence of numbers closely connected to the topic of the text (e.g., the year 1812 in L. Tolstoy’s War and Peace).
- Analysis of the use of the numerals themselves (and not the first significant digits) gives richer information about an author’s peculiarities of the text and, to a large extent, is not blocked by indistinguishability of the numeral one and the indefinite article.
- However, the analysis of numerals statistics is more difficult.
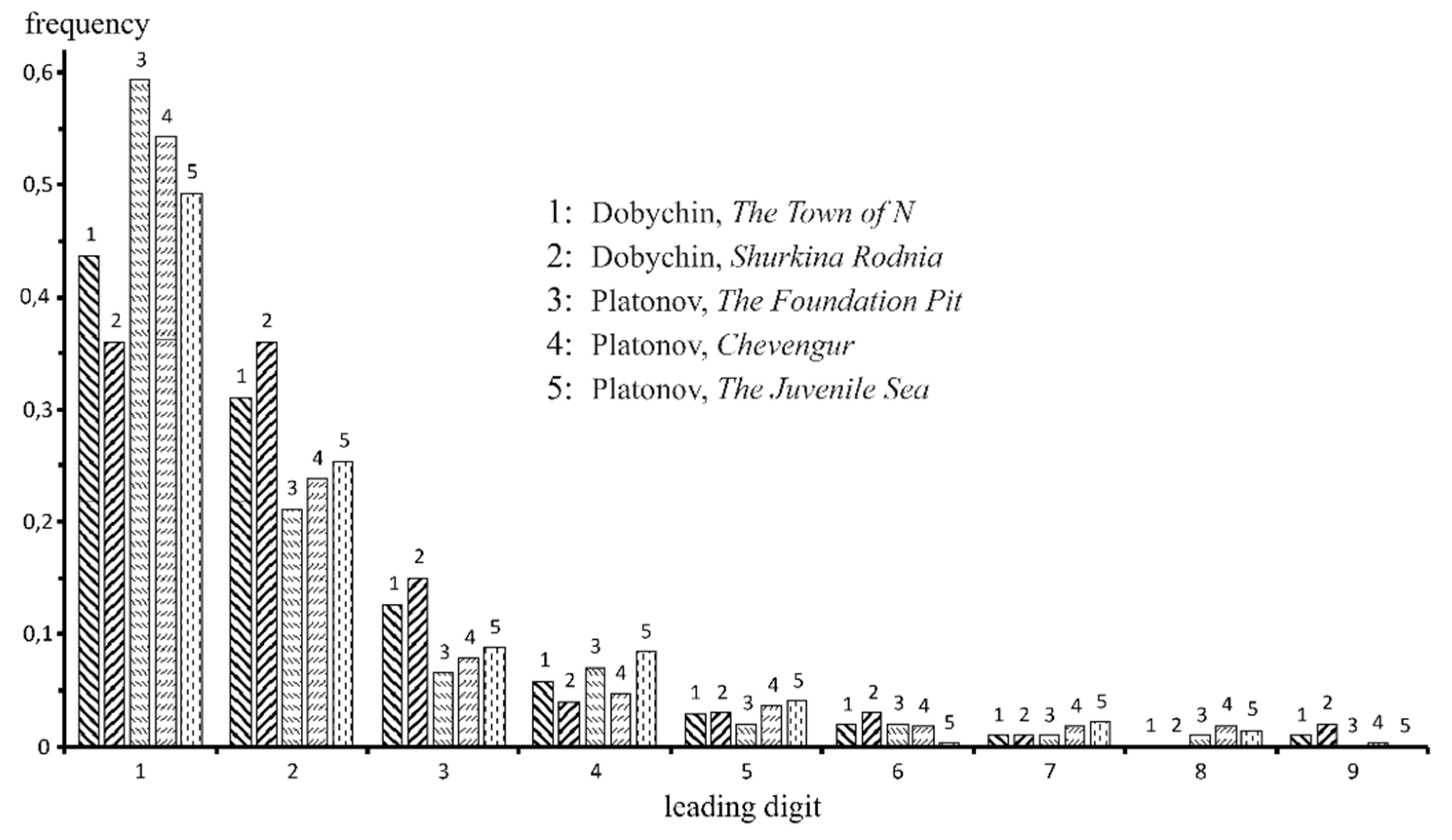
3.1. The Extension of the Numerals Analysis. Dobychin vs. Platonov
- Platonov, in his literary texts, more likely uses numerals than Dobychin.
- Platonov less often resorts to rounding of numerals (10, 20, 30...), which, in conjunction with item 1, can indirectly indicate a greater tendency to detail.
- The numeral one (in different word forms) is the undisputed leader among the numerals found in Platonov’s texts. In the texts by Dobychin, the numeral one is inferior in frequency to the numeral two!
- Note the psychologically understandable rarefaction of the series of numerals and a decrease in their occurrence as they increase, as well as a noticeable local maximum at the numeral 100, which, of course, plays the role of an indefinitely large number.
3.2. Who Wrote “The Twelve Chairs”?
- For all the analyzed texts, there are peaks in the occurrence of round numbers 10, 20,..., 100, 200,…
- In the texts by Ilf and Petrov, as well as in Bulgakov’s The Master and Margarita, the numeral 1 has the highest frequency (which is consistent with Benford’s Law), but in Kataev’s texts, the number 2 leads.
- These two texts are characterized by the greatest variety of numerals.
- On the contrary, Kataev’s texts are distinguished by the least variety of numerals.
- In terms of the variety of numerals, The Master and Margarita occupy an average position, but the frequencies of the numerals (after the initial frequent ones and twos) are usually lower than in other texts analyzed. In fact, many numbers occur once.
- The Twelve Chairs; a joint work by Ilf and Petrov, 1927–1928; vol. 1 [44];
- Joint works 1932–1937 (stories, feuilletons, articles, speeches, vaudevilles, screenplays) by Ilf and Petrov, included in vol. 3;
- The Little Golden Calf; a joint work by Ilf and Petrov, 1929–1930; vol. 2;
- Works (stories, essays, feuilletons) written individually by Petrov in 1924–1932 and included in vol. 5;
- Works (essays, articles, memoirs) written individually by Petrov in 1937–1942 and included in vol. 5;
- One-storied America (travel essays; sometimes translated as Little Golden America), 1936, vol. 4;
- Works (stories, essays, feuilletons) written solely by Ilf in 1923–1929, as well as his notebooks from 1925-37, included in vol. 5.
4. Discussion
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benford, F. The law of anomalous numbers. Proc. Am. Philos. Soc. 1938, 78, 551–572. [Google Scholar]
- Fewster, R.M. A Simple Explanation of Benford’s Law. Am. Stat. 2009, 63, 29–32. [Google Scholar] [CrossRef] [Green Version]
- Blondeau Da Silva, S. Limits of Benford’s law in experimental field. Int. J. Appl. Math. 2020, 33, 685–695. [Google Scholar]
- Hill, T.P. A Statistical Derivation of the Significant-Digit Law. Stat. Sci. 1995, 10, 354–363. [Google Scholar] [CrossRef]
- Alipour, A.; Alipour, S. Application of Benford’s Law in Analyzing Geotechnical Data. Civ. Eng. Infrastruct. J. 2019, 52, 323–334. [Google Scholar] [CrossRef]
- Mangoua, M.J.; Kouassi, K.A.; Douagui, G.A.; Savané, I.; Biémi, J. Application of Benford’s Law to Hydrogeological Parameters: Case of the Baya Watershed (Eastern Côte d’Ivoire). Asian J. Geol. Res. 2019, 2, 1–7. [Google Scholar]
- Morag, S.; Salmon-Divon, M. Characterizing Human Cell Types and Tissue Origin Using the Benford Law. Cells 2019, 8, 1004. [Google Scholar] [CrossRef] [Green Version]
- Özkundakci, D.; Pingram, M. Nature favours “one” as the leading digit in phytoplankton abundance data. Limnologica 2019, 78, 125707. [Google Scholar] [CrossRef]
- Cole, M.A.; Maddison, D.J.; Zhang, L. Testing the emission reduction claims of CDM projects using the Benford’s Law. Clim. Chang. 2020, 160, 407–426. [Google Scholar] [CrossRef] [Green Version]
- Vellwock, A.E.; Wei, A. On the Benfordness of Academic Citations. November 2020. Available online: https://www.researchgate.net/publication/345437332_On_the_Benfordness_of_academic_citations (accessed on 29 October 2021). [CrossRef]
- Sambridge, M.; Jackson, A. Spotlight on figures for COVID-19. Nature 2020, 581, 384. [Google Scholar] [CrossRef]
- Farhadi, N. Can we rely on COVID-19 data? An assessment of data from over 200 countries worldwide. Sci. Prog. 2021, 104, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Grammatikos, T.; Papanikolaou, N.I. Applying Benford’s Law to detect accounting data manipulation in the banking industry. J. Financ. Serv. Res. 2021, 59, 115–142. [Google Scholar] [CrossRef]
- Dacey, J. Benford’s Law and the 2020 US Presidential Election: Nothing Out Of The Ordinary. Available online: https://physicsworld.com/a/benfords-law-and-the-2020-us-presidential-election-nothing-out-of-the-ordinary/ (accessed on 29 October 2021).
- Kossovsky, A.E.; Miller, S.J. Report on Benford’s Law Analysis of 2020 Presidential Election Data. Available online: https://web.williams.edu/Mathematics/sjmiller/public_html/KossoskyMiller_FinalBenfordAnalysis.pdf (accessed on 29 October 2021).
- Nigrini, M.J. Benford’s Law: Applications for Forensic Accounting, Auditing, and Fraud Detection; John Wiley & Sons: Hoboken, NJ, USA, 2012; 330p. [Google Scholar]
- Hungerbühler, N. Benfords Gesetz über führende Ziffern: Wie die Mathematik Steuersündern das Fürchten lehrt. EducETH, Publikation der Eidgenössischen Technischen Hochschule Zürich. 2007. Available online: https://ethz.ch/content/dam/ethz/special-interest/dual/educeth-dam/documents/Unterrichtsmaterialien/mathematik/Benfords%20Gesetz%20über%20führende%20Ziffern%20(Artikel)/benford.pdf (accessed on 29 October 2021).
- Zenkov, A.V. Deviation from Benford’s law and identification of author peculiarities in texts. Comput. Res. Model. 2015, 7, 197–201. (In Russian) [Google Scholar] [CrossRef] [Green Version]
- Shulzinger, E.; Legchenkova, I.; Bormashenko, E. Co-occurrence of the Benford-like and Zipf Laws Arising from the Texts Representing Human and Artificial Languages. arXiv 2018, arXiv:1803.03667. [Google Scholar]
- Shulzinger, E.; Bormashenko, E. On the Universal Quantitative Pattern of the Distribution of Initial Characters in General Dictionaries: The Exponential Distribution is Valid for Various Languages. J. Quant. Linguist. 2017, 24, 273–288. [Google Scholar] [CrossRef]
- Zenkov, A.V. A Method of Text Attribution Based on the Statistics of Numerals. J. Quant. Linguist. 2018, 25, 256–270. [Google Scholar] [CrossRef]
- Pogorelsky, A.; Titov, V.; Pogodin, M.; Melgunov, N.; Baratynsky, E.; Bestuzhev (Marlinsky), A.; Polevoy, N.; Zagoskin, M.; Rostopchina, E.; Olin, V.; et al. Russian Romantic Novel; Khudozhestvennaia Literatura Publ.: Moscow, Russia, 1989; 384p. (In Russian) [Google Scholar]
- Novikov, N.; Radishchev, A.; Strakhov, N.; Berezaysky, B.; Karamzin, N.; Zhukovsky, V.; Yakovlev, P.; Pushkin, A.; Odoyevsky, V.; Herzen, A.; et al. Fascinated by the Book. Russian Writers on Books, Reading, Bibliophiles; Kniga Publ.: Moscow, Russia, 1982; 287p. (In Russian) [Google Scholar]
- Gorky, A.; Romanov, P.; Tikhonov, N.; Fadeev, A.; Kaverin, V.; Nikulin, L.; Babel, I.; Kolosov, M.; Lavrenev, B.; Sokolov-Mikitov, I.; et al. Under Clear Stars. The Soviet Story of the Thirties; The Moscow Worker Publ.: Moscow, Russia, 1983; 130p. (In Russian) [Google Scholar]
- Morris, G.P.; Poe, E.A.; Kirkland, C.M.S.; Leslie, E.; Curtis, G.W.; Hale, E.E.; Holmes, O.W.; Twain, M.; Edwards, H.S.; Johnston, R.M.; et al. The Best American Humorous Short Stories; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/10947 (accessed on 10 October 2021).
- Irving, W.; Poe, E.A.; Hawthorne, N.; Bret Harte, F.; Stevenson, R.L.; Kipling, R. The Short-Story; Transcribed from the 1916 Allyn and Bacon edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/21964 (accessed on 10 October 2021).
- Kipling, R.; Conan Doyle, A.; Castle, E.; Weyman, S.J.; Collins, W.; Stevenson, R.L. The Lock and Key Library, Classic Mystery and Detective Stories; Transcribed from the 1909 Review of Reviews Co. edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/2038 (accessed on 10 October 2021).
- Johnson, S.; Walpole, H.; Beckford, W. Shorter Novels, Eighteenth Century. The History of Rasselas, The Castle of Otranto, Vathek; Transcribed from the 1903 Aldine House edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/34766 (accessed on 10 October 2021).
- Boswell, J.; Wordsworth, W.; Scott, W.; Coleridge, S.T.; Southey, R.; Landor, W.S.; Lamb, C.; Hazlitt, W.; De Quincey, T.; Lord Byron, P.B.; et al. The Best of the World’s Classics, Vol. V (of X)—Great Britain and Ireland; Transcribed from the 1909 Funk & Wagnalls Co. edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/22182 (accessed on 10 October 2021).
- Defoe, D.; Hogg, J.; Irving, W.; Hawthorne, N.; Poe, E.A.; Brown, J.; Dickens, C.; Stockton, F.R.; Twain, M.; Bret Harte, F.; et al. The Great English Short-Story Writers, Volume 1; Transcribed from the 1910 Readers’ Library edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/10135 (accessed on 10 October 2021).
- Dickens, C.; Collins, W.; Gaskell, E.; Procter, A.A. A House to Let; Transcribed from the 1903 Chapman and Hall edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/2324 (accessed on 10 October 2021).
- Blackwood, A.; Rhodes James, M.; Rickford, K.; Harvey, W.F.; Adams Cram, R.; Stevenson, R.L.; Steele, W.D. Masterpieces of Mystery, Volume 1, Ghost Stories; Transcribed from the 1920 Doubleday, Page & Co. edition; The Project Gutenberg eBook: Salt Lake City, UT, USA; Available online: http://www.gutenberg.org/files/27722 (accessed on 10 October 2021).
- Zenkov, A.V. A novel method of stylometry based on the statistic of numerals. Comput. Res. Modeling 2017, 9, 837–850. (In Russian) [Google Scholar]
- Zenkov, A.V.; Místecký, M. The Romantic Clash: Influence of Karel Sabina over Mácha’s Cikáni from the Perspective of the Numerals Usage Statistics. Glottometrics 2019, 46, 12–28. [Google Scholar]
- Kjetsaa, G.; Gustavsson, S.; Beckman, B.; Gil, S. The Authorship of the Quiet Don. Slavica Norvegica; Solum Forlag: Oslo, Norway; Humanities Press: Atlantic Highlands, NJ, USA, 1984; Volume 1, 153p. [Google Scholar]
- Kuznetsov, F.F. (Ed.) New on Mikhail Sholokhov: Research and Materials; Institute of World Literature: Moscow, Russia, 2003; 450p. (In Russian) [Google Scholar]
- Herdan, G. Quantitative Linguistics; Butterworths: London, UK, 1964; 284p. [Google Scholar]
- Eidinova, V.V.; Platonov, A.; Dobychin, L. Stylistic Convergence and Repulsion. Andrei Platonov’s “Land of Philosophers”: Problems of Creativity. In Proceedings of the International Scientific Conference Dedicated to the 50th Anniversary of A. Platonov’s Death, Moscow, Russia, 23–25 April 2001; pp. 211–219. (In Russian). [Google Scholar]
- Zenkov, A.V. Statistics of Numerals in the Text: Development of a New Method of Stylometry, Advances in Economics, Business and Management Research. In Proceedings of the First International Volga Region Conference on Economics, Humanities and Sports FICEHS 19, Kazan, Russia, 24–25 September 2019; Atlantis Press: Amsterdam, The Netherlands, 2020; Volume 114, pp. 448–451. [Google Scholar] [CrossRef] [Green Version]
- Ščeglov, Y.K. The Novels by Ilf and Petrov. Readers’s Companion; Ivan Limbach Publishing House: St. Petersburg, Russia, 2009; 656p, ISBN 9785890591340. [Google Scholar]
- Amlinski, I. 12 Chairs from Mikhail Bulgakov; Kirschner: Berlin, Germany, 2013; 328p, ISBN 9783000432842. [Google Scholar]
- Zenkov, A.; Zenkov, E.; Belke, A. A Novel Text Analysis Method: Numerals Reveal the Author. In Proceedings of the International Scientific Conference on New Industrialization and Digitalization (NID 2020), Ekaterinburg, Russia, 12 December 2020; EDP Sciences: Les Ulis, France, 2021; Volume 93, p. 03026. [Google Scholar] [CrossRef]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications, ASA-SIAM Series on Statistics and Applied Probability; SIAM: Philadelphia, PA, USA, 2007. [Google Scholar]
- Ilf, I.; Petrov, E. Collected Works in 5 Volumes; Khudozhestvennaia Literatura Publ.: Moscow, Russia, 1961. (In Russian) [Google Scholar]
- Zenkov, A.; Zenkov, E.; Zenkov, M. New Approaches to Content Analysis of Data Based on Numerals Statistics. In Proceedings of the Conference of Applied Computer Science and Software Engineering (CACSSE 2021), CEUR Workshop Proceedings, Aachen, Germany, 2021. accepted for publication. [Google Scholar]
- Zenkov, A.; Zenkov, E.; Zenkov, M.; Sazanova, L. Numerals in authorial Turkish-language texts and the stylometric analysis. In Proceedings of the International Scientific Forum on Computer and Energy Sciences (WFCES 2021), Almaty, Kazakhstan, 20–21 May 2021; Nazarov, A.D., Ed.; EDP Sciences: Les Ulis, France, 2021; Volume 270, p. 01038. [Google Scholar] [CrossRef]
- Konrad, N.I. Essays on Japanese Literature. Articles and Research; Khudozhestvennaia literatura Publ.: Moscow, Russia, 1973; 462p. (In Russian) [Google Scholar]
- Burns, B.D. Do People Fit to Benford’s Law, or Do They Have a Benford Bias? Available online: https://cogsci.mindmodeling.org/2020/papers/0379/index.html (accessed on 8 December 2021).
- Tempestt, N.; Kalaivani, S.; Aneez, F.; Yiming, Y.; Yingfei, X.; Damon, W. Surveying Stylometry Techniques and Applications. ACM Comput. Surv. 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Burrows, J. Delta: A measure of stylistic difference and a guide to likely authorship. Lit. Linguist. Comput. 2002, 17, 267–287. [Google Scholar] [CrossRef]
- Brocardo, M.L.; Traore, I.; Woungang, I.; Obaidat, M.S. Authorship verification using deep belief network systems. Int. J. Commun. Syst. 2017, 30, e3259. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zenkov, A.V. Stylometry and Numerals Usage: Benford’s Law and Beyond. Stats 2021, 4, 1051-1068. https://doi.org/10.3390/stats4040060
Zenkov AV. Stylometry and Numerals Usage: Benford’s Law and Beyond. Stats. 2021; 4(4):1051-1068. https://doi.org/10.3390/stats4040060
Chicago/Turabian StyleZenkov, Andrei V. 2021. "Stylometry and Numerals Usage: Benford’s Law and Beyond" Stats 4, no. 4: 1051-1068. https://doi.org/10.3390/stats4040060
APA StyleZenkov, A. V. (2021). Stylometry and Numerals Usage: Benford’s Law and Beyond. Stats, 4(4), 1051-1068. https://doi.org/10.3390/stats4040060