
Investigating Self-Rationalizing Models for Commonsense Reasoning


Abstract
:1. Introduction
2. Background
2.1. Explainable NLP
2.2. Human Explanations
2.3. Rationales
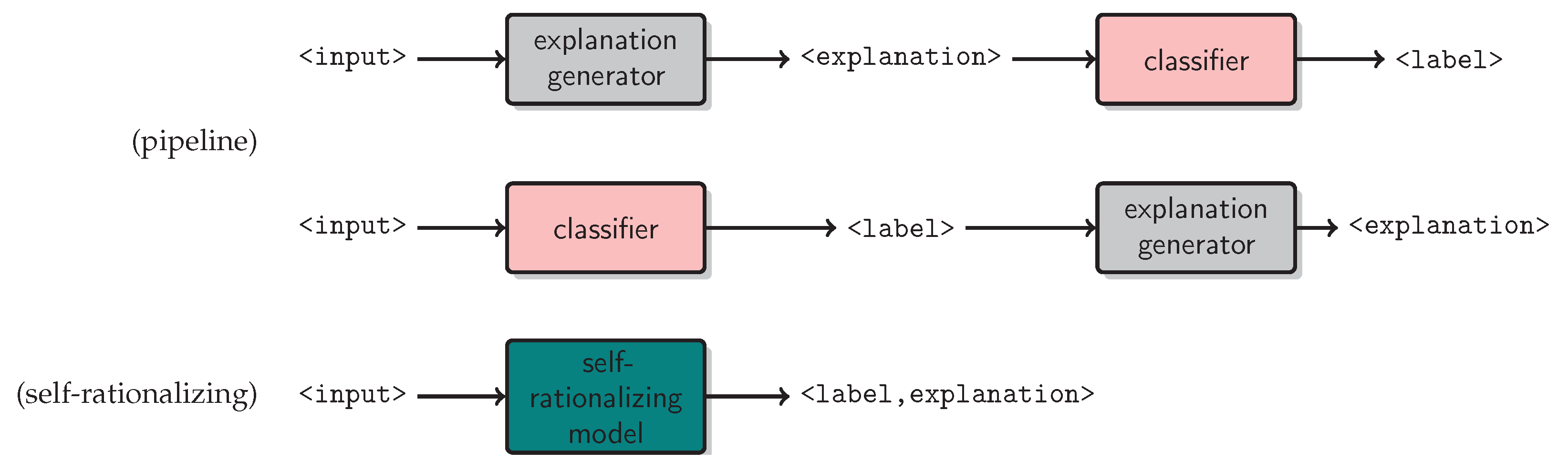
2.4. Self-Rationalizing Models
3. Experimental Setup
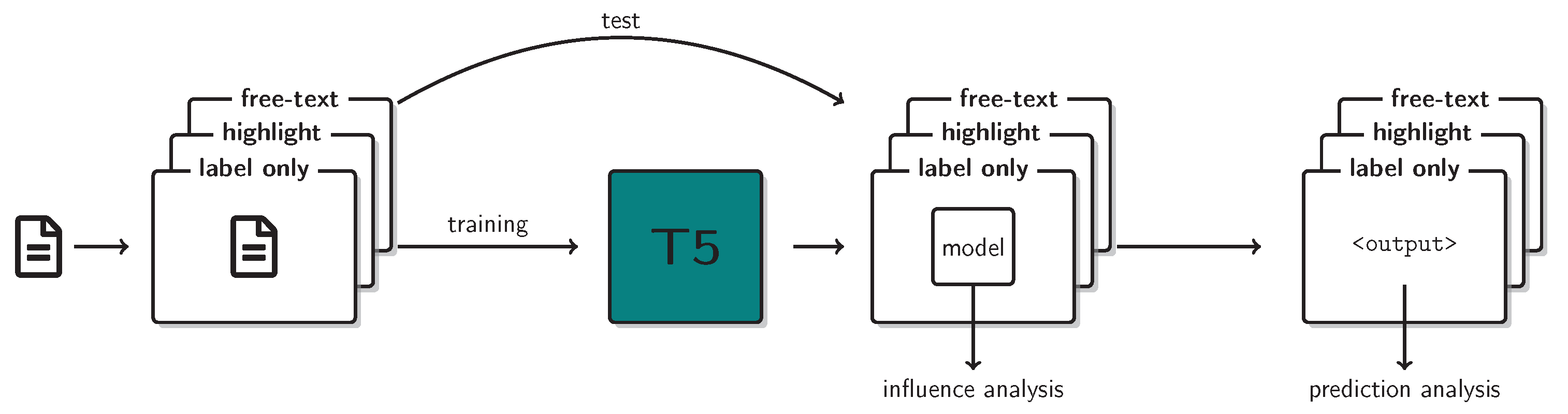
3.1. Data
3.2. Model
3.3. Instance Attribution
4. Results and Discussion
4.1. Task Performance
4.2. Output Validity
4.3. Probing Model Behavior
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| Cos-E | Commonsense Explanation (dataset) |
| GPT | generative pre-trained Transformer |
| IF | influence function |
| LLM | large language model |
| NLP | natural language processing |
| NLI | natural language inference |
| T5 | text-to-text transfer Transformer |
| XAI | explainable ai |
Appendix A. Computation Details
Appendix A.1. Implementation
Appendix A.2. Hardware and Runtimes
References
- Lyons, J.B.; Clark, M.A.; Wagner, A.R.; Schuelke, M.J. Certifiable Trust in Autonomous Systems: Making the Intractable Tangible. AI Mag. 2017, 38, 37–49. [Google Scholar] [CrossRef]
- Nor, A.K.M.; Pedapati, S.R.; Muhammad, M.; Leiva, V. Abnormality Detection and Failure Prediction Using Explainable Bayesian Deep Learning: Methodology and Case Study with Industrial Data. Mathematics 2022, 10, 554. [Google Scholar] [CrossRef]
- Dzindolet, M.T.; Peterson, S.A.; Pomranky, R.A.; Pierce, L.G.; Beck, H.P. The role of trust in automation reliance. Int. J. Hum.-Comput. Stud. 2003, 58, 697–718. [Google Scholar] [CrossRef]
- Mercado, J.E.; Rupp, M.A.; Chen, J.Y.; Barnes, M.J.; Barber, D.; Procci, K. Intelligent Agent Transparency in Human–Agent Teaming for Multi-UxV Management. Hum. Factors 2016, 58, 401–415. [Google Scholar] [CrossRef]
- Héder, M. Explainable AI: A brief History of the Concept. ERCIM News 2023, 134, 9–10. [Google Scholar]
- La Rocca, M.; Perna, C. Opening the Black Box: Bootstrapping Sensitivity Measures in Neural Networks for Interpretable Machine Learning. Stats 2022, 5, 440–457. [Google Scholar] [CrossRef]
- Hulsen, T. Explainable Artificial Intelligence (XAI): Concepts and Challenges in Healthcare. AI 2023, 4, 652–666. [Google Scholar] [CrossRef]
- Wiegreffe, S.; Marasović, A. Teach Me to Explain: A Review of Datasets for Explainable NLP. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, NeurIPS, Datasets and Benchmarks Track, Virtual, 6–14 December 2021. [Google Scholar]
- Rajani, N.F.; McCann, B.; Xiong, C.; Socher, R. Explain Yourself! Leveraging Language Models for Commonsense Reasoning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4932–4942. [Google Scholar] [CrossRef]
- Camburu, O.M.; Rocktäschel, T.; Lukasiewicz, T.; Blunsom, P. e-SNLI: Natural Language Inference with Natural Language Explanations. In Advances in Neural Information Processing Systems 31, NeurIPS; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 9539–9549. [Google Scholar]
- Wiegreffe, S.; Marasović, A.; Smith, N.A. Measuring Association Between Labels and Free-Text Rationales. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 10266–10284. [Google Scholar] [CrossRef]
- Jain, S.; Wiegreffe, S.; Pinter, Y.; Wallace, B.C. Learning to Faithfully Rationalize by Construction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, Virtual, 6–8 July 2020; pp. 4459–4473. [Google Scholar] [CrossRef]
- Narang, S.; hoffman, C.; Lee, K.; Roberts, A.; Fiedel, N.; Malkan, K. WT5?! Training Text-to-Text Models to Explain their Predictions. arXiv 2020, arXiv:2004.14546. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Hoffman, R.R.; Klein, G.; Mueller, S.T. Explaining Explanation for “Explainable AI”. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2018, 62, 197–201. [Google Scholar] [CrossRef]
- Han, X.; Wallace, B.C.; Tsvetkov, Y. Explaining Black Box Predictions and Unveiling Data Artifacts through Influence Functions. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, Virtual, 6–8 July 2020; pp. 5553–5563. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You? ”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd International Conference on Knowledge Discovery and Data Mining, ACM SIGKDD, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In Proceedings of the International Conference on Learning Representations, ICLR (Workshop Poster), Banff, Canada, 14–16 April 2014. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding Black-box Predictions via Influence Functions. In Proceedings of the 4th International Conference on Machine Learning, ICML, Sidney, Australia, 6–11 August 2017; Volume 70, pp. 1885–1894. [Google Scholar]
- Jacovi, A.; Goldberg, Y. Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, Virtual, 6–8 July 2020; pp. 4198–4205. [Google Scholar] [CrossRef]
- Pezeshkpour, P.; Jain, S.; Wallace, B.; Singh, S. An Empirical Comparison of Instance Attribution Methods for NLP. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, Virtual, 6–11 June 2021; pp. 967–975. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Bibal, A.; Cardon, R.; Alfter, D.; Wilkens, R.; Wang, X.; François, T.; Watrin, P. Is Attention Explanation? An Introduction to the Debate. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, ACL, Dublin, Irland, 22–27 May. 2022; Volume 1, pp. 3889–3900. [Google Scholar] [CrossRef]
- Bastings, J.; Filippova, K. The elephant in the interpretability room: Why use attention as explanation when we have saliency methods? In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, Online, 20 November 2020; pp. 149–155. [Google Scholar] [CrossRef]
- Wiegreffe, S.; Pinter, Y. Attention is not not Explanation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong-Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 11–20. [Google Scholar] [CrossRef]
- Jain, S.; Wallace, B.C. Attention is not Explanation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3543–3556. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar]
- Mathew, B.; Saha, P.; Yimam, S.M.; Biemann, C.; Goyal, P.; Mukherjee, A. HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Special Track on AI for Social Impact, Virtual-only, 2–9 February; 2021; Volume 35, pp. 14867–14875. [Google Scholar] [CrossRef]
- Zaidan, O.F.; Eisner, J.; Piatko, C.D. Using “Annotator Rationales” to Improve Machine Learning for Text Categorization. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, NAACL-HLT, Rochester, NY, USA, 22–27 April 2007; pp. 260–267. [Google Scholar]
- Strout, J.; Zhang, Y.; Mooney, R. Do Human Rationales Improve Machine Explanations? In Proceedings of the ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 56–62. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. [Google Scholar]
- McDonnell, T.; Lease, M.; Kutlu, M.; Elsayed, T. Why Is That Relevant? Collecting Annotator Rationales for Relevance Judgments. In Proceedings of the Conference on Human Computation and Crowdsourcing, AAAI-HCOMP, Austin, Texas, USA, 30 October–3 November 2016; Volume 4, pp. 139–148. [Google Scholar] [CrossRef]
- Kutlu, M.; McDonnell, T.; Elsayed, T.; Lease, M. Annotator Rationales for Labeling Tasks in Crowdsourcing. J. Artif. Intell. Res. 2020, 69, 143–189. [Google Scholar] [CrossRef]
- DeYoung, J.; Jain, S.; Rajani, N.F.; Lehman, E.; Xiong, C.; Socher, R.; Wallace, B.C. ERASER: A Benchmark to Evaluate Rationalized NLP Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL, Virtual, 6–8 July 2020; pp. 4443–4458. [Google Scholar] [CrossRef]
- Jacovi, A.; Goldberg, Y. Aligning Faithful Interpretations with their Social Attribution. Trans. Assoc. Comput. Linguist. 2021, 9, 294–310. [Google Scholar] [CrossRef]
- Sheh, R.; Monteath, I. Defining Explainable AI for Requirements Analysis. KI Künstliche Intell. 2018, 32, 261–266. [Google Scholar] [CrossRef]
- Meister, C.; Lazov, S.; Augenstein, I.; Cotterell, R. Is Sparse Attention more Interpretable? In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL-ICNLP, Virtual, 1–6 August 2021; Volume 2, pp. 122–129. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Talmor, A.; Herzig, J.; Lourie, N.; Berant, J. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4149–4158. [Google Scholar] [CrossRef]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A Large Annotated Corpus for Learning Natural Language Inference. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP, Lisbon, Portugal, 17–21 September 2015. [Google Scholar] [CrossRef]
- Rancourt, F.; Maupomé, D.; Meurs, M.J. On the Influence of Annotation Quality in Suicidal Risk Assessment from Text. In Proceedings of the Canadian Conference on Artificial Intelligence, CAI, Toronto, ON, Canada, 30 May–3 June 2022. [Google Scholar] [CrossRef]
- Guo, H.; Rajani, N.; Hase, P.; Bansal, M.; Xiong, C. FastIF: Scalable Influence Functions for Efficient Model Interpretation and Debugging. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 10333–10350. [Google Scholar] [CrossRef]
- Ni, J.; Hernandez Abrego, G.; Constant, N.; Ma, J.; Hall, K.; Cer, D.; Yang, Y. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Irland, 22–27 May 2022; pp. 1864–1874. [Google Scholar] [CrossRef]
- Breiman, L. Statistical Modeling: The Two Cultures. Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Aggarwal, S.; Mandowara, D.; Agrawal, V.; Khandelwal, D.; Singla, P.; Garg, D. Explanations for CommonsenseQA: New Dataset and Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL-IJCNLP, Virtual, 1–6 August 2021; Volume 1, pp. 3050–3065. [Google Scholar] [CrossRef]
- Lhoest, Q.; Villanova del Moral, A.; Jernite, Y.; Thakur, A.; von Platen, P.; Patil, S.; Chaumond, J.; Drame, M.; Plu, J.; Tunstall, L.; et al. Datasets: A Community Library for Natural Language Processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 175–184. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Virtual, 16–20 November 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Calcul Québec. Narval, a 5.9 Petaflops Supercomputer for Scientific Researchers in Canada. Available online: https://docs.alliancecan.ca/wiki/Narval/en (accessed on 1 August 2023).


{kind=link}
{kind=link}
{kind=link}
| Cos-E v1.0 | Cos-E v1.11 | e-SNLI | |
|---|---|---|---|
| T5 label-only | 69.4 (69.2) | 60.9 (61.8) | 91.1 (90.9) |
| T5 label + highlight | 60.6 | 51.2 | 90.1 |
| T5 label + free-text | 65.1 (64.8) | 56.8 (55.6, 59.4) | 91.0 (90.8 , 90.9) |
| human [40] | 95.3 | 88.9 | - |
| Question | Answer Choices | Model Explanation |
|---|---|---|
| Cos-E v1.0 | ||
| A great teacher can be what when you are attending school? | graduate, boredom, inspiration | inspiration is the only thing that can be done when you are attending school. |
| According to what book did an apple tree lead to the downfall of man? | woods, Spain, bible | bible is the only book that is a book |
| After he got hired he hoped for success at his what? | michigan, new job, vocation | new job is the only option that is not a vocation. |
| Aliens, humans and everything is a part of what? | outer space, universe, roswell | the universe is the only place that is a part of the universe. |
| Cos-E v1.11 | ||
| He has lactose intolerant, but was eating dinner made of cheese, what followed for him? | digestive, feel better, sleepiness, indigestion, illness | indigestion is the only answer that is not intolerant |
| If a person were going to bed, what would be their goal? | lazy, insomnia, rest, falling asleep, dreaming of | falling asleep is the only option that would help you fall asleep. |
| If you are hungry and going fishing, why would you be going fishing? | to see the fish, have fun, catching fish, wet clothes, killing | catching fish is the only option that would make you have fun. |
| If you’re remembering something, it’s because of your what of it to begin with? | knowledge, knowing, forgetful, pleasure, depression | knowing is the only thing that is remembering |
| Premise | Hypothesis | Label/ Prediction | Model Explanation |
|---|---|---|---|
| A couple walk hand in hand down a street. | The couple is married. | neutral neutral | Not all couples are married. |
| Two women are observing something together. | Two women are looking at a flower together. | neutral neutral | Not all things are a flower. |
| Two people using a water buffalo to cultivate a watery field. | A couple is farming with their pet buffalo. | entailment neutral | Not all water buffalos are pet buffalos. |
| A man playing an electric guitar on stage. | A man playing banjo on the floor. | contradiction contradiction | A banjo is not an electric guitar. |
| A little girl with pointy pigtails is sitting in the sand on the beach. | The girl is sitting on the beach. | entailment entailment | A little girl is a girl. |
| A speaker is talking with a TV in the background. | There is a live bear in the background. | neutral contradiction | A speaker is not a bear. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rancourt, F.; Vondrlik, P.; Maupomé, D.; Meurs, M.-J. Investigating Self-Rationalizing Models for Commonsense Reasoning. Stats 2023, 6, 907-919. https://doi.org/10.3390/stats6030056
Rancourt F, Vondrlik P, Maupomé D, Meurs M-J. Investigating Self-Rationalizing Models for Commonsense Reasoning. Stats. 2023; 6(3):907-919. https://doi.org/10.3390/stats6030056
Chicago/Turabian StyleRancourt, Fanny, Paula Vondrlik, Diego Maupomé, and Marie-Jean Meurs. 2023. "Investigating Self-Rationalizing Models for Commonsense Reasoning" Stats 6, no. 3: 907-919. https://doi.org/10.3390/stats6030056
APA StyleRancourt, F., Vondrlik, P., Maupomé, D., & Meurs, M.-J. (2023). Investigating Self-Rationalizing Models for Commonsense Reasoning. Stats, 6(3), 907-919. https://doi.org/10.3390/stats6030056