Abstract
Traditional encryption prioritises confidentiality but complicates search operations, requiring decryption before searches can be conducted. The public key encryption with keyword search (PEKS) scheme addresses this limitation by enabling authorised users to search for specific keywords within encrypted data without compromising the underlying encryption. This facilitates efficient and secure data retrieval without the need to decrypt the entire dataset. However, PEKS is susceptible to the keyword guessing attack (KGA), exploiting the deterministic nature of the PEKS trapdoor so that the adversary can correctly guess the keyword encrypted in a trapdoor. To enhance PEKS security to counter a KGA, various schemes have been proposed. A notable one is public key authenticated encryption with keyword search (PAEKS). PAEKS combines authentication and encryption with keyword-based search functionalities, ensuring data source authentication, encrypted information security, and keyword-based searches. However, many existing PAEKS schemes rely on computationally exhaustive bilinear pairing. In this paper, we propose a PAEKS scheme based on k-resilient identity-based encryption without bilinear pairing. By using the provable security approach, we show that our proposed PAEKS scheme satisfies both ciphertext privacy and trapdoor privacy. We present a comparison of the computation cost of our proposed PAEKS scheme with the existing PAEKS schemes and highlight its efficiency, particularly in the algorithm, where it achieves the fastest execution time. By performing experiments using the real-world Enron Email dataset, we show that the proposed scheme is efficient.
1. Introduction
Traditional encryption ensures confidentiality but complicates search operations, requiring decryption before searches can be performed. To address this limitation, Boneh et al. [1] proposed public key encryption with keyword search (PEKS), which enables secure keyword searches within encrypted data without revealing the underlying content. PEKS allows data to be encrypted using a public key while authorised users, possessing the corresponding private key, can generate trapdoors to search for specific keywords without decrypting the entire dataset. This approach enhances security and efficiency, making encrypted search more practical for real-world applications.
A common challenge in cloud storage is enabling keyword searches on encrypted documents without compromising security. Traditional encryption secures stored files but prevents efficient searching without decryption. PEKS addresses this by allowing users to search encrypted data using a trapdoor mechanism, retrieving only relevant encrypted documents without exposing their contents. This ensures both searchability and confidentiality, making it a practical solution for secure cloud storage. The keyword guessing attack (KGA) on the PEKS scheme is a vulnerability that exploits the deterministic nature of the PEKS trapdoor. This vulnerability was pointed out by Byun et al. [2] and then followed by several attacks performed on a number of PEKS schemes, showing vulnerability to the KGA [2,3,4,5]. In a KGA, adversaries repetitively guess and encrypt potential keywords; then, by observing the resulting ciphertexts, the attackers can analyse and compare these encrypted keywords to glean patterns or similarities, enabling them to deduce potential matches between the ciphertext and the trapdoor. This attack compromises the security of PEKS by potentially revealing matches between guessed keywords and the trapdoor, potentially leading to unauthorised access to sensitive information.
Several related schemes have been proposed in the literature to enhance the security of PEKS and counter the KGA attack. One significant scheme is the public key authenticated encryption with keyword search (PAEKS) introduced by Huang and Li [6]. It is designed to provide both authentication and encryption capabilities alongside keyword-based search functionalities. PAEKS allows users to authenticate the data source, encrypt the information, and perform searches based on keywords, ensuring both the confidentiality and integrity of the data. The advantage of PAEKS lies in its ability to combine authenticated encryption with a keyword search, providing a more robust and secure approach compared to traditional PEKS. Up to now, many PAEKS schemes have been proposed [7,8,9,10], but most of the schemes are based on bilinear pairing, which is known for its computation exhaustive.
Although some pairing-free PEKS and PAEKS schemes have been proposed, most of them still rely on the random oracle model for security proofs or fail to achieve resistance against KGAs. These limitations are particularly significant in settings that require long-term cryptographic assurance and complex query expressiveness. Our work addresses this gap by proposing a pairing-free PAEKS scheme in the standard model that achieves resistance against KGAs without relying on bilinear pairings.
In this paper, we focus on constructing a k-resilient PAEKS scheme without bilinear pairing based on the k-resilient PEKS scheme of [5], which was developed from Heng and Kurosawa’s k-resilient IBE scheme [11]. We follow the rigorous security analysis and show that our proposed PAEKS scheme satisfies ciphertext privacy and trapdoor privacy (i.e., indistinguishability under keyword guessing attack, IND-KGA), ensuring resistance to the KGA. Subsequently, we conduct a performance evaluation of our proposed PAEKS scheme with other related PAEKS schemes. Here, k-resilience refers to a bounded collusion model in which the scheme remains secure even if an adversary compromises up to k users (either senders or receivers) by obtaining their private keys, i.e., the security of ciphertexts and trapdoors generated under the public keys of uncorrupted users is still preserved. This notion of bounded collusion resistance, first formalised by Heng and Kurosawa [11], enables efficient pairing-free constructions that are well-suited for applications such as group communication and closed membership systems. Building on this foundation, we view k-resilience not as a stronger security guarantee but as a deliberate design trade-off that enables lightweight, pairing-free constructions tailored to constrained settings such as fixed-membership communication groups or distributed systems with limited resources.
2. Problem Statement and Technical Overview
2.1. Problem Statement
PEKS allows users to search encrypted data without decrypting them, but traditional PEKS schemes are vulnerable to KGAs and often rely on computationally expensive bilinear pairings. Moreover, many existing schemes operate under the random oracle model, which assumes idealised cryptographic behaviour and lacks real-world guarantees. To address these limitations, this paper considers the following problem:
Can we construct a pairing-free PAEKS scheme that is secure under the standard model and resistant against keyword guessing attacks?
This problem is significant for real-world applications, such as encrypted cloud storage and secure messaging, where both searchability and strong security guarantees are essential.
2.2. Technical Overview
Our proposed scheme builds upon the k-resilient PEKS framework introduced by Yau et al. [5], which in turn is based on the k-resilient IBE scheme by Heng and Kurosawa [11]. We extend this framework to a PAEKS setting by incorporating sender authentication.
Key features of our approach include the following:
- A polynomial-based key generation mechanism that enables k-resilience, meaning the scheme remains secure as long as the adversary corrupts at most k users (either senders or receivers) and obtains their full private keys. The scheme guarantees keyword privacy and trapdoor privacy for all honest users whose keys remain uncompromised.
- Pairing-free operations using standard elliptic curve groups, improving efficiency over traditional PAEKS schemes that use bilinear maps.
- A search functionality that remains constant in time with respect to the resilience parameter k, enhancing scalability.
The scheme is proven secure under the Decisional Diffie–Hellman (DDH) assumption in the standard model, achieving both ciphertext and trapdoor privacy (IND-CKA and IND-KGA security). While the security model adopts a bounded collusion assumption (i.e., k-resilience), the use of standard assumptions without random oracles ensures strong cryptographic guarantees within that setting.
3. Related Work
Boneh et al. [1] proposed the first pairing-based PEKS scheme in 2004. Abdalla et al. [12] further improved the definition of the PEKS scheme and presented a transformation framework such that any anonymous IBE scheme can be transformed into a secure PEKS scheme. Boneh et al.’s PEKS scheme required a secure channel to transmit the trapdoor during communication, as the keyword encrypted in the trapdoor can be easily guessed by knowing the corresponding public key. Baek et al. [13] solved this problem by constructing a new PEKS scheme called secure channel-free public key encryption with keyword search (SCF-PEKS) to eliminate the need for using a secure channel during communication by using two sets (server’s and receiver’s) of key pairs. Later, Byun et al. [2] presented an offline KGA on the PEKS scheme and demonstrated that Boneh et al.’s scheme [1] is vulnerable to the KGA. Yau et al. [4] also presented two offline KGA attacks on Baek et al.’s SCF-PEKS scheme [13] and the PKE/PEKS scheme [13]. In 2010, Rhee et al. [14] introduced trapdoor indistinguishability and demonstrated its effectiveness against KGAs. Following the work of Rhee et al. [14], it is obvious that a PEKS scheme must satisfy both ciphertext privacy and trapdoor privacy to be secure against a KGA.
An effective method to prevent KGAs is by resorting to the PAEKS scheme introduced earlier. A PAEKS scheme uses two sets of key pairs, but unlike the SCF-PEKS scheme, the PAEKS scheme ciphertext requires a sender’s private key and a receiver’s public key to generate and vice versa for the trapdoor. It is for this reason that the PAEKS scheme was able to prevent KGAs, even from malicious servers. Li et al. [15] proposed a designated-server identity-based PAEKS scheme that integrated the designated identity-based PEKS scheme with a PAEKS scheme. Noroozi and Eslami [9] noted that Huang and Li’s PAEKS scheme [6] was insecure against KGAs in a multi-user setting, and they have also proposed an improvement to the scheme that fixed the issue. Qin et al. [10] also noted that Huang and Li’s PAEKS scheme [6] was vulnerable to multi-ciphertext attack. They proposed a first scheme in order to fix the vulnerability, followed by a second scheme that simplifies the management of the data sender’s public key. Lu and Li [7] proposed the designated PAEKS scheme without bilinear pairing, which is like the integration of the SCF-PEKS scheme and the PAEKS scheme. Instead of using only the sender’s and the receiver’s key pairs, it also requires an additional server’s key pair. This limits their algorithm to run on the designated server only. Huang et al. [16] proposed a more efficient PAEKS scheme using bilinear pairing. They incorporated ciphertext deduplication and inverted index to lower the storage cost and accelerate the searching process. Pu et al. [17] proposed a PAEKS scheme that was suitable for industrial IoT devices, because it only requires one bilinear pairing operation in the testing algorithm. Bai et al. [18] also proposed a designated PAEKS scheme, and their proposed scheme was found to be more efficient than Lu and Li’s designated PAEKS scheme [7].
To improve the search functionality of the PEKS scheme, Park et al. [19] proposed public key encryption with conjunctive keyword search (PECKS). The PECKS scheme extends the PEKS scheme to allow searching on multiple keywords. The user can search for documents that include all specified keywords, similar to an AND operation. Hwang et al. [20] proposed a more efficient PECKS scheme than Park et al.’s scheme [19] by achieving a shorter ciphertext size. Chen and Horng [21] proposed a timestamp-based PECKS scheme that provides a secure communication between the sender and receiver. Chen et al. [22] proposed two PECKS schemes based on bilinear pairing with a constant ciphertext size and short trapdoor size. The first scheme was in the composite-order groups model, and the second scheme was in the prime-order groups model. Farràs and Ribes-González [23] proposed a PECKS scheme based on bilinear pairing. Their proposed scheme has a better efficiency compared to Park et al.’s scheme [19] and Hwang et al.’s scheme [20]. All the keyword indexes of the PECKS schemes discussed earlier are forward indexes, which will lead to slower searches when the number of keywords is greater. To improve the search efficiency, Zhang et al. [24] proposed a pairing-based tree index keyword structure PECKS scheme. Their proposed scheme enhanced the search efficiency and provided better adaptation to other complex search functionalities like Boolean search and range search. All these PECKS schemes are pairing-based.
4. Preliminaries
4.1. Lagrange Interpolation
Let q be a prime and a polynomial of degree k over . Let be distinct elements in , and we are given the values . Using Lagrange interpolation, we can construct the polynomial as
where the Lagrange coefficient is defined as
4.2. Decisional Diffie–Hellman Assumption
The Decisional Diffie–Hellman (DDH) assumption is defined as follows:
Given g, , , and ∈ , there is no adversary who can differentiate between and . We say that the DDH assumption holds if there is no probabilistic polynomial-time t algorithm A that has the advantage in solving the DDH problem in .
4.3. PAEKS Scheme
A PAEKS scheme consists of the following six algorithms:
- Setup (): This algorithm takes in security parameter to generate the common parameter that is required for the scheme.
- SenderKeyGen (): This algorithm takes in the common parameter to generate a set consisting of a public key and private key for the sender (data owner).
- ReceiverKeyGen (): This algorithm takes in the common parameter to generate a set consisting of a public key and private key for the receiver (data user).
- PAEKS : This algorithm takes in the common parameter , a keyword w, the sender’s private key , and the receiver’s public key to generate a searchable ciphertext of the keyword .
- Trapdoor : This algorithm takes in the common parameter , a keyword w, the sender’s public key , and the receiver’s private key to generate a trapdoor of the keyword .
- Test : This algorithm is run by the server. It takes in a searchable ciphertext and a trapdoor to perform the matching operation. If the searchable ciphertext matches with the trapdoor, it will output 1; if otherwise, it will output 0.
4.4. Security Models for PAEKS Scheme
We formally define two separate security notions: IND-CKA for ciphertext privacy and IND-KGA for trapdoor privacy.
4.4.1. Indistinguishability Under Chosen Keyword Attack (IND-CKA)/Ciphertext Privacy
We refer to the IND-CKA security notion as ciphertext privacy throughout this paper. This term reflects the idea that a secure scheme should prevent an adversary from learning any information about the queried keyword from the ciphertext. This model is defined by the following game between an adversary A and a challenger B.
Setup: The challenger B inputs the security parameter to the Setup algorithm to compute the common parameter . Then, it runs the SenderKeyGen and ReceiverKeyGen algorithms to generate the key pairs . In the end of this phase, B transfers to the adversary A.
Phase 1: In this phase, the adversary A can adaptively query the Ciphertext Oracle , Trapdoor Oracle , and Expose Oracle .
- Ciphertext Oracle : This oracle takes a keyword w as input and outputs the ciphertext by running the PAEKS algorithm. Finally, it returns the ciphertext to A.
- Trapdoor Oracle : This oracle takes a keyword w as input and outputs the trapdoor by running the Trapdoor algorithm. Finally, it returns the trapdoor to A.
- Exposure Oracle : The adversary may query this oracle with a public key (either sender or receiver). The challenger responds with the corresponding private key and records in a corruption set . The adversary may make at most k such queries. The public keys involved in the challenge must not be queried.
Challenge: The adversary selects two keywords as the challenge keywords. The only restriction is that the challenge keywords should not have been queried for the ciphertext and trapdoor previously, and the adversary must not have exposed the sender and receiver used in the challenge ciphertext. The challenger randomly chooses a bit and returns a value to the adversary A.
Phase 2: In this phase, the adversary can continue to adaptively query the Ciphertext Oracle and Trapdoor Oracle for any keyword , and may also query the Exposure Oracle for any user not involved in the challenge, as long as the total number of exposed users does not exceed k.
Guess: The adversary outputs a guess bit . If , it wins the game.
We say that a PAEKS scheme possesses keyword privacy, meaning it achieves indistinguishability against a chosen keyword attack if any polynomial-time adversary A has only a negligible advantage in the IND-CKA game, where
4.4.2. Indistinguishability Under Keyword Guessing Attack (IND-KGA)/Trapdoor Privacy
We refer to the IND-KGA security notion as trapdoor privacy throughout this paper. This term reflects the idea that a secure scheme should prevent an adversary from learning any information about the queried keyword from the trapdoor. This model is defined by the following game between an adversary A and a challenger B.
Setup: The challenger B inputs the security parameter to the Setup algorithm to compute the common parameter . Then, it runs the SenderKeyGen and ReciverKeyGen algorithms to generate the key pairs . In the end of this phase, B transfers to the adversary A.
Phase 1: In this phase, the adversary A can adaptively query the Ciphertext Oracle , Trapdoor Oracle , and Expose Oracle .
Challenge: The adversary selects two keywords as the challenge keywords. The only restriction is that the adversary cannot ask for the ciphertext of the challenge keywords and , and the adversary must not have exposed the sender and receiver used in the challenge ciphertext. The challenger randomly chooses a bit and returns the to the adversary A.
Phase 2: In this phase, the adversary can continue to adaptively query the Ciphertext Oracle and Trapdoor Oracle for any keyword , and may also query the Exposure Oracle for any user not involved in the challenge, as long as the total number of exposed users does not exceed k.
Guess: The adversary outputs a guess bit . If , it wins the game.
We say that a PAEKS scheme possesses trapdoor privacy, meaning it achieves indistinguishability against a keyword guessing attack if any polynomial-time adversary A has only a negligible advantage in the IND-KGA game, where
5. Proposed KR-PAEKS Scheme
Heng and Kurosawa [11] proposed the k-resilient IBE scheme in the standard model. It is well known that any anonymous IBE scheme can be transformed into a PEKS scheme following the transformation technique proposed by Abdalla et al. [12]. Using Heng and Kurosawa’s scheme and Abdalla et al.’s transformation technique, Khader [25] proposed the k-resilient PEKS scheme. Khader’s scheme [25] was later improved by Yau et al. [26]. They improved Khader’s scheme [25] efficiency by removing and simplifying some unnecessary and complex steps in the scheme construction. However, the proposed k-resilient PEKS scheme is still vulnerable to KGAs, as it does not possess trapdoor privacy. We thus propose the KR-PAEKS scheme to possess both keyword privacy and trapdoor privacy based on Yau et al.’s [26] scheme. Our scheme achieves k-resilience in the sense that it remains secure as long as the adversary compromises no more than k users (senders or receivers). That is, even if the adversary obtains the private keys of up to k users, the confidentiality of ciphertexts and trapdoors related to honest users remains protected. We emphasise that this is a weaker security model compared to standard PEKS or IBE constructions, where full collusion resistance is typically guaranteed via independent key generation. However, this design relaxation is intentional and allows us to construct a more efficient pairing-free scheme using polynomial-based key generation. In scenarios where the user set is fixed or the environment imposes performance constraints, this model enables a fast and scalable keyword search while retaining sufficient security.
In this section, we present our proposed k-resilient PAEKS scheme, which instantiates the generic PAEKS framework defined in Section 4.3. Specifically, our construction implements the generic algorithms as follows: .
We formally define the KR-PAEKS scheme as a tuple of six algorithms: . Each algorithm is defined as follows:
- : Takes the security parameter and a resilience threshold k and outputs the common parameter .
- : Outputs the sender’s public and private keys.
- : Outputs the receiver’s public and private keys.
- : Encrypts keyword w using the sender’s private key and receiver’s public key and outputs a searchable ciphertext C.
- : Generates a trapdoor for keyword w using the receiver’s private key and the sender’s public key.
- : Returns 1 if the ciphertext matches the trapdoor; otherwise, returns 0.
We now describe the concrete construction of each algorithm in detail.
KR-Setup: Choose a group of order q and a generator . Choose a random and compute . Set the common parameter .
KR-SenderKeyGen: Choose two random k-degree polynomials over :
Then, compute , for . Set the private key and the public key .
KR-ReceiverKeyGen: Choose two random k-degree polynomials over :
Then, compute , for . Set the private key and the public key .
KR-PAEKS: Choose a random . For a chosen keyword w, compute
and
Lastly, output the searchable ciphertext .
KR-Trapdoor: Choose a random . For a chosen keyword w, compute
and
Lastly, output the trapdoor .
KR-Test: Upon receiving a trapdoor , the server will test for a matching searchable ciphertext C by performing . It will output “1” if the result matches and output “0” if otherwise. The correctness of the equation is as follows:
6. Security Analysis
This section presents the security proofs for our proposed k-resilient PAEKS scheme. We prove that the scheme satisfies IND-CKA security and IND-KGA security, corresponding to ciphertext privacy and trapdoor privacy, respectively, as defined in Section 4.4. Specifically, we show that (i) the keyword ciphertext is indistinguishable under chosen keyword attacks (Section 4.4.1), and (ii) the trapdoor does not leak keyword information under keyword guessing attacks (Section 4.4.2). Both security notions are achieved under the DDH assumption in the standard model.
Each proof was structured as a reduction from the DDH problem. That is, we constructed a simulator that uses any adversary capable of breaking the scheme’s security to solve the DDH challenge with non-negligible probability. We followed the standard security reduction technique, where the adversary interacts with oracles simulating the scheme under a challenge, and the simulator carefully embeds the DDH instance into these simulations.
In the context of these proofs, we use to denote the adversary’s advantage in breaking the respective security game (e.g., IND-CKA or IND-KGA). Specifically, is the probability with which a polynomial-time adversary can correctly guess the encrypted keyword (or trapdoor keyword) during the challenge phase beyond random guessing. This advantage is directly used to quantify the probability of solving the DDH problem through the reduction.
Theorem 1.
The proposed KR-PAEKS scheme achieves ciphertext indistinguishability against IND-CKA if the DDH assumption holds.
Proof.
Suppose there exists an adversary A who can -break the KR-PAEKS scheme in the IND-CKA security model; then, we can construct a simulator B to solve the DDH problem. Given as input a problem instance over the cyclic group , B runs A and works as follows.
Setup: B sets the common parameter . Then, it runs the and algorithms to generate the key pairs . In the end of this phase, B transfers to the adversary A.
Phase 1: In this phase, the adversary A can adaptively query the Ciphertext Oracle , Trapdoor Oracle , and Exposure Oracle .
Challenge: The adversary selects two keywords as the challenge keywords. The only restriction is that the challenge keywords should not have been queried for the ciphertext and trapdoor previously, and the adversary must not have exposed the sender and receiver used in the challenge ciphertext. B randomly chooses a bit and returns a value to the adversary A as
where and Z are from the problem instance. Let . If , we have
Therefore, is a correct challenge ciphertext whose encrypted keyword is .
Phase 2: In this phase, the adversary can continue to adaptively query the Ciphertext Oracle and Trapdoor Oracle for any keyword , and may also query the Exposure Oracle for any user not involved in the challenge, as long as the total number of exposed users does not exceed k.
Guess: The adversary outputs a guess bit . The simulation outputs 1 if ; otherwise, it outputs 0.
Since the adversary is allowed to expose up to k users via the oracle, the simulator responds to all such queries by revealing the corresponding private keys, as long as the corrupted users do not include those involved in the challenge. All ciphertext and trapdoor queries involving corrupted users are simulated honestly using their known keys. For the challenge ciphertext, the simulator embeds the DDH challenge tuple using the honest (non-corrupted) keys.
Therefore, the adversary’s view is indistinguishable from a real execution, unless it can distinguish the DDH tuple. Hence, the simulator can solve the DDH instance with non-negligible probability if the adversary succeeds in the IND-CKA game. The correctness is analysed as follows.
The probability of breaking the challenge ciphertext is defined as follows:
- If , the simulation is indistinguishable from the real attack, and thus, the adversary has a probability of in guessing the encrypted message correctly.
- If Z is random, the challenge ciphertext is a one-time pad from the adversary’s viewpoint. Therefore, the adversary only has a probability of in guessing the encrypted keyword correctly.
Advantage and time cost. The advantage of solving the DDH problem is
as required in time t. This completes the proof of Theorem 1. □
Theorem 2.
The proposed KR-PAEKS scheme achieves trapdoor indistinguishability against IND-KGA if the DDH assumption holds.
Proof.
Suppose there exists an adversary A who can -break the KR-PAEKS scheme in the IND-KGA security model; then, we can construct a simulator B to solve the DDH problem. Given as input a problem instance over the cyclic group , B runs A and works as follows.
Setup: B runs the Setup algorithm to compute the common parameter , . Then, it runs the SenderKeyGen and ReceiverKeyGen algorithms to generate the key pairs . In the end of this phase, B transfers to the adversary A.
Phase 1: In this phase, the adversary A can adaptively query the Ciphertext Oracle , Trapdoor Oracle , and Exposure Oracle .
Challenge: The adversary selects two keywords as the challenge keywords. The only restriction is that the adversary cannot ask for the ciphertext of the challenge keywords and , and the adversary must not have exposed the sender and receiver used in the challenge ciphertext. The challenger randomly chooses a bit and returns a value to the adversary A as
where and Z are from the problem instance. Let . If , we have
Therefore, is a correct challenge trapdoor whose encrypted keyword is .
Phase 2: In this phase, the adversary can continue to adaptively query the Ciphertext Oracle and Trapdoor Oracle for any keyword , and may also query the Exposure Oracle for any user not involved in the challenge, as long as the total number of exposed users does not exceed k.
Guess: The adversary outputs a guess bit . The simulation outputs 1 if ; otherwise, it outputs 0.
Throughout the game, the adversary may adaptively expose up to k users via the oracle. The simulator answers these queries faithfully, as long as the exposed users do not include those involved in generating the challenge trapdoor. Trapdoor queries for corrupted users are computed using their private keys, which are known to the simulator. For the honest challenge user, the trapdoor is generated using the DDH instance embedded into the public parameters.
As the adversary’s view in the simulated game is computationally indistinguishable from a real execution unless it can solve the DDH problem, the simulator succeeds with the same advantage as the adversary in the IND-KGA game. The correctness is analysed as follows.
The probability of breaking the challenge ciphertext is defined as follows:
- If , the simulation is indistinguishable from the real attack, and thus, the adversary has a probability of in guessing the encrypted message correctly.
- If Z is random, the challenge ciphertext is a one-time pad from the adversary’s viewpoint. Therefore, the adversary only has a probability of in guessing the encrypted keyword correctly.
Advantage and time cost. The advantage of solving the DDH problem is
as required in time t. This completes the proof of Theorem 2. □
7. Performance Evaluation
Table 1 defines the list of notations used in the performance evaluation. Table 2 shows the comparison analysis of our PAEKS scheme with some existing schemes in terms of the computation cost. We only considered the cost of the algorithm, algorithm, and the algorithm. We did not consider and algorithms in the comparison, as they were executed only once.

Table 1.
Notations in the performance evaluation.
While our scheme incurred slightly higher computational cost compared to schemes built in the random oracle model, this reflects a deliberate trade-off in favour of stronger, more realistic security. Security proofs in the standard model are generally regarded as more robust, as they avoid idealised assumptions such as modelling hash functions as random oracles. Bellare and Rogaway [27] first proposed the random oracle model as a heuristic tool for designing efficient protocols, but later works [28] demonstrated that a scheme proven secure in the random oracle model may become insecure when any real-world hash function replaces the ideal oracle, indicating that security in the random oracle model does not carry over to the standard model in general. As such, constructions with standard model security, like ours, are preferred for applications where provable, real-world security guarantees are critical.
To perform a conservative comparison, although our scheme can be initialised with more efficient non-pairing curves such as Edwards 25519 (which uses a 255-bit modulus), we assumed a pairing curve such as BLS12-381 (which uses a 381-bit modulus). Subsequently, for clarity purposes, we set the complexity unit as the relative computation costs in equivalents of scalar multiplication in under the BLS12-381 curve, which provides approximately 128-bit security. For a multiplication in , it is about the same as computing 2-scalar multiplication M, an exponentiation in is about the same as computing 6-scalar multiplication M, and for a pairing, it is about the same as computing 9-scalar multiplication M [29]. The hash operation and the operation in are typically not as significant compared to the operations in , because they involve less computations.
From Table 2, it is evident that Pu et al.’s scheme [17] still has the advantage in the computation cost for the algorithm and the algorithm. However, a notable strength of our proposed scheme is in the algorithm, where our scheme only required 4M as compared to Pu et al.’s 9M. Nevertheless, it is imperative to acknowledge that Pu et al.’s scheme holds a natural efficiency advantage over our proposed scheme due to their security model being in the random oracle model, whereas our proposed scheme is in the standard model.
Table 2.
Comparison analysis of computation cost [30].
Table 2.
Comparison analysis of computation cost [30].
| Scheme | Computation Cost | Security Model | Pairing-Free | ||
|---|---|---|---|---|---|
| Encryption | Trapdoor | Test | |||
| Huang and Li (2017) [6] | Random Oracle | X | |||
| Noroozi and Eslami (2019) [9] | Random Oracle | X | |||
| Qin et al. (2020) 1 [10] | Random Oracle | X | |||
| Qin et al. (2020) 2 [10] | Random Oracle | X | |||
| Huang et al. (2023) [16] | Random Oracle | X | |||
| Pu et al. (2023) [17] | M | Random Oracle | X | ||
| Wu and Shi (2025) [31] | Random Oracle | ✓ | |||
| Ours | Standard | ✓ | |||
Note: Qin et al. (2020) [10] proposed two different schemes. We denote them as Qin et al. (2020) 1 and Qin et al. (2020) 2 for distinction.
To complement the theoretical analysis in Table 2, we conducted an empirical comparison with several representative PAEKS schemes: the classic pairing-based scheme by Huang and Li [6], the recent pairing-based construction by Pu et al. [17], and the pairing-free scheme by Wu and Shi [31]. While many recent works incorporated attribute-based encryption, policy enforcement, or extended search models, we selected these three schemes for comparison due to their well-specified designs and comparable core functionality. This allowed us to isolate the performance implications of pairing-based versus pairing-free constructions and to assess the runtime trade-offs in practical keyword search settings.
To this end, we implemented our pairing-free KR-PAEKS scheme and the three schemes in Rust. Huang and Li’s [6] and Pu et al.’s [17] schemes were instantiated using the BLS12-381 pairing-friendly curve, while our KR-PAEKS and Wu and Shi’s [31] schemes used the Edwards 25519 curve for group operations. All implementations were benchmarked under consistent environments with native cryptographic libraries to ensure fair comparison. As shown in Figure 1, we focused the comparison on the and algorithms, which are invoked frequently during searches, whereas is performed only once per document. We also report the combined time to show the overall performance and breakeven points.
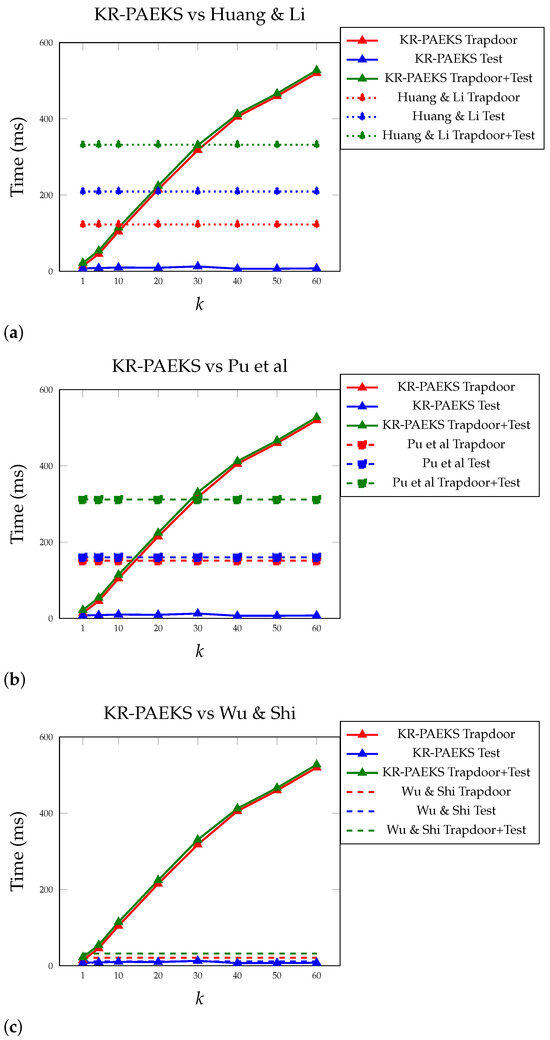
Figure 1.
Split comparison of KR-PAEKS with (a) Huang & Li [6], (b) Pu et al. [17], and (c) Wu & Shi [31] for varying values of k.
Our KR-PAEKS scheme achieved significantly faster times across all schemes. For instance, at , our scheme achieved 10.02 ms for compared to 209.32 ms in Huang and Li’s [6], 160.23 ms in Pu et al.’s [17], and 11.14 ms in Wu and Shi’s [31], with more than 20×, 16×, and comparable improvement, respectively. While Wu and Shi’s pairing-free design also benefits from low test-time cost and preserves keyword privacy under the computational Diffie–Hellman (CDH) assumption, it performs the operation using the server’s private key. As a result, the correctness of the match result depends on trusting the server to execute the test faithfully. In contrast, our KR-PAEKS test procedure does not rely on any secret key material at the server side and can be verified using only public parameters, offering better deployment suitability in untrusted or outsourced environments where server-side correctness cannot be guaranteed.
In terms of combined runtime, KR-PAEKS outperformed the pairing-based schemes at . At this point, the total time in KR-PAEKS was 330.48 ms, close to Pu et al.’s [17] constant 311.67 ms and surpassing Huang and Li’s [6] 332.01 ms result. As k increased further, the performance gap became more pronounced: at , our scheme required 527.39 ms in total, while Pu et al. and Huang and Li remained fixed at 311.67 ms and 332.01 ms, respectively. Although our trapdoor runtime increases with k due to its polynomial structure, the consistently low test-time enables scalable query performance in receiver-dominated workflows.
Crucially, the algorithm in KR-PAEKS maintained a nearly constant time regardless of k, making it well suited for lightweight clients such as edge devices or resource-constrained IoT nodes. This design aligns with hybrid computing models where the trapdoor is generated by a capable sender or backend, while the receiver (e.g., a light node) only needs to perform a fast verification. This separation of roles supports real-time keyword filtering while preserving strong security, minimal trust assumptions, and flexible deployment across heterogeneous environments.
To further improve the efficiency of our scheme, we applied the well-known multiple exponentiation algorithm [32], specifically the simultaneous square-and-multiply method, to both the and algorithms. Here, denote the costs of a group multiplication, group exponentiation, modular multiplication, and modular inversion, respectively. Using this technique, which cleverly combines several exponentiations into fewer overall operations, the computation cost can be reduced to approximately
This shows a significant reduction compared to executing all exponentiations and multiplications naively, resulting in about a 25% decrease in costs for exponentiation and multiplication based on the value of k.
Experiment with Enron Email Dataset
In this section, we evaluate the performance of the proposed KR-PAEKS schemes using the real-world Enron Email dataset [33]. This dataset comprises communications from approximately 150 users and is widely used in machine learning, natural language processing, and social network analysis research. It contains around 500,000 messages, including duplicates, and is considered one of the most extensive and valuable publicly available email corpora. Our experiments were conducted on a Windows 11 Home 22H2 machine with an Intel Core i5-1135G7 CPU (2.4 GHz)—implemented in Rust using the MIRACL Core Library with the Edwards 25519 curve for elliptic curve computations.
To provide a clear and controlled evaluation, we focused on a single user, John Arnold. We analysed 3852 emails from this user and identified the three most frequently occurring keywords: “forwarded”, “hey”, and “please”. These keywords were used in our performance tests, with “forwarded” selected as the representative keyword for evaluating the KR-PAEKS scheme. Among the analysed emails, 662 contained the keyword “forwarded”.
We acknowledge that email content and keyword frequency distributions vary significantly across users. While this single-user analysis provides valuable insight into the baseline performance of our schemes, it may not capture all user behaviours present in the dataset. As such, future work will include experiments involving a broader set of users from the Enron corpus to assess performance consistency across varying usage patterns and keyword diversity.
Note that our PAEKS scheme is based on the k-resilient IBE scheme [11]. The value of k represents the maximum number of a user’s secret keys that can be compromised without affecting overall system security. As shown in Figure 2, our KR-PAEKS scheme exhibits consistent performance trends aligned with its design.
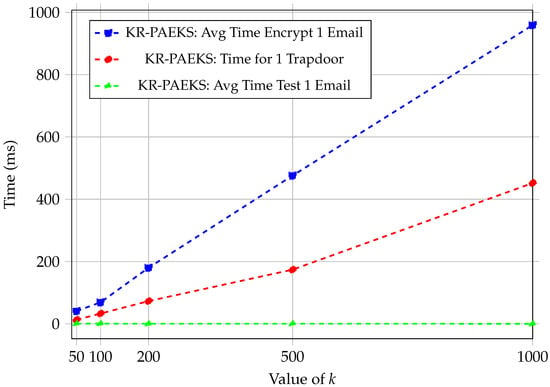
Figure 2.
Performance comparison of KR-PAEKS with Enron Email dataset.
Specifically, for the algorithm, which is critical to search efficiency, the average execution time across varying values of k (from 50 to 1000) remained approximately constant. For example, KR-PAEKS showed test times ranging from 0.11 ms to 0.77 ms. These fluctuations were minimal and did not increase with k, confirming the algorithm’s constant-time behaviour.
In contrast, the and algorithms displayed a clear linear scaling pattern. For KR-PAEKS, the encryption time increased from 41 ms at to 959 ms at , and the trapdoor generation grew from 13 ms to 452 ms. These trends are expected due to the polynomial-based key structures used in our scheme, where encryption and trapdoor operations depend linearly on the number of polynomial coefficients tied to the resilience parameter k.
These quantitative results support our claim that the proposed schemes are practically efficient. The constant-time search operation ensures scalability for large encrypted databases, while the linearly scaling components remain within acceptable limits even for . This makes our KR-PAEKS construction suitable for deployment in real-world encrypted search scenarios.
While our current evaluation is based on single-run measurements, we acknowledge the importance of statistical validation in performance analysis. Future work will include repeated experiments with appropriate statistical metrics to rigorously assess the consistency and significance of the observed performance trends. Additionally, although our scheme’s algorithm operates independently of keyword frequency due to its construction, we recognise that keyword distribution imbalances may affect efficiency in extended applications involving indexing or ranked retrieval. Investigating how to adapt our scheme to such use cases, without compromising security, remains an important direction for future research.
8. Conclusions
The PEKS scheme addresses the limitations of traditional encryption by enabling secure and efficient keyword-based searches within encrypted data. However, its vulnerability to KGAs has led to the development of more robust alternatives, such as the PAEKS scheme. In this work, we propose a k-resilient PAEKS scheme without bilinear pairing, which achieves security under the standard model, a stronger and more realistic cryptographic setting than the random oracle model. Through rigorous proofs, we have demonstrated that our scheme satisfies both keyword privacy and trapdoor privacy, making it resilient to KGA.
Our comparative performance evaluation showed that while the proposed scheme may be less efficient in the and algorithms compared to random oracle-based constructions, it achieves superior security guarantees without relying on idealised assumptions. The efficiency of our algorithm remains constant, and our experimental results on the Enron Email dataset confirm that the scheme remains practical even as the resilience parameter k increases. This balance between provable security and practical efficiency makes our scheme well suited for secure encrypted search in real-world applications.
Compared to many existing bilinear pairing-based PAEKS schemes, our approach avoids pairing operations, which leads to improved runtime performance in practice. While the scheme adopts a k-resilient security model that assumes a bounded number of user corruptions, it still provides ciphertext and trapdoor privacy under standard assumptions without relying on random oracles. This combination of efficiency and provable security makes the scheme suitable for deployment in constrained or semi-trusted environments. As part of future work, we plan to extend the scheme to support more expressive search functionalities such as conjunctive and Boolean keyword search, range queries, as well as ranked retrieval, while preserving both efficiency and security guarantees.
Author Contributions
Conceptualisation, K.-M.C., S.-H.H. and S.-Y.T.; formal analysis, S.-H.H., S.-Y.T. and S.-C.T.; funding acquisition, S.-H.H.; investigation, K.-M.C. and S.-Y.T.; methodology, K.-M.C. and S.-Y.T.; validation, S.-H.H., S.-Y.T. and S.-C.T.; writing—original draft preparation, K.-M.C.; writing—review and editing, S.-H.H., S.-Y.T. and S.-C.T.; supervision, S.-H.H. and S.-Y.T.; project administration, S.-H.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Telekom Malaysia Research & Development Grant (RDTC/221045).
Data Availability Statement
The original contributions presented in this study are included in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Boneh, D.; Di Crescenzo, G.; Ostrovsky, R.; Persiano, G. Public key encryption with keyword search. In Proceedings of the Advances in Cryptology-EUROCRYPT 2004: International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; Springer: Berlin/Heidelberg, Germany, 2004. Proceedings 23. pp. 506–522. [Google Scholar]
- Byun, J.W.; Rhee, H.S.; Park, H.A.; Lee, D.H. Off-line keyword guessing attacks on recent keyword search schemes over encrypted data. In Proceedings of the Workshop on Secure Data Management; Springer: Berlin/Heidelberg, Germany, 2006; pp. 75–83. [Google Scholar]
- Lu, Y.; Wang, G.; Li, J. Keyword guessing attacks on a public key encryption with keyword search scheme without random oracle and its improvement. Inf. Sci. 2019, 479, 270–276. [Google Scholar] [CrossRef]
- Yau, W.C.; Heng, S.H.; Goi, B.M. Off-line keyword guessing attacks on recent public key encryption with keyword search schemes. In Proceedings of the Autonomic and Trusted Computing: 5th International Conference, ATC 2008, Oslo, Norway, 23–25 June 2008; Springer: Berlin/Heidelberg, Germany, 2008. Proceedings 5. pp. 100–105. [Google Scholar]
- Yau, W.C.; Phan, R.C.W.; Heng, S.H.; Goi, B.M. Keyword guessing attacks on secure searchable public key encryption schemes with a designated tester. Int. J. Comput. Math. 2013, 90, 2581–2587. [Google Scholar] [CrossRef]
- Huang, Q.; Li, H. An efficient public-key searchable encryption scheme secure against inside keyword guessing attacks. Inf. Sci. 2017, 403, 1–14. [Google Scholar] [CrossRef]
- Lu, Y.; Li, J. Lightweight public key authenticated encryption with keyword search against adaptively-chosen-targets adversaries for mobile devices. IEEE Trans. Mob. Comput. 2022, 21, 4397–4409. [Google Scholar] [CrossRef]
- Ma, Y.; Kazemian, H. Public key authenticated encryption with multiple keywords search using Mamdani system. Evol. Syst. 2021, 12, 687–699. [Google Scholar] [CrossRef]
- Noroozi, M.; Eslami, Z. Public key authenticated encryption with keyword search: Revisited. IET Inf. Secur. 2019, 13, 336–342. [Google Scholar] [CrossRef]
- Qin, B.; Chen, Y.; Huang, Q.; Liu, X.; Zheng, D. Public-key authenticated encryption with keyword search revisited: Security model and constructions. Inf. Sci. 2020, 516, 515–528. [Google Scholar] [CrossRef]
- Heng, S.H.; Kurosawa, K. k-Resilient identity-based encryption in the standard model. In Proceedings of the Topics in Cryptology–CT-RSA 2004: The Cryptographers’ Track at the RSA Conference 2004, San Francisco, CA, USA, 23–27 February 2004; Springer: Berlin/Heidelberg, Germany, 2004. Proceedings. pp. 67–80. [Google Scholar]
- Abdalla, M.; Bellare, M.; Catalano, D.; Kiltz, E.; Kohno, T.; Lange, T.; Malone-Lee, J.; Neven, G.; Paillier, P.; Shi, H. Searchable encryption revisited: Consistency properties, relation to anonymous IBE, and extensions. In Proceedings of the Advances in Cryptology–CRYPTO 2005: 25th Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2005; Springer: Berlin/Heidelberg, Germany, 2005. Proceedings 25. pp. 205–222. [Google Scholar]
- Baek, J.; Safavi-Naini, R.; Susilo, W. Public key encryption with keyword search revisited. In Proceedings of the Computational Science and Its Applications–ICCSA 2008: International Conference, Perugia, Italy, 30 June–3 July 2008; Springer: Berlin/Heidelberg, Germany, 2008. Proceedings, Part I 8. pp. 1249–1259. [Google Scholar]
- Rhee, H.S.; Park, J.H.; Susilo, W.; Lee, D.H. Trapdoor security in a searchable public-key encryption scheme with a designated tester. J. Syst. Softw. 2010, 83, 763–771. [Google Scholar] [CrossRef]
- Li, H.; Huang, Q.; Shen, J.; Yang, G.; Susilo, W. Designated-server identity-based authenticated encryption with keyword search for encrypted emails. Inf. Sci. 2019, 481, 330–343. [Google Scholar] [CrossRef]
- Huang, Q.; Huang, P.; Li, H.; Huang, J.; Lin, H. A more efficient public-key authenticated encryption scheme with keyword search. J. Syst. Archit. 2023, 137, 102839. [Google Scholar] [CrossRef]
- Pu, L.; Lin, C.; Chen, B.; He, D. User-friendly Public-key Authenticated Encryption with Keyword Search for Industrial Internet of Things. IEEE Internet Things J. 2023, 10, 13544–13555. [Google Scholar] [CrossRef]
- Bai, L.; Yong, L.; Chen, Z.; Shao, J. Pairing-free public-key authenticated encryption with keyword search. Comput. Stand. Interfaces 2024, 88, 103793. [Google Scholar] [CrossRef]
- Park, D.J.; Kim, K.; Lee, P.J. Public key encryption with conjunctive field keyword search. In Proceedings of the International Workshop on Information Security Applications; Springer: Berlin/Heidelberg, Germany, 2004; pp. 73–86. [Google Scholar]
- Hwang, Y.H.; Lee, P.J. Public key encryption with conjunctive keyword search and its extension to a multi-user system. In Proceedings of the International Conference on Pairing-Based Cryptography, Tokyo, Japan, 2–4 July 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 2–22. [Google Scholar]
- Chen, Y.C.; Horng, G. Timestamped conjunctive keyword-searchable public key encryption. In Proceedings of the 2009 Fourth International Conference on Innovative Computing, Information and Control (ICICIC), Kaohsiung, Taiwan, 7–9 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 729–732. [Google Scholar]
- Chen, Z.; Wu, C.; Wang, D.; Li, S. Conjunctive keywords searchable encryption with efficient pairing, constant ciphertext and short trapdoor. In Proceedings of the Intelligence and Security Informatics: Pacific Asia Workshop, PAISI 2012, Kuala Lumpur, Malaysia, 29 May 2012; Springer: Berlin/Heidelberg, Germany, 2012. Proceedings. pp. 176–189. [Google Scholar]
- Farràs, O.; Ribes-González, J. Provably secure public-key encryption with conjunctive and subset keyword search. Int. J. Inf. Secur. 2019, 18, 533–548. [Google Scholar] [CrossRef]
- Zhang, Y.; You, L.; Li, Y. Tree-Based Public Key Encryption with Conjunctive Keyword Search. Secur. Commun. Netw. 2021, 2021, 7034944. [Google Scholar] [CrossRef]
- Khader, D. Public key encryption with keyword search based on K-resilient IBE. In Proceedings of the International Conference on Computational Science and Its Applications, Glasgow, UK, 8–11 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 298–308. [Google Scholar]
- Yau, W.C.; Heng, S.H.; Tan, S.Y.; Goi, B.M.; Phan, R.C.W. Efficient encryption with keyword search in mobile networks. Secur. Commun. Netw. 2012, 5, 1412–1422. [Google Scholar] [CrossRef]
- Bellare, M.; Rogaway, P. Random oracles are practical: A paradigm for designing efficient protocols. In Proceedings of the 1st ACM Conference on Computer and Communications Security, Fairfax, VA, USA, 3–5 November 1993; pp. 62–73. [Google Scholar]
- Canetti, R.; Goldreich, O.; Halevi, S. The random oracle methodology, revisited. J. ACM (JACM) 2004, 51, 557–594. [Google Scholar] [CrossRef]
- Tan, S.Y.; Groß, T. Monipoly—An expressive q-SDH-based anonymous attribute-based credential system. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Virtual, 7–11 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 498–526. [Google Scholar]
- Chan, K.M.; Heng, S.H.; Tan, S.Y.; Tan, S.C. K-Resilient Public Key Authenticated Encryption with Keyword Search. In Proceedings of the 21st International Conference on Security and Cryptography, Dijon, France, 8–10 July 2024; SciTePress: Setúbal, Portugal, 2024; Volume 1, pp. 381–388. [Google Scholar] [CrossRef]
- Wu, W.; Shi, H. Pairing-Free Searchable Encryption for Enhancing Security Against Frequency Analysis Attacks. Electronics 2025, 14, 552. [Google Scholar] [CrossRef]
- Menezes, A.J.; Van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography; CRC: Boca Raton, FL, USA, 1996; Volume 17. [Google Scholar]
- Klimt, B.; Yang, Y. The enron corpus: A new dataset for email classification research. In Proceedings of the European Conference on Machine Learning, Pisa, Italy, 20–24 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 217–226. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).