1. Introduction
Currently, the Internet of Things (IoT) and related technologies are playing a pivotal role in designing, controlling, and managing large and complex systems, such as industrial process automation and optimization, surveillance, smart lighting, parking, waste management, leakage management, digital healthcare, smart grids, and many more. The typical architecture of these systems often consists of various heterogeneous and distributed interconnected devices. In traditional ML settings, the data generated by IoT devices is collected and analyzed in central nodes, such as physical servers or cloud clusters, which usually have powerful computational resources. However, IoT devices are usually deployed at dispersed geographical locations with limited control. IoT devices are very resource-constrained and suffer connectivity issues due to low bandwidth. Heterogeneity in hardware, software, and communication are also common challenges for any IoT infrastructure. Considering the above challenges, continuous data collection from a large number of IoT devices and their storage at a centralized location is very often not feasible. Additionally, IoT devices can acquire highly personalized data that needs to be protected, ensuring compliance with GDPR.
To mitigate the aforementioned issues, edge computing is becoming increasingly popular, which facilitates analytics at the device level without the need of transferring data to a cloud service [
1]. Initially, the edge and fog computing was proposed to execute simple queries over low-powered, distributed devices [
2,
3]. A few recent studies in this field have focused on training ML models centrally and then deploying the trained models on local devices to provide personalization, and mobile user modeling [
4]. However, with the enhanced storage and computational capabilities of edge devices, we can leverage the local resources on each device to train ML models using distributed data sets. One such ML technique is known as Federated Learning (FL). In FL, the central server sends a copy of an untrained ML model to all clients in the network. Each client computes an update to the globally-shared central model based on its local training data set and sends the updated local model parameters to the server. The server aggregates the updates from all the clients, updates global model parameters, and sends the updated model back to the clients. This process is repeated until the desired results are achieved [
5]. A classic example of this is the Google keyboard. When the keyboard shows a possible suggestion, your phone locally stores the information about the current context and whether you clicked the suggestion. This on-device information is then used to improve the next iteration of Gboard suggestions.
The standard FL problem involves learning a globally shared statistical model from data residing on tens to potentially thousands of remote devices. This model is trained under the constraint that the data generated on the edge device is kept and processed locally, with only periodic updates communicated to the central server. Since the data is not shared at any point, the privacy is preserved. It also reduces communication overhead in IoT networks as it only shares periodic model updates instead of sending huge chunks of raw data. However, IoT systems consist of devices with different hardware capabilities (system heterogeneity) which generate massive amounts of data in a highly disparate manner (statistical heterogeneity), while the effects of heterogeneity are long studied and proven in IoT networks, and there have been many attempts to mitigate the problem, these methods cannot fully handle the scale of federated networks. Moreover, the impact of heterogeneity is far worse in federated networks because the model training relies entirely on distributed data sets.
To tackle the federated network challenges, Google formulated the very first vanilla FL algorithm known as FedAvg. However, FedAvg does not account for the intrinsic heterogeneous nature of federated networks. Since then, many algorithms have been developed to balance the global model performance including stochastic-based algorithms [
6,
7] and primal dual-optimization [
8]. Although a significant effort has been put into developing robust, fair, fault-tolerant, and heterogeneity-aware solutions, to the best of our knowledge, the following questions remain unanswered:
How sensitive is the FL training process to the system and statistical heterogeneity? Does this sensitivity change under different algorithms?
Are existing proposals effective in mitigating the statistical and system heterogeneity?
If so, are these solutions as effective as they claim? To what extent do they mitigate the network heterogeneity?
To this end, we reviewed previous works in the field and conducted an extensive set of experiments to assess the impact of statistical and system heterogeneity on FL training. We simulated a heterogeneous federated network and collected a comprehensive set of measurements to analyze the problem empirically. Furthermore, we carefully selected the top six state-of-the-art FL algorithms and stress-tested them under varying levels of heterogeneity in the network. Our experimental setup comprehensively considers statistical and system heterogeneity to evaluate and compare these six algorithms in terms of model performance and training time. These metrics are then used to quantify the existing solutions’ ability to mitigate the challenge of heterogeneity in the FL environment. The experimental environment is also carefully controlled and kept identical to ensure a fair comparison while testing these algorithms.
Our experimental results show that heterogeneity significantly affects the FL network and leads to model divergence. The results also show that its impact varies significantly depending on the type of heterogeneity in the network. For example, statistical heterogeneity causes non-trivial performance degradation in FL, including up to 33.76% accuracy drop in some algorithms. The impact of heterogeneity is more significant in the scenarios where both statistical and system heterogeneity is present. We not only observed a drastic degradation in average performance but also 3.42× lengthened training time and undermined fairness. Despite the claims, our experiments show that the existing solutions are less effective in mitigating the negative impact of heterogeneity in FL. Overall, we believe this study highlights the grey zones in existing solutions and provides essential and timely insights for system designers and FL researchers.
Outline:
Section 2 discusses heterogeneity in federated IoT networks and covers both, statistical and system heterogeneity.
Section 3 presents an overview of background and related previous works.
Section 4 presents a brief overview of algorithms selected for this study.
Section 5 presents our experimental setup and
Section 6 presents evaluation results including the conclusions made from empirical analysis. We conclude our work and present a few future research directions in
Section 7.
2. Heterogeneity in Federated IoT Networks
IoT networks are intrinsically heterogeneous. In real-life scenarios, FL is deployed over an IoT network with different data samples, device capabilities, device availability, network quality, and battery levels. As a result, heterogeneity is evidentiary and impacts the performance of a federated network. This section breaks down the heterogeneity and briefly discusses the two main categories, statistical and system heterogeneity.
2.1. Statistical Heterogeneity
Distributed optimization problems are often modeled under the assumption that data is Independent and Identically Distributed (IID). However, IoT devices generate and collect data in a highly dependent and inconsistent fashion. The number of data points also varies significantly across devices which adds complexity to problem modeling, solution formulation, analysis, and optimization. Moreover, the devices could be distributed in association with each other, and there might be an underlying statistical structure capturing their relationship. With the aim of learning a single, globally shared model, statistical heterogeneity makes it difficult to achieve an optimal performance.
2.2. System Heterogeneity
It is very likely for IoT devices in a network to have different underlying hardware (CPU, memory). These devices might also operate on different battery levels and use different communication protocols (WiFi, LTE, etc.) Conclusively, the computational storage, and communication capabilities differ for each device in the network. Moreover, IoT networks have to cope with stragglers as well. Low-level IoT devices operate on low battery power and bandwidth and can become unavailable at any given time.
The aforementioned system-level characteristics can introduce many challenges when training ML models over the edge. For example, federated networks consist of hundreds of thousands of low-level IoT devices, but only a handful of active devices might take part in the training. Such situations can make trained models biased towards the active devices. Moreover, low participation can result in a long convergence time when training. Due to the reasons mentioned above, heterogeneity is one of the main challenges for federated IoT networks, and federated algorithms must be robust, heterogeneity-aware, and fault-tolerant. Recently a few studies have claimed to address the challenge of heterogeneity; therefore, in this paper, we focus on empirical analysis for evaluating the existing approaches and quantifying their effectiveness in mitigating the problem of heterogeneity.
3. Background and Related Work
In the recent few years, there has been a paradigm shift in the way ML is applied in applications, and FL has emerged as a victor in systems driven by privacy concerns and deep learning [
9,
10,
11]. FL is being widely adopted due to its compliance with GDPR, and it can be said that it is laying the foundation for next-generation ML applications. Despite FL is showcasing promising results, however, it also brings in unique challenges; such as communication efficiency, heterogeneity, and privacy, which are thoroughly discussed in [
12,
13,
14,
15,
16]. To mitigate these challenges, various techniques have been presented over the last few years. For example, [
17] presented an adaptive averaging strategy, and authors in [
18] presented an In-Edge AI framework to tackle the communication bottleneck in federated networks. To deal with the resource optimization problem, [
19] focused on the design aspects for enabling FL at the network edge. In contrast, [
20] presented the Dispersed Federated Learning (DFL) framework to provide resource optimization for FL networks.
Heterogeneity is one of the major challenges faced by federated IoT networks. However, early FL approaches neither consider system and statistical heterogeneity in their design [
5,
21] and nor are straggler-aware. Instead, there is a major assumption of uniform participation from all clients and a sample fixed number of data parties in each learning epoch to ensure performance and fair contribution from all clients. Due to these unrealistic assumptions, FL approaches suffer significant performance loss and often lead to model divergence under heterogeneous network conditions.
Previously, many research works have tried to mitigate heterogeneity problem in distributed systems via system and algorithmic solutions [
22,
23,
24,
25]. In this context, heterogeneity results from different hardware capabilities of devices (system heterogeneity) and results in performance degradation due to stragglers. However, these conventional methods cannot handle the scale of federated networks. Moreover, heterogeneity in FL settings is not limited to hardware and device capabilities. Various other system artifacts such as data distribution [
26], client sampling [
27] and user behavior also introduce heterogeneity (known as statistical heterogeneity) in the network.
Recently, various techniques have been presented to tackle heterogeneity in a federated network. In [
28], the authors proposed to tackle heterogeneity via client sampling. Their approach uses a deadline-based approach to filter out all the stragglers. However, it does not consider how this approach affects the straggler parties in model training. Similarly, [
29] proposed to reduce the total training time via adaptive client sampling while ignoring the model bias. FedProx [
6] allows client devices to perform a variable amount of work depending on their available system resources and also adds a proximal term to the objective to account for the associated heterogeneity. A few other works in this area proposed reinforcement learning-based techniques to mitigate the negative effects of heterogeneity [
30,
31]. Furthermore, algorithmic solutions have also been proposed that mainly focus on tackling statistical heterogeneity in the federated network. In [
7], authors proposed a variance reduction technique to tackle the data heterogeneity. Similarly, [
8] proposed a new design strategy from a primal-dual optimization perspective to achieve communication efficiency and adaptivity to the level of heterogeneity among the local data. However, these techniques do not consider the communication capabilities of the participating devices. Furthermore, they have not been tested in real-life scenarios which keeps us in the dark regarding their
actual performance in comparison to the reported performance. Comparing the conventional and the new upcoming federated systems in terms of heterogeneity and distribution helps us understand the open challenges as well as track the progress of federated systems [
32].
A few studies have also been presented to understand the impact of heterogeneity in FL training. In [
33], the author demonstrated the potential impact of system heterogeneity by allocating varied CPU resources to the participants. However, the author only focused on training time and did not consider the impact of model performance. In [
34], the authors characterized the impact of heterogeneity on FL training, but they majorly focused on system heterogeneity while ignoring the other types of heterogeneity in the systems. Similarly, in [
35], the authors used large-scale smartphone data to understand the impact of heterogeneity but did not account for stragglers. However, all of the studies mentioned above failed to analyze the effectiveness of state-of-the-art FL algorithms under the heterogeneous network conditions.
Table 1 summarizes these previous works along with their key contributions and drawbacks.
Our study differs from the existing works in three aspects (i) we comprehensively consider statistical heterogeneity as well as system heterogeneity in the experimental environment; (ii) we focus on quantifying the effectiveness of proposed solutions in mitigating the heterogeneity in FL; and (iii) we carefully controlled the test-bed environment to keep all setting identical ensuring a fair comparison of the proposed solutions.
5. Experimental Design
We ran extensive experiments for image processing systems to evaluate the performance of different FL algorithms under heterogeneous network conditions. This section thoroughly discusses the experimental methodology.
5.1. Data Set
Our initial study includes a model for the MNIST digit recognition task. The MNIST data set has a training set of 60,000 28 × 28 grayscale images of the ten digits and a test set of 10,000 examples. This data set is used by almost all federated algorithms for experimentation, giving us a common ground for performance evaluation.
5.2. Experiment Details
For the classic MNIST digit recognition task, we carried out experiments using a convolutional neural network (CNN) with two 5 × 5 convolution layers (the first with 32 channels, the second with 64 each with a padding of 2 and followed by a 2 × 2 max pooling), a fully connected layer with 512 units and ReLu activation with a final softmax output layer. To understand the performance and optimization of different algorithms, we also needed to specify how to distribute data over the network. We distributed the data over 100 clients and studied two ways of data partitioning: the idealistic IID distribution where data is shuffled and distributed among the 100 clients so that each client receives 600 examples and the real-world non-IID distribution where data is sorted by the digit label divided into 200 shards of the size 300 images with each client receiving two shards. These settings let us explore the degree to which the algorithms can break under the data heterogeneity. We incorporate system heterogeneity in our experimental setup in the following two ways:
Fraction of active clients: where only a specified number of clients are randomly selected to participate in a training round. For our experiments, we specified 100 clients for our simulated IoT network, out of which only 10% will be actively taking part in one training round. The threshold of active clients is chosen randomly but is kept identical for all the algorithms. Moreover, active clients are chosen randomly in each training round. This simulation is backed by the fact that even though IoT networks consist of a large number of devices, it is common for these devices to become unavailable for training due to numerous reasons, i.e., connectivity, low battery, and user interruption. Thus, only a tiny fraction of devices are usually available in any training round.
Stragglers: which refers to the number of devices that fails to complete the local training rounds. It is common for IoT devices to drop out during the training round due to interruptions in network connectivity. Thus, initially, active devices can also fail to complete the local training and significantly delay the execution of the federated task. To simulate the problem, we set a threshold for devices that act as stragglers.
To thoroughly study the effects of system heterogeneity, we experimented with 10%, 30%, 50%, 70%, and 90% of stragglers. These settings serve as a testing bed, helping us understand how varying levels of system heterogeneity might affect an algorithm’s performance.
6. Evaluation & Results
This section is divided into two subsections, Statistical Heterogeneity and System Heterogeneity, to explain the corresponding results.
6.1. Impact of Statistical Heterogeneity
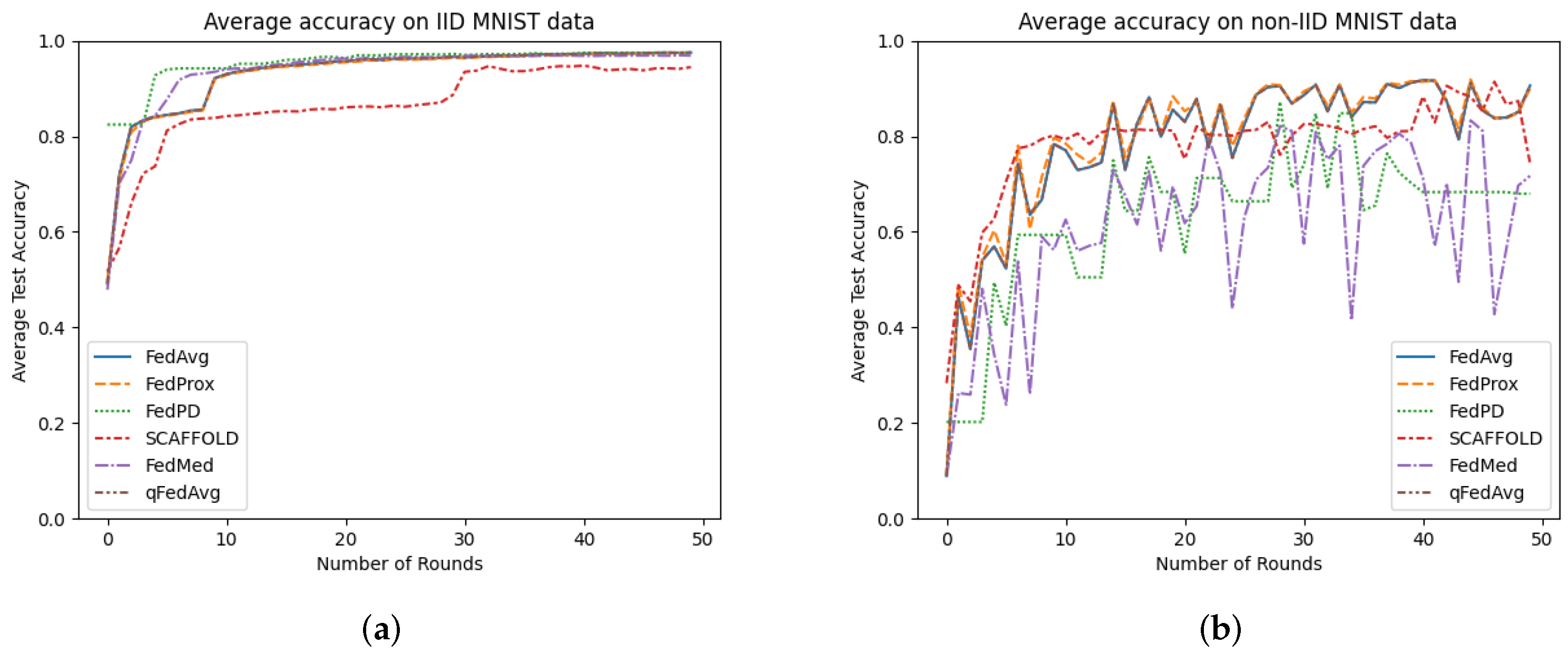
To mimic the ideal conditions of IID data distribution, we randomly shuffle the data and distribute it among the 100 clients. Only 10% of the clients were randomly chosen to participate in a training round. Under these settings, all the federated algorithms performed well, reaching an accuracy as high as 97%.
Figure 1a shows the average accuracy of FL algorithms over IID data. These results were expected since all the distributed optimization problems converge faster under IID data distribution.
However, federated networks have non-IID data distribution across the network, which reflects in performance degradation in real-world scenarios. The results in
Figure 1b show that the statistical heterogeneity significantly affects FL training. We observed an accuracy drop of 7.09% in the case of FedAvg. This accuracy drop does not come as a surprise since FedAvg does not account for any underlying heterogeneity. Our experiments also show a drastic accuracy drop of 30.24%, 26.02%, and 19.22% in the performance of FedPD, FedMed, and SCAFFOLD, respectively. These results were highly unexpected considering the fact that FedPD and SCAFFOLD incorporate data heterogeneity in their design, also claiming to outperform FedAvg.
The impact of statistical heterogeneity becomes more significant if the client population is small or if the participating clients have small numbers of data samples. Although recently developed solutions such as FedPD and SCAFFOLD claim to nullify the effects of statistical heterogeneity and guarantee convergence, not all of them are as good as they claim. We observed that FedMed and SCAFFOLD are very sensitive to local data batch size, and even a small change can cause a drastic shift in model performance. SCAFFOLD performs better over small data batches, but that comes at the cost of high training time and is not feasible. On the other hand, FedPD does not show any significant change.
The results show that statistical heterogeneity slightly lengthens the training time, but its impact is more significant on model performance. Despite the claims, all the existing proposals fall short in mitigating the impact of statistical heterogeneity, and none of the FL algorithms could outperform FedAvg.
6.2. Impact of System Heterogeneity
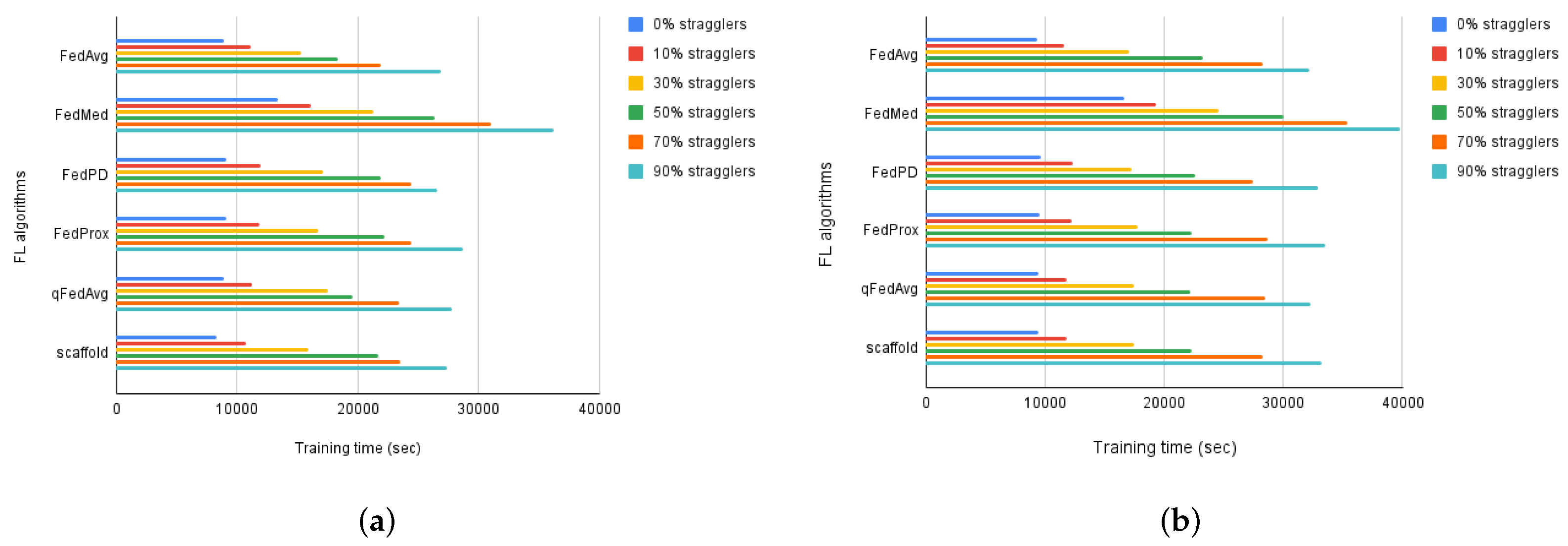
System heterogeneity is deep-rooted in IoT networks and often leads to divergence of the model, bias, etc. In order to estimate the effects of system heterogeneity in federated IoT networks, we set a threshold for the number of stragglers to have a controlled environment and keep the testing set up the same for all algorithms. In our experiments, every client has ten local epochs to complete one training iteration successfully. If a client fails to complete a training round in the given time frame, it is considered a straggler. We carried out experiments over IID and non-IID data distribution with varying levels of stragglers to explore the degree to which algorithms can break. We considered model performance and total training time the key performance metrics for our evaluation. The results, as shown in
Figure 2, demonstrate that system heterogeneity lengthens the training time irrespective of whether data distribution is IID or non-IID.
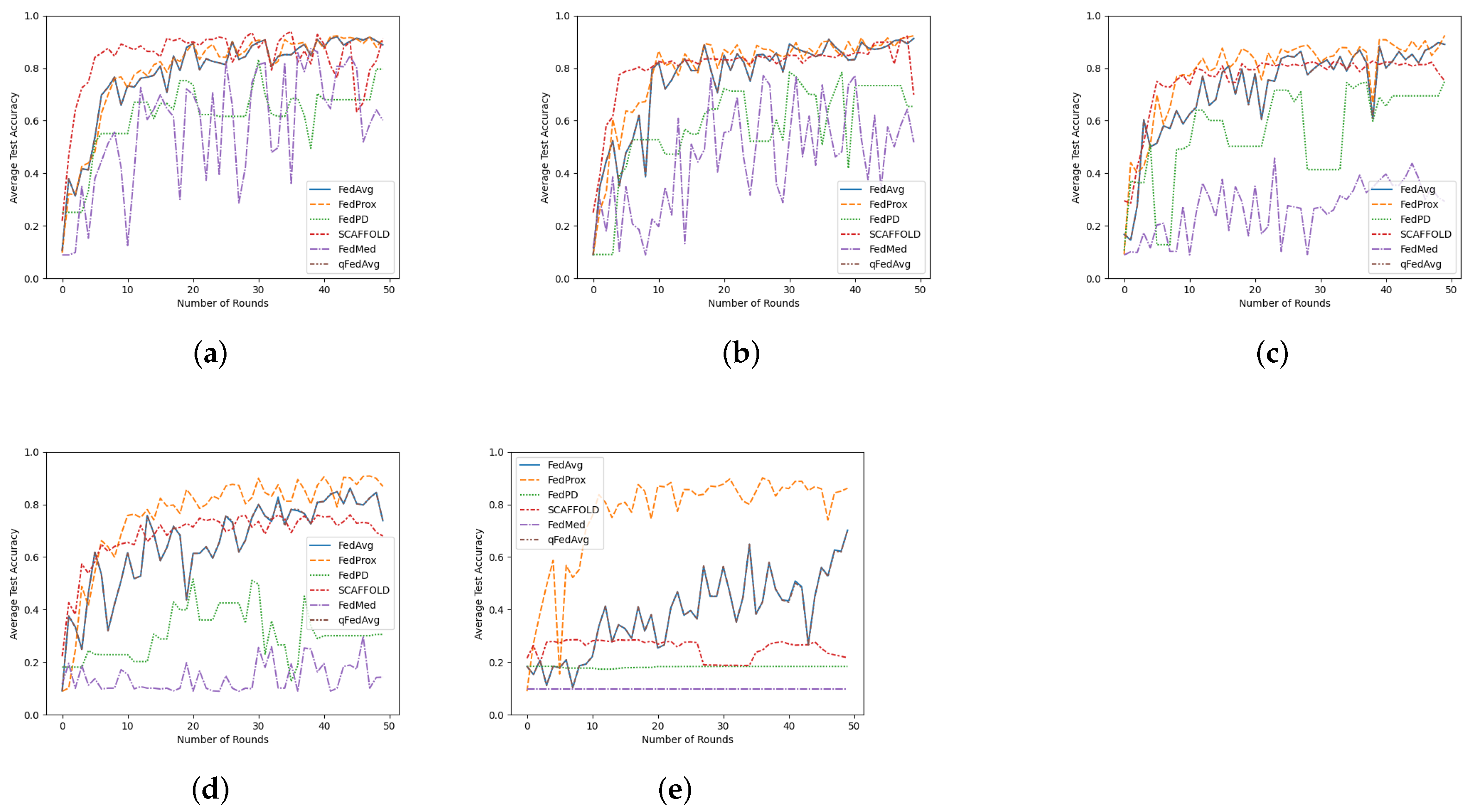
The results also show that the impact of heterogeneity varies depending on the scenario and sensitivity of the algorithm. A small threshold of stragglers is less likely to affect the model performance if the network has IID data distribution. However, this impact becomes more significant in the scenarios where both statistical and system heterogeneity come into the picture. For instance, we did not observe any accuracy drop for a threshold of 10% stragglers over IID data distribution, as can be seen in
Figure 3. On the other hand,
Figure 4 shows the same 10% threshold reports an accuracy drop of 16.04% over non-IID data for FedMed.
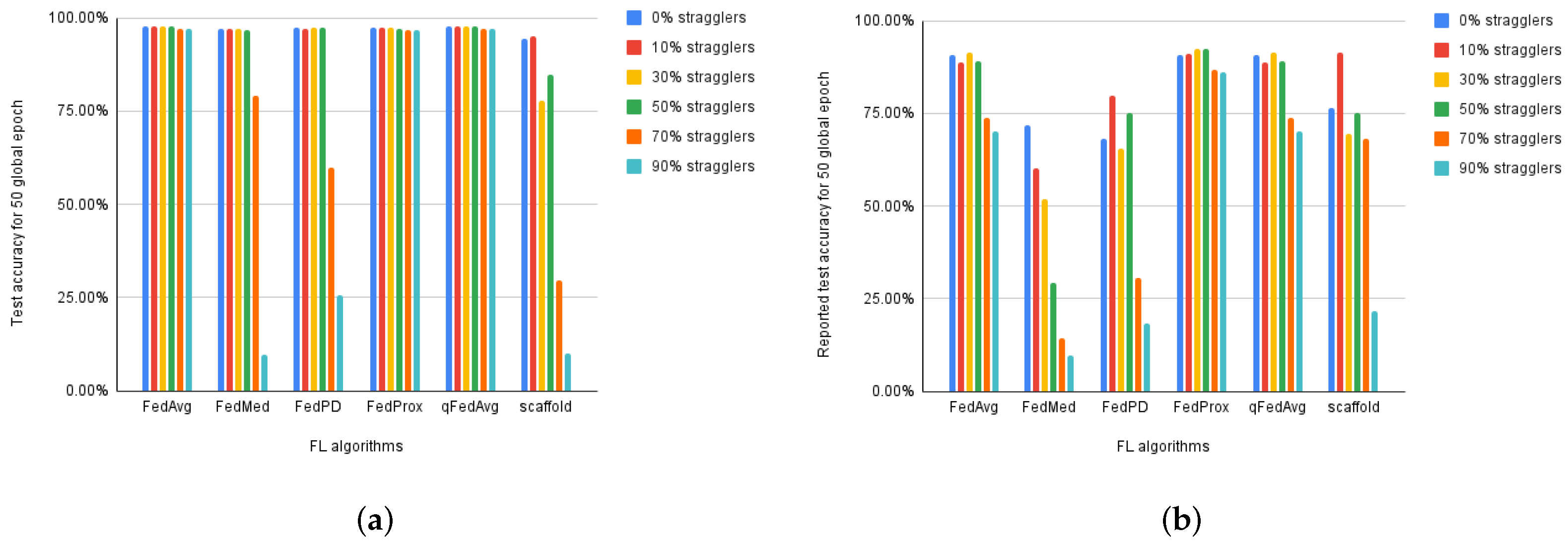
We extended our experiments to include the highly heterogeneous environment where data is distributed in a non-IID manner and up to 90% of the participating devices are stragglers. Under these settings, FedAvg reported an accuracy drop of 22.54% and a lengthened training time up to 3.42✕. This behavior can be expected because it does not account for system or statistical heterogeneity in its design. We also observed an accuracy drop of 20.03% and 4.84% in the performance of qFedAvg and FedProx, respectively, while FedMed, FedPD, and SCAFFOLD led to model divergence.
Our experiments show that the existing solutions are less effective in improving the training process when heterogeneity is considered. Instead, they are proved to be more sensitive to heterogeneity and thus lead to model divergence.
Figure 5 shows that all the FL algorithms report performance degradation under heterogeneous network conditions. The impact is more significant on model performance in scenarios where both system and statistical heterogeneity are present. Here, the devices are chosen at random for each training iteration which skews the distribution more and results in model divergence. Hence, we conclude that both statistical and system heterogeneity affects a federated network’s performance and we cannot simply ignore the repercussions of either.
7. Conclusions
We present a comprehensive experimental study to anatomize the potential impact of statistical and system heterogeneity on the performance and training time of the collaboratively learned models in FL settings. We evaluate state-of-the-art FL algorithms in their ability to mollify the negative implications of heterogeneity. Although, recent FL algorithms claim to be resilient and guarantee convergence under heterogeneous settings, this study shows that the existing solutions are less effective when system and statistical heterogeneity are considered. This situation is especially distressful for smart system manufacturers and IoT solution providers who demand highly optimum and adaptable mechanisms, while FL aims at laying the foundation for technology that extends security, the lack of resilient, heterogeneity-aware solutions is a major roadblock to achieving this goal.
We believe that our study not only highlights the limitations of existing algorithms but also provides timely insight for FL system designers. Although an optimizer’s choice depends on the nature of the learning problem, FL researchers can use this study to design more efficient and heterogeneity-aware FL systems. The choice of local epochs and batch size has to be moderate since there is a trade-off in training time and model performance. The performance benchmarks should be introduced for all learning domains to keep track of progress in federated IoT networks. Finally, we emphasize the importance of testing and fine-tuning the proposed solutions in realistic, heterogeneous environments to achieve better performance.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}