
A Failed Cross-Validation Study on the Relationship between LIWC Linguistic Indicators and Personality: Exemplifying the Lack of Generalizability of Exploratory Studies

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Instruments
2.3. Procedure
3. Results
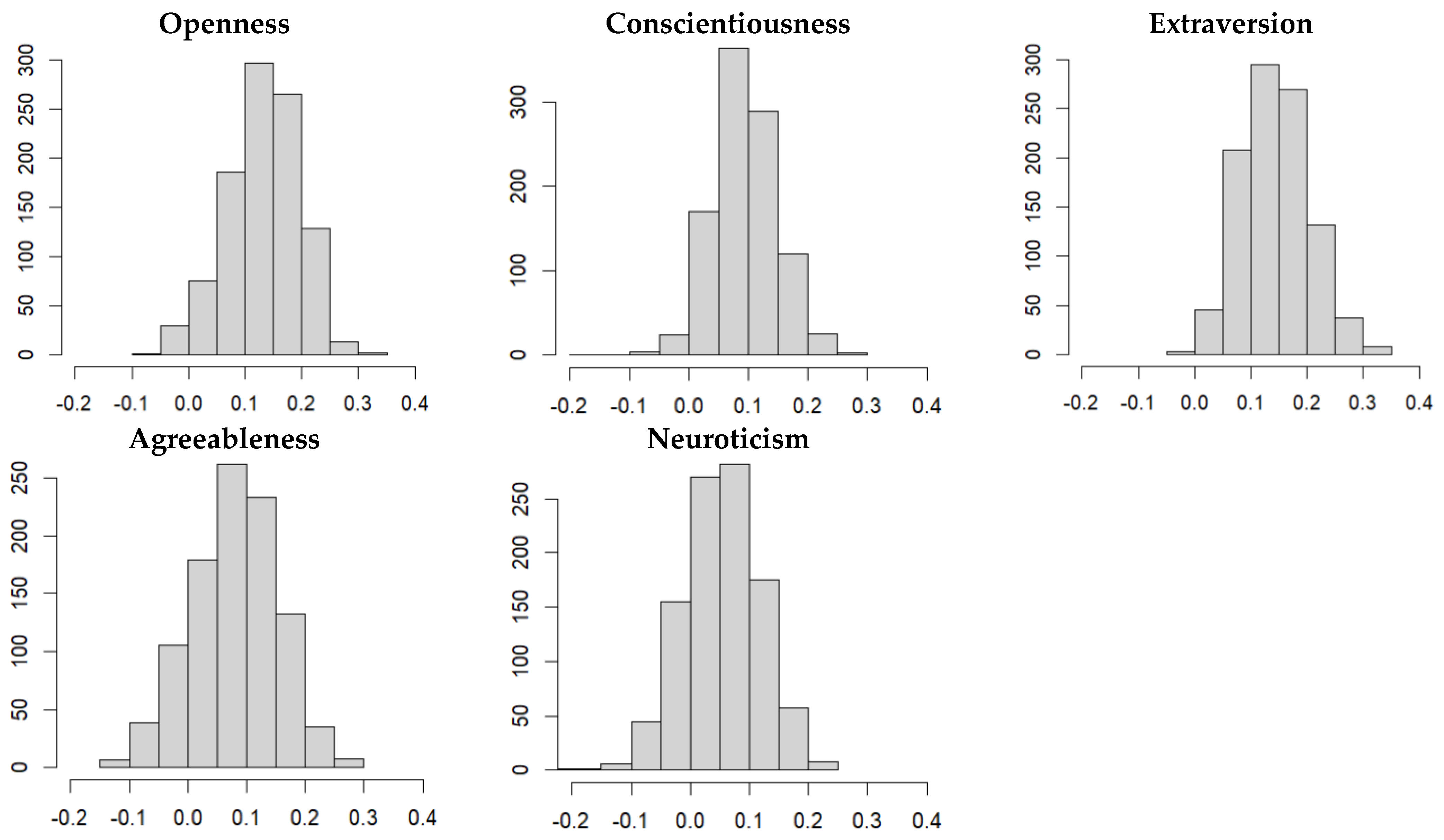
3.1. Analyzing the Complete Data Set
3.2. First Cross-Validation Study (Hold-Out Method)
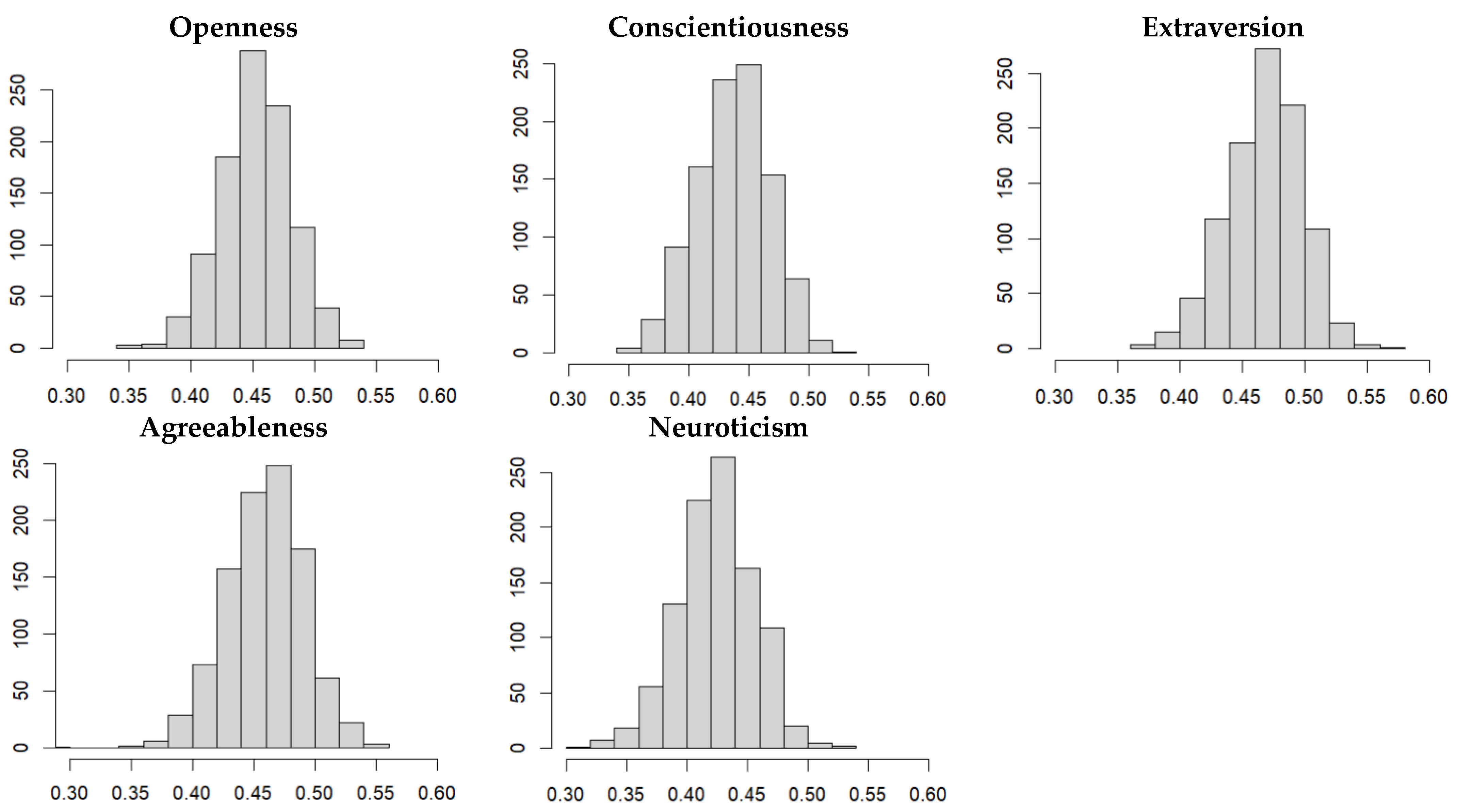
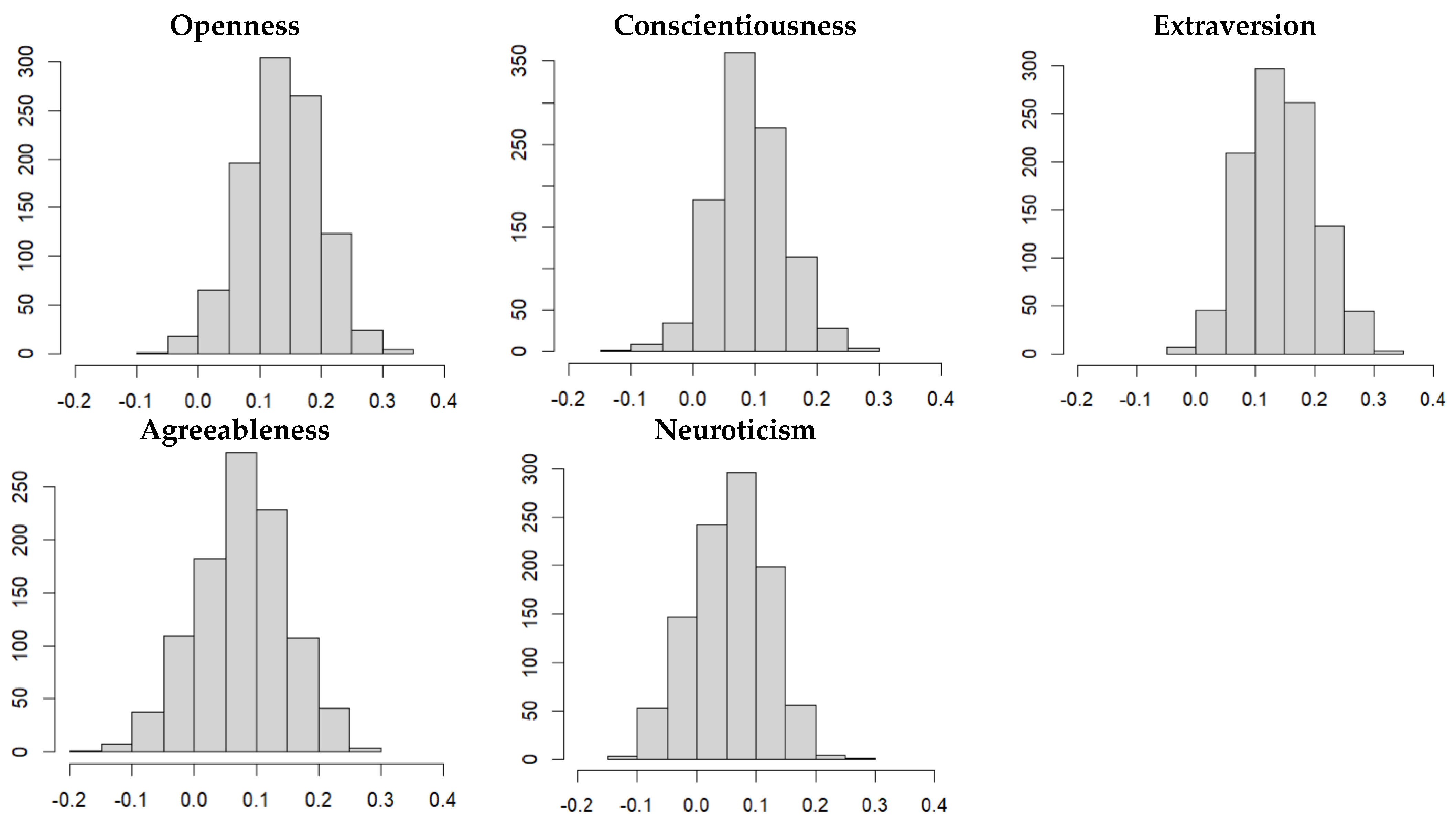
3.2.1. Distribution of Model Performances in the Training Data Sets
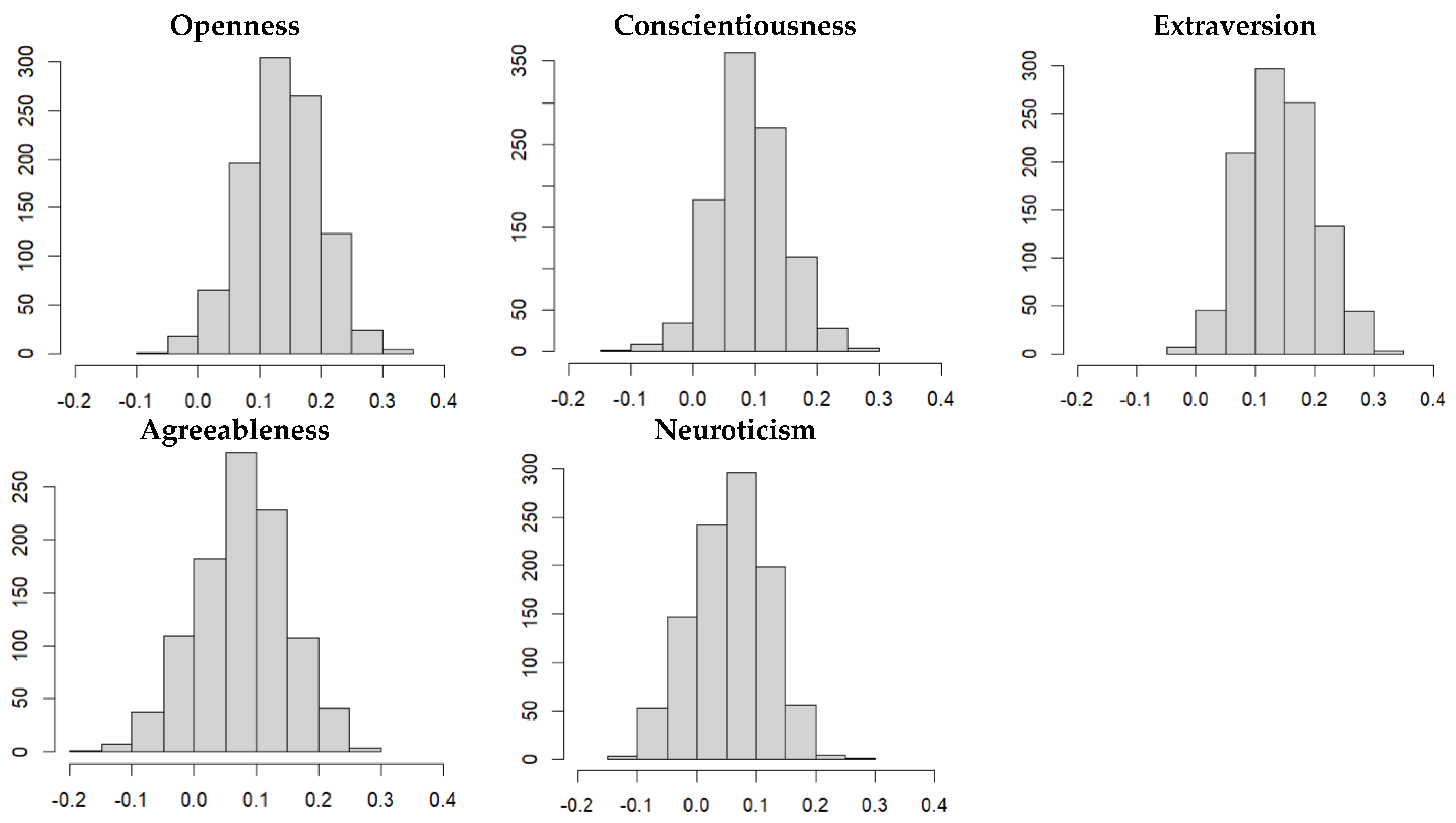
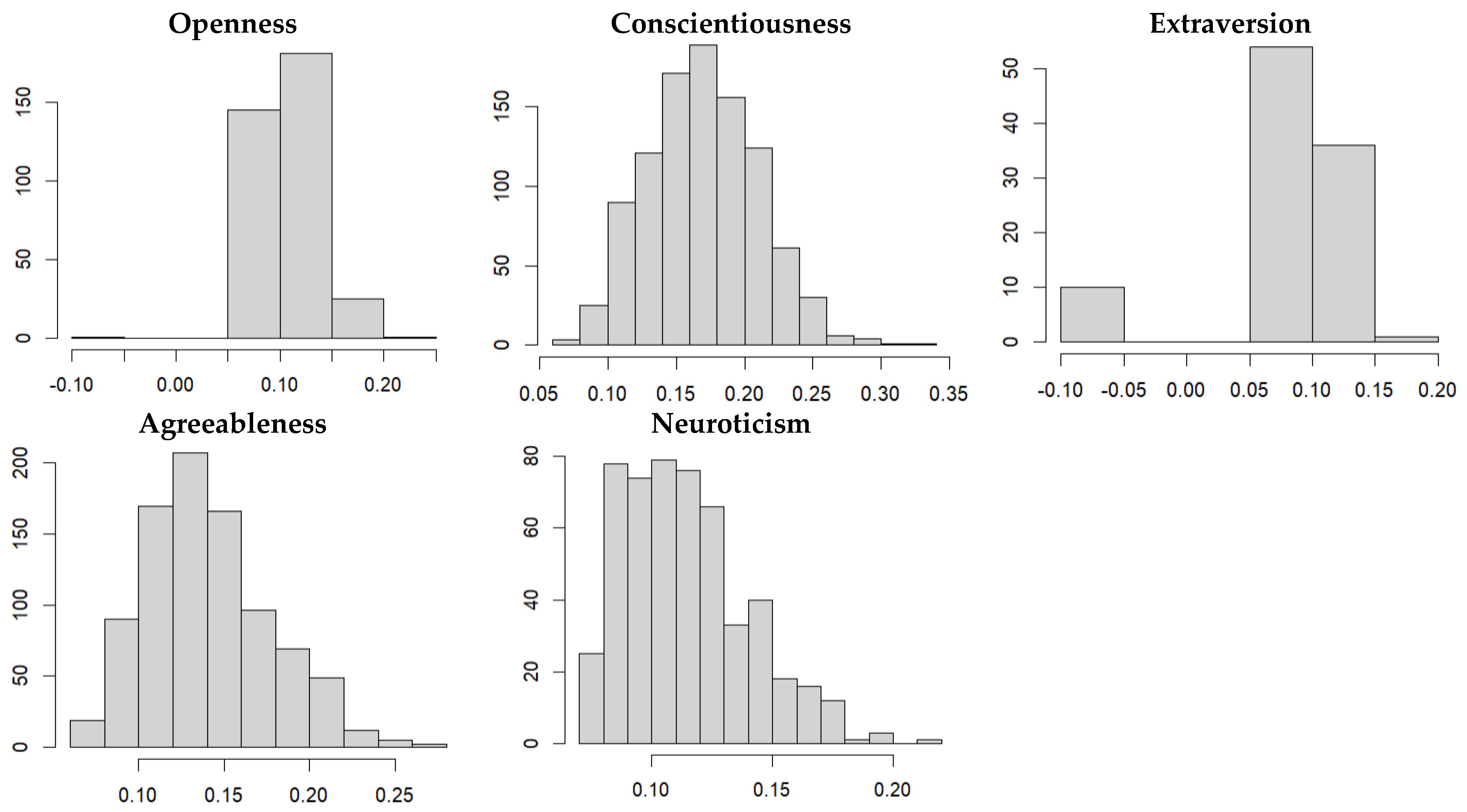
3.2.2. Distribution of Model Performances in the Validation Data Sets
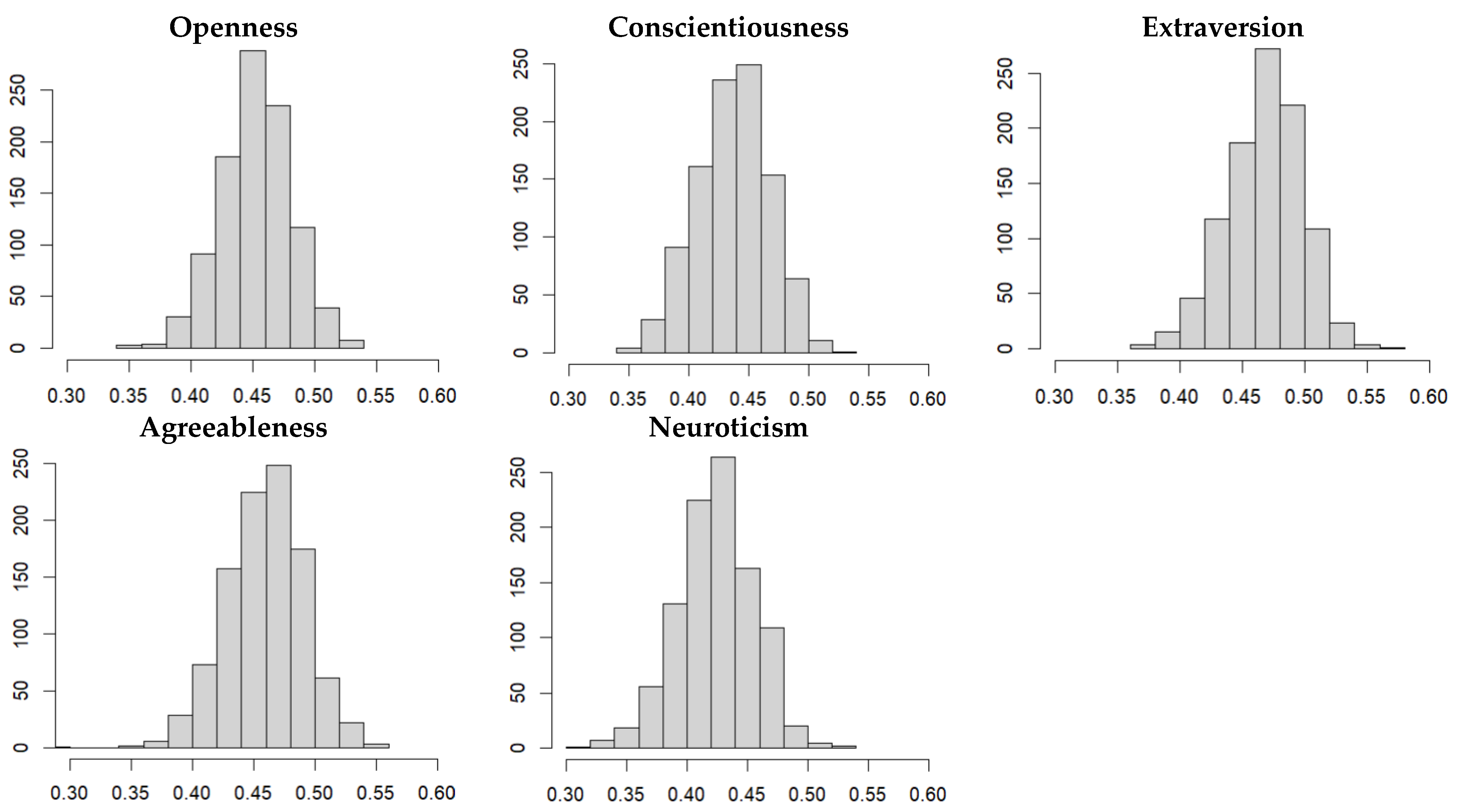
3.2.3. Predictor Selection and Mean Standardized Effect of Word Count in the Training Data Sets
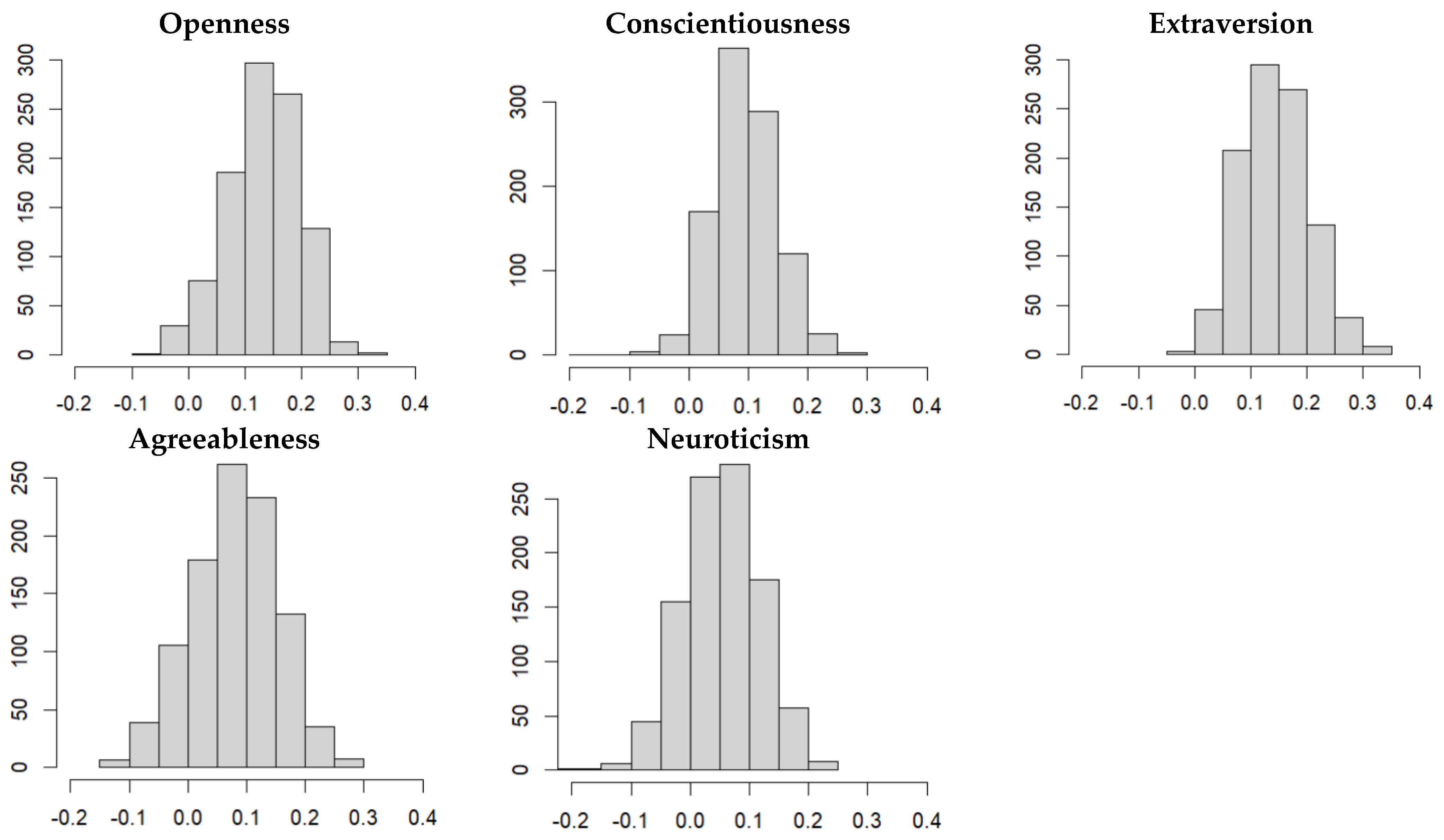
3.3. Second Cross-Validation Study (k-Fold Method)
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boyd, R.L.; Pennebaker, J.W. Language-based personality: A new approach to personality in a digital world. Curr. Opin. Behav. Sci. 2017, 18, 63–68. [Google Scholar] [CrossRef] [Green Version]
- Boyd, R.L.; Pennebaker, J.W. Did Shakespeare write Double Falsehood? Identifying individuals by creating psychological signatures with text analysis. Psychol. Sci. 2015, 26, 570–582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fast, L.A.; Funder, D.C. Personality as manifest in word use: Correlations with self-report, acquaintance report, and behavior. J. Pers. Soc. Psychol. 2008, 94, 334–346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwantes, P.J.; Derbentseva, N.; Lam, Q.; Vartanian, O.; Marmurek, H.H. Assessing the Big Five personality traits with latent semantic analysis. Pers. Indiv. Differ. 2016, 102, 229–233. [Google Scholar] [CrossRef]
- Boyd, R.L.; Schwartz, H.A. Natural Language Analysis and the Psychology of Verbal Behavior: The Past, Present, and Future States of the Field. J. Lang. Soc. Psychol. 2021, 40, 21–41. [Google Scholar] [CrossRef]
- Chung, C.K.; Pennebaker, J.W. What Do We Know When We LIWC a Person? Text Analysis As An Assessment Tool for Traits, Personal Concerns and life Stories. In The SAGE Handbook of Personality and Individual Differences: The Science of Personality and Individual Differences; Zeigler-Hill, V., Shackelford, T.K., Eds.; SAGE: London, UK, 2018; pp. 341–360. [Google Scholar] [CrossRef]
- Moreno, J.D.; Martínez-Huertas, J.Á.; Olmos, R.; Jorge-Botana, G.; Botella, J. Can personality traits be measured analyzing written language? A meta-analytic study on computational methods. Pers. Indiv. Differ. 2021, 177, 110818. [Google Scholar] [CrossRef]
- Hirsh, J.B.; Peterson, J.B. Personality and language use in self-narratives. J. Res. Pers. 2009, 43, 524–527. [Google Scholar] [CrossRef]
- Stachl, C.; Pargent, F.; Hilbert, S.; Harari, G.M.; Schoedel, R.; Vaid, S.; Gosling, S.D.; Bühner, M. Personality research and assessment in the era of machine learning. Eur. J. Personal. 2020, 34, 613–631. [Google Scholar] [CrossRef]
- McCrae, R.R.; Costa, P.T., Jr. The Five-Factor Theory of Personality. In Handbook of Personality: Theory and Research, 3rd ed.; John, O.P., Robins, R.W., Pervin, L.A., Eds.; Guilford Press: New York, NY, USA, 2008; pp. 159–181. [Google Scholar]
- Giner-Sorolla, R. From crisis of evidence to a “crisis” of relevance? Incentive-based answers for social psychology’s perennial relevance worries. Eur. Rev. Soc. Psychol. 2019, 30, 1–38. [Google Scholar] [CrossRef]
- Nosek, B.A.; Hardwicke, T.E.; Moshontz, H.; Allard, A.; Corker, K.S.; Dreber, A.; Vazire, S. Replicability, robustness, and reproducibility in psychological science. Annu. Rev. Psychol. 2022, 73, 719–748. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic Inquiry and Word Count: LIWC 2001; Erlbaum: Mahwah, NJ, USA, 2001. [Google Scholar]
- Pennebaker, J.W.; Boyd, R.L.; Jordan, K.; Blackburn, K. The Development and Psychometric Properties of LIWC2015; The University of Texas at Austin: Austin, TX, USA, 2015. [Google Scholar]
- Farnadi, G.; Sitaraman, G.; Sushmita, S.; Celli, F.; Kosinski, M.; Stillwell, D.; De Cock, M. Computational per-sonality recognition in social media. User Model. User Adap. 2016, 26, 109–142. [Google Scholar] [CrossRef] [Green Version]
- Hawkins, I.I.; Raymond, C.; Boyd, R.L. Such stuff as dreams are made on: Dream language, LIWC norms, and personality correlates. Dreaming 2017, 27, 102–121. [Google Scholar] [CrossRef]
- Proyer, R.T.; Brauer, K. Exploring adult playfulness: Examining the accuracy of personality judgments at ze-ro-acquaintance and an LIWC analysis of textual information. J. Res. Pers. 2018, 73, 12–20. [Google Scholar] [CrossRef]
- Qiu, L.; Lin, H.; Ramsay, J.; Yang, F. You are what you tweet: Personality expression and perception on Twitter. J. Res. Pers. 2012, 46, 710–718. [Google Scholar] [CrossRef]
- Qiu, L.; Lu, J.; Ramsay, J.; Yang, S.; Qu, W.; Zhu, T. Personality expression in Chinese language use. Int. J. Psychol. 2017, 52, 463–472. [Google Scholar] [CrossRef] [PubMed]
- Holtgraves, T. Text messaging, personality, and the social context. J. Res. Pers. 2011, 45, 92–99. [Google Scholar] [CrossRef]
- Yarkoni, T. Personality in 100,000 words: A large-scale analysis of personality and word use among bloggers. J. Res. Pers. 2010, 44, 363–373. [Google Scholar] [CrossRef] [Green Version]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Mehl, M.R.; Gosling, S.D.; Pennebaker, J.W. Personality in its natural habitat: Manifestations and implicit folk theories of personality in daily life. J. Pers. Soc. Psychol. 2006, 90, 862–877. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; King, L.A. Linguistic styles: Language use as an individual difference. J. Pers. Soc. Psychol. 1999, 77, 1296–1312. [Google Scholar] [CrossRef]
- Martínez-Huertas, J.A.; Jorge-Botana, G.; Luzón, J.M.; Olmos, R. Redundancy, isomorphism and propagative mechanisms between emotional and amodal representations of words: A computational study. Mem. Cognition 2021, 49, 219–234. [Google Scholar] [CrossRef] [PubMed]
- Bermúdez, J. Cuestionario “Big Five”; TEA Ediciones: Madrid, Spain, 2001. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Zhang, Z. Variable selection with stepwise and best subset approaches. Ann. Transl. Med. 2016, 4, 136. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Dziurzynski, L.; Ramones, S.M.; Agrawal, M.; Shah, A.; Kosinski, M.; Stillwell, D.; Ungar, L.H.; et al. Personality, gender, and age in the language of social media: The open-vocabulary approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef] [PubMed]
- Michels, M. General intelligence and the dark triad: A meta-analysis. J. Individ. Differ. 2022, 43, 35–46. [Google Scholar] [CrossRef]
- Bédard, M.A.; Le Corff, Y. Intelligence and personality: A replication and extension study of the association between intelligence and personality aspects. J. Individ. Differ. 2020, 41, 124. [Google Scholar] [CrossRef]
- DeYoung, C.G.; Quilty, L.C.; Peterson, J.B.; Gray, J.R. Openness to experience, intellect, and cognitive ability. J. Pers. Assess 2014, 96, 46–52. [Google Scholar] [CrossRef] [PubMed]
- Syzmanowicz, A.; Furnham, A. Gender differences in self-estimates of general, mathematical, spatial and verbal intelligence: Four meta analyses. Learn Individ. Differ. 2011, 21, 493–504. [Google Scholar] [CrossRef]
- Guest, O.; Martin, A.E. How computational modeling can force theory building in psychological science. Perspect. Psychol. Sci. 2021, 16, 789–802. [Google Scholar] [CrossRef]
- Smaldino, P.E. How to translate a verbal theory into a formal model. Soc. Psychol. 2020, 51, 207–218. [Google Scholar] [CrossRef]
- van Rooij, I.; Baggio, G. Theory before the test: How to build high-verisimilitude explanatory theories in psychological science. Perspect. Psychol. Sci. 2021, 16, 682–697. [Google Scholar] [CrossRef] [PubMed]
- Landauer, T.K.; Dumais, S. A solution to Plato’s problem: The Latent Semantic Analysis theory of the acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211–240. [Google Scholar] [CrossRef]
- Landauer, T.K.; McNamara, D.S.; Dennis, S.; Kintsch, W. The Handbook of Latent Semantic Analysis; Taylor & Francis: Mahwah, NJ, USA, 2007. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural. Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Martínez-Huertas, J.A.; Olmos, R.; Jorge-Botana, G.; León, J.A. Distilling vector space model scores for the assessment of constructed responses with bifactor Inbuilt Rubric method and latent variables. Behav. Res. Methods 2022, 1–23. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| O | C | E | A | N | ||
|---|---|---|---|---|---|---|
| Full model | R (R2) | 0.452 (0.205) | 0.429 (0.184) | 0.459 (0.211) | 0.449 (0.202) | 0.422 (0.178) |
| Radj (Radj2) | 0.283 (0.080) | 0.237 (0.056) | 0.295 (0.087) | 0.276 (0.076) | 0.221 (0.049) | |
| Backwards stepwise selection | R (R2) | 0.373 (0.139) | 0.357 (0.127) | 0.372 (0.138) | 0.370 (0.137) | 0.311 (0.097) |
| Radj (Radj2) | 0.342 (0.117) | 0.310 (0.096) | 0.345 (0.119) | 0.336 (0.113) | 0.279 (0.078) |
| Estimate | Openness | Conscientiousness | Extraversion | Agreeableness | Neuroticism |
|---|---|---|---|---|---|
| Intercept | 0.656 ** (0.000) | 0.157 (0.000) | 0.364 ** (0.000) | 0.199 (0.000) | 0.570 ** (0.000) |
| Large words a | 0.006 ** (0.117) | - | 0.006 ** (0.126) | - | - |
| Function words b | −0.008 ** (−0.173) | - | - | - | - |
| Personal pronouns | 0.008 (0.085) | 0.012 ** (0.142) | - | 0.038 ** (0.582) | - |
| Impersonal pronouns | 0.025 ** (0.253) | 0.008 * (0.095) | - | - | - |
| Past | −0.021 (−0.078) | - | - | - | −0.022 * (−0.083) |
| Present | −0.014 ** (−0.169) | - | - | - | - |
| Conjunctions | 0.024 ** (0.221) | - | - | - | - |
| Family | −0.028 ** (−0.153) | - | - | - | - |
| Humans | −0.025 ** (−0.124) | −0.016 * (−0.089) | - | - | - |
| Exclamations | −0.014 (−0.075) | −0.017 * (−0.098) | −0.018 * (−0.107) | - | - |
| Feelings | 0.029 * (0.082) | - | - | - | - |
| Biology | 0.061 * (0.411) | - | - | - | - |
| Body | −0.053 (−0.113) | - | - | - | - |
| Health | −0.055 * (−0.282) | - | - | - | - |
| Eating | −0.066 * (−0.252) | - | - | - | - |
| Death | 0.090 * (0.086) | - | - | - | 0.089 * (0.089) |
| Word count | - | 0.000 ** (0.175) | - | 0.000 ** (0.117) | 0.000 (0.077) |
| She/he | - | −0.014 ** (−0.119) | - | −0.044 ** (−0.478) | - |
| Prepositions | - | 0.007 * (0.106) | - | - | - |
| Informal | - | 0.052 ** (0.105) | 0.042 * (0.087) | - | - |
| Friends | - | −0.022 (−0.070) | - | - | - |
| Anger | - | 0.039 * (0.091) | 0.066 ** (0.156) | - | - |
| Insight | - | 0.012 * (0.095) | −0.014 * (−0.114) | - | - |
| Inclusive words | - | 0.011 ** (0.128) | - | - | - |
| Perception | - | −0.011 (−0.071) | - | - | - |
| Relativity | - | −0.025 * (−0.392) | - | - | - |
| Movement | - | −0.022 (0.155) | - | - | - |
| Space | - | 0.022 (0.205) | - | - | - |
| Time | - | 0.023 * (0.215) | - | - | - |
| Achievement | - | 0.013 ** (0.109) | 0.010 * (0.082) | - | 0.016 ** (0.124) |
| Pleasure | - | 0.010 ** (0.213) | - | - | - |
| Home | - | −0.026 * (−0.162) | - | −0.019 ** (−0.156) | - |
| Commas | - | 0.008 ** (0.112) | - | - | - |
| Quotes | - | 0.043 * (0.078) | - | - | - |
| I (me) | - | - | 0.006 (0.068) | −0.040 ** (−0.550) | −0.009 * (−0.089) |
| You | - | - | −0.026 (−0.077) | - | - |
| Anxiety | - | - | −0.058 ** (−0.139) | - | - |
| Cognitive processes c | - | - | 0.007 ** (0.164) | - | - |
| Tentativeness | - | - | −0.017 ** (−0.144) | - | - |
| Seeing | - | - | −0.022 (−0.072) | - | - |
| Religion | - | - | −0.068 (−0.064) | - | - |
| Question marks | - | - | 0.139 (0.065) | - | - |
| Dictionary words | - | - | - | 0.007 ** (0.222) | - |
| Determinants | - | - | - | −0.005 (−0.077) | - |
| Adverbs | - | - | - | −0.015 ** (−0.180) | - |
| Quantifiers | - | - | - | −0.012 ** (−0.114) | - |
| First person (verbs) | - | - | - | −0.010 ** (−0.109) | - |
| Second person (verbs) | - | - | - | −0.080 ** (−0.154) | - |
| Third person (verbs) | - | - | - | −0.025 * (−0.090) | - |
| Formal | - | - | - | 10.450 * (0.097) | - |
| Sexual | - | - | - | 0.053 ** (0.119) | - |
| Assent | - | - | - | −0.025 (0.072) | - |
| Colons | - | - | - | 0.053 * (0.090) | 0.052 (0.065) |
| Exclamations | - | - | - | 0.030 ** (0.109) | - |
| Negative Emotions | - | - | - | - | −0.036 ** (−0.178) |
| Certainty | - | - | - | - | −0.014 * (−0.085) |
| Hearing | - | - | - | - | −0.039 ** (−0.121) |
| Work | - | - | - | - | −0.021 ** (−0.157) |
| Dashes | - | - | - | - | −0.085 * (−0.084) |
| Apostrophes | - | - | - | - | 0.272 * (0.077) |
| Other punctuation | - | - | - | - | −0.070 * (−0.092) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez-Huertas, J.Á.; Moreno, J.D.; Olmos, R.; Martínez-Mingo, A.; Jorge-Botana, G. A Failed Cross-Validation Study on the Relationship between LIWC Linguistic Indicators and Personality: Exemplifying the Lack of Generalizability of Exploratory Studies. Psych 2022, 4, 803-815. https://doi.org/10.3390/psych4040059
Martínez-Huertas JÁ, Moreno JD, Olmos R, Martínez-Mingo A, Jorge-Botana G. A Failed Cross-Validation Study on the Relationship between LIWC Linguistic Indicators and Personality: Exemplifying the Lack of Generalizability of Exploratory Studies. Psych. 2022; 4(4):803-815. https://doi.org/10.3390/psych4040059
Chicago/Turabian StyleMartínez-Huertas, José Ángel, José David Moreno, Ricardo Olmos, Alejandro Martínez-Mingo, and Guillermo Jorge-Botana. 2022. "A Failed Cross-Validation Study on the Relationship between LIWC Linguistic Indicators and Personality: Exemplifying the Lack of Generalizability of Exploratory Studies" Psych 4, no. 4: 803-815. https://doi.org/10.3390/psych4040059
APA StyleMartínez-Huertas, J. Á., Moreno, J. D., Olmos, R., Martínez-Mingo, A., & Jorge-Botana, G. (2022). A Failed Cross-Validation Study on the Relationship between LIWC Linguistic Indicators and Personality: Exemplifying the Lack of Generalizability of Exploratory Studies. Psych, 4(4), 803-815. https://doi.org/10.3390/psych4040059