
Enhancing Spreading Factor Assignment in LoRaWAN with a Geometric Distribution Approach for Practical Node Distributions

Abstract
1. Introduction
- Performance: indication of the overall system throughput.
- Ease of implementation (complexity): indication of the amount of processing resource required at the gateway to decode a transmitted packet from a node.
- Application: indication of ability to handle dynamic scale of the network such as scenario mitigation, number of nodes, and inclusion and exclusion of nodes.
2. LoRaWAN Overview
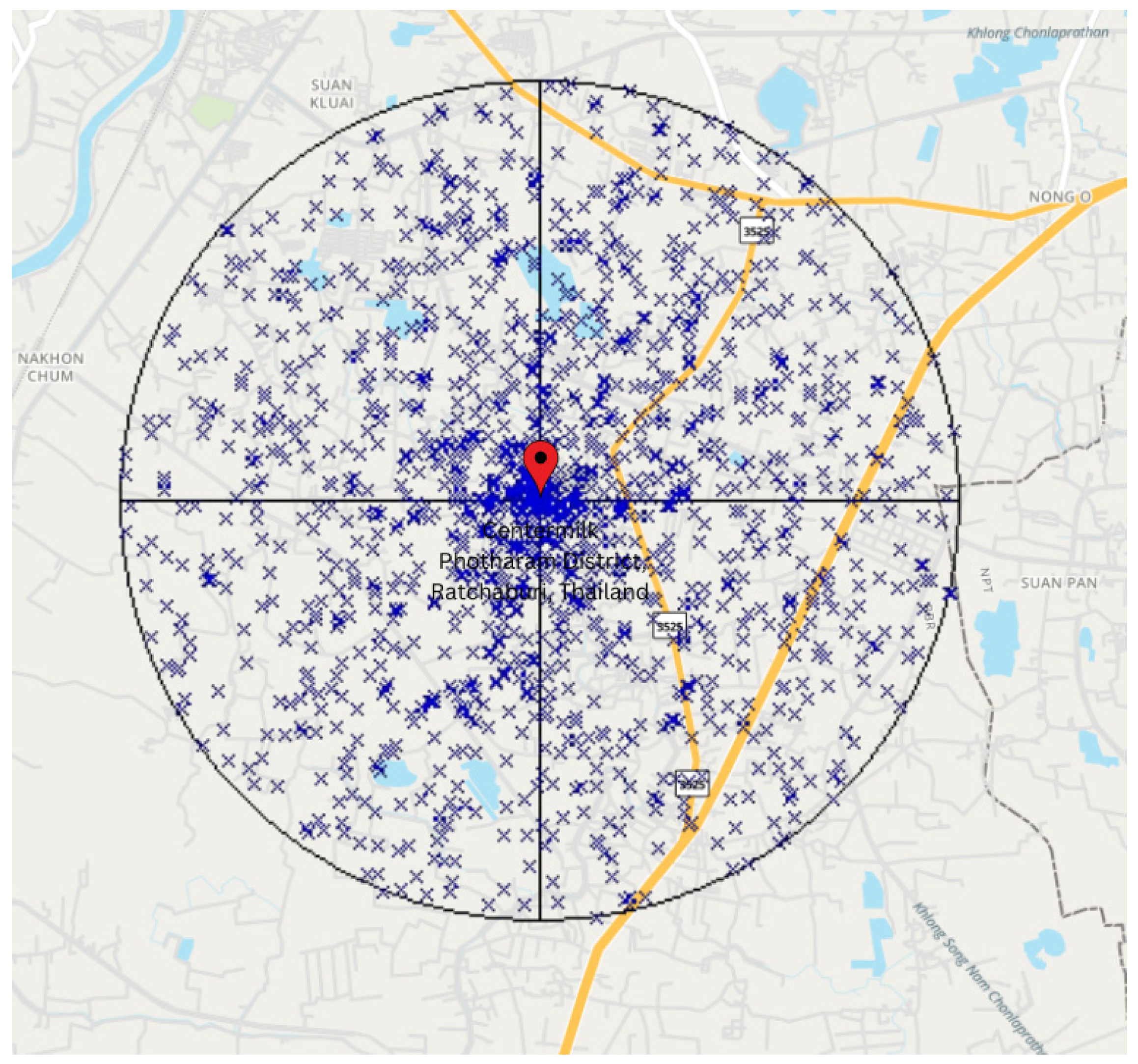
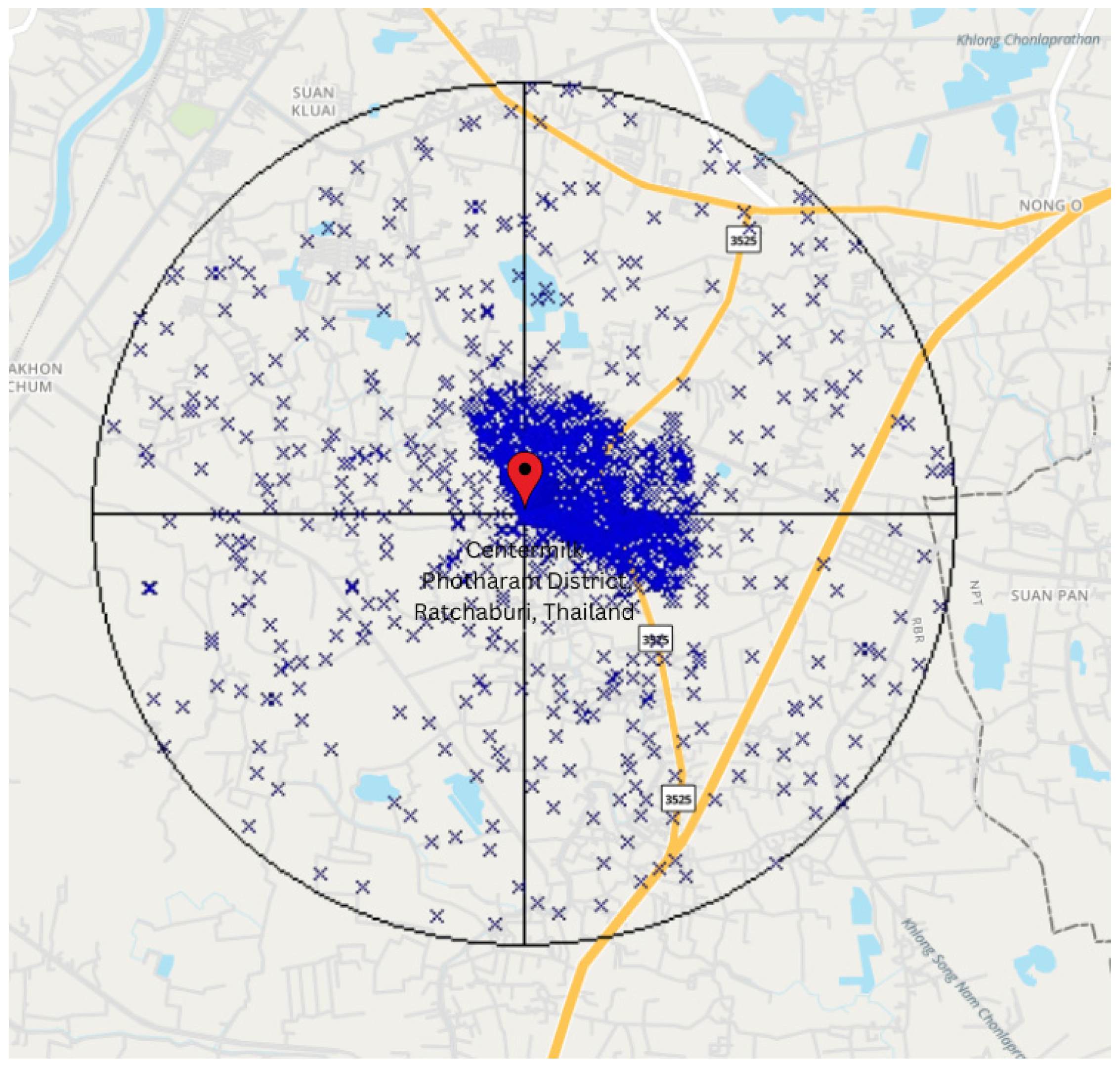
3. Network Simulations for Fixed and Uniform Random Patterns of Nodes
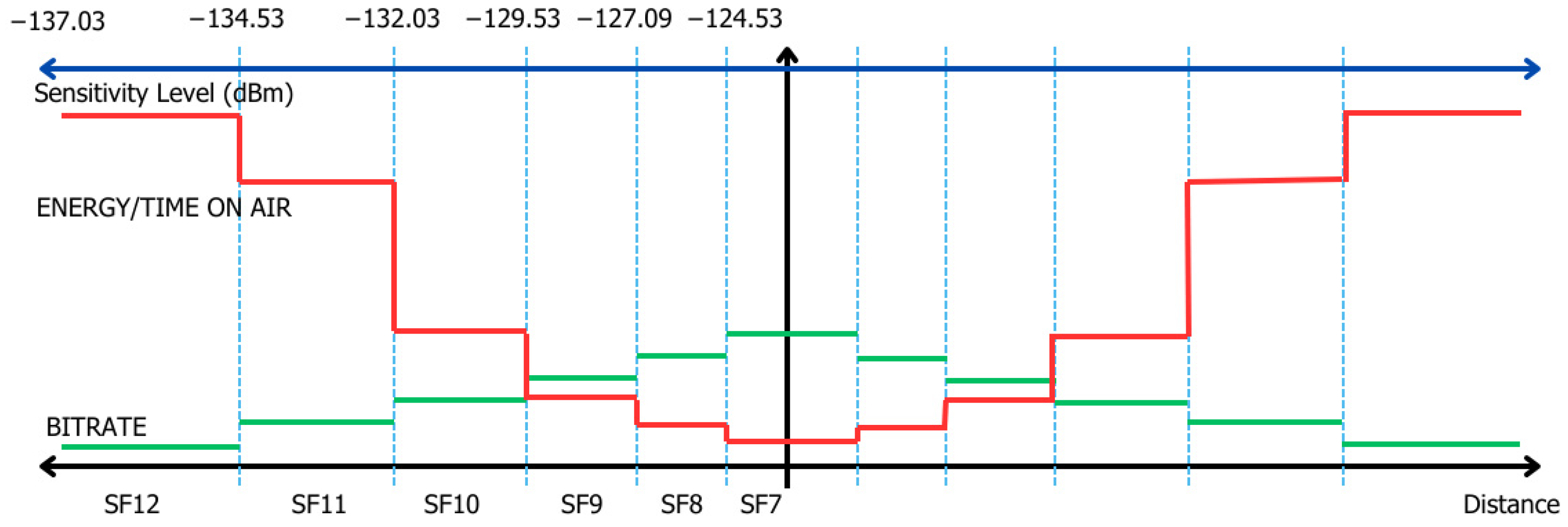
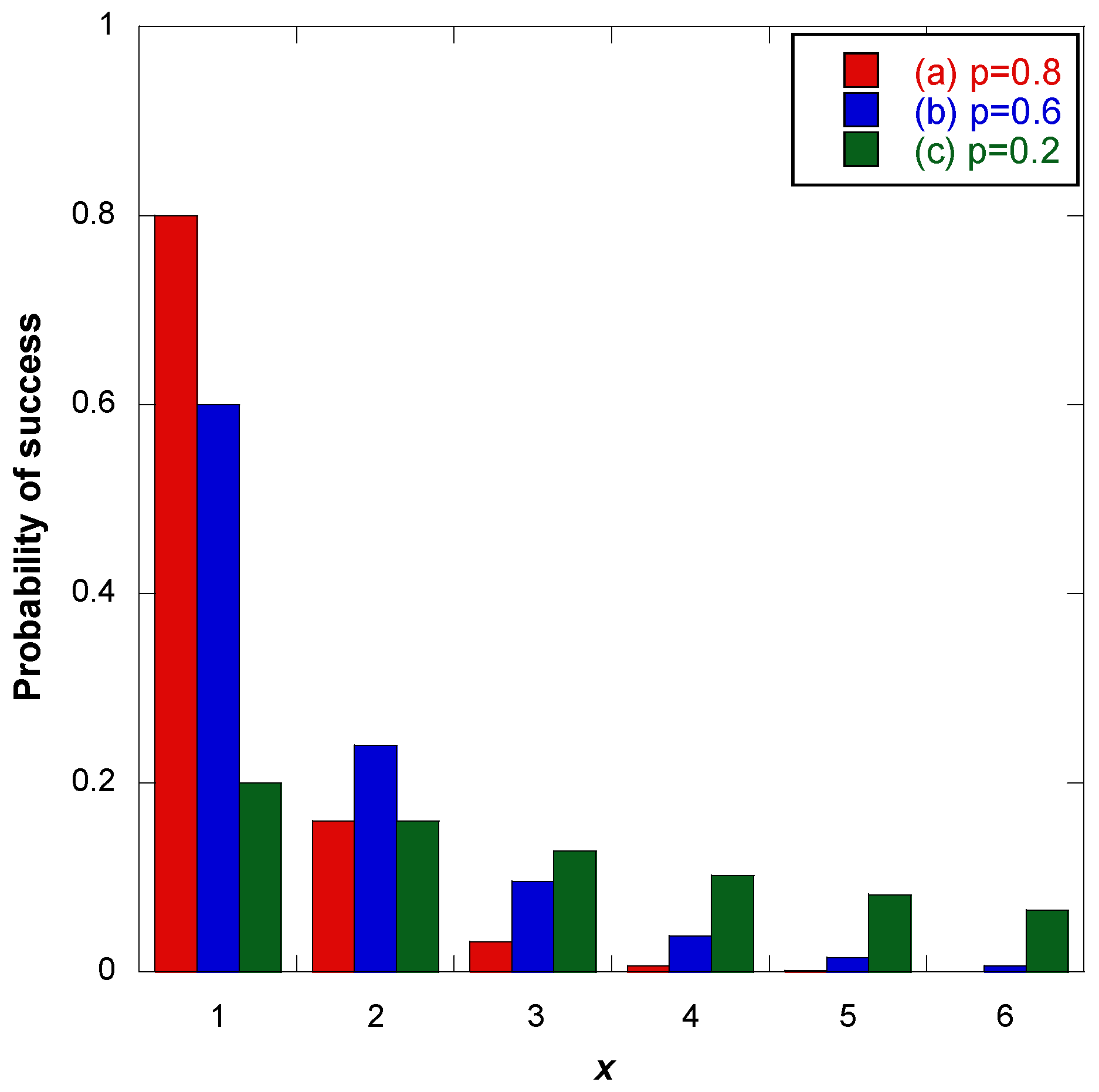
4. Geometric Distribution Approach
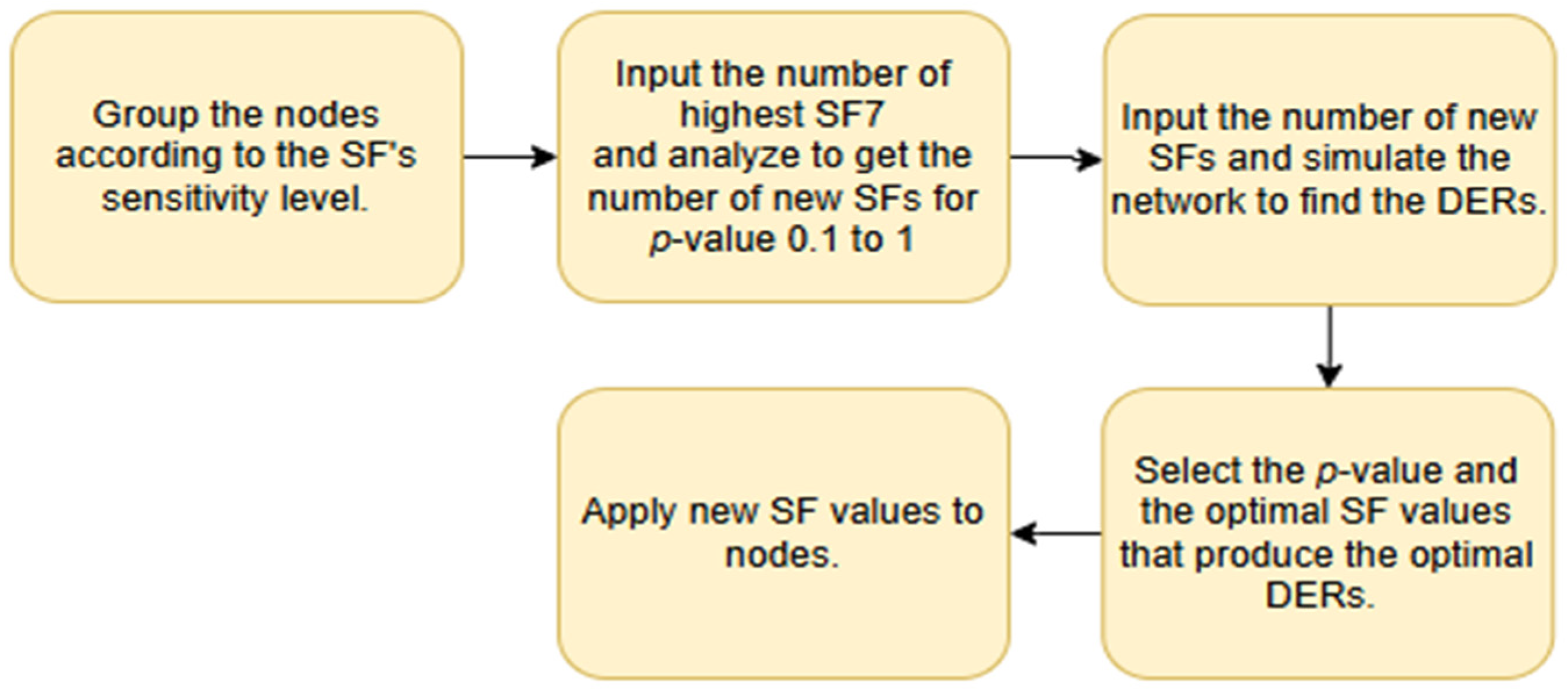
5. The Geometric Distribution Algorithm for SF Assignment
| Algorithm 1: Geometric distribution | |
| 1: | Input: Number of highest SF (NSF max) |
| 2: | Define: Weight factor (w) |
| 3: | Geometric distribution factor (p) |
| 4: | Initialize: p = 1 |
| 5: | Do |
| 6: | // Calculate the weight factor of each SF |
| 7: | w[x] ← p × (1 − p) ^ (x − 1) let x = 1, 2, 3, 4, 5, 6 |
| 8: | // Calculate the number of each SF |
| 9: | SF[y] ← NSF max × w[x] let x = 1, 2, 3, 4, 5, 6 and y = 7, 8, 9, 10, 11, 12 |
| 10: | // Return the new number of each SF |
| 11: | Return SF [7], SF [8], SF [9], SF [10], SF [11], SF [12] |
| 12: | p ← p − 0.1 |
| 13: | While p > 0.1 // p starts at 1 to 0.1, with 0.1 decrement |
6. Geometric Distribution Algorithm Performance Assessment
7. Results and Discussion
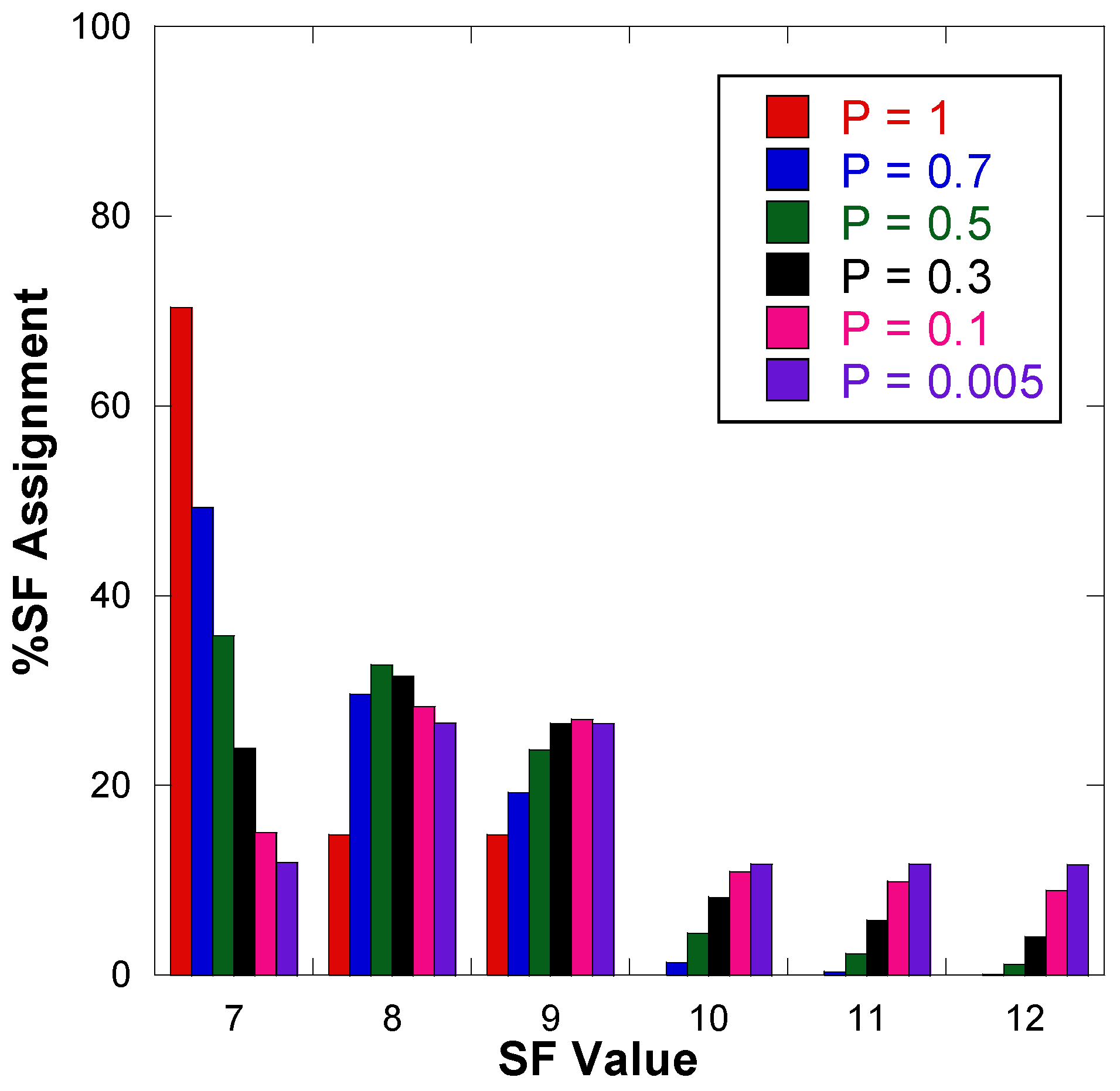
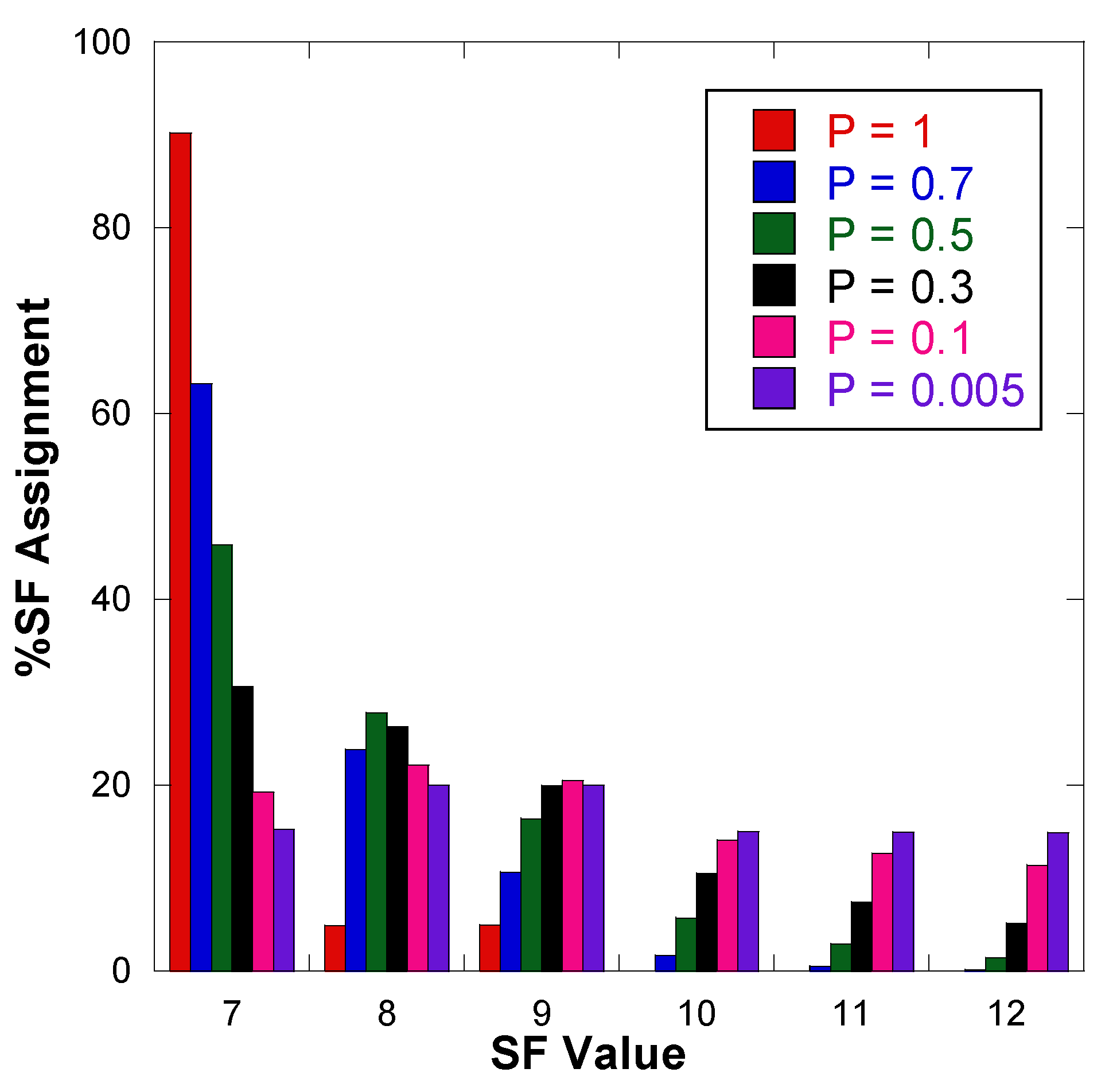
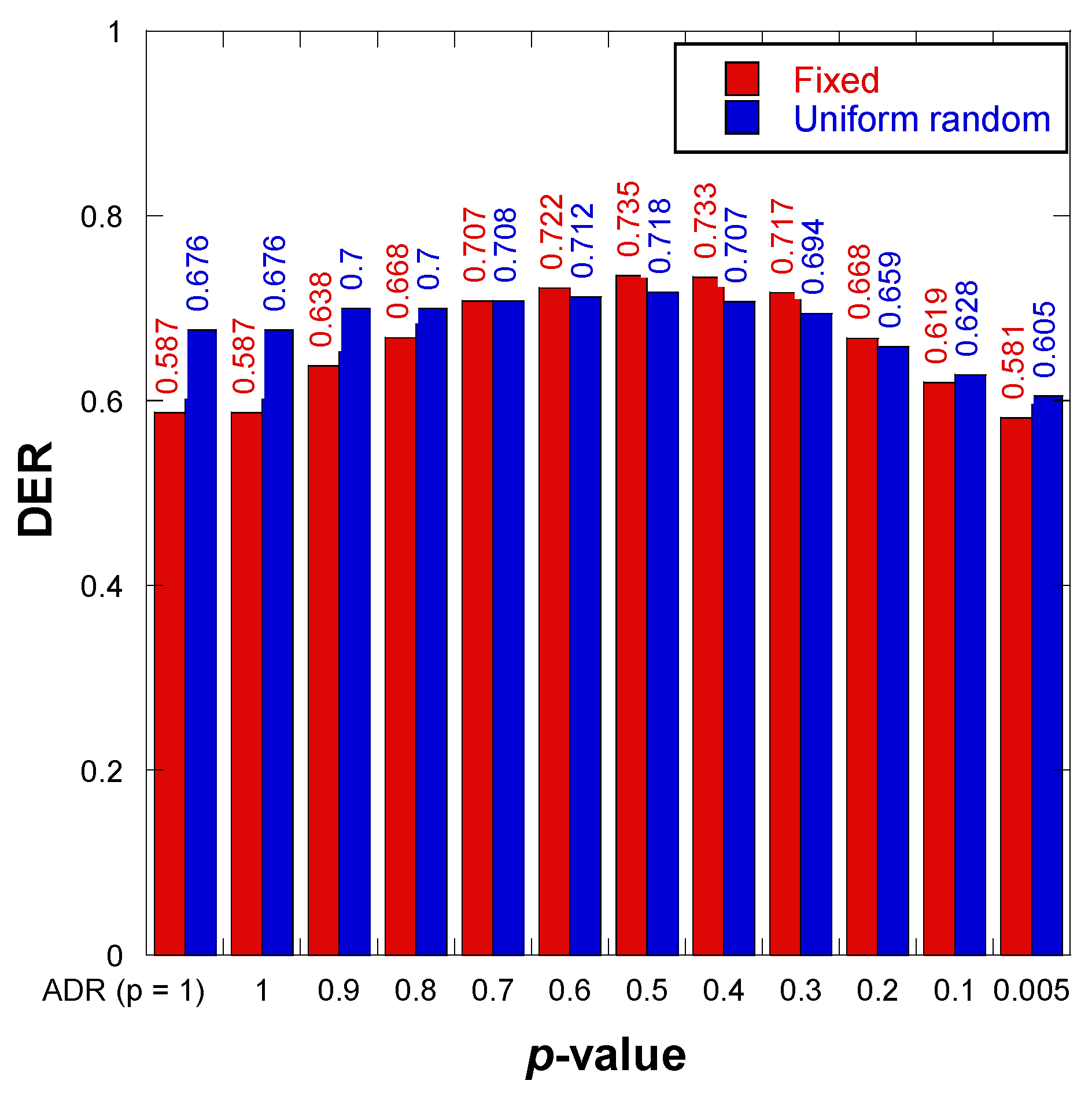
7.1. Experiment 1: Evaluation of the GD Algorithm for Uniform Random and Fixed Patterns
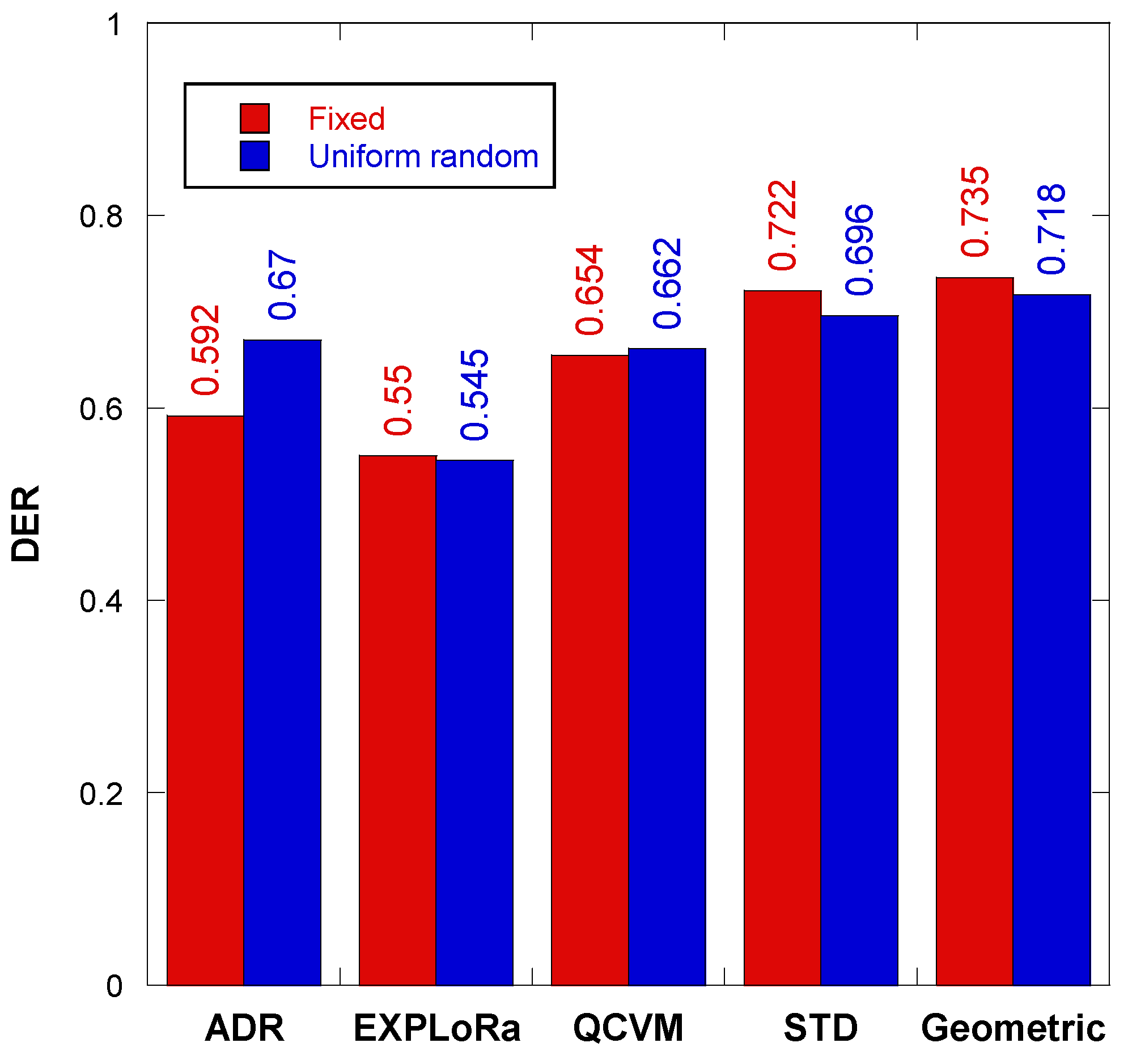
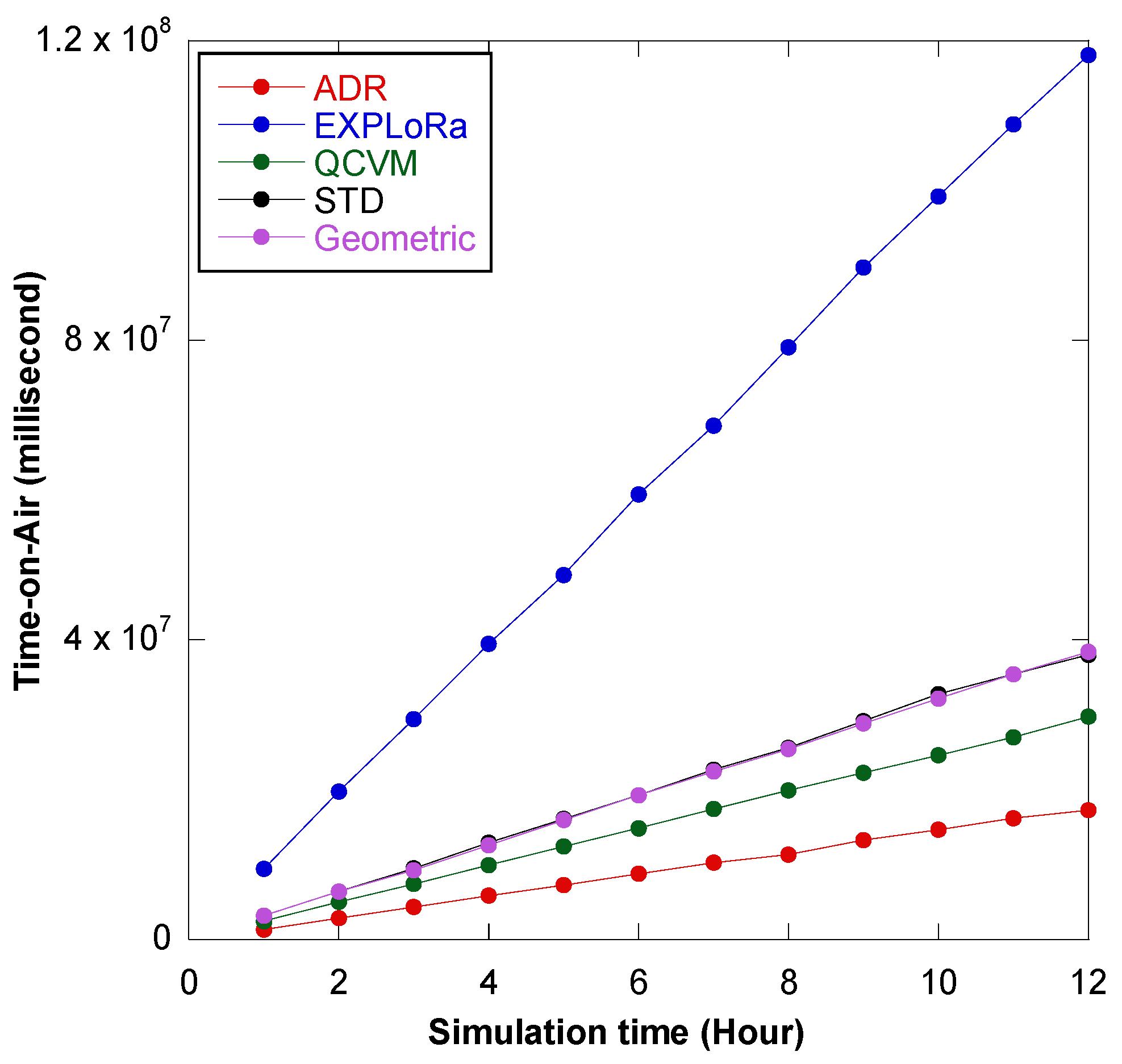
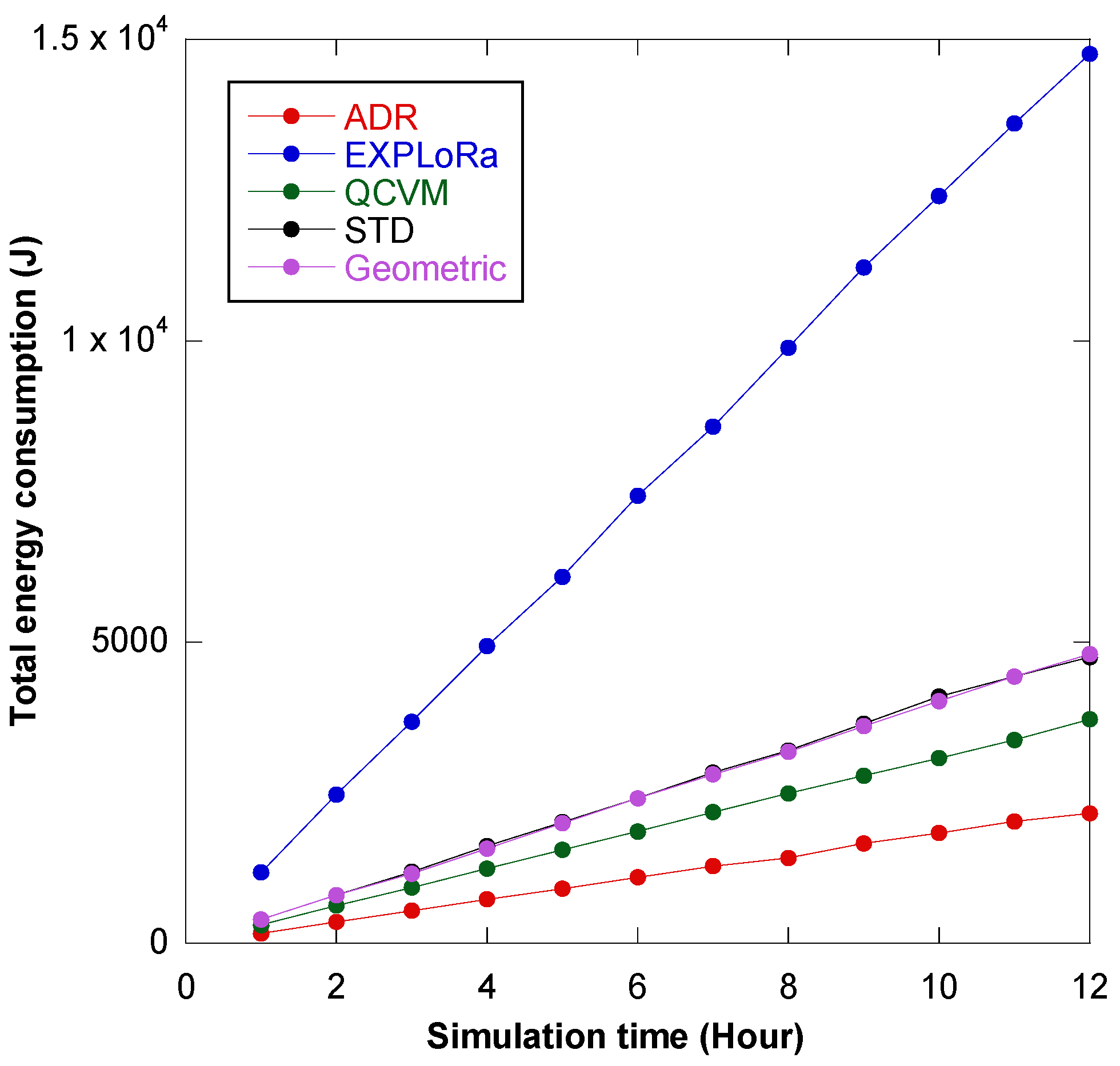
7.2. Experiment 2: Comparison of the GD Algorithm with Previous Reported Algorithms
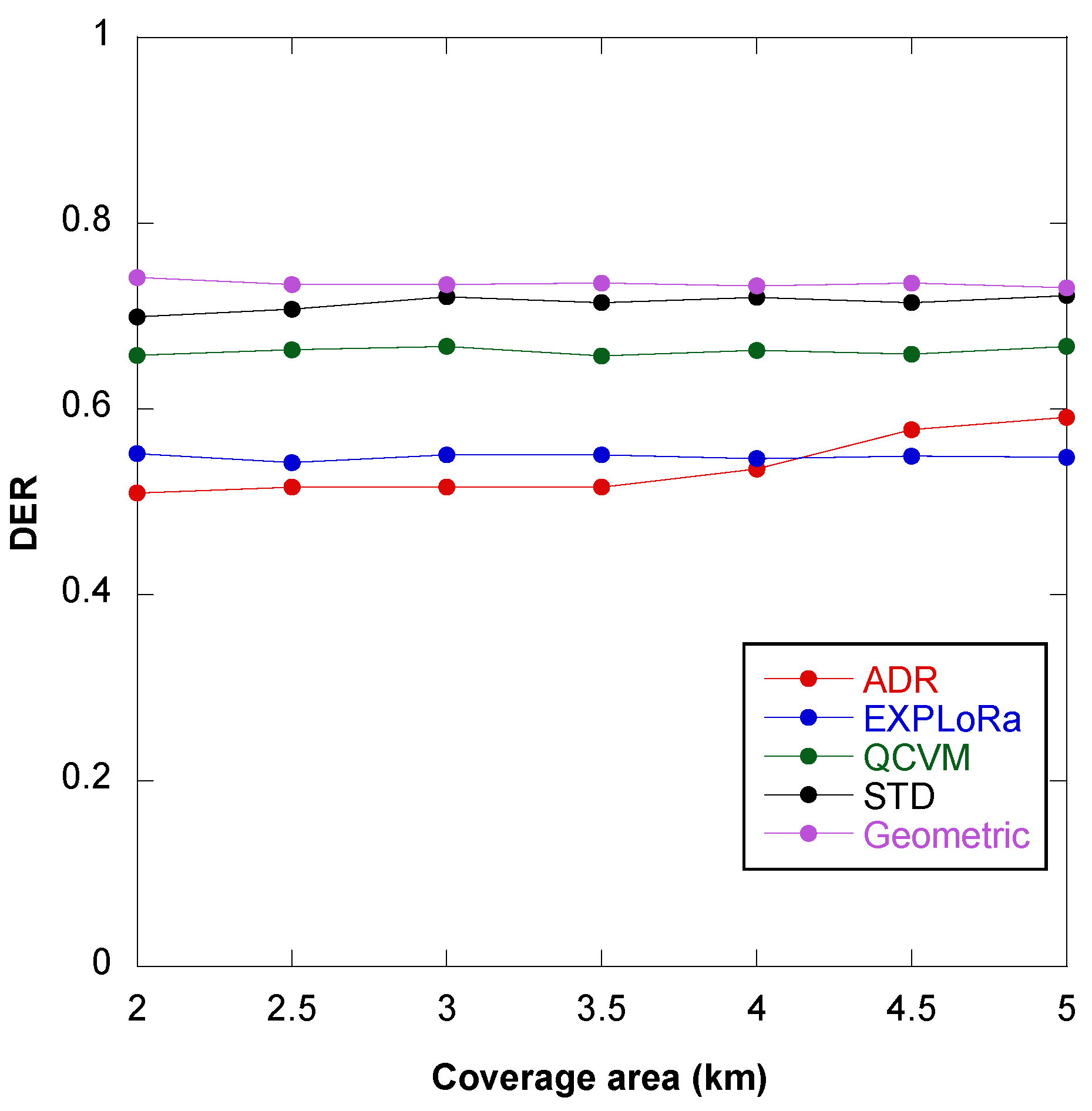
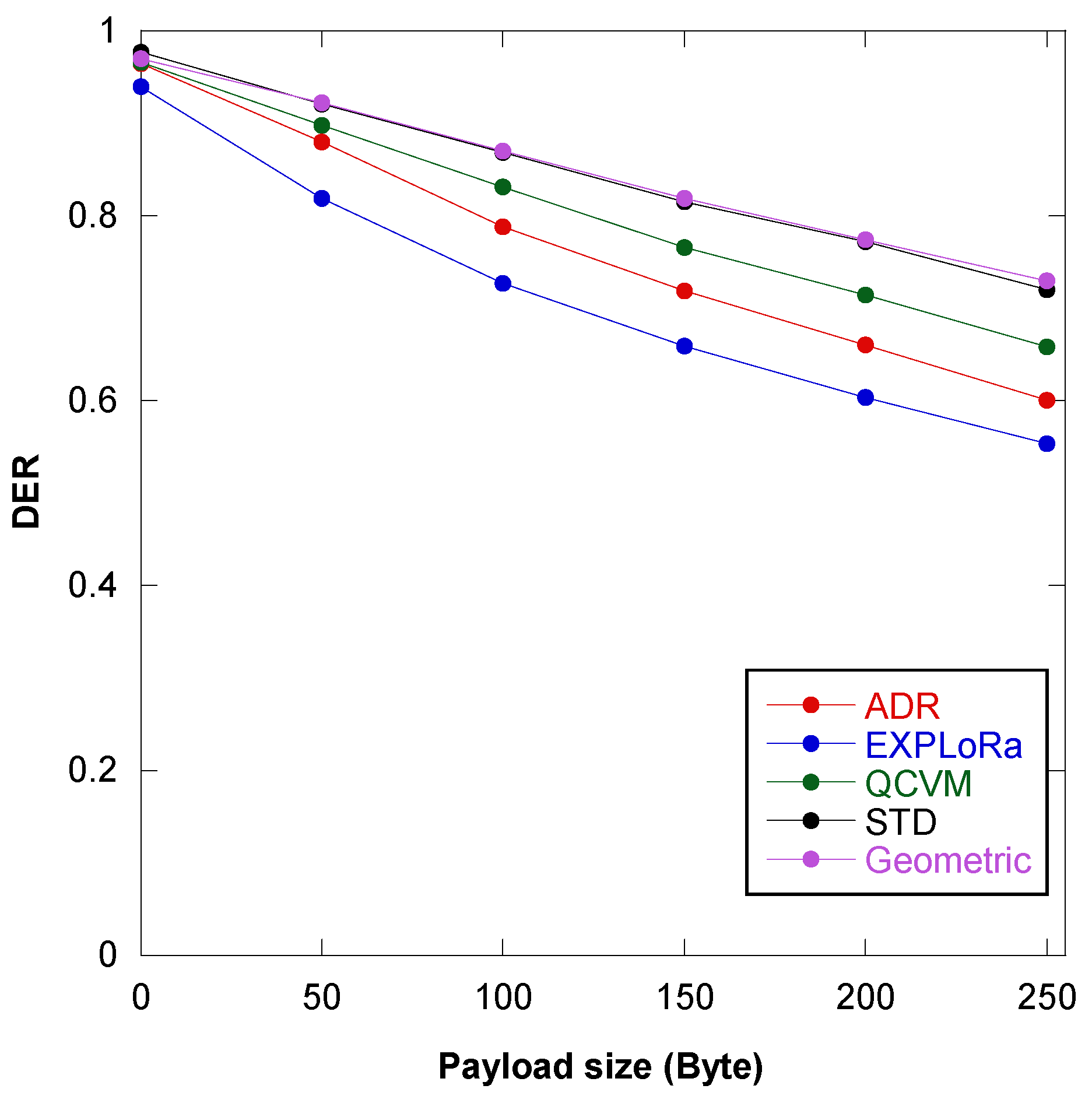
7.3. Experiment 3: Network Performance Evaluation of the GD Algorithm Based on Coverage Area, Payload Size, and Energy Consumption
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Augustin, A.; Yi, J.; Clausen, T.; Townsley, W.M. A Study of LoRa: Long Range & Low Power Networks for the Internet of Things. Sensors 2016, 16, 1466. [Google Scholar] [CrossRef] [PubMed]
- Haxhibeqiri, J.; De Poorter, E.; Moerman, I.; Hoebeke, J. A Survey of LoRaWAN for IoT: From Technology to Application. Sensors 2018, 18, 3995. [Google Scholar] [CrossRef] [PubMed]
- Mwakwata, C.B.; Malik, H.; Mahtab Alam, M.; Le Moullec, Y.; Parand, S.; Mumtaz, S. Narrowband Internet of Things (NB-IoT): From Physical (PHY) and Media Access Control (MAC) Layers Perspectives. Sensors 2019, 19, 2613. [Google Scholar] [CrossRef] [PubMed]
- Sigfox. Available online: https://www.sigfox.com (accessed on 14 November 2019).
- Mohamad, M. Performance Analysis of Air Monitoring System Using 433 MHz LoRa Module. Prz. Elektrotech. 2024, 1, 225–229. [Google Scholar] [CrossRef]
- Sujono, H. Drip Irrigation Control System Based on Mamdani Fuzzy Logic and Internet of Things (IoT). Prz. Elektrotech. 2024, 1, 65–69. [Google Scholar] [CrossRef]
- Boonsong, W. Proposed Precision Analysis of Water Quality Monitoring Embedded IoT Network. Prz. Elektrotech. 2023, 1, 177–180. [Google Scholar] [CrossRef]
- Sambor, S. Przykład Zastosowania Sieci LoRaWAN do Monitorowania Parametrów Środowiskowych w Budynku Wielkopowierzchniowym. Prz. Elektrotech. 2022, 1, 29–34. [Google Scholar] [CrossRef]
- Zankiewicz, A. Eksperymentalna Analiza Efektywności Transmisji Danych w Sieci LoRaWAN w Eksploatacji na Terenie Miejskim. Prz. Elektrotech. 2023, 1, 43–50. [Google Scholar] [CrossRef]
- El Chall, R.; Lahoud, S.; El Helou, M. LoRaWAN Network: Radio Propagation Models and Performance Evaluation in Various Environments in Lebanon. IEEE Internet Things J. 2019, 6, 2366–2378. [Google Scholar] [CrossRef]
- Semtech Corporation. Understanding the LoRa Adaptive Data Rate. Available online: https://learn.semtech.com/mod/page/view.php?id=136 (accessed on 20 December 2019).
- Mahmood, A.; Ge Sisinni, E.; Guntupalli, L.; Rondon, R.; Hassan, S.A.; Gidlund, M. Scalability Analysis of a LoRa Network under Imperfect Orthogonality. IEEE Trans. Ind. Inform. 2019, 15, 1425–1436. [Google Scholar] [CrossRef]
- Saluja, D.; Singh, R.; Baghel, L.K.; Kumar, S. Scalability Analysis of LoRa Network for SNR-Based SF Allocation Scheme. IEEE Trans. Ind. Inform. 2021, 17, 6709–6719. [Google Scholar] [CrossRef]
- Al-Gumaei, Y.A.; Aslam, N.; Chen, X.; Raza, M.; Ansari, R.I. Optimizing Power Allocation in LoRaWAN IoT Applications. IEEE Internet Things J. 2022, 9, 3429–3442. [Google Scholar] [CrossRef]
- Cuomo, F.; Campo, M.; Caponi, A.; Bianchi, G.; Rossini, G.; Pisani, P. EXPLoRa: Extending the Performance of LoRa by Suitable Spreading Factor Allocations. In Proceedings of the 2017 IEEE 13th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Rome, Italy, 9–11 October 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Garlisi, D.; Tinnirello, I.; Bianchi, G.; Cuomo, F. Capture Aware Sequential Waterfilling for LoRaWAN Adaptive Data Rate. IEEE Trans. Wirel. Commun. 2021, 20, 2019–2033. [Google Scholar] [CrossRef]
- Hong, S.; Yao, F.; Zhang, F.; Ding, Y.; Yang, S.-H. Reinforcement Learning Approach for SF Allocation in LoRa Network. IEEE Internet Things J. 2023, 10, 18259–18272. [Google Scholar] [CrossRef]
- Usama Minhaj, S.; Mahmood, A.; Fakhrul Abedin, S.; Ali Hassan, S.; Talha Bhatti, M.; Ali, S.; Gidlund, M. Intelligent Resource Allocation in LoRaWAN Using Machine Learning Techniques. IEEE Access 2023, 11, 10092–10106. [Google Scholar] [CrossRef]
- Tempiem, P.; Silapunt, R. Quantile Classification of Variance from the Mean for Spreading Factor Allocation in LoRaWAN. In Proceedings of the 2020 5th International Conference on Information Technology (InCIT), Chonburi, Thailand, 21–22 October 2020; pp. 179–184. [Google Scholar] [CrossRef]
- Tempiem, P.; Silapunt, R. Spreading Factor Allocation Using the Standard Deviation Classification Method. In Proceedings of the 2020 International Symposium on Antennas and Propagation (ISAP), Osaka, Japan, 25–28 January 2021; pp. 145–146. [Google Scholar] [CrossRef]
- Poluektov, D.; Polovov, M.; Kharin, P.; Štůsek, M.; Zeman, K.; Masek, P.; Kochetkova, I.; Hosek, J.; Samouylov, K. On the Performance of LoRaWAN in Smart City: End-Device Design and Communication Coverage. In Distributed Computer and Communication Networks; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Harinda, E.; Hosseinzadeh, S.; Larijani, H.; Gibson, R.M. Comparative Performance Analysis of Empirical Propagation Models for LoRaWAN 868MHz in an Urban Scenario. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019; pp. 154–159. [Google Scholar] [CrossRef]
- Kamonkusonman, K.; Phunthawornwong, M.; Tempiem, P.; Silapunt, R. Utilization-Weighted Algorithm for LoRaWAN Capacity Improvement for Local Smart Dairy Farms in Ratchaburi Province of Thailand. IEEE Access 2021, 9, 141738–141746. [Google Scholar] [CrossRef]
- Britannica. Geometric Distribution Probability. Available online: https://www.britannica.com/topic/geometric-distribution (accessed on 14 February 2024).
- Maurya, P.; Singh, A.; Kherani, A.A. A Review: Spreading factor allocation schemes for LoRaWAN. Telecommun. Syst. 2022, 80, 449–468. [Google Scholar] [CrossRef]
- Molisch, A.F. Wireless Communications Handbook; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Morariu, C.; Morariu, O.; Răileanu, S.; Borangiu, T. Machine learning for predictive scheduling and resource allocation in large scale manufacturing systems. Comput. Ind. 2020, 120, 103244. [Google Scholar] [CrossRef]
- Luo, F.L. Machine Learning for Optimal Resource Allocation. In Machine Learning for Future Wireless Communications; Wiley-IEEE Press: Hoboken, NJ, USA, 2020; pp. 85–103. [Google Scholar] [CrossRef]
- Mak, H.W.L.; Han, R.; Yin, H.H.F. Application of Variational AutoEncoder (VAE) Model and Image Processing Approaches in Game Design. Sensors 2023, 23, 3457. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SF Allocation Scheme | Approach and References | Publication Year | Contribution |
|---|---|---|---|
| ADR | Adaptive data rate [11] | 2019 | The ADR scheme is a default mechanism of LoRaWAN that allows the network to dynamically adjust the data rate and spreading factor (SF) of a device’s transmission based on its signal quality and network load. |
| SNR-based SFs | SNR-based allocation [13] | 2021 | This paper introduced an SF allocation scheme based on the target Signal-to-Noise Ratio (SNR) of the received packet and the impact of channel fading and distance. |
| Best-Equal LoRa (BE-LoRa) [14] | 2022 | This paper introduced an SF allocation scheme through the optimization and balancing of the SINR of received packets at the gateway for proper power setting and SF updates. | |
| RSSI-based SFs | EXPLoRa-SF [15] | 2017 | This paper introduced a SF allocation scheme where SFs were distributed equally to the nodes based on their RSSI values to create coexisting orthogonal sub-channels in the same channel bandwidth, enabling simultaneous communication among all nodes. |
| Time-on-Air-based SFs | EXPLoRa-AT [15] | 2017 | This paper introduced an SF allocation scheme by balancing the total offered packets (load) through the ordered waterfilling of SFs that then guaranteed the ToA equalization in each SF group. |
| EXPLoRa-C [16] | 2021 | This paper introduced an SF allocation scheme by demonstrating a concept of sequential waterfilling, where nodes were firstly ordered based on their RSSI values and then were allocated to the given SF group until the total offered packets in the group is full. | |
| Distance-based SFs | EIB and EAB [12] | 2018 | This paper proposed two SF allocation schemes: EIB, which divides the network area into concentric circles of equal intervals, and EAB, which uses equal areas. In the EIB scheme, lower SFs are assigned to inner annuli, resulting in higher packet success probability in interference-prone environments. Conversely, the EAB scheme improves packet success probability at longer distances by mitigating near–far effects in smaller outer annuli. |
| Machine learning-based SFs | 2023 | This paper proposed the LR-RL algorithm, which is a reinforcement learning algorithm designed to optimize SF allocation based on channel traffic equilibrium, aiming at mitigating packet collisions. Nodes will receive positive rewards for successful packet delivery and negative rewards otherwise. | |
| LR-RL [17] Decentralized reinforcement learning [18] | 2023 | This paper proposed the SF allocation scheme by treating the SF allocation as a contextual multi-arm bandit problem, which was solved for packet reception ratio (PRR) maximization using the decentralized EXP4 reinforcement learning algorithm that can converge quickly. | |
| Descriptive Statistics-based SFs | Quantile classification of the variance from the mean [19] | 2021 | This paper introduced an SF allocation scheme where the quantile classification was applied to assign new SFs based on the mean and probability density function (PDF) of the RSSI data in each original SF group. |
| Standard deviation classification [20] | 2021 | This paper introduced an SF allocation scheme where the standard deviation was applied to assign new SFs based on the mean and standard deviation of the RSSI data inside each original SF group. | |
| This paper | Geometric Distribution (GD) | 2024 | This paper introduces an SF allocation scheme by using the Geometric Distribution (GD) algorithm, a novel inferential statistics approach to address the challenge of non-uniform or biased SF node distribution. The algorithm possesses flexibility in finely tuning the weight factor (w) via an intricately linked geometric distribution factor (p-value) until the optimal p-value and corresponding weight factor (w) that yields the highest DER of the network are identified. |
| SF Allocation Scheme | Type | Performance | Ease of Implementation (Complexity) | Application | References |
|---|---|---|---|---|---|
| ADR | Dynamic | High | High | Yes | [11,25] |
| SNR-based SFs | Dynamic | High | High | Yes | [13,14,25] |
| RSSI-based SFs | Dynamic | Moderate | Moderate | Yes | [15,16] |
| Time-on-Air-based SFs | Dynamic | High | Moderate | Yes | [15,16] |
| Distance-based SFs | Static | Moderate | Moderate | No | [12,25] |
| Machine learning-based SFs | Dynamic | High | High | Yes | [17,18,25] |
| Descriptive Statistics-based SFs | Dynamic | QCVM—Moderate SD–High | Moderate | Yes | [19,20] |
| The proposed GD algorithm | Dynamic | High | Moderate | Yes | This paper |
| Coverage Area | Pattern | %SF7 | %SF8 | %SF9 | %SF10 | %SF11 | %SF12 | DER Value |
|---|---|---|---|---|---|---|---|---|
| 2 km | Uniform random | 100.00 | - | - | - | - | - | 0.514 |
| Fixed | 100.00 | - | - | - | - | - | 0.510 | |
| 3 km | Uniform random | 100.00 | - | - | - | - | - | 0.512 |
| Fixed | 100.00 | - | - | - | - | - | 0.514 | |
| 4 km | Uniform random | 87.60 | 12.40 | - | - | - | - | 0.600 |
| Fixed | 96.53 | 3.47 | - | - | - | - | 0.538 | |
| 5 km | Uniform random | 70.33 | 15.40 | 14.27 | - | - | - | 0.676 |
| Fixed | 89.53 | 4.93 | 5.53 | - | - | - | 0.589 |
| p-Value | w1 | w2 | w3 | w4 | w5 | w6 |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0.9 | 0.90 | 0.09 | 0.01 | 0.00 | 0.00 | 0.00 |
| 0.8 | 0.80 | 0.16 | 0.03 | 0.01 | 0.00 | 0.00 |
| 0.7 | 0.70 | 0.21 | 0.06 | 0.02 | 0.01 | 0.00 |
| 0.6 | 0.60 | 0.24 | 0.10 | 0.04 | 0.02 | 0.01 |
| 0.5 | 0.51 | 0.25 | 0.13 | 0.06 | 0.03 | 0.02 |
| 0.4 | 0.42 | 0.25 | 0.15 | 0.09 | 0.05 | 0.03 |
| 0.3 | 0.34 | 0.24 | 0.17 | 0.12 | 0.08 | 0.06 |
| 0.2 | 0.27 | 0.22 | 0.17 | 0.14 | 0.11 | 0.09 |
| 0.1 | 0.21 | 0.19 | 0.17 | 0.16 | 0.14 | 0.13 |
| 0.005 | 0.17 | 0.17 | 0.17 | 0.17 | 0.17 | 0.16 |
| Parameter | Value |
|---|---|
| Number of nodes | 1500 |
| Number of gateways | 1 |
| Node transmitted power | 14 dBm |
| Simulation time | 43,200 s (12 h) |
| Average sending message time | 1800 s (30 min) |
| Bandwidth | 125 kHz |
| Frequency (AS923) | 923 MHz |
| Path-loss model | Suburban Hata–Okumura |
| Payload size | 255 bytes |
| Coverage area | 5 km |
| Algorithm | %SF7 | %SF8 | %SF9 | %SF10 | %SF11 | %SF12 |
|---|---|---|---|---|---|---|
| Default ADR | 70.00 | 16.53 | 13.47 | 0.00 | 0.00 | 0.00 |
| EXPLoRa | 16.67 | 16.67 | 16.67 | 16.67 | 16.67 | 16.67 |
| QCVM | 33.40 | 33.40 | 33.20 | 0.00 | 0.00 | 0.00 |
| SD | 25.60 | 37.47 | 14.27 | 14.47 | 6.33 | 1.87 |
| GD (p = 0.5) | 34.73 | 33.13 | 24.60 | 4.07 | 2.07 | 1.40 |
| Algorithm | %SF7 | %SF8 | %SF9 | %SF10 | %SF11 | %SF12 |
|---|---|---|---|---|---|---|
| Default ADR | 89.67 | 5.40 | 4.93 | 0.00 | 0.00 | 0.00 |
| EXPLoRa | 16.67 | 16.67 | 16.67 | 16.67 | 16.67 | 16.67 |
| QCVM | 33.40 | 33.40 | 33.20 | 0.00 | 0.00 | 0.00 |
| SD | 35.20 | 32.73 | 17.33 | 12.67 | 1.33 | 0.73 |
| GD (p = 0.5) | 45.53 | 27.67 | 16.93 | 5.40 | 2.67 | 1.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tempiem, P.; Silapunt, R. Enhancing Spreading Factor Assignment in LoRaWAN with a Geometric Distribution Approach for Practical Node Distributions. Telecom 2024, 5, 941-960. https://doi.org/10.3390/telecom5040047
Tempiem P, Silapunt R. Enhancing Spreading Factor Assignment in LoRaWAN with a Geometric Distribution Approach for Practical Node Distributions. Telecom. 2024; 5(4):941-960. https://doi.org/10.3390/telecom5040047
Chicago/Turabian StyleTempiem, Phanupong, and Rardchawadee Silapunt. 2024. "Enhancing Spreading Factor Assignment in LoRaWAN with a Geometric Distribution Approach for Practical Node Distributions" Telecom 5, no. 4: 941-960. https://doi.org/10.3390/telecom5040047
APA StyleTempiem, P., & Silapunt, R. (2024). Enhancing Spreading Factor Assignment in LoRaWAN with a Geometric Distribution Approach for Practical Node Distributions. Telecom, 5(4), 941-960. https://doi.org/10.3390/telecom5040047