2.1. Artificial Neural Networks
The objective of spectral radionuclide identification is to produce a function which maps a gamma-ray spectrum to an output vector corresponding to the presence or absence of N different sources of interest. In spectral anomaly detection, the procedure simply outputs a binary value indicating the presence or absence of an anomalous source, without attempting to identify sources. Neural networks are a general data-driven method for performing function approximation, and are capable of producing functions for performing detection and identification.
The first applications of neural networks for source identification were examined between the early 1990s and 2000s [
2,
7,
8,
9,
10], with networks that mapped input spectra to the relative amount of known background and sources contained within the spectrum. More recently, modern approaches to perform identification using neural networks have been developed [
3,
11,
12,
13,
14,
15], using methods similar to those seen since the deep learning boom of the early 2010s (e.g., ref. [
16]). Recent research in the area (e.g., refs. [
12,
13,
14]) has emphasized methodologies that are more applicable to nuclear safety and security, however, due to a lack of a characterization of these methods under operationally-relevant conditions, compared to a known benchmark method, the utility of these methods remains unclear. Additionally, the use of neural networks for spectral anomaly detection has not been previously studied, and this work begins by briefly introducing networks that can be used to accomplish this.
Neural networks are used to form a function
f which operates on an input
(e.g., an image or gamma-ray spectrum), producing an output
. The function
f consists of a series of relatively simple operations, which are parameterized by a set of learned model parameters
. Neural networks can generally be considered a composition of
l different functions, that is,
where the output of composed function up to
is referred to as the
layer, denoted by
. Equation (
1) specifically defines a
feedforward neural network, which can be represented as a directed acyclic graph. This is in contrast to a
recurrent neural network (RNN), which contains cycles and is used for modeling sequential data.
Section 2.3 introduces the use of RNNs for performing spectral identification using temporal sequences of spectra.
For a defined functional form of
f, the parameters
are estimated from examples of pairs of inputs
and corresponding target values of output
, such that
. The functional form of commonly-used layer types are provided in
Appendix A. The following sections provide functional forms of
f for accomplishing both detection and identification, as well as the procedure for estimating
.
2.2. Spectral Anomaly Detection using Autoencoders
Generally speaking, spectral anomaly detection can be performed by generating an estimate
of the background in an input spectrum
, and computing an error measure
between the two.
is chosen to measure differences between the two inputs, and a threshold
T is set, either empirically or analytically using statistical principles, to alarm on spectra that exceed this threshold.
Autoencoders [
17,
18] are a type of neural network suitable for performing the background estimation required for anomaly detection. Autoencoders are used to produce an output that is approximately equal to the input, meaning a function
f is learned such that
Undercomplete autoencoders, which perform dimensionality reduction to learn salient features about the input data, are examined in this work. Note that it is not expected for an undercomplete autoencoder to reproduce the input exactly, but instead that it returns a denoised copy of the input. The general architecture for an undercomplete autoencoder is to reduce the dimensionality using an encoder, then increase to the input dimensionality using a decoder. For anomaly detection, the parameters of f are learned from background spectra, and ideally, spectra containing anomalous sources are reconstructed less accurately, resulting in higher detection metrics.
Counts in the input spectra are assumed to be Poisson-distributed, leading to the use of a Poisson negative log-likelihood loss function of the form
for a mini-batch
of
n d-dimensional spectra and corresponding autoencoder output
. By minimizing the loss function in Equation (
3), the network seeks a solution
that is the Poisson mean of the input
(i.e.,
), meaning that
provides a denoised version of the input. Deviance [
19] is used here as a goodness-of-fit measure between input spectra and their corresponding autoencoder reconstructions. In essence, deviance gives a measure of the difference between an ideal model where each parameter is known exactly (i.e.,
), and the model determined from maximum likelihood estimation (i.e.,
). For a spectrum
and associated reconstruction
, the Poisson deviance is computed as
and used as a detection metric. The detection threshold is produced empirically from known background data. Specifically,
is computed on background spectra, giving a distribution of test statistics, and for a given FAR, a threshold is empirically set using this distribution.
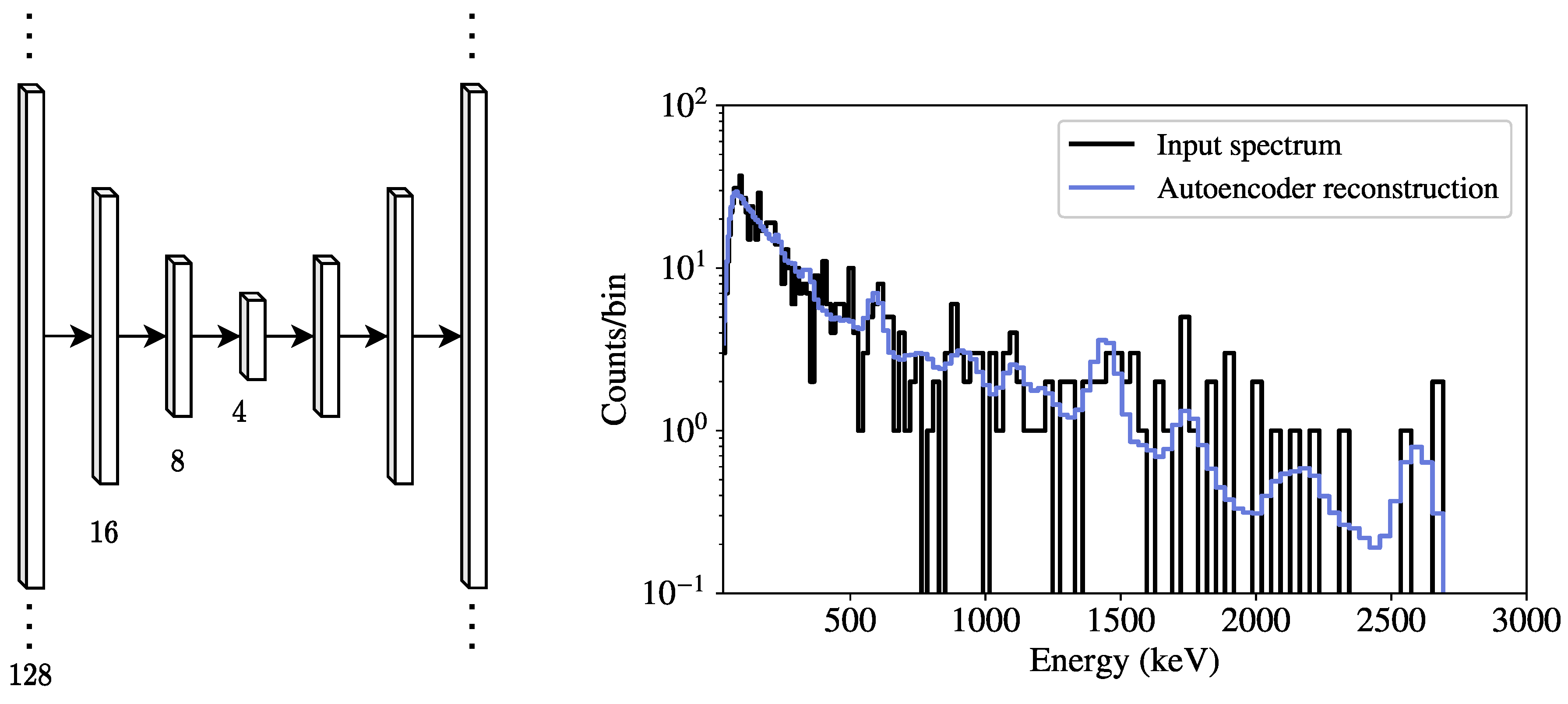
Encoders and decoders can be built from arbitrary combinations of dense and convolutional layers. Both dense autoencoders (DAE) and convolutional autoencoders were seen to perform comparably during experimentation, but only DAEs are examined here due to their relative simplicity. In this work, only symmetric DAEs (i.e., decoders that mirror the encoders) are considered here, as it reduces the hyperparameter search space. A DAE with five hidden layers (seven layers total when including the input and output), each using a rectified linear unit (ReLU) activation function, is used to demonstrate spectral anomaly detection. This particular configuration was seen to perform sufficiently well for this initial assessment and the hyperparameter space explored. The number of neurons in each dense layer is found via a random optimization, described further below.
Figure 1 shows a diagram of an example dense autoencoder, along with a sample input spectrum
and its corresponding reconstructed spectrum
. By training the autoencoder using the Poisson loss in Equation (
3),
can be seen as a sample from a Poisson distribution with mean rate
. As a result,
contains smoothened spectral features corresponding to background peaks (e.g.,
40K at 1460 keV) and the associated downscattering continuum, seen in
Figure 1.
2.3. Source Identification
In performing identification, an input spectrum
is mapped to an output vector
indicating the presence or absence of a source. In many common applications of neural networks for classification, the mapping from
to
involves encoding one or more classes of instances present in
as
(e.g., an image
containing a dog, encoded in
). In gamma-ray spectroscopy, however, background contributions will always be present in a given spectrum, and sources will appear in different proportions, or sources could potentially be shielded by attenuating material. As a result, the standard method of directly predicting a vector
, with a 1 at element
i indicating the presence of class
i, is generally not performed. Instead, the output
is treated as the proportion of each source and background to the spectrum, such that
, meaning the network is performing regression. To achieve this behavior, the output of the network
is passed to the softmax function, defined as
for each network output
, which outputs values between 0 and 1.
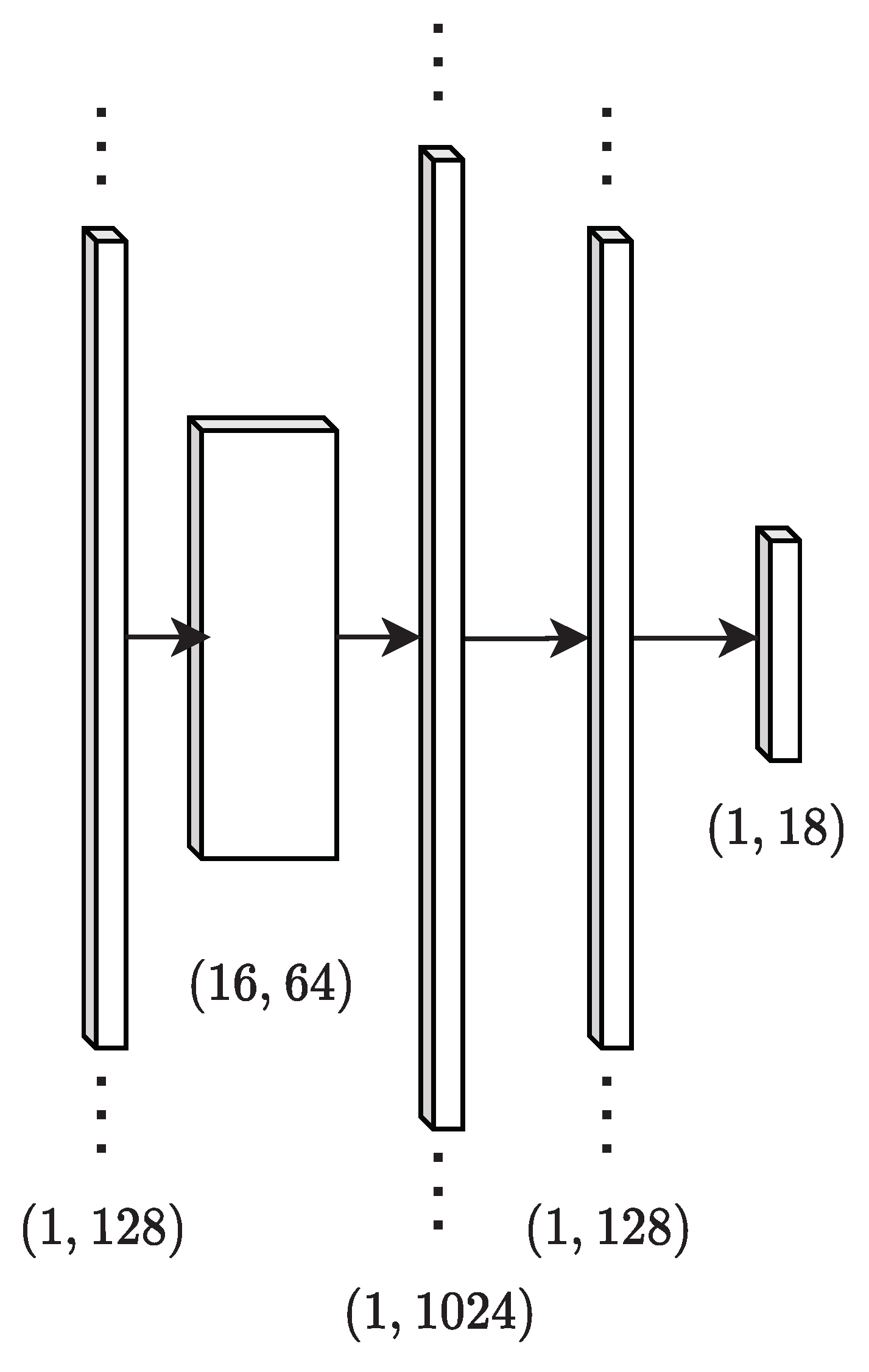
A common approach to such classification problems (e.g., in the form of AlexNet [
16]) is to use a series of convolutional layers followed by dense layers. Specifically, one or more convolutional layers are used to produce convolutional feature maps, and these feature maps are flattened into a 1-dimensional vector, as done in refs. [
12,
13], which is then transformed using dense layers. This work makes use of a network with one convolutional layer followed by a max pooling layer and two dense layers, shown in
Figure 2. Additional layers did not enhance performance for the experiments performed and hyperparameter search space used in this work. Identification networks are trained using mini-batches of spectra
containing known proportions of source and background
. The cross-entropy loss function is used in optimizing network parameters, having the form
where
and
are the elements of
and
, respectively. Minimizing cross-entropy loss is equivalent to minimizing the Kullback-Leibler (KL) divergence, which is a measure between two probability distributions
and
. The KL divergence, and thus cross-entropy, is appropriate in this case since the true value of fractional source and background contributions
and the corresponding estimate
can be treated as probability distributions (i.e.,
and
). Cross-entropy is used here over the KL divergence, however, simply because it is more common for network-based applications.
Feedforward networks, which include the ANN-based identification methods from previous studies, treat sequential measurements as independent—no information from one measurement is passed to the following. In mobile detection, however, there is generally a relationship between sequential measurements—both background and source contributions to spectra generally do not vary abruptly. As a result, recent measurements can potentially be used to inform the current measurement being processed. For example, if source was present in a spectrum at time t, it is more likely that the spectrum at also contains source than another source . In other words, leveraging temporal information has the potential to improve classification, and thus the ability to accurately detect weaker sources.
RNNs are capable of sharing information contained in hidden states between sequential inputs, or in this case, sequences of spectra. This work makes use of Elman layers [
20], which are an extension of fully-connected layers. In addition to transforming the state
to
, as done in dense feedforward layers, Elman layers also feed the output at time
t,
, as an input at time
:
where
,
, and
are learned parameters, and
is a nonlinear activation function, described further in
Appendix A. There are additional types of recurrent layers, such as long short-term memory modules [
21] and gated recurrent units [
22], and these more sophisticated modules generally excel at modeling long time sequences where salient information is spread through the sequence. Due to the simple time dependence of the source models examined in this work, this paper only examines Elman layers for relating sequential spectra. In this work, the first dense layer following the flattening of convolutional features is replaced with an Elman layer, allowing for information from previous spectra
to be used in performing inference on new spectra (i.e., computing
).
In training feedforward networks, mini-batches of spectra are used, where each spectrum contains a random radionuclide with a source activity randomly sampled uniformly from a predefined range. To provide additional variability in training data, a random source-detector angle
(see
Appendix B) is used for each spectrum, but a fixed standoff distance of 10 m is used since the activity sampling provides variability in SNR. Additionally, pure background is included for the model to appropriately learn background features in the absence of source. RNNs, however, need to learn the temporal dynamics of sources, meaning that mini-batches cannot simply contain random samples of spectra with different physical parameters—the data must include series of spectral measurements of the detector moving past the source. Instead of training the network on random mini-batches of spectra in the form of a matrix
, 3-dimensional tensors
are used, where
r refers to a number of runs of data which model the kinematics of a detector moving past a source. With this approach, the network simultaneously learns the mapping between input spectra and relative source contributions and also the temporal behavior of the detector past sources.
2.4. Performance Evaluation and Data
The performance of each method discussed in this work is evaluated by injecting sources with known properties (e.g., activity, distance to detector, etc.) into sequences of background spectra. Source spectra, generated to model the effect of a detector system moving past a stationary source, are added to the background spectra, and algorithms are evaluated on these injection spectra. The outputs of the detection and identification methods are then used to compute the probability of detection, which is the fraction of runs in which the source was successfully detected or identified. The probability of detection is computed as a function of source activity, and the minimum detectable activity (MDA) [
5,
6] is computed, giving a single measure for how well a given method performs at a particular FAR. Suppose a source with activity
A is injected into
R different runs, resulting in
D detections. The probability of detection is simply
, and as a function of activity, this ratio is modeled with a sigmoid function
q of the form
where
and
are estimated empirically from
p using least squares. Figures illustrating the sigmoid behavior of the probability of detection as a function of activity are omitted here for brevity, and we refer the reader to refs. [
5,
6] for examples. Using these estimated parameters, the MDA is computed as
for some target detection probability
. In this work,
is used. Note that theoretical lower bounds for MDA can be estimated for each method [
6], which can be useful in assessing potential performance improvements for a given algorithm.
The runs of sequential background spectra are generated from simulations of a detector system moving through an urban environment, originating from a dataset produced as part of a public data competition [
23,
24]. List-mode gamma-ray events were produced from a 2” × 4” × 16” NaI(Tl) detector moving through a simulated urban environment. Only runs that do not contain anomalous sources, 4900 in total, are used in this work to produce data for training and evaluation. Runs are then divided into training and testing data using a 90–10% split; 4410 runs of training spectra are used as background for learning and validating models parameters, and the 490 testing runs are used for quantifying performance via source injection. Note that the test set only refers to a background dataset that are neither used in training nor validation, and that sources are injected into this background.
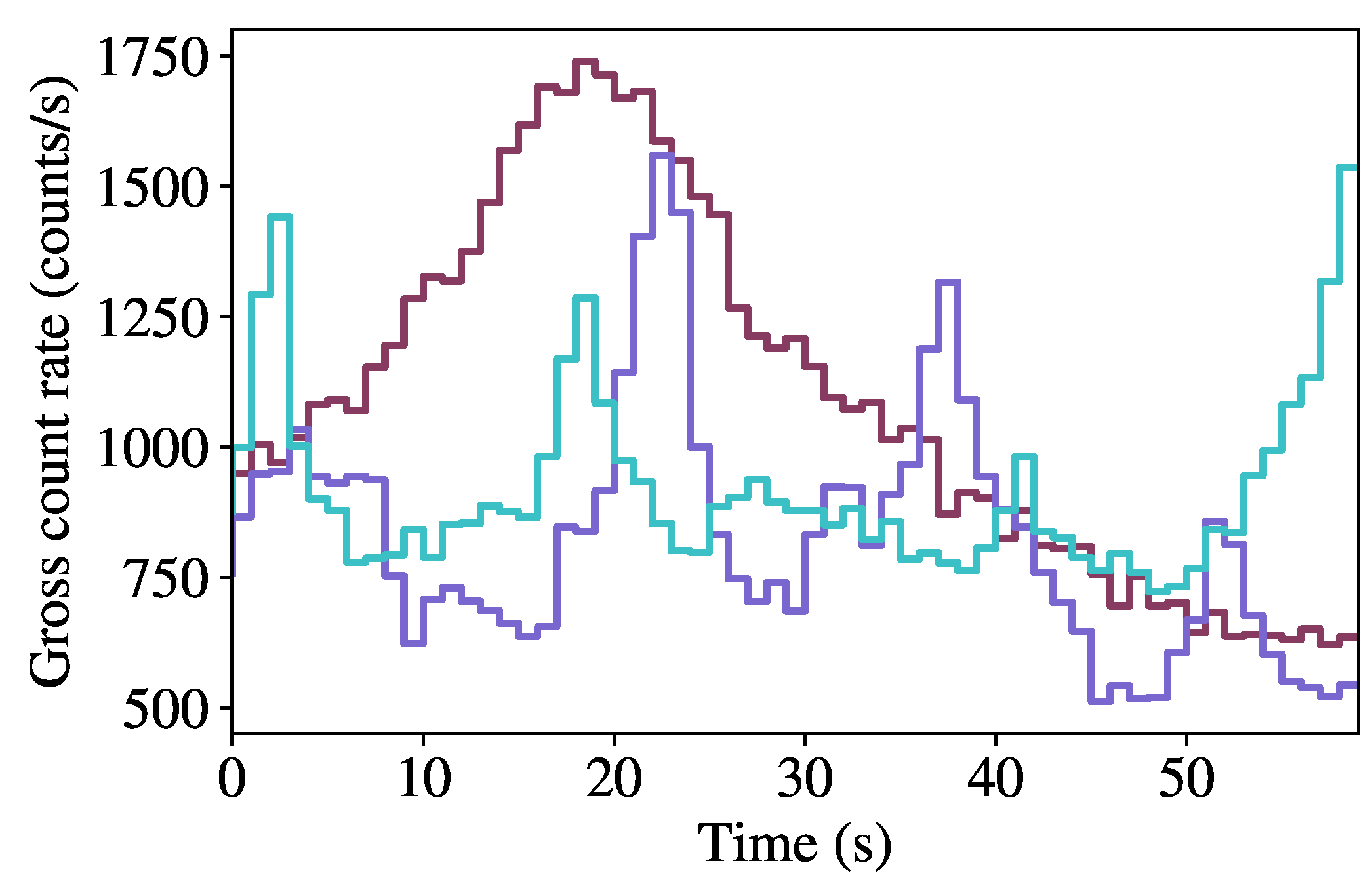
Figure 3 shows the background count rate as a function of time for the first 60 s of three randomly-sampled runs, highlighting the variability in background rates within the dataset.
Spectra are formed by binning events between 30 and 3000 keV using 128 bins with widths that increase as the square root of energy and with a 1-s integration time. Note that square root binning is used both in attempt to put full-energy peaks on a similar scale (i.e., span a similar number of bins independent of gamma-ray energy), and to reduce sparsity in spectra, particularly at higher energies where there are fewer counts. Neither the temporal nor spectral binning schemes are optimized, and results can potentially improve by tuning these values. Experimenting with binning schemes commonly reported by fielded systems (e.g., 1024 linearly-spaced bins) is worth examining from a practical standpoint, however, it is beyond the scope of this work.
Source data are generated separately from background, using Geant4 [
25] to produce list mode data.
Appendix B provides a detailed description of the procedure used for generating source spectra. Seventeen source types are generated using this procedure:
198Au,
133Ba,
82Br,
57Co,
60Co,
137Cs,
152Eu,
123I,
131I,
111In,
192Ir,
54Mn,
124Sb,
46Sc,
75Se,
113Sn, and
201Tl.
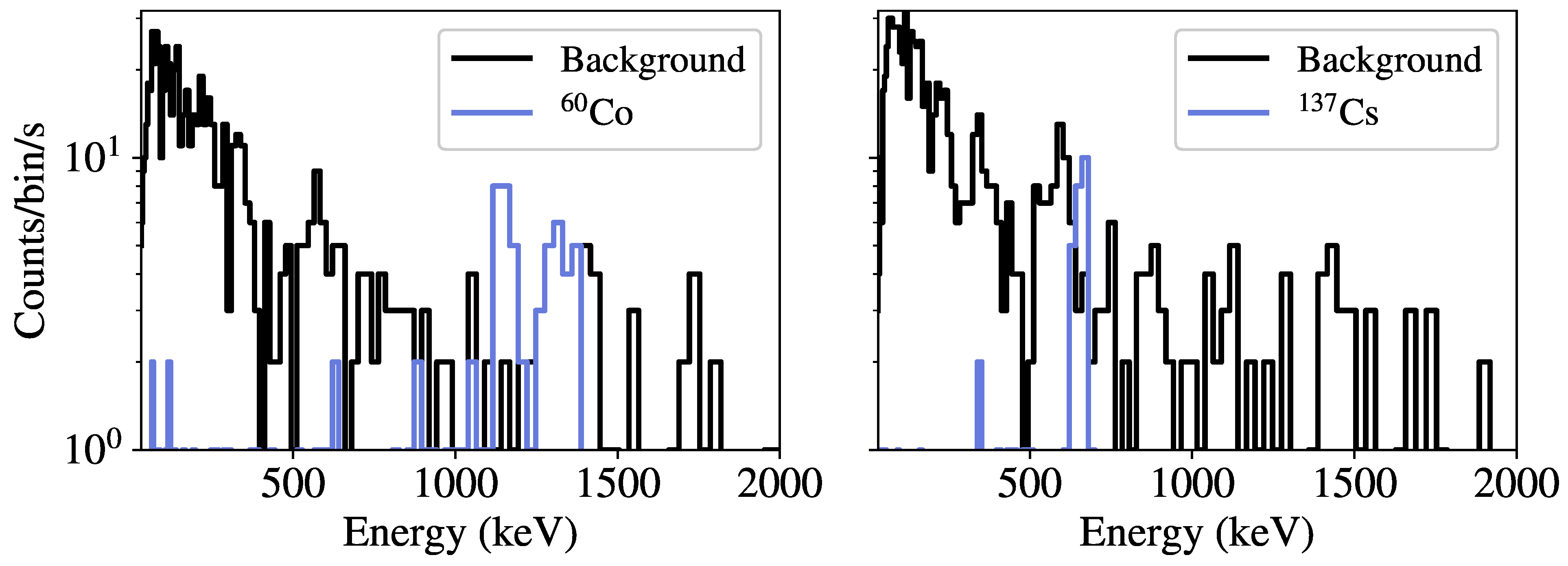
Figure 4 gives examples of spectra from low-activity
60Co and
137Cs sources compared to randomly-sampled background spectra. Note that the injected sources are simulated independently in vacuum, meaning the effects of environmental scattering or occlusions are not contained in the resulting spectra. In modeling the kinematics of the detector past the source, a vehicle speed of
m/s, along a straight line, and a standoff distance
m are used. According to information provided as part of the competition, the detector speed used in generating a given background run was a constant value ranging between 1 m/s and 13.1 m/s. However, the detector speed for each run was not provided as part of the original data competition, meaning the speed
v used in modeling the source kinematics is not necessarily the same. While not ideal, this discrepancy is not believed to affect the conclusions drawn from these analyses, as the speed used here (5 m/s) is in the range of values used to produce the background data.
2.5. Model Optimization
In this context, optimization refers to the process of using a dataset , split into training and validation subsets, to update model parameters , generally by some variation of stochastic gradient descent, such that the loss evaluated on decreases with number of training iterations, or epochs. The elements of optimization, as they pertain to the current analyses, are briefly discussed in this section.
2.5.1. Training, Validation, and Early Stopping
First, the training set is subdivided into a set used for updating model parameters, also referred to as training data, and a validation set used for assessing model performance during optimization. During each epoch, the model parameters are updated based on each mini-batch of training data, and following these parameter updates, the error is computed on the validation data, giving a sense for how accurately the model is performing on data that was not used to update model parameters. The validation set is used to assess the generalization capabilities of the model, and in particular, it is used to indicate when the optimization procedure should cease. Initially, the loss from both the training and validation sets will decrease, however, there will often be a point at which the training loss continues to decrease, while the validation loss increases—a sign of overfitting. Early stopping is the method of stopping the training process once the validation loss begins to increase for some number of iterations, referred to as the patience. In this work, early stopping with a patience of 10 iterations is used in training each network.
2.5.2. Data Preprocessing and Batch Normalization
Models often converge faster when performing input data preprocessing and feature rescaling within the network [
26]. During the experimentation for this work, a linear rescaling based on the mean and standard deviation of training data, referred to as
standardization, was found to perform well for both detection and identification networks. Standardization transforms an input spectrum
to
as
where
and
are the mean spectrum and standard deviation, respectively, and
is a small positive constant to avoid division by 0. Furthermore, features in the network’s hidden layers can be standardized, referred to as
batch normalization [
27] which additionally has a regularizing effect. In this work, DAEs and feedforward identification networks use batch normalization.
2.5.3. Optimizer and Regularization
This work uses the Adam optimizer [
28] with an initial learning rate of
for performing parameter optimization. The learning rate is reduced by a factor of 10 when the validation loss does not decrease for 5 trials, reducing the maximum step size, as the model is presumably near a local minimum. To reduce overfitting, an L2 penalty is used, controlled by a coefficient
. Additionally,
dropout [
29], in which neurons are randomly set to 0 with some probability
p (
here), is used in the identification networks following the convolutional layer and after the first dense layer. Note that the initial learning rate and dropout probability were deemed to work sufficiently well during manual experimentation and are not optimized further.
2.5.4. Hyperparameter Optimization
The optimization procedure is performed for a given model architecture, dataset, and
hyperparameter configuration. Hyperparameters refer to parameters that are not learned (i.e., they are configured prior to training), and generally determine a network’s modeling capacity. In the discussion so far, some hyperparameters include the number of neurons in a layer, number of convolutional kernels in a layer, and the L2 regularization coefficient
. Because of the impact that hyperparameters have on model performance, care must be taken to choose optimal values. Common methods for performing hyperparameter optimization include grid search, random search, and Bayesian optimization. A joint optimization of all hyperparameters is beyond the scope of this work, and instead, this work does a partial optimization: a subset of hyperparameters for a model are fixed, determined from manual experimentation, and a random search [
30] is performed with remaining hyperparameters.
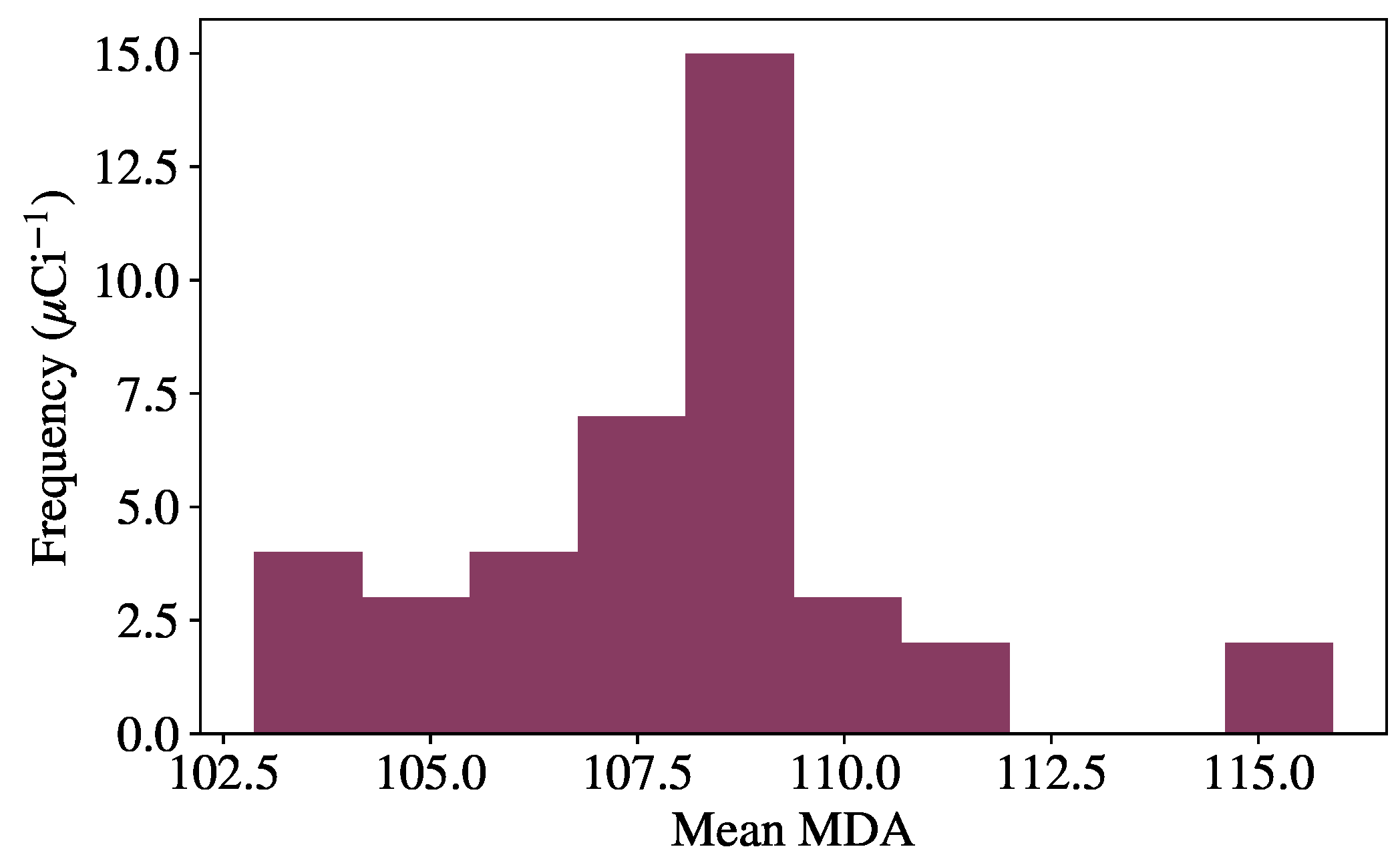
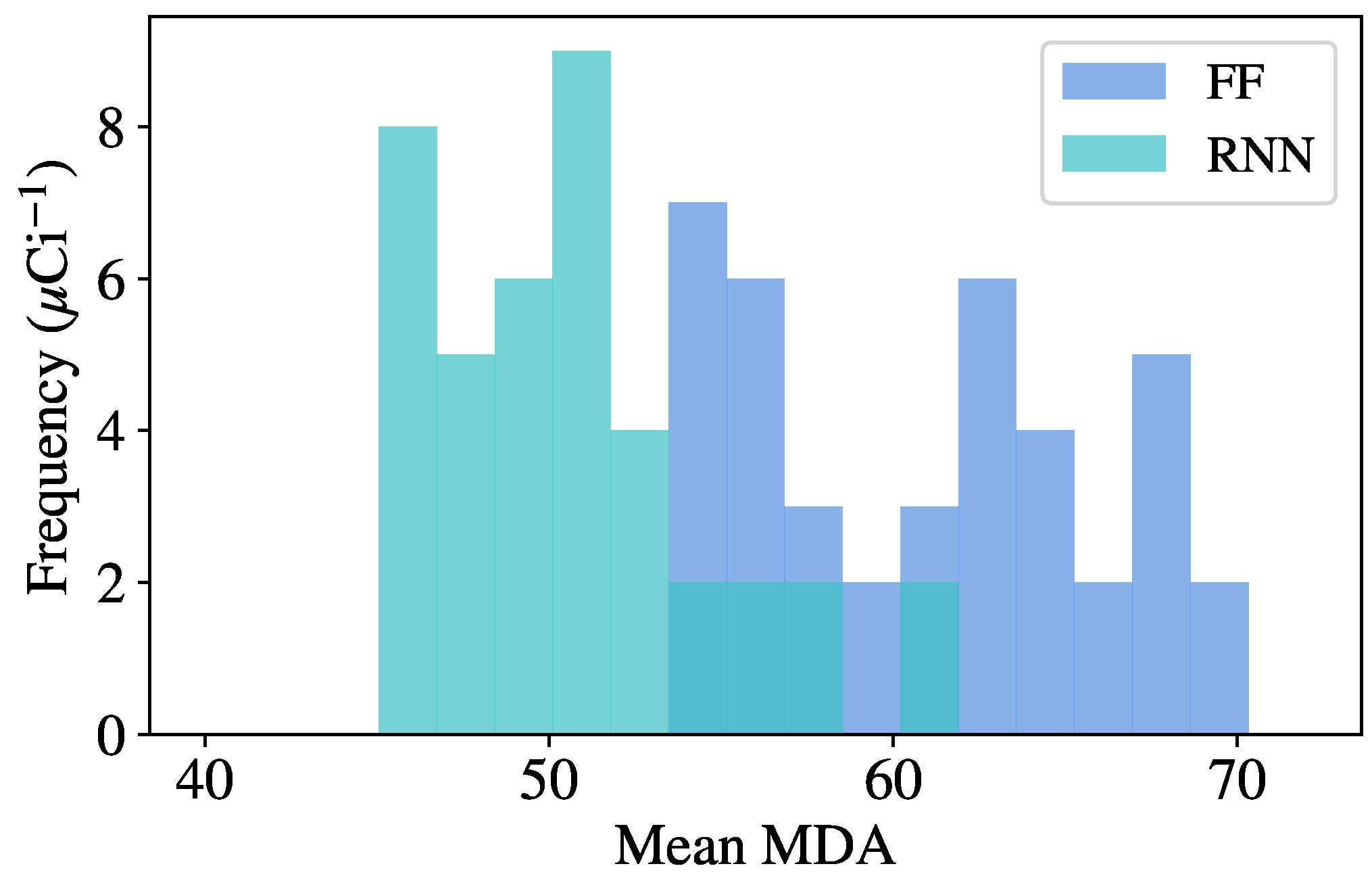
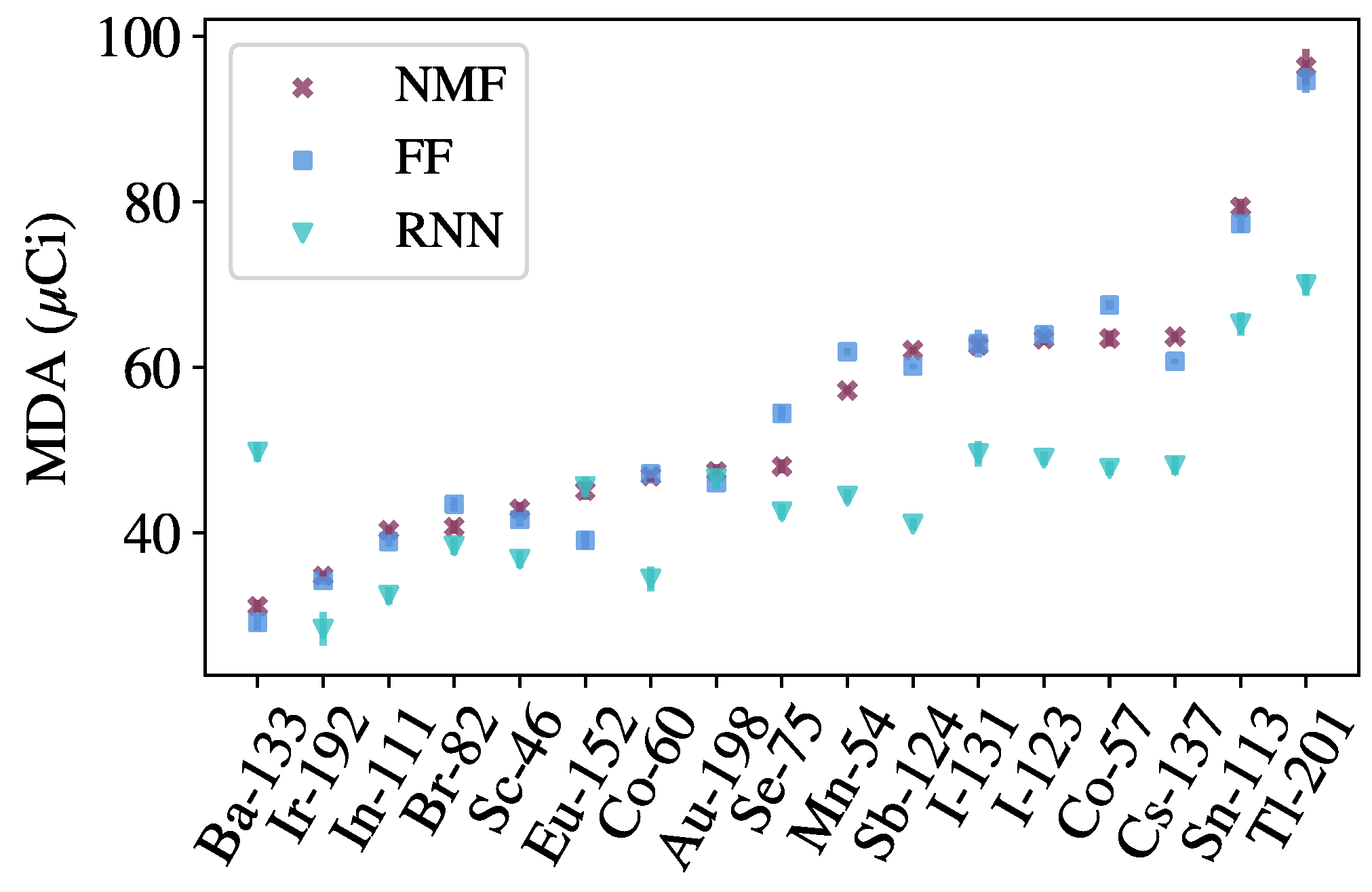
To perform the random optimization, the following procedure is used. First, the variable hyperparameters are randomly sampled from a predefined space, and the model is trained and validated using the procedure previously described. Once a model has finished training, source injection is performed on background data from the validation set, giving an initial MDA for each source. Many models are trained using this procedure, and the model resulting in the lowest mean MDA across all sources is used to evaluate the final test set, as the model has shown the greatest generalization capabilities on unseen data. This optimal model is then evaluated on the test set and compared to benchmark algorithms. The specific hyperparameters tuned for each model are described in the following section with the results.
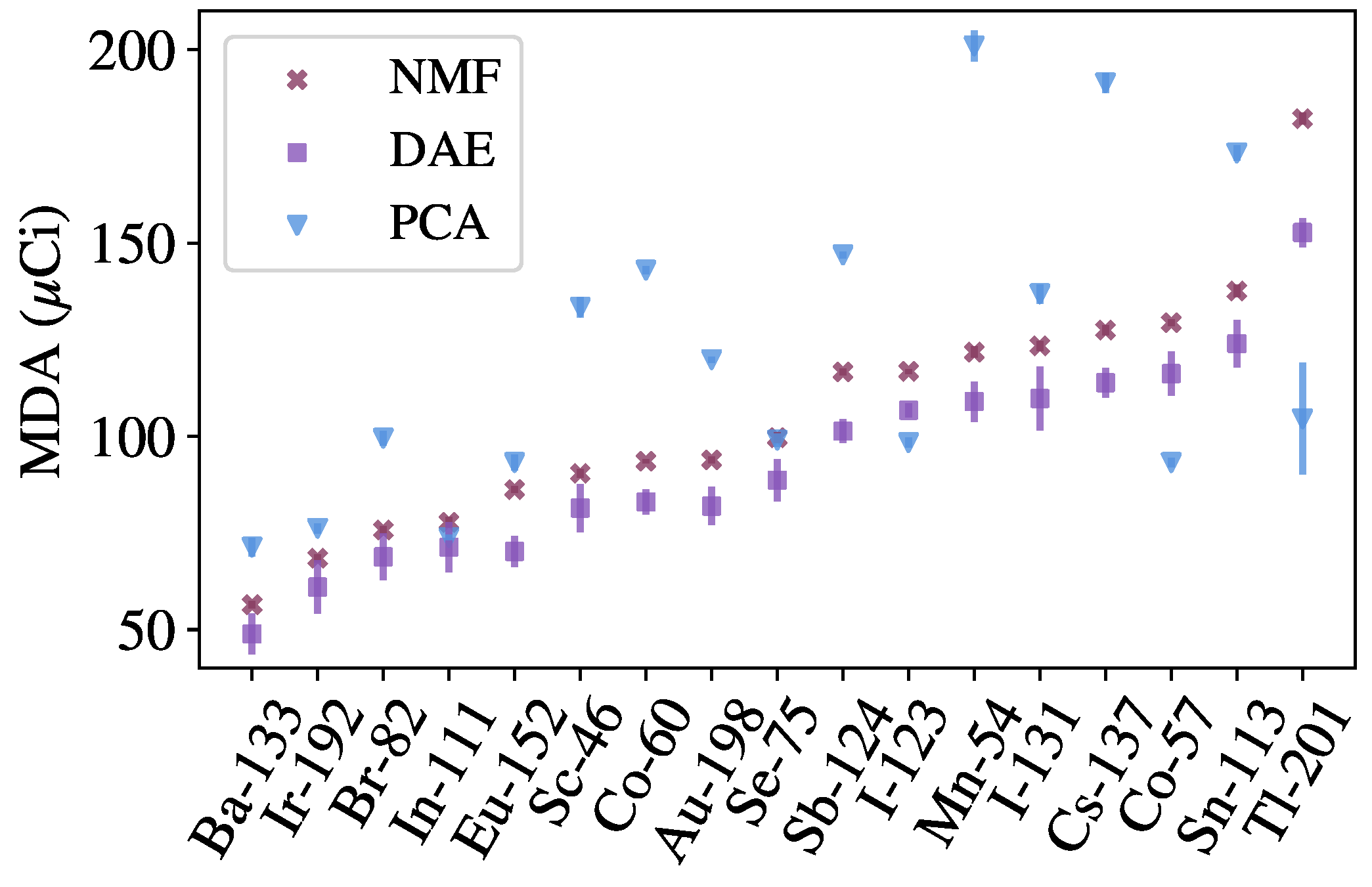
2.6. Benchmarking
The methods discussed in this work are benchmarked against approaches from recent literature. In particular, anomaly detection methods based on Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF) are used to benchmark the autoencoder methods [
6]. Both methods are linear models that operate similar to the autoencoders, in that the models are used to provide approximations of background spectra, and detection metrics are computed between the inputs and approximations. To perform the approximation, both methods can be thought of as performing a matrix decomposition
, where
is a matrix of training data, and
and
are generally low-rank matrices with
k degrees of freedom, or
components. The NMF-based method also uses the Poisson deviance as a detection metric, whereas the PCA-based method, based on previous literature [
31], uses the following detection metric:
where the subscripts 1 and 2 denote the L1 and L2 norms, respectively.
An identification method, also based on NMF, is used to benchmark the identification networks. The components
, learned from background data, are augmented with templates for each source of interest, allowing for reconstructions of spectra containing both background and sources. A likelihood ratio test is performed, providing a detection metric for each source of interest. Both the detection and identification methods set thresholds based on distributions of metrics produced from evaluating on background data. See ref. [
6] and the references therein for additional details about the benchmarking methods.


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







