3.1. Hierarchical Clustering: Dendrogram
A dendrogram demonstrates the composition of hierarchical clusters with a U-shaped link. The top of this link indicates the merging of clusters. The legs of the clusters denote which clusters have been merged using the U-link. The length of the link is a measure between the child clusters. Hierarchical clusters were produced from the pairwise distances among the languages in our dataset. The parameters were the same for all three of the distance measures, with Ward’s minimization method being used as the linkage method. This method minimizes the total variance within clusters iteratively [
28]. This objective function is used at every iteration as an objective function to merge new cluster pairs together. The Euclidean distance is used to measure the distance between data points.
3.1.1. Hierarchical Clustering: Eigensimilarity
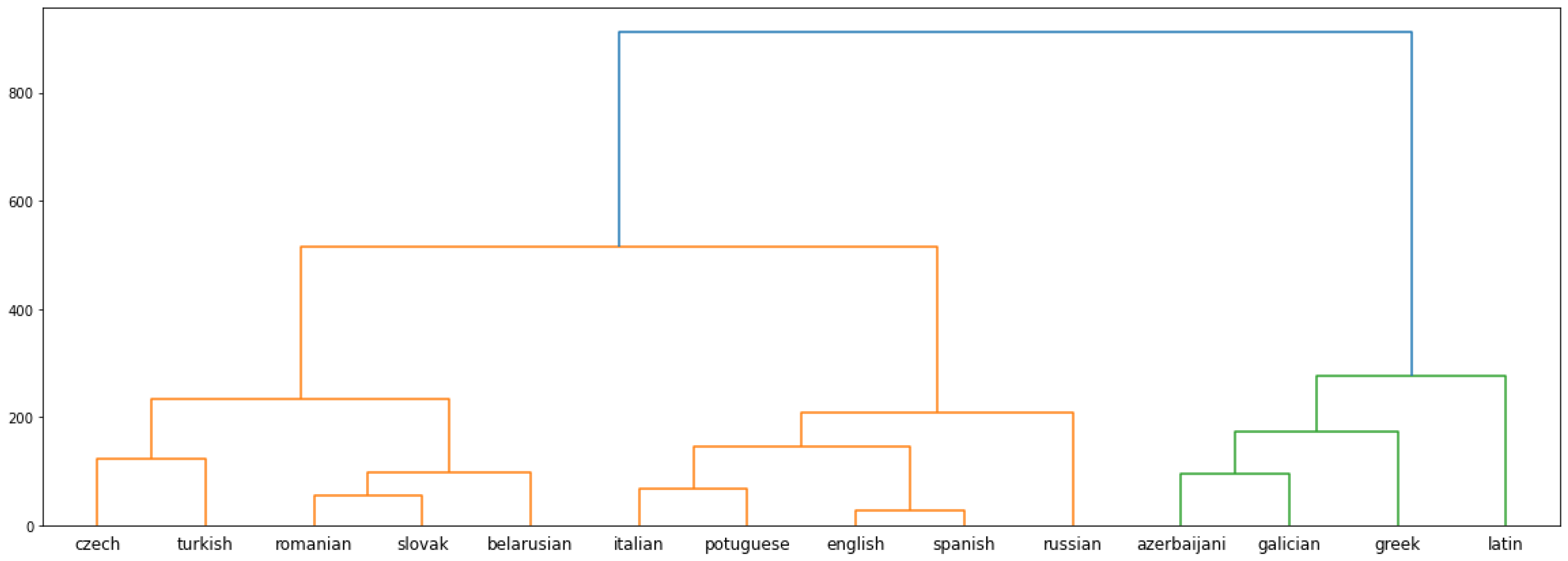
Figure 2 shows the dendrogram produced from the pairwise Eigensimilarity values. It produces three clusters if cut at a distance of 400. The first cluster consists of Czech, Turkish, Romanian, Slovak, and Belarusian. The second cluster consists of Italian, Portuguese, English, Spanish, and Russian. The third cluster is made up of Azerbaijani, Galician, Greek, and Latin. The first and second clusters combine into a single cluster if the dendrogram is cut at a distance of 600. Since the two clusters are separated by a significant distance, the clustering results will be discussed with the dendrogram cut at a distance of 400, resulting in three clusters.
Of the languages in the first cluster, Romanian and Slovak share the lowest distance. The two of them are then clustered together to form a close-knit group of languages. Similarly, Czech and Turkish are grouped closer together than the rest of the languages. Of the five languages forming the second cluster, English and Spanish share the lowest distance, followed by Italian and Portuguese. In the latter stage, these two pairs are grouped together at a distance below 200. Later, these four languages are grouped together with Russian at a distance of around 200. Azerbaijani and Galician are the closest languages In the third cluster. They eventually get grouped together with Greek and Latin.
Impact of Embedding Size
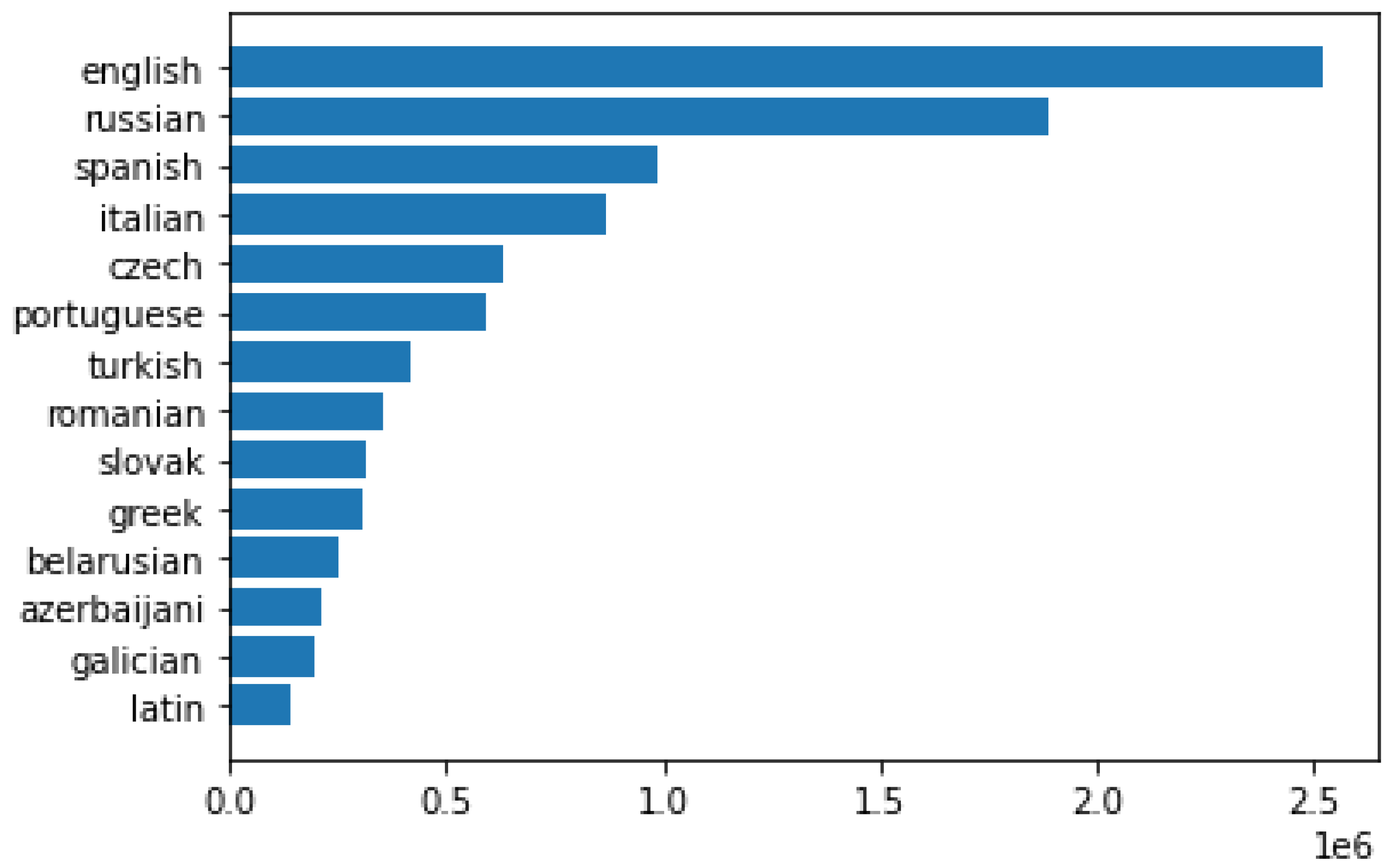
The first cluster groups low-resource Belarusian with moderate-resource Romanian, Slovak, Turkish, and resource-rich Czech. Resource-wise, the Czech space is the fifth largest, and the Belarusian space is the eleventh largest embedding space in our set of languages. Except for the sixth largest Portuguese and the tenth largest Greek, all the language spaces whose embedding sizes fall between the size range of the Czech and Belarusian spaces are part of the cluster. The languages with similar resources have lower distances among themselves in the dendrogram. The Romanian and Slovak spaces are similar in terms of available resources; they also are placed at a low distance in the dendrogram. In the dendrogram, Belarusian is placed at a low distance from Romanian and Slovak. The Czech and Turkish spaces placed closer together have a larger difference in their embedding space sizes.
The second cluster is made up of resource-rich English, Russian, Spanish, Italian, and Portuguese. Except for the fifth largest embedding space, Czech, this cluster groups together five of the six largest embedding spaces. Although English and Russian are the two largest embedding spaces, English shares the smallest distance with Spanish in the dendrogram. The Italian space is closer to the Spanish space in terms of available resources but shares a lower distance with Portuguese in the dendrodram. Russian, on the other hand, is further apart from these four languages.
The third cluster is made up of low-resource languages Latin, Galician, Azerbaijani, and moderate-resource Greek. Azerbaijani and Galician are similar in terms of available resources and are placed at a low distance in the dendrogram. The Latin space has similar resources as Azerbaijani and Galician, but moderate-resource Greek is placed at a closer distance from those two languages compared to Latin.
Impact of Typological Similarities
The first cluster contains languages from the Slavic (Czech, Slovak, and Belarusian), Romance (Romanian), and Turkic (Turkish) language families. Romanian, due to it being a Balkan/Eastern Romance language, has had influence from the Slavic languages. However, the hierarchical clustering algorithm applied to the pairwise Eigensimilarity values does not seem to capture the close typological relationship between Czech and Slovak. They are part of the same cluster but placed at a considerable distance in the dendrogram. The major Slavic language, Russian, is not part of the cluster, and neither is Azerbaijani—the other Turkic language in our experiment set. The second cluster contains languages from the Romance (Italian, Portuguese, Spanish), Slavic (Russian), and Germanic (English) families. English is heavily influenced by the Romance language Spanish and is also placed close to Spanish. The distance of Russian from the other languages in the cluster could be an indication of it being typologically dissimilar to them. The third language cluster is made up of Turkic (Azerbaijani), Romance (Galician), and Indo-European (Greek, Latin) languages.
From the discussion above, it seems that both embedding size and typological similarities have an impact on forming the clusters. This conclusion is supported by the inclusion of Russian with the other resource-rich languages of the experiment set. The third cluster is also formed by typologically dissimilar languages. On the other hand, low-resource Belarusian and resource-rich Czech are part of the first cluster, along with moderate-resource languages. However, it should be noted that the clear division of resources is defined by this research, and the embedding sizes of Belarusian and Czech are close to the embedding sizes of Slovak and Turkish, respectively, which are also part of the same cluster. Romanian-Slovak and Galician-Azerbaijani pairs are placed at a low distance in the dendrogram. From
Figure 1, it can be seen that their embedding spaces are also of similar size. However, languages are not completely grouped in order of their embedding resources. If that were the case, Greek and Portuguese would have been the languages to be grouped with the moderate resource languages instead of Belarusian and Czech, which indicates a level of impact from typological similarities among the languages in the cluster. Some other interesting aspects of the results include the relatively greater distance of Russian from the rest of the languages in the second cluster. In the same cluster, English and Spanish, known to be very similar languages due to the impact of French on English, are placed at a very low distance in the dendrogram.
3.1.2. Hierarchical Clustering: Gromov–Hausdorff Distance
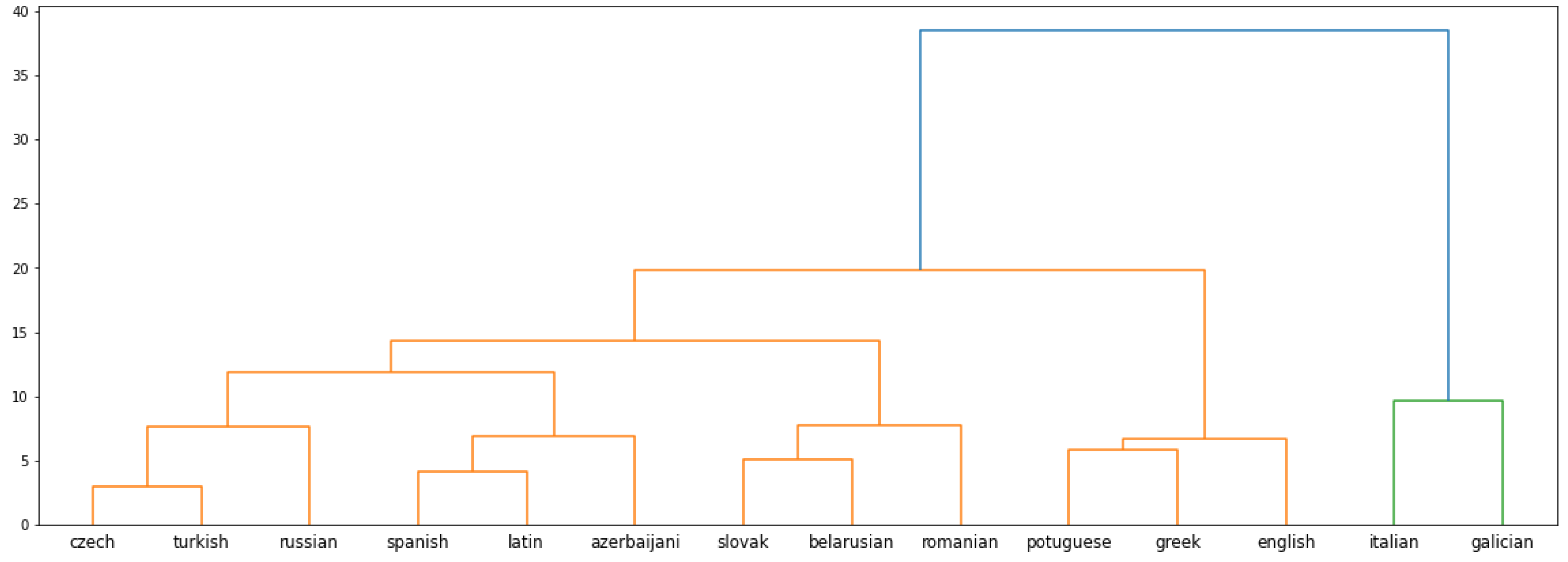
The dendrogram produced from applying hierarchical clustering on pairwise Gromov–Hausdorff distances will be discussed in terms of the three clusters produced if the dendrogram is cut at a distance of 18. From
Figure 3, it can be seen that the first of these three clusters is made up of Czech, Turkish, Russian, Spanish, Latin, Azerbaijani, Slovak, Belarusian, and Romanian. Of these, Czech-Turkish, Spanish-Latin and Slovak-Belarusian pairs share the lowest distances. Czech and Turkish are later grouped together with Russian, while Spanish-Latin and Slovak-Belarusian pairs are later grouped together with Azerbaijani and Romanian, respectively. The second cluster is closer in distance to the first one, containing spaces for the Portuguese, Greek, and English languages. The third cluster is made up of just two languages, Italian and Galician.
Impact of Embedding Size
The first major cluster in the dendrogram is made up of low-resource (Latin, Azerbaijani, and Belarusian), moderate-resource (Slovak, Romanian, and Turkish), and resource-rich (Czech and Russian) languages. If the dendrogram is cut at a distance of 10 to closely examine the smaller clusters that join to form the first cluster, it shows some possible instances of grouping languages with similar resources. Although the resource classifies Turkish as a moderate-resource language, the disparity in resources between Turkish and Czech is relatively lower than that between Czech and Russian. Similarly, Belarusian, Slovak, and Romanian are similar in terms of available resources. The only other language with a similar embedding size that is missing from this cluster is Greek. Latin and Azerbaijani are low-resource languages, but the embedding size of Spanish is greater than both of them. The second cluster has two resource-rich languages—Portuguese and English, with moderate-resource Greek. The third cluster groups together low-resource Galician with resource-rich Italian.
Impact of Typological Similarity
The first major cluster in the dendrogram clusters languages from the Romance (Romanian and Spanish), Slavic (Belarusian, Slovak, Czech, and Russian), Turkic (Azerbaijani and Turkish) language families, along with Latin. A closer look, however, does not consistently reveal a closer distance that correlates with the language families. If the dendrogram is cut at a distance of 10 to examine the languages in the first cluster at a more granular level, it can be seen that Czech, Turkish, and Russian are placed close together. Czech and Russian are Western and Eastern Slavic languages, respectively, while Turkish belongs to the Turkic language family. Another smaller cluster places the Romance language Spanish with Latin, and the Turkic language Azerbaijani close together. It can be argued that as the source of Romance languages, the clustering of Latin with Spanish makes sense. These smaller clusters are joined at a distance of 12. The third of these clusters places Slavic languages Belarusian and Slovak with Slavic-influenced Romance language Romanian. The second larger cluster formed at a distance of 18 groups Romance language Portuguese with Romance-influenced Germanic language English together with Greek. Greek forms its own independent branch in the Indo-European language tree. The third and final cluster groups two Romance languages, Galician and Italian. Although both these languages are Romance languages, Galician is known to be typologically more similar to Portuguese and Spanish than Italian.
From the discussion above, it seems unlikely that embedding space size has a significant impact on forming the clusters from pairwise Gromov–Hausdorff distances. Slovak, Belarusian, and Romanian being placed close together on the dendrogram could result from both their embedding sizes being similar and their typological relatedness. The dendrogram shows several instances of languages of disparate resources being placed in close proximity. Notable among them is the close distance between Latin-Spanish, Portuguese-Greek, and Italian-Galician pairs. There are also instances of languages with similar resources being grouped together, such as the Czech-Turkish and, as mentioned before, Belarusian-Slovak-Romanian.
3.1.3. Hierarchical Clustering: Relational Similarity
The dendrogram in
Figure 4 is produced from pairwise Relational Similarities and shows three clusters if cut at a distance of 1.25. The first cluster is made up of Turkish, Romanian, Galician, Czech, Slovak, Greek, Latin, and Azerbaijani. Of these languages, Czech and Slovak share the smallest distance. They are followed by Turkish and Romanian, which are later grouped together with Galician. Similarly, Greek and Latin share a closer distance within this larger cluster. Finally, these languages are grouped together with Azerbaijani, which has a greater distance from the other languages in the clusters than they have among themselves. The second cluster is made up of only two languages, Russian and Belarusian. The third cluster is made up of Spanish, Portuguese, Italian, and English. Of these, Spanish and Portuguese have a low distance, which is then followed by Italian and then English.
Impact of Embedding Size
The first cluster groups together low-resource (Latin, Azerbaijani, and Galician), moderate-resource (Greek, Slovak, Romanian, and Turkish) with resource-rich Czech. It should be noted that with the exception of Belarusian and Portuguese, these languages are among the first ten embedding spaces if they were sorted in increasing order of their sizes. Hence, a closer look at the cluster might reveal more information. If the dendrogram is cut at a lower distance, it produces four clusters from the languages in the first cluster. The first of them contains the Turkish, Romanian, and Galician spaces. Turkish and Romanian are both moderate-resource languages with a very similar number of words making up the embedding spaces, but Galician is a low-resource language. The second of these smaller clusters contains the Czech and Slovak spaces. Czech is a resource-rich language, while Slovak is a moderate-resource language in our language set. The third of these clusters is made up of Greek and Latin, which are moderate-resource and low-resource, respectively. The fourth cluster is made of a single language, Azerbaijani. The second major cluster contains the language spaces of Russian and Belarusian. The Russian space is the second largest embedding space in our language space, while the Belarusian space is the fourth smallest one. The final and third major cluster is made up of resource-rich spaces of Spanish, Portuguese, Italian, and English. These are among the six largest embedding spaces in our language space, the remaining two being Russian and Czech.
Impact of Typological Similarity
The first cluster groups together languages from the Slavic (Czech and Slovak), Turkic (Turkish and Azerbaijani), and Romance (Romanian and Galician), along with Indo-European Greek and Latin. Taking a closer look at the different clusters if the dendrogram is cut at a lower distance reveals smaller clusters where Romanian and Turkish are grouped close together and then clustered with Galician at an increased distance. Romanian has had some influence from Turkish, while Galician and Romanian are both Romance languages. More interesting is the result where two Slavic languages, specifically Western Slavic languages, are grouped together at a low distance. Greek and Latin are grouped together with a low distance between them. Of the languages in the experiment set, these two can be considered independent. While Latin is the language from which all Romance languages were generated, modern Romance languages have diverged from Latin. Greek forms its own independent branch in the Indo-European language family. These two languages being grouped together is also an interesting aspect of the result. The second major cluster is formed with Eastern Slavic languages Belarusian and Russian. The third and final cluster is formed with Romance languages Spanish, Portuguese, Italian, and Spanish-influenced Germanic language English. A closer look at the cluster at a lower distance reveals that Spanish and Portuguese are placed at a very low distance, reflecting their typological similarity since they both belong to the Ibero-Romance sub-family. These two languages are then grouped with Italian at a slightly higher distance. Italian, although a Romance language, belongs to a different branch of the Romance family tree. Finally, English is grouped with these three Romance languages at an even greater distance. This correlates with the fact that although English has been heavily influenced by the Romance languages, especially French, typologically, it is a Germanic language.
From the discussion above, it seems that the clusters produced by the hierarchical clustering algorithm from pairwise Relational Similarity values are impacted more by typological similarities than the size of the embedding space. Some of the results that provide strong support for this include the grouping together of Czech-Slovak, Spanish-Portuguese, and Russian-Belarusian pairs. Czech-Slovak and Russian-Belarusian pairs are disparate in terms of their embedding sizes. The cluster that groups Spanish, Portuguese, Italian, and English reflects in its inter-lingual distances the relationships that these languages share among themselves. On the other hand, the grouping of languages that may be influenced by the language pair’s embedding size is the Romanian-Turkish pair. Both languages have a similar number of words in their respective embedding spaces. However, they are also joined by Galician at a slightly higher distance, which is a decidedly low-resource language. Another reason for this grouping may be that Romanian has had some Turkish influence over the years, which may be embedded in their language spaces. Further, both Galician and Romanian are Romance languages. Romanian has distinct features due to it being a Balkan/Eastern Romance language. Galician is typologically similar to Spanish and Portuguese. However, its lack of resources compared to these Ibero-Romance languages may have resulted in a divergence that has caused it to be closer in the dendrogram to Romanian than the rest of the Romance languages. The language whose positioning in the dendrogram cannot be clearly explained is Azerbaijani. Although it is part of the same larger cluster that Turkish is part of, the distance between these two Turkic languages is quite significant, and it is grouped together with the rest of the languages in the first cluster at the same distance.
3.2. Fuzzy C-Means Clustering Algorithm
Based on the results in
Section 3.1, the number of clusters was set to three for the Fuzzy C-Means clustering algorithm.
3.2.1. FCM: Eigensimilarity
Table 1 shows the results from the FCM clustering algorithm applied on pairwise Eigensimilarity values with the languages divided into three clusters. Latin, Galician, Azerbaijani, and Greek form Cluster 0. Of these, Galician has the highest degree of membership in its assigned cluster. Latin, Greek, and Azerbaijani have memberships of 0.12, 0.15, and 0.20 to Cluster 2 as well. Cluster 1 contains the languages Portuguese, Italian, Spanish, Russian, and English. Of these, Italian and Russian have 0.21 and 0.12 memberships to Cluster 2 while having 0.74 and 0.82 membership to their assigned cluster label. The third cluster, with label 2, is made up of languages Belarusian, Slovak, Romanian, Turkish and Czech. Of these, Turkish and Czech display a considerable degree of membership to Cluster 1 with 0.33 and 0.42 membership, respectively, while they belong to their assigned cluster with 0.58 and 0.52 membership, respectively.
Impact of Typological Similarity
Cluster 0 contains a Romance language, Galician, a Turkic language, Azerbaijani, along with general Indo-European languages Latin and Greek. Cluster 1 contains languages from the Romance (Portuguese, Italian, and Spanish), Slavic (Russian), and Germanic (English) language families. Cluster 2 contains languages from Slavic (Belarusian, Slovak, and Czech), Romance (Romanian), and Turkic (Turkish) language families. It makes sense for English to be clustered with the Romance languages due to their heavy influence on the language. Russian, which is a Slavic language clustered with Romance languages with 0.82 membership. It has 0.12 membership to Cluster 2, which contains the other Slavic languages of the language set. Romanian is assigned to Cluster 2 with a high degree of membership (0.97). Although a Romance language, it has had influences from the Slavic languages. Czech is assigned to Cluster 2 but has a considerable degree of membership to Cluster 1 (0.42). Turkish, too, is assigned to Cluster 2 with 0.58 membership, while it has 0.33 membership to Cluster 1.
Impact of Embedding Size
The languages in Cluster 0 are the first, second, third, and fifth lowest resource languages in our experiment set. On the other hand, Cluster 1 is made up of five of the six highest resource languages in our experiment set. Belarusian, which is among the low-resource languages, and Czech, which is among the resource-rich languages, are clustered together with Slovak, Romanian, and Turkish, which are moderate resource languages in our language set. Czech is assigned to Cluster 2 with 0.53 membership, while it has around 0.42 membership to Cluster 1, which contains the other high-resource languages in the language set. A similar trend is not visible in Belarusian. It belongs to Cluster 2 with 0.86 membership, while it belongs to Cluster 0 and Cluster 1 with around 0.08 and 0.06 membership.
The embedding spaces for the languages in Cluster 0 are the first, second, third, and fifth smallest languages in the dataset. Neither of these four languages is etymologically close to each other. However, Galician, being a Romance language, may have some similarities with Latin. Of these, Portuguese, Italian, and Spanish are major Romance languages, while English is also heavily influenced by the Romance family of languages. Russian, however, is a Slavic language. The embedding spaces for these languages are the first, second, third, fourth, and sixth largest in our dataset. Among these languages, Belarusian, Czech, and Slovak are Slavic languages. Romanian, even though a Romance language, has strong Slavic influences. Turkish is from the Turkic family of languages. The inclusion of Belarusian and Czech in Cluster 2 may have resulted from the typological similarity they share with Slovak. However, the inclusion of Russian in Cluster 1 with other typologically distant but similarly resourced languages, as well as the high degree of membership of Czech to Cluster 1 indicate that the embedding size has a marginally stronger effect.
3.2.2. FCM: Gromov–Hausdorff Distance
The results of the FCM clustering algorithm can be seen in
Table 2. In this case, one of the three clusters is identical to the one formed in the previous iteration of Fuzzy C-Means clustering on the pairwise Gromov–Hausdorff distances. This cluster, labeled 1 here, consists of Italian and Galician. Galician has 0.05 membership to Cluster 0 and 0.08 membership to Cluster 2. Italian, on the other hand, has 0.03, 0.93, and 0.04 membership to Clusters 0, 1, and 2, respectively. Of the other two clusters, Cluster 0 is made up of Azerbaijani, Belarusian, Slovak, Romanian, Turkish, Czech, and Russian. Of these languages, Slovak and Czech show a similar distribution of membership across the Clusters. A similar trend can be seen in the distribution of membership for Turkish-Romanian and Azerbaijani-Russian pairs. Finally, Cluster 2 is made up of Latin, Greek, Spanish, Portuguese, and English, where Latin and Spanish show a similar distribution of membership across the three clusters, while Greek, Portuguese, and English also have similar degrees of cluster membership.
Impact of Embedding Size
Cluster 0 is made up of low-resource (Azerbaijani and Belarusian), moderate-resource (Slovak, Romanian, and Turkish), and resource-rich (Czech and Russian) languages. Cluster 1 is made up of two languages, with one of them being a low-resource language while the other is a resource-rich language. Cluster 2 contains low-resource (Latin), moderate-resource (Greek), and resource-rich (Portuguese, Spanish, and English) languages. In Cluster 0, low-resource Azerbaijani and resource-rich Russian have the same distribution of membership across clusters. Romanian and Turkish also show a similar distribution, but they are comparable in terms of the resources their respective embedding spaces were trained on. Slovak and Czech are disparate in their embedding sizes, with Slovak being a moderate-resource language and Czech a resource-rich one. These two languages also have a similar membership distribution across clusters. Similarly, in Cluster 2, low-resource Latin and high-resource Spanish have similar membership distribution. Greek, a moderate resource language, is also similar in distribution to resource-rich Portuguese and English.
Impact of Typological Similarity
Cluster 0 consists of languages from the Turkic (Azerbaijani and Turkish), Slavic (Belarusian, Slovak, Czech, and Russian), and Romance (Romanian) family of languages. However, the membership distribution of Azerbaijani and Turkish is not similar. Rather Azerbaijani and Russian show a similar membership distribution as do Romanian and Turkish. There have been some influences of Turkish on Romanian over the years, which may have contributed to the similarity in distribution. Slovak and Czech, two typologically similar languages, also display similar membership distribution, which is shared also by Belarusian, yet another Slavic language. Cluster 1 has two Romance languages, Galician and Italian. Cluster 2 is made up of languages from the Romance family of languages (Portuguese and Spanish) with the Romance-influenced Germanic language English. The cluster also contains Latin and Greek. Of these languages, Greek, Portuguese, and English have similar distributions, while Latin and Spanish share similar distributions.
From the discussions above, it is unlikely that embedding size is playing a role in the clustering of languages on their pairwise Gromov–Hausdorff distances using the Fuzzy C-Means clustering algorithm. On the other hand, the distance measure and the clustering algorithm used seem to be encoding some typological information. Slavic languages Belarusian, Slovak, Czech, and Russian are all in the same cluster, with Belarusian, Czech, and Slovak showing a similar distribution of cluster membership. Azerbaijani, Turkish, and Romanian are also part of the same cluster. Turkish and Azerbaijani are typologically related, while Romanian has had influences from both the Slavic languages as well as Turkish. On the other hand, the Romance languages in our language set are divided into two different clusters, with Galician and Italian forming Cluster 1 and Spanish and Portuguese forming Cluster 2 together with English, Latin, and Greek. Although Galician is known to be typologically closer to Portuguese and Spanish, its clustering with a Romance language is still significant because it is a severely low-resource language, which is known to be one of the factors affecting the isomorphism between vector spaces. The clustering of English together with major Romance languages is consistent with its real-world influence from the Romance languages.
3.2.3. FCM: Relational Similarity
Table 3 shows the three clusters formed from the pairwise Relational Similarity values. Galician, Azerbaijani, Slovak, Romanian, Turkish, and Czech make up Cluster 0. Although, broadly, all five languages have a similar degree of membership, hence clustered under the same cluster label, they vary in their membership to Clusters 1 and 2. Galician and Romanian are distributed almost evenly between Clusters 1 and 2. On the other hand, Azerbaijani, Slovak, Turkish, and Czech have a comparatively higher degree of membership to Cluster 2 compared to Cluster 1. Portuguese, Italian, Spanish, and English make up Cluster 1. Of these, Portuguese, Italian, and Spanish are more similar in their membership distribution. Their membership to the three clusters ranges between 0.11–0.16, 0.72–0.81, and 0.08–0.12, respectively. On the other hand, English is distributed with a 0.25–0.53–0.22 membership across the three clusters. Latin, Belarusian, Greek, and Russian make up Cluster 2. Latin is slightly different in membership distribution across the three clusters. Of these, Belarusian, Russian, and Greek diverge from Latin with respect to their membership to Clusters 0 and 2. Latin belongs to Clusters 0 and 2 with 0.40 and 0.45 membership. The other three languages’ memberships to Clusters 0 and 2 fall between 0.30–0.34 and 0.49–0.55. The memberships to Cluster 1 for these languages range between 0.10–0.21.
Impact of Embedding Size
Of the five languages making up Cluster 1, Galician and Azerbaijani are low-resource languages; Slovak, Romanian, and Turkish are moderate-resource languages, while Czech is a resource-rich language. Galician and Azerbaijani do show a similar distribution of membership across the three clusters. Slovak, Romanian, and Turkish belong to Cluster 0, with membership ranging from 0.49–0.54. Their degrees of membership to Cluster 1 fall between a wider range (0.13–0.24). Among these languages, Slovak has the lowest degree of membership at 0.13, followed by Turkish at 0.18 and Romanian at 0.24. Their membership degrees to Cluster 2 also have a similar range (0.27–0.38). Slovak has the highest degree of membership to Cluster 2 at 0.38, while Turkish and Romanian belong to Cluster 2 with a membership of 0.28 and 0.27, respectively. Czech belongs to the three clusters with 0.51, 0.18, and 0.31 membership.
The languages making up Cluster 1—Portuguese, Italian, Spanish, and English—are all resource-rich languages. As mentioned above, the membership distribution is slightly different from the other three languages. The English embedding space is, however, significantly larger in size than the other three, with around 2.5 million words. The Spanish space, the third largest in our set of languages, contains 985,667 words.
Cluster 2 is made up of low-resource Latin and Belarusian, moderate-resource Greek, and resource-rich Russian. Latin has the lowest membership to its assigned cluster and has a significant membership to Cluster 0. Of the remaining languages, Belarusian and Greek have a higher degree of membership to Cluster 0, compared to Russian, which has a more evenly distributed membership degree to Clusters 0 and 1.
Impact of Typological Similarity
Cluster 0 is made up of languages from Romance (Galician and Romanian), Turkic (Azerbaijani and Turkish), and Slavic (Slovak and Czech) languages. As mentioned while discussing the impact of embedding size in forming the clusters, Galician and Romanian have a similar distribution. However, their membership is evenly distributed between Clusters 1 and 2, clusters that contain the major Romance and Slavic languages, respectively. The Slavic languages, as well as the Turkic languages, are similar in their membership distributions. Romance languages Portuguese, Italian, and Spanish are clustered with the Romance-influenced Germanic language English. On the other hand, Cluster 2 is made up of Slavic languages Belarusian and Russian, along with Latin and Greek.
From the discussion above, it seems that typological similarities impact the language clusters more than their embedding sizes. Languages with disparate resources are clustered together, while languages belonging to the same language family are clustered together. Although Galician belonging to the same cluster as Romanian may not be an indication of both being Romance languages, as Azerbaijani is also part of the cluster, and both Azerbaijani and Galician are low-resource languages. A similar explanation can be provided for Belarusian being clustered with Russian, Greek, and Latin, where Belarusian and Russian are Slavic languages and Latin and Belarusian are low-resource languages. Although the similar membership distributions of Romanian and Galician make the case stronger for it being an impact of their typological similarities. A similar phenomenon is also noticed in the membership distributions of Belarusian and Russian but less so in the membership distributions of Azerbaijani and Turkish—two Trukic languages. Interestingly, Czech and Slovak are clustered together in Cluster 0, while Russian and Belarusian are clustered together in Cluster 2. This could possibly be an indication of the two pairs of languages belonging to different branches of the Slavic family tree. Of the languages forming Cluster 1, the Romance languages show similar degrees of membership to the three clusters, while English shows a different distribution. This could be both an indication of English being relatively richer in resource than the other three resource-rich languages and English being a Germanic language, albeit with heavy Romance influences.










{kind=link}
{kind=link}
{kind=link}
{kind=link}