


Advanced Swine Management: Infrared Imaging for Precise Localization of Reproductive Organs in Livestock Monitoring


Abstract
:1. Introduction
2. Background
3. Related Work
3.1. Vulva Detection in Sows Using Gabor with the SVM Classifier
3.2. Vulva Detection Using YOLOv3
4. Method Overview
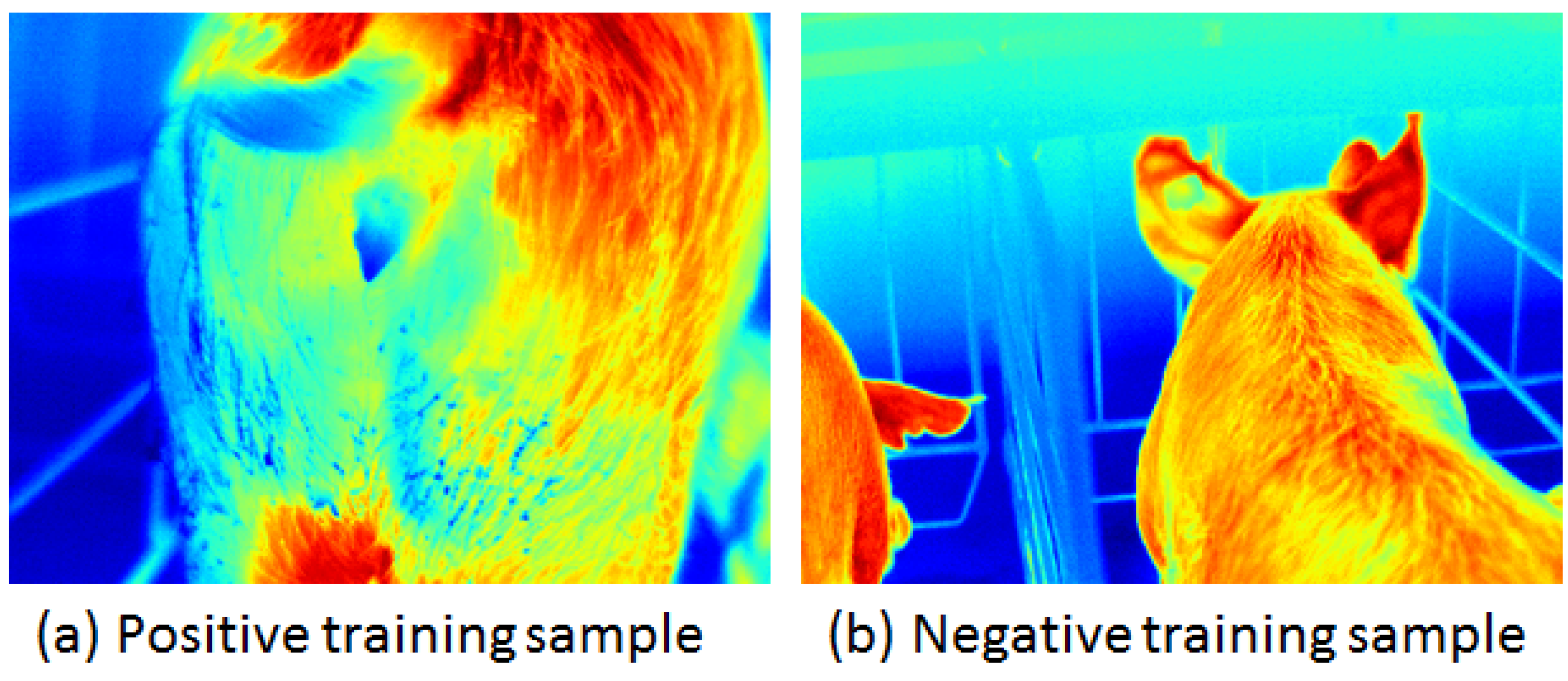
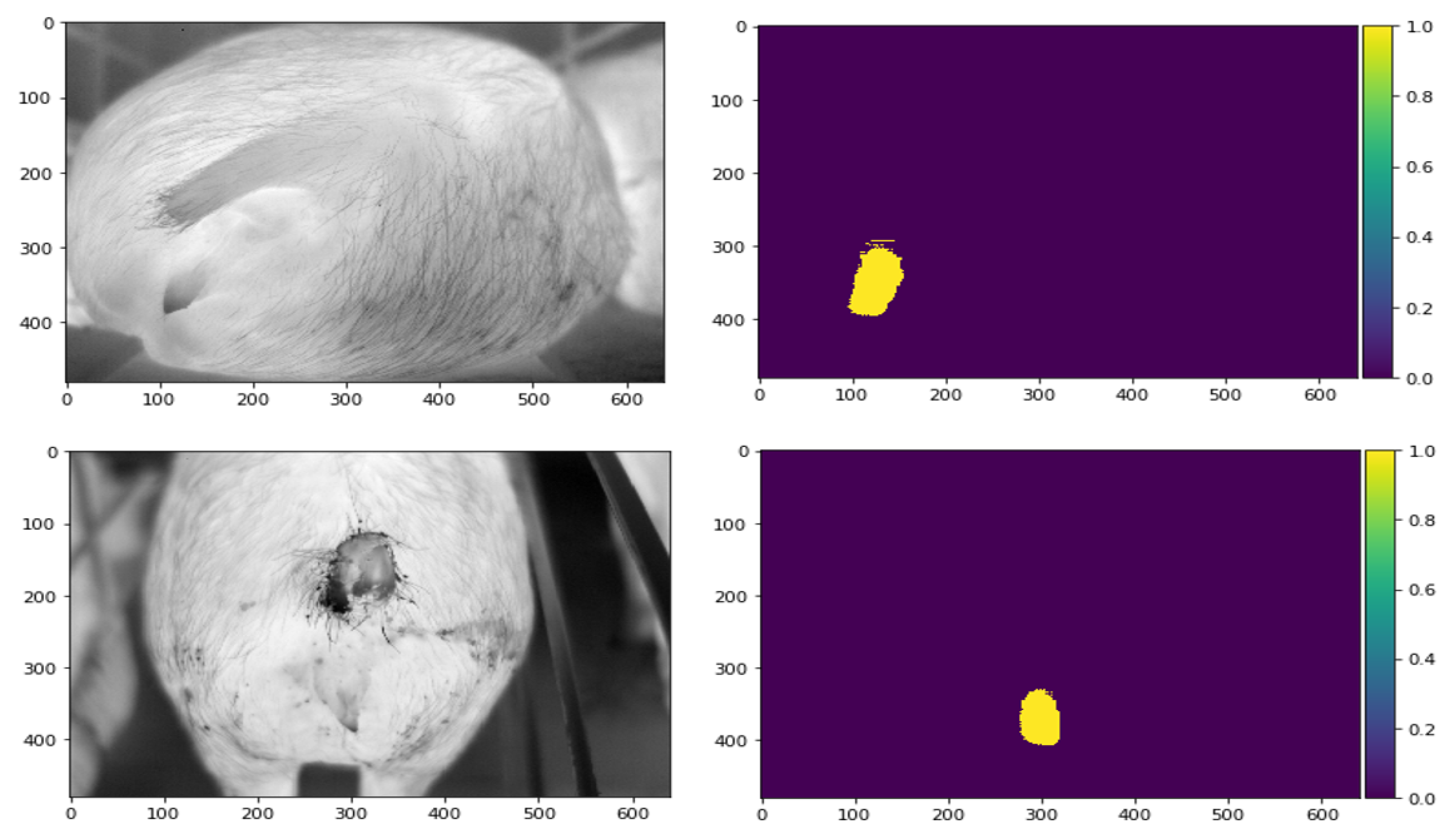
4.1. Data Collection and Preparation
4.2. Color Threshold
4.3. U-Net Semantic Segmentation Architecture
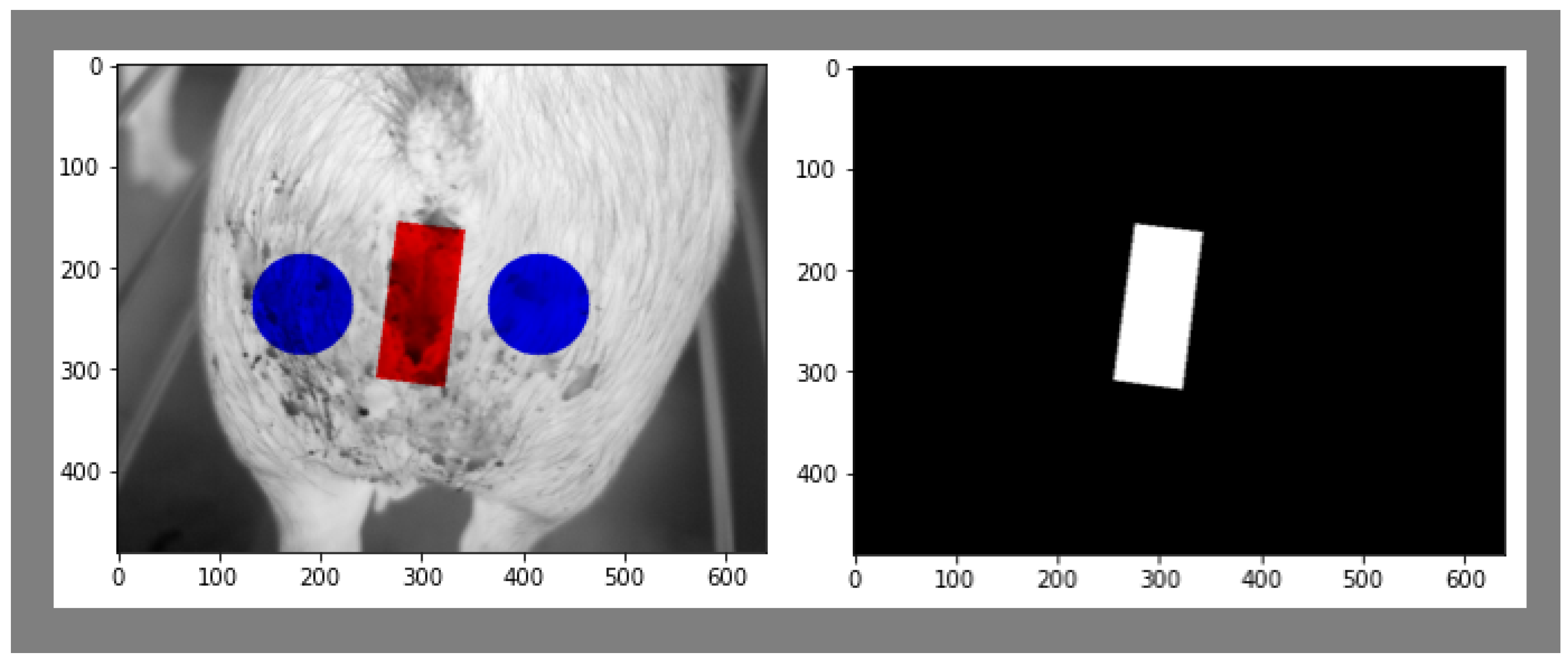
4.4. Training Masks
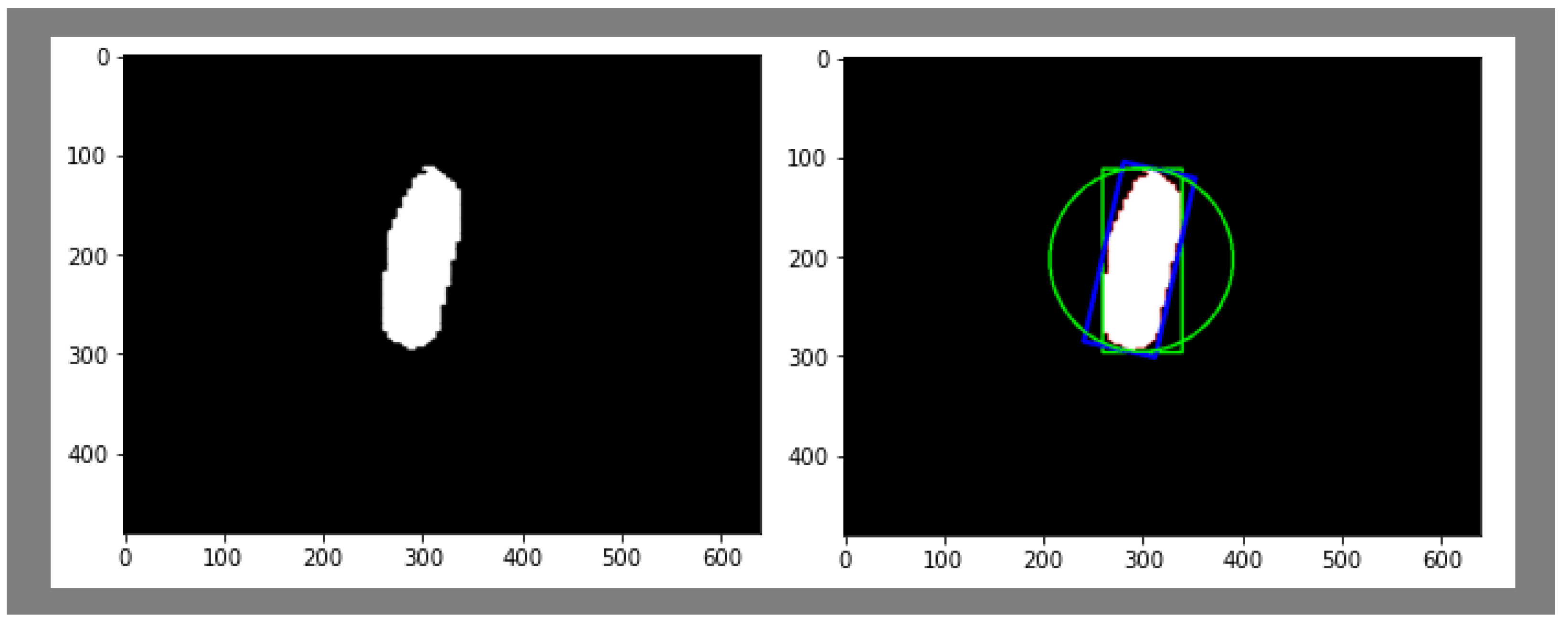
4.5. Minimum Area Rectangle
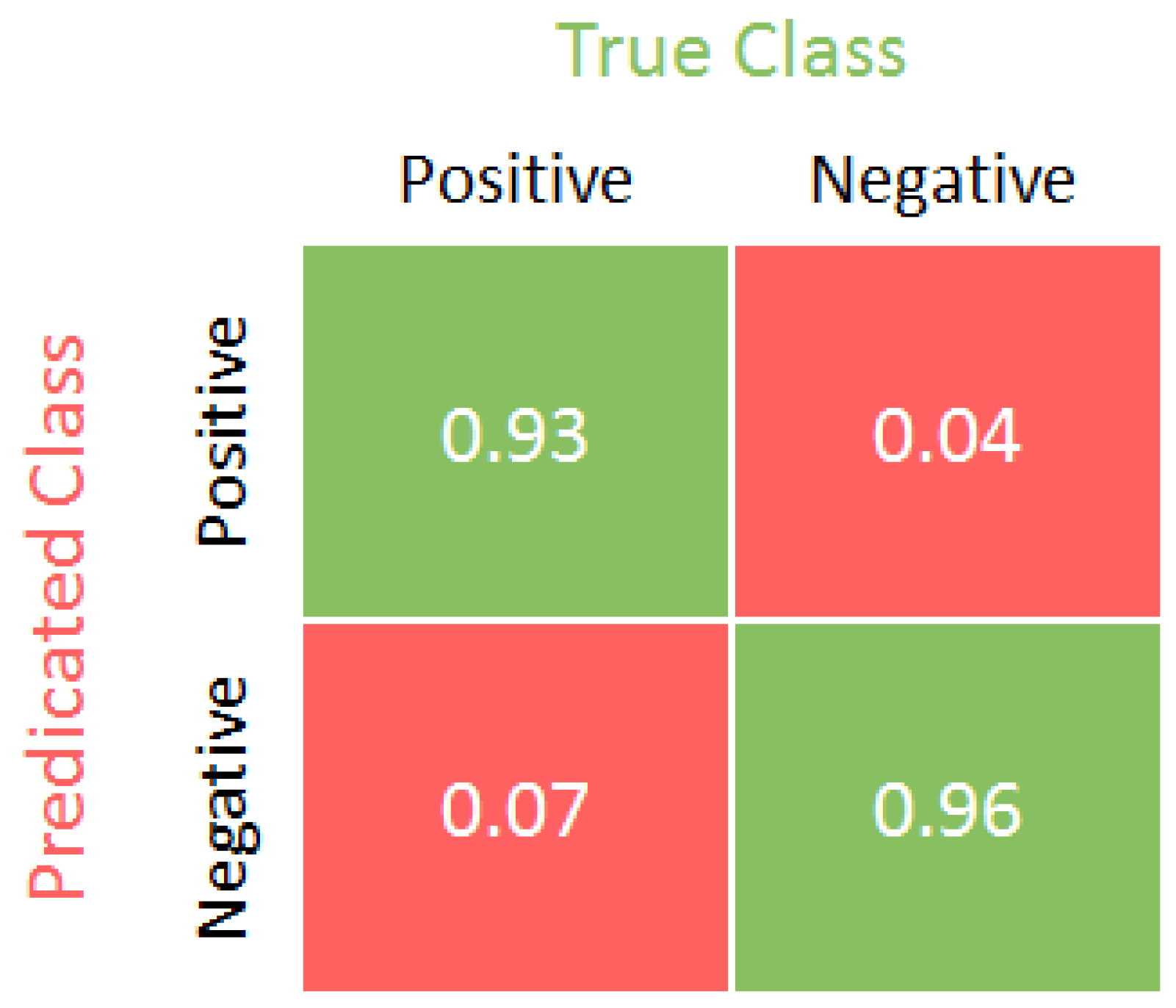
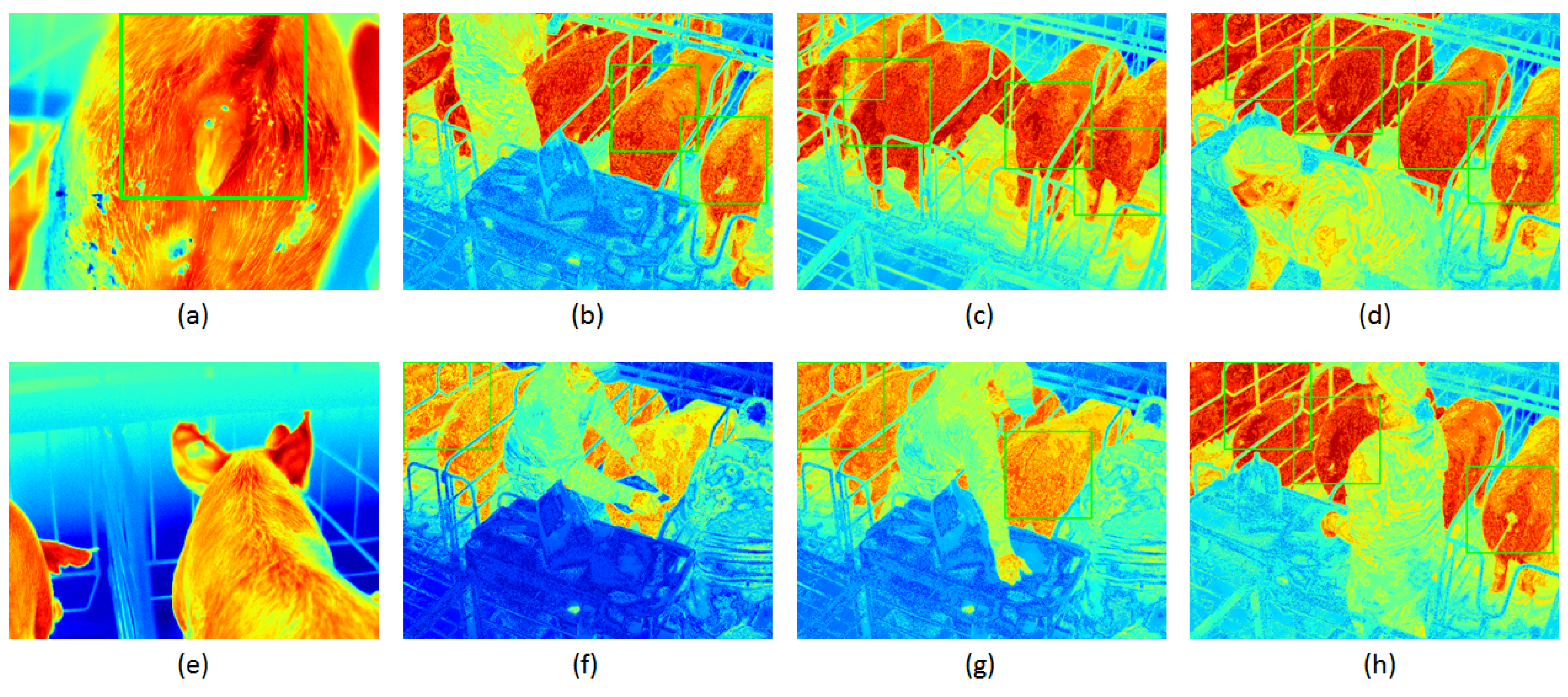
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koketsu, Y.; Tani, S.; Iida, R. Factors for improving reproductive performance of sows and herd productivity in commercial breeding herds. Porc. Health Manag. 2017, 3, 1. [Google Scholar] [CrossRef] [PubMed]
- Fry, J.P.; Mailloux, N.A.; Love, D.C.; Milli, M.C.; Cao, L. Feed conversion efficiency in aquaculture: Do we measure it correctly? Environ. Res. Lett. 2018, 13, 024017. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Labrecque, J.; Rivest, J. A real-time sow behavior analysis system to predict an optimal timing for insemination. In Proceedings of the 10th International Livestock Environment Symposium (ILES X), Omaha, NE, USA, 25–27 September 2018; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2018; p. 1. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Barbole, D.K.; Jadhav, P.M.; Patil, S. A review on fruit detection and segmentation techniques in agricultural field. In Proceedings of the Second International Conference on Image Processing and Capsule Networks: ICIPCN 2021, Bangkok, Thailand, 27–28 May 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 269–288. [Google Scholar]
- Qiao, Y.; Truman, M.; Sukkarieh, S. Cattle segmentation and contour extraction based on Mask R-CNN for precision livestock farming. Comput. Electron. Agric. 2019, 165, 104958. [Google Scholar] [CrossRef]
- Feng, D.; Harakeh, A.; Waslander, S.L.; Dietmayer, K. A review and comparative study on probabilistic object detection in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9961–9980. [Google Scholar] [CrossRef]
- Latif, J.; Xiao, C.; Imran, A.; Tu, S. Medical imaging using machine learning and deep learning algorithms: A review. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Almadani, M.; Elhayek, A.; Malik, J.; Stricker, D. Graph-Based Hand-Object Meshes and Poses Reconstruction With Multi-Modal Input. IEEE Access 2021, 9, 136438–136447. [Google Scholar] [CrossRef]
- Almadani, M.; Waheed, U.b.; Masood, M.; Chen, Y. Dictionary Learning With Convolutional Structure for Seismic Data Denoising and Interpolation. Geophysics 2021, 86, 1–102. [Google Scholar] [CrossRef]
- Abuhussein, M.; Robinson, A. Obscurant Segmentation in Long Wave Infrared Images Using GLCM Textures. J. Imaging 2022, 8, 266. [Google Scholar] [CrossRef] [PubMed]
- Chauhan, R.; Ghanshala, K.K.; Joshi, R. Convolutional neural network (CNN) for image detection and recognition. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 278–282. [Google Scholar]
- Moinuddin, K.A.; Havugimana, F.; Al-Fahad, R.; Bidelman, G.M.; Yeasin, M. Unraveling Spatial-Spectral Dynamics of Speech Categorization Speed Using Convolutional Neural Networks. Brain Sci. 2022, 13, 75. [Google Scholar] [CrossRef] [PubMed]
- Havugimana, F.; Moinuddin, K.A.; Yeasin, M. Deep Learning Framework for Modeling Cognitive Load from Small and Noisy EEG data. IEEE Trans. Cogn. Dev. Syst. 2022. [Google Scholar] [CrossRef]
- Havugimana, F.; Muhammad, M.B.; Moinudin, K.A.; Yeasin, M. Predicting Cognitive Load using Parameter-optimized CNN from Spatial-Spectral Representation of EEG Recordings. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 710–715. [Google Scholar]
- Jogin, M.; Mohana; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature extraction using convolution neural networks (CNN) and deep learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2319–2323. [Google Scholar]
- Li, G.; Jiao, J.; Shi, G.; Ma, H.; Gu, L.; Tao, L. Fast Recognition of Pig Faces Based on Improved Yolov3. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2171, p. 012005. [Google Scholar]
- Mao, Q.C.; Sun, H.M.; Liu, Y.B.; Jia, R.S. Mini-YOLOv3: Real-time object detector for embedded applications. IEEE Access 2019, 7, 133529–133538. [Google Scholar] [CrossRef]
- Sivamani, S.; Choi, S.H.; Lee, D.H.; Park, J.; Chon, S. Automatic posture detection of pigs on real-time using Yolo framework. Int. J. Res. Trends Innov. 2020, 5, 81–88. [Google Scholar]
- Ju, M.; Choi, Y.; Seo, J.; Sa, J.; Lee, S.; Chung, Y.; Park, D. A Kinect-based segmentation of touching-pigs for real-time monitoring. Sensors 2018, 18, 1746. [Google Scholar] [CrossRef] [PubMed]
- Almadani, I.; Abuhussein, M.; Robinson, A.L. Sow Localization in Thermal Images Using Gabor Filters. In Advances in Information and Communication, Proceedings of the FICC2022, San Francisco, CA, USA, 3–4 March 2022; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Xue, H.; Chen, J.; Ding, Q.; Sun, Y.; Shen, M.; Liu, L.; Chen, X.; Zhou, J. Automatic detection of sow posture and estrus based on convolutional neural network. Front. Phys. 2022, 10, 1037129. [Google Scholar] [CrossRef]
- Xu, Z.; Sullivan, R.; Zhou, J.; Bromfield, C.; Lim, T.T.; Safranski, T.J.; Yan, Z. Detecting sow vulva size change around estrus using machine vision technology. Smart Agric. Technol. 2023, 3, 100090. [Google Scholar] [CrossRef]
- Simões, V.G.; Lyazrhi, F.; Picard-Hagen, N.; Gayrard, V.; Martineau, G.P.; Waret-Szkuta, A. Variations in the vulvar temperature of sows during proestrus and estrus as determined by infrared thermography and its relation to ovulation. Theriogenology 2014, 82, 1080–1085. [Google Scholar] [CrossRef]
- Cabib, D.; Lavi, M.; Gil, A.; Milman, U. Long wave infrared (8 to 14 microns) hyperspectral imager based on an uncooled thermal camera and the traditional CI block interferometer (SI-LWIR-UC). In Proceedings of the Infrared Technology and Applications. International Society for Optics and Photonics, Orlando, FL, USA, 25–29 April 2011; Volume 8012, p. 80123H. [Google Scholar]
- Shen, F.; Zeng, G. Semantic image segmentation via guidance of image classification. Neurocomputing 2019, 330, 259–266. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Freeman, H.; Shapira, R. Determining the minimum-area encasing rectangle for an arbitrary closed curve. Commun. ACM 1975, 18, 409–413. [Google Scholar] [CrossRef]
- GitHub-Qengineering/YoloV8-ncnn-Raspberry-Pi-4: YoloV8 for a Bare Raspberry Pi 4—github.com. Available online: https://github.com/Qengineering/YoloV8-ncnn-Raspberry-Pi-4 (accessed on 26 April 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contraction Path (Encoder) | |||
|---|---|---|---|
| Block | Layer | No. of Filters | Activation Function |
| Block 1 | Conv2D (3,3) | 16 | relu |
| Conv2D (3,3) | 16 | relu | |
| Block 2 | Conv2D (3,3) | 32 | relu |
| Conv2D (3,3) | 32 | relu | |
| Block 3 | Conv2D (3,3) | 64 | relu |
| Conv2D (3,3) | 64 | relu | |
| Block 4 | Conv2D (3,3) | 128 | relu |
| Conv2D (3,3) | 128 | relu | |
| Block 5 | Conv2D (3,3) | 256 | relu |
| Conv2D (3,3) | 256 | relu | |
| Expansive Path (Decoder) | |||
| Block | Layer | No. of Filters | Activation Function |
| Block 6 | Conv2DTranspose (2,2) | 128 | …… |
| Concatenate (c4,Transpose(2,2)) | 128 | …… | |
| Conv2D (3,3) | 128 | relu | |
| Block 7 | Conv2DTranspose (2,2) | 64 | …… |
| Concatenate (c3,Transpose(2,2)) | 64 | …… | |
| Conv2D (3,3) | 64 | relu | |
| Block 8 | Conv2DTranspose (2,2) | 32 | …… |
| Concatenate (c2,Transpose(2,2)) | 32 | …… | |
| Conv2D (3,3) | 32 | relu | |
| Block 9 | Conv2DTranspose (2,2) | 16 | …… |
| Concatenate (c1,Transpose(2,2)) | 16 | …… | |
| Conv2D (3,3) | 16 | relu | |
| Comparison between Models | |||
|---|---|---|---|
| Approach | Mean IOU | Improved IOU | FPS |
| SVM | 0.400 | 0.450 | 35 |
| SVM with Gabor | 0.490 | 0.515 | 25 |
| YOLOv3 | 0.520 | 0.520 | 40 |
| U-Net | 0.500 | 0.586 | 45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almadani, I.; Ramos, B.; Abuhussein, M.; Robinson, A.L. Advanced Swine Management: Infrared Imaging for Precise Localization of Reproductive Organs in Livestock Monitoring. Digital 2024, 4, 446-460. https://doi.org/10.3390/digital4020022
Almadani I, Ramos B, Abuhussein M, Robinson AL. Advanced Swine Management: Infrared Imaging for Precise Localization of Reproductive Organs in Livestock Monitoring. Digital. 2024; 4(2):446-460. https://doi.org/10.3390/digital4020022
Chicago/Turabian StyleAlmadani, Iyad, Brandon Ramos, Mohammed Abuhussein, and Aaron L. Robinson. 2024. "Advanced Swine Management: Infrared Imaging for Precise Localization of Reproductive Organs in Livestock Monitoring" Digital 4, no. 2: 446-460. https://doi.org/10.3390/digital4020022
APA StyleAlmadani, I., Ramos, B., Abuhussein, M., & Robinson, A. L. (2024). Advanced Swine Management: Infrared Imaging for Precise Localization of Reproductive Organs in Livestock Monitoring. Digital, 4(2), 446-460. https://doi.org/10.3390/digital4020022