
StreetLines: A Smart and Scalable Tourism Platform Based on Efficient Knowledge-Mining

 ,
,  ,
,  , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
2. Related Work
2.1. Tourism-Related Data Mining Platforms
2.2. Keyword Extraction
2.3. Sentiment Analysis
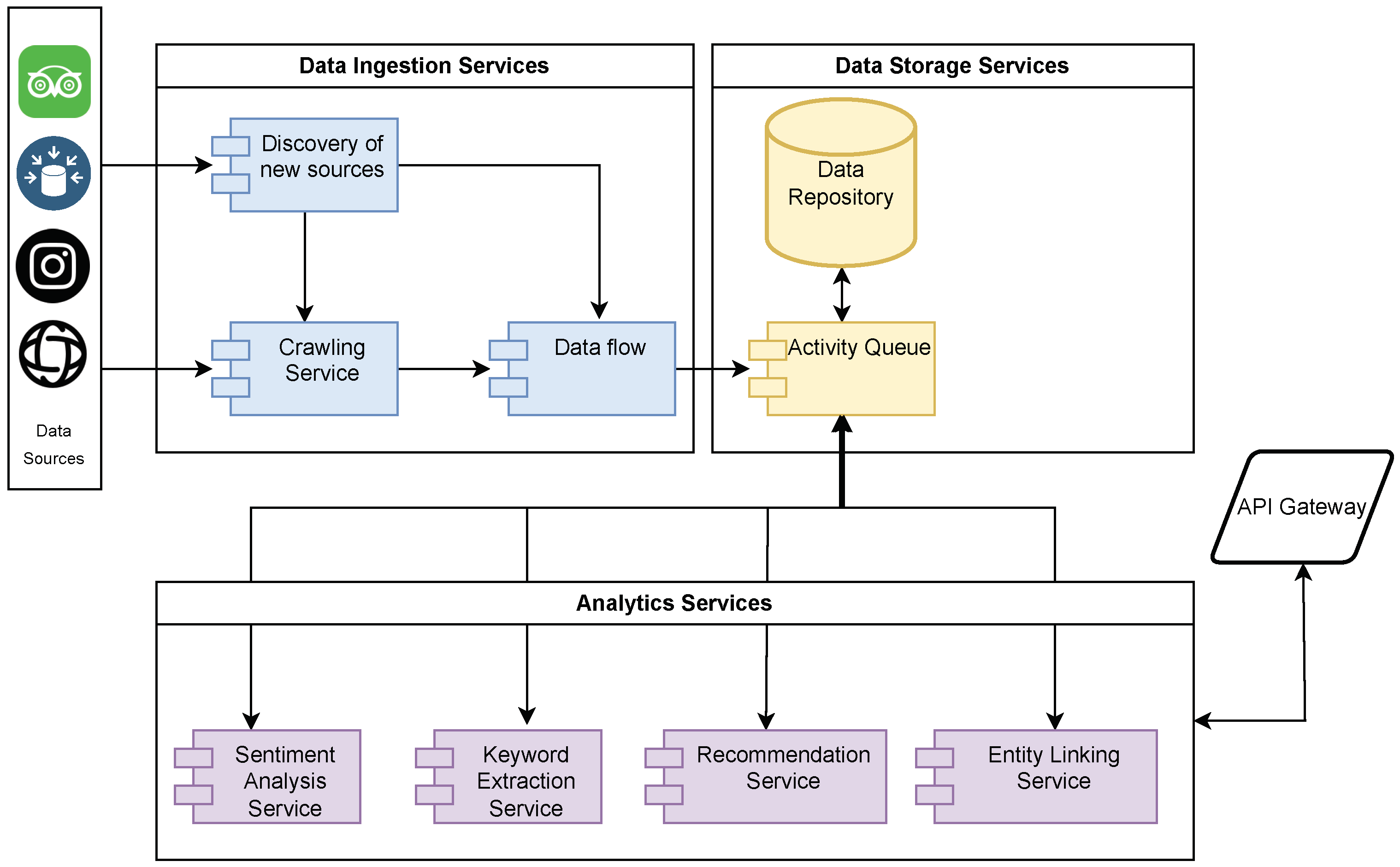
3. System Architecture
3.1. The StreetLines Platform
3.2. Implementation Details
4. Components
4.1. Data Sources and Crawling
4.2. Keyword Extraction
4.3. Sentiment Analysis
4.4. Entity Linking
4.5. Recommendation
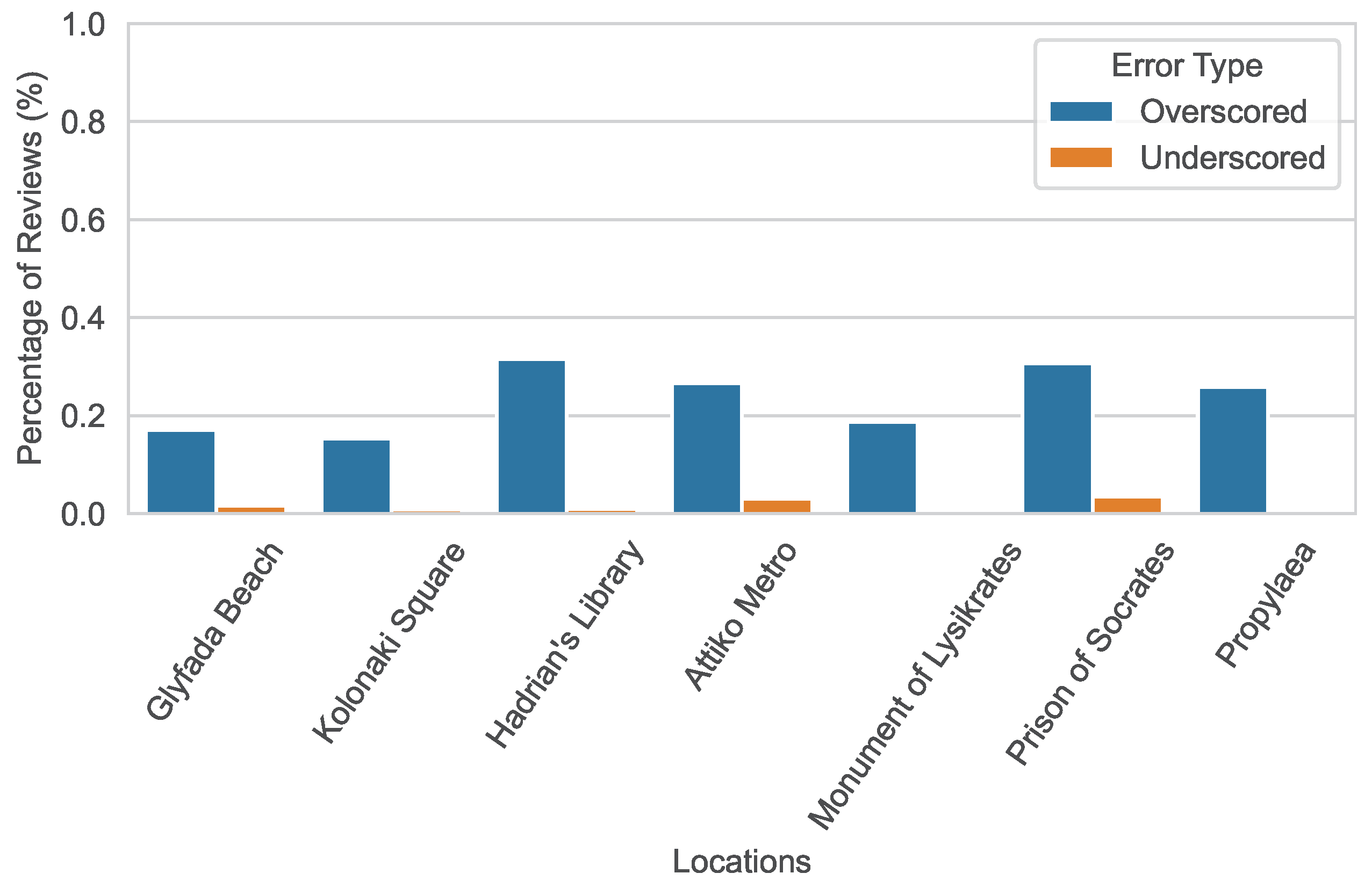
5. Evaluation
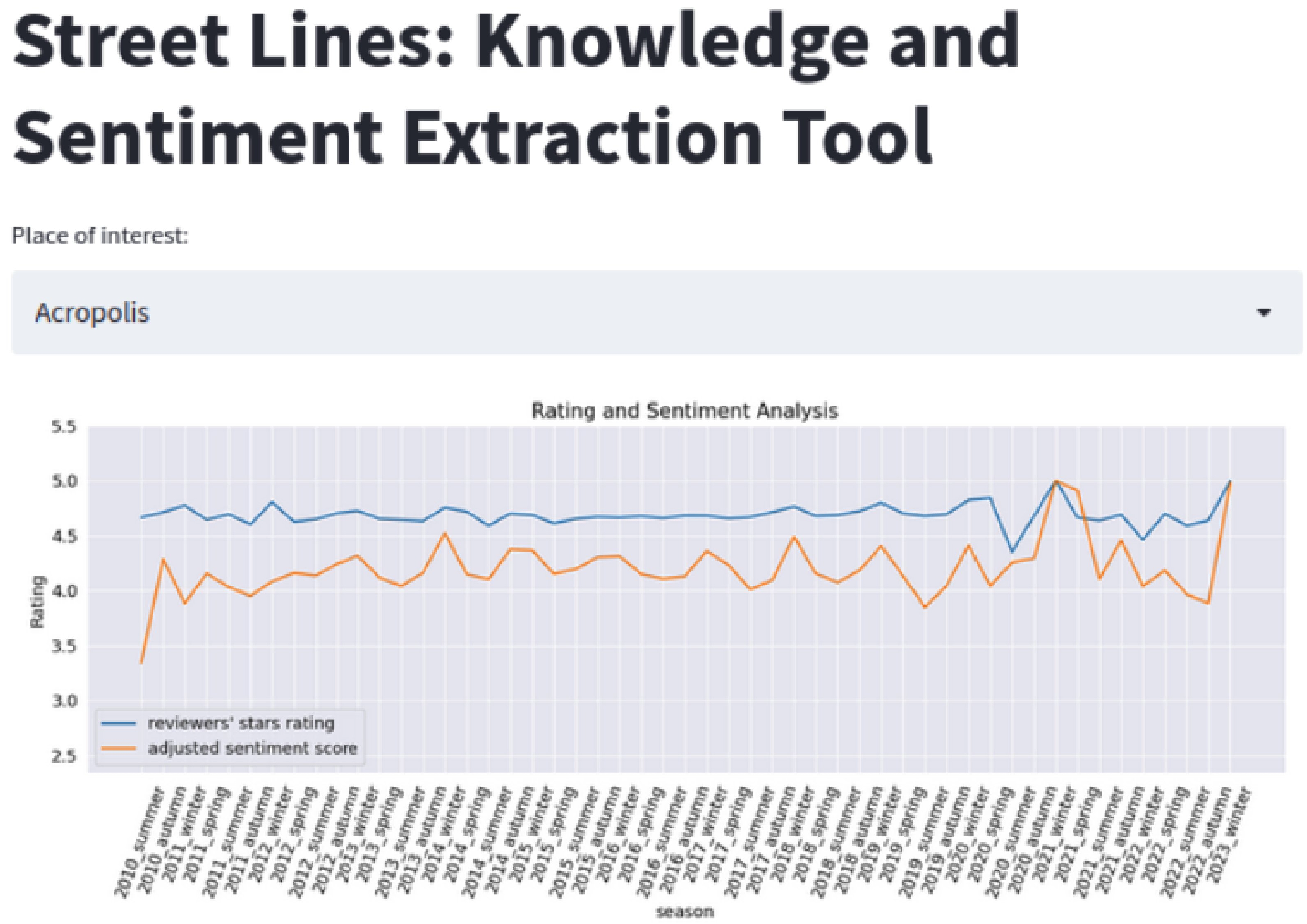
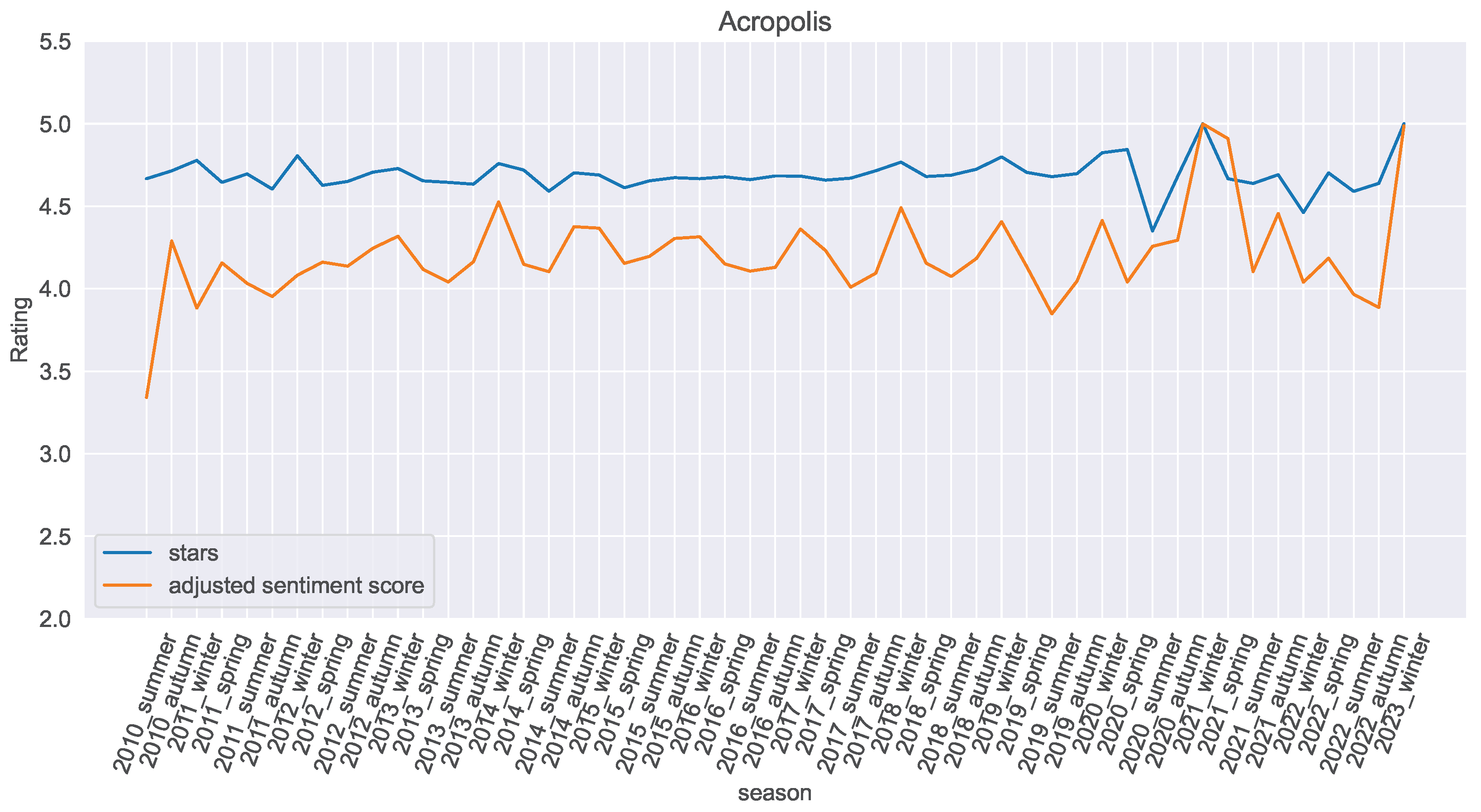
5.1. Platform
5.2. Sentiment Analysis Service
6. Discussion
6.1. Overview
6.2. Limitations
6.3. Extensions
6.3.1. Context and Personalization
6.3.2. Recommendation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AJAX | Asynchronous JavaScript and XML |
| API | Application Programming Interface |
| AR | Augmented Reality |
| BERT | Bidirectional Encoder Representations from Transformers |
| BiLSTM | Bidirectional Long Short-Term Memory networks |
| CNN | Convolutional Neural Network |
| DOM | Document Object Model |
| ED | Entity Disambiguation |
| EL | Entity Linking |
| ER | Entity Recognition |
| FFNN | Feed Forward Neural Network |
| HTTP | Hypertext Transfer Protocol |
| JSON | JavaScript Object Notation |
| KB | Knowledge Base |
| LOD | Linked Open Data |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| POI | Point of Interest |
| REST | Representational State Transfer |
| RS | Recommender System |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| UGC | User-Generated Content |
| URI | Uniform Resource Identifier |
| URL | Uniform Resource Locator |
| VR | Virtual Reality |
| XML | Extensible Markup Language |
References
- Buhalis, D.; Amaranggana, A. Smart Tourism Destinations Enhancing Tourism Experience Through Personalisation of Services. In Proceedings of the Information and Communication Technologies in Tourism, Lugano, Switzerland, 3–6 February 2015; Tussyadiah, I., Inversini, A., Eds.; Springer: Cham, Swizerland, 2015; pp. 377–389. [Google Scholar]
- Lu, W.; Stepchenkova, S. User-Generated Content as a Research Mode in Tourism and Hospitality Applications: Topics, Methods, and Software. J. Hosp. Mark. Manag. 2015, 24, 119–154. [Google Scholar] [CrossRef]
- Iorio, C.; Pandolfo, G.; D’Ambrosio, A.; Siciliano, R. Mining big data in tourism. Qual. Quant. 2020, 54, 1655–1669. [Google Scholar] [CrossRef]
- Han, S.; Anderson, C.K. Web Scraping for Hospitality Research: Overview, Opportunities, and Implications. Cornell Hosp. Q. 2021, 62, 89–104. [Google Scholar] [CrossRef]
- StreetLines. StreetLines Project. 2023. Available online: https://streetlines.gr/ (accessed on 20 January 2024).
- Lyu, J.; Khan, A.; Bibi, S.; Chan, J.H.; Qi, X. Big data in action: An overview of big data studies in tourism and hospitality literature. J. Hosp. Tour. Manag. 2022, 51, 346–360. [Google Scholar] [CrossRef]
- Raj, S.; Kajla, T. Tourism analytics: Social media analytics framework for promoting Asian tourist destinations using big data approach. J. Glob. Bus. Adv. 2018, 11, 64–88. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, C.; Kimmons, B. Detecting tourism destinations using scalable geospatial analysis based on cloud computing platform. Comput. Environ. Urban Syst. 2015, 54, 144–153. [Google Scholar] [CrossRef]
- Bustamante, A.; Sebastia, L.; Onaindia, E. BITOUR: A Business Intelligence Platform for Tourism Analysis. ISPRS Int. J. Geo-Inf. 2020, 9, 671. [Google Scholar] [CrossRef]
- Marine-Roig, E.; Anton Clavé, S. Tourism analytics with massive user-generated content: A case study of Barcelona. J. Destin. Mark. Manag. 2015, 4, 162–172. [Google Scholar] [CrossRef]
- Wenan, T.; Shrestha, D.; Gaudel, B.; Rajkarnikar, N.; Jeong, S.R. Analysis and Evaluation of TripAdvisor Data: A Case of Pokhara, Nepal. In Proceedings of the Intelligent Computing & Optimization, Hua Hin, Thailand, 27–28 October 2022; Vasant, P., Zelinka, I., Weber, G.W., Eds.; Springer: Cham, Switzerland, 2022; pp. 738–750. [Google Scholar]
- Álvarez Carmona, M.A.; Aranda, R.; Rodríguez-Gonzalez, A.Y.; Fajardo-Delgado, D.; Sánchez, M.G.; Pérez-Espinosa, H.; Martínez-Miranda, J.; Guerrero-Rodríguez, R.; Bustio-Martínez, L.; Díaz-Pacheco, Á. Natural language processing applied to tourism research: A systematic review and future research directions. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 10125–10144. [Google Scholar] [CrossRef]
- Li, J.; Xu, L.; Tang, L.; Wang, S.; Li, L. Big data in tourism research: A literature review. Tour. Manag. 2018, 68, 301–323. [Google Scholar] [CrossRef]
- Le Huy, H.N.; Minh, H.H.; Van, T.N.; Van, H.N. Keyphrase extraction model: A new design and application on tourism information. Informatica 2021, 45. [Google Scholar] [CrossRef]
- Liu, Z.; Masui, F.; Ptaszynski, M. Supporting Inbound Tourism in Hokkaido: Keyword Extraction and Focus Point Analysis from Spot Reviews. In Proceedings of the 2021 International Workshop on Modern Science and Technology, Hangzhou, China, 16–18 July 2021; The International Center of National University Corporation Kitami Institute: Kitami, Japan, 2021; Voluem 2021, pp. 151–156. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Qian, H.; Tang, Z.; Ren, Y.; Li, Q.; Zeng, D. A Transformer-based Approach for Identifying Target-oriented Opinions from Travel Reviews. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Mehraliyev, F.; Chan, I.C.C.; Kirilenko, A.P. Sentiment analysis in hospitality and tourism: A thematic and methodological review. Int. J. Contemp. Hosp. Manag. 2022, 34, 46–77. [Google Scholar] [CrossRef]
- Anis, S.; Saad, S.; Aref, M. Sentiment Analysis of Hotel Reviews Using Machine Learning Techniques. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 19–21 October 2020; Hassanien, A.E., Slowik, A., Snášel, V., El-Deeb, H., Tolba, F.M., Eds.; Springer: Cham, Switzerland, 2021; pp. 227–234. [Google Scholar]
- Puh, K.; Bagić Babac, M. Predicting sentiment and rating of tourist reviews using machine learning. J. Hosp. Tour. Insights 2023, 6, 1188–1204. [Google Scholar] [CrossRef]
- FastAPI. Available online: https://fastapi.tiangolo.com/ (accessed on 15 June 2024).
- Streamlit. Available online: https://streamlit.io/ (accessed on 15 June 2024).
- TripAdvisor. Over a Billion Reviews & Contributions for Hotels, Attractions, Restaurants, and More. Available online: https://www.tripadvisor.com/ (accessed on 29 February 2024).
- Google Maps. Available online: https://maps.google.com/ (accessed on 29 February 2024).
- Tripadvisor Content API. Available online: https://tripadvisor-content-api.readme.io/reference/getlocationreviews (accessed on 29 February 2024).
- Places Details|Places API|Google for Developers. Available online: https://developers.google.com/maps/documentation/places/web-service/details (accessed on 29 February 2024).
- Zhao, B. Web Scraping. In Encyclopedia of Big Data; Schintler, L.A., McNeely, C.L., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–3. [Google Scholar] [CrossRef]
- Bar-Ilan, J. Data collection methods on the Web for infometric purposes—A review and analysis. Scientometrics 2001, 50, 7–32. [Google Scholar] [CrossRef]
- Yi, J.; Nasukawa, T.; Bunescu, R.; Niblack, W. Sentiment analyzer: Extracting sentiments about a given topic using natural language processing techniques. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003; pp. 427–434. [Google Scholar] [CrossRef]
- W3C. Document Object Model (DOM) Level 3 Core Specification; Technical report; World Wide Web Consortium, 2004; Available online: https://www.w3.org/TR/DOM-Level-3-Core/ (accessed on 29 February 2024).
- Free Software Foundation. GNU Wget; GNU Project; Free Software Foundation: Boston, MA, USA, 2021. [Google Scholar]
- Curl—A Tool to Transfer Data from or to a Server. 2024. Available online: https://curl.se/ (accessed on 29 February 2024).
- Urllib—URL Handling Modules. Available online: https://docs.python.org/3/library/urllib.html (accessed on 29 February 2024).
- Reitz, K. Requests: HTTP for Humans. In Requests Documentation; 2013; Available online: https://requests.readthedocs.io/en/latest/ (accessed on 29 February 2024).
- The Selenium Browser Automation Project. Available online: https://www.selenium.dev/ (accessed on 29 February 2024).
- Richardson, L. Beautiful Soup. 2004. Available online: https://www.crummy.com/software/BeautifulSoup/ (accessed on 29 February 2024).
- Introduction to Marionette. Available online: https://firefox-source-docs.mozilla.org/testing/marionette/Intro.html (accessed on 29 February 2024).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; 2017; pp. 5998–6008. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. In Proceedings of the The IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Hamborg, F.; Meuschke, N.; Breitinger, C.; Gipp, B. News-please: A Generic News Crawler and Extractor. In Proceedings of the 15th International Symposium of Information Science, Berlin, Germany, 13–15 March 2017; pp. 218–223. [Google Scholar] [CrossRef]
- Gokaslan, A.; Cohen, V. OpenWebText Corpus. 2019. Available online: http://Skylion007.github.io/OpenWebTextCorpus (accessed on 29 February 2024).
- Trinh, T.H.; Le, Q.V. A Simple Method for Commonsense Reasoning. arXiv 2019, arXiv:1806.02847. [Google Scholar]
- Papagiannis, T.; Ioannou, G.; Michalakis, K.; Alexandridis, G.; Caridakis, G. Analyzing User Reviews in the Tourism & Cultural Domain - The Case of the City of Athens, Greece. In Proceedings of the Artificial Intelligence Applications and Innovations. AIAI 2023 IFIP WG 12.5 International Workshops, Leόn, Spain, 14–17 June 2023; Maglogiannis, I., Iliadis, L., Papaleonidas, A., Chochliouros, I., Eds.; Springer: Cham, Switzerland, 2023; pp. 284–293. [Google Scholar]
- Cao, L.; Luo, C.; Zhang, C. Agent-mining interaction: An emerging area. In Proceedings of the International Workshop on Autonomous Intelligent Systems: Multi-Agents and Data Mining, St. Petersburg, Russia, 3–5 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 60–73. [Google Scholar]
- Mohit, B. Named entity recognition. In Natural Language Processing of Semitic Languages; Springer: Berlin/Heidelberg, Germany, 2014; pp. 221–245. [Google Scholar]
- Derczynski, L.; Maynard, D.; Rizzo, G.; Van Erp, M.; Gorrell, G.; Troncy, R.; Petrak, J.; Bontcheva, K. Analysis of named entity recognition and linking for tweets. Inf. Process. Manag. 2015, 51, 32–49. [Google Scholar] [CrossRef]
- Shen, W.; Wang, J.; Han, J. Entity linking with a knowledge base: Issues, techniques, and solutions. IEEE Trans. Knowl. Data Eng. 2014, 27, 443–460. [Google Scholar] [CrossRef]
- Guo, Z. Towards an Accurate, Robust, and Scalable Named Entity Disambiguation System. Ph.D. Thesis, University of Alberta, Edmonton, AB, Canada, 2018. [Google Scholar]
- Fafalios, P.; Baritakis, M.; Tzitzikas, Y. Exploiting linked data for open and configurable named entity extraction. Int. J. Artif. Intell. Tools 2015, 24, 1540012. [Google Scholar] [CrossRef]
- Ristoski, P.; Paulheim, H. Rdf2vec: Rdf graph embeddings for data mining. In Proceedings of the The Semantic Web–ISWC 2016: 15th International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; Proceedings, Part I 15. Springer: Berlin/Heidelberg, Germany, 2016; pp. 498–514. [Google Scholar]
- Frontini, F.; Brando, C.; Ganascia, J.G. Semantic web based named entity linking for digital humanities and heritage texts. In Proceedings of the First International Workshop Semantic Web for Scientific Heritage at the 12th ESWC 2015 Conference, Portorož, Slovenia, 1 June 2015. [Google Scholar]
- Kolitsas, N.; Ganea, O.E.; Hofmann, T. End-to-end neural entity linking. arXiv 2018, arXiv:1808.07699. [Google Scholar]
- Ji, Y.; Tan, C.; Martschat, S.; Choi, Y.; Smith, N.A. Dynamic entity representations in neural language models. arXiv 2017, arXiv:1708.00781. [Google Scholar]
- Lee, K.; He, L.; Lewis, M.; Zettlemoyer, L. End-to-end neural coreference resolution. arXiv 2017, arXiv:1707.07045. [Google Scholar]
- Ganea, O.E.; Hofmann, T. Deep joint entity disambiguation with local neural attention. arXiv 2017, arXiv:1704.04920. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Wang, H.; Lu, Y.; Zhai, C. Latent aspect rating analysis on review text data: A rating regression approach. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 783–792. [Google Scholar]
- Kusumasondjaja, S.; Shanka, T.; Marchegiani, C. Credibility of online reviews and initial trust: The roles of reviewer’s identity and review valence. J. Vacat. Mark. 2012, 18, 185–195. [Google Scholar] [CrossRef]
- Choi, S.; Mattila, A.S.; Hoof, H.B.V.; Quadri-Felitti, D. The Role of Power and Incentives in Inducing Fake Reviews in the Tourism Industry. J. Travel Res. 2017, 56, 975–987. [Google Scholar] [CrossRef]
- Mariani, M.M.; Borghi, M.; Okumus, F. Unravelling the effects of cultural differences in the online appraisal of hospitality and tourism services. Int. J. Hosp. Manag. 2020, 90, 102606. [Google Scholar] [CrossRef]
- Papadis, N.; Stai, E.; Karyotis, V. A path-based recommendations approach for online systems via hyperbolic network embedding. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 973–980. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Result | POI | BPR Score |
|---|---|---|
| 1 | Benaki Museum | |
| 2 | Church of Kapnikarea | |
| 3 | Arch of Hadrian | |
| 4 | Attiko Metro | |
| 5 | Anafiotika |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| NEGATIVE | 61 | |||
| POSITIVE | 169 | |||
| Accuracy | - | - | 230 | |
| Macro Avg | 230 | |||
| Weighted Avg | 230 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alexandridis, G.; Siolas, G.; Papagiannis, T.; Ioannou, G.; Michalakis, K.; Caridakis, G.; Karyotis, V.; Papavassiliou, S. StreetLines: A Smart and Scalable Tourism Platform Based on Efficient Knowledge-Mining. Digital 2024, 4, 676-697. https://doi.org/10.3390/digital4030034
Alexandridis G, Siolas G, Papagiannis T, Ioannou G, Michalakis K, Caridakis G, Karyotis V, Papavassiliou S. StreetLines: A Smart and Scalable Tourism Platform Based on Efficient Knowledge-Mining. Digital. 2024; 4(3):676-697. https://doi.org/10.3390/digital4030034
Chicago/Turabian StyleAlexandridis, Georgios, Georgios Siolas, Tasos Papagiannis, George Ioannou, Konstantinos Michalakis, George Caridakis, Vasileios Karyotis, and Symeon Papavassiliou. 2024. "StreetLines: A Smart and Scalable Tourism Platform Based on Efficient Knowledge-Mining" Digital 4, no. 3: 676-697. https://doi.org/10.3390/digital4030034
APA StyleAlexandridis, G., Siolas, G., Papagiannis, T., Ioannou, G., Michalakis, K., Caridakis, G., Karyotis, V., & Papavassiliou, S. (2024). StreetLines: A Smart and Scalable Tourism Platform Based on Efficient Knowledge-Mining. Digital, 4(3), 676-697. https://doi.org/10.3390/digital4030034