
GDPR-Compliant Social Network Link Prediction in a Graph DBMS: The Case of Know-How Development at Beekeeper



Abstract
1. Introduction
1.1. Use Case
1.2. Research Goals, Questions, and Objectives
- Results of model accuracy
- Training time
- Model features
- Advantages and disadvantages of the models
- Disadvantages of the individual models
- Model performance on small datasets
- Artifact 1: Building Knowledge Graph-Based on User Interaction
- Artifact 2: Link Prediction with Neo4J Graph Machine Learning Algorithms
- Artifact 3: Link Prediction for User Relationships with scikit-learn
1.3. Limitations
2. State of the Art
2.1. Social Networks
2.2. Community Detection
2.3. Link Prediction
2.4. Graph Databases
2.5. Machine Learning on Graphs
3. Materials and Methods
- Look at the big picture.
- Get the data.
- Discover and visualize the data to gain insights.
- Prepare the data for machine learning algorithms.
- Select a model and train it.
- Fine tune your model.
- Present your solution.
- Launch, monitor, and maintain your system.
3.1. Data Preparation
3.2. Data Transformation
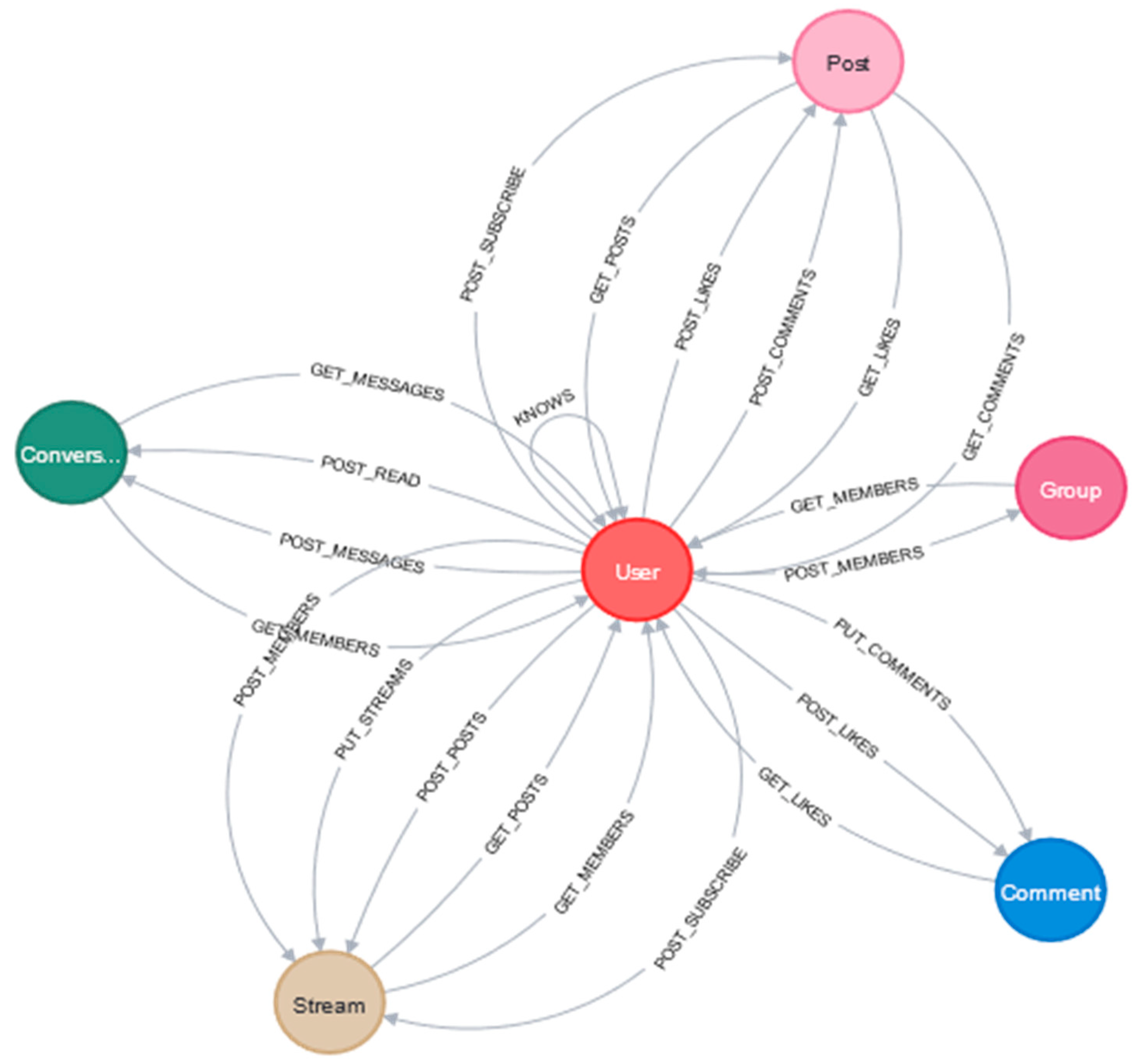
3.3. Data Model in Neo4j
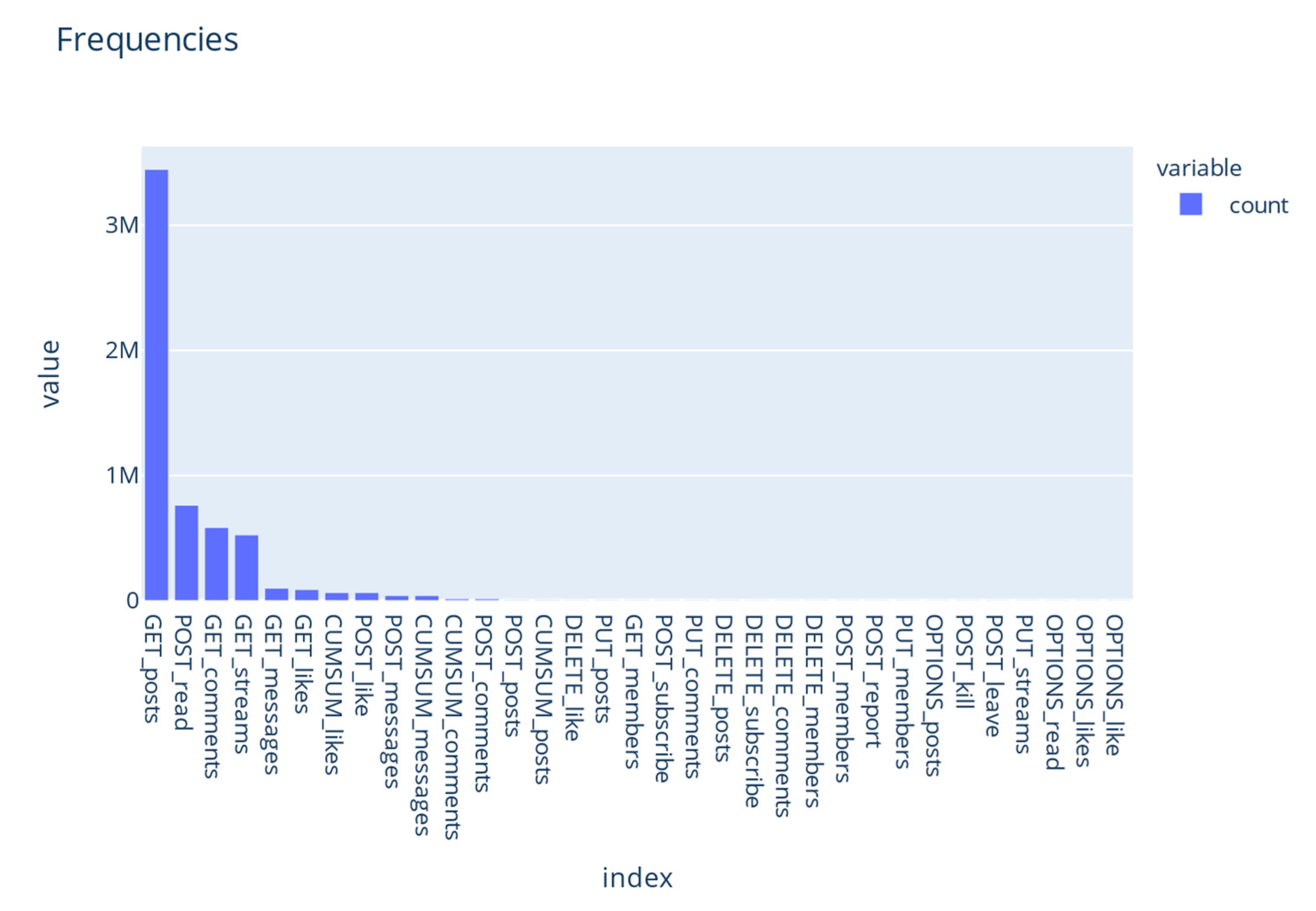
3.4. Exploratory Analysis
3.5. Artifact Design
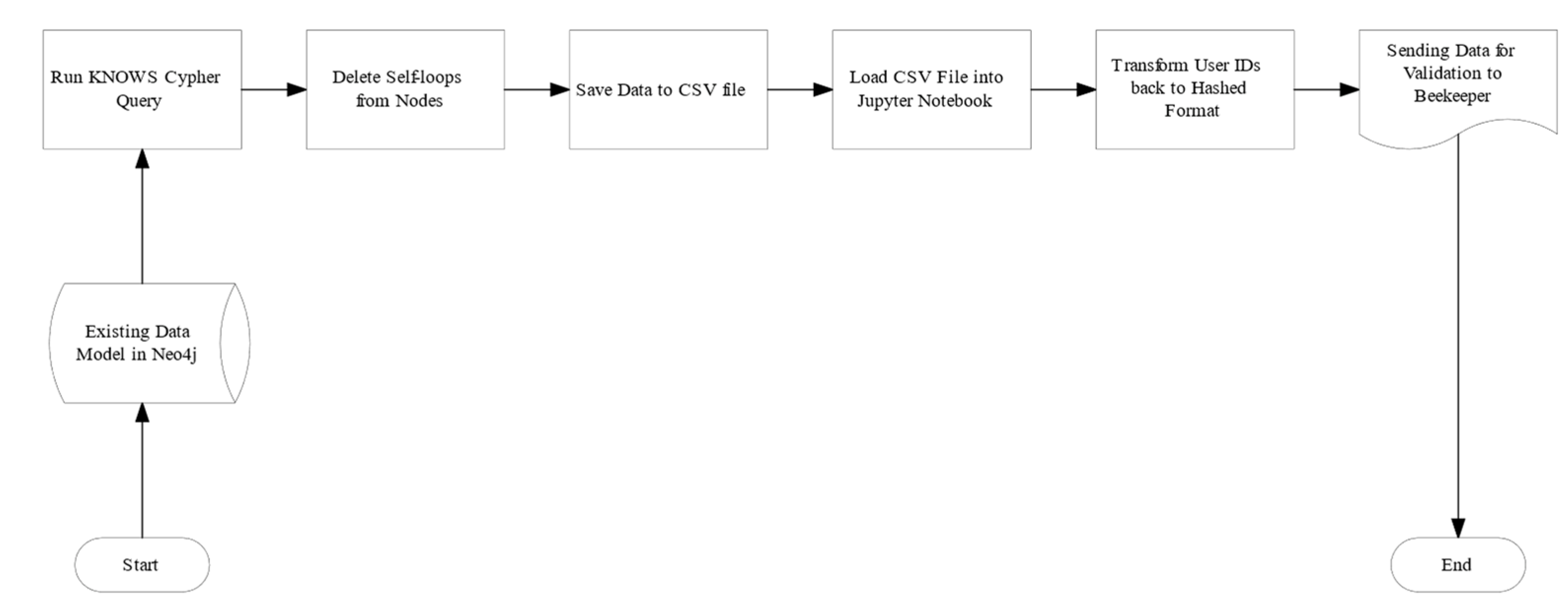
3.5.1. Artifact 1: Building Knowledge Graph-Based on User Interaction
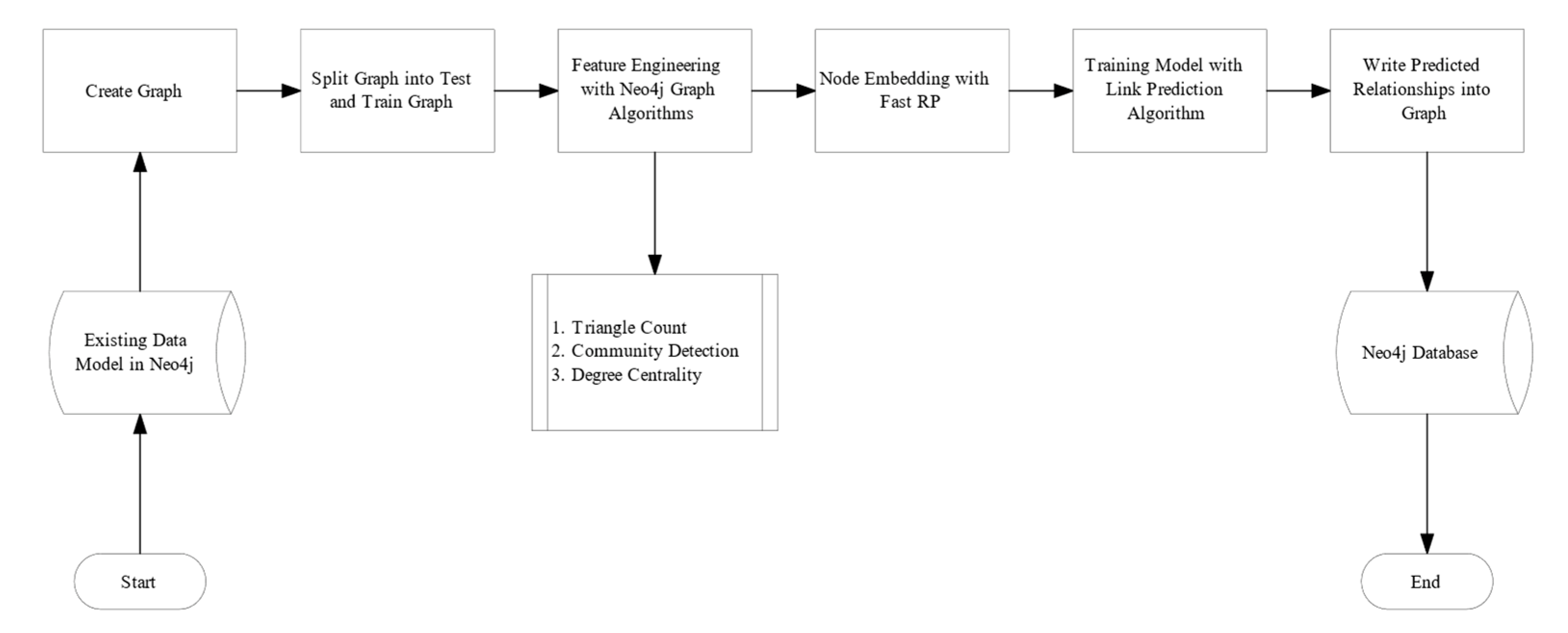
3.5.2. Artifact 2: Link Prediction with Neo4J Graph Machine Learning Algorithms
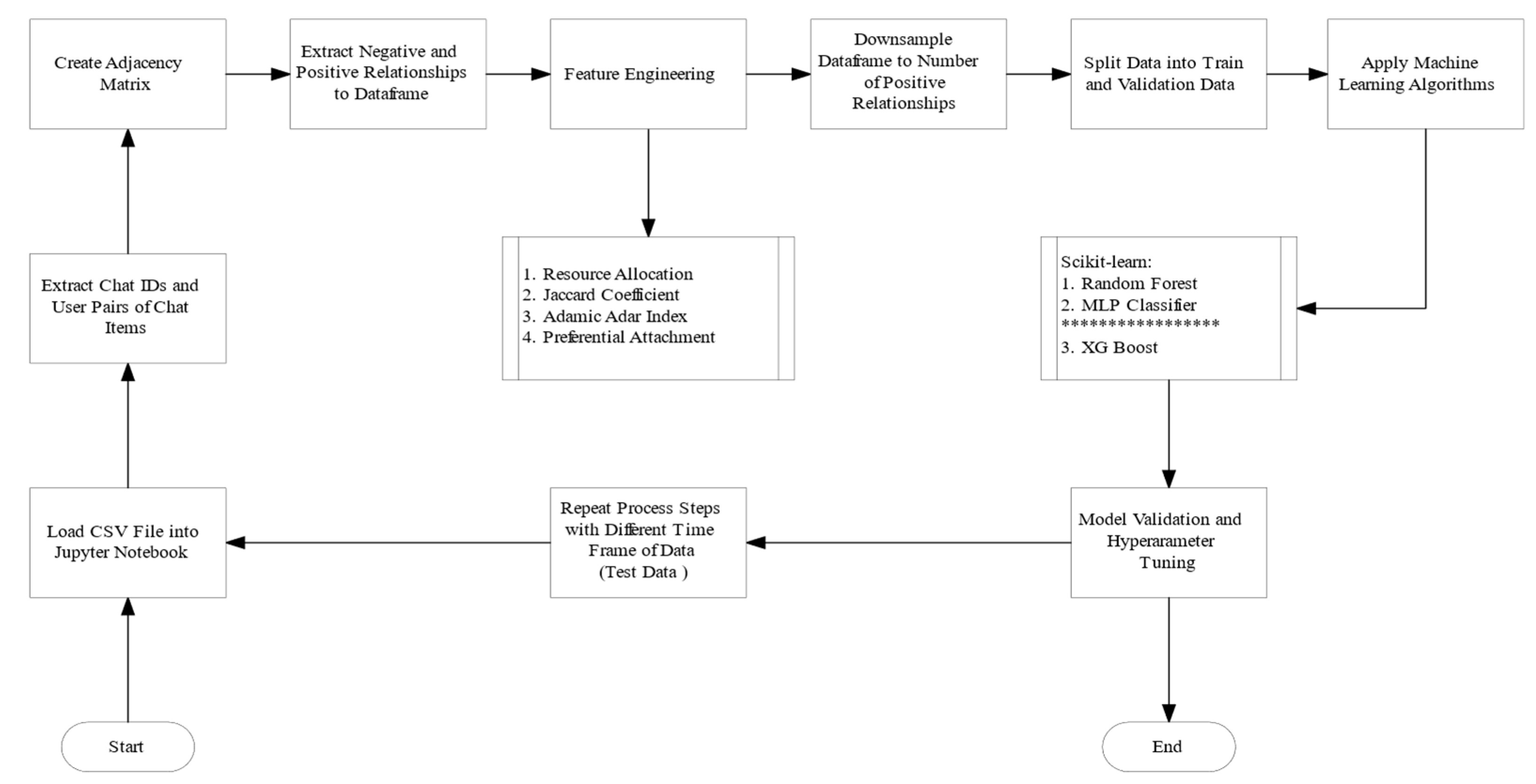
3.5.3. Artifact 3: Link Prediction for User Relationships with Scikit-Learn
4. Results
4.1. Resulting Artifacts
4.1.1. Artifact 1: Who knows who Knowledge Graph
4.1.2. Artifact 2: Link Prediction using Neo4j in-Database Algorithms
4.1.3. Artifact 3: Link Prediction with Scikit-Learn
4.2. Evaluation of Artifacts
4.2.1. Evaluation of Artifact 1
4.2.2. Evaluation of Artifact 2
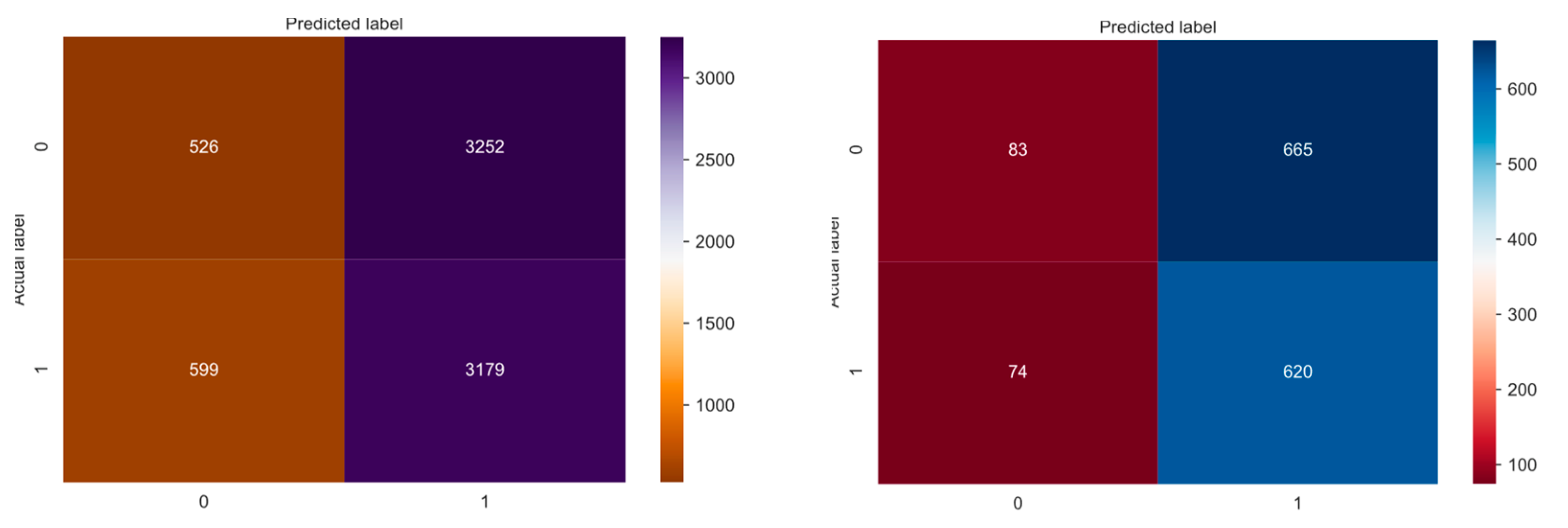
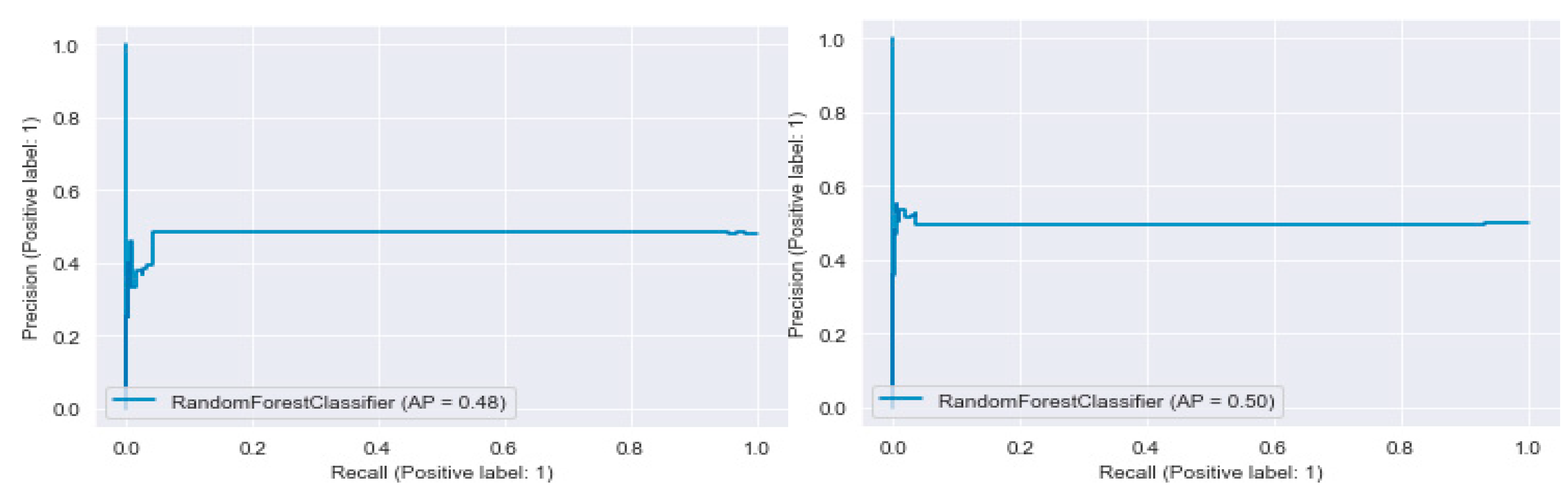
4.2.3. Evaluation of Artifact 3
5. Discussion
5.1. Insights from the Artifact Evaluation
5.2. Lessons Learned in the Study Case (Beekeeper)
- Outsourcing the prototype to industry partners and consultants such as Price Waterhouse Coopers, Accenture, etc.
- Internal research and development or prototyping through an academic partner.
5.3. Summary and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boyd, D.M.; Ellison, N.B. Social Network Sites: Definition, History, and Scholarship. J. Comput.-Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef]
- Heim, S.; Yang, S. Content Attractiveness in Enterprise Social Networks. In Proceedings of the 2nd European Conference on Social Media (ecsm 2015), Porto, Portugal, 9–10 July 2015; pp. 199–206. Available online: https://www.webofscience.com/wos/woscc/full-record/WOS:000404225700025 (accessed on 11 October 2021).
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link Prediction in Social Networks: The State-of-the-Art. arXiv 2014, arXiv:physics/1411.5118. Available online: http://arxiv.org/abs/1411.5118 (accessed on 29 March 2021). [CrossRef]
- Rajaraman, A.; Ullman, J.D.; Leskovec, J. (Eds.) Mining Social-Network Graphs. In Mining of Massive Datasets, 2nd ed.; Cambridge University Press: Cambridge, UK, 2014; pp. 325–383. [Google Scholar] [CrossRef]
- Beekeeper—The Secure Employee App. Beekeeper. Available online: https://www.beekeeper.io/en/home-copy/ (accessed on 1 June 2021).
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Meske, C.; Wilms, K.; Stieglitz, S. Enterprise Social Networks as Digital Infrastructures-Understanding the Utilitarian Value of Social Media at the Workplace. Inf. Syst. Manag. 2019, 36, 350–367. [Google Scholar] [CrossRef]
- Drahošová, M.; Balco, P. The Benefits and Risks of Enterprise Social Networks. In Proceedings of the 2016 International Conference on Intelligent Networking and Collaborative Systems (INCoS), Ostrava, Czech Republic, 7–9 September 2016; pp. 15–19. [Google Scholar] [CrossRef]
- Luo, N.; Guo, X.; Lu, B.; Chen, G. Can non-work-related social media use benefit the company? A study on corporate blogging and affective organizational commitment. Comput. Hum. Behav. 2018, 81, 84–92. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Yang, Z.; Algesheimer, R.; Tessone, C.J. A Comparative Analysis of Community Detection Algorithms on Artificial Networks. Sci. Rep. 2016, 6, 1–18. [Google Scholar] [CrossRef]
- Ding, Z.; Zhang, X.; Sun, D.; Luo, B. Overlapping Community Detection based on Network Decomposition. Sci. Rep. 2016, 6, 24115. [Google Scholar] [CrossRef]
- Rosvall, M.; Delvenne, J.-C.; Schaub, M.T.; Lambiotte, R. Different approaches to community detection. arXiv 2019, arXiv:Physics/1712.06468. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Harush, U.; Barzel, B. Dynamic patterns of information flow in complex networks. Nat. Commun. 2017, 8, 2181. [Google Scholar] [CrossRef]
- Zareie, A.; Sakellariou, R. Similarity-based link prediction in social networks using latent relationships between the users. Sci. Rep. 2020, 10, 20137. [Google Scholar] [CrossRef]
- Menon, A.K.; Elkan, C. Link Prediction via Matrix Factorization. In Machine Learning and Knowledge Discovery in Databases; Gunopulos, D., Hofmann, T., Malerba, D., Vazirgiannis, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6912, pp. 437–452. [Google Scholar] [CrossRef]
- Barabási, A.-L.; Pósfai, M. Network Science; Cambridge University Press: Cambridge, UK, 2016; Available online: http://barabasi.com/networksciencebook/ (accessed on 5 November 2021).
- Broido, A.D.; Clauset, A. Scale-free networks are rare. Nat. Commun. 2017, 10, 1017. [Google Scholar] [CrossRef]
- Algorithms—Neo4j Graph Data Science. Neo4j Graph Database Platform. Available online: https://neo4j.com/docs/graph-data-science/1.7/algorithms/ (accessed on 15 October 2021).
- Panagopoulos, G.; Nikolentzos, G.; Vazirgiannis, M. Transfer Graph Neural Networks for Pandemic Forecasting. arXiv 2021, arXiv:2009.08388. Available online: http://arxiv.org/abs/2009.08388 (accessed on 15 October 2021).
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2020, arXiv:1706.02216. Available online: http://arxiv.org/abs/1706.02216 (accessed on 13 December 2020).
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation Learning on Graphs: Methods and Applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. arXiv 2016, arXiv:1607.00653. Available online: http://arxiv.org/abs/1607.00653 (accessed on 15 April 2021).
- Fast Random Projection—Neo4j Graph Data Science. Neo4j Graph Database Platform. Available online: https://neo4j.com/docs/graph-data-science/1.7/algorithms/fastrp/ (accessed on 15 October 2021).
- Li, M.; Wang, X.; Gao, K.; Zhang, S. A Survey on Information Diffusion in Online Social Networks: Models and Methods. Information 2017, 8, 118. [Google Scholar] [CrossRef]
- Graph Classification—StellarGraph 1.2.1 Documentation. Available online: https://stellargraph.readthedocs.io/en/stable/demos/graph-classification/ (accessed on 15 October 2021).
- Österle, H.; Becker, J.; Frank, U.; Hess, T.; Karagiannis, D.; Krcmar, H.; Loos, P.; Mertens, P.; Oberweis, A.; Sinz, E.J. Memorandum Zur Gestaltungsorientierten Wirtschaftsinformatik. Available online: http://www.alexandria.unisg.ch/Publikationen/71074 (accessed on 5 May 2021). (In German) [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; O’Reilly Media, Inc.: Newton, MA, USA, 2019; Available online: https://www.oreilly.com/library/view/hands-on-machine-learning/9781492032632/ (accessed on 5 December 2021).
- Escobar-Viera, C.G.; Shensa, A.; Bowman, N.D.; Sidani, J.E.; Knight, J.; James, A.E.; Primack, B.A. Passive and Active Social Media Use and Depressive Symptoms Among United States Adults. Cyberpsychol. Behav. Soc. Netw. 2018, 21, 437–443. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Becchetti, L.; Boldi, P.; Castillo, C.; Gionis, A. Efficient semi-streaming algorithms for local triangle counting in massive graphs. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; Association for Computing Machinery: New York, NY, USA; pp. 16–24. [CrossRef]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Chen, H.; Sultan, S.F.; Tian, Y.; Chen, M.; Skiena, S. Fast and Accurate Network Embeddings via Very Sparse Random Projection. arXiv 2019, arXiv:1908.11512. Available online: http://arxiv.org/abs/1908.11512 (accessed on 21 October 2021).
- Link Prediction—Neo4j Graph Data Science. Available online: https://neo4j.com/docs/graph-data-science/1.7/algorithms/ml-models/linkprediction/ (accessed on 5 November 2021).
- Link Prediction—NetworkX 2.6.2 Documentation. Available online: https://networkx.org/documentation/stable/reference/algorithms/link_prediction.html (accessed on 16 November 2021).
- Barabasi, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Zhou, T.; Lu, L.; Zhang, Y.-C. Predicting Missing Links via Local Information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Description | Data Type |
|---|---|---|
| _inserted_at | The time of insert into the database | Datetime |
| id | Anonymized ID of the interaction | String |
| occurred_at | The time of user interaction happened | Datetime |
| user_id | Anonymized ID of the user | String |
| is_bot | True or False whether the interaction was performed by a bot | Boolean |
| client | Client of user device | String |
| client_version | Client version of user device | String |
| path | API endpoint of interaction | String |
| normalized_path | Normalized API endpoint | String |
| method response_status | HTTP Response Status Code | String |
| turnaround_time | Turnaround time | String |
| Variable Name | Description | Data Type |
|---|---|---|
| occured_at | The time the user interaction happened | Datetime |
| user_id | Anonymized ID of the user | Integer |
| client | Client of user device | Integer |
| path | API endpoint of interaction | String |
| normalized_path | Normalized API endpoint | String |
| Node Type | Property | CSV Column | Data Type |
|---|---|---|---|
| Post | post_id | posts | Integer |
| User | user_id | user_id | Integer |
| Group | group_id | groups | Integer |
| Comment | comment_id | comments | Integer |
| Stream | stream_id | streams | Integer |
| User_Id | Client | Client_Version | Path | Normalized Path | Method | |
|---|---|---|---|---|---|---|
| unique | 4008 | 5 | 45 | 138835 | 150 | 6 |
| top | - | app-ios | 4.23.6b49 | /status | /{streamid}/posts | GET |
| freq | 104637 | 8664127 | 8551708 | 1607679 | 2770088 | 12943606 |
| Parameter Name | Parameter Value |
|---|---|
| propertyDimension | 45 |
| embeddingDimension | 250 |
| featureProperties | [“communityId”, “triangles”, ‘degree’], |
| relationshipTypes | [“KNOWS_REMAINING”] |
| iterationWeights | [0, 0, 1.0, 1.0] |
| normalizationStrength | 0.05 |
| mutateProperty | ‘fastRP_Embedding_Extended’ |
| Parameter Name | Parameter Value |
|---|---|
| trainRelationshipType | ‘KNOWS_TRAINGRAPH’ |
| testRelationshipType | ‘KNOWS_TESTGRAPH’, |
| modelName | ‘FastRP-embedding |
| featureProperties | [fastRP_Embedding_Extended], |
| validationFolds | 5 |
| negativeClassWeight | 1.0 |
| randomSeed | 2 |
| concurrency | 1 |
| params | [{penalty: 0.5, maxEpochs: 1000}, {penalty: 1.0, maxEpochs: 1000}, penalty: 0.0, maxEpochs: 1000}] |
| Model Name | Parameter Value | |||
|---|---|---|---|---|
| Winning Model | TrainGraphScore | TestGraphScore | ||
| Max Epochs | Penalty | |||
| myModel | 1000 | 0.5 | 0.352 | 0.344 |
| Feature Name | Adamic_Score | Jaccard_Score | Resource_All_Score | Pref_Att_Score |
|---|---|---|---|---|
| adamic_score | 1.000000 | 0.369536 | 0.934130 | 0.661546 |
| jaccard_score | 0.369536 | 1.000000 | 0.138377 | 0.011785 |
| resource_all_score | 0.934130 | 0.138377 | 1.000000 | 0.741458 |
| pref_att_score | 0.661546 | 0.011785 | 0.741458 | 1.000000 |
| Parameter Name | Validation Dataset | Test Dataset | ||
|---|---|---|---|---|
| Max_Depth | N_Estimator | Max_Depth | N_Estimator | |
| Grid best parameter (max. accuracy) | 10 | 50 | 5 | 10 |
| Grid best parameter (max. AUC) | 10 | 100 | 5 | 50 |
| Score Name | ||||
| Grid best score (accuracy) | 0.516 | 0.516 | ||
| Grid best score (AUC) | 0.511 | 0.512 | ||
| Sample size | 7210 | 7556 | ||
| Parameter Name | Validation Dataset | Test Dataset |
|---|---|---|
| Accuracy | 0.516 | 0.490 |
| Precision | 0.510 | 0.494 |
| Recall | 0.876 | 0.858 |
| Model Name | AUC (Average Precision) | Training Time | Model Features | Model Performance on Small Datasets |
|---|---|---|---|---|
| Artifact 2 with Fast RP (Trained Graph) | 0.352 (Table 8) [n.a.] | 758 ms | 3–features per node | N/A |
| Artifact 3 with Random Forest Classifier (Validation Data) | 0.511 (Table 10) [0.50] (Figure 9) | 13 084 ms | 4–features pairwise | Higher AP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Korányi, R.; Mancera, J.A.; Kaufmann, M. GDPR-Compliant Social Network Link Prediction in a Graph DBMS: The Case of Know-How Development at Beekeeper. Knowledge 2022, 2, 286-309. https://doi.org/10.3390/knowledge2020017
Korányi R, Mancera JA, Kaufmann M. GDPR-Compliant Social Network Link Prediction in a Graph DBMS: The Case of Know-How Development at Beekeeper. Knowledge. 2022; 2(2):286-309. https://doi.org/10.3390/knowledge2020017
Chicago/Turabian StyleKorányi, Rita, José A. Mancera, and Michael Kaufmann. 2022. "GDPR-Compliant Social Network Link Prediction in a Graph DBMS: The Case of Know-How Development at Beekeeper" Knowledge 2, no. 2: 286-309. https://doi.org/10.3390/knowledge2020017
APA StyleKorányi, R., Mancera, J. A., & Kaufmann, M. (2022). GDPR-Compliant Social Network Link Prediction in a Graph DBMS: The Case of Know-How Development at Beekeeper. Knowledge, 2(2), 286-309. https://doi.org/10.3390/knowledge2020017