3.1. Classification Techniques and Performance Metrics
Several experiments have been conducted in [
1] in order to compare supervised classification techniques (decisions trees, artificial neural systems, regressions, etc.) in terms of their overall and partial discrimination efficiencies in various implementations and schemes. One of the most balanced discrimination rates emerged from the employment of artificial neural training for the development of the supervised classifier. Consequently, in the current work, artificial neural systems (ANS) are solely utilized for supervised classification purposes. Several topologies were tested in order to achieve efficient training performance leading to network implementations of two sigmoid hidden layers and an output linear layer, while an approximate number of 20 nodes are engaged in the hidden layers. Furthermore, the k-fold validation method is utilized, dividing the initial audio samples set into k-subsets and thereafter using the (k − 1) subsets for training requirements and the remaining subset for validation purposes; the whole procedure is iteratively repeated k times. The k-fold validation technique is employed for the performance evaluation of the ANS classifiers and, moreover, favors the formulation of generalization classification rules. For the current experiments, we selected k = 10, ensuring that for each of the 10 iterations, 90% of the audio frames’ feature values are engaged in the model training process and 10% for validation purposes.
The performance rates for each parameters’ combination (window length, k-fold iteration, etc.) are based on the extracted confusion matrix of the respective model. Specifically, the confusion matrix represents an array of values of the correctly classified instances and the misclassified ones.
Table 3 presents an example of the output confusion matrix for the temporal length 125 ms for the taxonomy voice (V), phone (P) and residual (R) according to VPR scheme. As shown, the correctly classified samples are on the main diagonal of the array, while above and below are the erroneously classified samples.
The overall pattern recognition performance PS of the ANS for each of the implemented schemes is evaluated by the % ratio of the number of the correctly classified samples Ncor to the total number of the input samples N. In the same way, the partial discrimination rate PSci of a class Ci is defined as the % ratio of the correctly classified samples Ncci in the class Ci to the total number of samples Nci that Ci class includes. The above definitions are described in Equations (1) and (2).
Applying Equations (1) and (2) in our example of
Table 3, the numbers of correctly classified samples in each class are N
CCV = 2255 (for class V), N
CCP = 755 (for class P) and N
CCR = 1545 (for class R), while the total number of correctly classified instances in the model is Ncor = 2255 + 755 + 1545 = 4555. Furthermore, as
Table 1 exhibits, the input dataset had N = 4800 samples in total, and for each class, we have N
V = 2400, N
P = 800 and N
R = 1600. Consequently, the partial recognition rates for each class are:
On the other hand, the clustering process in the current work is being implemented through the k-means classification algorithm that aims to detect the formulation of group of data/feature values, according to a similarity metric. The criteria that defines the integration of a sample into a cluster, usually refers to a distance metric such as Euclidean, Manhattan, Chebyshev or min–max distance from the cluster center/average. The experiments that are carried out in the present work utilize both Euclidean and Manhattan distance in the k-means implementation for additional comparison purposes.
Since the clustering process only detects data groups, the classification performances cannot be directly evaluated with Equations (1) and (2). One of the main objectives of the current work is to investigate the feasibility of the automatic unsupervised classification in audio data through clustering methods and compare the results with the respective ones by supervised ANS. In this way, we can compare the data clusters formulations of k-means with the corresponding classes in ANS in order solely to evaluate the clusters.
Table 4 presents the example of the output cluster formulation of the k-means algorithm for the same window length of 125 ms.
The partial discrimination performance
PUGi of cluster
Gi is defined as the % ratio of the number of samples of class
Ci that have been classified to cluster
Gi to the total number of samples of class
Ci. The above metric is essentially a % measurement of resemblance of cluster class. In addition, the overall discrimination performance of clustering
PU is evaluated as the % ratio of the sum of the numbers of samples of each class
Ci that have been correctly grouped in cluster
Gi to the total number of input samples
N. The above metrics are described in Equations (3) and (4). The classification results of the employed supervised/unsupervised techniques in the next section are evaluated based on Equations (1)–(4).
Applying Equations (3) and (4) in our example of
Table 4, the number of clusters is nclusters = 3 and the distribution of class samples in the respective clusters is
(for class V in Group1),
(for class P in Group 2) and
(for class R in Group 3). Again, as
Table 1 exhibits, the input dataset had
N = 4800 samples in total and for each class, we have
NV = 2400,
NP = 800 and
NR = 1600. Consequently, the partial recognition rates for each class are:
3.2. Performance Results on Combined Taxonomies
The supervised ANS models and the clustering k-means algorithm are implemented independently in the first classification layer of the VPR scheme. Furthermore, the data mining techniques are optionally combined in the subsequent layers, in order to evaluate either a strict supervised or unsupervised character of classification or a hybrid one, while moving down in the classification schemes/layers.
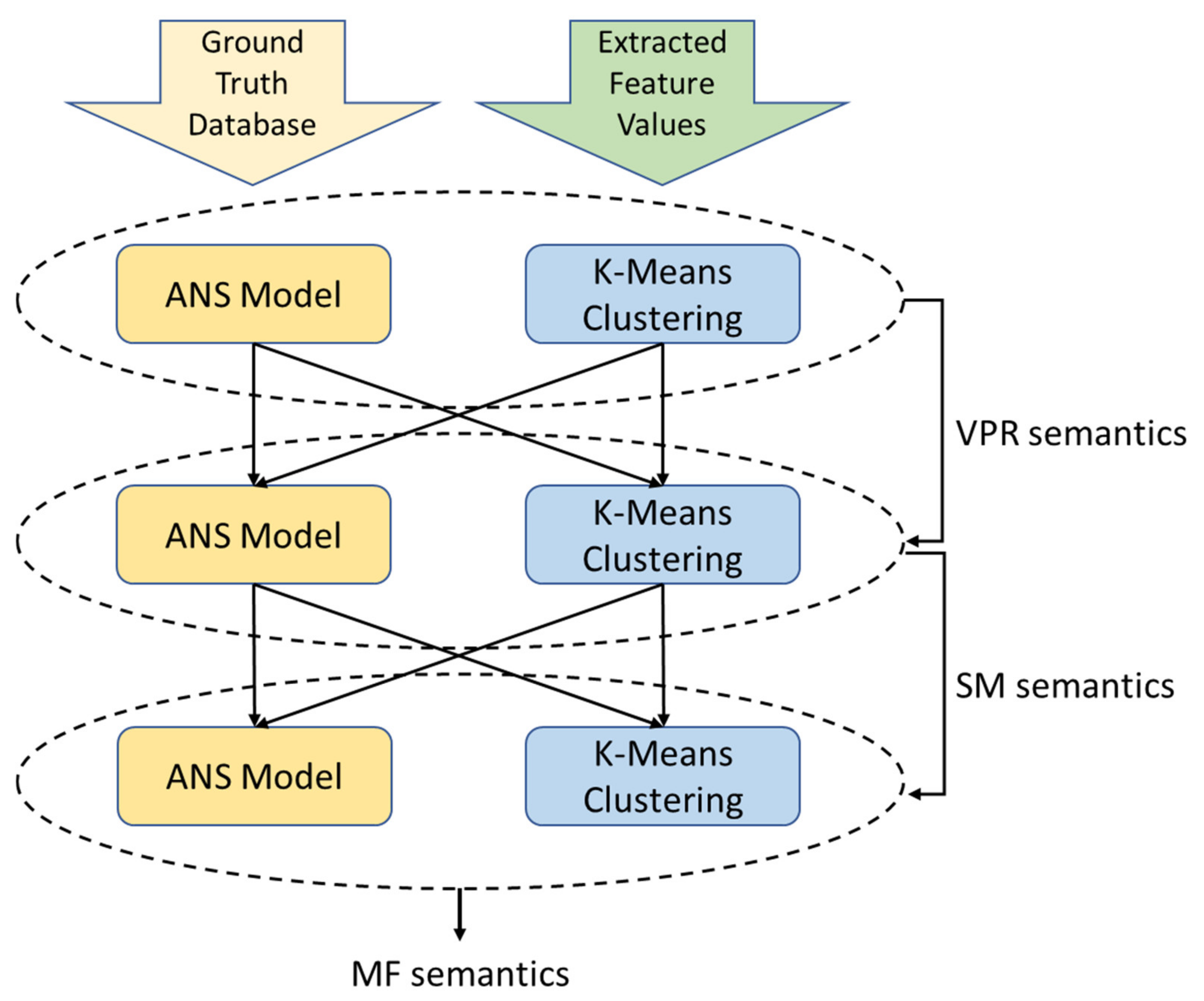
Figure 4 exhibits the combinations of classification methods. It must be noted that the clustering “path” leads to a more automated whole semantic analysis process compared to the prerequisites of ground truth databases that ANS classifiers demand.
In order to follow the successive implementations of ANS and k-means algorithms, each path in
Figure 4 is represented with the initials S (for supervised classification) and U (for clustering) for the three layers, namely, the X-X-X notation where X = S or X = U. For example, the notation S-S-U stands for the combined classification with ANS modeling in VPR and SM schemes and k-means clustering in the MF scheme.
Table 5 presents the performance rates of ANS and k-means for the first VPR classification scheme for several temporal segmentation windows. The overall and partial discrimination rates for supervised classification are quite high for all of the V, P and R classes, reaching even values of 100%. A useful remark derives from the slight decline in performances dependent on the window duration. The unsupervised k-means algorithm also presents high performance rates, i.e., for 1000 ms windowing, 94.76% for overall discrimination, and 96.67%, 100.00% and 93.08% for the cluster formulation according to the corresponding class V, P and R respectively. The phone signal class reaches the 100% discrimination performance, for both algorithms, confirming the initial assumptions of its more specific temporal and spectral audio properties. Moreover, the implementations with Manhattan distance usually lead to slightly increased performance values, but on the other hand, decreases in temporal windowing considerably deteriorate the clustering process with discrimination values of 71.55% and 63.51% for 250 ms and 125 ms framing windows, respectively. The 1000 ms segmentation window leads to the highest discrimination rates for both supervised/unsupervised techniques, but the impact of temporal differentiations is quite obvious, especially in the clustering process.
In order to proceed to the next classification level/layer, the most efficient results of 1000 ms segmentation windowing are employed from the VPR scheme, which provide 100% voice signal discrimination in ANS and 96.67% clustering in k-means. Thereafter, the classification techniques are employed again for the SM scheme, in order to discriminate a single speaker from multiple speakers in the detected voice signal of the VPR scheme.
Table 6 exhibits the discrimination rates for the SM scheme.
The selection of temporal window also remains crucial for the ANS and k-means implementations for the SM classification scheme. The 1000 ms framing leads to more efficient overall and partial discrimination rates for all of the S-S, S-U, U-S and U-U combinations. Moreover, the Manhattan distance metric for the k-means results in better clustering performances compared to Euclidean distance. Finally, the most useful remark refers to the 100% discrimination and clustering performance in the combined algorithms’ implementation for the multiple speakers class of the voice signal.
Moreover, the U-S and S-S sequences lead to more efficient single speaker discrimination (97.5%), and consequently, the ANS classification is vital in the second layer of the SM scheme. This allows the semantic analysis to proceed in the third hierarchical MF scheme for genre voice classification of the single speaker voice.
Table 7 exhibits the classification rates for the third layer of MF scheme.
As
Table 7 exhibits, the male/female voice is discriminated in high performances for both supervised and unsupervised implementations, with overall discrimination values of about 90%. More thoroughly, the ANS modeling offers slightly better and more balanced classification results (92.50%, 95%, 90%) compared to the k-means clustering rates (90%, 100%, 80%). Furthermore, it is quite useful to note that, in the MF scheme, the ANS implementations yield better overall and partial performances for smaller segmentation windows, while the opposite stands for k-means clustering. Finally, the same observation for the better selection of the Manhattan distance metric also remains for the MF classification scheme.
Summarizing the remarks of the overall semantic analysis for hierarchical classification in the three layers of
Figure 4, it must be noted that several combinations can be sought for pure or hybrid classification techniques in order to reach efficient discrimination results. The integration of clustering methods in supervised implementations promotes automation and functionality in the whole semantic analysis process.
3.3. Validation and Optimization Issues
As mentioned in
Section 2.5, the feature evaluation process is crucial for the overall processing load and time, especially for the supervised classification techniques. Even though the clustering k-means algorithm noted reduced computational load in the previous experiments while exploiting the whole extracted feature set, in this section, a feature evaluation process is conducted especially for the clustering method, while also utilizing the ranking results of
Table 2. The k-means algorithm is employed for the three classification schemes VPR, SM and MF, but different numbers of audio properties are exploited in each implementation, based on the ranking of
Table 2.
Figure 5,
Figure 6 and
Figure 7 present the overall and partial discrimination rates while utilizing differentiated numbers of audio features.
From the above diagrams, the optimum number of features is determined based on the best performance rates.
Table 8 presents the number of features and the corresponding discrimination rates for the k-means clustering in the hierarchical classification schemes of
Figure 2. Comparing the values of
Table 8 with the corresponding performances of
Table 5,
Table 6 and
Table 7, we can observe the positive impact of the diversification of the number of features in clustering, in the context of the whole semantic analysis process performance rates.
Another aspect that must be taken into consideration while employing the pattern recognition analysis refers to the selection of the segmentation window, which has a crucial impact on the discrimination performances. More specifically, in almost all of the current experiments and also previous ones in [
1,
25], the 1000 ms framing length leads to better classification results. One justification may derive from the fact that 1000 ms contains more information data, which is a determinant factor for classification purposes, especially of heterogeneous audio content (i.e., VPR scheme). In order to further investigate and validate the selection of 1000 ms framing length, besides the comparisons in the previous section with various temporal windows (1000 ms, 500 ms, 250 ms, 125 ms) in terms of their corresponding classification results, several experiments are conducted in this section with a sliding 1000 ms segmentation window. In the following analysis, the 1000 ms segmentation begins with 100 ms, 200 ms, 300 ms and 400 ms delays, resulting in successive information loss compared to the initial accurately annotated frames. Moreover, in real conditions, the whole semantic analysis process may suffer from inaccurate annotation tasks, and consequently, the sliding 1000 ms windows may reveal the impact of the selected window, on the grounds of a sensitivity analysis in the classification problem.
Table 9 presents the performance values for supervised and unsupervised classification on the VPR scheme with the sliding effect.
As
Table 9 exhibits, the segmentation delay results are different from the respective ones with no sliding. Nevertheless, the impact of the sliding effect is not so obvious for 100 ms, 200 ms or 300 ms temporal delays, but when referring to 400 ms sliding, the classification performances decrease for both ANS and k-means methods, which indicates a significant information loss. Consequently, the 1000 ms framing selection appears to be an efficient segmentation window, which also allows real condition annotation fault margins. Furthermore, in the same table, the discrimination results for k-means with 32 feature implementations are exhibited, which are more increased with the corresponding implementations with the whole feature set. This remark reinforces the previous conclusions of the feature adaptivity potential in the whole semantic analysis process.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}