1. Introduction
In many experimental or theoretical approaches the effort of acquiring data may be costly, time consuming or both. The goal is to get insights in either the overall or extremal behaviour of a target quantity with respect to a set of parameters. If insights to functional dependencies between target and parameters are only to be obtained from a computationally expensive function, which may be considered as a black box function, it is instructive to employ surrogate modelling: already acquired data serve as a starting basis for establishing a surrogate surface in parameter space which then gets explored by Bayesian optimization [
1]. An overall survey about Bayesian optimization may be found in [
2], though it concentrates on an expected improvement (EI) utility and considers noise in the data only in the last paragraph, again by concentrating on EI. In contrast to this nice study we propose to alternate the different utilities at hand. Moreover, a fast information theory related to Bayesian optimization is shown in [
3], though this approach approximates any black-box function by a parabolic form which differs from our ansatz letting the black-box function untouched. Interesting insights to multi-objective Bayesian optimization are provided by [
4], which considers “multi-objective” in the sense of seeking the extrema–each is free of choice maximum or minimum–of a bunch of single-objective functions. However, the present paper concentrates on finding a common extremum depending on multiple parameters.
For the surrogate modelling we use the Gaussian process method (GP) [
5] whose early stages date back to the middle of last century with very first efforts in geosciences [
6] tackling the problem of surrogate modelling by so-called kriging [
7]. Afterwards, GP has been appreciated much in the fields of neural networks and machine learning [
8,
9,
10,
11,
12] and further work showed the applicability of active data selection via variance based criterions [
13,
14]. Our implementation of the GP method in this paper was already introduced at [
15], and follows in notation–and apart from small amendments—the very instructive book of Rasmussen & Williams [
5].
While in a previous work [
16] we investigated the performance of utility functions for the expected improvement of an additional data point or for a data point with the maximal variance, in this paper we would like to introduce the global variance, i.e., the integral over the variance for a target surrogate within a region of interest with respect to a newly added data point. It is the substantial advantage of the Gaussian process method that such a task may be tackled simply on the basis of already acquired data, i.e., before new data have to be determined.
2. Global Variance for Gaussian Process-Based Model
In the following we concisely report the formulas leading to the results in this paper. For a thorough discussion of Gaussian processes please refer to the above mentioned papers, especially to the book of Rasmussen & Williams [
5].
The problem of predicting function values in a multi-dimensional space supported by given data is a regression problem for a non-trivial function of unknown shape. Given are
n target data
for input data vectors
of dimension
with matrix
=
written as
We assume that target data
are blurred by Gaussian noise with
. Further, we assume that the black box function interconnecting input
and target
is at least uniformly continuous and thereby justifies a description of a target surface with a surrogate from the Gaussian process method. Despite the experimental data and the physics background all quantities throughout this paper are without units.
The decisive quantity of a Gaussian process is the covariance function
k describing the distance between two vectors
and
defined by
with the signal variance
and length scale
. A covariance matrix
considers the covariances of all input data
. The GP method describes a target value
at test input vector
by a normal distribution
with mean
, and variance
, where the term
represents the degree of information in the data. While
is the diagonal matrix of the given variances
, the variance
accounts for an overall noise in the data. Then the full covariance matrix
of the Gaussian Process is
In Bayesian probability theory the three parameters
are considered to be hyper-parameters which show up in the marginal likelihood as
In [
16], we showed, that for a sufficiently large data base the target surrogate is well described by using the expectation values of the hyper-parameters in the formulas for
and
, at least well enough to determine a global optimum in a region of interest (RoI). The global optimum is found by employing utility functions, as there are the expected improvement
and the maximum variance
. For both the respective maximum at
is sought. While the first one (
) evaluates the possible information gain from a new data point, the second utility (
simply estimates the vector in input space with largest variance in the target surrogate.
In order to have a look on the implications of an additional data point in the surrogate, we propose a further utility function, i.e., the global variance defined on the multi-dimensional RoI
by
The exact integration shown in the
Appendix A leads to
Though Equation (
6) represents the correct result, it may turn out in computation runs that the determination of the error-function is substantially time consuming compared to the total expenditure. Therefore, we would like to introduce two alternatives to the exact integration in Equation (
5).
The first one is kind of an approximation. Since outside of the RoI the integrand in Equation (
5) shows only trivial contributions we shift the upper and lower integral bounds to ± infinity and get from the simple Gaussian integrals
We dropped the first term in the integral over
for being infinity, since at least it is a constant contribution regardless of changes in the input
. Although the utility
in Equation (
7) is an approximation only, it has the advantage of being much easier accessible by numerical means and its computation performs much faster compared to Equation (
6).
A second much more sophisticated approach is to insert an enveloping Gaussian function with adjustable location
(guiding center) and variance
in the integral of Equation (
5). Again the integration limits are shifted to ± infinity, however this time the enveloping Gaussian function takes care of the integrability and we get
The two parameters and provide a toolset to guide the search for the next target data evaluations: a smaller standard deviation shifts the attention to the center of the enveloping Gaussian, while gives us the possibility to focus on certain regions in the RoI.
All three utilities employing the global variance,
,
,
require the inversion of the full covariance matrix
of Equation (
3). Since the inversion has to be performed for every newly proposed test input
this is the main time consuming part in the whole procedure. Let us remind the reader, that the method we are proposing fully resides on input space (together with already acquired data) and the bottle neck is the generation of new target data. Therefore, the starting condition of very expensive (aka time consuming) data acquisition still holds. However, we can beneficially use blockwise matrix inversion [
17] since a new input vector
expands the covariance matrix for one additional row and line only. Consequently, we reduced the computational effort to
-behaviour instead of
for standard inversion.
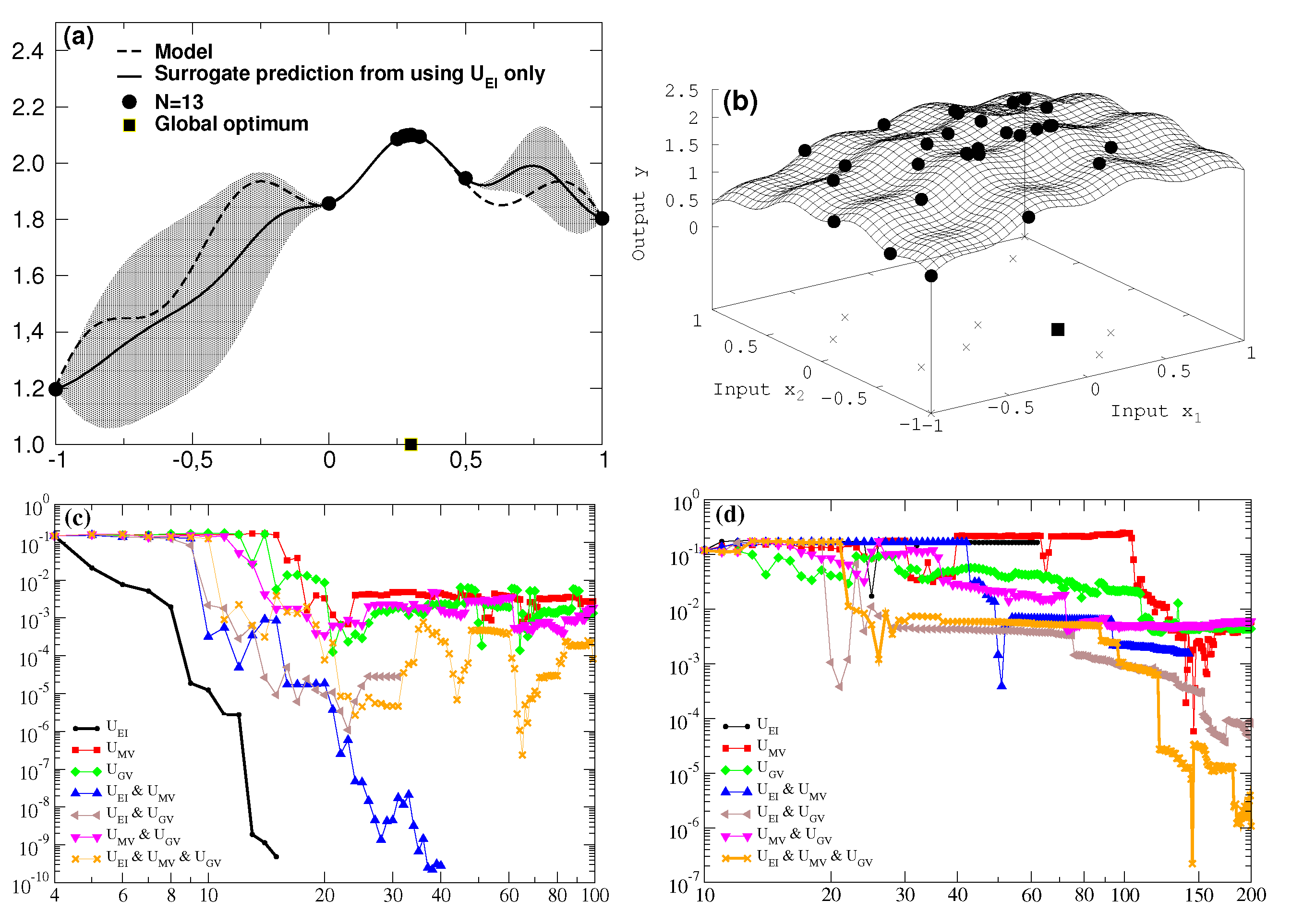
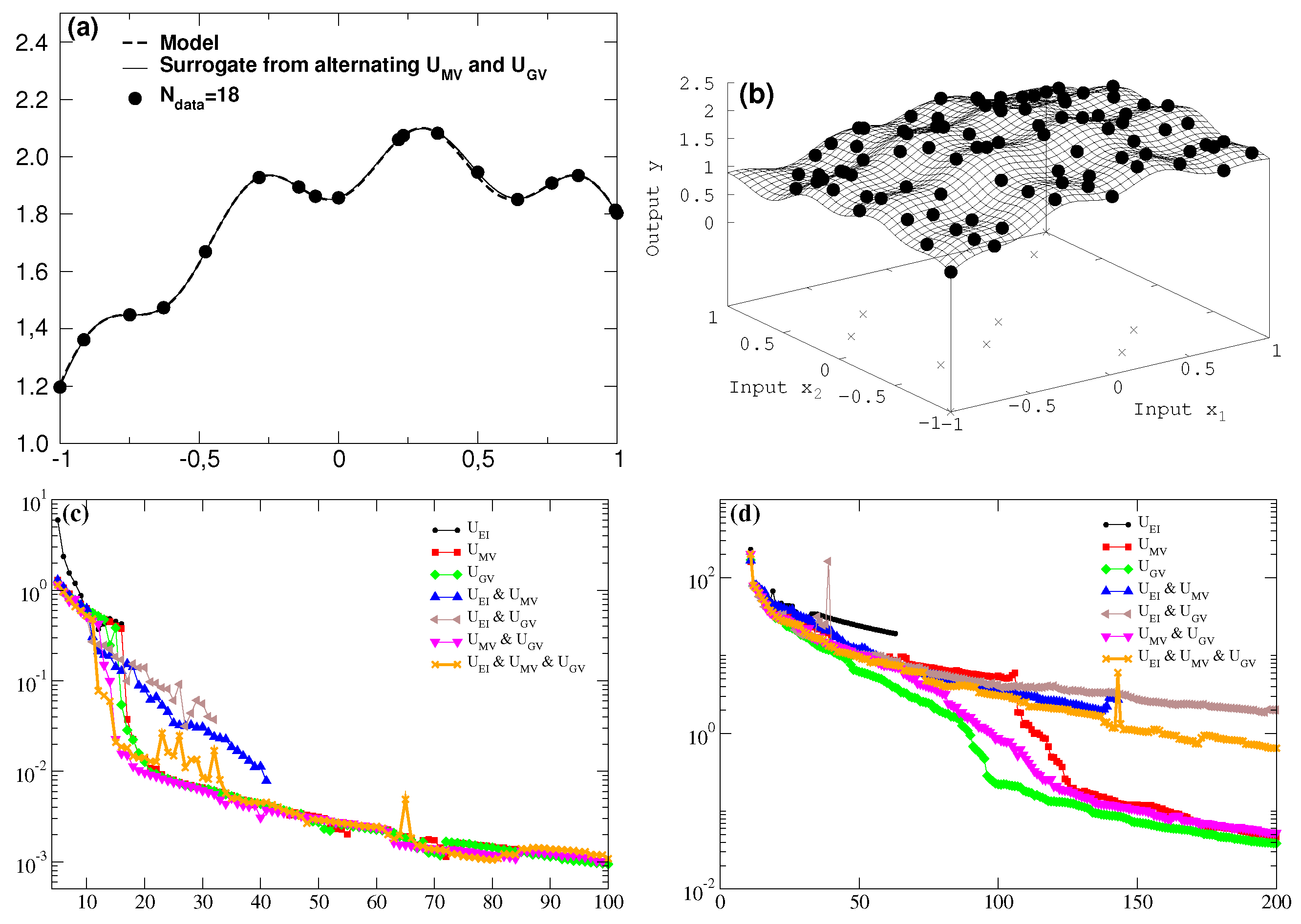
3. Proof of Principle
We follow the global optimization scheme from Section 4 of [
18]. Again we give proof of principle with a “black box” model featuring a broad parabolic maximum
together with a smaller cosine structure
on top of it, while we focus on a decent ripple on
=0.6 in one and two dimensions (
=1, 2).
Figure 1,
Figure 2 and
Figure 3 show in left and right panels the results for one and two dimensions, respectively. The
x axis to the right counts the number of newly acquired data for the utility comparisons in
Figure 3 and in the bottom rows (
c), (
d) of
Figure 1 and
Figure 2.
For every newly added data point proposed by the various utilities, the distance between the true location of the global optimum and the maximal value of the surrogate residing on the data at hand is calculated in
Figure 1. In a similar fashion, the search for the best surrogate description of the hidden model is shown in
Figure 2.
Eventually
Figure 3 demonstrates the use of an enveloping Gaussian function in the integral of the global variance by varying its center
, e.g., if an educated guess about the location of the extremal structure is at hand, i.e., the guiding center
is preset to the positive axis (1d) or the quadrant (2d) with the true model maximum. Consequently,
Table 1 displays for 1d the specific number of data and for 2d the saturation level for which the target surrogate enters the stage of resembling the true model, i.e. the summed up (absolute) differences between all grid points of the target surrogate and the model starts to diminish with the number of target data only.
4. Discussion
The results above show the usage of various utilities as a toolbox for surrogate modeling. Depending on the task—either to find an extremum or to get a best surrogate description of an unknown “black box” model—and depending on the prior knowledge at hand—presumption of location of the sought extremum or concentration on the region of interest—it is advisable to choose the most eligible utility function. However, even more promising is the combination of utilities of different character to profit from their benefits in toto and to compensate for pitfalls and drawbacks of one or the other utility.
As can be seen in the very first example in
Figure 1 for the one-dimensional case the global optimum is found very fast with help of the expected improvement utility
(starting to enter the bump with the correct extremum already below
N = 10). However, a known drawback of this utility is that it gets stuck in local extrema and that it takes an unreasonably high number of additional data to get distracted from this pitfall.
This is taken into account for the two-dimensional case where the best result with lowest difference to the exact result is obtained by acting in combination of all three utilities
,
and
. Focusing the maximum search on the utility regarding expected improvement alone (black line in
Figure 1d would have got stuck in a local extremum with
y = 2.03 in the “wrong” quadrant at (−0.26; −0.29) for not recovering from this at all at about N = 63 (internal stop of algorithm for no improvement after entering computing accuracy level) and totally missing the true optimum with
y = 2.2 at (0.3; −0.3).
The situation changes for the task of getting a best overall description within the region of interest. To accomplish this the newly introduced global variance utility
is of tremendous help both in one and two dimensions—either alone or in combination with at least the maximum variance utility
. As shown in
Figure 2d the best surrogate can already be established around ninety data points by employing
only (full circles in the target surface of
Figure 2b, with very few deviations from the true model left.
A guess about the approximate occurrence of an extremal structure–without excluding another region—can be emphasized by a further refinement to the global variance utility. In letting act an enveloping Gaussian within the global variance integral Equation (
5) the result is not only much easier to be tackled from a computational point of view, but also the focus of the numerical search for the global optimum can be guided by predetermining the center of Gaussian
and its integral weight (aka width
).
Figure 3 shows the results for three different integral weights (0.6; 0.8; 0.9) of the enveloping Gaussian function at two guiding centers: the first one at the origin corresponds to an ignorant scenario where one is not sure about a certain position of some global optimum at all. In the second approach we suppose that the extremal structure may be found in one dimension for positive values and thereby set
, while in two dimensions it may be located within the quadrant with positive values for
and negative ones for
resulting in
. As can be seen already in
Figure 3, but all the more learned from the numbers of
Table 1, displacing the center of the enveloping Gaussian function to the real center of the optimum of the hidden model facilitates the development of a best—regarding similarity to the true model—surrogate surface.







{kind=link}
{kind=link}
{kind=link}