
Avatar Detection in Metaverse Recordings



Abstract
1. Introduction
2. Current State of the Art
2.1. Definitions and Characterizations of Avatars in Literature
2.2. Object Detection
2.3. Summary
3. Modeling
3.1. Avatar Classification
| Listing 1. Information Model Formal Language Specification of Avatars. |
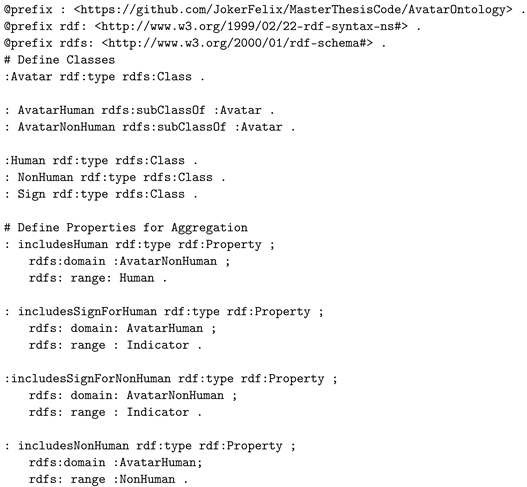 |
3.2. Avatar Detector Model
4. Implementation
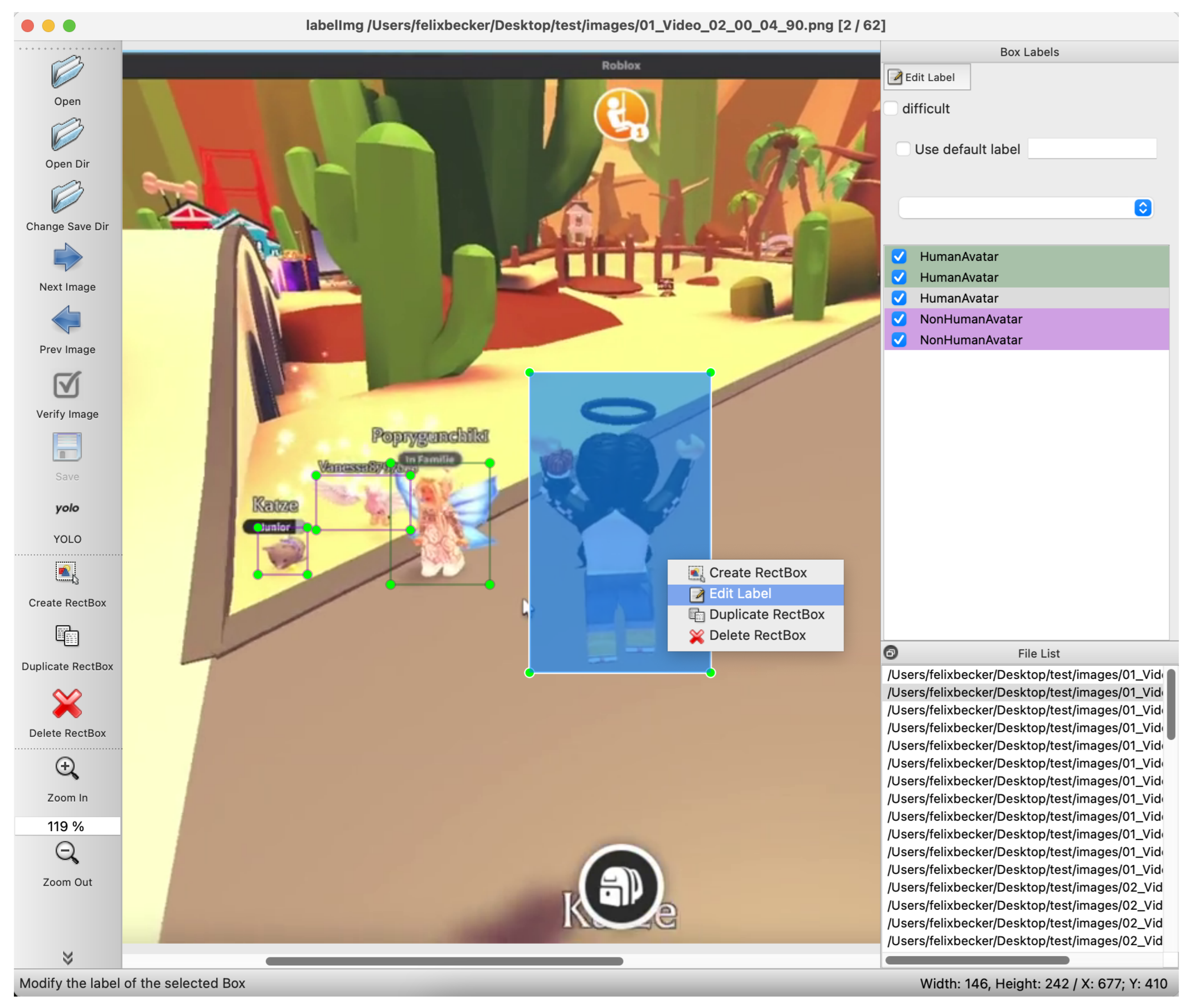
4.1. ADET Dataset
4.2. Avatar Detector
5. Evaluation
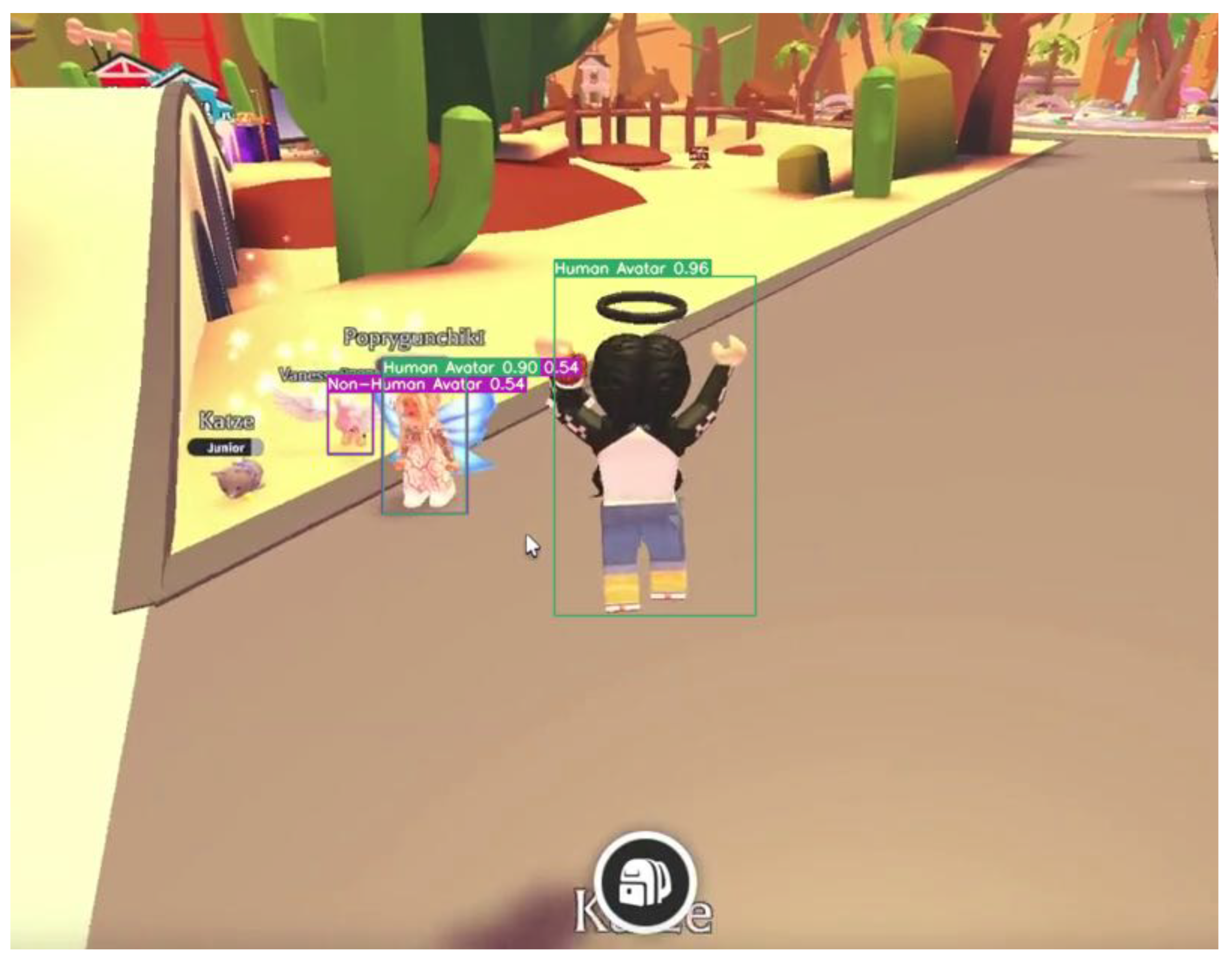
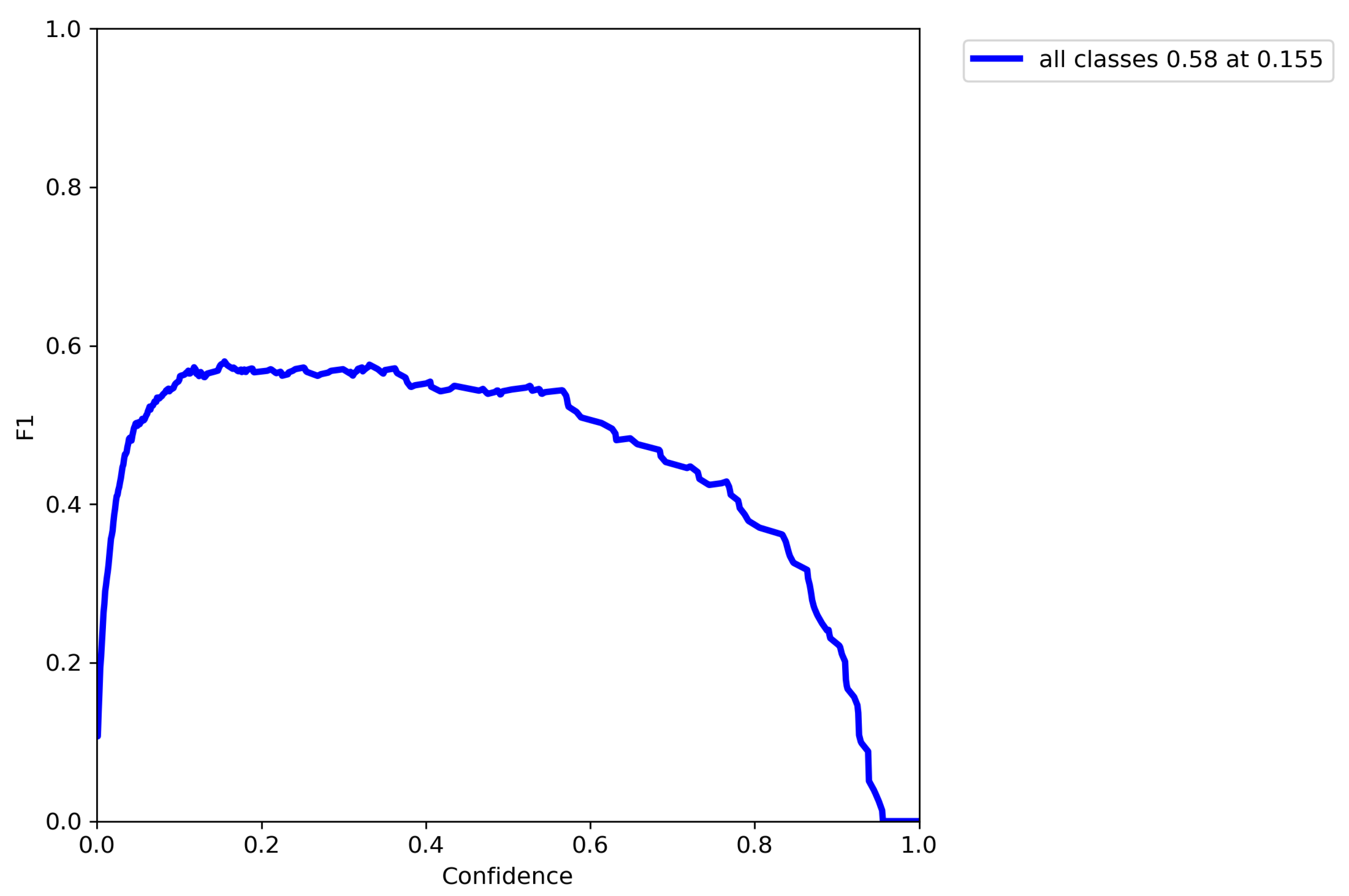
5.1. Evaluation of the Avatar Detection
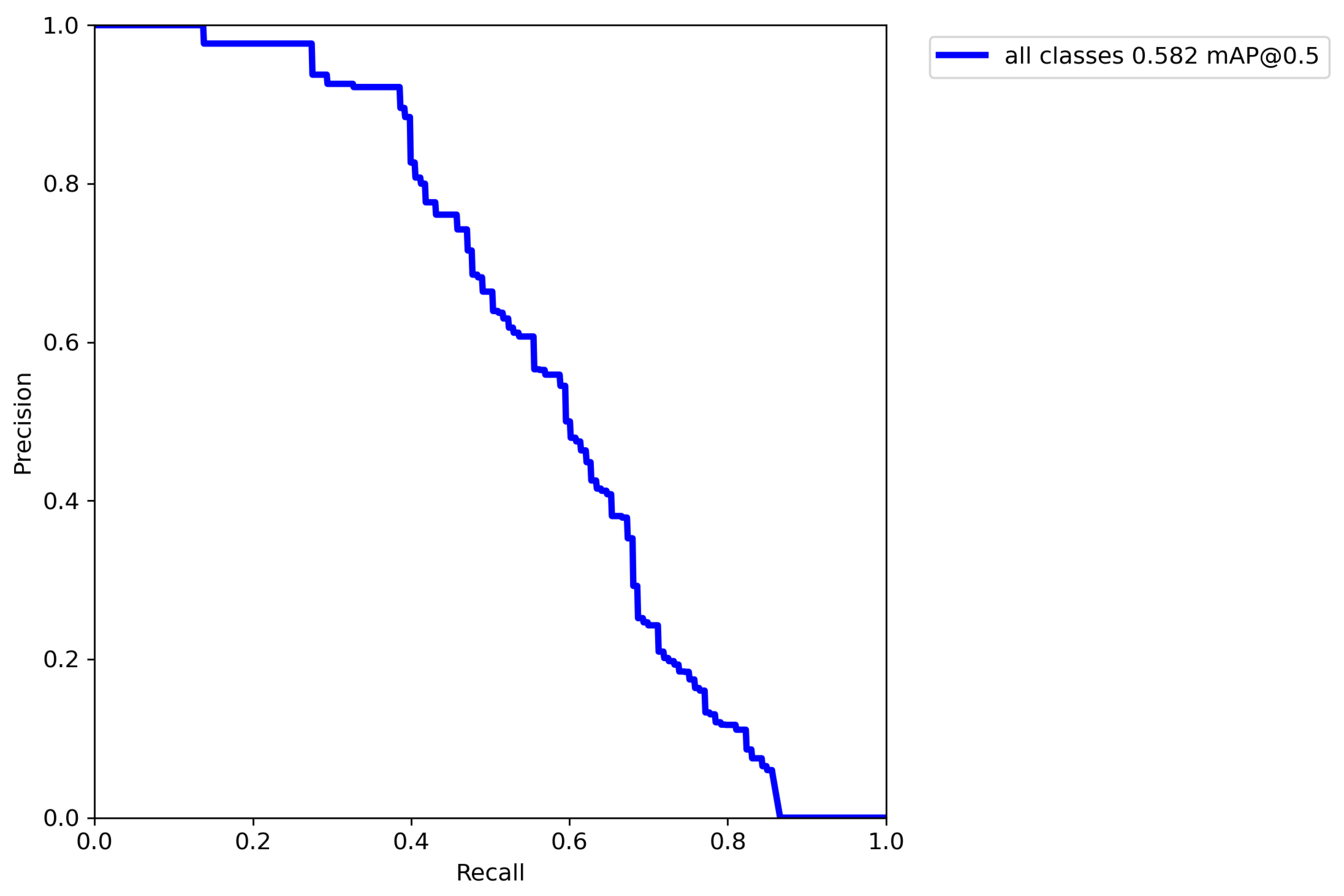
5.1.1. Baseline
5.1.2. Avatar Detector
5.2. Ablation Study: Evaluating the Avatar Indicator
6. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gartner Inc. Gartner Predicts 25% of People Will Spend at Least One Hour per Day in the Metaverse by 2026; Gartner Inc.: Stamford, CT, USA, 2022. [Google Scholar]
- Mystakidis, S. Metaverse. Encyclopedia 2022, 2, 486–497. [Google Scholar] [CrossRef]
- Ritterbusch, G.D.; Teichmann, M.R. Defining the Metaverse: A Systematic Literature Review. IEEE Access 2023, 11, 12368–12377. [Google Scholar] [CrossRef]
- KZero Worldwide. Exploring the Q1 24’ Metaverse Radar Chart: Key Findings Unveiled; KZero Worldswide: Dubai, United Arab Emirates, 2024. [Google Scholar]
- Karl, K.A.; Peluchette, J.V.; Aghakhani, N. Virtual Work Meetings During the COVID-19 Pandemic: The Good, Bad, and Ugly. Small Group Res. 2022, 53, 343–365. [Google Scholar] [CrossRef] [PubMed]
- Meta Platforms, Inc. Meta Connect 2022: Meta Quest Pro, More Social VR and a Look Into the Future; Meta Platforms, Inc.: Menlo Park, CA, USA, 2022. [Google Scholar]
- Takahashi, D. Nvidia CEO Jensen Huang Weighs in on the Metaverse, Blockchain, and Chip Shortage. GamesBeat News, 12 June 2021. [Google Scholar]
- Apple Inc. Apple Vision Pro Available in the U.S. Newsroom, 2 February 2024.
- INTERPOL. Grooming, Radicalization and Cyber-Attacks: INTERPOL Warns of ‘Metacrime’; INTERPOL: Lyon, France, 2024. [Google Scholar]
- Linden Lab. Official Site Second Life; Linden Lab: San Francisco, CA, USA, 2024. [Google Scholar]
- Decentraland. Official Website: What Is Decentraland? 2020. Available online: https://decentraland.org (accessed on 9 June 2023).
- Corporation, R. Roblox: About Us. 2023. Available online: https://www.roblox.com/info/about-us?locale=en_us (accessed on 3 November 2023).
- Games, E. FAQ, Q: What Is Fortnite? 2023. Available online: https://www.fortnite.com/faq (accessed on 6 November 2023).
- Meta Platforms, Inc. Horizon Worlds | Virtual Reality Worlds and Communities; Meta Platforms, Inc.: Menlo Park, CA, USA, 2023. [Google Scholar]
- Wikipedia. Virtual World. 2023. Page Version ID: 1141563133. Available online: https://en.wikipedia.org/wiki/Virtual_world (accessed on 8 March 2023).
- Lochtefeld, J.G. The Illustrated Encyclopedia of Hinduism; The Rosen Publishing Group, Inc.: New York, NY, USA, 2002. [Google Scholar]
- Bartle, R. Designing Virtual Worlds; New Riders Games: Indianapolis, IN, USA, 2003. [Google Scholar]
- Steinert, P.; Wagenpfeil, S.; Frommholz, I.; Hemmje, M.L. Towards the Integration of Metaverse and Multimedia Information Retrieval. In Proceedings of the 2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Milano, Italy, 25–27 October 2023; pp. 581–586. [Google Scholar] [CrossRef]
- Ksibi, A.; Alluhaidan, A.S.D.; Salhi, A.; El-Rahman, S.A. Overview of Lifelogging: Current Challenges and Advances. IEEE Access 2021, 9, 62630–62641. [Google Scholar] [CrossRef]
- Bestie Let’s Play. Wir Verbringen Einen Herbsttag mit der Großfamilie!!/Roblox Bloxburg Family Roleplay Deutsch. 2022. Available online: https://www.youtube.com/watch?v=sslXNBKeqf0 (accessed on 28 February 2023).
- Uhl, J.C.; Nguyen, Q.; Hill, Y.; Murtinger, M.; Tscheligi, M. xHits: An Automatic Team Performance Metric for VR Police Training. In Proceedings of the 2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Milano, Italy, 25–27 October 2023; pp. 178–183. [Google Scholar] [CrossRef]
- Koren, M.; Nassar, A.; Kochenderfer, M.J. Finding Failures in High-Fidelity Simulation using Adaptive Stress Testing and the Backward Algorithm. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 5944–5949. [Google Scholar] [CrossRef]
- Li, X.; Yalcin, B.C.; Christidi-Loumpasefski, O.O.; Martinez Luna, C.; Hubert Delisle, M.; Rodriguez, G.; Zheng, J.; Olivares Mendez, M.A. Exploring NVIDIA Omniverse for Future Space Resources Missions. In Proceedings of the Space Resources Week 2022, Luxembourg, 3–5 May 2022. [Google Scholar]
- NVIDIA Corp. NVIDIA DRIVE Sim; NVIDIA Corp.: Santa Clara, CA, USA, 2024. [Google Scholar]
- Rüger, S.; Marchionini, G. Multimedia Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2010; OCLC: 1333805791. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Steinert, P.; Wagenpfeil, S.; Frommholz, I.; Hemmje, M.L. Integration of Metaverse Recordings in Multimedia Information Retrieval. In Proceedings of the ICSCA 2024, Bali Island, Indonesia, 1–3 February 2024; pp. 137–145. [Google Scholar] [CrossRef]
- TSB Gaming Ltd. The Sandbox Game—Own the Future. Play, Create, Earn; TSB Gaming Ltd.: St. Julians, Malta, 2024. [Google Scholar]
- Abdari, A.; Falcon, A.; Serra, G. Metaverse Retrieval: Finding the Best Metaverse Environment via Language. In Proceedings of the 1st International Workshop on Deep Multimodal Learning for Information Retrieval, Ottawa, ON, Canada, 2 November 2023; pp. 1–9. [Google Scholar] [CrossRef]
- Steinert, P. 256-MetaverseRecordings-Dataset Repository. 2024. Original-Date: 2024-01-12T07:26:01Z. Available online: https://github.com/marquies/256-MetaverseRecordings-Dataset (accessed on 20 January 2024).
- Nunamaker, J.; Chen, M. Systems development in information systems research. In Proceedings of the Twenty-Third Annual Hawaii International Conference on System Sciences, Kailua-Kona, HI, USA, 2–5 January 1990; Volume 3, pp. 631–640. [Google Scholar] [CrossRef]
- Anderson, J.; Rainie, L. The metaverse in 2040 Pew Research Center, Washington, DC USA. 2022. Available online: https://www.pewresearch.org/internet/2022/06/30/the-metaverse-in-2040/ (accessed on 20 January 2024).
- Kim, D.Y.; Lee, H.K.; Chung, K. Avatar-mediated experience in the metaverse: The impact of avatar realism on user-avatar relationship. J. Retail. Consum. Serv. 2023, 73, 103382. [Google Scholar] [CrossRef]
- Triberti, S.; Durosini, I.; Aschieri, F.; Villani, D.; Riva, G. Changing Avatars, Changing Selves? The Influence of Social and Contextual Expectations on Digital Rendition of Identity. Cyberpsychol. Behav. Soc. Netw. 2017, 20, 501–507. [Google Scholar] [CrossRef] [PubMed]
- Fong, K.; Mar, R.A. What Does My Avatar Say About Me? Inferring Personality from Avatars. Personal. Soc. Psychol. Bull. 2015, 41, 237–249. [Google Scholar] [CrossRef] [PubMed]
- Franceschi, K.; Lee, R.; Zanakis, S.; Hinds, D. Engaging Group E-Learning in Virtual Worlds. J. Manag. Inf. Syst. 2009, 26, 73–100. [Google Scholar] [CrossRef]
- Ante, L.; Fiedler, I.; Steinmetz, F. Avatars: Shaping Digital Identity in the Metaverse. 2023. Available online: https://www.blockchainresearchlab.org/wp-content/uploads/2020/05/Avatars-Shaping-Digital-Identity-in-the-Metaverse-Report-March-2023-Blockchain-Research-Lab.pdf (accessed on 17 July 2023).
- Miao, F.; Kozlenkova, I.V.; Wang, H.; Xie, T.; Palmatier, R.W. An Emerging Theory of Avatar Marketing. J. Mark. 2022, 86, 67–90. [Google Scholar] [CrossRef]
- Mourtzis, D.; Panopoulos, N.; Angelopoulos, J.; Wang, B.; Wang, L. Human centric platforms for personalized value creation in metaverse. J. Manuf. Syst. 2022, 65, 653–659. [Google Scholar] [CrossRef]
- Steinert, P.; Wagenpfeil, S.; Hemmje, M.L. 256-MetaverseRecords Dataset. 2023. Available online: https://www.patricksteinert.de/256-metaverse-records-dataset/ (accessed on 3 January 2024).
- Steinert, P.; Wagenpfeil, S.; Frommholz, I.; Hemmje, M. 256 Metaverse Recording Dataset. In Proceedings of the ACM Multimedia 2024, Melbourne, Australia, 28 October–1 November 2024. [Google Scholar]
- Linden Research, Inc. SecondLife. 2023. Available online: https://secondlife.com (accessed on 3 November 2023).
- Naphade, M.; Smith, J.; Tesic, J.; Chang, S.F.; Hsu, W.; Kennedy, L.; Hauptmann, A.; Curtis, J. Large-scale concept ontology for multimedia. IEEE MultiMed. 2006, 13, 86–91. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar] [CrossRef]
- Rauch, L.; Huseljic, D.; Sick, B. Enhancing Active Learning with Weak Supervision and Transfer Learning by Leveraging Information and Knowledge Sources. In Proceedings of the Workshop on Interactive Adaptive Learning co-located with European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Grenoble, France, 23 September 2022; pp. 27–42. [Google Scholar]
- Ratner, A.J.; De Sa, C.M.; Wu, S.; Selsam, D.; Ré, C. Data Programming: Creating Large Training Sets, Quickly. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Ukhwah, E.N.; Yuniarno, E.M.; Suprapto, Y.K. Asphalt Pavement Pothole Detection using Deep learning method based on YOLO Neural Network. In Proceedings of the 2019 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2019; pp. 35–40. [Google Scholar] [CrossRef]
- Dharneeshkar, J.; Soban Dhakshana, V.; Aniruthan, S.A.; Karthika, R.; Parameswaran, L. Deep Learning based Detection of potholes in Indian roads using YOLO. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 381–385. [Google Scholar] [CrossRef]
- Rumpe, B. Modeling with UML; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- W3C. RDF Model and Syntax; W3C: Cambridge, MA, USA, 1997. [Google Scholar]
- Wikipedia. Notation3. 2024. Page Version ID: 1221181897. Available online: https://en.wikipedia.org/wiki/Notation3 (accessed on 8 June 2024).
- FFmpeg Project. FFmpeg. 2024. Available online: https://www.ffmpeg.org/ (accessed on 10 October 2023).
- Lin, T.T. labelImg PyPI. 2021. Available online: https://pypi.org/project/labelImg/ (accessed on 21 January 2024).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. WongKinYiu/yolov7. 2022. Available online: https://github.com/WongKinYiu/yolov7 (accessed on 22 January 2024).
- Becker, F. JokerFelix/MasterThesisCode. 2023. Available online: https://github.com/JokerFelix/MasterThesisCode (accessed on 21 January 2024).
- Becker, F. JokerFelix/Gmaf-Master. 2023. Available online: https://github.com/JokerFelix/gmaf-master (accessed on 21 January 2024).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Wong, K.-Y. yolov7/data/hyp.scratch.p5.yaml at Main · WongKinYiu/yolov7. 2022. Available online: https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p5.yaml (accessed on 21 October 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector | |||
|---|---|---|---|
| Base Algorithm | YOLOv7 | YOLOv7 | YOLOv7 |
| Classes | MS COCO classes, e.g., Person | HumanAvatar, NonHumanAvatar | HumanAvatar, NonHumanAvatar |
| Training Dataset | MS COCO | - with indicators in bounding box annotations | - without indicators in bounding box annotations |
| Configuration | - | p5 | p5 |
| Learning rate | - | 0.001 | 0.001 |
| AP ↑ | mAP@0.5 ↑ | F1@Optimum ↑ | ||
|---|---|---|---|---|
| Class HumanAvatar | 0.905 | |||
| Class NonHumanAvatar | 0.745 | |||
| Both Classes | 0.825 | 0.800 | ||
| Person | 0.582 | 0.580 |
| Model | Train Set | AP Human ↑ | AP Non-Human ↑ | mAP ↑ |
|---|---|---|---|---|
| Indicator | 0.905 | 0.745 | 0.825 | |
| No Indicator | 0.883 | 0.586 | 0.735 | |
| YOLO | COCO | 0.582 * | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Becker, F.; Steinert, P.; Wagenpfeil, S.; Hemmje, M.L. Avatar Detection in Metaverse Recordings. Virtual Worlds 2024, 3, 459-479. https://doi.org/10.3390/virtualworlds3040025
Becker F, Steinert P, Wagenpfeil S, Hemmje ML. Avatar Detection in Metaverse Recordings. Virtual Worlds. 2024; 3(4):459-479. https://doi.org/10.3390/virtualworlds3040025
Chicago/Turabian StyleBecker, Felix, Patrick Steinert, Stefan Wagenpfeil, and Matthias L. Hemmje. 2024. "Avatar Detection in Metaverse Recordings" Virtual Worlds 3, no. 4: 459-479. https://doi.org/10.3390/virtualworlds3040025
APA StyleBecker, F., Steinert, P., Wagenpfeil, S., & Hemmje, M. L. (2024). Avatar Detection in Metaverse Recordings. Virtual Worlds, 3(4), 459-479. https://doi.org/10.3390/virtualworlds3040025