

The Use of Educational Process Mining on Dropout and Graduation Data in the Curricula (Re-)Design of Universities


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Data-Driven Curriculum Design
1.2. Educational Data Mining: Process Mining
1.3. Research Aim: Developing an Educational Process Mining Method
2. Materials and Methods
2.1. Data Background
2.2. Event Logs
2.3. Process Map Design
- Information on the curriculum: field of study, type of degree and curriculum version can be selected to apply the filters to the output.
- Student status: this switch defines the data source dependent on student status, i.e., dropouts or graduates.
- Top-n processes: the number of processes displayed in the maps, from highest frequency to lowest. The animated plots are accompanied by a table, listing the top-n processes per frequency. It is intended as a helper in choosing the optimal settings. The higher the number, the more processes and students are included. The range of the settings is top-1 to top-50 processes.
- Length of processes: the number of exams per process displayed. Every process with a maximum number of exams equal to or lower than the chosen setting will be included. Longer processes for dropouts will not be displayed if the cutoff is set too small. Graduates’ processes are shortened by this variable prior to the calculations. The higher the number, the more processes and students are included. The range of settings is one to ten courses.
- Frequencies: a switch to choose between absolute or relative frequencies.
- Line type: the rendering of the map can be influenced by changing the line type (round or straight). In some process maps changes improve the structuring of the plot.
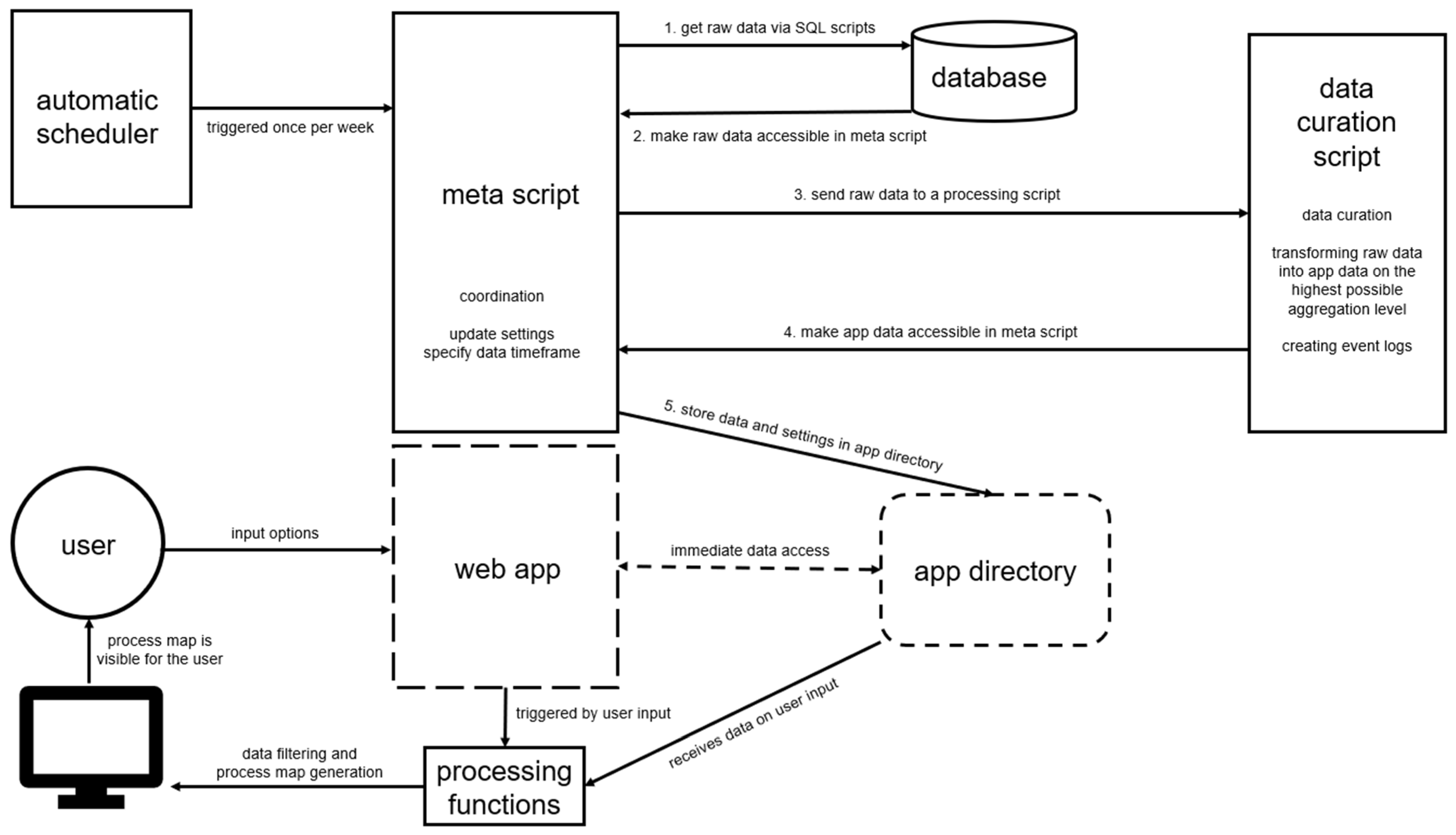
2.4. Apparatus
2.5. Algorithm and Data Model
3. Results
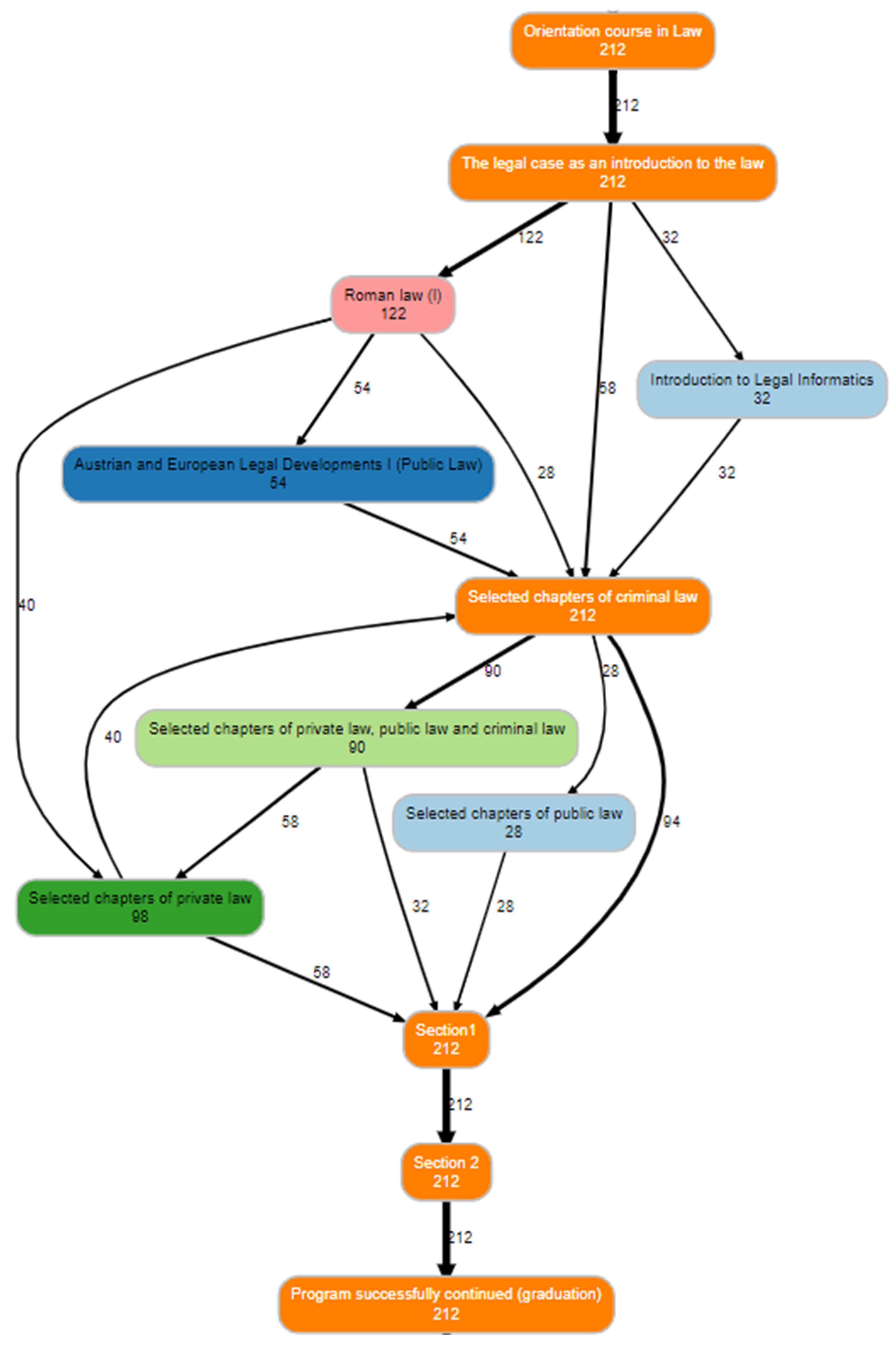
3.1. Standard Settings
3.2. Increased Top-n Processes
3.3. An Increased Number of Courses
4. Discussion
4.1. Usability and Implementation
4.2. Challenges and Limitations
4.3. Future Advancements
5. Conclusions
Supplementary Materials
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- OECD. Education at a Glance 2019. Available online: https://www.oecd-ilibrary.org/education/education-at-a-glance-2019/summary/spanish_f6dc8198-es (accessed on 14 December 2023).
- Marsh, L.M. College dropouts—A review. Pers. Guid. J. 1966, 44, 475–481. [Google Scholar] [CrossRef]
- Federal Ministry of Education, Science and Research, Federal Act on the Capacity Orientated, Student-Centered Financing of Universities (Universities’ Financing Act—UniFinV). 2018. Available online: https://eurydice.eacea.ec.europa.eu/national-education-systems/austria/legislation-and-official-policy-documents (accessed on 14 December 2023).
- Federal Ministry of Education, Science and Research, Federal Act on the Organisation of Universities and their Studies (Universities Act 2002—UG). 2002. Available online: https://eurydice.eacea.ec.europa.eu/national-education-systems/austria/legislation-and-official-policy-documents (accessed on 14 December 2023).
- Alban, M.; Mauricio, D. Predicting university dropout through data mining: A systematic literature. Indian J. Sci. Technol. 2019, 12, 1–12. [Google Scholar] [CrossRef]
- Solomon, D.; Patil, S.; Agrawal, P. Predicting performance and potential difficulties of university student using classification: Survey paper. Int. J. Pure Appl. Math. 2018, 118, 2703–2707. [Google Scholar]
- Márquez-Vera, C.; Cano, A.; Romero, C.; Noaman, A.Y.M.; Mousa Fardoun, H.; Ventura, S. Early dropout prediction using data mining: A case study with high school students. Expert Syst. 2016, 33, 107–124. [Google Scholar] [CrossRef]
- Suhlmann, M.; Sassenberg, K.; Nagengast, B.; Trautwein, U. Belonging mediates effects of student-university fit on well-being, motivation, and dropout intention. Soc. Psychol. 2018, 49, 16–28. [Google Scholar] [CrossRef]
- Zając, T.Z.; Komendant-Brodowska, A. Premeditated, dismissed and disenchanted: Higher education dropouts in Poland. Tert. Educ. Manag. 2019, 25, 1–16. [Google Scholar] [CrossRef]
- Ferguson, R. Learning analytics: Drivers, developments and challenges. Technol. Enhanc. Learn. 2012, 4, 304–317. [Google Scholar] [CrossRef]
- Campbell, J.P.; DeBlois, P.B.; Oblinger, D.G. Academic analytics: A new tool for a new era. Educ. Rev. 2007, 42, 40. [Google Scholar]
- Siemens, G.; Long, P. Penetrating the fog: Analytics in learning and education. Educ. Rev. 2011, 46, 30–32. [Google Scholar]
- Enarson, C.; Cariaga-Lo, L. Influence of curriculum type on student performance in the United States Medical Licensing Examination Step 1 and Step 2 exams: Problem-based learning vs. lecture-based curriculum. Med. Educ. 2001, 35, 1050–1055. [Google Scholar] [CrossRef]
- Mendez, G.; Ochoa, X.; Chiluiza, K.; De Wever, B. Curricular design analysis: A data-driven perspective. J. Learn. Anal. 2014, 1, 84–119. [Google Scholar] [CrossRef]
- dos Santos Garcia, C.; Meincheim, A.; Junior, E.R.F.; Dallagassa, M.R.; Sato, D.M.V.; Carvalho, D.R.; Santos, E.A.P.; Scalabrin, E.E. Process mining techniques and applications–A systematic mapping study. Expert Syst. Appl. 2019, 133, 260–295. [Google Scholar] [CrossRef]
- Ameen, A.O.; Alarape, M.A.; Adewole, K.S. Students’ academic performance and dropout predictions: A review. Malays. J. Comput. 2019, 4, 278–303. [Google Scholar] [CrossRef]
- Moretti, A.; Gonzalez-Brenes, J.; McKnight, K. Data-driven curriculum design: Mining the web to make better teaching decisions. In Proceedings of the 7th International Conference on Educational Data Mining, London, UK, 4–7 July 2014. [Google Scholar]
- Ornstein, A.C.; Hunkins, F.P. Curriculum Foundations, Principles and Issues, 5th ed.; Allyn & Bacon: Boston, MA, USA, 2009. [Google Scholar]
- DaRosa, D.A.; Bell, R.H. Graduate surgical education redesign: Reflections on curriculum theory and practice. Surgery 2004, 136, 974–996. [Google Scholar] [CrossRef] [PubMed]
- Neary, M. Curriculum concepts and research. In Curriculum Studies in Post-Compulsory and Adult Education: A Teacher’s and Student Teacher’s Study Guide; Nelson Thornes Ltd.: Cheltenham, UK, 2003; pp. 33–56. [Google Scholar]
- González, J.; Wagenaar, R.; Beneitone, P. Tuning-América Latina: Un proyecto de las universidades [Tuning-Latin America: A project of the universities]. Rev. Iberoam. Educ. 2004, 35, 151–164. [Google Scholar]
- Pukkila, P.J.; DeCosmo, J.; Swick, D.C.; Arnold, M.S. How to engage in collaborative curriculum design to foster undergraduate inquiry and research in all disciplines. In How to Design, Implement, and Sustain a Research-Supportive Undergraduate Curriculum: A Compendium of Successful Curricular Practices for Faculty and Institutions Engaged in Undergraduate Research; Council on Undergraduate Research: Washington, DC, USA, 2007; pp. 341–357. [Google Scholar]
- Denton, J.W.; Franke, V.; Surendra, K.N. Curriculum and course design: A new approach using quality function deployment. J. Educ. Bus. 2005, 81, 111–117. [Google Scholar] [CrossRef]
- Wolf, P. A model for facilitating curriculum development in higher education: A faculty-driven, data-informed, and educational developer supported approach. New Dir. Teach. Learn. 2007, 112, 15–20. [Google Scholar] [CrossRef]
- Van den Akker, J.; De Boer, W.; Folmer, E.; Kuiper, W.; Letschert, J.; Nieveen, N.; Thijs, A. Curriculum in Development; Netherlands Institute for Curriculum Development (Slo): Enschede, The Netherlands, 2009. [Google Scholar]
- Van der Aalst, W.; Damiani, E. Processes meet big data: Connecting data science with process science. IEEE Trans. Serv. Comput. 2015, 8, 810–819. [Google Scholar] [CrossRef]
- Bogarín, A.; Cerezo, R.; Romero, C. A survey on educational process mining. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1230. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data science in massive open online courses. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1187. [Google Scholar] [CrossRef]
- Weijters, A.J.M.M.; van Der Aalst, W.M.; De Medeiros, A.A. Process mining with the heuristics miner-algorithm. Tech. Univ. Eindh. Tech Rep. WP 2006, 166, 1–34. [Google Scholar]
- Trcka, N.; Pechenizkiy, M.; van der Aalst, W. Process mining from educational data. In Handbook of Educational Data Mining; CRC Press: Boca Raton, FL, USA, 2010; pp. 123–142. [Google Scholar]
- Ghazal, M.A.; Ibrahim, O.; Salama, M.A. Educational process mining: A systematic literature review. In Proceedings of the 2017 European Conference on Electrical Engineering and Computer Science (EECS), Bern, Switzerland, 17–19 November 2017. [Google Scholar]
- Van Der Aalst, W. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Aulck, L.; Velagapudi, N.; Blumenstock, J.; West, J. Predicting student dropout in higher education. arXiv 2017, arXiv:1606.06364. [Google Scholar]
- Bogarín, A.; Cerezo, R.; Romero, C. Discovering learning processes using inductive miner: A case study with learning management systems (LMSs). Psicothema 2018, 30, 322–329. [Google Scholar] [PubMed]
- Mukala, P.; Buijs, J.; Leemans, M.; Van der Aalst, W. Learning analytics on coursera event data: A process mining approach. CEUR Workshop Proc. 2015, 1527, 18–32. [Google Scholar]
- Buck-Emden, R.; Dahmann, F.D. Analyse von Studienverläufen mit Process-Mining-Techniken. HMD Prax. Wirtsch. 2018, 55, 846–865. [Google Scholar] [CrossRef]
- Buck-Emden, R.; Dahmann, F.D. Zur Auswertung von Studienverläufen Mit Process-Mining-Techniken; Technical Report 07-2017; Hochschule Bonn-Rhein-Sieg: Sankt Augustin, Germany, 2017. [Google Scholar]
- Thaler, B.; Haag, N.; Binder, D.; Unger, M. Studierenden-Monitoring (STUDMON), Begleitender Projektbericht, Version 2, 24.09. 2019; HIS: Vienna, Austria, 2019. [Google Scholar]
- R Core Team. R: A Language an Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Ripley, B.; Lapsley, M. RODBC. 2022. Available online: https://CRAN.R-project.org/package=shiny (accessed on 14 December 2023).
- Janssenswillen, G.; van Hulzen, G.; Mannhardt, F.; Martin, N.; Van Houdt, G. bupaR. 2023. Available online: https://CRAN.R-project.org/package=shiny (accessed on 14 December 2023).
- Janssenswillen, G.; van Hulzen, G.; Depaire, B.; Mannhardt, F.; Beuving, T. processmapR. 2023. Available online: https://CRAN.R-project.org/package=shiny (accessed on 14 December 2023).
- Mannhardt, F. processanimateR. 2023. Available online: https://CRAN.R-project.org/package=shiny (accessed on 14 December 2023).
- Chang, W.; Cheng, J.; Allaire, J.; Sievert, C.; Schloerke, B.; Xie, Y.; Allen, J.; McPherson, J.; Dipert, A.; Borges, B. shiny. 2023. Available online: https://CRAN.R-project.org/package=shiny (accessed on 14 December 2023).
- Mol, M. Rosetta Code. 2023. Available online: https://rosettacode.org/wiki/Evaluate_binomial_coefficients (accessed on 14 December 2023).
- Heublein, U. Student drop-out from German higher education institutions. Eur. J. Educ. 2014, 49, 497–513. [Google Scholar] [CrossRef]
- Ozga, J.; Sukhnandan, L. Undergraduate non-completion: Developing an explanatory model. High. Educ. Q. 1998, 52, 316–333. [Google Scholar] [CrossRef]
- Wilcox, P.; Winn, S.; Fyvie-Gauld, M. ‘It was nothing to do with the university, it was just the people’: The role of social support in the first-year experience of higher education. Stud. High. Educ. 2005, 30, 707–722. [Google Scholar] [CrossRef]
- Bardach, L.; Lüftenegger, M.; Oczlon, S.; Spiel, C.; Schober, B. Context-related problems and university students’ dropout intentions—The buffering effect of personal best goals. Eur. J. Psychol. Educ. 2020, 35, 477–493. [Google Scholar] [CrossRef]
- Barbera, S.A.; Berkshire, S.D.; Boronat, C.B.; Kennedy, M.H. Review of undergraduate student retention and graduation since 2010: Patterns, predictions, and recommendations for 2020. J. Coll. Stud. Retent. Res. Theory Pract. 2020, 22, 227–250. [Google Scholar] [CrossRef]
- Chan, Z.C.; Cheng, W.Y.; Fong, M.K.; Fung, Y.S.; Ki, Y.M.; Li, Y.L.; Wong, H.T.; Wong, L.T.; Tsoi, W.F. Curriculum design and attrition among undergraduate nursing students: A systematic review. Nurse Educ. Today 2019, 74, 41–53. [Google Scholar] [CrossRef]
- Devadas, B. A Critical Review of Qualitative Research Methods in Evaluating Nursing Curriculum Models: Implication for Nursing Education in the Arab World. J. Educ. Pract. 2016, 7, 119–126. [Google Scholar]
- Ariani, D.W.; Susilo, Y.S. Why do it later? Goal orientation, self-efficacy, test anxiety, on procrastination. J. Educ. Cult. Psychol. Stud. (ECPS J.) 2018, 17, 45–73. [Google Scholar] [CrossRef]
- Krispenz, A.; Gort, C.; Schültke, L.; Dickhäuser, O. How to reduce test anxiety and academic procrastination through inquiry of cognitive appraisals: A pilot study investigating the role of academic self-efficacy. Front. Psychol. 2019, 10, 1917. [Google Scholar] [CrossRef]
- Bey, A.; Champagnat, R. Analyzing Student Programming Paths using Clustering and Process Mining. In Proceedings of the CSEDU 2022—14th International Conference on Computer Supported Education, Virtual Event, 22–24 April 2022. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Loder, A.K.F. The Use of Educational Process Mining on Dropout and Graduation Data in the Curricula (Re-)Design of Universities. Trends High. Educ. 2024, 3, 50-66. https://doi.org/10.3390/higheredu3010004
Loder AKF. The Use of Educational Process Mining on Dropout and Graduation Data in the Curricula (Re-)Design of Universities. Trends in Higher Education. 2024; 3(1):50-66. https://doi.org/10.3390/higheredu3010004
Chicago/Turabian StyleLoder, Alexander Karl Ferdinand. 2024. "The Use of Educational Process Mining on Dropout and Graduation Data in the Curricula (Re-)Design of Universities" Trends in Higher Education 3, no. 1: 50-66. https://doi.org/10.3390/higheredu3010004
APA StyleLoder, A. K. F. (2024). The Use of Educational Process Mining on Dropout and Graduation Data in the Curricula (Re-)Design of Universities. Trends in Higher Education, 3(1), 50-66. https://doi.org/10.3390/higheredu3010004