A U-Net Based Approach for Automating Tribological Experiments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
State of the Art
2. Materials and Methods
2.1. Setup
2.2. Dataset
2.3. Pre-Processing and Data Augmentation
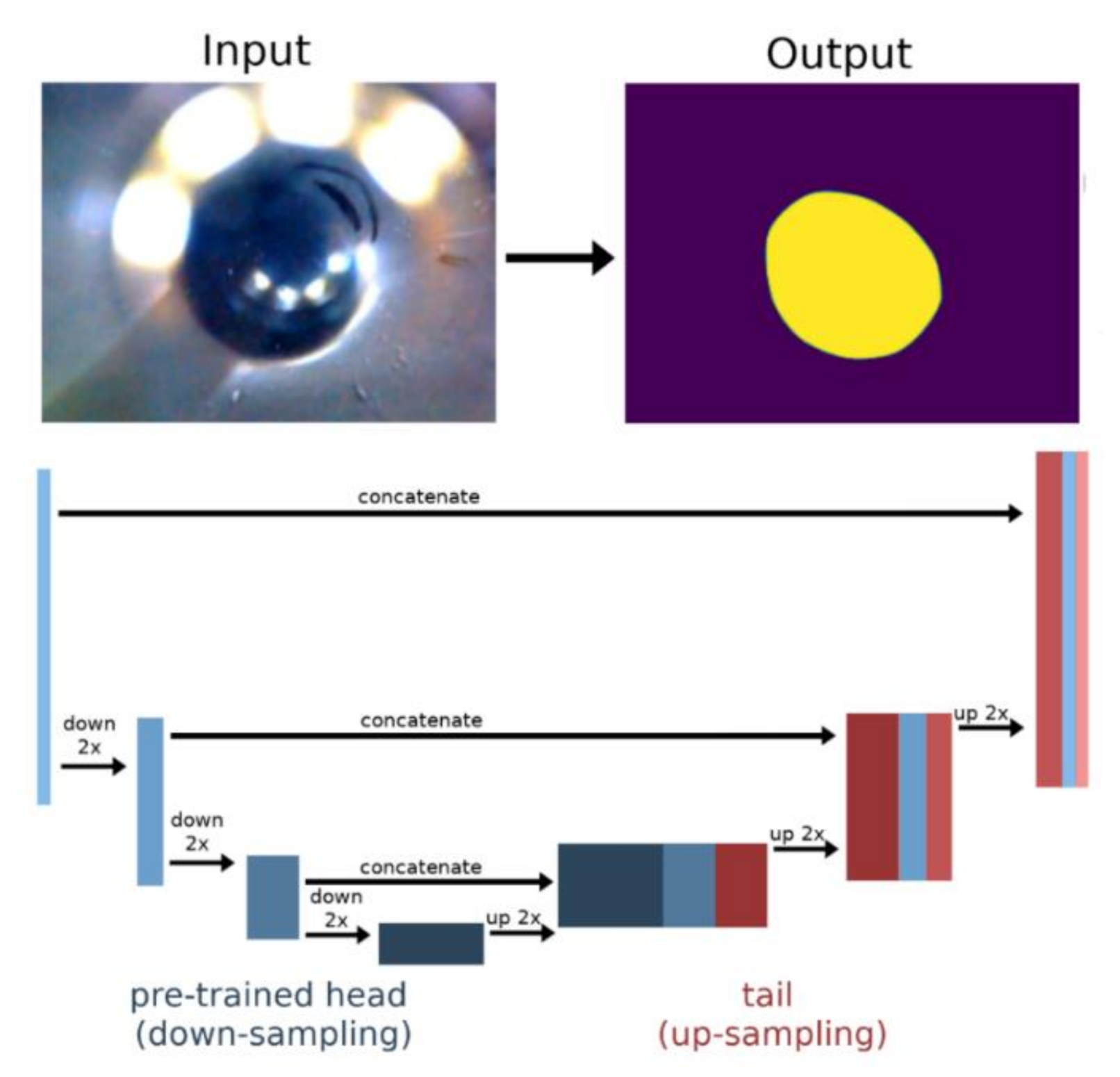
2.4. U-Net Architecture with Pre-Trained Head
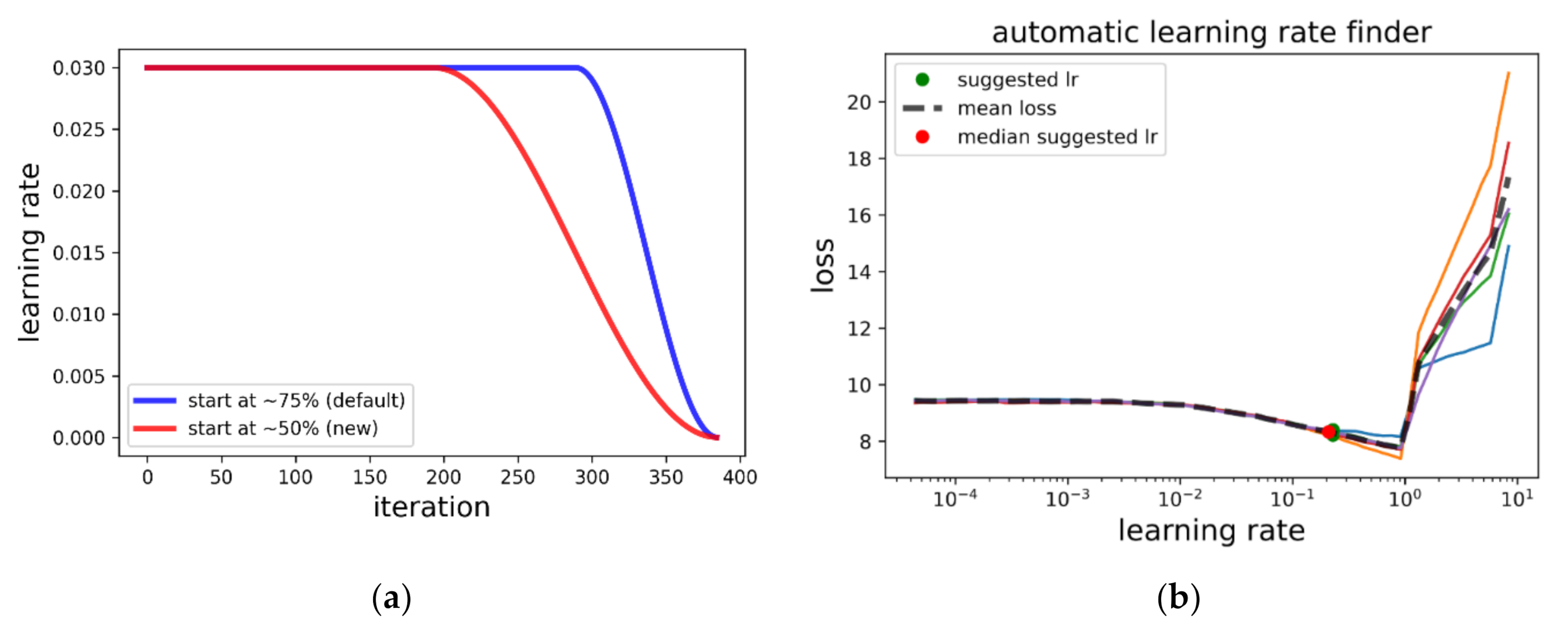
2.5. Network Tweaks
2.6. Optimization
- 20 epochs: only tail weights trainable, fca schedule, maximum learning rate =
- 20 epochs: all weights trainable, fca schedule, maximum learning rate =
2.7. Evaluation
2.8. Software and Hardware
3. Results
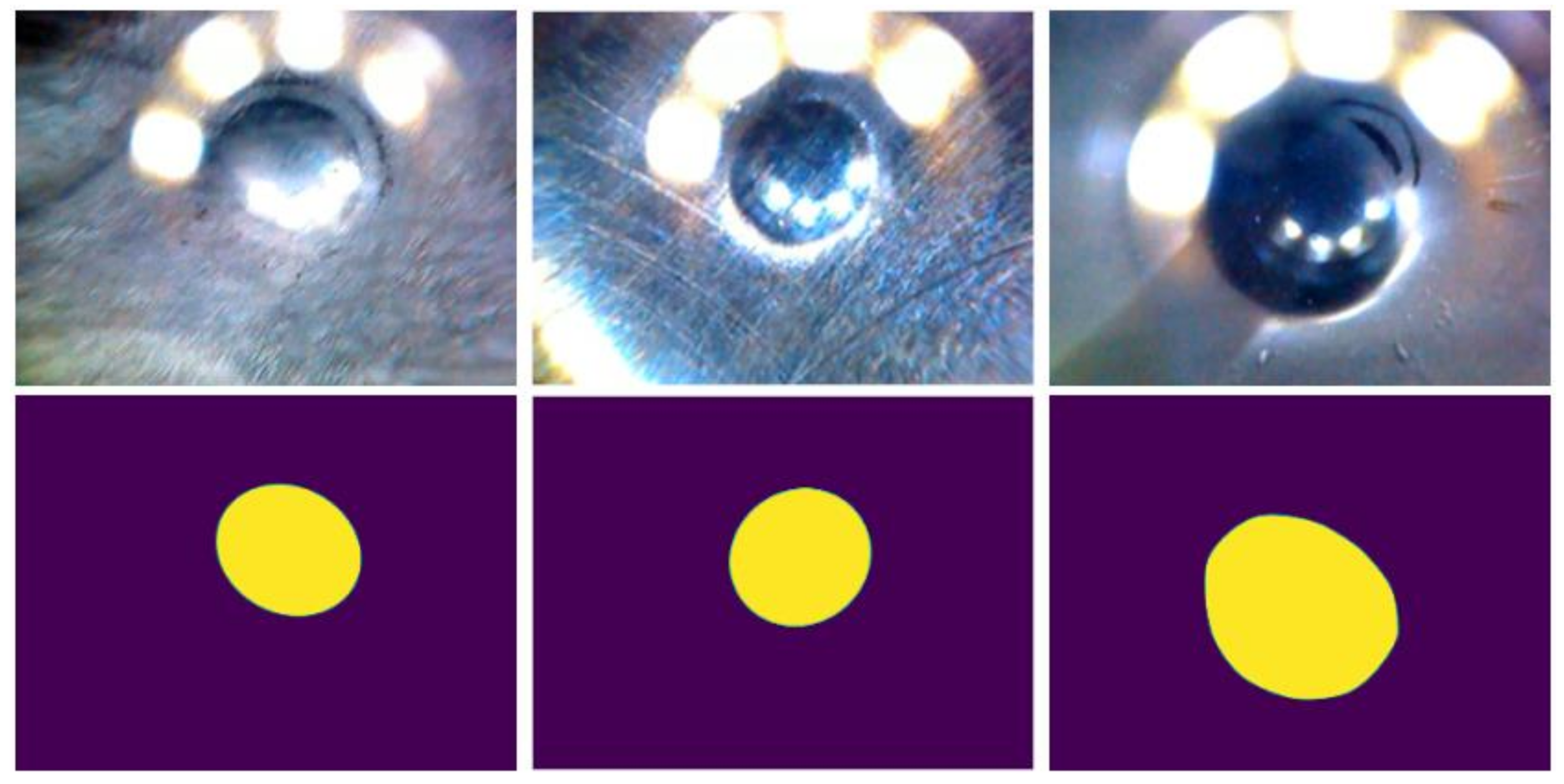
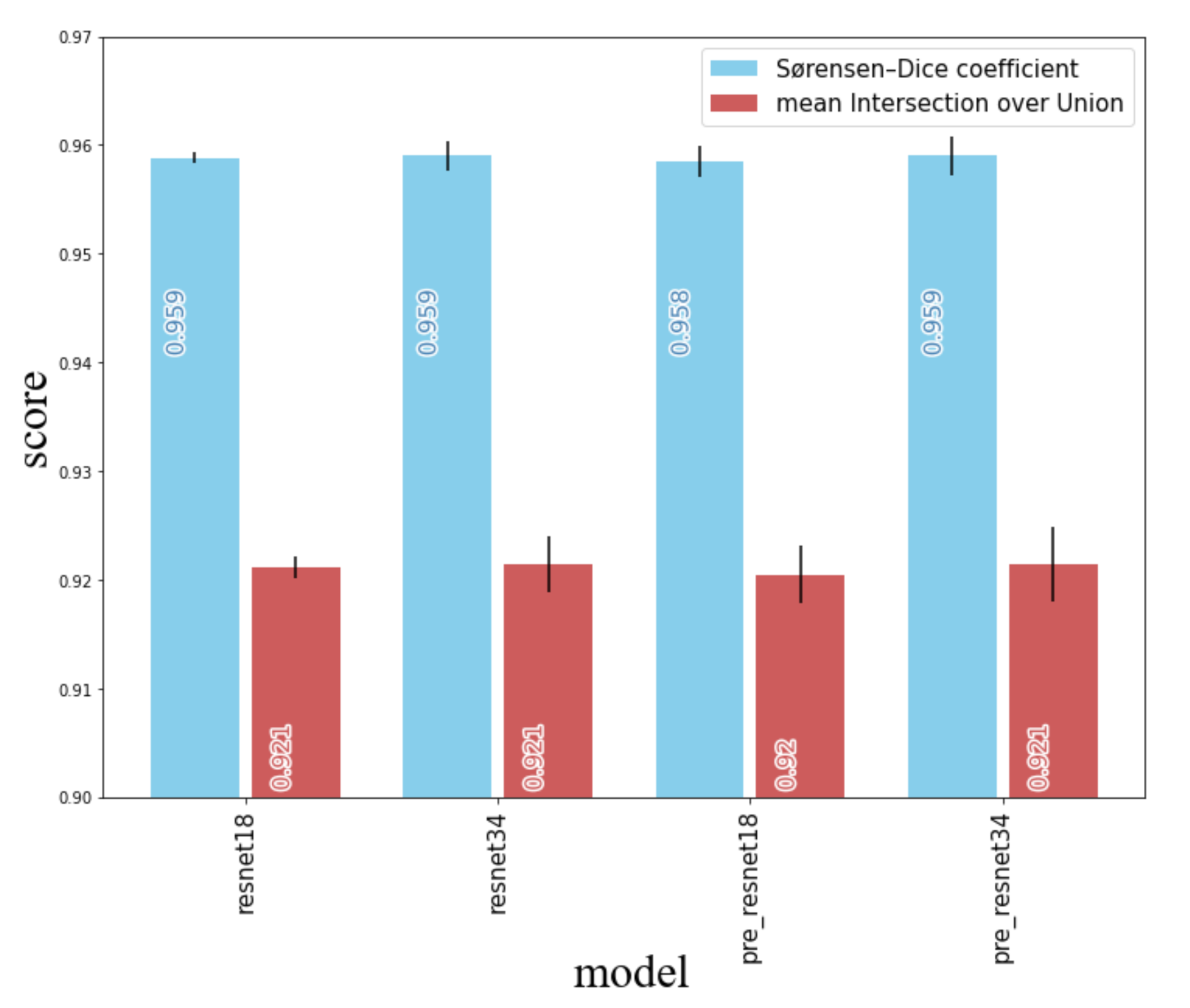
3.1. Performance
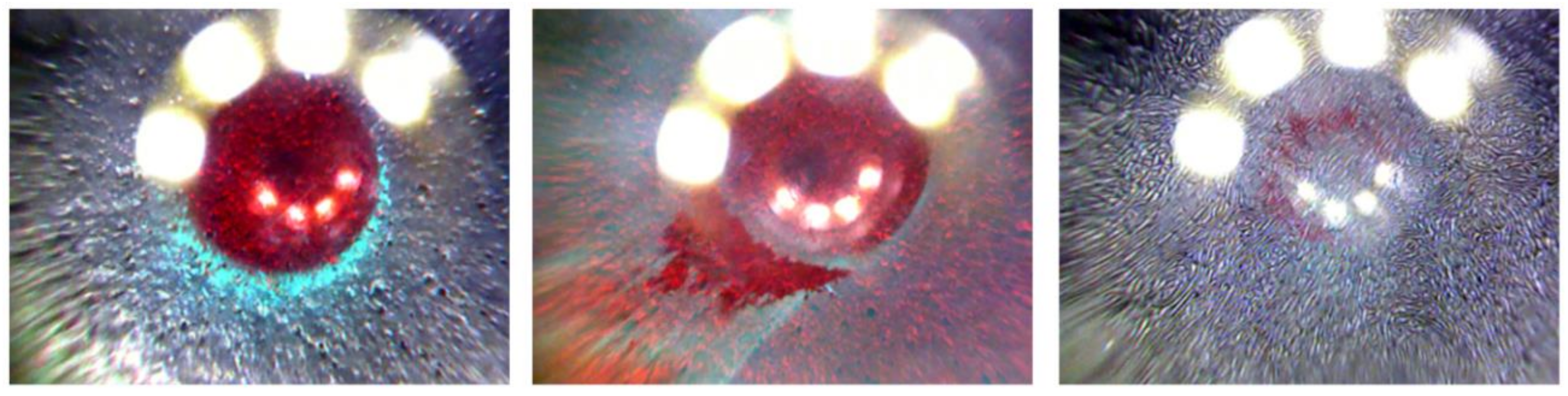
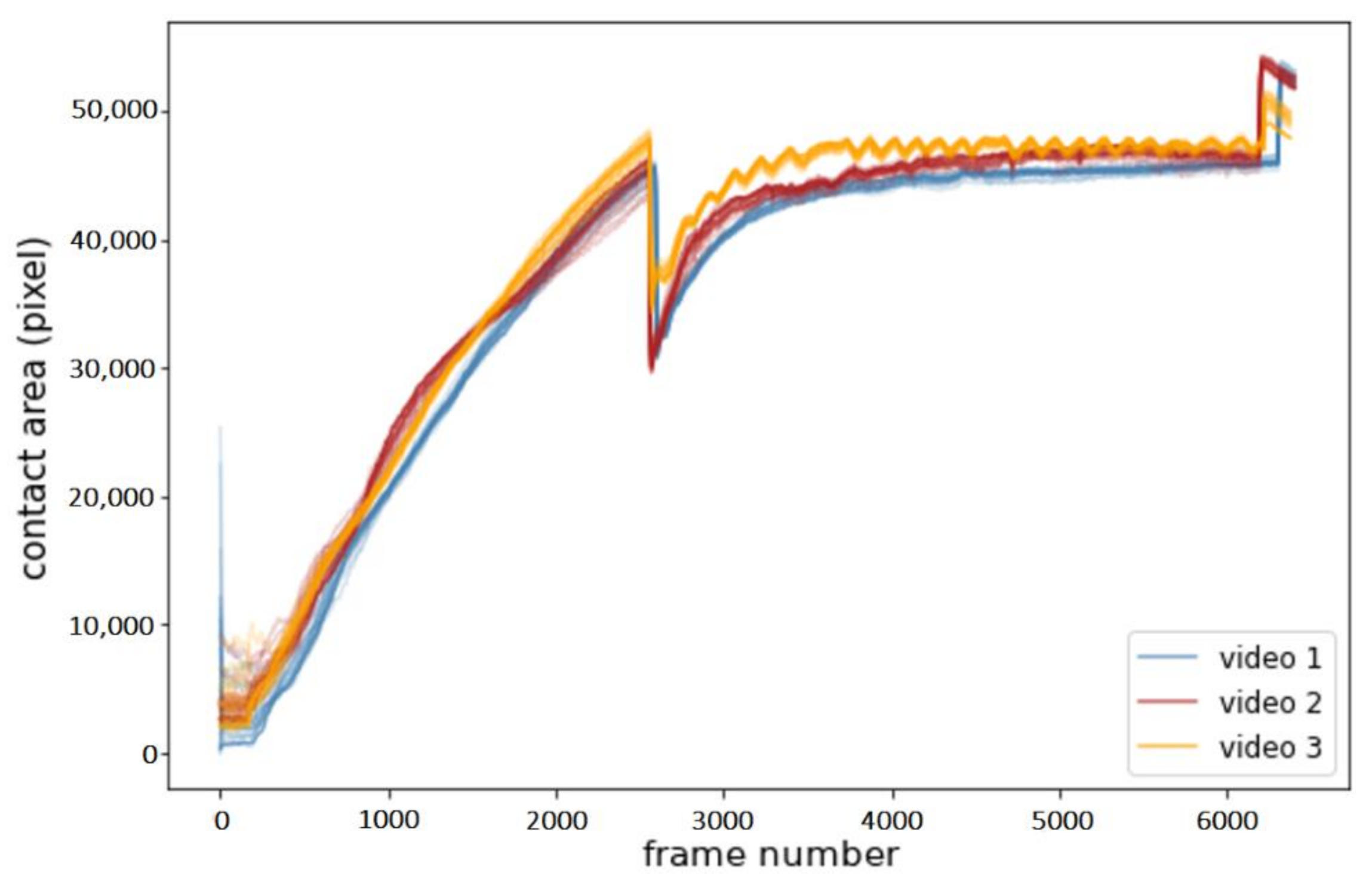
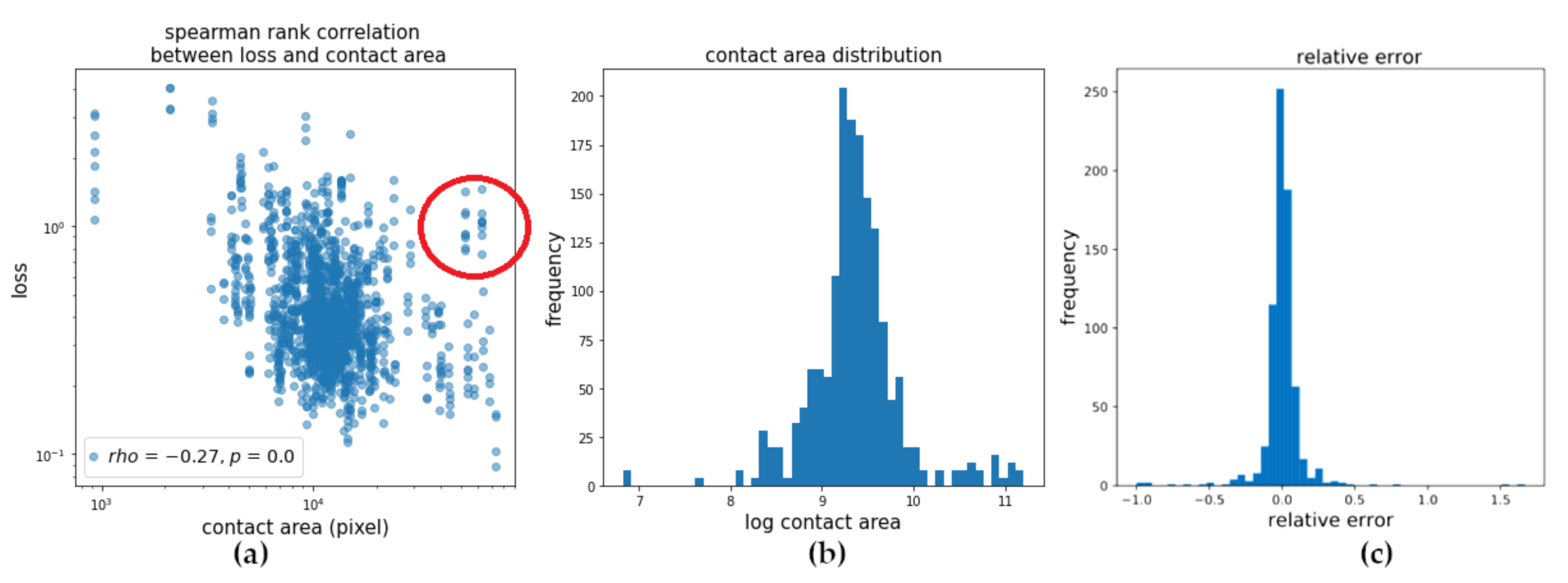
3.2. Failure Cases
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Persson, B.N.J.; Albohr, O.; Heinrich, G.; Ueba, H. Crack propagation in rubber-like materials. J. Physics: Condens. Matter. 2005, 17, R1071–R1142. [Google Scholar] [CrossRef]
- Greenwood, J.A.; Johnson, K.L. The mechanics of adhesion of viscoelastic solids. Philos. Mag. A 1981, 43, 697–711. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Wu, H. Mixed Precision Training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Touvron, H.; Vedaldi, A.; Douze, M.; Jégou, H. Fixing the train-test resolution discrepancy: Fix efficient net. arXiv 2020, arXiv:2003.08237. [Google Scholar]
- Xie, Q.; Luong, M.-T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves ImageNet Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 16–18 June 2020; pp. 10684–10695. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Li, M. ResNeSt: Split-attention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Du, X.; Lin, T.-Y.; Jin, P.; Ghiasi, G.; Tan, M.; Cui, Y.; Le, Q.V.; Song, X. SpineNet: Learning scale-permuted backbone for recognition and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; pp. 11589–11598. [Google Scholar]
- Everingham, M.; Van-Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 20 September 2020).
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with Atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. ExFuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. arXiv 2020, arXiv:1909.11065. [Google Scholar]
- Mohan, R.; Valada, A. EfficientPS: Efficient panoptic segmentation. arXiv 2020, arXiv:2004.02307. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic understanding of scenes through the ADE20K dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xu, H.; Mo, H.; Tan, J.; Yang, C.; Ren, W. DCNAS: Densely connected neural architecture search for semantic image segmentation. arXiv 2020, arXiv:2003.11883. [Google Scholar]
- Hirasawa, T.; Aoyama, K.; Tanimoto, T.; Ishihara, S.; Shichijo, S.; Ozawa, T.; Ohnishi, T.; Fujishiro, M.; Matsuo, K.; Fujisaki, J.; et al. Application of artificial intelligence using a convolutional neural network for detecting gastric cancer in endoscopic images. Gastric Cancer 2018, 21, 653–660. [Google Scholar] [CrossRef] [Green Version]
- Shichijo, S.; Nomura, S.; Aoyama, K.; Nishikawa, Y.; Miura, M.; Shinagawa, T.; Takiyama, H.; Tanimoto, T.; Ishihara, S.; Matsuo, K.; et al. Application of convolutional neural networks in the diagnosis of helicobacter pylori infection based on endoscopic images. EBioMedicine 2017, 25, 106–111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodrigues, P.; Antunes, M.; Raposo, C.; Marques, P.; Fonseca, F.; Barreto, J.P. Deep segmentation leverages geometric pose estimation in computer-aided total knee arthroplasty. Heal. Technol. Lett. 2019, 6, 226–230. [Google Scholar] [CrossRef] [PubMed]
- Wen, S.; Chen, Z.; Li, C. Vision-based surface inspection system for bearing rollers using convolutional neural networks. Appl. Sci. 2018, 8, 2565. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Cai, J.; Wu, T.; Cao, G.; Kwok, N.; Zhou, S.; Peng, Z. A hybrid convolutional neural network for intelligent wear particle classification. Tribol. Int. 2019, 138, 166–173. [Google Scholar] [CrossRef]
- Chang, H.; Borghesani, P.; Peng, Z. Automated assessment of gear wear mechanism and severity using mould images and convolutional neural networks. Tribol. Int. 2020, 147, 106280. [Google Scholar] [CrossRef]
- Yu, S.Q.; Dai, X.J. Wear particle image segmentation method based on the recognition of background color. Tribol. (Beijing) 2007, 27, 467. [Google Scholar]
- Liu, H.; Wei, H.; Li, J.; Yang, Z. The segmentation of wear particles images using j-segmentation algorithm. Adv. Tribol. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Deng, Y.; Manjunath, B. Unsupervised segmentation of color-texture regions in images and video. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 800–810. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Yuan, F.; Gao, L.; Huang, R.; Wang, W. Wear debris classification and quantity and size calculation using convolutional neural network. In Proceedings of the International 2019 Cyberspace Congress, CyberDI and CyberLife, Beijing, China, 16–18 December 2019; pp. 470–486. [Google Scholar]
- Howard, J.; Gugger, S. Fastai: A Layered API for deep learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on deep transfer learning. In Proceedings of the Artificial Neural Networks and Machine Learning (ICANN 2018), Rhodes, Greece, 4–7 October 2018; pp. 270–279. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Riba, E.; Mishkin, D.; Ponsa, D.; Rublee, E.; Bradski, G. Kornia: An open source differentiable computer vision library for PyTorch. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV 2020), Snowmass Village, CO, USA, 1–5 March 2020; pp. 3663–3672. [Google Scholar]
- Ranger-Deep-Learning-Optimizer. Available online: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer (accessed on 20 September 2020).
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Zhang, M.R.; Lucas, J.; Hinton, G.; Ba, J. Lookahead Optimizer: K steps forward, 1 step back. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019; pp. 9597–9608. [Google Scholar]
- Yong, H.; Huang, J.; Hua, X.; Zhang, L. Gradient centralization: A new optimization technique for deep neural networks. arXiv 2020, arXiv:2004.01461. [Google Scholar]
- Sørensen, T. A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons. K. Dan. Videnskabernes Selsk. 1948, 5, 1–34. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Taghanaki, S.A.; Zheng, Y.; Zhou, S.K.; Georgescu, B.; Sharma, P.; Xu, D.; Comaniciu, D.; Hamarneh, G. Combo loss: Handling input and output imbalance in multi-organ segmentation. Comput. Med Imaging Graph. 2019, 75, 24–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, K.C.L.; Moradi, M.; Tang, H.; Syeda-Mahmood, T. 3D segmentation with exponential logarithmic loss for highly unbalanced object sizes. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI 2017), Quebec City, Canada, 11–13 September 2017; pp. 612–619. [Google Scholar]
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1—Learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- OpenCV. Available online: https://opencv.org/ (accessed on 28 August 2020).
- Suzuki, S.; Be, K. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Van Rossum, G. Python programming language. In Proceedings of the USENIX Annual Technical Conference, Santa Clara, CA, USA, 17–22 June 2007; p. 36. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Staar, B.; Bayrak, S.; Paulkowski, D.; Freitag, M. A U-Net Based Approach for Automating Tribological Experiments. Sensors 2020, 20, 6703. https://doi.org/10.3390/s20226703
Staar B, Bayrak S, Paulkowski D, Freitag M. A U-Net Based Approach for Automating Tribological Experiments. Sensors. 2020; 20(22):6703. https://doi.org/10.3390/s20226703
Chicago/Turabian StyleStaar, Benjamin, Suleyman Bayrak, Dominik Paulkowski, and Michael Freitag. 2020. "A U-Net Based Approach for Automating Tribological Experiments" Sensors 20, no. 22: 6703. https://doi.org/10.3390/s20226703
APA StyleStaar, B., Bayrak, S., Paulkowski, D., & Freitag, M. (2020). A U-Net Based Approach for Automating Tribological Experiments. Sensors, 20(22), 6703. https://doi.org/10.3390/s20226703