1. Introduction
Optimization is not limited to applied mathematics, engineering, medicine, economics, computer science, operations research or any other science, but has become a fundamental tool in all fields, where constantly developing new algorithms and theoretical methods have allowed it to evolve in all directions, with a particular focus on artificial intelligence, such as deep learning, machine learning, computer vision, fuzzy logic systems, and quantum computing [
1,
2].
Optimization has grown steadily over the past 50 years. Modern society not only lives in a highly competitive environment, but is also forced to plan for growth in a sustainable manner and be concerned about resource conservation. Therefore, it is essential to optimally plan, design, operate and manage resources and assets. The first approach is to optimize each operation separately. However, the current trend is toward an integrated approach: synthesis and design, design and control, production planning, scheduling and control [
3].
Theoretically, optimization has evolved to provide general solutions to linear, non-linear, unbounded and constrained network optimization problems. These optimization problems are called mathematical programming problems and are divided into two different categories: linear and nonlinear programming problems. Biologically derived genetic algorithms and simulated annealing are two equally powerful methods that have emerged in recent years. The development of computer technology has provided users with a variety of optimization codes with varying degrees of rigor and complexity. It is also possible to extend the capabilities of an existing method by integrating the features of two or more optimization methods to achieve more efficient optimization methodologies [
4]; current optimization methods that can solve specific problems are still being developed, as we do not yet have a method that can solve them all, such as explained by the No Free Lunch (NFL) Algorithm [
5], although the research trend is moving in that direction.
RNNs are a special class of neural network characterized by their inherent self-connectivity [
6], and their variants are used in many contexts where temporal dependence of data is an important latent feature in model design [
7]. The most important applications of RNNs include time series prediction [
8], sequence transduction [
9], language modeling [
10,
11,
12,
13], speech recognition [
14], word embedding learning [
15], sound modeling [
16], handwriting recognition [
17,
18], and image generation [
19]. A common variant of RNN called long short-term memory [
20] is used in many of these studies.
One of the main advantages of this method with respect to others is that in general the NARNN-DMOA method is much easier to implement with better results, and with lower computation costs. Other methods use very robust Ensemble Neural Network architectures of several layers and of more than 2000 neurons and different architectures of Interval Type-2 Fuzzy Logic Systems (IT2FLSs), in addition to optimization algorithms such as PSO Genetic Algorithms [
21,
22,
23], which implies a high computational cost.
The algorithm can be applied, as we previously mentioned, to robots, microsystems, sensors, devices, etc., in the optimization of the parameters of their models that are being experimented upon. The proposed algorithm can be used in the optimization of the architecture of a neural network or in the parameters of the membership functions of a fuzzy logic system; as we have seen in other articles [
24,
25,
26,
27], this type of experimentation with the DMOA is the subject of a future work that we plan to undertake in due course
The main contribution of this research is to use the DMOA algorithm to optimize the architecture of the NARNN neural network using the MG chaotic time series, which has not previously been done in the current literature.
The structure of this paper is as follows: (1) brief introduction of Optimization and Recurrent Neural Networks (RNNs), (2) we include a brief description of Nonlinear Autoregressive Neural Networks (NARNNN), (3) presentation of the Discrete Mycorrhiza Optimization Algorithm (DMOA) inspired by the symbiosis of plant roots and MN, (4) proposed method using the NARNN, the new DMOA algorithm and Mackey Glass chaotic time series, (5) results obtained from this research, such as statistical data, hypothesis testing and comparison of the DMOA-NARNN method with other methods, (6) in-depth discussion of the results and comparison of the error with other methods, and (7) conclusions of the obtained results.
2. Nonlinear Autoregressive Neural Networks
An Artificial Neural Network (ANN) is a type of neural network represented by a mathematical model inspired by the neural connections of the human brain. It is an intelligent system capable of recognizing time series patterns and nonlinear features.
Therefore, it is widely used to model nonlinear dynamic time series [
28]. ANN incorporates artificial neurons to process information. It consists of single neurons connected to a network via weighted links. Each input is multiplied by a weight calculated by a mathematical function that determines the activation of the neurons. Another activation function calculates the output of the artificial neuron based on a certain threshold [
29].
The output of a neuron can be written as Equation (1):
where
b is the bias of the neuron, the bias input to the neuron algorithm is an offset value that helps the signal exceed the threshold of the activation function,
f is the activation function,
wi is the weight,
xi is the input, and
y is the output.
Several types of ANNs have been presented in the literature, including Multilayer Perceptron (MLP), in which neurons are grouped into an input layer, one or more hidden layers, and an output layer. These also include RNNs such as Layer Recurrent Networks [
30], Time Delay Neural Networks (TDNN) [
31], and NARNN [
32]. In RNNs, the output of a dynamic system depends not only on the current inputs, but also on the history of inputs and states of the system. The NARNN is a recurrent dynamic network based on a linear autoregressive model with feedback connections, and consists of several network layers.
Humans do not start their thinking from scratch every second. As we read, we understand each word based on our understanding of the previous words. We never start thinking from scratch every time we do; our thoughts have permanence. A traditional ANN cannot do this, and it seems like a major shortcoming. For example, imagine that you want to classify what kind of event is happening at each point in a movie. It is not clear how a traditional ANN could use its reasoning about earlier events in the movie to inform later events, and RNN address this problem. They are networks with loops in them which allows information to persist.
An RNN is a type of artificial neural network that uses sequential or time series da-ta. These deep learning algorithms are commonly used for ordinal or temporal problems, such as language translation, natural language processing (NLP) [
33,
34], speech recognition, and image captioning [
35]. They are distinguished by their "memory" because they take information from previous inputs to influence the current input and output. While traditional deep neural networks assume that inputs and outputs are independent of each other, the output of recurrent neural networks depends on previous elements within the sequence.
NARNNs are a type of RNN with memory and feedback capabilities. The output of each point is based on the result of the dynamic synthesis of the system before the current time. It has great advantages for modeling and simulating dynamic changes in time series [
36]. Typical NARNNs mainly consist of an input layer, a hidden layer, an output layer and an input delay function, the basic structure of which is shown in
Figure 1.
In
Figure 1,
y(t) is the output of the NARNN, 1..19 represents the delay order, w is the joint weight and b is the threshold of NARNNs. The model of NARNN networks can be expressed as in Equation (2), where d is the delay order and f are a nonlinear function, where the future values depend only on the previous values d of the output signal.
From the equation, it can be seen that the value of
y(t) is determined by the values of
y(t − 1), …, y(t − d), which indicates that based on the continuity of data development, the model uses past values to estimate the current value [
37,
38].
The prediction method of the NARNN model adopts the recursive prediction method. The main purpose of this prediction method is to reproduce the predicted value one step ahead.
The future values of the time series
y(t) are predicted only from the past values of this series. This type of prediction is called Nonlinear Autoregression (NAR) and can be written as Equation (2):
This model can be used to predict financial instruments, but it does not use additional sequences [
39].
Looking at
Figure 2, NARNN represents the entire neural network.
Figure 3 “Unrolled” represents the individual layers, or time steps, of the NARNN network. Each layer corresponds to a single piece of data [
40,
41].
Predicting a sequence of values in a time series is also known as multi-pass fore-casting. Closed-loop networks can perform multi-step forecasting. When external feedback is missing, closed-loop networks can still make predictions using internal feedback. In NARNN prediction, the future values of a time series are predicted only from the past values of that series.
The current literature provides a history of very extensive research on the use of NARNNs in the following areas:
The use of NARNN in medical devices such as continuous glucose monitors and drug delivery pumps that are often combined with closed-loop systems to treat chronic diseases, for error detection and correction due to their predictive capabilities [
42].
The use of NARNNs as Chinese e-commerce sales forecasting to develop purchasing and inventory strategies for EC companies [
43], to support management decisions [
44], the effects of air pollution on respiratory morbidity and mortality [
45], the relationship between time series in the economy [
46], to model and forecast the prevalence of COVID-19 in Egypt. [
47], etc.
3. Discrete Mycorrhiza Optimization Algorithm
Most of the world’s plant species are associated with mycorrhizal fungi in nature; this association involves the interaction of fungal hyphae on plant roots. Hyphae extend from the roots into the soil, where they absorb nutrients and transport them through the mycelium to the colonized roots [
48]. Some hyphae connect host plants in what is known as a Mycorrhizal Network (MN). The MN is subway and is difficult to understand. As a result, plant and ecosystem ecologists have largely overlooked the role of MNs in plant community and ecosystem dynamics [
49].
It is clear that most MN are present and provide nutrition to many plant species. This has important implications for plant competition for soil nutrients, seedling formation, plant succession and plant community and ecosystem dynamics [
50].
Plant mycorrhizal associations have large-scale consequences throughout the eco-system [
51,
52]. The origins of plant-fungal symbiosis are ancient and have been proposed as a mechanism to facilitate soil colonization by plants 400 Mya [
53,
54]. Mycorrhizal symbiosis is a many-to-many relationship: plants tend to form symbioses with a diverse set of fungal species and, similarly, fungal species tend to be able to colonize plants of different species [
55].
In
Figure 4 we can see that through the MN resources such as carbon (CO
2) from plants to fungi and water, phosphorus, nitrogen and other nutrients from fungi to plants are exchanged, in addition to an exchange of information through chemical signals when the habitat feels threatened by fire, floods, pests, or predators. It should be noted that this exchange of resources can be between plants of the same species or of different species.
Figure 5 shows the symbiosis between plants and the fungal network and how the carbon in the form of sugars flows from the plants to the MN and how the MN fixes the nutrients in the roots of the plants.
The Nobel optimization algorithm DMOA is inspired by the nature of the Mycorrhiza Network (MN) and plant roots with this intimate interaction between these two organisms (plant roots and the network of MN fungi), a symbiosis is generated and it has been discovered that in this relationship [
56,
57,
58,
59,
60]:
There is a communication between plants, which may or may not be of the same species, through a network of fungi (MN).
There is an exchange of resources between plants through the fungal network (MN).
There is a defensive behavior against predators that can be insects or animals, for the survival of the whole habitat (plants and fungi).
The colonization of a forest through a fungal network (MN) thrives much more than a forest where there is no exchange of information and resources.
The launch and publication of the DMOA algorithm has just been carried out in 2022 [
61].
Figure 6 describes the flowchart of the DMOA algorithm: we initialize the parameters such as dimensions, epochs, number of iterations, etc., and we also initialize the two populations of plants and mycorrhizae; with these populations we find the best fitness of plants and mycorrhizae, while with these results we use the biological operators. The first operator is represented by the Lotka-Volterra System of Discrete Equations (LVSDE) Cooperative Model [
62], whose result has inference on the other two models represented by LVSDE, Defense and Competitive [
63,
64], and in this frequency we evaluate the fitness to determine if it is better than the previous one and we update the same as the populations, if not we continue with the next iteration and continue the calculation with the biological operators. If the stop condition is fulfilled we obtain the last solution before evaluation and the algorithm ends.
4. Proposed Method
The proposed method is to use the Discrete Mycorrhiza Optimization Algorithm (DMOA) to optimize the architecture of the Nonlinear Autoregressive Neural Network (NARNN), and as input data we use the Mackey-Glass chaotic time series. In
Figure 7 and Algorithm 1 we can find the DMOA-NARNN flowchart and DMOA-NARNN pseudocode, respectively. The DMOA algorithm is explained in
Figure 6 in the previous section, in this flowchart we include the optimization of the NARNN, evaluating its results by means of the RMSE, until we manage to find the minimum error of that architecture through the iterations and the populations of the DMOA algorithm (Algorithm 1).
| Algorithm 1 DMOA-NARNN Pseudocode. Discrete Mycorrhiza Optimization Algorithm (DMOA) |
Objective min or max f(x), x = (x1, x2, …, xd) Define parameters (a, b, c, d, e, f, x, y) Initialize a population of n plants and mycorrhiza with random solutions Find the best solution fit in the initial population while (t < maxIter) for i = 1:n (for n plants and Mycorrhiza population) end for Apply (LV-Cooperative Model) if else end if rand ([1 2]) if (rand = 1) Apply (LV-Predator-Prey Model) else Apply (LV- Competitive Model) end if Evaluate new solutions. NARNN-Architecture Evaluate Error Error minor? Update NARNN-Architecture. Find the current best NARNN-Architecture solution. end while
|
Difference equations often describe the evolution of a particular phenomenon over time. For example, if a given population has discrete generations, the size of
(n + 1
) 1st generation
x(n + 1
) is a function of the nth generation
x(
n). This relationship is expressed by Equation (3):
We can look at this issue from another perspective. You can generate a sequence from the point
x0, Equation (4):
f(x0) is called the first iterate of x0 under f.
Discrete models driven by difference equations are more suitable than continuous models when reproductive generations last only one breeding season (no overlapping generations) [
65,
66].
An example would be a population that reproduces seasonally, that is, once a year. If we wanted to determine how the population size changes over many years, we could collect data to estimate the population size at the same time each year (say, shortly after the breeding season ends). We know that between the times at which we estimate population size, some individuals will die and that during the breeding season many new individuals will be born, but we ignore changes in population size from day to day, or week to week, and look only at how population size changes from year to year. Thus, when we build a mathematical model of this population, it is reasonable that the model only predicts the population size for each year shortly after the breeding season. In this case, the underlying variable, time, is represented in the mathematical model as increasing in discrete one-year increments.
The LVSDE Equations (5)–(10), have many uses in applied science. These models were first developed in mathematical biology, after which research spread to other fields [
67,
68,
69,
70,
71].
Discrete Equations (5) and (6) Cooperative Model (Resource-Exchange), for both species, where parameters
a, b, d, e, g, and
h are positive constants,
xi and
yi represent the initial conditions of the population for both species and are positive real numbers [
72].
The biological operators are represented by LVSDE, the mathematical description of the Discrete Equations (7) and (8) Defense Model (Predator-Prey), where the parameters a, b, d and g are positive constants,
xi and
yi represent the initial population conditions for both species and are positive real numbers [
73,
74].
Discrete Equations (9) and (10) Competitive Model (Colonization), for two species, where the parameters
a, b, d, e, g, and
h are positive constants,
xi and
yi are the populations for each of the species respectively and are positive real numbers. Each of the parameters of the above equations is described in
Table 1, [
74].
Table 1 contains the parameters used in all the experiments performed in this research, both those of the DMOA algorithm and those of the NARNN neural network.
The theory of Differential Equations, as well as that of Equations by Differences, can be found in Youssef N. Raffoul.
Qualitative Theory of Volterra Difference Equations [
75], Sigrun Bodine et al.,
Asymptotic Integration of Differential and Difference Equations [
76], Takashi Honda et al.,
Operator Theoretic Phenomena of the Markov Operators which are Induced by Stochastic Difference Equations [
77], Ronald E. Mickens,
Difference Equations Theory, Applications and Advanced Topics [
78], and Konrad Kitzing, et al.,
A Hilbert Space Approach to Difference Equations [
79].
The metric for measuring error is RMSE (Root Mean Square Error) or root mean square deviation, which is one of the most commonly used measures for evaluating the quality of predictions. It shows how far predictions fall from measured true values using Euclidean distance Equation (11), where n is the number of data points,
yi is the
ith measurement and
ŷi is the expected prediction [
80,
81].
Mackey-Glass
Chaotic and random time series are both disordered and unpredictable. In extreme cases, the data are so mixed up that those consecutive values seem unrelated to each other. Such disorder would normally eliminate the ability to predict future values from past data.
The Mackey-Glass chaotic time series Equation (12) is a nonlinear differential equation of time delay, and this equation is widely used in the modeling of natural phenomena to make comparisons between different forecasting techniques and regression models [
82,
83,
84], where
a = 0.1,
b = 0.2, and
τ = 17 are real numbers,
t is the time, and with this setting the series produces chaotic behavior, and we can compare the forecasting performance of DMOA-NARNN with other models in the literature.
5. Results
This section shows the results of the experiments performed in the research involving the Non-Optimized and Optimized results of the method.
Table 2 presents 10 different non-optimized NARNN architectures using only the Mackey-Glass chaotic time series; in the table the columns are represented by: N—Experiment Number, Experiment Name, S—Sample size, T—Training, V—Validation, P—Prediction, HL—Hidden Layers of the NARNN, E—Number of experiment and RMSE (Root Mean Square Error), while the best architecture of the non-optimized NARNN is found in experiment number 4, with the RMSE of 0.1670.
In
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13, the
y axes represent the input values (Validation-Training) and output values of the samples (Prediction-Error), the
x axis represents the number of samples in time, Name is the name of the experiment, Samples is the total number of samples in the experiment, Training is the number of samples for training, Error is the minimum error obtained in the experiment, and
HL represents the number of neurons in the hidden layers.
Figure 8 shows the behavior of the data for 1000 samples of the NARNN403, obtaining an RMSE of 0.2307, with the reference data at the top of the figure.
Figure 9 and
Figure 10 show the data behavior for 1000 samples of the NARNN404 and NARNN405, obtaining an RMSE of 0.167 and 0.2488, respectively, with the reference data at the top of each figure.
Table 3 shows the results of 39 NARNN architectures optimized with the DMOA algorithm using the Mackey-Glass chaotic time series, in the table the columns are represented by: N - Experiment Number, Experiment Name, S—Sample size, T—Training, V—Validation, P—Prediction, HL—Hidden Layers of the NARNN, I—Number of iterations, Tt—total time of the experiments in seconds, T—time in which the best result was found and RMSE (Root Mean Square Error). The best architecture of the non-optimized NARNN is found in experiment number 31, with the RMSE of 0.0023.
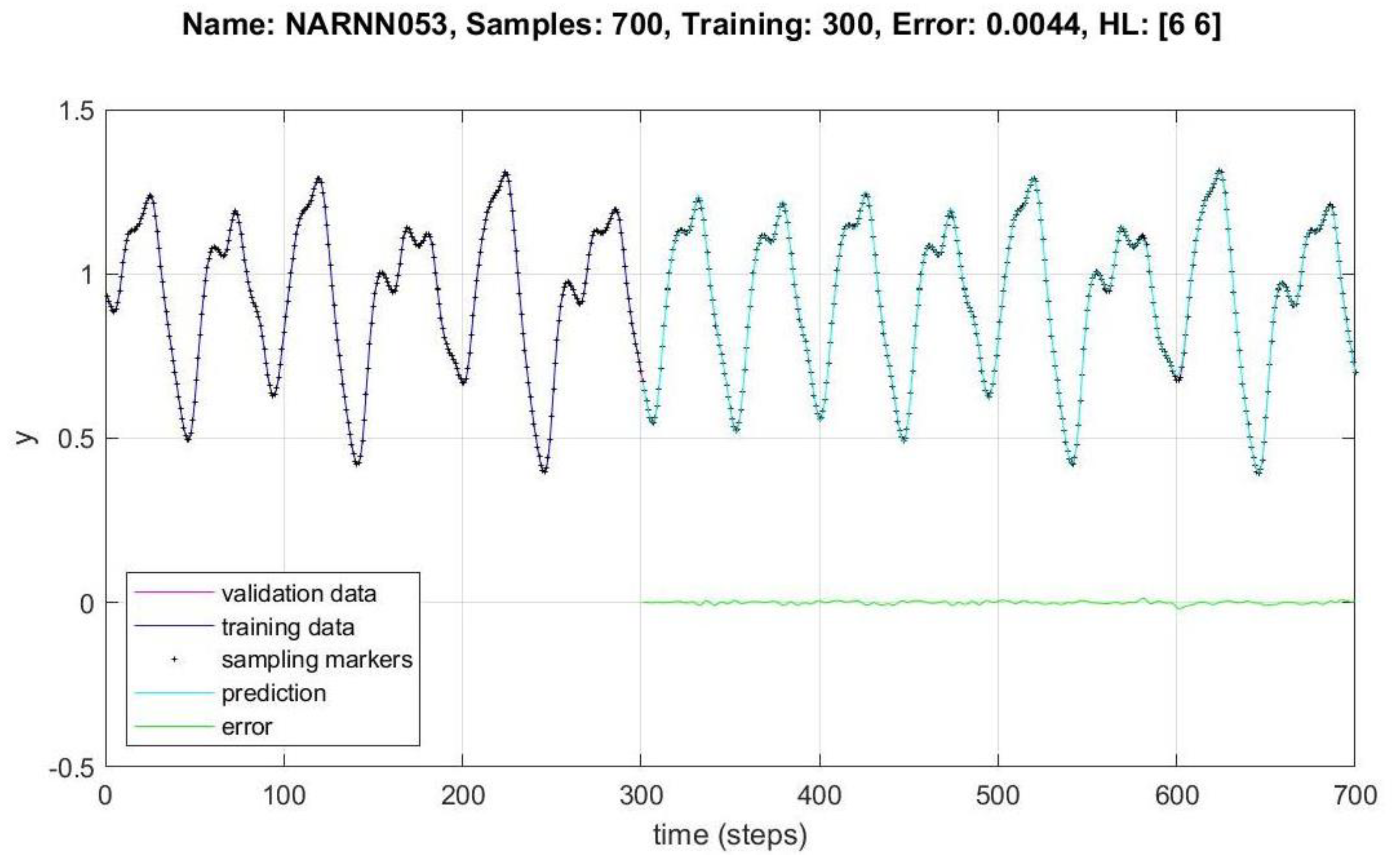
Figure 11,
Figure 12 and
Figure 13 show the data behavior for 700, 700 and 1000 samples of the NARNN053, NARNN302 and NARNN303, obtaining an RMSE of 0.0044, 0.0023 and 0.0033, respectively, with the reference data at the top of each figure.
As for the complexity of the DMOA algorithm, it is a linear order algorithm that uses the discrete equations of Lotka-Volterra Equations (5)–(10), and in the search to find the global minimum it performs iterations and in each cycle it compares the best previous local minimum with the lowest current minimum and updates the value in the case that this is the case. As for the times,
Table 3 shows the times Tt which represents the total time (seconds) of the experiment and T (seconds) the time in which the DMOA algorithm found the lowest local minimum; in terms of its efficiency the algorithm took 1235 s, about 21 min, to find the lowest minimum 0.0023, which seems to us a short time compared to the times used by the method [
22] of up to 3 h and a half, the method [
21], its experiments took up to 81 h to find the lowest minimum and as for the method [
23] it does not provide the times of its experiments.
5.1. Statistical Data
Table 4 shows 30 experiments with eight non-optimized NARNNN architectures. Each column represents the total number of samples and the number of training samples used for each architecture (700 × 300), and at the end of the table we can find the results of the total sum, mean and standard deviation for each column.
Table 5 shows 30 experiments with eight optimized NARNNN architectures; each column represents the total number of samples and the number of training samples used by each architecture (700 × 300), and at the end of the table we can find the results of the total sum, mean and standard deviation for each column.
5.2. Hypothesis Test
Equation (13) represents Hypothesis Testing, Null Hypothesis Equation (14) and Alternative Hypothesis Equation (15), with which comparisons were made between the non-optimized and optimized experiments of the method proposed here.
where
is the Mean of sample 1,
Mean of sample 2,
Standard Deviation of sample 1,
Standard Deviation of sample 2,
Number of sample data 1,
Number of sample data 2,
and
.
Significance Level α = 0.05, Confidence Level = 95%, Confidence Level = 1 − α; 1−0.05 = 0.95 o 95%, Since the p-value is less than 0.01, the null hypothesis is rejected.
Table 6 and
Table 7 show the results of the hypothesis testing done on the non-optimized and optimized methods shown above; of the eight different architectures, the test results show that in only six were the optimized NARNNs better, and the non-optimized NARNNs were better in two.
In
Table 6, N and Name represent the number and name of the experiment, respectively. Error is the minimum error found, HL are the Hidden Layers of neural network (1, 2, 3), and N is the number of neurons in each HL. In
Table 7, the samples are represented by Total number of samples, T is the training samples, V is the validation samples, P represents the prediction, and
p-value represents the results of the hypothesis test.
5.3. Comparisone with Other Methods
Table 8 shows the comparison with other methods that performed experimentation with the chaotic Mackey-Glass time series, and it can be seen from the table that the lowest error belongs to the optimized NARNN-302.
In
Table 8, case number 1, the method is the Optimization of the Fuzzy Integrators in Ensembles of ANFIS Model for Time Series Prediction [
21], where the authors use the Mackey-Glass chaotic time series, with genetic optimization of Type-1 Fuzzy Logic System (T1FLS) and Interval Type-2 Fuzzy Logic System (IT2FLS) integrators in Ensemble of ANFIS models and evaluate the results through Root Mean Square Error (RMSE). ANFIS is a hybrid model of a neural network implementation of a TSK (Takagi-Sugeno-Kang) fuzzy inference system. ANFIS applies a hybrid algorithm which integrates BP (Backpropagation) and LSE (least square estimation) algorithms, and thus it has a fast learning speed.
Case number 2 refers to the method using Particle Swarm Optimization of ensemble neural networks with fuzzy aggregation for time series prediction of the Mexican Stock Exchange [
22]. In this case, the authors propose an ensemble neural network model with type-2 fuzzy logic for the integration of responses; in addition, the particle swarm optimization method determines the number of modules of the ensemble neural network, the number of layers and number of neurons per layer, and thus the best architecture of the ensemble neural network is obtained. Once this architecture is obtained, the results of the modules with type-1 and type-2 fuzzy logic systems are added, the inputs to the fuzzy system are the responses according to the number of modules of the network, and this is the number of inputs of the fuzzy system.
Case number 3 refers to the Application of Interval Type-2 Fuzzy Neural Networks (IT2FNN) in non-linear identification and time series prediction (MG) [
23]. The authors propose IT2FNN models that combine the uncertainty management advantage of type-2 fuzzy sets with the learning capabilities of neural networks. One of the main ideas of this approach is that the proposed IT2FNN architectures can obtain similar or better outputs than type-2 interval fuzzy systems using the Karnik and Mendel (KM) algorithm, but with lower computational cost, which is one of the main disadvantages of KM mentioned in many papers in the literature. Cases 4 and 5 have already been explained earlier in this article.
By making a brief description of the techniques of the different methods above, we can observe the complexity of their designs using optimization algorithms such as PSO and GAs as optimizers, robust Ensemble Neural Networks, T1FLS and IT2FLS, in comparison with our method that uses the optimization algorithm DMOA and NARNNN, which are neural networks with short memory, and according to the results are made precisely for the prediction of time series. In a future work we plan to perform experiments with the RNN LSTM networks, which have short- and long-term memories.
7. Conclusions
A total of 49 different architectures were designed, of which 10 non-optimized and 39 were optimized by the DMOA algorithm, 30,000 experiments were performed with the non-optimized architectures, and approximately 110,000 experiments were performed with the optimized architectures. A total of 700, 1000 and 1500 samples were generated with the MG chaotic time series, of which between 300 and 1000 were used for training, between 300 and 900 were used for validation in different combinations, and between 300 and 900 points were generated as prediction points, as can be seen in
Table 2 and
Table 3. The design of the NARNN architectures were two and three hidden layers, with neurons in the range of 2–9, and the graphs of the most representative results of the non-optimized and optimized NARNNs are presented in
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13.
The optimization of the NARNN network with the DMOA algorithm obtained good results, better than without optimizing the network, and better than the other methods with which it was compared, although not all of the optimized architectures were better in the hypothesis test (only five of them were), the results of the error were much better, as can be seen in
Table 7. In the comparison with other methods, the results were also better, as demonstrated in
Table 8. We were also able to verify that the DMOA optimization algorithm is fast and efficient, which was really the reason for this research. We wish to continue investigating the efficiency of the algorithm in the optimization of architectures with other types of neural networks, also in Fuzzy Logic Systems Type-1 and Type-2, and also to do the same with the optimization algorithm CMOA (Continuous Mycorrhiza Optimization Algorithm). In addition, the proposed algorithm can be applied to robots, microsystems, sensors, devices, MEMS, microfluidics, piezoelectricity, motors, biosensors, 3D printing, etc.
We also intend to conduct further research and experimentation with the DMOA method and other time series. We will also consider the DMOA and the LSTM (Long Short-Term Memory) Neural Regression Network for Mackey-Glass time series, weather and financial forecasting, and we are interested in hybridizing the method with Interval Type-2 Fuzzy Logic System (IT2FLS), and Generalized Type-2 Fuzzy Logic System (GT2FLS).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}