
Automatic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation

Abstract
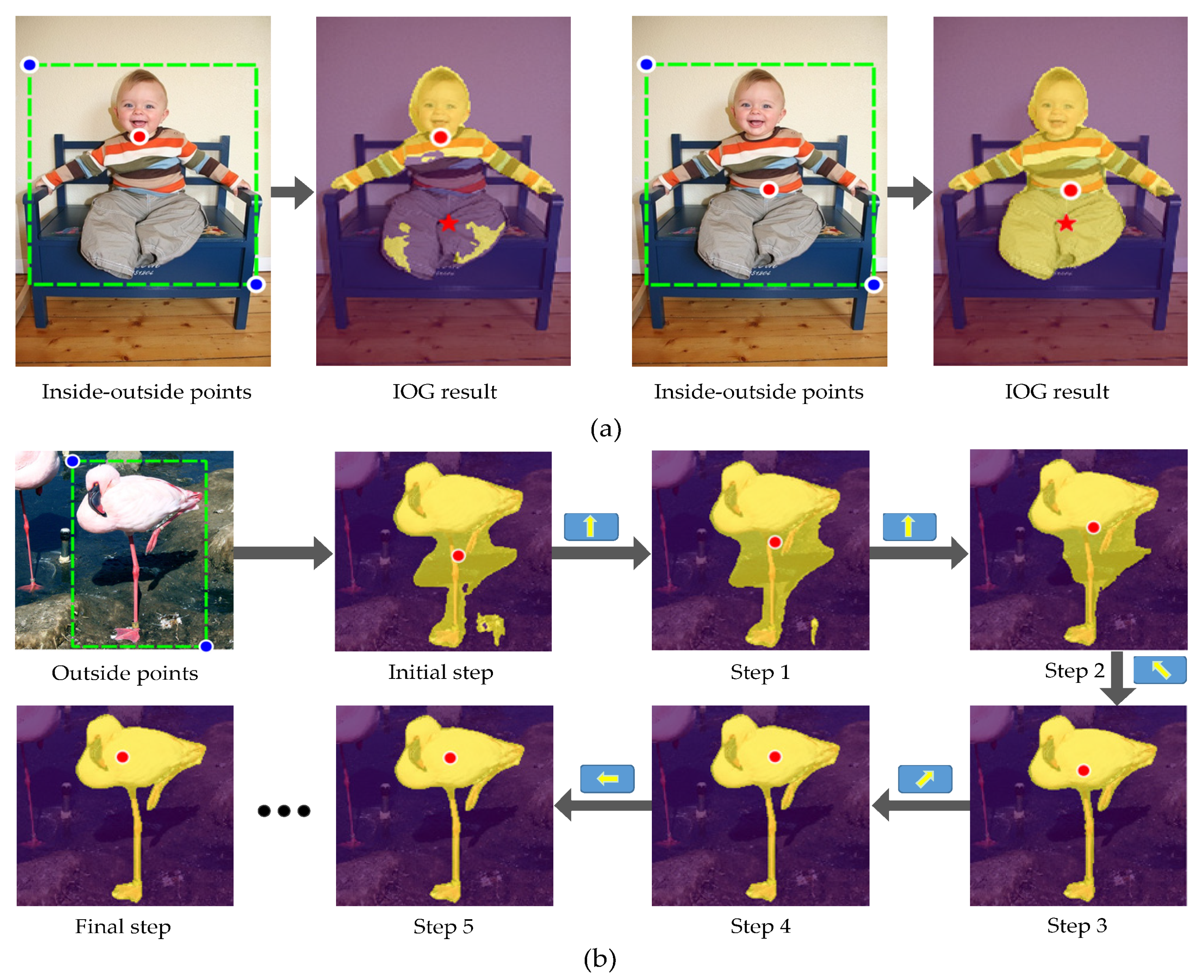
:1. Introduction
2. Related Work
3. Automatic Inside Point Localization System
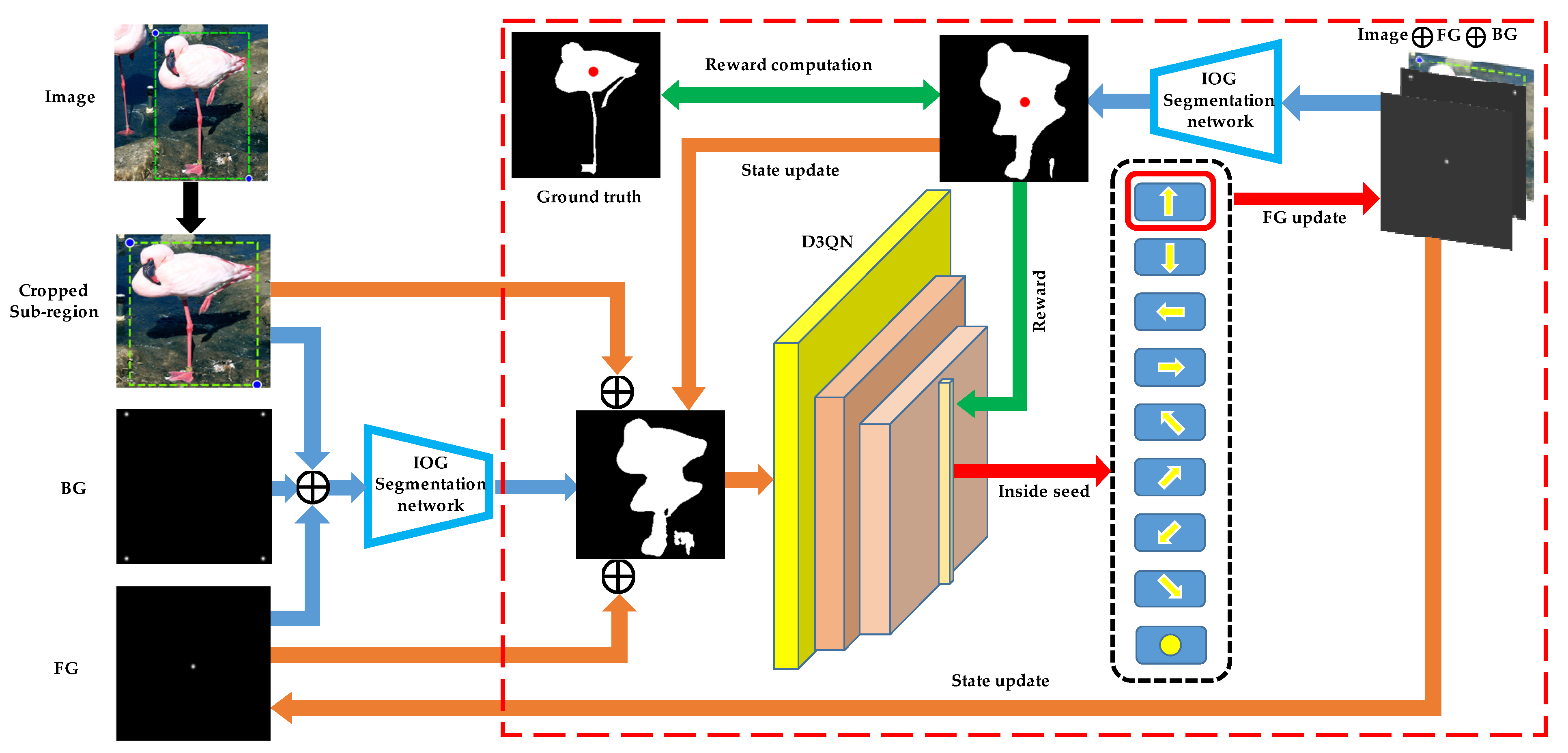
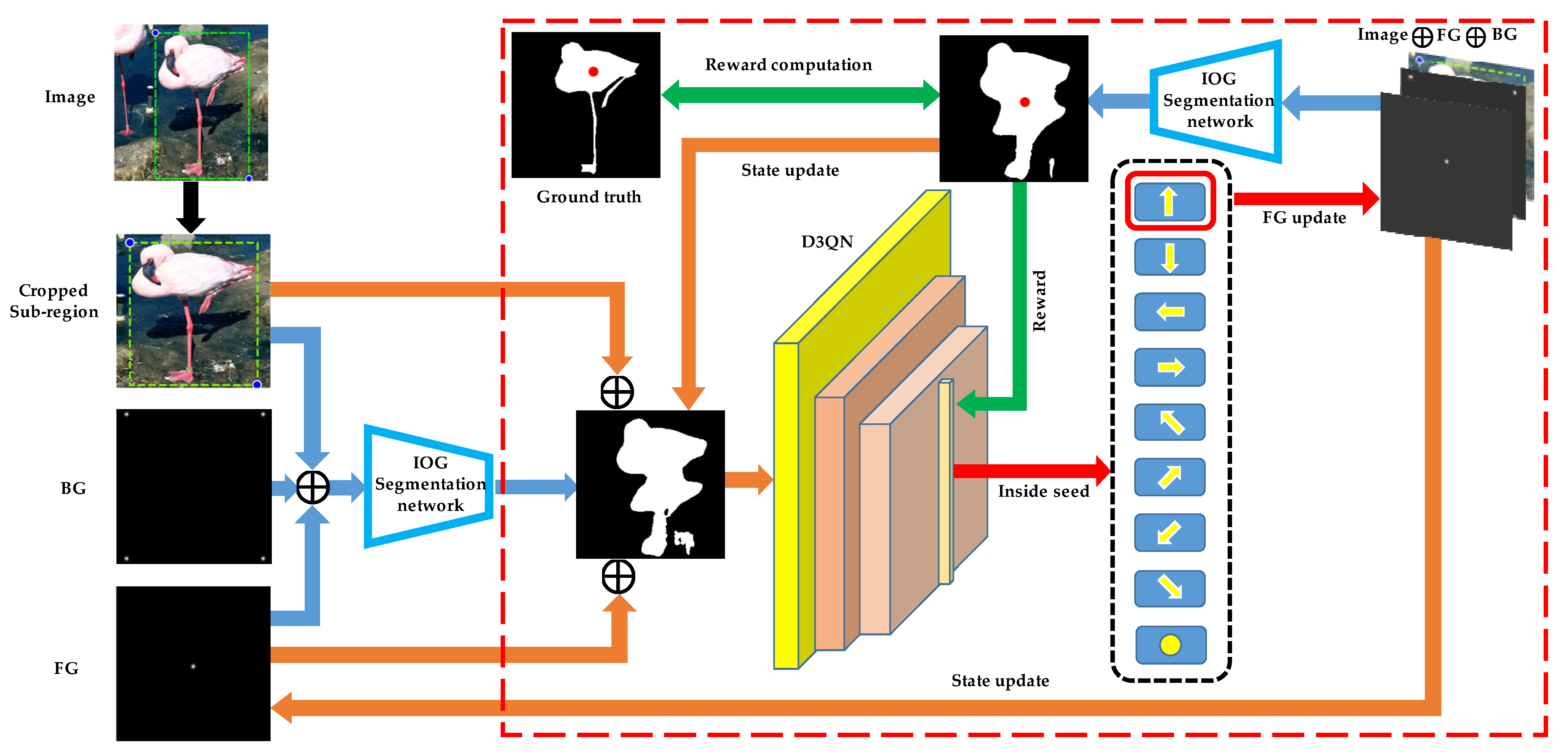
3.1. Overview
3.2. The Model
3.3. Training the Inside Point Localization Agent with Deep Reinforcement Learning
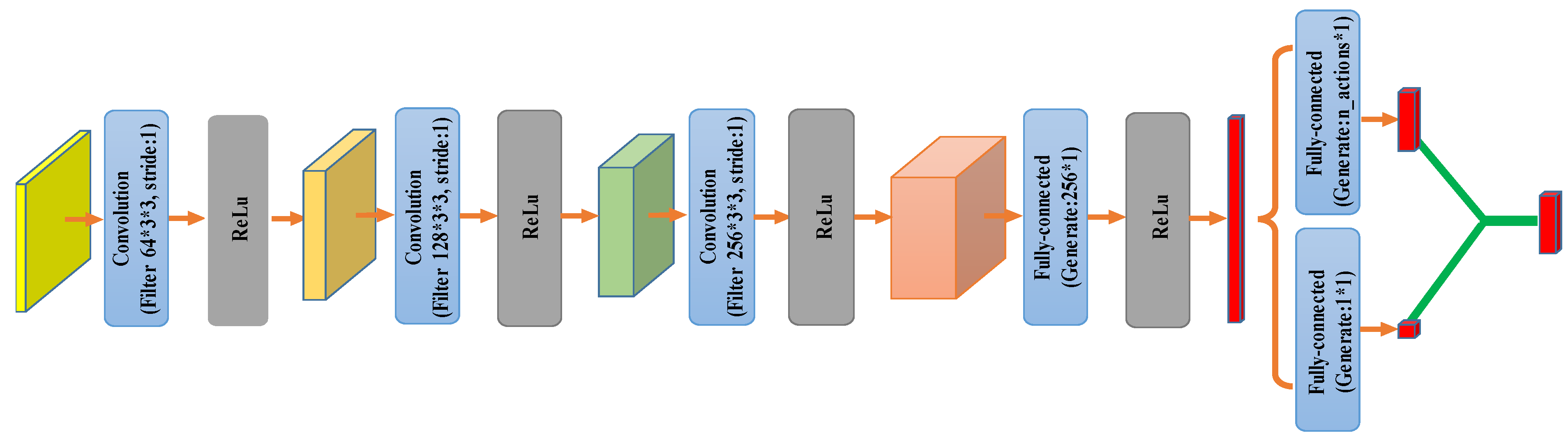
3.4. Network Architecture
4. Experiments
4.1. Datasets
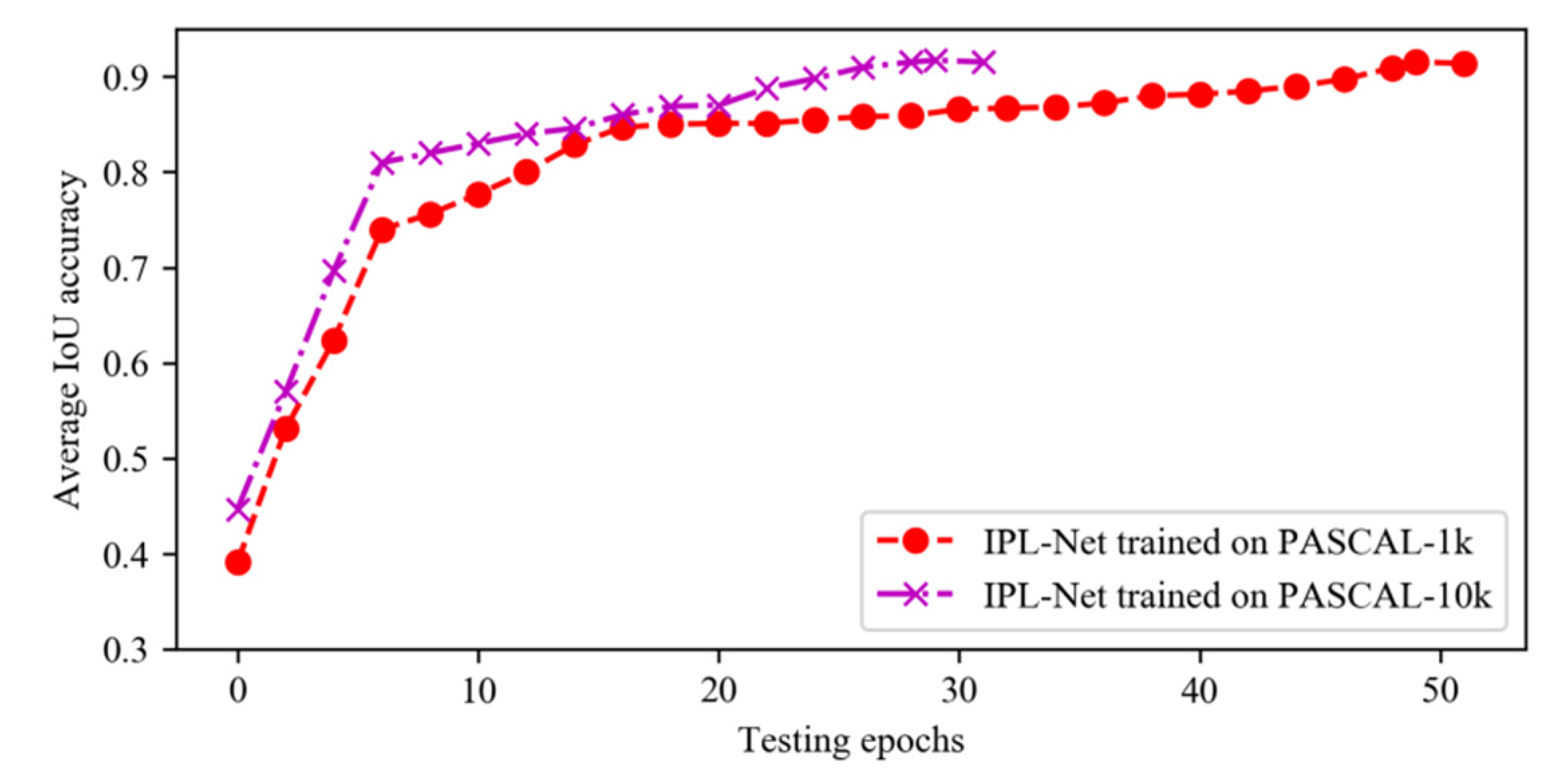
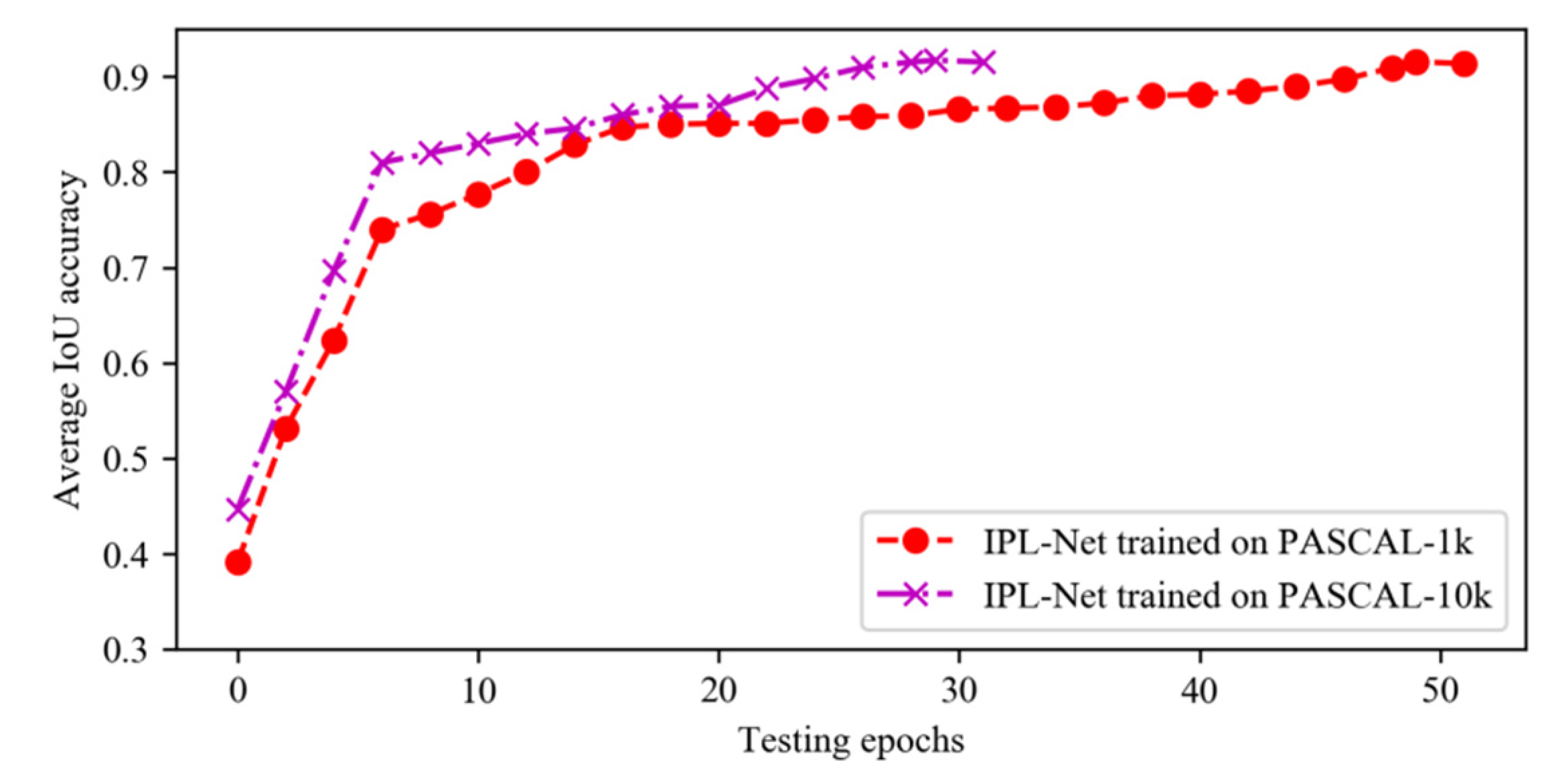
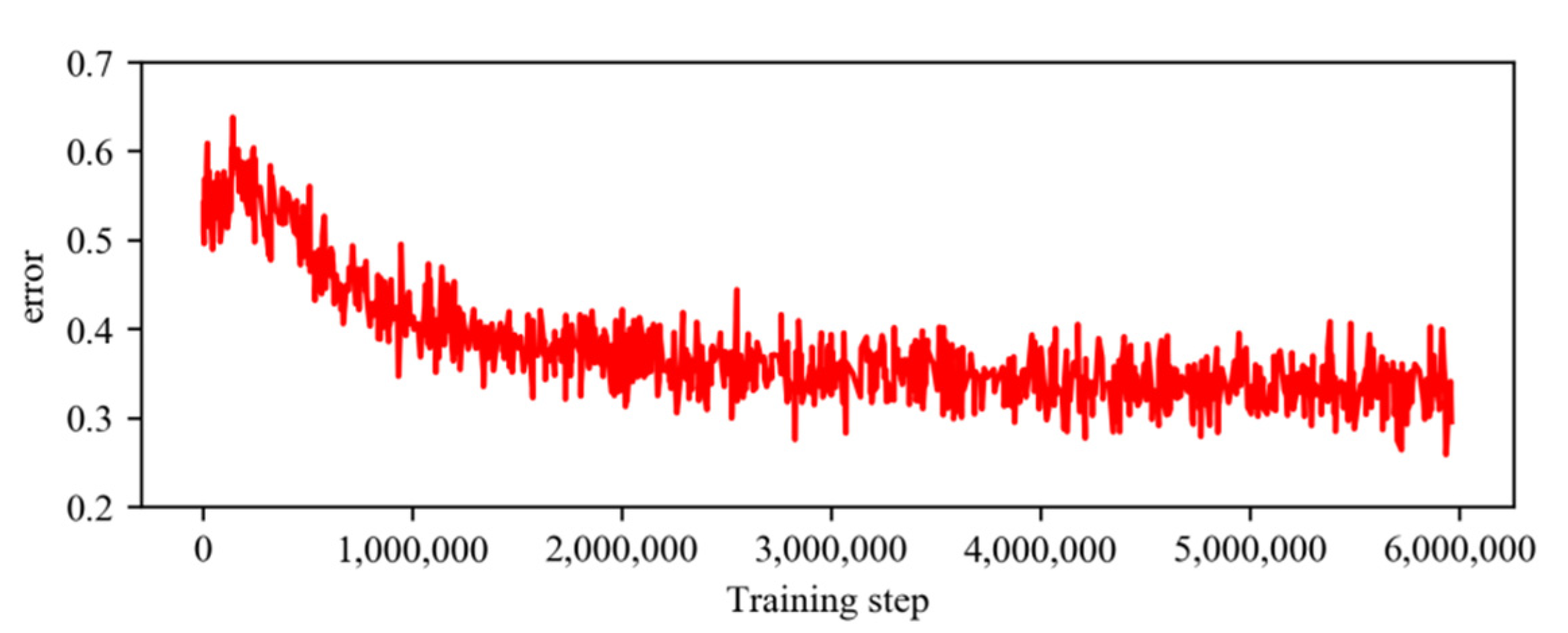
4.2. Network Training
4.3. Interactive Segmentation Results
4.4. Comparison with the State of the Arts
4.5. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive Medical Image Segmentation Using Deep Learning with Image-Specific Fine Tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef] [PubMed]
- Cheng, M.-M.; Hou, Q.-B.; Zhang, S.-H.; Rosin, P.L. Intelligent Visual Media Processing: When Graphics Meets Vision. J. Comput. Sci. Technol. 2017, 32, 110–121. [Google Scholar] [CrossRef]
- Lin, Z.; Zhang, Z.; Chen, L.-Z.; Cheng, M.-M.; Lu, S.-P. Interactive Image Segmentation with First Click Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 13339–13348. [Google Scholar]
- Boykov, Y.; Jolly, M.-P. Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images. In Proceedings of the International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 105–112. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive foreground extraction using iterated graph cuts. In Proceedings of the International Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–12 August 2004; pp. 309–314. [Google Scholar]
- Price, B.L.; Morse, B.; Cohen, S. Geodesic graph cut for interactive image segmentation. Comput. Vis. Pattern Recognit. 2010. [Google Scholar] [CrossRef] [Green Version]
- Grady, L. Random walks for image segmentation. TPAMI, 28, 1768-1783. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bai, X.; Sapiro, G. Geodesic Matting: A Framework for Fast Interactive Image and Video Segmentation and Matting. Int. J. Comput. Vis. 2009, 82, 113–132. [Google Scholar] [CrossRef]
- Ning, X.; Price, B.; Cohen, S.; Yang, J.; Huang, T. Deep Interactive Object Selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liew, J.H.; Wei, Y.; Wei, X.; Ong, S.H.; Feng, J. Regional Interactive Image Segmentation Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, Z.; Chen, Q.; Koltun, V. Interactive Image Segmentation with Latent Diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mahadevan, S.; Voigtlaender, P.; Leibe, B. Iteratively Trained Interactive Segmentation. arXiv 2018, arXiv:1805.04398. [Google Scholar]
- Jang, W.D.; Kim, C.S. Interactive Image Segmentation via Backpropagating Refinement Scheme. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 6–20 June 2019. [Google Scholar]
- Sofiiuk, K.; Petrov, I.; Barinova, O.; Konushin, A. F-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Maninis, K.K.; Caelles, S.; Pont-Tuset, J.; Gool, L.V. Deep Extreme Cut: From Extreme Points to Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, S.; Liew, J.H.; Wei, Y.; Wei, S.; Zhao, Y. Interactive Object Segmentation with Inside-Outside Guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Lee, K.M.; Myeong, H.; Song, G. SeedNet: Automatic Seed Generation with Deep Reinforcement Learning for Robust Interactive Segmentation. Comput. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1760–1768. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the National Conference on Artificial Intelligence, (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.V.; Lanctot, M.; Freitas, N.D. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Harley, T.; Lillicrap, T.P.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Fujimoto, S.; Hoof, H.V.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Caicedo, J.C.; Lazebnik, S. Active Object Localization with Deep Reinforcement Learning. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar]
- Siekmann, J.; Green, K.; Warila, J.; Fern, A.; Hurst, J. Blind Bipedal Stair Traversal via Sim-to-Real Reinforcement Learning. In Proceedings of the Robotics: Science and Systems, Virtual Conference, 12–16 July 2021. [Google Scholar]
- Feng, K.; Wang, Q.; Li, X.; Wen, C.-K. Deep Reinforcement Learning Based Intelligent Reflecting Surface Optimization for MISO Communication Systems. IEEE Wirel. Commun. Lett. 2020, 9, 745–749. [Google Scholar] [CrossRef]
- Bellemare, M.G.; Candido, S.; Castro, P.S.; Gong, J.; Machado, M.C.; Moitra, S.; Ponda, S.S.; Wang, Z. Autonomous navigation of stratospheric balloons using reinforcement learning. Nature 2020, 588, 77–82. [Google Scholar] [CrossRef] [PubMed]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Outside Only [16] | 2-Stage [16] | IPL-Net |
|---|---|---|---|
| IoU | 90.9 | 91.1 | 91.7 |
| Methods | Number of Clicks | |
|---|---|---|
| PASCAL@85% | GrabCut@90% | |
| Graph cut [4] | >20 | >20 |
| Geodesic matting [8] | >20 | >20 |
| Random walker [7] | 16.1 | 15 |
| iFCN [9] | 8.7 | 7.5 |
| RIS-Net [10] | 5.7 | 6 |
| DEXTR [15] | 4 | 4 |
| IOG [16] | 3 | 3 |
| IPL-Net(ours) | 2 | 2 |
| Train | Test | IOG [16] | Ours |
|---|---|---|---|
| PASCAL-10k | COCO Mval | 81.9 | 81.3 |
| PASCAL-10k | COCO Mval(seen) | 81.7 | 81.3 |
| PASCAL-10k | COCO Mval(unseen) | 82.1 | 81.5 |
| PASCAL-10k | GrabCut | 96.3 | 95.9 |
| Pretrain Model | Train | Test | IOG [16] | Ours |
|---|---|---|---|---|
| PASCAL | PASCAL-1k | PASCAL | 92.0 | 90.5 |
| PASCAL_SBD | PASCAL-1k | PASCAL | 93.2 | 91.5 |
| PASCAL_SBD | PASCAL-10k | PASCAL | 93.2 | 91.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Zhang, G.; Qin, C. Automatic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation. Sensors 2021, 21, 6100. https://doi.org/10.3390/s21186100
Li G, Zhang G, Qin C. Automatic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation. Sensors. 2021; 21(18):6100. https://doi.org/10.3390/s21186100
Chicago/Turabian StyleLi, Guoqing, Guoping Zhang, and Chanchan Qin. 2021. "Automatic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation" Sensors 21, no. 18: 6100. https://doi.org/10.3390/s21186100
APA StyleLi, G., Zhang, G., & Qin, C. (2021). Automatic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation. Sensors, 21(18), 6100. https://doi.org/10.3390/s21186100