1. Introduction
The ultimate goal of science and engineering is to serve humanity and humans by creating ease in their daily lives. Robotics is an innovative engineering discipline that does so by automatically performing repetitive, laborious, and complex tasks, providing relief to humans. Recently, with the advancement in robotic technologies, the acceptance of robots in society has improved considerably, resulting in an increased human-robot interaction application [
1]. Large volumes of robots are not only brought into the industry, but are also introduced in dynamic environments that were originally designed for humans, such as in homes, schools, and hospitals [
2]. As these environments are dynamic in nature, such workplaces demand a high level of autonomy and dexterity, which needs to be developed in robots to perform their task autonomously [
3].
Vision is the fundamental sensor that humans use to perceive, adapt, and work in dynamic environments. Henceforth, robotic vision has emerged as the vital tool for robots to perceive the environment and acquire autonomy to perform their tasks in human-centric environments in human-robot interactions (HRIs) [
4].
One key area of HRI is providing care to patients, the elderly, and people with disabilities. Recently, assistive robotic arms (ARAs), a form of robotic assistive care have gained wide attention in the research community [
5]. ARAs for giving care to the patients and the elderly such as in [
4,
5] showed that assistive robotic arms are quite effective in providing support to the people with disabilities to recover most of their autonomy.
Many companies commercially developed ARAs such as
MANUS and
i-ARM by Exact dynamics (Netherlands), the
WAM arm by Barrett Technology (USA), and, the
JACO and
MICO series robotic arms by Kinova
® Robotics (Canada) [
6]. A comparative study of different assistive robotic arms platforms can be found in [
7]. Among these companies, Kinova
® robotics is the leading manufacturers of ARAs with more than 50% share in the market [
8].
In this paper, we discuss the integration of visual sensors in ARAs which plays a vital role in inducing autonomous behavior. We demonstrate how visual servo control in the direct Cartesian control mode is the preferred control scheme to implement on assistive robotic arms. We also note that assistive robotic arms are kinematically different from other robotic arms that use a hybrid mixed frame configuration for their operation. Hence, conventional visual servo controllers cannot be directly deployed on ARAs. Therefore, we explored the task space kinematics of a mixed frame assistive robotic arm and developed our mixed frame visual servo control framework, which led us to the novel development of the proposed mixed frame Jacobian and the mixed frame velocity. We successfully deployed an Adaptive proportional derivative (PD) image-based visual servoing (IBVS) controller on ARAs using their embodied mix frame kinematics while safeguarding its core functionality. Our work will induce autonomous behavior in ARAs and will inherently pave the way for implementing conventional visual servo controllers on ARAs.
Related Work: Autonomous Control Schemes for Assistive Robotic Arms
Various methods are well-documented in the literature to induce autonomous behavior in robotic arms such as picking and placing objects, assistive feeding, and sip and puff, which are frequently required activities of daily living (ADL). Several examples can be found in [
4,
5,
9].
ARAs are useful to user with disabilities, yet face one major challenge. Most ARAs still provide dull and non-intuitive interfaces to interact with the robotic arms and thus lacks the basic autonomy required to perform (ADL). Commonly, these devices provide a joystick control of ARAs with limited preset buttons, the use of force feedback and moving the joystick can be very imprecise with users suffering from muscular weakness, consequently, it is problematic to perform ADL, given the mere amount of autonomy in control of the robotic arm. Several studies were conducted showing user dissatisfaction towards the efforts, time, and expertise needed to control these ARAs such as work carried out by Campeau et al. (2018) [
10], and problems faced during joystick control are discussed by Beaudoin et al. (2018) [
11]. Ka et al. (2018) [
12] evaluated the user’s satisfaction using a joystick and semi-autonomous control for performing ADL.
To address this problem, several other interfaces were developed by researchers such as Poirier et al. (2019) [
13] who introduced voice-controlled ARAs in an open-loop fashion. However, the voice command technique did not decrease the time to perform a task as compared with joystick control. Kuhner et al. [
14] used deep learning techniques to develop brain signal computer interface (BCI) systems to control ARAs. Nevertheless, BCI methods need prior training with the user, and post and preconditioning of the signals to be used in real-time. A human user must wear detection leads which are not practical to wear all the time by the user. For the case of assistive feeding. Aronson et al., 2019 [
15] added autonomy to ARAs by integrating an eye gaze tracking system.
One good way of making robotic arms autonomous is to integrate visual sensors in ARAs, resultantly, robotic arms can see and interact with their environment autonomously. Jiang et al. [
16] developed a multimodal voice and, vision integrated system on a wheelchair-mounted robotic manipulator (WMRM). Law-Kam Cio et al. (2019) [
17], integrated a vision sensor to ARAs using two Kinect depth cameras, one to identify the user’s face, and another for guiding the robotic arm to grab an object using the look and move method, the application was promising; however we argue that the method was computationally expensive and also an abundance of hardware was mounted on the wheelchair by using two Kinect cameras on a wheelchair, which reduces the user autonomy and mobility of the wheelchair in narrow areas around the house. Therefore, we developed our system with minimal hardware using a single camera.
For developing autonomous control of ARAs, some researchers have developed their application in the robot operating system
ROS®-MOVE-IT® environment. Snoswell et al. (2018) [
18], developed a pick and place system on Kinova
® MOVO dual-arm robot using a Kinect vision sensor. We argue that using a generic robot controller with a robot kinematic model defined in a separate
URDF file, as was the case of [
19], will add complexity to the system and compromise the core functionality of the assistive robotic arm such as its safety features, singularities avoidance, and self-collision avoidance behavior during operation. We propose using a dedicated manufacturer-designed kinematic controller for operating the ARAs.
Most of the applications that we discussed in this section, uses a ‘look and move’ approach in an open-loop manner [
20], that is the positioning of the end-effector to a certain prescribed pose, learned through visual pose estimation methods of the desired object. Using an open-loop look and move method to position a robotic arm for probabilistic grasp may be an easier option to implement besides being computationally inexpensive. Nevertheless, it carries its shortcomings, for instance, measurements are made in an open-loop manner, hence the system becomes sensitive to uncertainties, such as a lack of positional accuracy of the robotic manipulator due to errors in the kinematic model of the robotic arm; internal errors such as wear, backlash, and other external reasons may such as, error in camera intrinsic parameters and extrinsic calibration, weak information of object 3D model, or if the object moved during the approach motion of the gripper. Hence, the reliability and accuracy of an open-loop look and move systems remain lesser than the visual servo feedback control systems [
20].
Generally, an ARA is designed to provide a coarse, wide range of assistance to the user, they are not an accurate positioning device as discussed in the work by Karuppiah et al. (2018) [
19]. Hence, their positional accuracy remains subpar to industrial manipulators, and thus position control cannot be solely depended upon to achieve the desired pose for grasping an object. Moreover, a major concern in ARAs and WMRM cases, is to ensure user and robotic arm’s safety [
21], while preference is given for performing tasks in the direct Cartesian control approach.
Naturally, ARAs are required to operate in the Cartesian task space of its end effector to complete ADL. Hence, modern ARAs and WMRM utilize 6 degrees of freedom (DOF) or preferably 7 DOF to perform ADL in direct Cartesian control, as also discussed by Herlant (2018) [
22]. Direct control is when the operator or control algorithm directly commands the position and orientation of the end effector in Cartesian space but does not explicitly specify the joint angles or velocity of each joint of the manipulator. The joint angles and joint velocities will be automatically determined by the robot controller. Hence, the direct Cartesian mode is an efficient control method for ARAs [
23].
Considering these constraints, an optimal way to design an autonomous ARAs vision control system is to complement it with a closed-loop visual servo control in direct Cartesian task space, which can immunize the system against positioning errors, inherently present in ARAs.
Visual servo control can be defined as the use of visual information to control the pose of the robot end-effector relative to a target object in a closed-loop visual feedback manner. Visual-servo control schemes are primarily divided into two different methods, one that realizes visual servo in a 3D operational space also called pose-based visual servo (PBVS), and another that realizes visual servo in the 2D image space, referred to as image-based visual servoing (IBVS) [
24], using a camera which may be mounted on the robotic arm as an eye-in-hand, or can be fixed in the workspace using an eye-to-hand configuration. Visual servo control literature can be found in [
25], recent work, and an update on the field can be seen in [
26].
During the literature review, we observed that researchers have not completely explored the potential of visual servo control to develop an autonomous ARAs system. An earlier attempt to utilize visual servo control with ARAs was performed by Kim et al. (2009) [
27], in which hybrid visual servo control was deployed on an assistive robotic arm, i-ARM, this study pioneered the concept of our approach to utilize visual servo control to operate an assistive robotic arm in Cartesian control mode. However, our case differs as the assistive robotic arm used in our study is a redundant manipulator designed to operate in a mixed frame configuration using an adaptive image-based visual servo controller using 2D features only, whereas the aforementioned case of i-ARM uses a stereo camera and, 2-1/2 visual servo control requiring a mix of 2D and depth features, also it does not take into account safety features and self-collision avoidance behavior, which is implicitly ensured in our proposed framework. In a later work performed by Tsai et al. (2017) [
28], a joint space visual servo control was developed in the IBVS scheme. However, in that work, research was not aimed at assistive robotic arms, rather it tested a light field camera model for image capturing, and an under-actuated 4 DOF Kinova
® MICO robotic arm was used, which cannot realize 6D Cartesian motion; thus, necessitating the use of a joint control scheme.
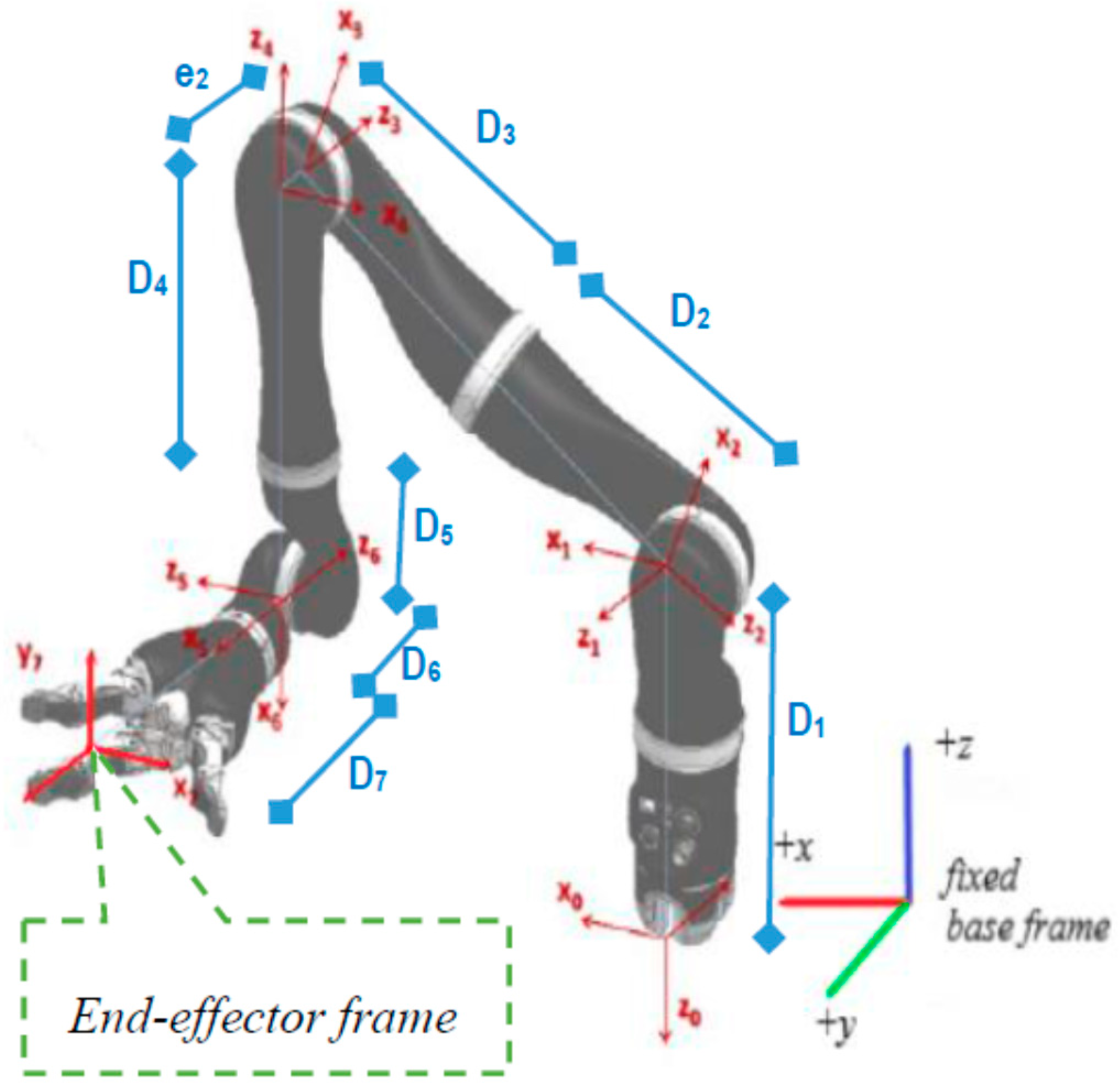
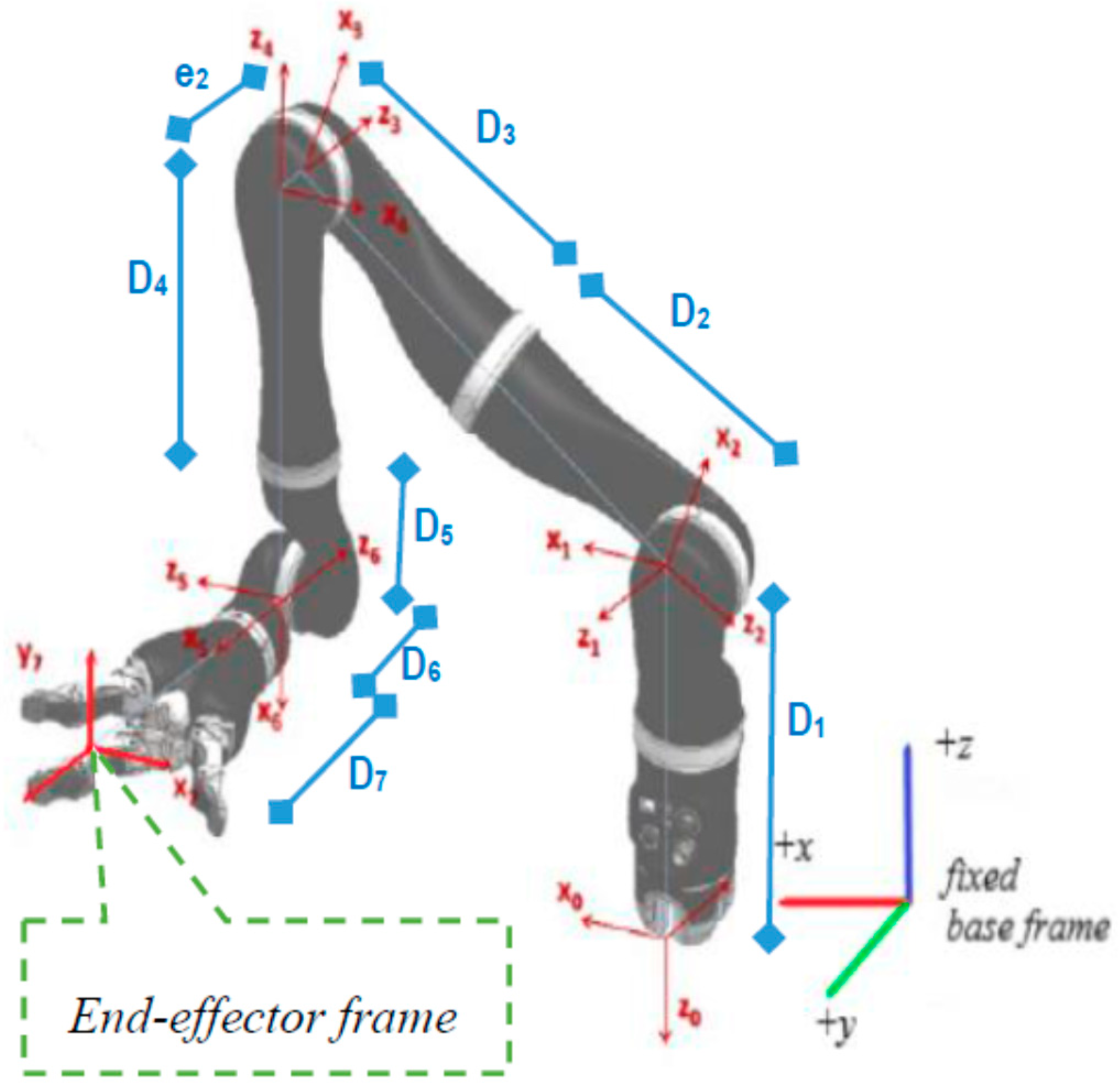
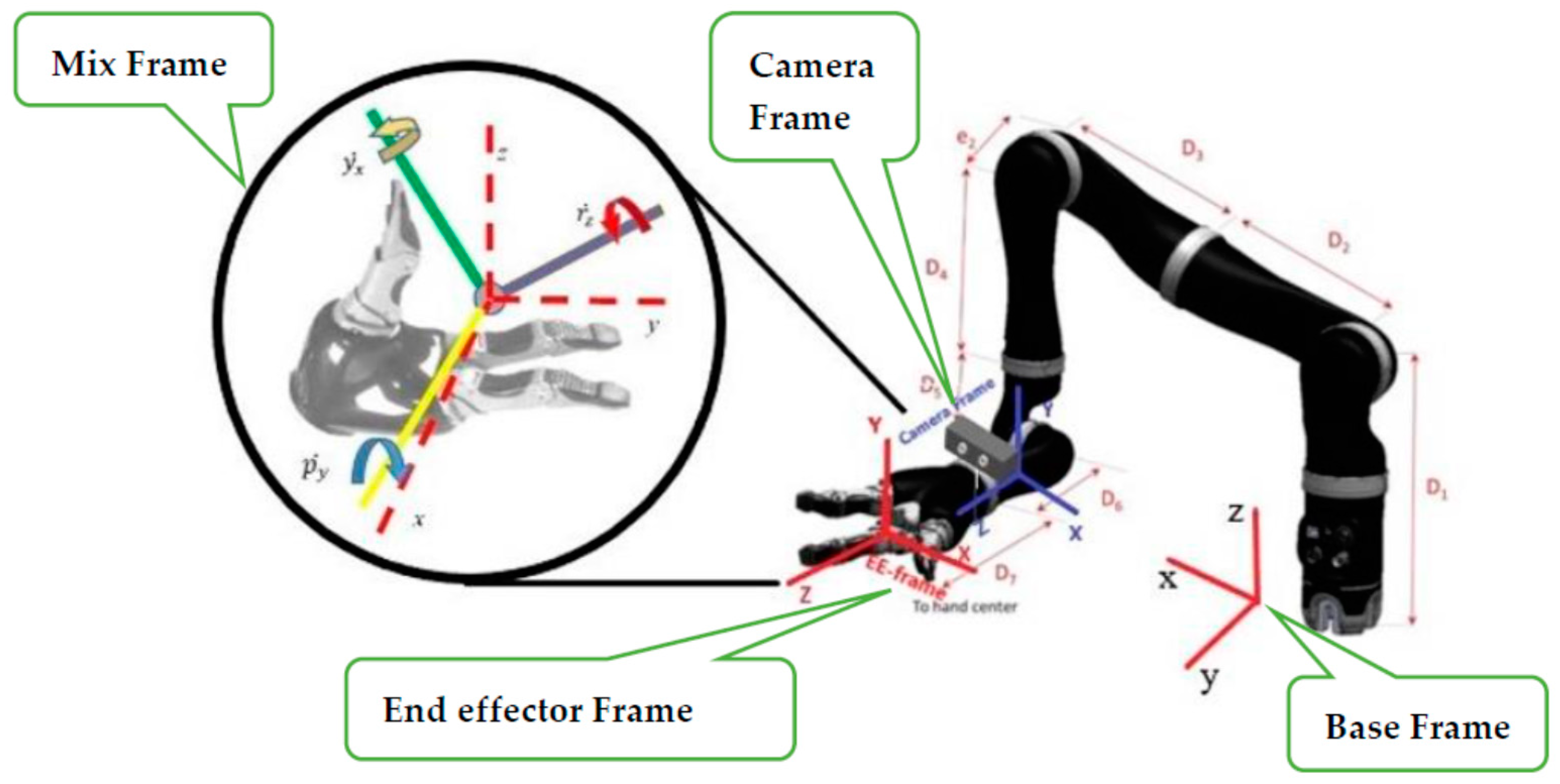
Mix frame robotic arms are designed to operate in an arbitrary hybrid mixed frame task space, where the end-effector position and velocity cannot be directly controlled in the end-effector frame or the base frame, rather the position of the end effector is defined in a mixed frame of reference, i.e., fixed base frame for positioning of the end effector, while the orientation is expressed as the Euler angles in the end-effector frame, as shown in
Figure 1 and further discussed in
Section 2. After an extensive literature review and to the best of the author’s knowledge, a formal account of the kinematics of a mixed-frame robotic arm could not be found in the literature. Therefore, the use of a mixed frame configuration in ARAs poses a major problem, which restricts the use of several mainstream control laws on mixed-frame robots. Concluding our literature review. We indicated an important problem about the absence of a visual servo control scheme for a mixed frame ARA. In pursuit of a solution, we developed a mixed frame visual servo control framework for an assistive robotic arm to devise an autonomous approach movement for picking up an object, using an adaptive gain proportional derivative image-based controller, directly controlled in the Cartesian task space. The performance is compared with the joint control scheme developed for ARAs. the experimental results showed the superiority of our proposed framework in all traits. We also developed an open-source
ViSP library class for interfacing and controlling Kinova
® JACO-2 robots with
ViSP® [
29], which is a well-known library for vision and control.
To the best of the author’s knowledge and belief, this is the first instance of work to describe a visual servo control law in a mixed frame configuration for ARAs such as the Kinova
® JACO-2. The rest of this paper is organized as follows:
Section 2 formulates the task space kinematics and develops a novel mix frame Jacobian for mix frame ARAs,
Section 3 develops a mixed frame image-based visual servo control framework,
Section 4 describes the experimental implementation on a real 7 DOF robotic arm and discussion on the results, and
Section 5 provides the conclusion of this paper.
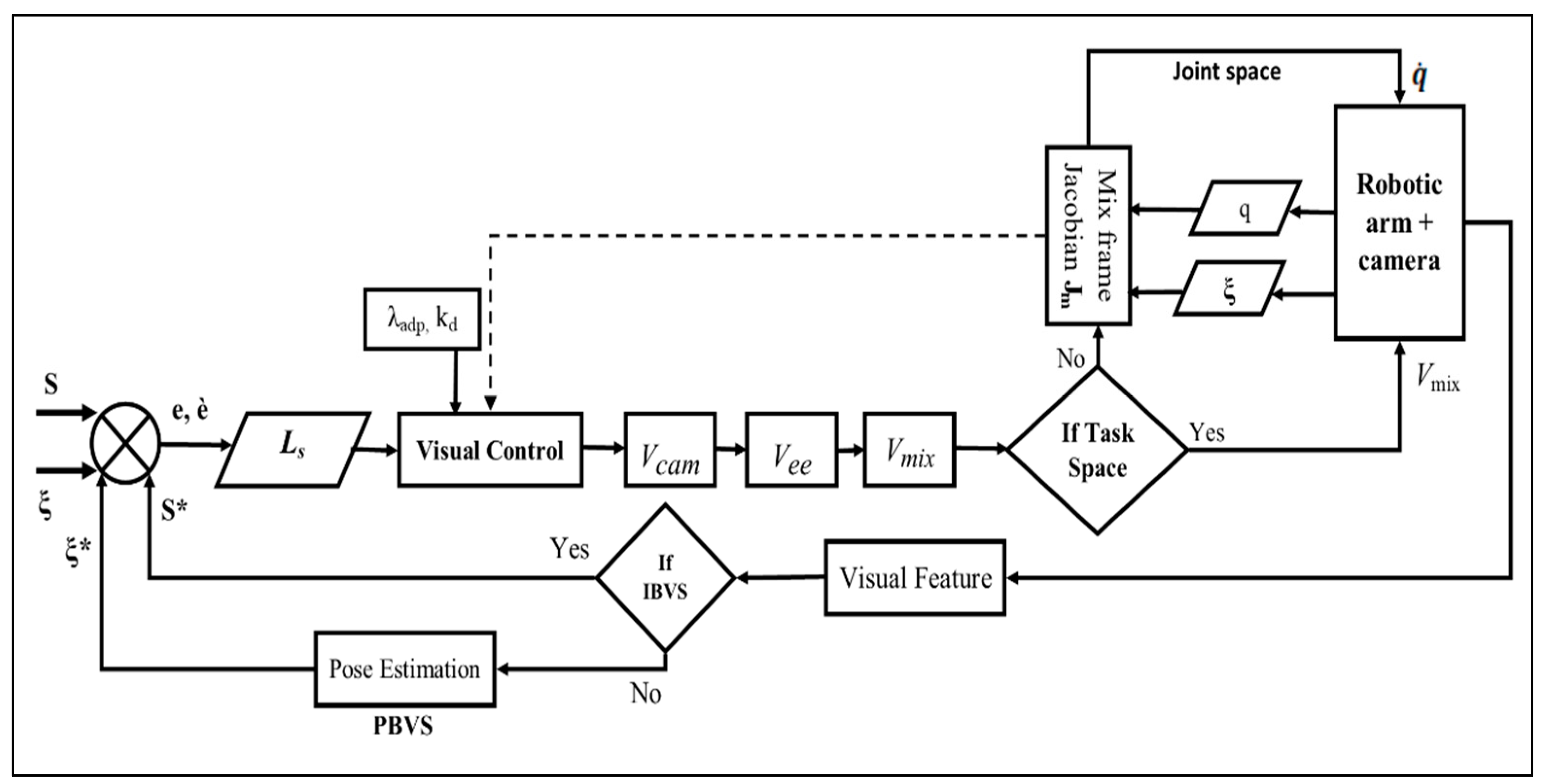
3. Mixed-Frame Visual Servo Control Framework
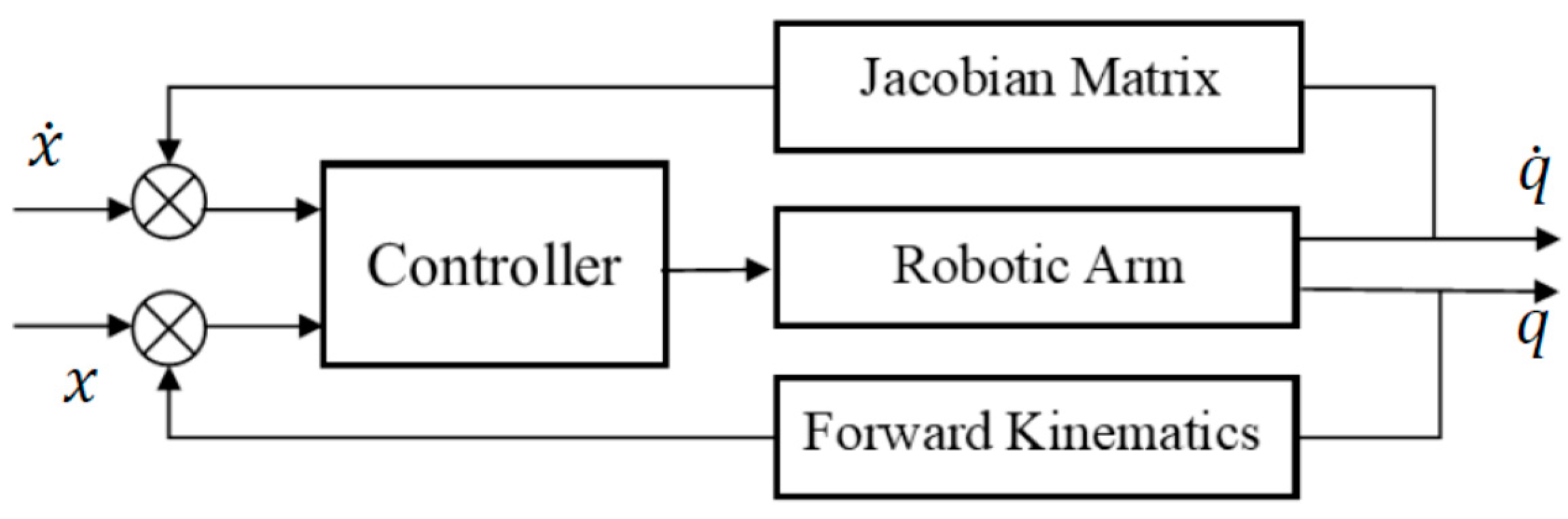
In this section, we shall design a framework for deploying a visual servo control law for assistive robotic arms in a mixed frame direct Cartesian control. The proposed framework as depicted in the block diagram of
Figure 4 is not constrained by the type of visual servo control scheme, that is IBVS, PBVS, or
2-1/2 D control schemes can also be used within the framework for operating mixed frame ARAs.
Primarily, we begin with image-based visual servoing, also called 2D visual servoing. IBVS is based on the selection of a set
of the image’s visual features that need to reach the desired value
in the image plane. The task is to derive the selected features and related error in the image plane to zero, the error
, which is typically defined by:
The control schemes use the image-plane coordinate of a set of points (other features line, centroid, etc., can also be used) [
25] to define the set of visual features
. Where
are the coordinates of the image point represented in pixel units, and the camera intrinsic parameter is given by
to convert pixels into meters using the
ViSP camera projection model [
24].
As a standard practice, we avoid singularities in the image interaction matrix. Let us consider a set of 4 co-planer, non-linear points P
n = (X, Y, Z) as image features,
such that each point in the image plane is given by
and
is the desired image coordinates, in our case we used camera calibration parameters and geometry of target, to compute the desired image feature values of any specified goal pose [
42]. The spatial velocity of the camera is denoted by,
with
the instantaneous linear velocity of the origin of the camera frame and
the instantaneous angular velocity of the camera frame. The relation between the rate of change in image features error and camera velocity can be given as:
where the interaction matrix between camera velocity and feature error
is given by [
24] as:
In cases where visual servo control law is required to operate in joint space and angular velocities are required as input velocities to the robot controller, using a mix frame task Jacobian approach, the articular velocity
of the robotic arm can be calculated by [
36]:
where
is the end-effector frame Jacobian,
is the approximation of the interaction matrix which can be formed using constant the goal frame or varying current frame Jacobian approximation technique,
is a 6 × n motion transformation matrix to convert from end-effector frame to the camera frame,
is the task feature error and the projector operator
deals with secondary tasks such as avoiding joint limit, singularities, and self-collision avoidance [
41]. Now for the mixed frame configuration Equation (17) can be rearranged as Equation (18), where
is the mixed frame Jacobian from Equation (10) and
is the transformation matrix from the mixed frame to the camera frame.
However, in this work, we are interested in producing a visual servo control law that produces Cartesian task space velocities in the mixed frame. Therefore, we will be considering the control law in direct Cartesian velocity control and deal with proportional error decay and moving target compensation given by [
36] as:
where in Equation (19),
is a real-valued positive decay factor as a constant gain,
is the pseudo-inverse of the approximation of the interaction matrix and
is the image feature error to regulate, where the term
expresses the time variation in error approximation due to the target motion for the case of a non-static target, here
∈ R
(6×k) is chosen as the Moore–Penrose pseudo-inverse of the approximation of
such that
, when
is of full rank, i.e., feature points k ≥ 6 and
, this ensures the Cartesian space velocity to be minimal in the task space. There are several choices available for estimating the depth ‘Z’ of the image point for constructing the
. We used the current visual feature depth approach for approximating the interaction matrix as described in [
24].
3.1. Adaptive Proportional Derivative IBVS Controller
A better control law can be adopted for the system in consideration, as only a simple proportional controller is not able to minimize error with a high convergence rate to the desired low norm error. The proportional controller has a known problem of residual steady-state error or local minima convergence during visual servoing, also it has a large overshoot problem for high proportional gain, for achieving a faster rate of convergence in the time domain. Therefore, combining the proportional law with a derivative controller, which can work on the rate of change in error function would certainly help in decreasing the overshoots and decreasing the settling time [
43,
44].
Another problem that we encountered during the execution of IBVS control on the Kinova® JACO-2 robotic arm in direct Cartesian control mode was, slow or no movement near the task convergence zone, as it does not move for minimal Cartesian velocities computed by the control law near convergence zone.
Therefore, the control law in Equation (19) can be further improved by taking into account an adaptive gain visual servo controller. In practice, we want our adaptive controller to produce nominal camera velocities when the task error is significant. On the other hand, a large gain value is needed when our feature error is in the convergence zone since camera velocities produced by a constant gain controller were not sufficient to converge the task as it may be stuck in local minima and not have fast decay response. We needed a larger value of gain near the convergence zone to produce higher camera velocities to achieve the task convergence rapidly.
While designing an adaptive gain for the controller, we shall rely on the task’s inherent infinity norm. Considering a range of gain values tuned between two different peak gain values, one for the case when feature error is very large, near infinity, where already camera velocities are higher. Another one for the case, where the image feature error is near zero in the convergence zone and the camera velocity is very small. For ensuring this behavior, we can replace the constant gain term with an adaptive gain as developed in [
45]:
where,
is the infinity norm of the feature error vector.
is the gain in 0 for very small values of .
, is the gain to infinity, that is for very high values of .
is the slope of at .
IBVS velocity controller in Equation (19) can be updated using a proportional derivative adaptive gain controller to move the current feature points towards desired image points by moving the end-effector mounted camera with a Cartesian task space velocity given by:
where
is the adaptive proportional gain,
is the derivative control gain and both are symmetric positive gain matrix of appropriate dimensions,
is the change in feature error due to eye-in-hand camera motion at each iteration of the control cycle.
The problem of residual error can also be improved using an adaptive gain proportional derivative controller, where the gain values were adapted from the visual feature error norm and the gain was continuously tuned to achieve a low constant zero error. The Euclidean error norm was calculated from the visual features error vector, where a Euclidean error norm of 0.00005 m in the image plane was used as a convergence threshold for successful IBVS task achievement.
The usage of an adaptive gain proportional derivative controller Equation (21) rather than a constant gain proportional controller for visual servo control law in Equation (19) will result in a better performance of the controller, for avoiding local minima and, a reduction in convergence time is observed in the experimental results in
Section 4.
3.2. Mixed Frame Visual Servoing
The image-based visual servo control law derived in Equation (21) will ensure an exponential decoupled decrease in the image feature error by producing a minimum norm Cartesian velocity
, in the camera frame for the eye-in-hand manipulator which needs to be implemented in the mixed frame configuration. For most practical applications, the camera is usually mounted on an end effector with a constant transformation as shown in
Figure 5, which can be obtained through camera extrinsic calibration [
29].
Therefore, camera velocities should be transformed to end-effector velocities
by using a constant spatial motion transformation matrix.
where:
is a 6 × 6 spatial motion transformation matrix as a function of camera pose w.r.t end effector. Where
is a 3 × 3 rotation matrix from the camera frame to the end-effector frame and
is the skew-symmetric matrix of the camera frame translation vector [
25]. This motion transformation matrix converts the camera frame velocity to an equivalent spatial velocity
which can be applied in the end-effector frame to ensure camera motion as computed by visual servo control law.
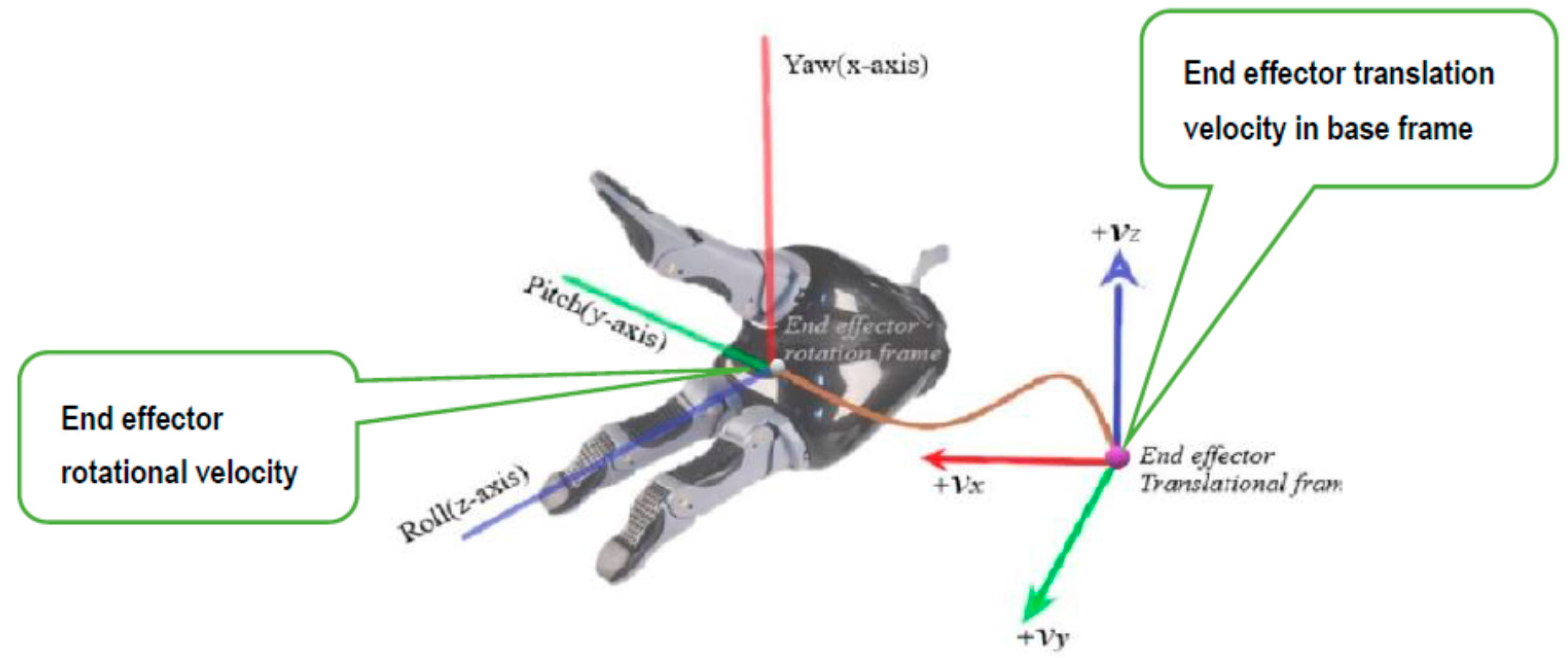
The velocity vector
obtained in Equation (22) provides the velocity of the end-effector frame w.r.t end-effector body frame. This is the end-effector velocity conventionally used as input to the controller for materializing image-based control in industrial robotic arms. However, for an ARAs operating in a mixed frame, this end-effector velocity was not applicable and should be converted to mix frame velocity
, i.e., translation velocity w.r.t fixed base frame and rotation velocity in the end-effector body frame as the rate of change in roll, pitch, and yaw angles as shown in
Figure 6.
For converting this end-effector velocity into the desired mix frame velocity, first, we can convert end-effector velocity to the base frame using a rotation matrix
which can be obtained by the pose of the end-effector w.r.t base frame.
where,
is a 6 × 6 spatial motion transformation matrix as a function of end-effector pose w.r.t base frame.
The rotational component of the end-effector velocity vector
is still in the angular velocity form. Whereas, for the input to the robot controller, we need a velocity vector expressed as the rate of change in Euler angles of the end-effector frame. Hence, using the relationship developed in
Section 2 Equation (12) for transforming angular velocity to the task space velocity expressed as the rate of change in Euler angles, we have
comparing with Equation (22) and solving for the rotational velocity
.
Equation (24) shows the relation between angular velocity and the rate of change in roll, pitch and yaw angles of the end effector, where
,
r = roll angle,
p = pitch angle, and
y = yaw angle of the end-effector frame. Recall from Equation (12):
Now, we can combine the translational vector from base frame velocity vector, and rotational velocity vector expressed as the rate of change in roll, pitch and yaw angles of the end effector, to form a 6 × 1 spatial mix frame velocity vector; Concisely by combining Equations (22) and (24), we can form a single transformation matrix to transform
in the desired mix frame velocity
:
where:
is a 6 × 6 spatial motion transformation matrix, is the 3 × 3 rotation matrix from the end-effector to the base frame, and is the transformation from angular velocity to the rate of change in the end-effector Euler angles. The motion transformation matrix in Equation (25) converts the end-effector frame velocity to an equivalent mix frame velocity .
in Equation (25) is the desired mix frame velocity as proposed in this paper, i.e., the end effector’s translation velocity in base frame and rotation velocity expressed as a rate of change in Euler angles of the end-effector frame. is constructed through the Cartesian task space camera velocity using Equation (21), needed to converge the IBVS control law. is the minimum norm velocity for a robotic arm end effector due to the use of the pseudo-inverse method in Equation (21). Hence, from Equation (25) can be directly fed to the robot high-level controller to operate the end effector in the Cartesian velocity mode for the desired visual servo control.
Moreover, if a joint control scheme is required while remaining within the framework, one can utilize the developments made in
Section 2. Robot-controllers can utilize a mixed frame velocity
for visual servoing from Equation (25) and mix frame task Jacobian
developed in Equation (10), to compute the required joint velocity
. To implement visual servoing in joint space using mix frame velocity we obtain:
where
is the mixed frame task Jacobian,
is a Moore–Penrose (M-P) pseudoinverse of
, I is the identity matrix, and ξ is an arbitrary secondary task vector that can be designed to avoid singularities and joint limits by following the developments in [
41,
46].
Equation (26) will compute a joint velocity vector with a minimum norm, it implicitly ensures the implementation of required Cartesian velocity in the camera frame and also satisfies the joint limits and singularity avoidance behavior for successfully performing the visual servoing task.
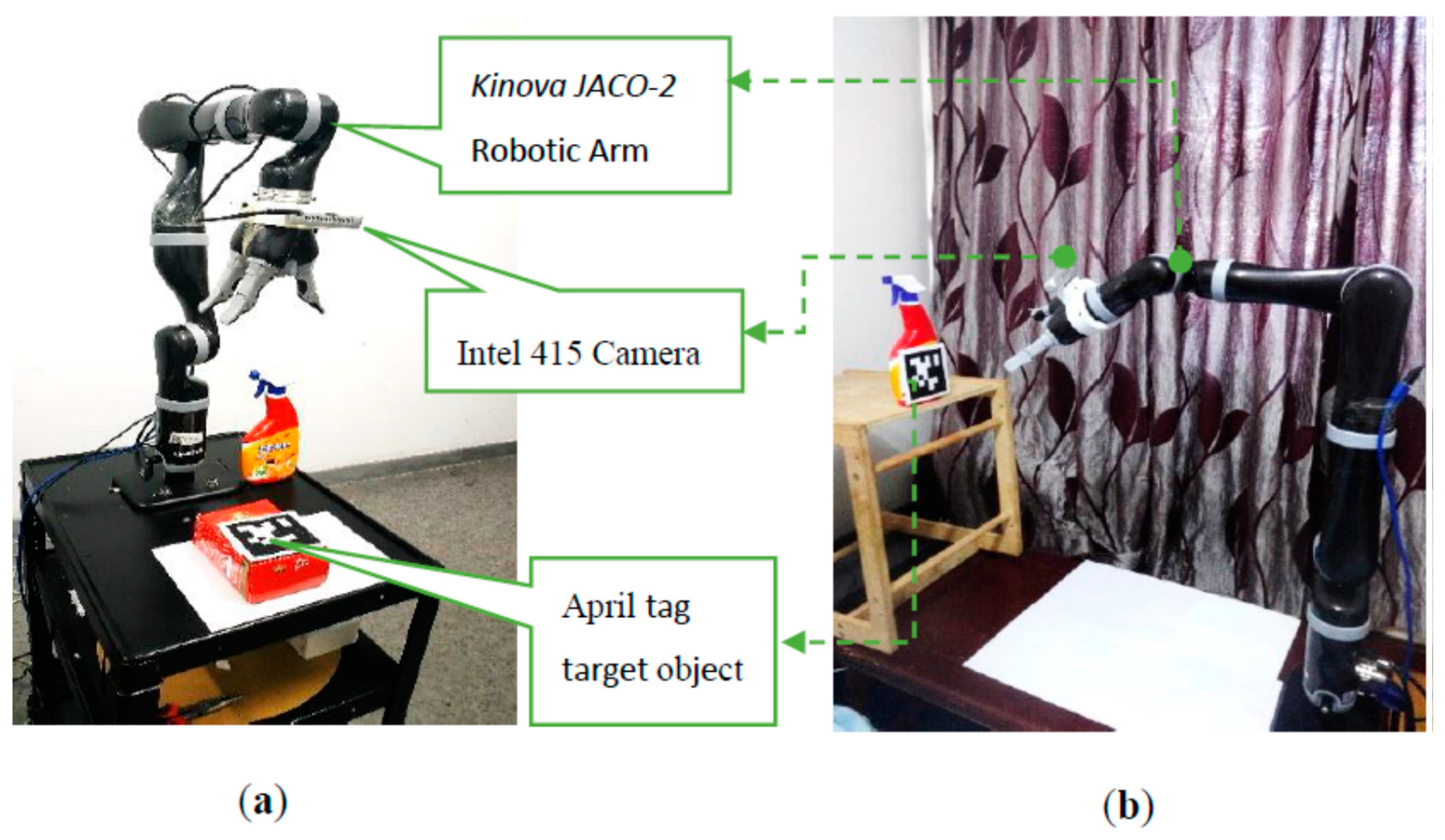
4. Experiment & Results
To evaluate our proposed mix frame visual servo control framework, developed in
Section 3, experiments were conducted to achieve an IBVS task with a mixed frame 7 DOF Kinova
® JACO-2 Assistive robotic arm, an
Intel RGB-D415 camera in the eye-in-hand configuration and, an April tag [
42] target was utilized as shown in the
Figure 7, Experimental setup and results are presented in this section.
A
JACO-2 robotic arm from Kinova
® Robotics was selected for the experiments, which is a serial-link stationery, mixed-frame, 7 DOF, spherical wrist ARA. To make the experiment robust to the lighting conditions and evaluate its performance in an unstructured environment, our experiment was conducted under the lab and home environment as shown in
Figure 7a,b. Kinova JACO-2 was operated in a mixed frame configuration to perform image-based visual servo control. An
Intel RGB-D 415 camera was mounted on the robotic arm’s gripper in the eye-in-hand configuration with a constant pose transformation, which can be calculated offline by camera intrinsic and extrinsic calibration by using the Visual Servoing Platform
ViSP® library [
47]. Nevertheless, considering the robustness of IBVS towards camera calibration errors, a coarse estimation will also work.
The program was executed on a desktop PC using an
Intel Core-i5-8500 CPU with 8GB of RAM, and graphic processing was rendered by a 6 GB
NVidia graphic card. We noticed that without having a good GPU for the image processing part, the overall program performance becomes sluggish, resulting in longer convergence times, and sometimes visual feature detection failure may occur. The program was developed using C++,
Visual Studio 2017,
OpenCV, and the Visual Servoing Platform
ViSP library [
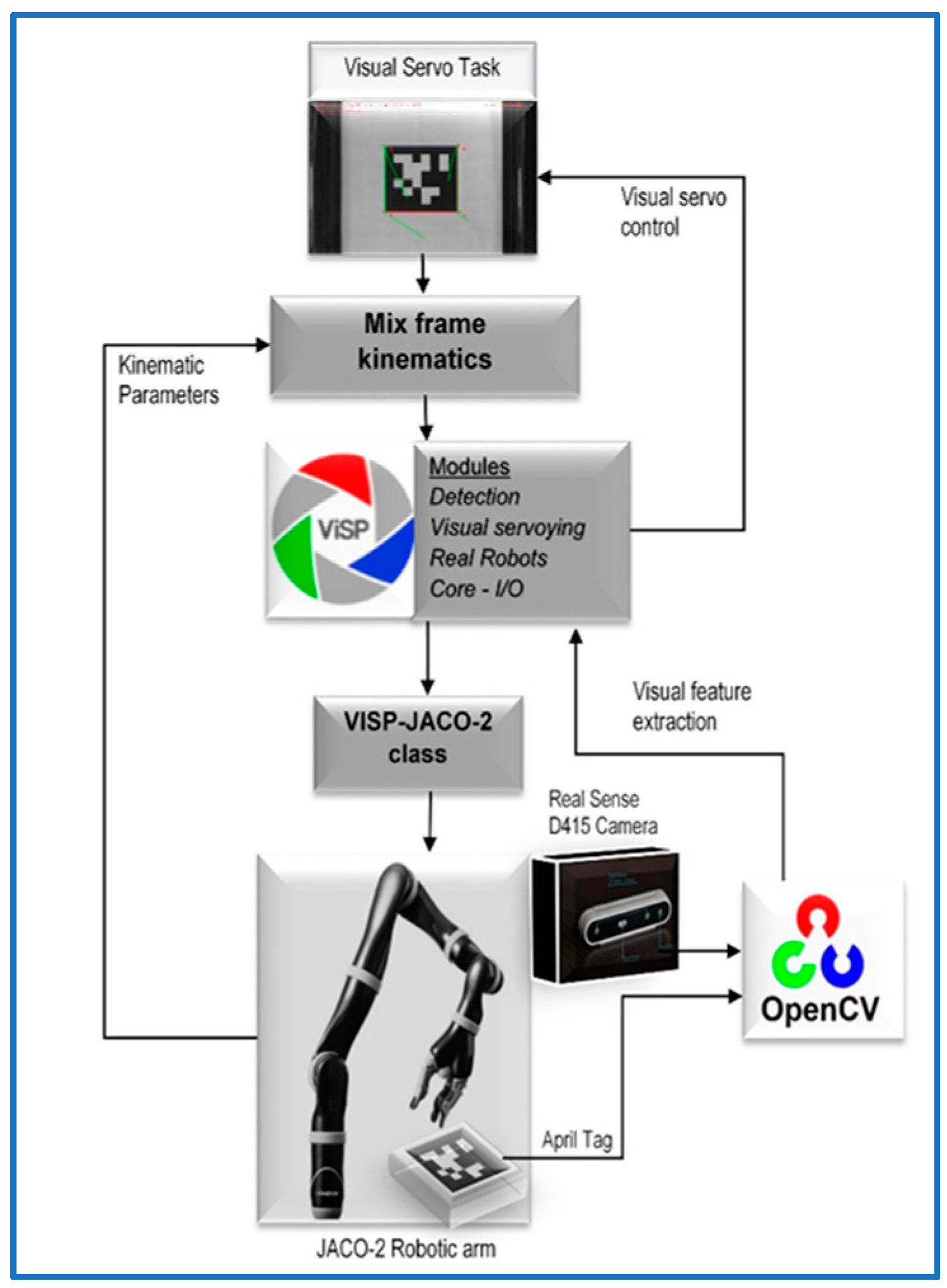
47]. A flowchart of the experiment is shown in
Figure 8.
While making this
ViSP work with the Kinova
® JACO-2 robotic arm, we developed a new class for
ViSP library interfacing the Kinova
® robotic arm, namely ‘
ViSP-JACO-2’ with mix frame configuration, it is a much-needed addition in
ViSP which was not available earlier in the
ViSP library. It is our major open-source code contribution in the
ViSP library which is also acknowledged on the
ViSP developer’s webpage [
48] and freely available for use at our GitHub repository [
49].
The experiment was divided into sub-parts, A, B, C, and D; where each sub experiment was aimed to investigate a specific aspect of our proposed framework.
In Part-A of this experiment, the need for the mixed frame visual servo control framework was established. This experiment describes a conventional IBVS control scheme in the end effector frame, was deployed on a Kinova
® JACO-2 ARA in Cartesian control mode using Kinova
®-API high-level controller [
33], without the use of the mixed frame control framework.
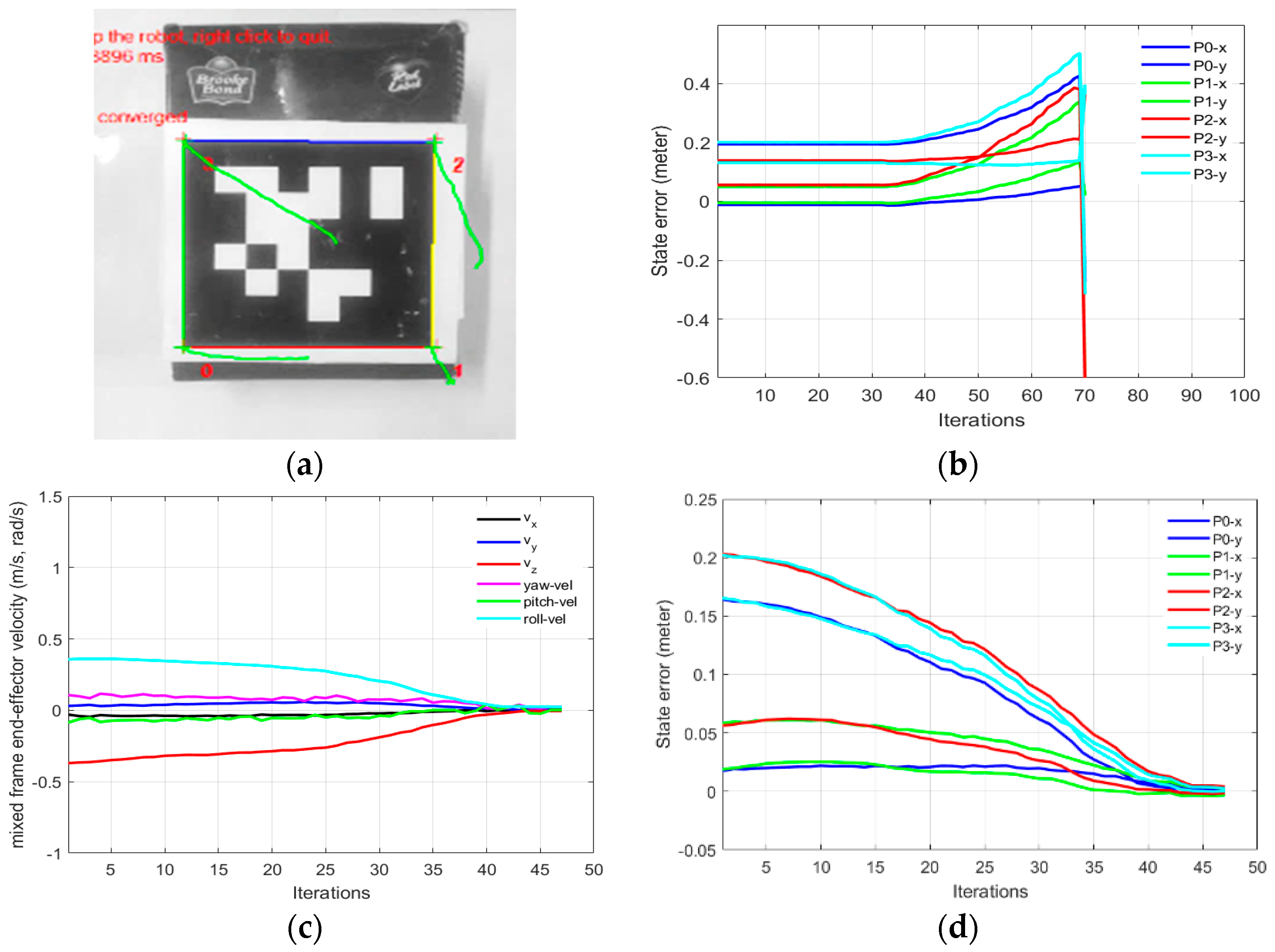
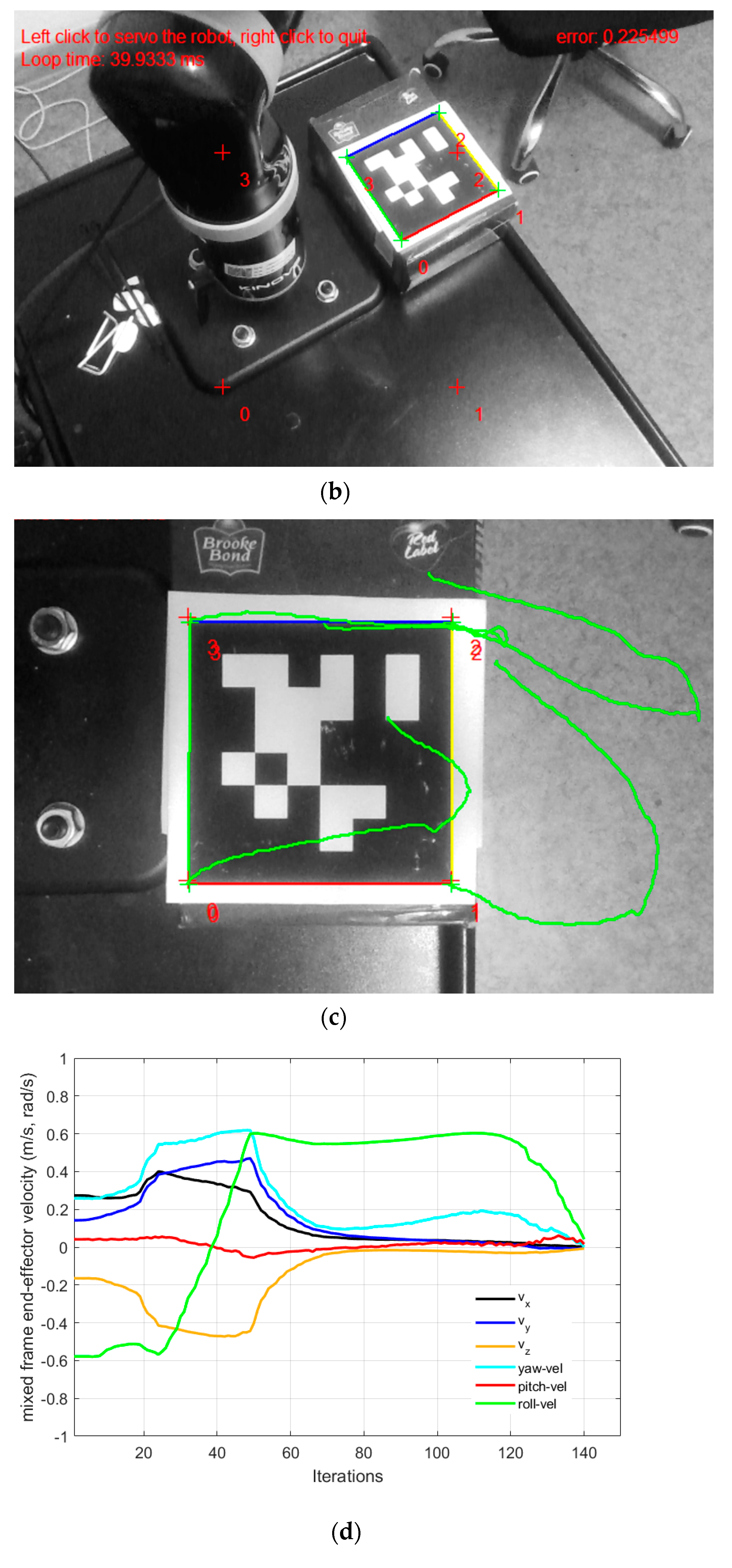
Table 2 shows the initial and the desired feature values of the four corner points of the April tag, used as the visual features for the IBVS as shown in
Figure 7. The results are given in
Figure 9. While, using the conventional end effector frame configuration for deploying IBVS, the robotic arm rapidly diverges from the task as shown in
Figure 9b [see
video results-V1], which clearly indicates the need for the development of a mixed frame velocity framework. In Part-A, although the camera velocity Vc, calculated in the camera body frame was converted to the end-effector frame using Equation (22), which is acceptable by industrial robotic arms, it was not compatible with the Kinova
® ARA controller that requires velocity in the mixed frame as discussed in
Section 3. Therefore, the visual task does not converge and the end effector diverges from the target as seen in
Figure 9b, eventually, features leave the camera field of view (
video results attached). The visual servo task was failed because the output was Cartesian velocities in the end effector; however, the desired output required by the controller should be in the mixed frame. This was a confusing result for researchers working on the development of visual servo control of assistive mixed frame robots such as Kinova
® JACO-2, that the robotic arm was not accepting the Cartesian velocities in the end-effector frame.
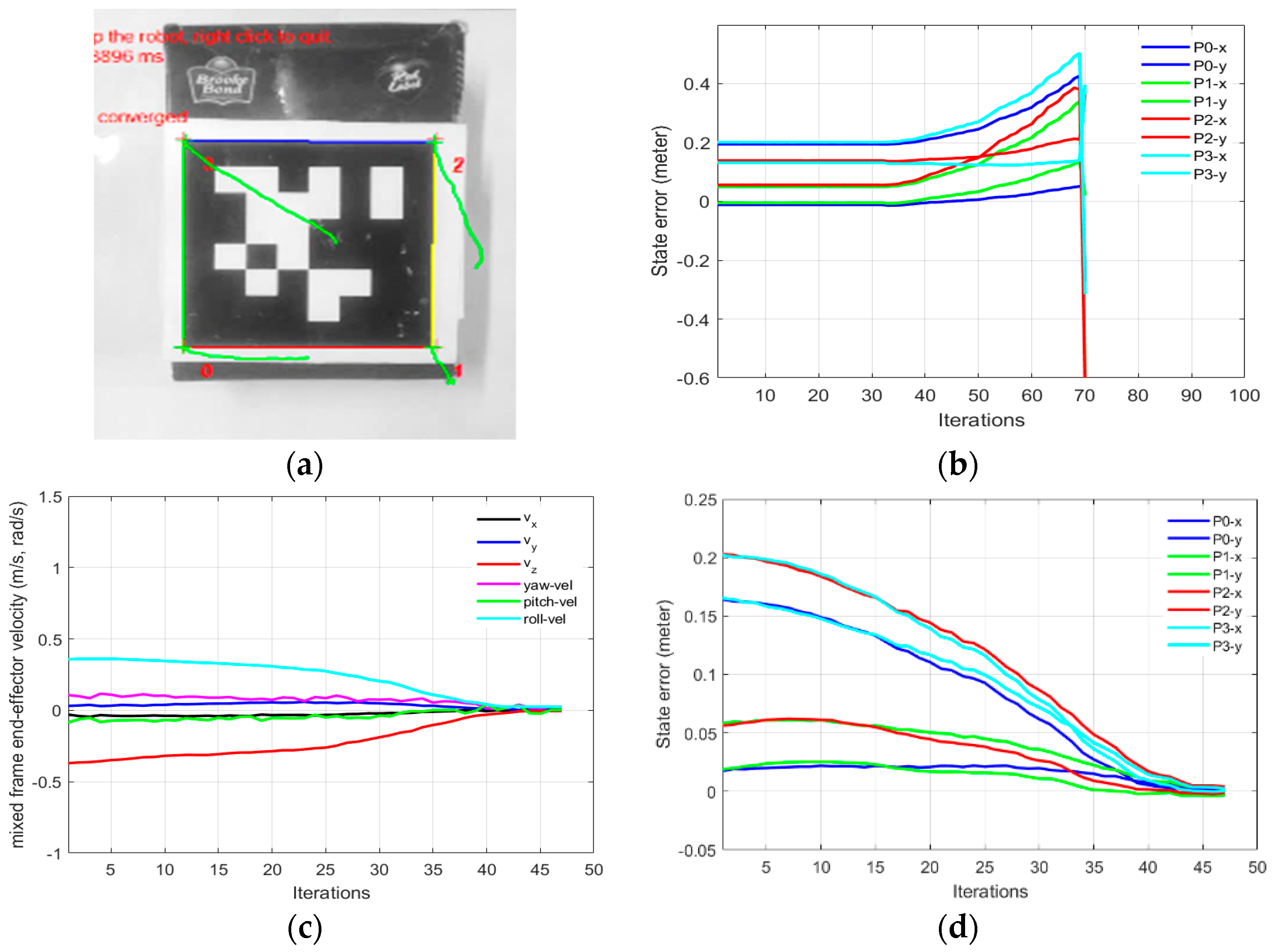
In part 1-B of this experiment, using our proposed mix frame visual servo controller, the correct mixed frame Cartesian velocities were applied to the controller of the robotic arm, i.e., translation velocities
in base frame and
in the end-effector frame. Results are shown in
Figure 9 which demonstrates a successful visual servo control task with sub-millimeter accuracy [see
video results-V2]. The visual feature error decay in
Figure 9d was fast and smooth. Mixed frame Cartesian velocities were within the maximum velocity limits and converge smoothly as shown in
Figure 9c. The initial and desired feature points are shown in
Figure 9a where the feature trajectory is almost a straight line. The convergence rate is fast and no overshoots are observed, thanks to the use of an adaptive gain P-D controller which took only 47 iterations to converge to an Euclidean error norm of 0.00005 m.
This paper aims to develop an effective IBVS control scheme for the mixed frame ARAs; therefore, we only discuss the relevant design details of a mixed frame adaptive gain PD Cartesian IBVS controller whereas the optimization and a comparison of PID schemes are beyond the scope of this paper. Yet, we briefly present our findings for ARAs comparing the proposed Cartesian mixed frame velocity controller to a joint controller with a constant gain, adaptive proportional gain, and an adaptive proportional derivative controller. For experiment -1, we present a comparison of the mixed frame Cartesian and joint control scheme for ARAs for an IBVS task in
Figure 10 and
Table 3.
Table 3 summarizes the effect of adaptive gain values on the convergence rate of the task. Starting with a conventional constant gain
P joint velocity controller using Equation (18) which converged slowly in 446 iterations.
While using an adaptive gain using Equation (20) and a P joint controller, the convergence rate was increased with a significant decrease in the number of iterations from 446 to 189, this controller was further improved by introducing adaptive gain PD controller and, thus allowing a larger adaptive gain value, resultantly convergence iterations were further reduced to 114.
Increasing gains beyond this point for a joint controller would yield a curve trajectory of the features in the image plane. Taking 114 iterations as a yardstick for comparing our proposed controller with a joint control scheme, a mixed frame Cartesian velocity adaptive gain PD controller using Equation (21) in Equation (25), when deployed on the same task, it converges smoothly in 79 iterations with a substantial increase in the convergence rate by 31% compared with the PD joint controller as shown in
Figure 10. This shows the efficiency of our proposed framework compared with the established joint controller.
Generally, while handling end effectors in the Cartesian control mode during conventional IBVS schemes, the manipulator became susceptible to joint limits and kinematic singularities. However, our proposed mix frame IBVS Cartesian control framework for mixed frame ARAs is capable of demonstrating deterrence towards joint limits avoidance and singularity occurrence and is also capable of successfully achieving visual tasks under complex situations.
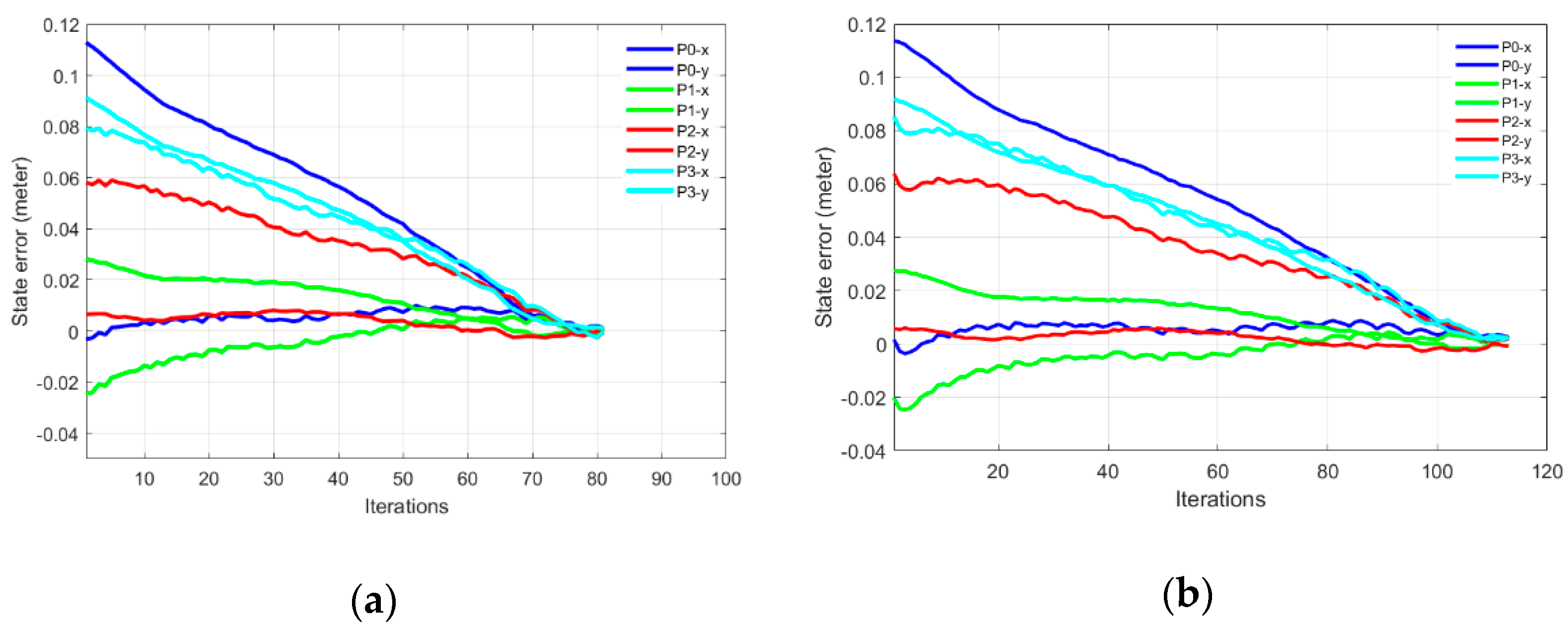
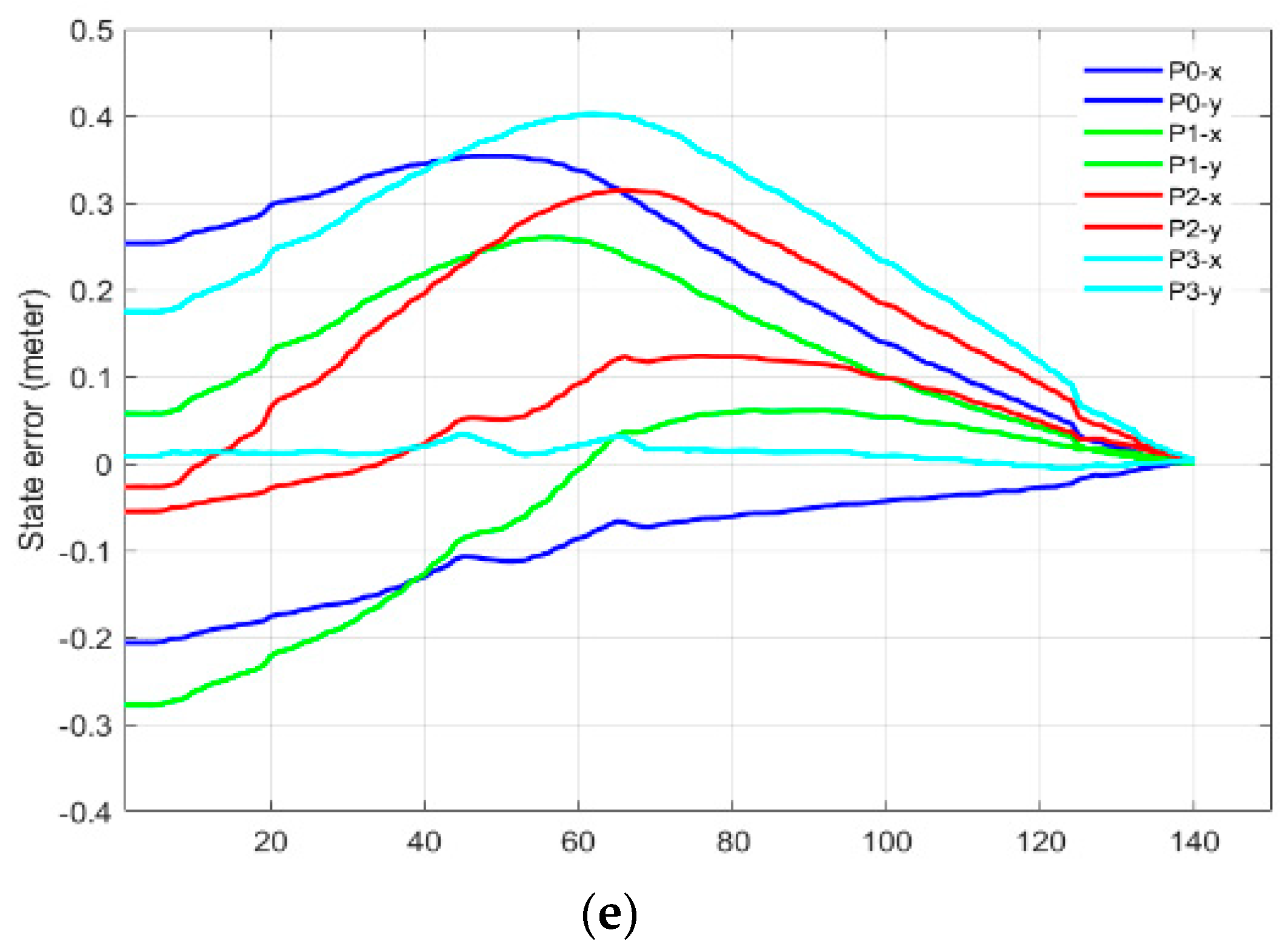
This behavior of singularity avoidance is prominent in Part-B of this experiment where the task was defined in the extended arm positions near the boundary of the working envelope of the robotic arm.
Figure 11a,b shows the initial and desired pose of the IBVS task,
Figure 11c,d shows the initial, the desired feature points and the visual feature trajectory for mix frame Cartesian control.
Figure 11e,f shows the feature errors for the mixed frame and joint velocity cases.
The effect of singularity and joint limit occurrence can be observed in
Figure 11e–g near the 25th iteration where the arm is struggling to keep its shape in the outstretched position while performing visual servoing [see
video results-V3]. Resultantly abrupt changes in joint velocities occurred that leads to the task failure in the conventional joint controller. Whereas the same task was successfully handled by the proposed controller for the arm outstretched position as shown in
Figure 11f,h, where smooth decay of feature error can be observed [see
video results-V4, V5, V6]. Thanks to the use of task space end-effector mixed frame velocity controller so the joint limits and singularity avoidance behavior were inherently taken care of, by the robotic arm’s controller.
In part-C of this experiment, the IBVS task was completed successfully near the base frame. Starting from an initial pose where the self-collision of the arm is expected during the visual servoing as shown in
Figure 12a,b. Nevertheless, our proposed mix frame visual servo controller in the Cartesian control mode successfully achieved this IBVS task without stopping or colliding with the robotic arm, rather it glides over the safety zone defined near the base of the robotic arm as seen in feature trajectory
Figure 12c,d [see
video results-V7]. Please note points 0 and 3 cannot be derived in a straight line towards the target features, if they do, it would collide with the end effector in the base of the robotic arm, therefore the controller forced the image points to travel away from the base frame avoiding to come near the body of the robotic arm, which forced the image points to take a curved route to their desired feature position, as can be observed in
Figure 12c. The results in
Figure 12 show the visual features trajectory, feature error decay, and the mix frame velocity for this part of the experiment.
As shown in part-B and part C of this experiment in
Figure 11 and
Figure 12, while operating the arm in the outstretched condition and near the base frame, where the robotic arm was suspected for singularities, joint limits and self-collision. Our proposed mix frame IBVS controller was capable of demonstrating deterrence towards joint limits, singularities, and self-collision problems and successfully achieved visual tasks under complex situations thanks to the use of Kinova
® ARAs low-level controller’s inherent ability [
30,
35] to avoid these constraints when operated in the mixed frame Cartesian velocity control mode. We achieved this behavior without the use of an external singularity avoidance and joint limits algorithm, which needs to be implemented otherwise as a secondary task, if used in conjunction with a joint controller [
37,
41]. For generic robotic arms, these features can be separately included in the framework following the developments made in [
46,
50].
After repetitive trials, none of the experiments had failed due to joint limits, kinematic singularity, or self-collision occurrence in the manipulator, which shows the robustness of our proposed framework.
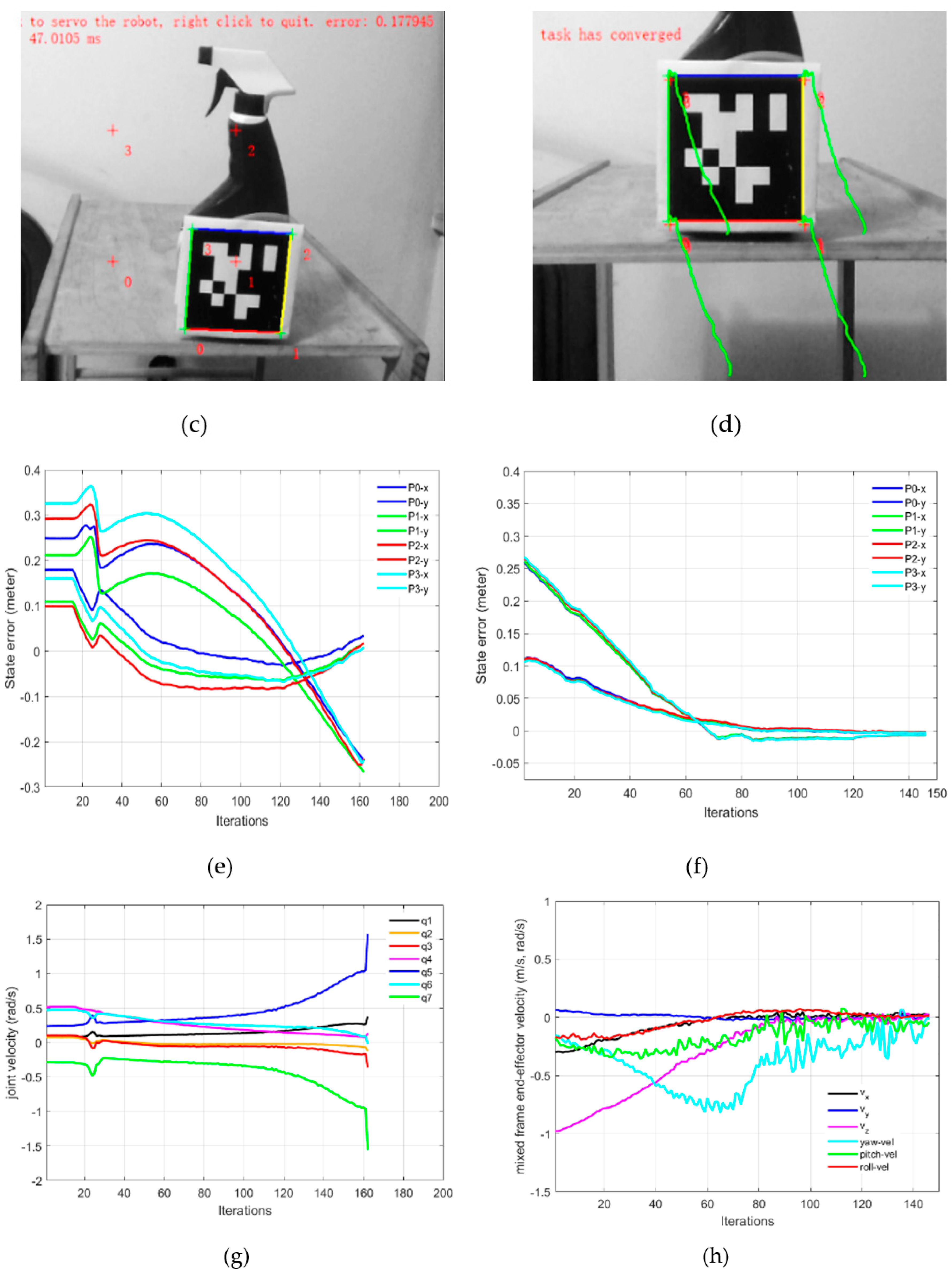
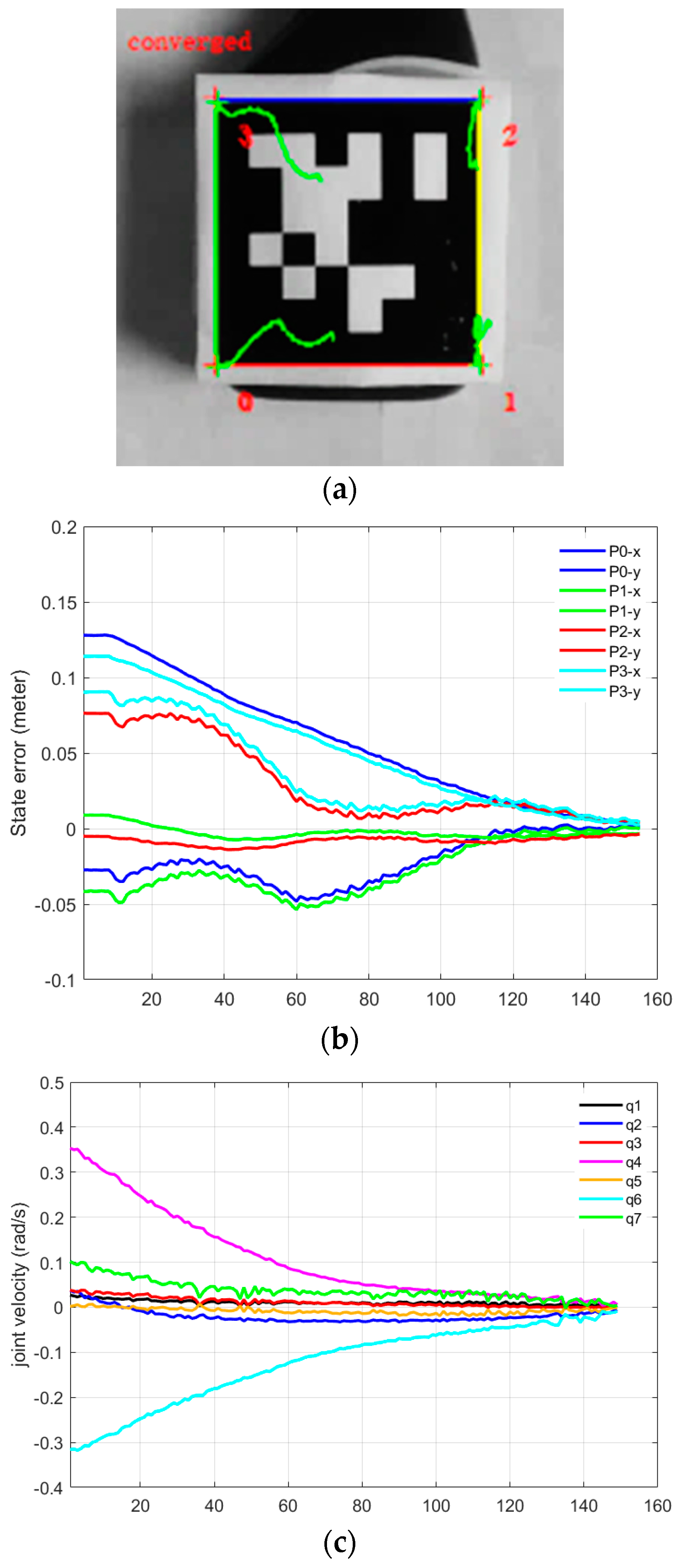
In Part-D of this experiment, we validated joint velocity control through our proposed framework, in which our newly developed mix frame Jacobian from
Section 2, and mixed frame end-effector velocity from
Section 3, were utilized using Equation (26) to implement a joint velocity controller to achieve an IBVS task.
Figure 13a–c shows the results of the experiment including visual feature trajectories, error decay, and the manipulator’s joint velocities.
An important observation to note in Part-D is that the task took 154 iterations for convergence with a wavy image point trajectory [see
video results-V8]; however, with a stabilized decreasing joint velocity as shown in
Figure 13c. This behavior is apprehensible, considering that, even if the robotic arm is 6 DoF or it may be redundant, generally it is not identical to compute first the
Vm using Equation (25) and then calculating the corresponding joint velocities
using the mixed frame Jacobian in Equation (26), or on the other hand, to directly compute
for visual servo control using Equation (18). Nevertheless, both techniques are correct, yet the two control schemes are different and will produce two different joint velocities and image point trajectories. Actually, it may happen that the manipulator Jacobian may be singular whereas the feature Jacobian is not (that occurs if k < n). Moreover, the use of pseudo-inverse in Equation (21) ensures that camera velocities
are minimal while in this case for Equation (26), joint velocities
are minimal. Hence, the choice of the state space variable is vital.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}