
Analytical Review of Event-Based Camera Depth Estimation Methods and Systems



Abstract
:1. Introduction
2. Event-Based Cameras

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Resolution | Latency (μs) | Dynamic Range (dB) | Pixel Size (μm2) | Power Consumption (mW) | Supply Voltage (V) |
|---|---|---|---|---|---|---|
| [15] | 128 × 128 | 15 | 120 | 40 × 40 | 24 | 3.3 |
| [7] | 304 × 240 | 3 | 143 | 30 × 30 | 175 | 3.3 |
| [17] | 128 × 128 | 3.6 | >100 | 35 × 35 | 132–231 | 3.3 |
| [18] | 64 × 64 | - | - | 33 × 33 | 15 | 3.3 |
| [19] | 128 × 128 | 3 | 120 | 30 × 31 | 4 | 3.3 |
| [20] | 240 × 180 | 12 | 120 | 18.5 × 18.5 | 7.4–13.5 | 3.3 |
| [21] | 240 × 180 | 3 | 130 | 18.5 × 18.5 | 5 | 3.3 |
| [22] | 640 × 480 | <200 | >80 | 9 × 9 | 27 | 2.8 |
| [6] | 768 × 640 | <0.5 | >120 | 18 × 18 | - | - |
| [23] | 346 × 260 | - | - | 18.5 × 18.5 | - | - |
| [24] | 320 × 262 | 1000 | >100 | 13 × 13 | 70 | - |
| [8] | 132 × 1024 | - | - | 10 × 10 | 0.25 | 1.2 |
| [5] | 1280 × 800 | <0.5 | >120 | 9.8 × 9.8 | 400 | 3.3 |
| [11] | 1280 × 720 | <200 | >124 | 4.86 × 4.86 | 32 | 2.8 |
| [9] | 1280 × 960 | - | - | 4.95 × 4.95 | 150 | 2.8 |
| [24] | 800 × 600 | 1000 | >100 | 7.2 × 7.2 | 250 | - |
2.1. Event-Based Camera Data Coding
2.2. Events and Spiking Neural Networks
- The ways in which information is encoded in SNNs and ANNs are different. A non-spiking neuron uses real-value activations to convey information whereas a spiking neuron modulates information on spikes.
- A non-spiking neuron in an ANN does not have any memory, yet spiking neurons typically have memory.
- The output generated by many ANNs, especially feedforward ANNs, is not a function of time, yet most SNNs are time-varying in nature.
2.2.1. Hodgkin–Huxley Model
2.2.2. Leaky Integrate-And-Fire Model
2.2.3. Izhikevich Model
2.3. Event-Based Camera Characteristics
- Power consumption: The dynamic vision sensor outputs only event data when objects in the scene move with respect to the camera or the camera itself moves. The events are generated at the edges of objects, i.e., where the light intensity changes. This characteristic drastically reduces redundant data. When the scene is static and objects in the scene do not move, no output is generated, except for the noise from individual pixels. However, this noise can be filtered out using background filtering techniques [32].
- Latency: The latency of the dynamic vision sensor is closely correlated with the asynchronous behaviour of the pixel. Conventional cameras need to synchronously capture every pixel’s data and then pass this data to some processing unit. The DVS event is asynchronous, and the subsequent processing unit time step is on the order of microseconds, as limited by the analogue circuitry comprising the pixel, not the integration time. Hence, it can be extensively used in safety-critical applications like those related to the automotive industry [33].
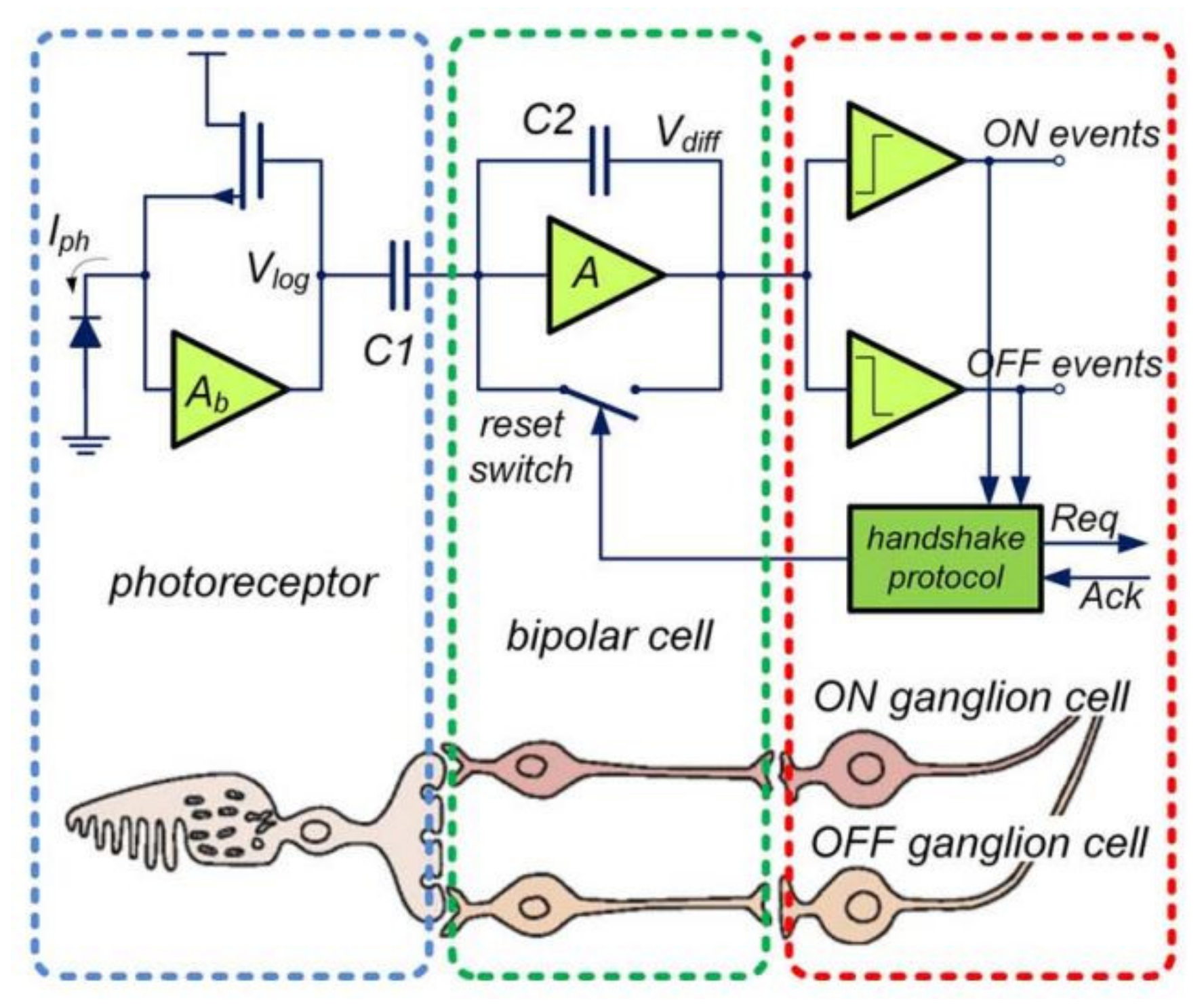
- Dynamic range: In event-based cameras, the dynamic range is 120 dB (or even more) as compared to frame-based cameras— 60 dB. In the biological retina, the adaptation to light level already starts in photoreceptors. It eliminates the dependency on absolute lighting level and instead the receptors respond to changes in the incident light (also known as temporal contrast) [13,34]. In silicon, this is based on a compressive logarithmic transformation in the photoreceptor circuit [14].
3. Event-Based Depth Estimation in Hardware
3.1. Field-Programmable Gate Arrays
Stereo Matching with Two Asynchronous Time-Based Image Sensors
3.2. Neuromorphic Processors
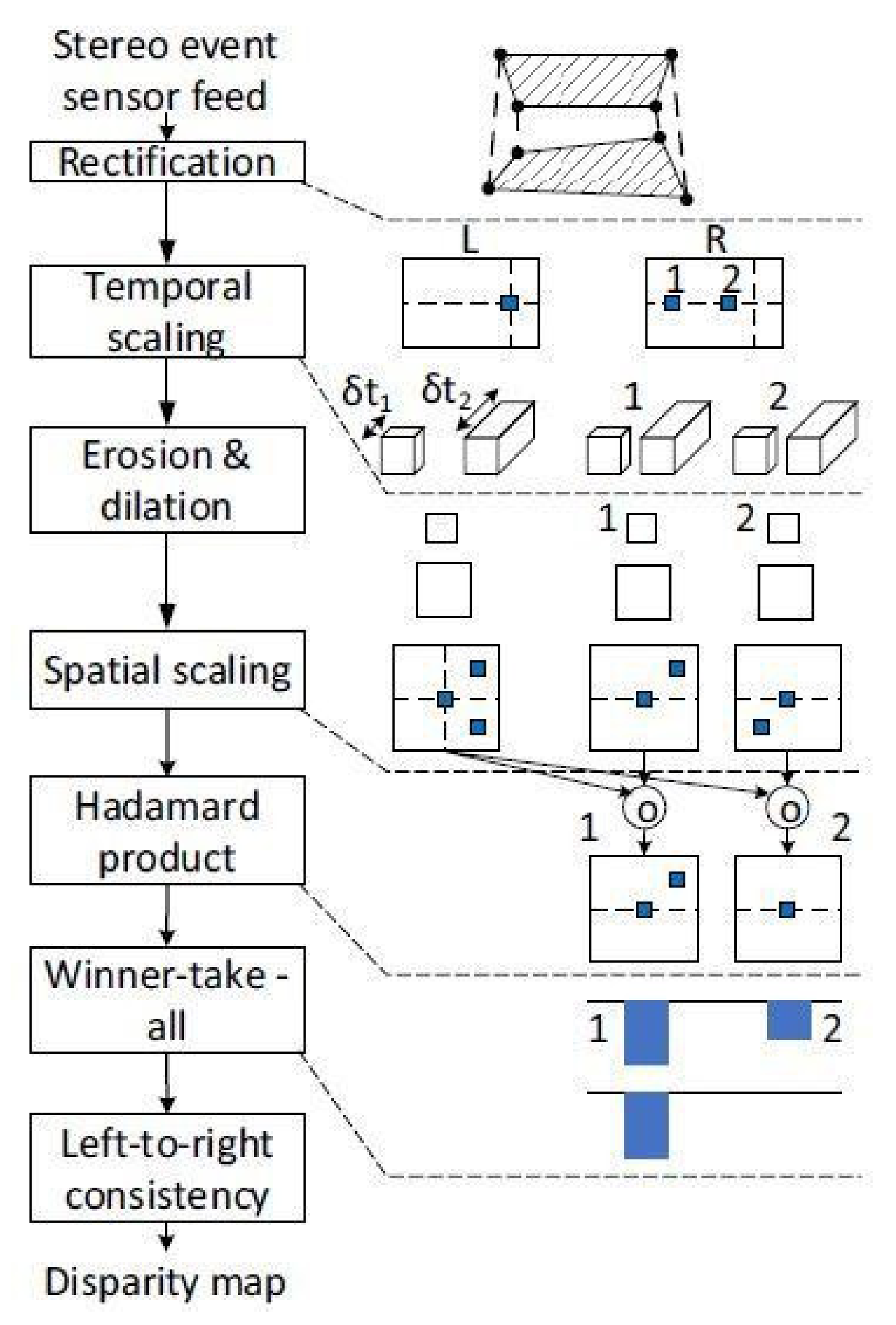
Disparity Maps from Fully Event-Based Systems
3.3. Standard Processors
3.3.1. Correspondence Problem in Stereo Depth-Estimation
3.3.2. Simultaneous Localization and Mapping
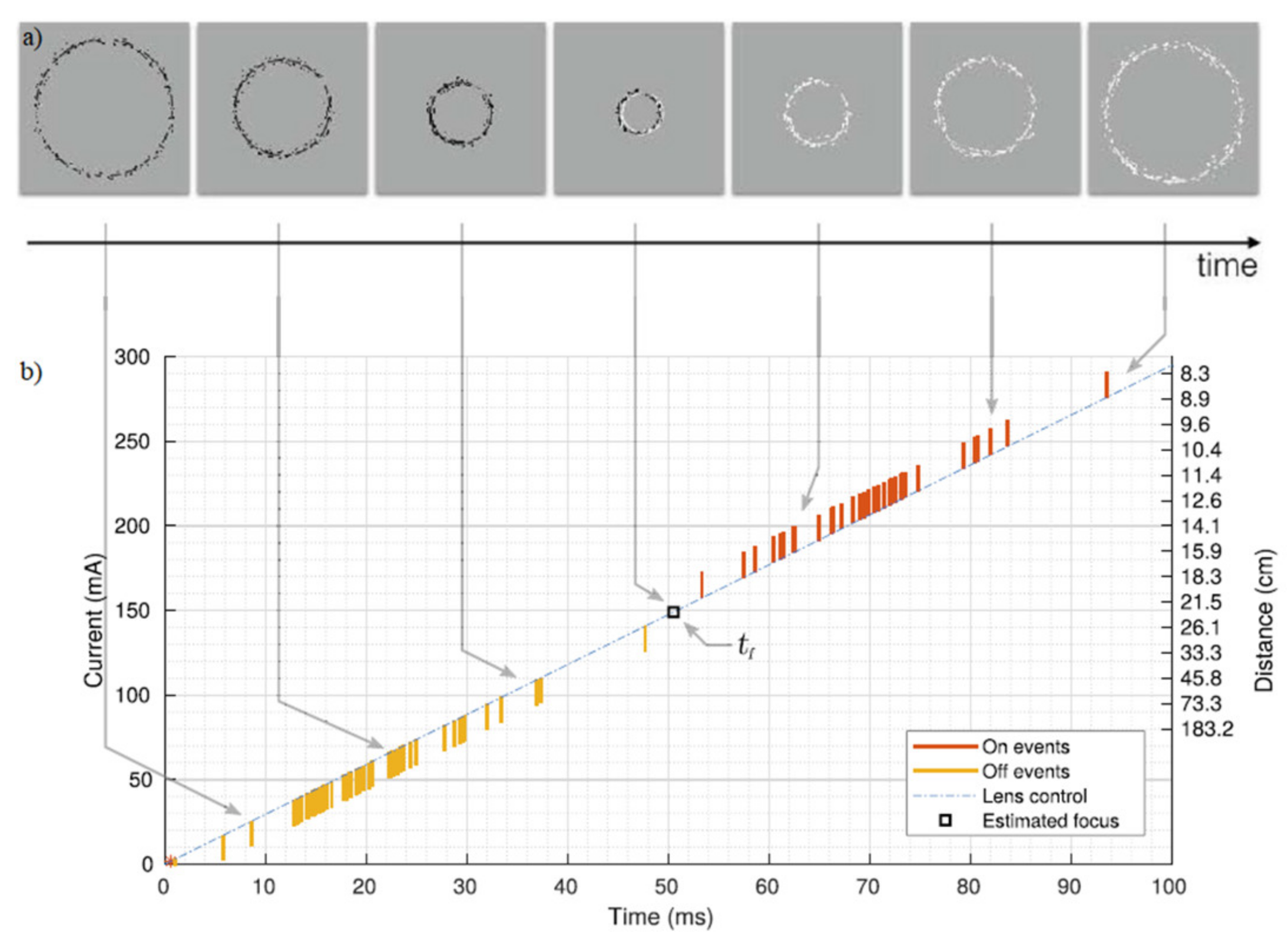
3.3.3. 6-DOF Tracking from Photometric Depth Map
3.3.4. Spiking Neural Networks in Stereo and Monocular Depth Estimation
3.3.5. Monocular Dense Depth
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer: London, UK, 2010. [Google Scholar]
- Gong, D.; Yang, J.; Liu, L.; Zhang, Y.; Reid, I.; Shen, C.; Van Den Hengel, A.; Shi, Q. From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Schuman, C.D.; Potok, T.E.; Patton, R.M.; Birdwell, J.D.; Dean, M.E.; Rose, G.S.; Plank, J.S. A survey of neuromorphic computing and neural networks in hardware. arXiv 2017, arXiv:1705.06963. [Google Scholar]
- Etienne-Cummings, R.; Van der Spiegel, J. Neuromorphic vision sensors. Sens. Actuators A Phys. 1996, 56, 19–29. [Google Scholar] [CrossRef]
- Chen, S.; Guo, M. Live demonstration: CELEX-V: A 1m pixel multi-mode event-based sensor. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Guo, M.; Huang, J.; Chen, S. Live demonstration: A 768 × 640 pixels 200 Meps dynamic vision sensor. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017. [Google Scholar]
- Posch, C.; Matolin, D.; Wohlgenannt, R. A QVGA 143 DB dynamic range frame-free PWM image sensor with lossless pixel-level video compression and time-domain cds. IEEE J. Solid State Circuits 2011, 46, 259–275. [Google Scholar] [CrossRef]
- Li, C.; Longinotti, L.; Corradi, F.; Delbruck, T. A 132 by 104 10 μm-pixel 250 μw 1kefps Dynamic Vision sensor with pixel-parallel noise and spatial redundancy suppression. In Proceedings of the 2019 Symposium on VLSI Circuits, Kyoto, Japan, 9–14 June 2019. [Google Scholar]
- Suh, Y.; Choi, S.; Ito, M.; Kim, J.; Lee, Y.; Seo, J.; Jung, H.; Yeo, D.-H.; Namgung, S.; Bong, J.; et al. A 1280 × 960 dynamic vision sensor with a 4.95-μm pixel pitch and motion artifact minimization. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020. [Google Scholar]
- Gallego, G.; Delbruck, T.; Orchard, G.M.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.; Conradt, J.; Daniilidis, K.; et al. Event-based Vision: A Survey. arXiv 2020, arXiv:1904.08405. [Google Scholar] [CrossRef]
- Finateu, T.; Niwa, A.; Matolin, D.; Tsuchimoto, K.; Mascheroni, A.; Reynaud, E.; Mostafalu, P.; Brady, F.; Chotard, L.; LeGoff, F.; et al. 5.10 a 1280 × 720 back-illuminated stacked temporal contrast event-based vision sensor with 4.86 µm pixels, 1.066 GEPS readout, programmable event-rate controller and compressive data-formatting pipeline. In Proceedings of the 2020 IEEE International Solid- State Circuits Conference (ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Purnyn, H. The mammalian retina: Structure and blood supply. Neurophysiology 2013, 45, 266–276. [Google Scholar] [CrossRef]
- Posch, C.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Delbruck, T. Retinomorphic event-based vision sensors: Bioinspired cameras with spiking output. Proc. IEEE 2014, 102, 1470–1484. [Google Scholar] [CrossRef] [Green Version]
- Barth, F.G.; Humphrey, J.A.; Srinivasan, M.V. Frontiers in Sensing: From Biology to Engineering; Springer Wien: New York, NY, USA, 2012. [Google Scholar]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 × 128 120 dB 15 µs latency asynchronous temporal contrast vision sensor. IEEE J. Solid State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef] [Green Version]
- Bigasa, M.; Cabrujaa, E.; Forestb, J.; Salvib, J. Review of CMOS image sensors. Microelectron. J. 2006, 37, 433–451. [Google Scholar] [CrossRef] [Green Version]
- Lenero-Bardallo, J.A.; Serrano-Gotarredona, T.; Linares-Barranco, B. A 3.6 µs latency asynchronous frame-free event-driven dynamic-vision-sensor. IEEE J. Solid State Circuits 2011, 46, 1443–1455. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Tang, W.; Zhang, X.; Culurciello, E. A 64 × 64 pixels UWB wireless temporal-difference digital image sensor. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2012, 20, 2232–2240. [Google Scholar] [CrossRef]
- Serrano-Gotarredona, T.; Linares-Barranco, B. A 128 × 128 1.5% contrast sensitivity 0.9% FPN 3 µs latency 4 MW asynchronous frame-free dynamic vision sensor using Transimpedance preamplifiers. IEEE J. Solid State Circuits 2013, 48, 827–838. [Google Scholar] [CrossRef]
- Berner, R.; Brandli, C.; Yang, M.; Liu, S.-C.; Delbruck, T. A 240 × 180 10 mW 12 µs latency sparse-output vision sensor for mobile applications. In Proceedings of the Symposium on VLSI Circuits, Kyoto, Japan, 12–14 June 2013. [Google Scholar]
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.-C.; Delbruck, T. A 240 × 180 130 DB 3 µs latency global shutter spatiotemporal vision sensor. IEEE J. Solid State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Son, B.; Suh, Y.; Kim, S.; Jung, H.; Kim, J.-S.; Shin, C.; Park, K.; Lee, K.; Park, J.; Woo, J.; et al. 4.1 a 640 × 480 dynamic vision sensor with a 9 µm pixel and 300 Meps address-event representation. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017. [Google Scholar]
- Taverni, G.; Moeys, D.P.; Li, C.; Delbruck, T.; Cavaco, C.; Motsnyi, V.; Bello, D.S. Live demonstration: Front and back illuminated dynamic and active pixel vision sensors comparison. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar]
- Insightness. Insightness Rino 3-4. Available online: https://www.insightness.com/technology/ (accessed on 19 November 2021).
- Orchard, G.; Meyer, C.; Etienne-Cummings, R.; Posch, C.; Thakor, N.; Benosman, R. HFirst: A temporal approach to object recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2028–2040. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lagorce, X.; Orchard, G.; Galluppi, F.; Shi, B.E.; Benosman, R.B. Hots: A hierarchy of event-based time-surfaces for pattern recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1346–1359. [Google Scholar] [CrossRef] [PubMed]
- Sironi, A.; Brambilla, M.; Bourdis, N.; Lagorce, X.; Benosman, R. Hats: Histograms of averaged time surfaces for robust event-based object classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Haessig, G.; Berthelon, X.; Ieng, S.-H.; Benosman, R. A spiking neural network model of depth from defocus for event-based Neuromorphic Vision. Sci. Rep. 2019, 9, 3744. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, N.; Mazumder, P. Learning in Energy-Efficient Neuromorphic Computing: Algorithm and Architecture Co-Design; Wiley-IEEE Press: Hoboken, NJ, USA, 2020. [Google Scholar]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500–544. [Google Scholar] [CrossRef]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef] [Green Version]
- Linares-Barranco, A.; Perez-Pena, F.; Moeys, D.P.; Gomez-Rodriguez, F.; Jimenez-Moreno, G.; Liu, S.-C.; Delbruck, T. Low latency event-based filtering and feature extraction for dynamic vision sensors in real-time FPGA applications. IEEE Access 2019, 7, 134926–134942. [Google Scholar] [CrossRef]
- Chen, G.; Cao, H.; Conradt, J.; Tang, H.; Rohrbein, F.; Knoll, A. Event-based neuromorphic vision for autonomous driving: A paradigm shift for bio-inspired visual sensing and perception. IEEE Signal Processing Mag. 2020, 37, 34–49. [Google Scholar] [CrossRef]
- Gollisch, T.; Meister, M. Eye smarter than scientists believed: Neural computations in circuits of the retina. Neuron 2010, 65, 150–164. [Google Scholar] [CrossRef] [Green Version]
- Eibensteiner, F.; Kogler, J.; Scharinger, J. A high-performance hardware architecture for a frameless stereo vision algorithm implemented on a FPGA platform. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–29 June 2014. [Google Scholar]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.-J.; et al. TrueNorth: Design and tool flow of a 65 MW 1 million neuron programmable neurosynaptic chip. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The spinnaker project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Kuang, Y.; Cui, X.; Zhong, Y.; Liu, K.; Zou, C.; Dai, Z.; Wang, Y.; Yu, D.; Huang, R. A 64K-neuron 64m-1B-synapse 2.64PJ/SOP neuromorphic chip with all memory on chip for spike-based models in 65NM CMOS. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 2655–2659. [Google Scholar] [CrossRef]
- Dikov, G.; Firouzi, M.; Röhrbein, F.; Conradt, J.; Richter, C. Spiking cooperative stereo-matching at 2 ms latency with neuromorphic hardware. In Biomimetic and Biohybrid Systems; Mangan, M., Cutkosky, M., Mura, A., Verschure, P., Prescott, T., Lepora, N., Eds.; Springer: Cham, Switzerland, 2017; Volume 10384, pp. 119–137. [Google Scholar]
- Andreopoulos, A.; Kashyap, H.J.; Nayak, T.K.; Amir, A.; Flickner, M.D. A low power, high throughput, fully event-based Stereo System. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Schraml, S.; Schön, P.; Milosevic, N. Smartcam for real-time stereo vision–address-event based embedded system. In Proceedings of the Second International Conference on Computer Vision Theory and Applications, Barcelona, Spain, 8–11 March 2007. [Google Scholar]
- Rogister, P.; Benosman, R.; Ieng, S.-H.; Lichtsteiner, P.; Delbruck, T. Asynchronous event-based binocular stereo matching. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 347–353. [Google Scholar] [CrossRef]
- Piatkowska, E.; Belbachir, A.N.; Gelautz, M. Asynchronous stereo vision for event-driven dynamic stereo sensor using an adaptive cooperative approach. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013. [Google Scholar]
- Piatkowska, E.; Kogler, J.; Belbachir, N.; Gelautz, M. Improved cooperative stereo matching for Dynamic Vision sensors with ground truth evaluation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gallego, G.; Lund, J.E.A.; Mueggler, E.; Rebecq, H.; Delbruck, T.; Scaramuzza, D. Event-based, 6-DOF camera tracking from photometric depth maps. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2402–2412. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Leutenegger, S.; Davison, A.J. Real-time 3D reconstruction and 6-DOF tracking with an event camera. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9910, pp. 349–364. [Google Scholar]
- Schraml, S.; Belbachir, A.N.; Bischof, H. Event-driven stereo matching for real-time 3D panoramic vision. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Weikersdorfer, D.; Adrian, D.B.; Cremers, D.; Conradt, J. Event-based 3D slam with a depth-augmented dynamic vision sensor. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Zhou, Y.; Gallego, G.; Shen, S. Event-based Stereo Visual Odometry. IEEE Trans. Robot. 2021, 37, 1433–1450. [Google Scholar] [CrossRef]
- Camunas-Mesa, L.A.; Serrano-Gotarredona, T.; Ieng, S.H.; Benosman, R.B.; Linares-Barranco, B. On the use of orientation filters for 3D reconstruction in event-driven Stereo Vision. Front. Neurosci. 2014, 8, 48. [Google Scholar]
- Zhu, A.Z.; Chen, Y.; Daniilidis, K. Realtime Time Synchronized Event-based stereo. In Computer Vision–ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11210, pp. 438–452. [Google Scholar]
- Osswald, M.; Ieng, S.-H.; Benosman, R.; Indiveri, G. A spiking neural network model of 3D perception for event-based Neuromorphic Stereo Vision Systems. Sci. Rep. 2017, 7, 40703. [Google Scholar] [CrossRef]
- Kuck, J.; Chakraborty, S.; Tang, H.; Luo, R.; Song, J.; Sabharwal, A.; Ermon, S. Belief Propagation Neural Networks. arXiv 2020, arXiv:2007.00295. Available online: https://ui.adsabs.harvard.edu/abs/2020arXiv200700295K (accessed on 15 January 2022).
- Xie, Z.; Chen, S.; Orchard, G. Event-based stereo depth estimation using belief propagation. Front. Neurosci. 2017, 11, 535. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hidalgo-Carrio, J.; Gehrig, D.; Scaramuzza, D. Learning monocular dense depth from events. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020. [Google Scholar]
- Tulyakov, S.; Fleuret, F.; Kiefel, M.; Gehler, P.; Hirsch, M. Learning an event sequence embedding for dense event-based deep stereo. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Zhu, A.Z.; Thakur, D.; Ozaslan, T.; Pfrommer, B.; Kumar, V.; Daniilidis, K. The Multivehicle Stereo Event Camera Dataset: An event camera dataset for 3D perception. IEEE Robot. Autom. Lett. 2018, 3, 2032–2039. [Google Scholar] [CrossRef] [Green Version]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, Z.; Snavely, N. MegaDepth: Learning single-view depth prediction from internet photos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 × 128 120 db 30 MW asynchronous vision sensor that responds to relative intensity change. In Proceedings of the 2006 IEEE International Solid State Circuits Conference–Digest of Technical Papers, San Francisco, CA, USA, 6–9 February 2006. [Google Scholar]
- Conradt, J.; Berner, R.; Cook, M.; Delbruck, T. An embedded AER dynamic vision sensor for low-latency pole balancing. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Posch, C.; Matolin, D.; Wohlgenannt, R. High-DR frame-free PWM imaging with asynchronous AER intensity encoding and focal-plane temporal redundancy suppression. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010. [Google Scholar]
- Viollet, S.A. Vibrating makes for better seeing: From the Fly’s Micro-Eye movements to hyperacute visual sensors. Front. Bioeng. Biotechnol. 2014, 2, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]





| Reference | Range | Accuracy/Error | Latency | Power Consumption | Complexity |
|---|---|---|---|---|---|
| Indoor | |||||
| [42] | ++ | + | + | + | +++ |
| [43] | + | ++ | +++ | + | +++ |
| [44] | - | ++ | - | - | +++ |
| [51] | + | ++ | + | - | ++ |
| [35] | + | + | +++ | - | ++ |
| [49] | - | - | - | + | +++ |
| [48] 1 | + | + | - | - | +++ |
| [47] 2 | - | - | - | - | ++ |
| [40] | + | + | ++ | + | + |
| [53] | + | ++ | + | +++ | + |
| [45] | + | ++ | + | - | +++ |
| [55] | + | + | ++ | - | ++ |
| [41] | + | ++ | ++ | ++ | + |
| [52] | +++ | +++ | + | - | +++ |
| [28] | ++ | + | ++ | +++ | + |
| [57] | +++ | +++ | - | - | + |
| [50] | ++ | ++ | + | - | ++ |
| Outdoor | |||||
| [46] 3 | +++ | + | - | - | ++ |
| [58] | +++ | ++ | - | - | ++ |
| [56] | +++ | +++ | - | - | ++ |
| Reference | Camera | Platform | Monocular/Stereo | Max Reported Depth (m) | Accuracy/Error | Latency | Power Consumption |
|---|---|---|---|---|---|---|---|
| INDOOR | |||||||
| [42] | [63] | Embedded Blackfin BF537 DSP | Stereo | 3.5 | Error: 2.00–45 cm | 5.0–50 ms | 5 W |
| [43] | [15] | Standard CPU (Pentium 4 laptop) | Stereo | 0.060 | Error: 3.67–5.79% | 0.30 ms | 30% CPU load |
| [44] | [15] | CPU | Stereo | - | Accuracy: 95.0% | - | - |
| [51] | [19] | Spartan 6 FPGA | Stereo | 1.0 | Error: <1.50% | 50 ms | - |
| [35] | [15] | FPGA | Stereo | 3.5 | Error: 0.1–0.5 m | 13.7 µs | - |
| [49] | [64] | Single-core Intel i7 1.9 GHz CPU | Stereo | - | Error: 3.10–13.4 cm | - | 17W |
| [48] 1 | [15] | CPU | Stereo | 5.0 | Accuracy: 75–85% | - | - |
| [47] 2 | [15] | CPU | Monocular | - | - | - | - |
| [40] | [15] | SpiNNaker | Stereo | 2.8 | Accuracy: 96.7–62.2% | 2 ms | 90 W |
| [53] | [21] | CPU i7 3.40 GHz | Stereo | 5.0 | Accuracy: 96.0% | 30 ms | 1.99 mW |
| [45] | [7] | CPU | Stereo | 4.5 | Error: 0.110 m | - | - |
| [55] | [21] | Intel i7 3.4 GHz CPU | Stereo | 5.0 | Accuracy: 61.1–92.0% | 2 ms | - |
| [41] | [21] | TrueNorth | Stereo | 0.12 | Error: 5.00–11.6% | 9 ms | 0.058 mW/Pixel |
| [52] | [23] | NVIDIA 960M GPU | Stereo | 30 | Error: 0.36–0.44 m | 40 ms | - |
| [28] | [65] | CPU | Monocular | 5.5 | Error: 4.00–23.0% | 10 ms | 200 mW |
| [57] | [60] | GeForce GTX TITAN X GPU | Stereo | 30 | Error: 0.136–0.184 m | - | - |
| [50] | [65] | Intel Core i7-8750H CPU | Stereo | 6.0 | Error: 0.16–0.19 m | 78 ms | - |
| Outdoor | |||||||
| [46] 3 | [15] | Intel® i7 processor at 2.60 GHz | Stereo | 30 | Error: 3.97–6.47% | 32 μs/event | - |
| [58] | [60] | CPU | Monocular | 30 | Error: 2.19–5.05 m | - | - |
| [56] | [60] | CPU | Monocular | 30 | Error: 1.42–4.46 m | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Furmonas, J.; Liobe, J.; Barzdenas, V. Analytical Review of Event-Based Camera Depth Estimation Methods and Systems. Sensors 2022, 22, 1201. https://doi.org/10.3390/s22031201
Furmonas J, Liobe J, Barzdenas V. Analytical Review of Event-Based Camera Depth Estimation Methods and Systems. Sensors. 2022; 22(3):1201. https://doi.org/10.3390/s22031201
Chicago/Turabian StyleFurmonas, Justas, John Liobe, and Vaidotas Barzdenas. 2022. "Analytical Review of Event-Based Camera Depth Estimation Methods and Systems" Sensors 22, no. 3: 1201. https://doi.org/10.3390/s22031201
APA StyleFurmonas, J., Liobe, J., & Barzdenas, V. (2022). Analytical Review of Event-Based Camera Depth Estimation Methods and Systems. Sensors, 22(3), 1201. https://doi.org/10.3390/s22031201