






Informatics 2026, 13(4), 58; https://doi.org/10.3390/informatics13040058 - 3 Apr 2026
Abstract
►
Show Figures
The rapid advancement of digital and mobile technologies has reshaped the educational landscape, fostering the adoption of interactive and learner-centered methodologies. Among these, immersive technologies such as Augmented Reality (AR), when coupled with next-generation wireless communication systems, hold the potential to revolutionize knowledge
[...] Read more.
The rapid advancement of digital and mobile technologies has reshaped the educational landscape, fostering the adoption of interactive and learner-centered methodologies. Among these, immersive technologies such as Augmented Reality (AR), when coupled with next-generation wireless communication systems, hold the potential to revolutionize knowledge acquisition and student engagement. In this paper, we present the design and development of an AR-based educational tool specifically oriented to teaching concepts of fifth-generation (5G) mobile networks. The tool provides a real-time interactive visualization of 3D network components on mobile devices, enabling learners to explore 5G NSA/SA architectures in an accessible manner with real-world environments through mobile devices and their integrated cameras. The application was developed using Blender for 3D modeling and Unity as the rendering engine, incorporating the Vuforia SDK for marker-based AR tracking, and it was deployed on the Android operating system. Unlike traditional static approaches, the proposed solution enables learners to explore complex network architectures and key functionalities of 5G in an interactive and accessible manner. To assess its perceived effectiveness, quantitative surveys were conducted with both university and high school students, focusing on usability, engagement, and perceived learning outcomes. Results indicate that the tool is user-friendly, enhances motivation, and supports conceptual understanding as perceived by participants of 5G technologies. These findings highlight the potential of AR, supported by advanced wireless networks, as a pedagogical strategy to improve STEM education and foster technological literacy in the era of digital transformation.
Full article
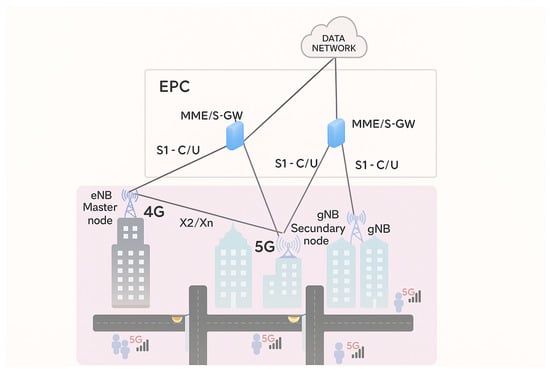
Figure 1





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}