

Multimodal Technol. Interact. 2026, 10(6), 67; https://doi.org/10.3390/mti10060067 - 4 Jun 2026
Abstract
►
Show Figures
Traditional European craft practices face dual pressures: the erosion of tacit knowledge held by aging practitioners, and the risk of cultural homogenization through uninformed digital adoption. This paper presents a comparative analysis of a structured design pilot conducted across five Representative Craft Instances
[...] Read more.
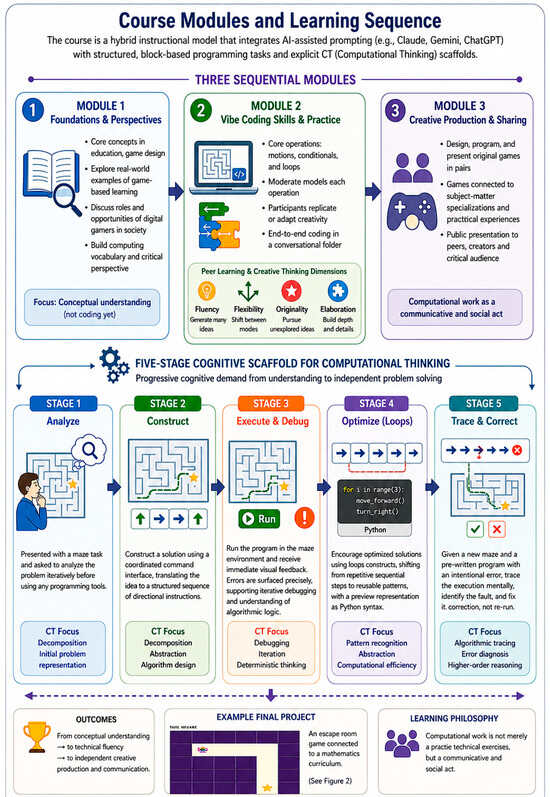
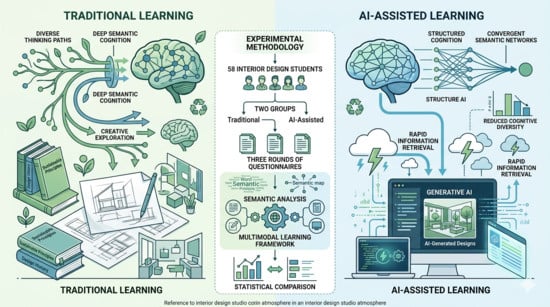
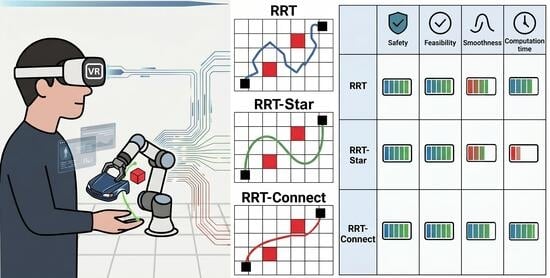
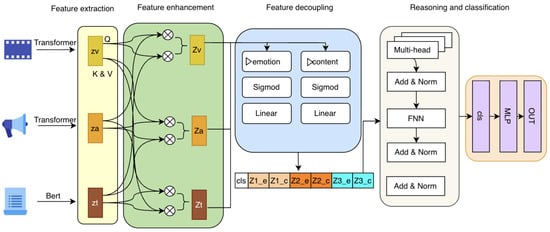
Traditional European craft practices face dual pressures: the erosion of tacit knowledge held by aging practitioners, and the risk of cultural homogenization through uninformed digital adoption. This paper presents a comparative analysis of a structured design pilot conducted across five Representative Craft Instances (RCIs): glassblowing, tapestry, marble/silversmithing, porcelain, and woodcarving within the Horizon Europe CRAEFT project. Drawing on co-creative workshops, motion capture pipelines, physically based rendering (PBR), interactive simulation, and additive manufacturing, we analyze how context-specific digital tools performed as mediators rather than modernizers across heterogeneous craft domains. Cross-domain analysis reveals that digital tools achieve cultural legitimacy only when introduced through co-creative, practitioner-led cycles; that gesture and tacit knowledge are transferable via structured computational pipelines; and that methodological portability, not workflow replication, is the appropriate model for cross-context scaling. Implications are discussed for sustainable heritage policy, design education, and the development of craft-sensitive digital infrastructure in Europe. A cross-RCI comparative assessment matrix evaluates all five domains across seven analytical dimensions: practitioner adoption, perceived usefulness, cultural legitimacy, technical maturity, sustainability impact, transferability potential, and educational effectiveness. Finally, practitioner reflective accounts from participating designers and craftspeople are presented to ground the analytical findings empirically.
Full article

Figure 1





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}