In this section, we present the results and discuss the outcome. We show the performance of the approaches and also evaluate some of their key parameters to obtain some insights about the suitability of these approaches for the domain.
5.1. Performance Comparison
The results of the proposed deep methods on the OPPORTUNITY dataset and the Skoda dataset are shown in
Table 4 and
Table 9, respectively. In the case of the OPPORTUNITY dataset, we report here the classification performance either including or ignoring the
Null class. Including the
Null class may lead to an overestimation of the performance given its large prevalence. By providing both results, we get better insights about the type of errors made by the models.
Table 3 includes a comprehensive list of past published classification techniques employed on the datasets. The techniques competing in the OPPORTUNITY challenge were sliding window based and only differ in the classifier and features extracted.
Table 3.
Baseline classifiers included in the datasets’ comparative evaluation.
Table 3.
Baseline classifiers included in the datasets’ comparative evaluation.
| OPPORTUNITY Dataset |
|---|
| | Challenge Submissions [7] |
|---|
| | Method | Description |
|---|
| | LDA | Linear discriminant analysis. Gaussian classifier that classifies on the assumption that the features are normally distributed and all classes have the same covariance matrix. |
| | QDA | Quadratic discriminant analysis. Similar to the LDA, this technique also assumes a normal distribution for the features, but the class covariances may differ. |
| | NCC | Nearest centroid classifier. The Euclidean distance between the test sample and the centroid for each class of samples is used for the classification. |
| | 1NN | k nearest neighbour algorithm. Lazy algorithm where the Euclidean distances between a test sample and the training samples are computed and the most frequently-occurring label of the
k-closest samples is the output. |
| | 3NN | See 1NN. Using 3 neighbours. |
| | UP | Submission to the OPPORTUNITY challenge from U. of Parma. Pattern comparison using mean, variance, maximum and minimum values. |
| | NStar | Submission to the OPPORTUNITY challenge from U. of Singapore. kNN algorithm using a single neighbour and normalized data. |
| | SStar | Submission to the OPPORTUNITY challenge from U. of Singapore. Support vector machine algorithm using scaled data. |
| | CStar | Submission to the OPPORTUNITY challenge from U. of Singapore. Fusion of a kNN algorithm using the closest neighbour and a support vector machine. |
| | NU | Submission to the OPPORTUNITY challenge from U. of Nagoya. C4.5 decision tree algorithm using mean, variance and energy. |
| | MU | Submission to the OPPORTUNITY challenge from U. of Monash. Decision tree grafting algorithm. |
| | Deep approaches |
| | Method | Description |
| | CNN [17] | Results reported by Yang et. al., in [17]. The value is computed using the average performance for Subjects 1, 2 and 3. |
| Skoda dataset |
| | Deep approaches |
| | Method | Description |
| | CNN [23] | Results reported by Ming Zeng et. al., in [23]. Performance computed using one accelerometer on the right arm to identify all activities. |
| | CNN [43] | Results reported by Alsheikh et. al., in [43]. Performance computed using one accelerometer node (id #16) to identify all activities. |
Table 4.
score performance on OPPORTUNITY dataset for the gestures and modes of locomotion recognition tasks, either including or ignoring the Null class. The best results are highlighted in bold.
Table 4.
score performance on OPPORTUNITY dataset for the gestures and modes of locomotion recognition tasks, either including or ignoring the Null class. The best results are highlighted in bold.
| Method | Modes of Locomotion | Modes of Locomotion | Gesture Recognition | Gesture Recognition |
|---|
| | (No Null Class) | | (No Null Class) | |
|---|
| | OPPORTUNITY Challenge Submissions |
| LDA | 0.64 | 0.59 | 0.25 | 0.69 |
| QDA | 0.77 | 0.68 | 0.24 | 0.53 |
| NCC | 0.60 | 0.54 | 0.19 | 0.51 |
| 1 NN | 0.85 | 0.84 | 0.55 | 0.87 |
| 3 NN | 0.85 | 0.85 | 0.56 | 0.85 |
| UP | 0.84 | 0.60 | 0.22 | 0.64 |
| NStar | 0.86 | 0.61 | 0.65 | 0.84 |
| SStar | 0.86 | 0.64 | 0.70 | 0.86 |
| CStar | 0.87 | 0.63 | 0.77 | 0.88 |
| NU | 0.75 | 0.53 | | |
| MU | 0.87 | 0.62 | | |
| | Deep architectures |
| CNN [17] | | | | 0.851 |
| Baseline CNN | 0.912 | 0.878 | 0.783 | 0.883 |
| DeepConvLSTM | 0.930 | 0.895 | 0.866 | 0.915 |
From the results in
Table 4, we can see that DeepConvLSTM consistently outperforms baselines on both tasks. When compared to the best submissions of the OPPORTUNITY challenge, it improves the performance by 6% on average. For some specific tasks, it can be noticed how DeepConvLSTM offers a striking performance improvement: there is more than a 9% improvement in the gesture recognition task without the
Null class when compared to the OPPORTUNITY challenge models. DeepConvLSTM also improves by 6% over results previously reported by Yang
et. al. [
17] using a CNN.
The baseline CNN also offers better results than the OPPORTUNITY submissions in the recognition of models of locomotion. However, in the case of gesture recognition, it obtains a similar recognition performance as the ensemble approach named CStar. These results of the baseline CNN are consistent with those obtained previously by Yang
et. al. in [
17] using a CNN on raw signal data. Among deep architectures, DeepConvLSTM systematically performs better than the CNNs, improving the performance by 5% on average on the OPPORTUNITY dataset.
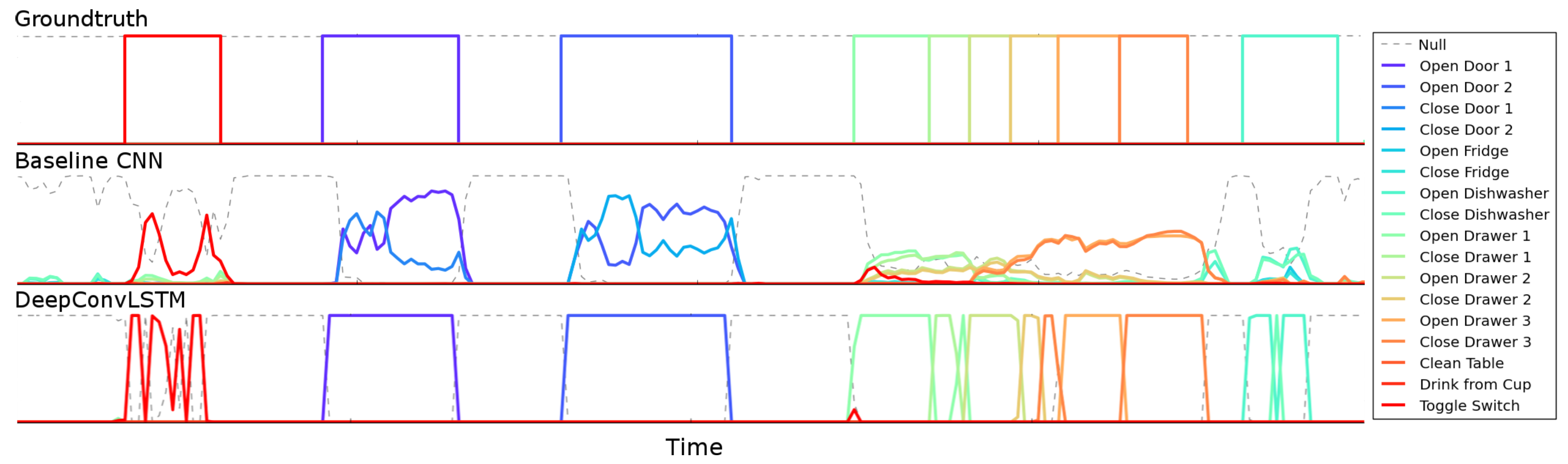
In
Figure 6, we illustrate the differences in the output predictions of the different architectures on the OPPORTUNITY dataset. One of the main challenges in this domain is the automatic segmentation of the activities. The baseline CNN approach tends to make more mistakes and has difficulties making crisp decisions about the boundaries of the gestures. It has troubles defining where the gesture starts or ends.
The confusion matrices on the OPPORTUNITY dataset for the gesture recognition task are illustrated in
Table 5 and
Table 7 for the DeepConvLSTM approach and in
Table 6 and
Table 8 for the baseline CNN. The confusion matrices contain information about actual and predicted gesture classifications done by the system, to identify the nature of the classification errors, as well as their quantities. Each cell in the confusion matrix represents the number of times that the gesture in the row is classified as the gesture in the column. Given the class imbalance in the data due to the presence of the dominant
Null class, we report confusion matrices including and ignoring the
Null class, in order to get better insights on the actual system performance.
When the
Null class is included in the recognition task (see
Table 5 and
Table 6), most classification errors, both false positives and false negatives, are related to this class. This is the most realistic setup, where almost 75% of the data (see
Table 2) processed is not considered as an activity of interest.
When the
Null class is removed from the classification task (see
Table 7 and
Table 8), both approaches tend to misclassify gestures that are relatively similar, such as “Open Door 2”-“Close Door 2” or “Open Fridge”-“Close Fridge”. This may be because these gestures involve the activation of the same type of sensors, but with a different sequentiality. In the case of gestures “Open Door 2”-“Close Door 2”, one is misclassified as the other 44 times by the baseline CNN, while DeepConvLSTM made only 14 errors. Similarly, for gestures “Open Drawer 3”-“Close Drawer 3”, the baseline CNN made 33 errors, while DeepConvLSTM misclassified only 14 sequences. The better performance of DeepConvLSTM for these similar gestures may be explained by the ability of LSTM cells to capture temporal dynamics within the data sequence processed. On the other hand, the baseline CNN is only capable of modelling time sequences up to the length of the kernels.
Table 5.
Confusion matrix for OPPORTUNITY dataset using DeepConvLSTM.
Table 5.
Confusion matrix for OPPORTUNITY dataset using DeepConvLSTM.
| | | Predicted Gesture |
|---|
| | | Null | Open Door 1 | Open Door 2 | Close Door 1 | Close Door 2 | Open Fridge | Close Fridge | Open Dishwasher | Close Dishwasher | Open Drawer 1 | Close Drawer 1 | Open Drawer 2 | Close Drawer 2 | Open Drawer 3 | Close Drawer 3 | Clean Table | Drink from Cup | Toggle Switch |
|---|
| Actual Gesture | Null | 13,532 | 16 | 5 | 15 | 13 | 54 | 35 | 35 | 72 | 10 | 13 | 5 | 4 | 22 | 39 | 7 | 158 | 29 |
| Open Door 1 | 10 | 76 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Door 2 | 7 | 0 | 155 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Door 1 | 8 | 15 | 0 | 78 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Door 2 | 10 | 0 | 0 | 0 | 130 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Fridge | 111 | 0 | 0 | 0 | 0 | 253 | 22 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Close Fridge | 41 | 0 | 0 | 0 | 0 | 19 | 210 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Dishwasher | 61 | 0 | 0 | 0 | 0 | 6 | 0 | 99 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Dishwasher | 43 | 0 | 0 | 0 | 0 | 2 | 0 | 10 | 79 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| Open Drawer 1 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 1 | 38 | 6 | 2 | 1 | 3 | 1 | 0 | 0 | 1 |
| Close Drawer 1 | 20 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 8 | 46 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Drawer 2 | 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 18 | 2 | 29 | 6 | 1 | 0 | 0 | 0 | 1 |
| Close Drawer 2 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 5 | 4 | 25 | 0 | 3 | 0 | 0 | 0 |
| Open Drawer 3 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 0 | 88 | 3 | 0 | 0 | 0 |
| Close Drawer 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 9 | 5 | 80 | 0 | 0 | 0 |
| Clean Table | 88 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 81 | 2 | 0 |
| Drink from Cup | 143 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 397 | 0 |
| Toggle Switch | 57 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 122 |
Table 6.
Confusion matrix for OPPORTUNITY dataset using the baseline CNN.
Table 6.
Confusion matrix for OPPORTUNITY dataset using the baseline CNN.
| | | Predicted Gesture |
|---|
| | | Null | Open Door 1 | Open Door 2 | Close Door 1 | Close Door 2 | Open Fridge | Close Fridge | Open Dishwasher | Close Dishwasher | Open Drawer 1 | Close Drawer 1 | Open Drawer 2 | Close Drawer 2 | Open Drawer 3 | Close Drawer 3 | Clean Table | Drink from Cup | Toggle Switch |
|---|
| Actual Gesture | Null | 13,752 | 5 | 8 | 6 | 5 | 39 | 18 | 14 | 29 | 2 | 0 | 1 | 1 | 40 | 20 | 2 | 114 | 8 |
| Open Door 1 | 17 | 51 | 0 | 28 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Door 2 | 15 | 0 | 111 | 0 | 38 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Door 1 | 10 | 22 | 0 | 69 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Door 2 | 9 | 0 | 7 | 0 | 124 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Fridge | 130 | 0 | 0 | 0 | 0 | 220 | 34 | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Fridge | 49 | 0 | 0 | 0 | 0 | 76 | 146 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Dishwasher | 108 | 0 | 0 | 0 | 0 | 4 | 0 | 45 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Dishwasher | 75 | 0 | 0 | 0 | 0 | 4 | 0 | 30 | 26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Drawer 1 | 31 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 27 | 5 | 0 | 0 | 2 | 0 | 0 | 0 | 1 |
| Close Drawer 1 | 40 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Drawer 2 | 36 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 1 | 18 | 1 | 6 | 0 | 0 | 0 | 0 |
| Close Drawer 2 | 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 1 | 13 | 5 | 9 | 0 | 0 | 0 | 0 |
| Open Drawer 3 | 29 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 56 | 28 | 0 | 0 | 0 |
| Close Drawer 3 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 51 | 42 | 0 | 0 | 0 |
| Clean Table | 98 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 73 | 0 | 0 |
| Drink from Cup | 194 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 349 | 0 |
| Toggle Switch | 99 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 82 |
Table 7.
Confusion matrix for OPPORTUNITY dataset using DeepConvLSTM (without the Null class).
Table 7.
Confusion matrix for OPPORTUNITY dataset using DeepConvLSTM (without the Null class).
| | | Predicted Gesture |
|---|
| | | Open Door 1 | Open Door 2 | Close Door 1 | Close Door 2 | Open Fridge | Close Fridge | Open Dishwasher | Close Dishwasher | Open Drawer 1 | Close Drawer 1 | Open Drawer 2 | Close Drawer 2 | Open Drawer 3 | Close Drawer 3 | Clean Table | Drink from Cup | Toggle Switch |
|---|
| Actual Gesture | Open Door 1 | 81 | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Open Door 2 | 0 | 149 | 1 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Door 1 | 15 | 0 | 73 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Close Door 2 | 0 | 2 | 1 | 124 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Fridge | 1 | 1 | 0 | 0 | 342 | 29 | 11 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 2 |
| Close Fridge | 0 | 0 | 0 | 0 | 10 | 258 | 0 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| Open Dishwasher | 0 | 0 | 0 | 0 | 4 | 0 | 151 | 5 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 2 |
| Close Dishwasher | 0 | 0 | 0 | 0 | 4 | 0 | 15 | 107 | 0 | 0 | 0 | 2 | 0 | 6 | 0 | 1 | 2 |
| Open Drawer 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 36 | 17 | 0 | 1 | 0 | 2 | 0 | 0 | 8 |
| Close Drawer 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 5 | 66 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Open Drawer 2 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 13 | 8 | 35 | 3 | 1 | 0 | 0 | 0 | 5 |
| Close Drawer 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 4 | 2 | 10 | 3 | 26 | 1 | 0 | 0 | 0 | 0 |
| Open Drawer 3 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 2 | 0 | 7 | 4 | 87 | 7 | 0 | 0 | 1 |
| Close Drawer 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 27 | 7 | 66 | 0 | 0 | 0 |
| Clean Table | 0 | 0 | 0 | 0 | 2 | 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 147 | 17 | 0 |
| Drink from Cup | 1 | 1 | 2 | 1 | 0 | 0 | 24 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 515 | 0 |
| Toggle Switch | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 3 | 3 | 0 | 0 | 0 | 0 | 1 | 1 | 161 |
Table 8.
Confusion matrix for OPPORTUNITY dataset using the baseline CNN (without the Null class).
Table 8.
Confusion matrix for OPPORTUNITY dataset using the baseline CNN (without the Null class).
| | | Predicted Gesture |
|---|
| | | Open Door 1 | Open Door 2 | Close Door 1 | Close Door 2 | Open Fridge | Close Fridge | Open Dishwasher | Close Dishwasher | Open Drawer 1 | Close Drawer 1 | Open Drawer 2 | Close Drawer 2 | Open Drawer 3 | Close Drawer 3 | Clean Table | Drink from Cup | Toggle Switch |
|---|
| Actual Gesture | Open Door 1 | 73 | 0 | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| Open Door 2 | 0 | 111 | 0 | 43 | 0 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 4 |
| Close Door 1 | 22 | 0 | 63 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Close Door 2 | 2 | 4 | 1 | 118 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| Open Fridge | 1 | 1 | 0 | 0 | 304 | 59 | 17 | 1 | 4 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 2 |
| Close Fridge | 0 | 0 | 0 | 0 | 20 | 243 | 5 | 2 | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| Open Dishwasher | 0 | 0 | 0 | 0 | 15 | 1 | 121 | 11 | 5 | 0 | 0 | 0 | 6 | 4 | 0 | 1 | 3 |
| Close Dishwasher | 0 | 0 | 0 | 0 | 7 | 11 | 19 | 90 | 1 | 0 | 3 | 1 | 0 | 4 | 1 | 0 | 0 |
| Open Drawer 1 | 0 | 0 | 0 | 0 | 3 | 0 | 2 | 3 | 35 | 12 | 6 | 0 | 1 | 1 | 0 | 0 | 4 |
| Close Drawer 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 16 | 51 | 3 | 0 | 0 | 0 | 0 | 2 | 0 |
| Open Drawer 2 | 0 | 0 | 0 | 0 | 4 | 0 | 2 | 0 | 19 | 3 | 31 | 5 | 2 | 0 | 0 | 0 | 1 |
| Close Drawer 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 4 | 1 | 15 | 18 | 1 | 6 | 0 | 0 | 0 |
| Open Drawer 3 | 0 | 0 | 0 | 0 | 1 | 0 | 6 | 1 | 3 | 0 | 9 | 0 | 62 | 29 | 1 | 0 | 1 |
| Close Drawer 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 1 | 14 | 84 | 0 | 0 | 0 |
| Clean Table | 1 | 0 | 2 | 0 | 9 | 11 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 134 | 12 | 0 |
| Drink from Cup | 3 | 1 | 4 | 1 | 4 | 6 | 9 | 14 | 0 | 0 | 3 | 0 | 0 | 0 | 2 | 499 | 0 |
| Toggle Switch | 0 | 1 | 1 | 0 | 0 | 4 | 0 | 0 | 15 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 149 |
From the results in
Table 9, we can see that DeepConvLSTM outperforms other deep non-recurrent approaches on the Skoda dataset, improving the best reported result by 6%. The Skoda dataset has some specific characteristics: the gestures are long on average; it does not contain a
Null class; and unlike the OPPORTUNITY dataset, it is quite well balanced. The greater length of the gestures does not diminish the performance of the model. These results corroborate our findings, supporting that the use of LSTM brings a significant advantage across very different scenarios.
Table 9.
score performance on the Skoda dataset.
Table 9.
score performance on the Skoda dataset.
| Method | |
|---|
| CNN [23] | 0.861 |
| CNN [43] | 0.893 |
| Baseline CNN | 0.884 |
| DeepConvLSTM | 0.958 |
5.2. Multimodal Fusion Analysis
Wearable activity recognition can make use of a variety of sensors. While accelerometers tend to be extremely small and low power, inertial measurement units are more complex (combining accelerometers, gyroscopes and magnetic sensors), but can provide accurate limb orientation. It is therefore important for an activity recognition framework to be applicable to a wide range of commonly-used sensor modalities to accommodate for the various size and power trade-offs.
We evaluate how the automated feature extraction provided by the kernels in convolutional layers is suitable to deal with signals of sensors of different modalities. In
Table 10, we show the performance of DeepConvLSTM at recognizing gestures on the OPPORTUNITY dataset (without the
Null class) for different selections of sensors. It can be noticed how,without any specific preprocessing, convolution operations can be interchangeably applied to individual sensor modalities. Starting from a 69%
score using only the accelerometers on the dataset, the performance improves on average by 15% fusing accelerometers and gyroscopes and by 20% when fusing accelerometers, gyroscopes and magnetic sensors. As the number of sensor channels is increased, the performance of the model is consistently improved, regardless of the modalities of the sensors. These results demonstrate that the convolutional layers can extract features from sensor signals of different modalities without
ad hoc preprocessing.
Table 10.
Performance using different sensor modalities.
Table 10.
Performance using different sensor modalities.
| | Accelerometers | Gyroscopes | Accelerometers | Accelerometers | Opportunity |
|---|
| | + Gyroscopes | + Gyroscopes | Sensors Set |
|---|
| | | + Magnetic | |
|---|
| # of sensors channels | 15 | 15 | 30 | 45 | 113 |
| score | 0.689 | 0.611 | 0.745 | 0.839 | 0.864 |
5.3. Hyperparameters Evaluation
We characterise the influence of the key hyperparameters of the system. We evaluate the influence of two key architectural parameters: the sequence length processed by the network and the number of convolutional layers.
As previously stated, the input of the recurrent model is composed of a 500-ms data sequence. Therefore, the gradient signal is unable to notice time dependencies longer than the length of this sequence. Firstly we want to evaluate the influence of this parameter in the recognition performance of gestures with different durations, in particular if the gestures are significantly longer or shorter than the sequence duration.
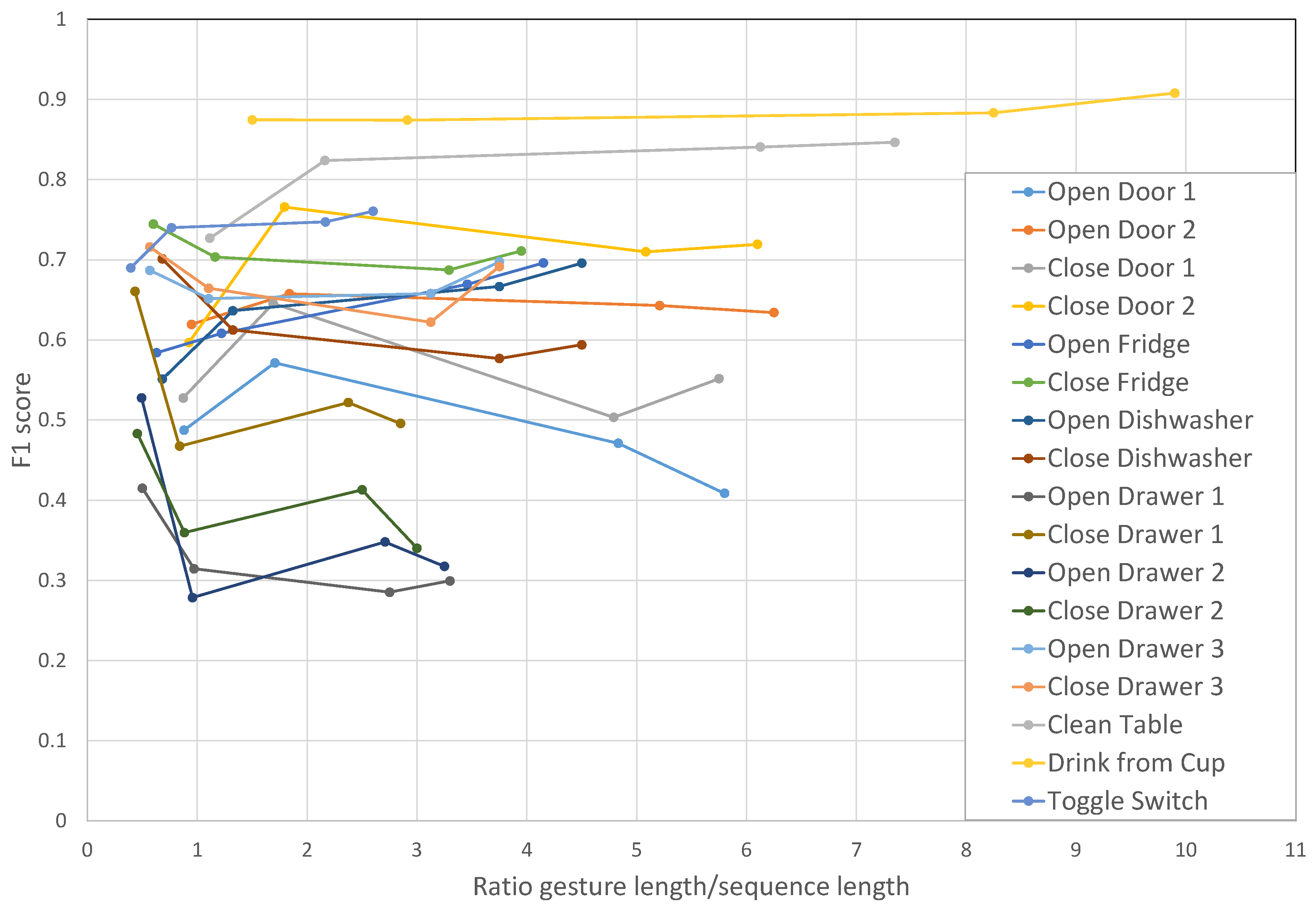
The
score on individual gestures of the dataset are shown in
Figure 7. This figure displays performance at recognizing individual gestures as a function of the ratio between the gesture length and the sequence length. Ratios under one represent performance for gestures whose durations are shorter than the sequence duration and, thus, that can be fully observed by the network before it provides an output prediction. Besides 500 ms, we carried out experiments with sequences of lengths of 400 ms, 1400 ms and 2750 ms. For most gestures, there are no significant performance changes when modifying the length of the sequence, although shorter gestures seem to benefit from being completely included in the sequence observed by the model. That is the case for several short gestures (“Open Drawer 1”, “Close Drawer 1”, “Open Drawer 2”, “Close Drawer 2”) when their ratio is under one. When the gesture duration is longer than the sequence duration, DeepConvLSTM can only come up with a classification result based on a partial view of the temporal unfolding of the features within the sequence. However, results show that DeepConvLSTM can nevertheless obtain good performance. For example, the gesture “drink from cup”, which is 10-times longer than the sequence in one of the experiments, on average achieves a 0.9
score. We speculate that this is due to the fact that longer gestures (as “clean table” or “drink from cup” in this dataset) may be made of several shorter characteristic patterns, which allows DeepConvLSTM to spot and classify the gesture even without a complete view of it.
Figure 7.
score performance of DeepConvLSTM on the OPPORTUNITY dataset. Classification performance is displayed individually per gesture, for different lengths of the input sensor data segments. Experiments carried out with sequences of length of 400 ms, 500 ms, 1400 ms and 2750 ms. The horizontal axis represents the ratio between the gesture length and the sequence length (ratios under one represent performance for gestures whose durations are shorter than the sequence duration).
Figure 7.
score performance of DeepConvLSTM on the OPPORTUNITY dataset. Classification performance is displayed individually per gesture, for different lengths of the input sensor data segments. Experiments carried out with sequences of length of 400 ms, 500 ms, 1400 ms and 2750 ms. The horizontal axis represents the ratio between the gesture length and the sequence length (ratios under one represent performance for gestures whose durations are shorter than the sequence duration).
We characterised the effect of the number of convolutional layers employed to automatically learn feature representations.
Figure 8 shows that increasing the number of convolutional layers tends to increase the performance for the OPPORTUNITY dataset, improving by 1% when a new layer is added. Performance changes are not significant in the case of the Skoda dataset, showing a plateau. Results for the OPPORTUNITY dataset show that performance may be further improved if the number of convolution operations are increased.
Figure 8.
Performance of Skoda and OPPORTUNITY (recognizing gestures and with the Null class) datasets with different numbers of convolutional layers.
Figure 8.
Performance of Skoda and OPPORTUNITY (recognizing gestures and with the Null class) datasets with different numbers of convolutional layers.
5.4. Discussion
The main findings from the direct comparison of our novel DeepConvLSTM against the baseline model using standard feedforward units in the dense layer is that: (i) DeepConvLSTM reaches a higher F1 score; (ii) it offers better segmentation characteristics illustrated by clearer cut decision boundaries between activities; (iii) it is significantly better able to disambiguate closely-related activities, which tend to differ only by the ordering of the time series (e.g., “Open/Close Door 2” or “Open/Close Drawer 3”); and (iv) it is applicable even if the gestures are longer than the observation window. These findings support the hypothesis that the LSTM-based model takes advantage of learning the temporal feature activation dynamics, which the baseline model is not capable of modelling.
DeepConvLSTM is and eight-layer deep network. Other publications showed much deeper networks, such as “GoogLeNet”, which is a 27-layer deep neural network applied to image classification [
45]. Indeed, findings illustrated in
Figure 8 show that increasing further the number of layers may be beneficial, especially for the OPPORTUNITY dataset. Training time, however, increases with the number of layers, and depending on computational resources available, future work may consider how to find trade-offs between system performance and training time. This is especially important as a deep learning approach tends to be more suitable for training on a “cloud” infrastructure, possibly using data contributed by individual wearables (e.g., as in [
46]). Therefore, the choice of the number of layers is not solely a function of the desired performance, but also of the computational budget available.
In the literature, CNN frameworks often include convolutional and pooling layers successively, as a measure to reduce data complexity and introduce translation invariant features. Nevertheless, such an approach is not strictly part of the architecture, and in the time series domain, we can see some examples of CNNs where not every convolutional layer is followed by a pooling operation [
16]. DeepConvLSTM does not include pooling operations because the input of the network is constrained by the sliding window mechanism defined by the OPPORTUNITY challenge, and this fact limits the possibility of downsampling the data, given that DeepConvLSTM requires a data sequence to be processed by the recurrent layers. However, without the sliding window requirement, a pooling mechanism could be useful to cover different sensor data time scales at deeper layers. With the introduction of pooling layers, it would be possible to have different convolutional layers operating on sensor data sequences downsampled at different levels.
As general guidelines, we would recommend to focus the main effort on optimizing hyperparameters related to the network architecture, which have the major influence on performance. Indeed, parameters related to the learning and regularization processes seem to have less overall influence on the performance. For instance, we tested higher drop-out rates (
) with no difference in terms of performance. These results are consistent with those presented in [
23]. Nevertheless, there is a power-performance trade-off, and stacking more layers to augment the hierarchic representation of the features may not be relevant if one factors computational aspects.
We show how convolution operations are robust enough to be directly applied to raw sensor data, to learn features (salient patterns) that, within a deep framework, successfully outperformed previous results on the problem. A main benefit of using CNNs is that hand-crafted or heuristic features can be avoided, thus minimising engineering bias. This is particularly important, as activity recognition techniques are applied to domains that include more complex activities or open-ended scenarios, where classifiers must adaptively model a varying number of classes.
It is also noticeable, in terms of data, how the recurrent model is capable of obtaining a very good performance with relatively small datasets, since the largest training dataset used during the experiments (the one corresponding to the OPPORTUNITY dataset) is composed of ~80 k sensor samples, corresponding to 6 h of recordings. This seems to indicate that although deep learning techniques are often employed with large amounts of data, (e.g., millions of frames in computer vision [
22]), they may actually be applicable to problem domains where acquiring annotated data is very costly, such as in supervised activity recognition.
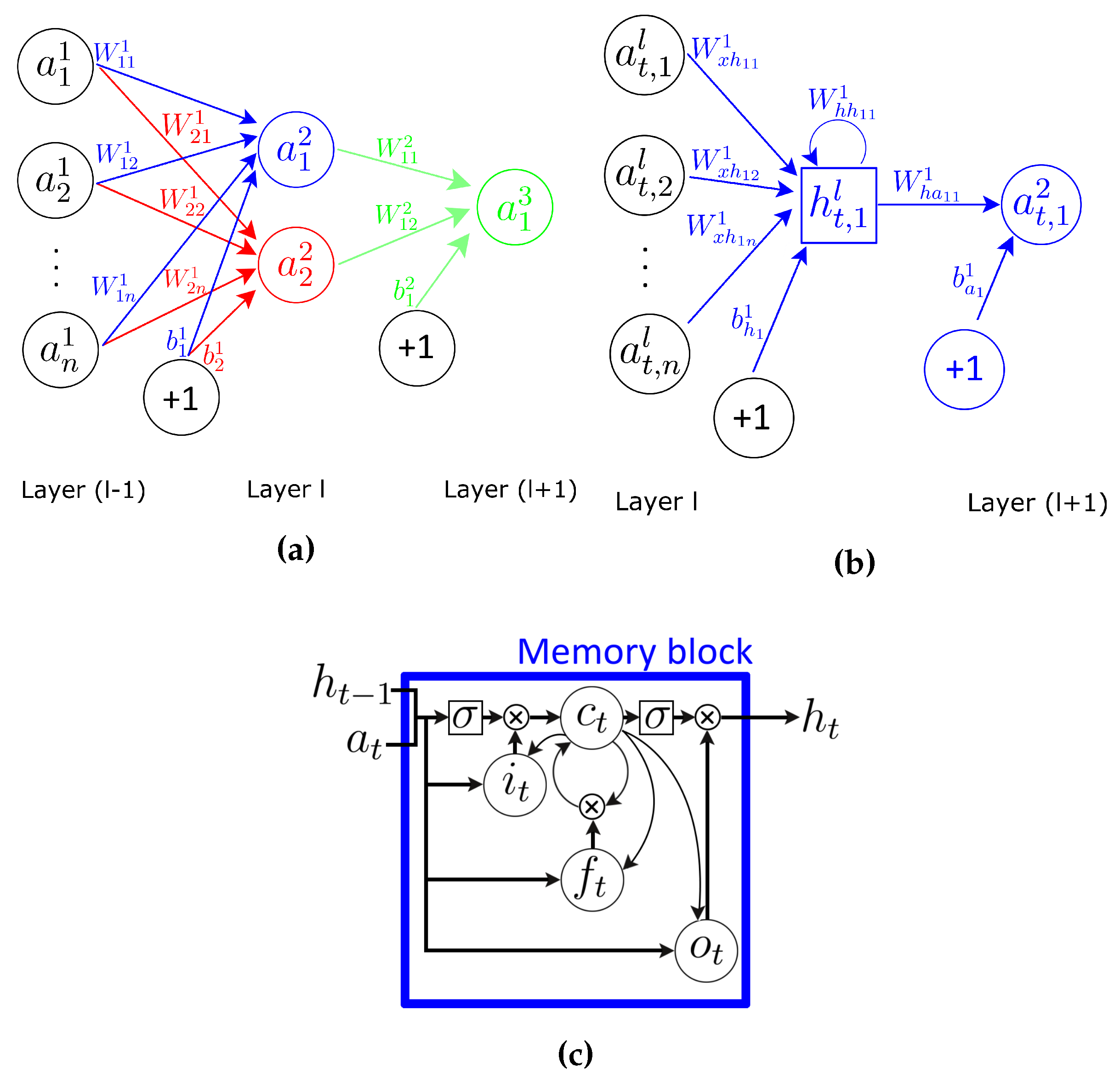
Although LSTM cells are composed of a much higher number of parameters per cell, the overall number of parameter values is significantly larger for the baseline CNN model than for DeepConvLSTM. For the specific case of the OPPORTUNITY dataset with a
Null class and following the equation in
Table 1, the parameters of DeepConvLSTM are composed of 999,122 values, while the baseline CNN parameters contain 7,445,458 values; this represents an increase of
. As illustrated in
Table 1, this difference in size is due to the type of connection between the convolutional and dense layers (Layers 5 and 6). In the fully-connected architecture, the units in the dense layer (Layer 6) have to be connected with every value of the last feature map (Layer 5), needing a very large weight matrix to parametrize this connection. On the other hand, the recurrent model processes the feature map sample by sample, thus requiring a much reduced number of parameter values. Although DeepConvLSTM is a more complex approach, it is composed of much smaller parameters, and this has a direct beneficial effect in the memory and computational efforts required to use this approach.
However, in terms of training and classification time, there is not such a significant difference between the two models, despite the more complex computational units included in the dense layers of DeepConvLSTM. Training DeepConvLSTM on the OPPORTUNITY dataset requires 340.3 min to converge, while the baseline CNN requires 282.2 min. The classification time of the baseline CNN is 5.43 s, while DeepConvLSTM needs 6.68 s to classify the whole dataset. On average, within a second, DeepConvLSTM can classify almost 15 min of data. Thus, this implementation is suitable for online HAR on the GPU used in this work.
We have not yet implemented DeepConvLSTM on a wearable device. The GPU used in this work clearly outperforms the computational power available today even in a high-end wearable system (e.g., a multicore smartphone). However, DeepConvLSTM achieves a recognition speed of 900× real-time using 1664 GPU cores at 1050 MHz. High-end mobile platforms already contain GPUs that can be used for general purpose processing [
47]. A mobile processor, such as the Qualcomm Snapdragon 820, comprises 256 GPU cores running at 650 MHz and supports OpenCL profiles for general purpose GPU computing. While cores differ in capabilities, the available computational power may well be sufficient for real-time recognition in upcoming mobile devices. Training, however, is best envisioned server-side (e.g., as in [
46]).
Removing the dependency on engineered features by exploiting convolutional layers is particularly important if the set of activities to recognise is changing over time, for instance as additional labelled data become available (e.g., through crowd-sourcing [
48]). In such an “open-ended” learning scenario, where the number of classes could be increased after the system is initially deployed, backpropagation of the gradient to the convolutional layer could be used to incrementally adapt the kernels according to the new data at runtime. Future work may consider the representational limits of such networks for open-ended learning and investigate rules to increase network size (e.g., adding new kernels) to maintain a desired representational power.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




