A Biological Signal-Based Stress Monitoring Framework for Children Using Wearable Devices


Abstract
:1. Introduction
2. Literature Review
3. Biological Signal-Based Stress Detection Framework for Children
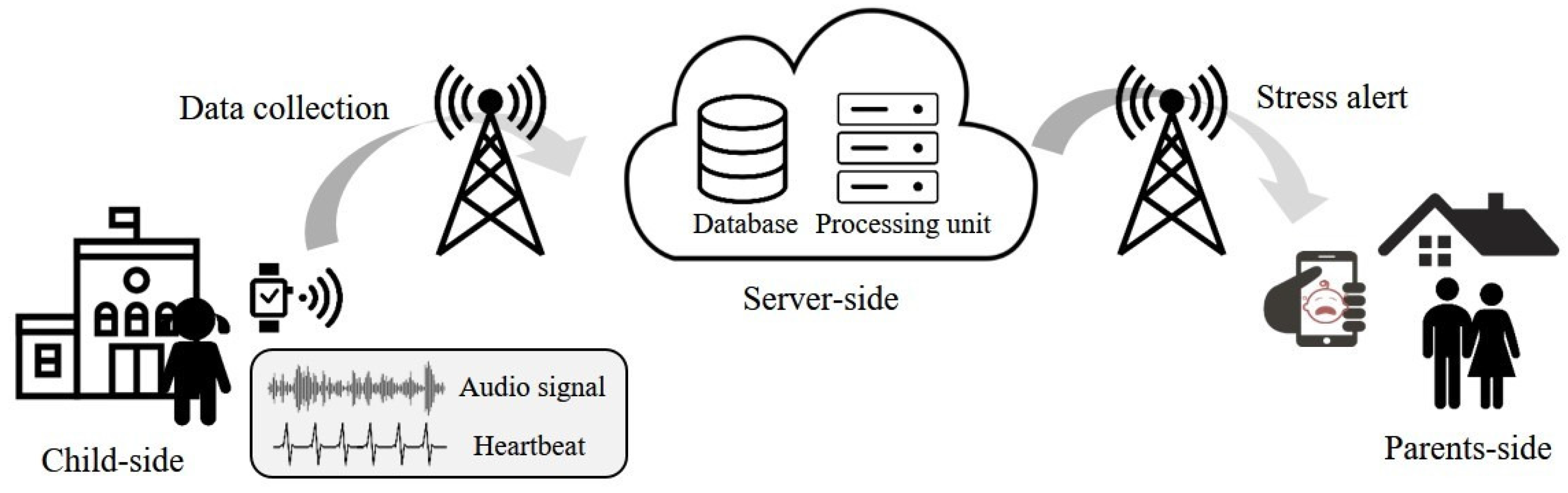
3.1. Stress Detection Framework
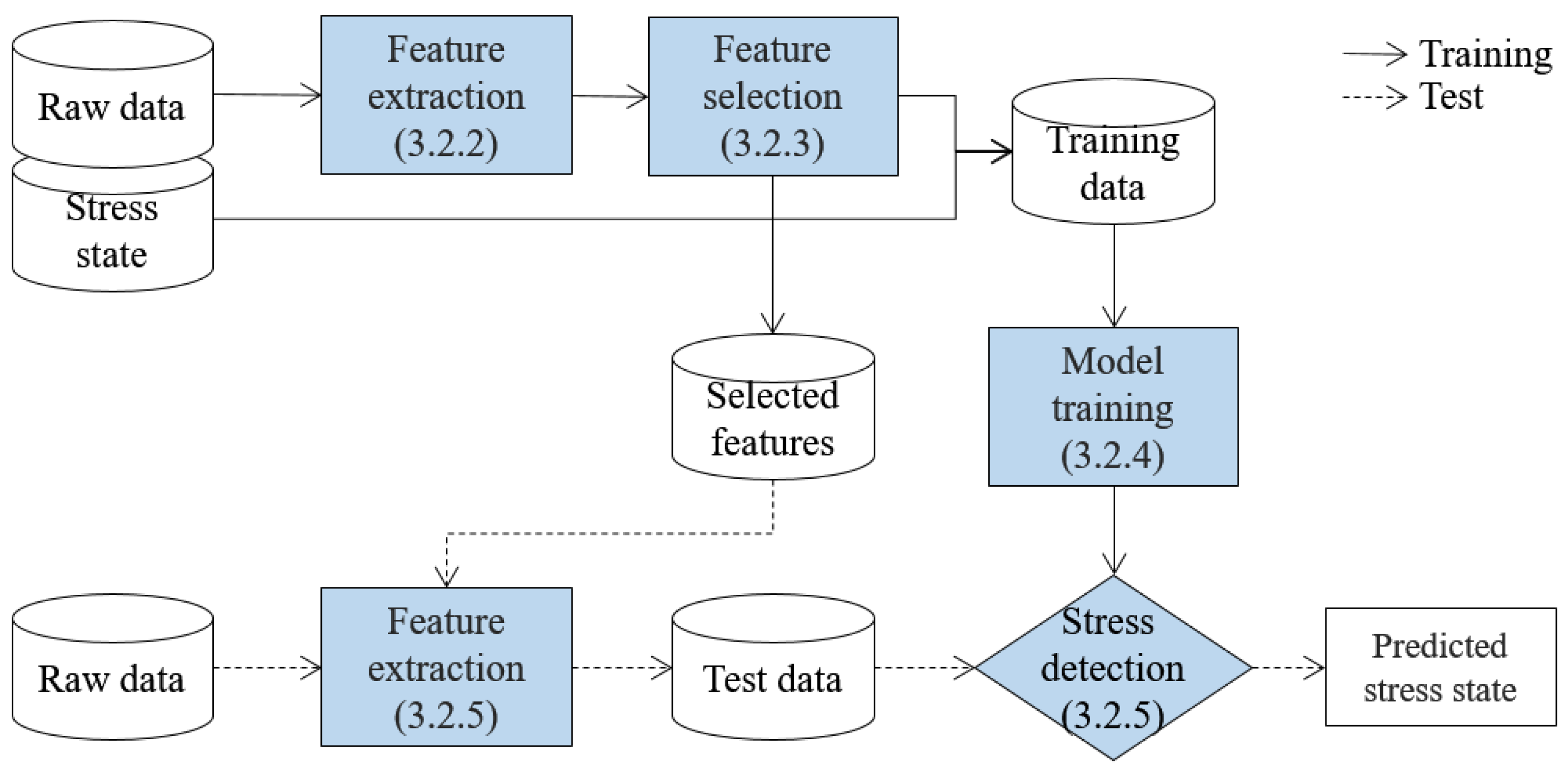
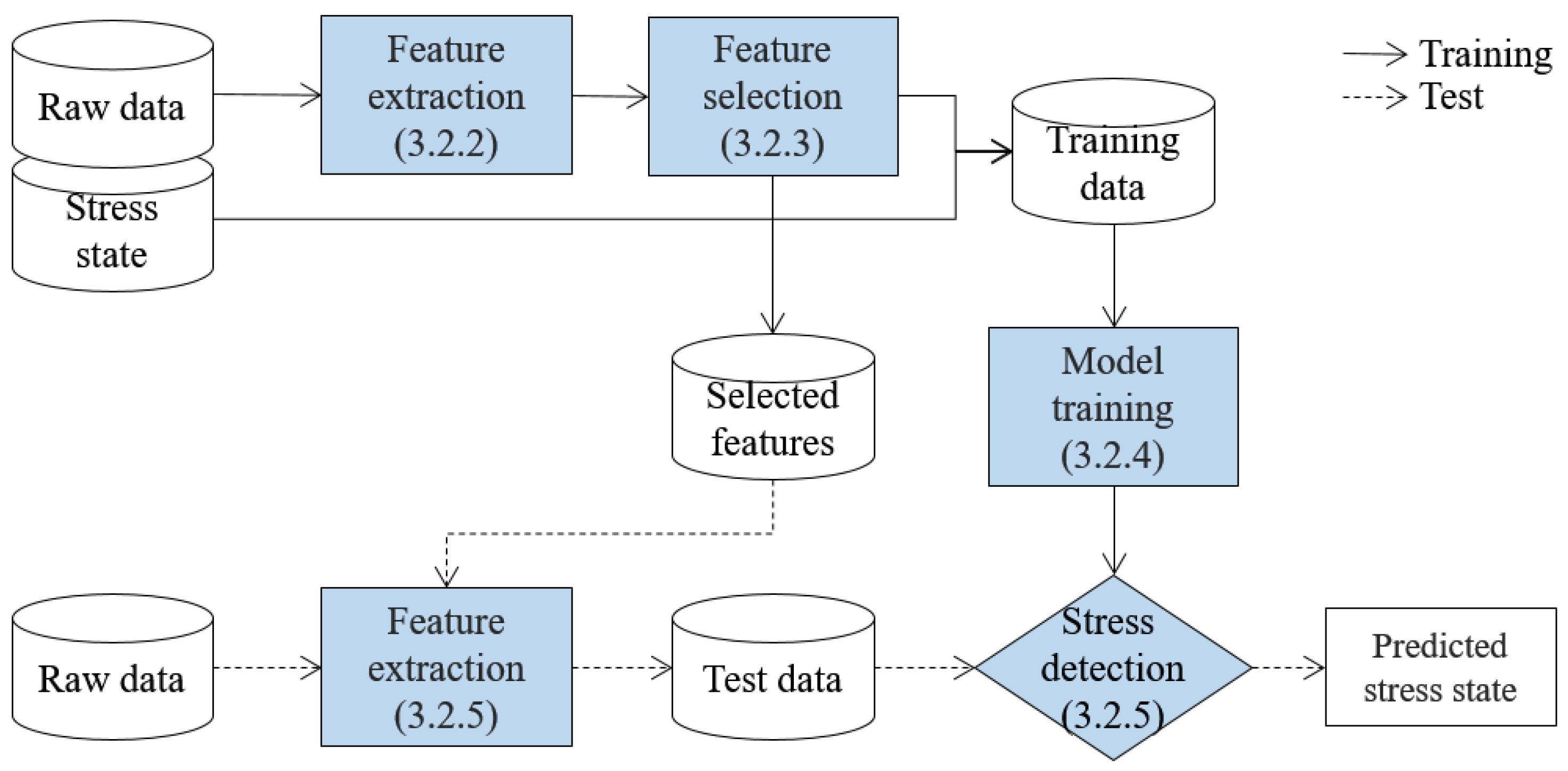
3.2. Stress Detection Algorithm
3.2.1. Overview
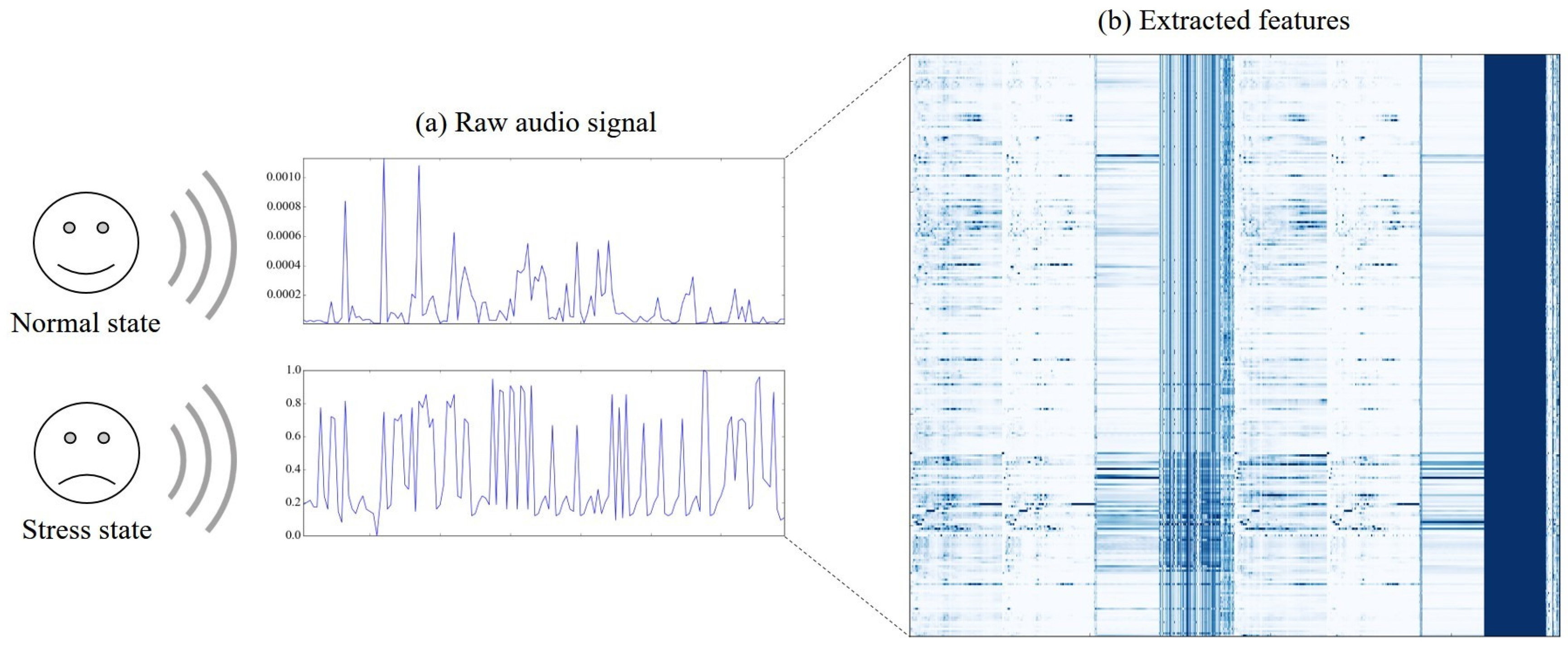
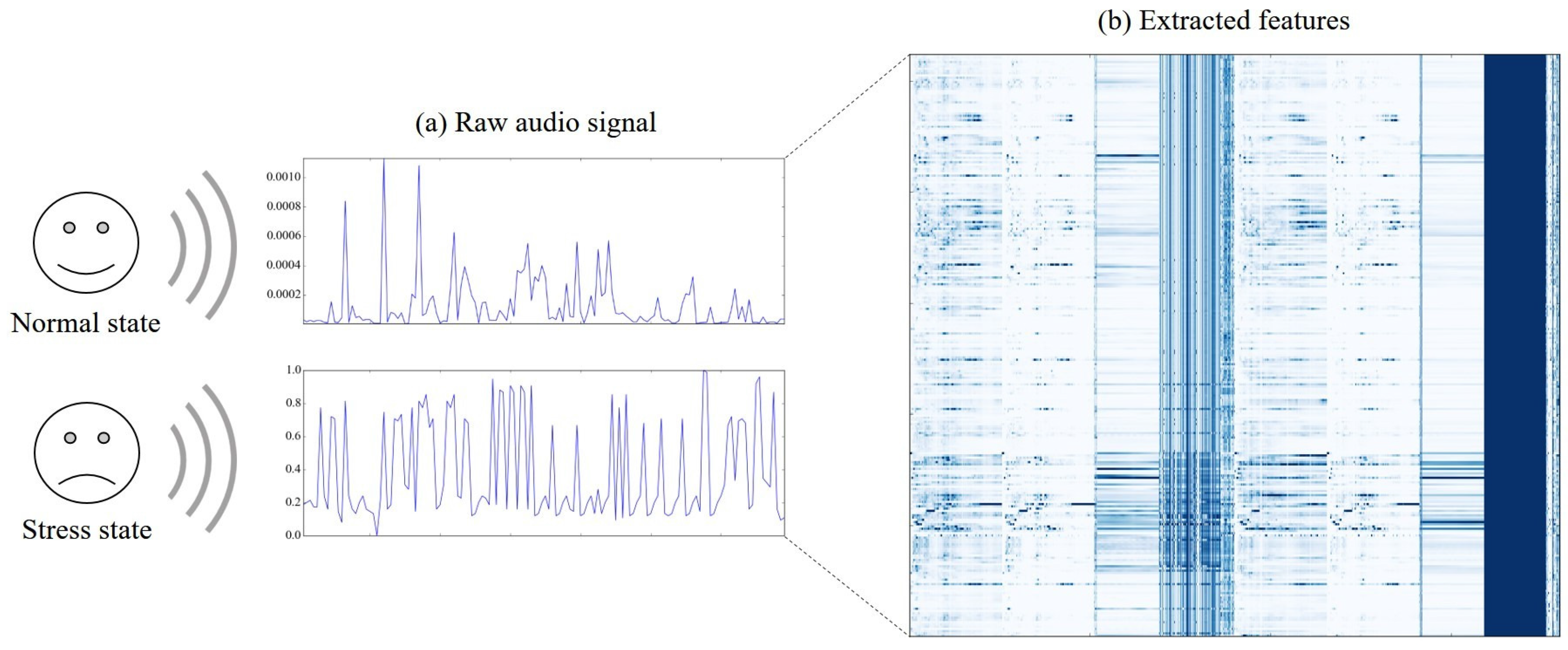
3.2.2. Feature Extraction
3.2.3. Feature Selection
- Chi-square-based selectionCHI utilizes the correlation between a feature and stress states by measuring the divergence of observed data from the expected distribution which assumes that the feature and labels are independent. The score for CHI is obtained as the sum of the square of the difference between observed value and expected value of a feature over the expected value. According to the score, the predefined number of features, denoted by , are selected.
- Information gain-based selectionIG evaluates a feature by measuring the information gain with respect to the stress states. The score for IG is obtained as the difference in entropy when a feature is given or not. According to the score, the top features are selected.
- SVM wrapper-based selectionSVMW utilizes SVM as a classifier for the performance evaluation of subsets. For the subset generation, a best-first search is utilized, which known to work best for SVM [20]. Accuracy is adopted as an evaluation metric. According to the accuracy obtained by classification using subsets, the features included in the best subset are selected.
3.2.4. Detection Model Training
- Decision tree-based detectionDT is a tree-shaped classifier where each node is composed of a feature and a corresponding classification value.When an instance is given to the root node, each node classifies the instance according to its feature and value pair. We utilized the C4.5 algorithm [26] which is an extension of ID3 [27] to handle continuous features as we examine time-series signals for the detection. The Gini index was adopted for the feature selection in each node.
- Naive Bayes-based detectionNB [28] uses Bayes’ rule for the computation of the probability of a given to be in . A formal representation of the probability is shown in Equation (2). It assumes that, given a label, features are conditionally independent. The probabilities for features are estimated from data using maximum likelihood estimation.
- Support vector machine-based detectionSVM [29] is one of the most well-known machine learning methods, and is widely applied to diverse domains (e.g., document classification) [30]. It finds the maximum margin among instances of normal and stress states. As a result, SVM shows relatively stable performances regardless of the number of training data and features. Equation (3) is a Lagrangian dual problem of the objective function of SVM. The optimal solution can be obtained by solving a quadratic programming.SVM has the advantage that it is able to classify data which are not linearly separated by using kernel function which maps a vector into a higher dimension. In this paper, we considered radial and linear kernels for comparison, and named them as SVM-R and SVM-L, respectively.
3.2.5. Stress Detection
4. Experiment
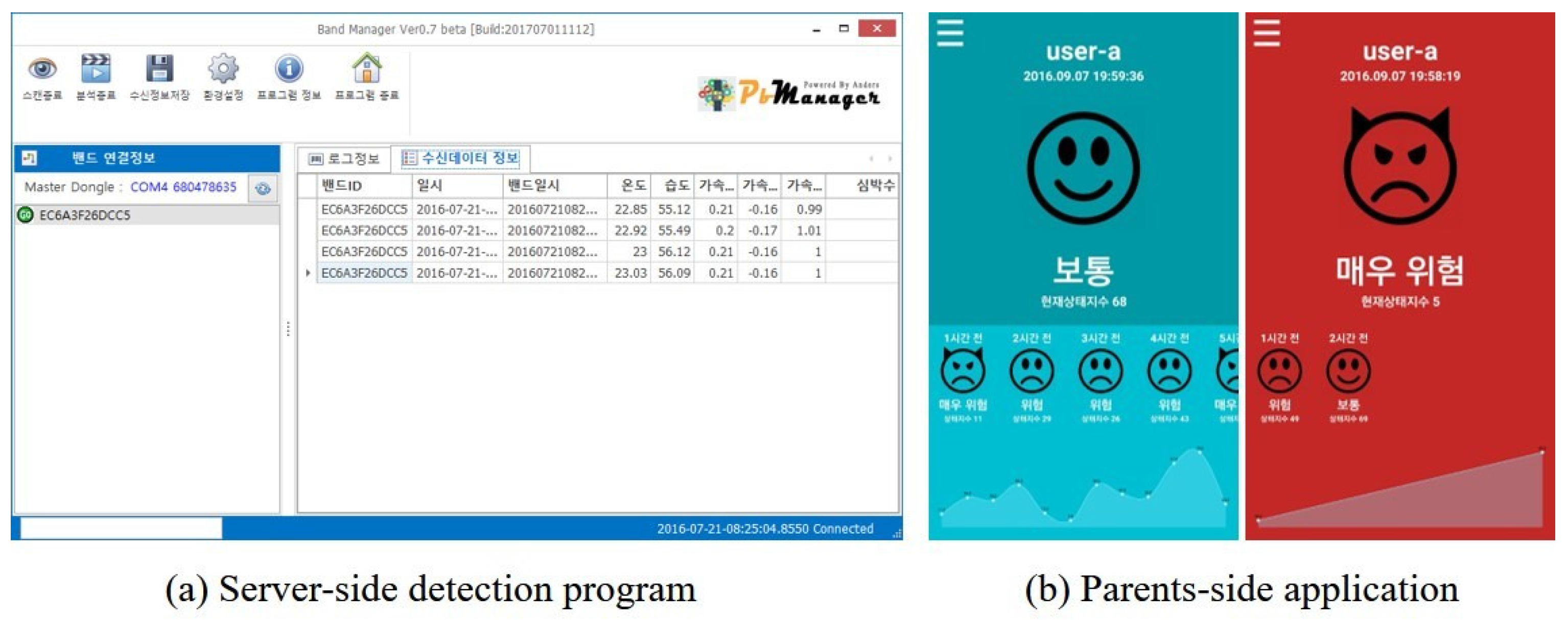
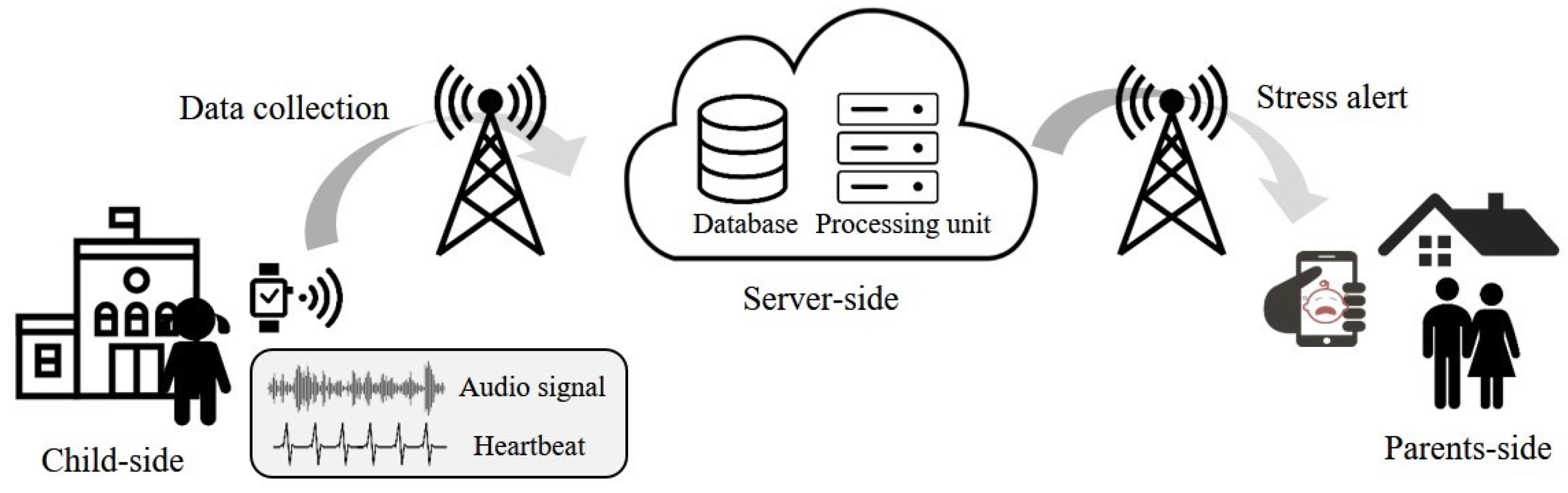
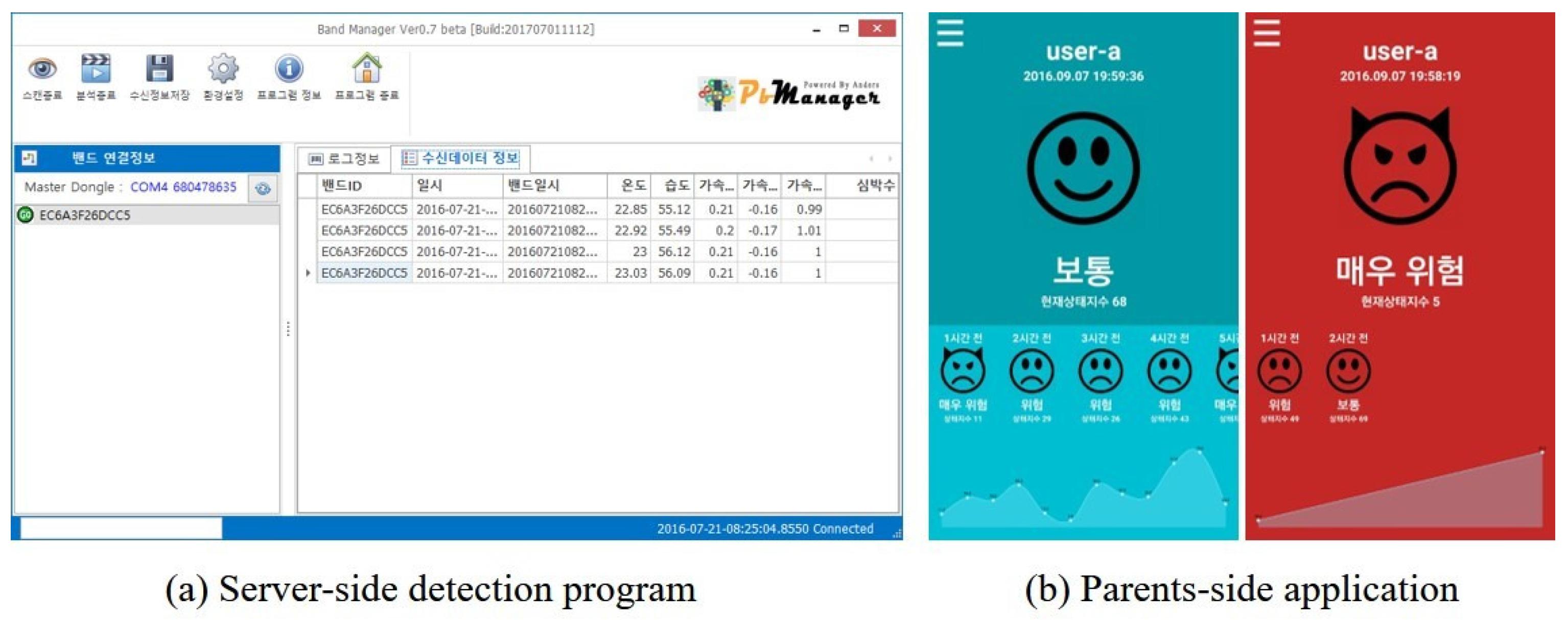
4.1. Stress Detection Device Prototype
4.2. Experiment Settings
4.3. Experimental Results
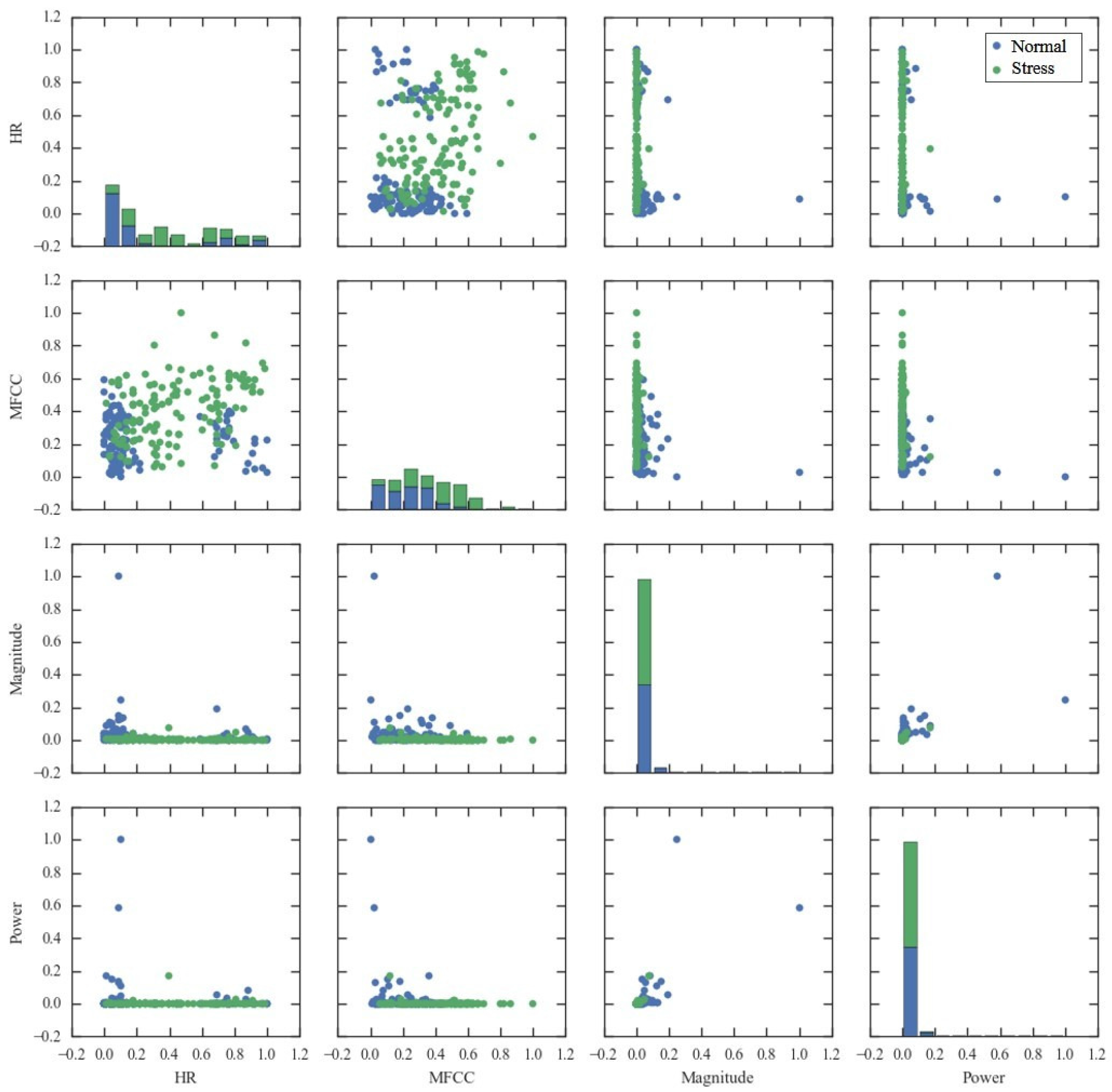
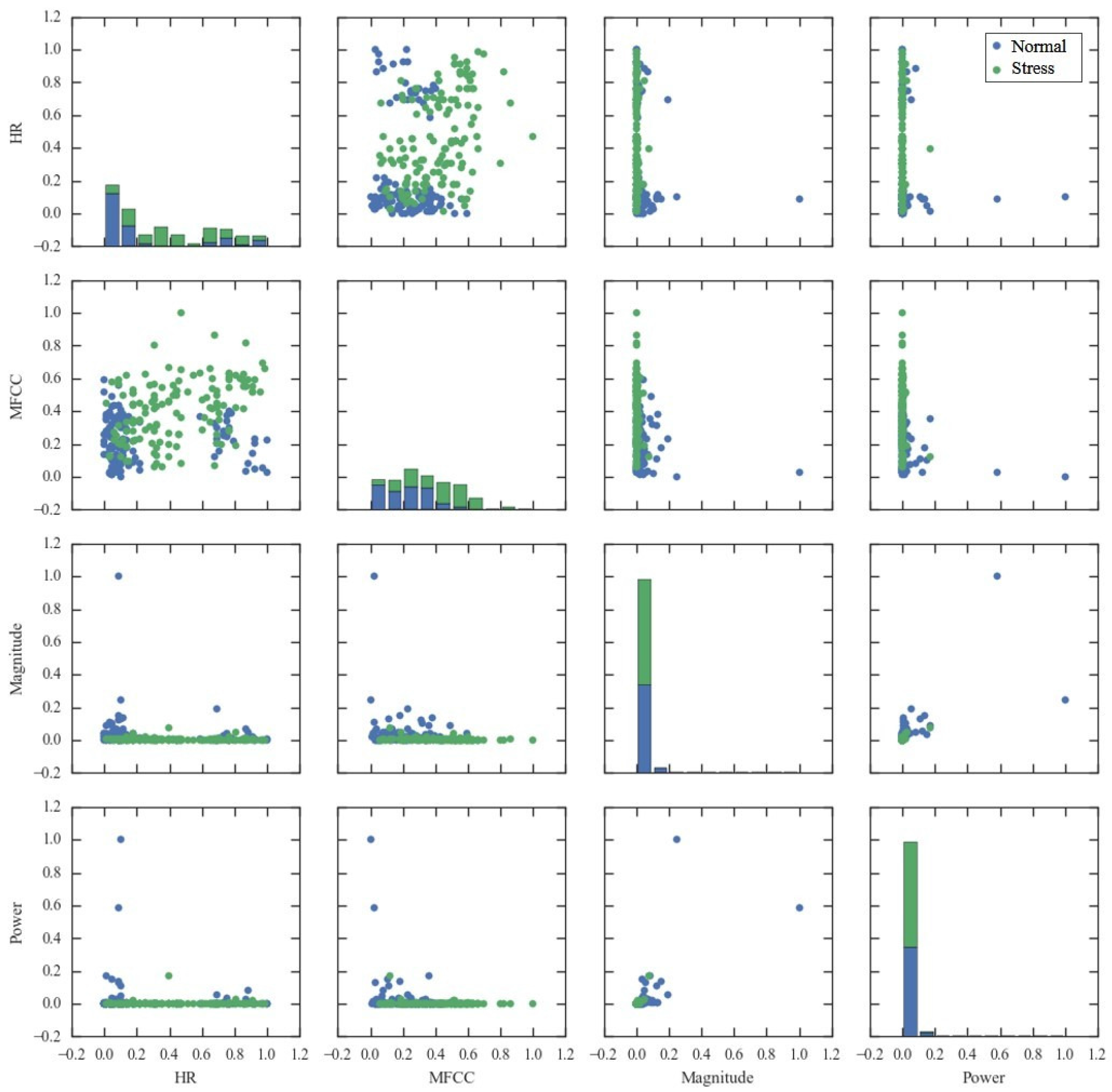
4.3.1. Feature Selection
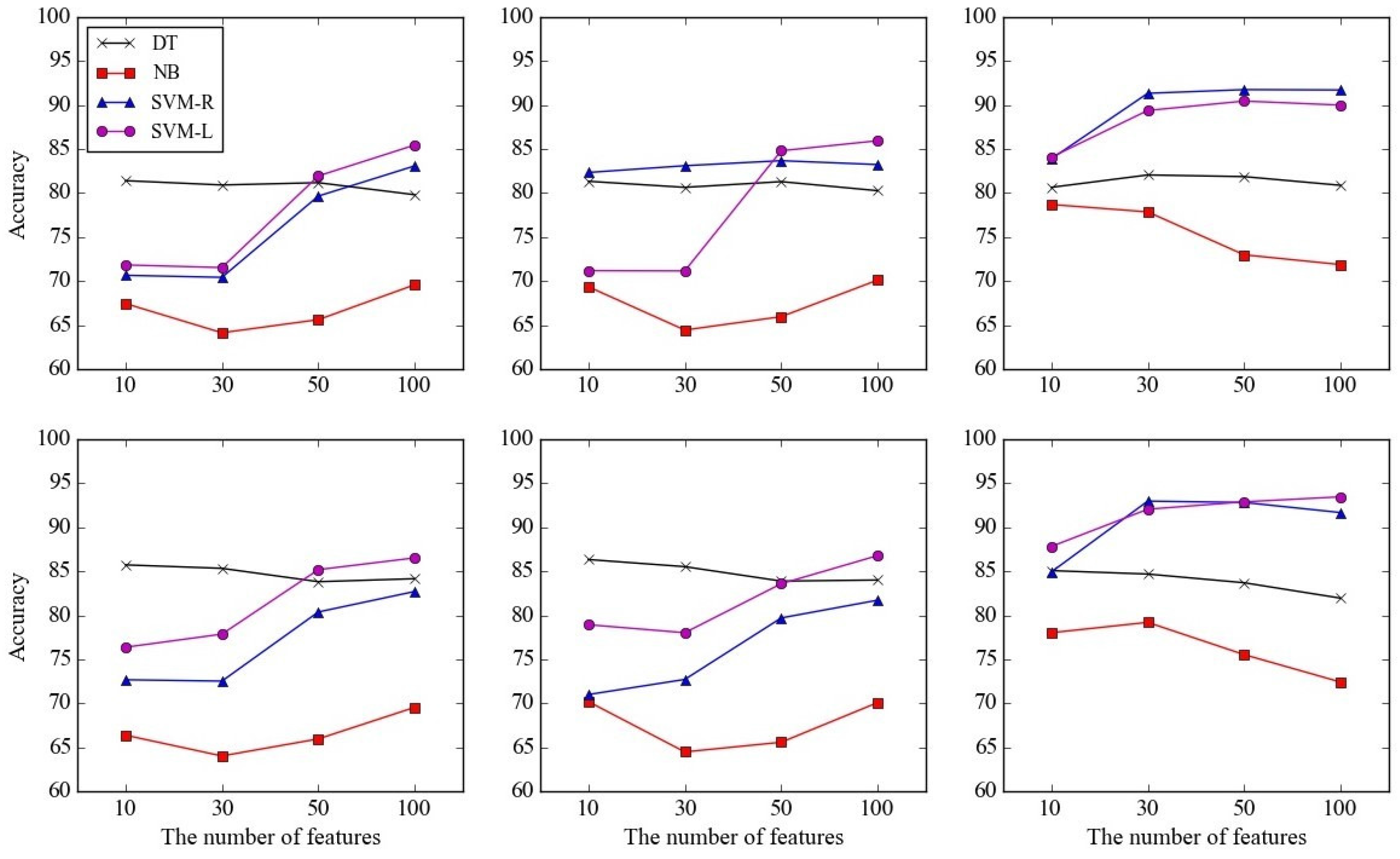
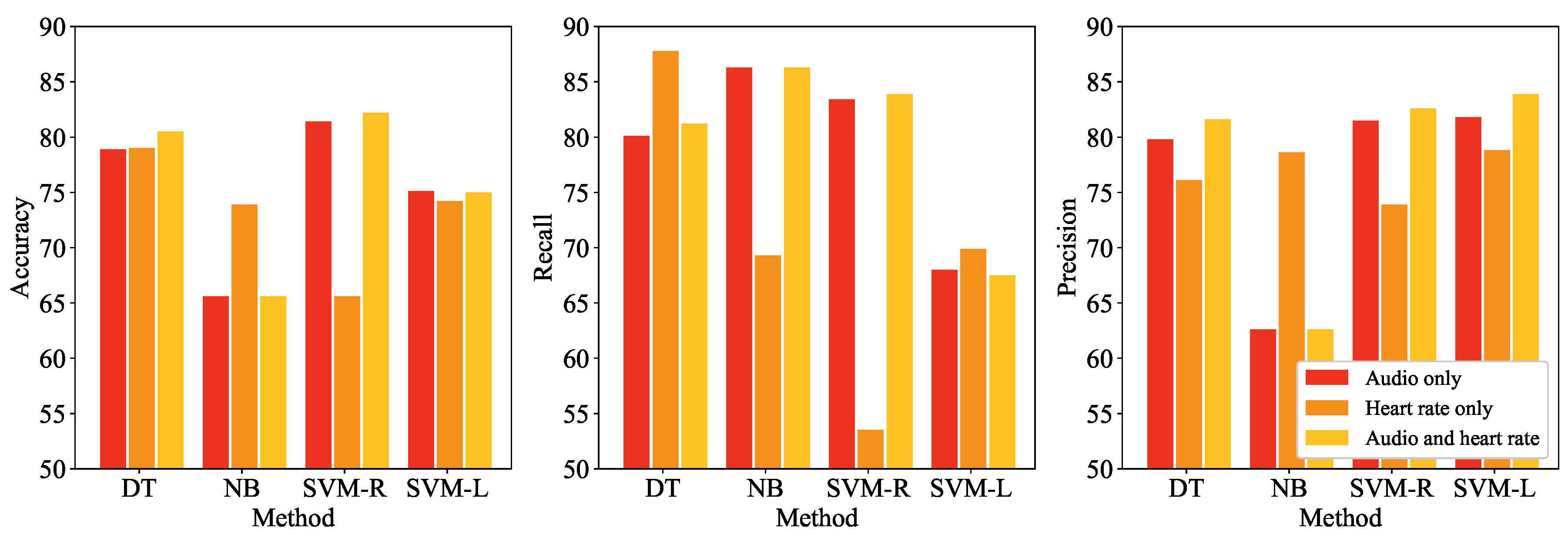
4.3.2. Performance Comparison
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ryu, J. Child Maltreatment and Improvement Direction for Child Protection System. In Health and Welfare Policy Forum; Korea Institute for Health and Social Affairs: Seoul, Korea, 2017; pp. 5–23. [Google Scholar]
- Abou-Abbas, L.; Alaie, H.F.; Tadj, C. Automatic detection of the expiratory and inspiratory phases in newborn cry signals. Biomed. Signal Process. Control 2015, 19, 35–43. [Google Scholar] [CrossRef]
- Rosales-Pérez, A.; Reyes-García, C.A.; Gonzalez, J.A.; Reyes-Galaviz, O.F.; Escalante, H.J.; Orlandi, S. Classifying infant cry patterns by the Genetic Selection of a FuzzyModel. Biomed. Signal Process. Control 2015, 17, 38–46. [Google Scholar] [CrossRef]
- Cohen, R.; Lavner, Y. Infant cry analysis and detection. In Proceedings of the IEEE Convention of Electrical Electronics Engineers in Israel, Eilat, Israel, 14–17 November 2012; pp. 1–5. [Google Scholar]
- Ruvolo, P.; Movellan, J. Automatic cry detection in early childhood education settings. In Proceedings of the IEEE International Conference on Development and Learning, Monterey, CA, USA, 9–12 August 2008; pp. 204–208. [Google Scholar]
- Melillo, P.; Bracale, M.; Pecchia, L. Nonlinear Heart Rate Variability features for real-life stress detection. Case study: Students under stress due to university examination. Biomed. Eng. Online 2011, 10. [Google Scholar] [CrossRef] [PubMed]
- Riganello, F.; Sannita, W.G. Residual brain processing in the vegetative state. J. Psychophysiol. 2009, 23, 18–26. [Google Scholar] [CrossRef]
- Kurniawan, H.; Maslov, A.V.; Pechenizkiy, M. Stress detection from speech and Galvanic Skin Response signals. In Proceedings of the IEEE International Symposium on Computer-Based Medical Systems, Porto, Portugal, 20–22 June 2013; pp. 209–214. [Google Scholar]
- Setz, C.; Arnrich, B.; Schumm, J.; La Marca, R.; Tröster, G.; Ehlert, U. Discriminating stress from cognitive load using a wearable EDA device. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 410–417. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.T.; Kuo, C.; Cheng, H.T.; Buthpitiya, S.; Collins, P.; Griss, M. Activity-aware mental stress detection using physiological sensors. In Proceedings of the International Conference on Mobile Computing, Applications, and Services, Santa Clara, CA, USA, 25–28 October 2010; pp. 211–230. [Google Scholar]
- Bakker, J.; Pechenizkiy, M.; Sidorova, N. What’s Your Current Stress Level? Detection of Stress Patterns from GSR Sensor Data. In Proceedings of the IEEE International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 573–580. [Google Scholar]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Tsapeli, F.; Musolesi, M. Investigating causality in human behavior from smartphone sensor data: A quasi-experimental approach. EPJ Data Sci. 2015, 4, 24. [Google Scholar] [CrossRef]
- Fletcher, R.R.; Dobson, K.; Goodwin, M.S.; Eydgahi, H.; Wilder-Smith, O.; Fernholz, D.; Kuboyama, Y.; Hedman, E.B.; Poh, M.Z.; Picard, R.W. iCalm: Wearable sensor and network architecture for wirelessly communicating and logging autonomic activity. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 215–223. [Google Scholar] [CrossRef] [PubMed]
- App Paired With Sensor Measures Stress and Delivers Advice to Cope in Real Time. Available online: http://jacobsschool.ucsd.edu/news/news_releases/release.sfe?id=1526 (accessed on 23 August 2017).
- Birvinskas, D.; Jusas, V.; Martisius, I.; Damasevicius, R. EEG dataset reduction and feature extraction using discrete cosine transform. In Proceedings of the European Symposium on Computer Modeling and Simulation, Valetta, Malta, 14–16 November 2012; pp. 199–204. [Google Scholar]
- Frigui, H.; Nasraoui, O. Unsupervised learning of prototypes and attribute weights. Pattern Recognit. 2004, 37, 567–581. [Google Scholar] [CrossRef]
- Geng, X.; Liu, T.Y.; Qin, T.; Li, H. Feature selection for ranking. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 407–414. [Google Scholar]
- Mcennis, D.; Mckay, C.; Fujinaga, I. JAudio: A feature extraction library. In Proceedings of the International Conference on Music Information Retrieval, London, UK, 11–15 September 2005. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Forman, G. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 2003, 3, 1289–1305. [Google Scholar]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; pp. 137–142. [Google Scholar]
- Bogomolov, A.; Lepri, B.; Larcher, R.; Antonelli, F.; Pianesi, F.; Pentland, A. Energy consumption prediction using people dynamics derived from cellular network data. EPJ Data Sci. 2016, 5, 13. [Google Scholar] [CrossRef]
- Ribeiro, F.N.; Araújo, M.; Gonçalves, P.; André Gonçalves, M.; Benevenuto, F. SentiBench—A benchmark comparison of state-of-the-practice sentiment analysis methods. EPJ Data Sci. 2016, 5, 1–29. [Google Scholar] [CrossRef]
- Sarigöl, E.; Pfitzner, R.; Scholtes, I.; Garas, A.; Schweitzer, F. Predicting scientific success based on coauthorship networks. EPJ Data Sci. 2014, 3, 9. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Anderson, J.R.; Matessa, M. Explorations of an incremental, Bayesian algorithm for categorization. Mach. Learn. 1992, 9, 275–308. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Kim, K.; Chung, B.S.; Choi, Y.; Lee, S.; Jung, J.Y.; Park, J. Language independent semantic kernels for short-text classification. Expert Syst. Appl. 2014, 41, 735–743. [Google Scholar] [CrossRef]
- Stock Music and Sound Effects for Creative Projects. Available online: http://www.audiomicro.com/ (accessed on 23 August 2017).
- Adobe Audition. Available online: http://www.adobe.com/kr/products/audition.html (accessed on 23 August 2017).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | Method | Data | References |
|---|---|---|---|
| Child | Machine learning | Audio signal | [2] |
| [3] | |||
| [4] | |||
| [5] | |||
| Adult | Machine learning | Electrodermal data | [8] |
| [9] | |||
| [10] | |||
| Heart rate | [6] | ||
| [7] | |||
| Audio signal etc. | [8] | ||
| [10] | |||
| Index-based | Electrodermal data etc. | [11] | |
| [12] | |||
| [13] |
| Proposed Framework | iCalm | ParentGuardian | |
|---|---|---|---|
| Target | Infants, children | Infants, children, adults | ADHD children |
| Data | Audio signal, Heart rate | Temperature Motion Electrodermal data Blood volume pulse | Electrodermal data |
| Wearable design | Wrist | Wrist, foot | Wrist |
| Power Spectrum | Spectral Flux | Fraction of Low-Energy Frames |
| Magnitude Spectrum | Partial-Based Spectral Flux | Linear Prediction Filter Coefficients |
| Magnitude Spectrum Peaks | Method of Moments | Beat Histogram |
| Spectral Variability | Area Method of Moments | Strongest Beat |
| Spectral Centroid | MFCC | Beat Sum |
| Partial-Based Spectral Centroid | Area Method of Moments of MFCCs | Strength of Strongest Beat |
| Partial-Based Spectral Smoothness | Zero Crossings | Strongest Frequency via Zero Crossings |
| Compactness | RMS | Strongest Frequency via Spectral Centroid |
| Spectral Roll-off Point | Relative Difference Function | Strongest Frequency via FFT Maximum |
| Predicted State | |||
|---|---|---|---|
| Stress | Normal | ||
| Actual state | Stress | True positive (TP) | False positive (FP) |
| Normal | False negative (FN) | True negative (TN) | |
| Rank | CHI | IG | SVMW |
|---|---|---|---|
| 1 | Heart rate | Heart rate | MFCC overall standard deviation |
| 2 | MFCC overall standard deviation | MFCC overall standard deviation | Spectral flux overall standard deviation |
| 3 | Magnitude spectrum overall average | Magnitude spectrum overall average | Strongest beat overall average |
| 4 | Power spectrum overall average | MFCC overall average | Magnitude spectrum overall standard deviation |
| 5 | MFCC overall average | Power spectrum overall average | Compactness overall average |
| Data | Model | t | p-Value | Mean Difference |
|---|---|---|---|---|
| Audio only | NB and DT | −30.87 | 0.00 | −14.89 |
| NB and SVM-L | −24.06 | 0.00 | −9.46 | |
| NB and SVM-R | −33.86 | 0.00 | −16.60 | |
| DT and SVM-L | 8.23 | 0.00 | 5.42 | |
| DT and SVM-R | −2.10 | 0.07 | −1.72 | |
| SVM-L and SVM-R | −13.00 | 0.00 | −7.14 | |
| Heart rate only | NB and DT | −25.88 | 0.00 | −5.15 |
| NB and SVM-L | −3.25 | 0.01 | −0.35 | |
| NB and SVM-R | 87.20 | 0.00 | 8.32 | |
| DT and SVM-L | 26.42 | 0.00 | 4.81 | |
| DT and SVM-R | 71.24 | 0.00 | 13.47 | |
| SVM-L and SVM-R | 76.02 | 0.00 | 8.67 | |
| Audio and heart rate | NB and DT | −26.65 | 0.00 | −13.28 |
| NB and SVM-L | −19.11 | 0.00 | −9.54 | |
| NB and SVM-R | −31.43 | 0.00 | −15.80 | |
| DT and SVM-L | 4.76 | 0.00 | 3.74 | |
| DT and SVM-R | −3.10 | 0.01 | −2.52 | |
| SVM-L and SVM-R | −7.84 | 0.00 | −6.26 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, Y.; Jeon, Y.-M.; Wang, L.; Kim, K. A Biological Signal-Based Stress Monitoring Framework for Children Using Wearable Devices. Sensors 2017, 17, 1936. https://doi.org/10.3390/s17091936
Choi Y, Jeon Y-M, Wang L, Kim K. A Biological Signal-Based Stress Monitoring Framework for Children Using Wearable Devices. Sensors. 2017; 17(9):1936. https://doi.org/10.3390/s17091936
Chicago/Turabian StyleChoi, Yerim, Yu-Mi Jeon, Lin Wang, and Kwanho Kim. 2017. "A Biological Signal-Based Stress Monitoring Framework for Children Using Wearable Devices" Sensors 17, no. 9: 1936. https://doi.org/10.3390/s17091936
APA StyleChoi, Y., Jeon, Y.-M., Wang, L., & Kim, K. (2017). A Biological Signal-Based Stress Monitoring Framework for Children Using Wearable Devices. Sensors, 17(9), 1936. https://doi.org/10.3390/s17091936