FedMed: A Federated Learning Framework for Language Modeling




Abstract
:1. Introduction
- We design a novel federated learning framework, namely FedMed, to improve the overall performance in language modeling.
- We first propose the adaptive aggregation and mediation incentive scheme for efficient aggregation and the topK strategy to reduce communication cost, respectively.
- A range of experiments are conducted on the FedMed. Its effectiveness and generalization is proved on three benchmark datasets.
2. Related work
2.1. Federated and Distributed Learning
2.2. Language Modeling
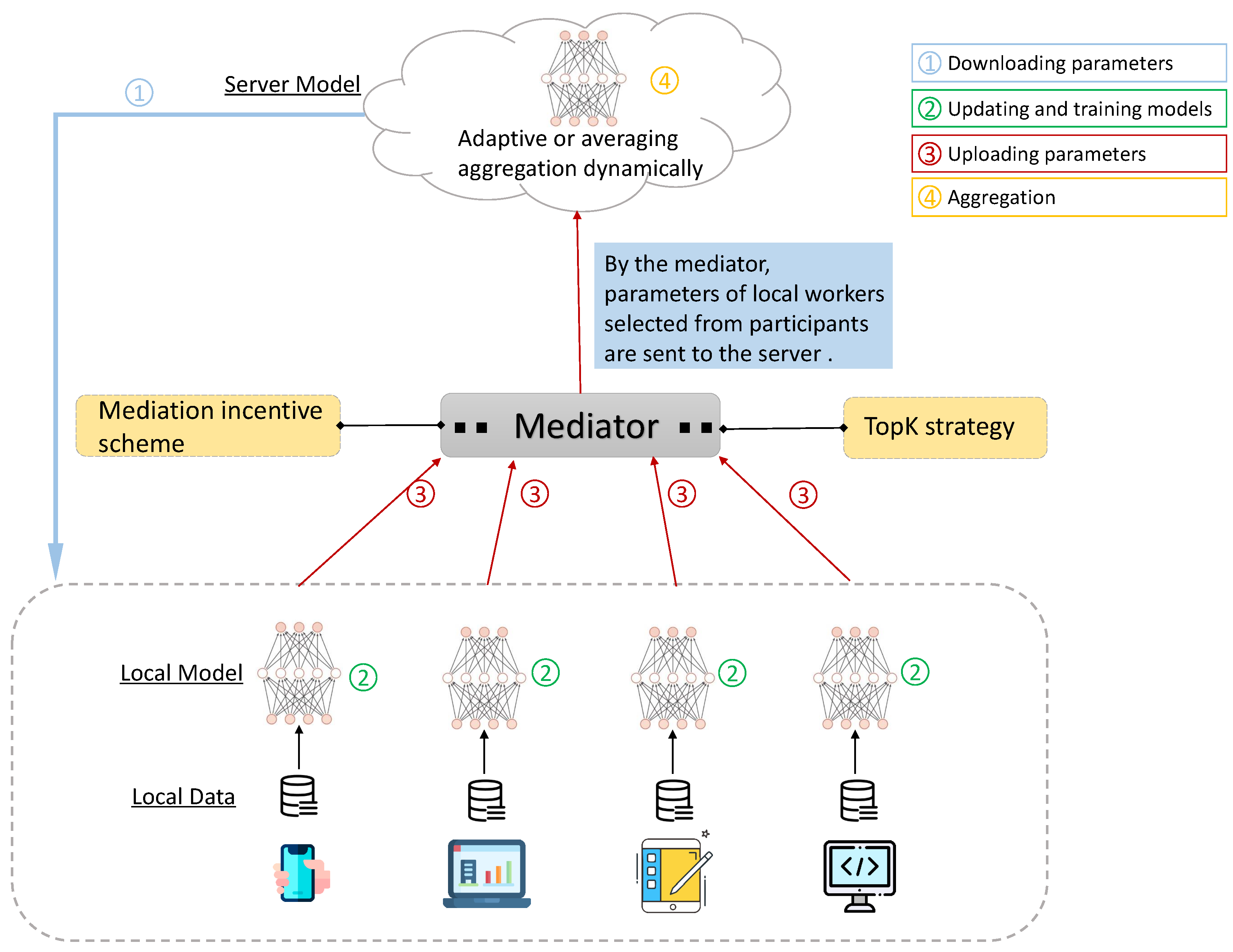
3. Proposed Method
3.1. Preliminaries
3.2. Adaptive Aggregation in FedMed
3.3. Mediation Incentive Scheme in FedMed
| Algorithm 1 FedMed. p is the size of workers for training, E is the size of local epochs; the U workers are indexed by u, and indicates the choice of adaptive aggregation or FedAvg. |
| 1: procedure SERVERUPDATE: 2: Initialize 3: for each round do 4: max 5: (random p workers) 6: for each worker in parallel do 7: WorkerUpdate 8: end for 9: //Implement mediation incentive scheme 10: alteration of two losses 11: 12: if is 1 then 13: Adaptive aggregation 14: else 15: 16: end if 17: end for 18: end procedure |
| 19: procedure WorkerUpdate() 20: //Run on worker u 21: (split data into batches size of B) 22: for each local epoch i from 1 to do 23: for batch do 24: 25: end for 26: end for 27: return w to server 28: end procedure |
3.4. TopK Strategy in FedMed
4. Evaluation
4.1. Datasets
4.2. Settings
- FedSGD: Federated stochastic gradient descent involves all local workers in models aggregation, and local training runs one iteration of gradient descent.
- FedAvg: Global server computes averaging parameters from local workers each round, and local training runs several iterations of gradient descent.
- FedAtt: Global server adopts attentive aggregation for federated optimization each round, and local training keeps a comparable presetting as FedAvg.
- FedMed: Our proposed FedMed develops a novelty aggregation method for federated learning each round, and the local worker keeps a comparable presetting as FedAvg.
4.3. Results
4.3.1. Perplexity Comparison
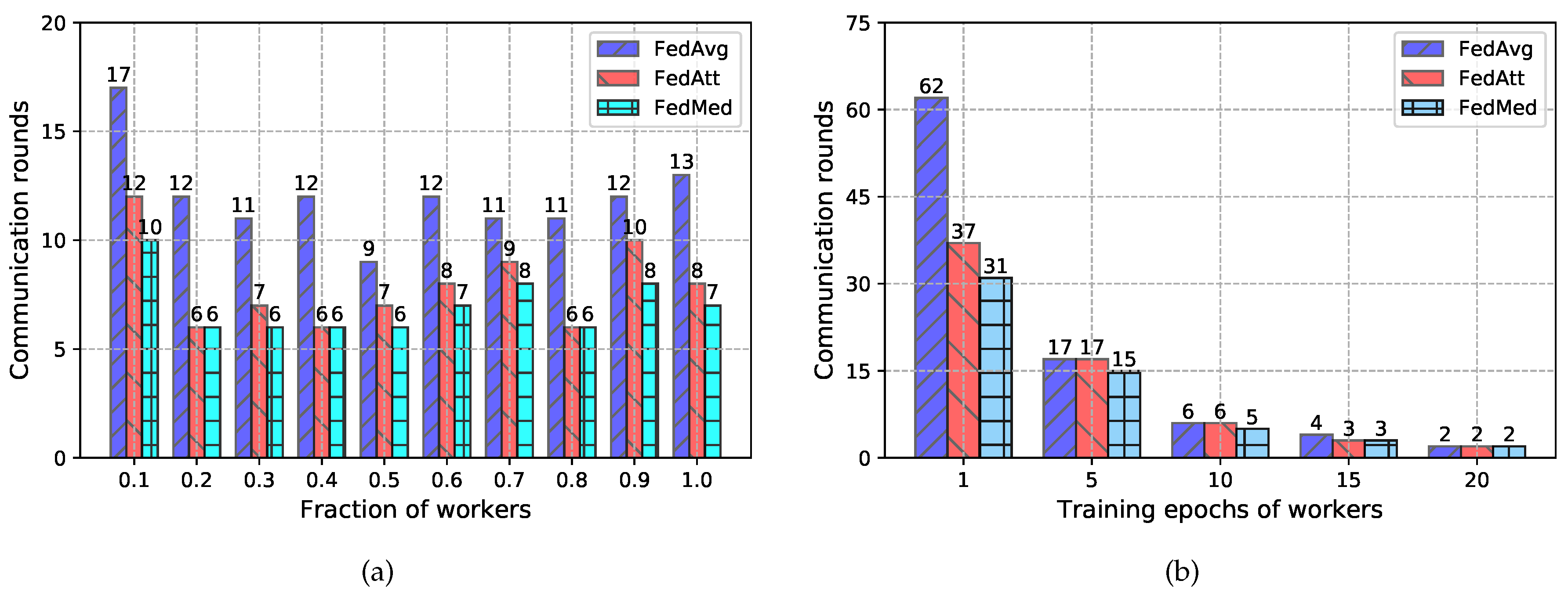
4.3.2. Communication Efficiency
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| LSTM | Long Short-Term Memory |
| PPL | Perplexity |
| JS | Jensen-Shannon |
| FL | Federated Learning |
| SGD | Stochastic Gradient Descent |
References
- Bisio, I.; Garibotto, C.; Lavagetto, F.; Sciarrone, A. Towards IoT-Based eHealth Services: A Smart Prototype System for Home Rehabilitation. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Wu, F.; Wu, T.; Yuce, M.R. Design and Implementation of a Wearable Sensor Network System for IoT-Connected Safety and Health Applications. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019. [Google Scholar]
- Hassani, A.; Haghighi, P.D.; Ling, S.; Jayaraman, P.P.; Zaslavsky, A.B. Querying IoT services: A smart carpark recommender use case. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018. [Google Scholar]
- Zaidan, A.A.; Zaidan, B.B. A review on intelligent process for smart home applications based on IoT: Coherent taxonomy, motivation, open challenges, and recommendations. Artif. Intell. Rev. 2020, 53, 141–165. [Google Scholar] [CrossRef]
- Williams, R.J.; Zipser, D. A Learning Algorithm for Continually Running Fully Recurrent Neural Networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Yu, S.; Kulkarni, N.; Lee, H.; Kim, J. On-Device Neural Language Model Based Word Prediction. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations, Santa Fe, NM, USA, 20–26 August 2018. [Google Scholar]
- Cattle, A.; Ma, X. Predicting Word Association Strengths. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Yi, J.; Tao, J. Self-attention Based Model for Punctuation Prediction Using Word and Speech Embeddings. In Proceedings of the ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When Edge Meets Learning: Adaptive Control for Resource-Constrained Distributed Machine Learning. In Proceedings of the IEEE INFOCOM 2018 - IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Fantacci, R.; Picano, B. Federated learning framework for mobile edge computing networks. CAAI Trans. Intell. Technol. 2020, 5, 15–21. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.; Samek, W. Robust and Communication-Efficient Federated Learning From Non-i.i.d. Data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.; Wang, W.; Li, B. CMFL: Mitigating Communication Overhead for Federated Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; McMahan, B.; et al. Towards Federated Learning at Scale: System Design. In Proceedings of the Machine Learning and Systems 2019, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, A.; Luo, Y.; Huang, H.; Liu, Y.; Chen, Y.; Feng, L.; Chen, T.; Yu, H.; Yang, Q. FedVision: An Online Visual Object Detection Platform Powered by Federated Learning. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Lu, S.; Zhang, Y.; Wang, Y. Decentralized Federated Learning for Electronic Health Records. In Proceedings of the 2020 54th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 18–20 March 2020. [Google Scholar]
- Zhang, J.; Chen, B.; Yu, S.; Deng, H. PEFL: A Privacy-Enhanced Federated Learning Scheme for Big Data Analytics. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Lim, H.; Kim, J.; Heo, J.; Han, Y. Federated Reinforcement Learning for Training Control Policies on Multiple IoT Devices. Sensors 2020, 20, 1359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, D.; Dligach, D.; Miller, T.A. Two-stage Federated Phenotyping and Patient Representation Learning. In Proceedings of the 18th ACL Workshop on Biomedical Natural Language Processing, Florence, Italy, 1 August 2019. [Google Scholar]
- Xiao, P.; Cheng, S.; Stankovic, V.; Vukobratovic, D. Averaging is probably not the optimum way of aggregating parameters in federated learning. Entropy 2020, 22, 314. [Google Scholar] [CrossRef] [Green Version]
- Yurochkin, M.; Agarwal, M.; Ghosh, S.; Greenewald, K.; Hoang, N.; Khazaeni, Y. Bayesian Nonparametric Federated Learning of Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Ji, S.; Pan, S.; Long, G.; Li, X.; Jiang, J.; Huang, Z. Learning private neural language modeling with attentive aggregation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Yao, X.; Huang, C.; Sun, L. Two-stream federated learning: Reduce the communication costs. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018. [Google Scholar]
- Vogels, T.; Karimireddy, S.P.; Jaggi, M. PowerSGD: Practical low-rank gradient compression for distributed optimization. In Proceedings of the 2019 Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Lin, Y.; Han, S.; Mao, H.; Wang, Y.; Dally, B. Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gerz, D.; Vulić, I.; Ponti, E.; Naradowsky, J.; Reichart, R.; Korhonen, A. Language modeling for morphologically rich languages: Character-aware modeling for word-level prediction. Trans. Assoc. Comput. Ling. 2018, 6, 451–465. [Google Scholar] [CrossRef] [Green Version]
- Lam, M.W.Y.; Chen, X.; Hu, S.; Yu, J.; Liu, X.; Meng, H. Gaussian Process Lstm Recurrent Neural Network Language Models for Speech Recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Ma, K.; Leung, H. A Novel LSTM Approach for Asynchronous Multivariate Time Series Prediction. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Aina, L.; Gulordava, K.; Boleda, G. Putting Words in Context: LSTM Language Models and Lexical Ambiguity. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 308–318. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ketkar, N. Introduction to pytorch. In Deep Learning with Python; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.M.; Józefowicz, R.; Bengio, S. Generating Sentences from a Continuous Space. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016. [Google Scholar]
- Marcus, M.P.; Santorini, B.; Marcinkiewicz, M.A. Building a Large Annotated Corpus of English: The Penn Treebank. Comput. Ling. 1993, 19, 313–330. [Google Scholar]
- Xu, J.; Chen, D.; Qiu, X.; Huang, X. Cached Long Short-Term Memory Neural Networks for Document-Level Sentiment Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Merity, S.; Xiong, C.; Bradbury, J.; Socher, R. Pointer Sentinel Mixture Models. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Valid. | Test |
|---|---|---|---|
| PTB | 887,521 | 70,390 | 78,669 |
| Yelp | 3,063,578 | 380,877 | 424,879 |
| WikiText-2 | 2,088,628 | 217,646 | 245,569 |
| Frac. | Method | WikiText-2 | PTB | Yelp |
|---|---|---|---|---|
| 1 | FedSGD | 38.41 | ||
| FedAVG | 34.42 | |||
| 0.1 | FedAtt | 32.02 | ||
| FedMed | 80.32 | 113.03 | 31.90 | |
| FedAVG | 32.43 | |||
| 0.5 | FedAtt | 31.93 | ||
| FedMed | 68.42 | 122.23 | 30.50 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Liang, Z.; Wang, J. FedMed: A Federated Learning Framework for Language Modeling. Sensors 2020, 20, 4048. https://doi.org/10.3390/s20144048
Wu X, Liang Z, Wang J. FedMed: A Federated Learning Framework for Language Modeling. Sensors. 2020; 20(14):4048. https://doi.org/10.3390/s20144048
Chicago/Turabian StyleWu, Xing, Zhaowang Liang, and Jianjia Wang. 2020. "FedMed: A Federated Learning Framework for Language Modeling" Sensors 20, no. 14: 4048. https://doi.org/10.3390/s20144048
APA StyleWu, X., Liang, Z., & Wang, J. (2020). FedMed: A Federated Learning Framework for Language Modeling. Sensors, 20(14), 4048. https://doi.org/10.3390/s20144048