1. Introduction
Since the first cases of COVID-19 were registered in a hospital in Wuhan City, China [
1,
2] in December 2019, more than 122 million confirmed cases and 2.7 million deaths worldwide have been reported to the World Health Organization (WHO) [
3]. Currently, the disease continues to spread, and new virus variants, some of them more resistant to antibody neutralization, are appearing rapidly. Additionally, these variants have a higher transmission rate [
4,
5,
6], leading to the appearance of new epidemic outbreaks in various parts of the globe [
7], potentially overloading the entire health system.
COVID-19 transmission is difficult to control. It depends on many aspects, being the object of study by several researchers who have proposed different artificial intelligence (AI) techniques to forecast the spread [
8,
9,
10,
11] and aid in the medical diagnosis of COVID-19 [
12,
13,
14]. Other studies have considered the impact of climatic and urban variables on the forecast models for the spread of the disease [
15,
16]. In addition to significant lifestyle changes in large cities, COVID-19 has also impacted the economy and financial markets, as investigated in [
17]. These works reflect the rapid effort of science to understand the impact caused by the disease and reinforce the importance of AI as a powerful tool in the fight against COVID-19.
Studies based on patients affected by COVID-19 indicate a high prevalence of respiratory symptoms that require a comprehensive evaluation [
18,
19]. The standard method for diagnosing the disease involves a clinical examination, performing pulmonary auscultation of the patient using a stethoscope, and then additional imaging examinations such as X-ray (XR) and computed tomography (CT) [
20,
21]. The laboratory test known as reverse transcription-polymerase chain reaction (RT-PCR) is considered the gold standard [
22] being used to diagnosis the disease. However, this test, in addition to demanding time (about two days), presents results that indicate a low sensitivity of 70%, according to [
23], making a result confirmation necessary.
Clinical and imaging exams are prone to the spread of the virus, mainly due to the number of people in the medical team mobilized to examine and move the patient to the centers where the diagnostic imaging equipment is located. Another aspect that must be considered is the possibility of the virus spreading through the contamination of equipment and of the stethoscope itself, which needs to be sterilized at each examination [
20]. In addition to the risk of contamination, there is the fact that the stethoscope and auscultation in these cases are of low proven usefulness.
Studies indicate that thorax ultrasound can surpass the current standard of care, both in speed and diagnosis in cases of respiratory failure [
24]. Lung ultrasound (LUS) has good sensitivity in detecting lung pathology (bacterial or viral) [
25,
26]. Regarding COVID-19, studies report a high correlation between the clinical findings of the LUS and the chest CT examination [
27,
28,
29,
30,
31,
32]. In this sense, some studies suggest the use of ultrasound as an alternative to auscultation and auxiliary XR and CT exams [
33,
34,
35,
36,
37].
Ultrasound (US) has advantages that can help fight COVID-19, as it is portable, radiation-free, easy to sterilize, has a low acquisition cost, allows the examination to be performed at the bedside, and can be used by the physician without the need to mobilize other professionals [
38]. Moreover, due to the portability and low cost of US equipment, such devices enable rapid prototyping of systems that make intensive use of AI and computer vision (CV) techniques to aid in the diagnosis of COVID-19 [
39]. However, despite the advantages presented in the use of LUS images for the diagnosis of pulmonary pathology and COVID-19, few studies are exploring Deep Learning (DL) techniques compared to the number of studies performed with other medical imaging techniques such as XR and CT [
21,
40,
41,
42,
43].
DL models are currently considered state-of-the-art in many CV and medical applications. According to the review conducted in [
44], many applications surpass or equal the results obtained by human specialists. Although the use of DL has advanced in the medical field, including CAD [
45,
46,
47], the application of these techniques in US images can be considered incipient [
48]. Considering the main global issue since the last year, the COVID-19 pandemic, there are works on DL related with promising results, which corroborates the clinical findings in the area.
These techniques are predominantly applied to other types of medical imaging (XR and CT) [
21,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59], while studies that consider US imaging in their medical diagnostic models are less frequent. One of the possible causes for it is the lag of public databases available for scientific research, especially concerning LUS videos containing proved cases of COVID-19, according to a survey conducted by [
60]. Another possible cause may be that some have a concern over US studies’ quality since it is a modality dependent on the skill of the operator [
61].
In the review performed with five studies and 466 participants [
62], despite the US having a good sensitivity of 86.4% for the diagnosis of COVID-19, the specificity presented in the results was 54.6%; that is, the ability to diagnose healthy individuals is low. There is an opportunity for DL experiments to improve the ability of human experts to diagnose positive and negative cases of COVID-19.
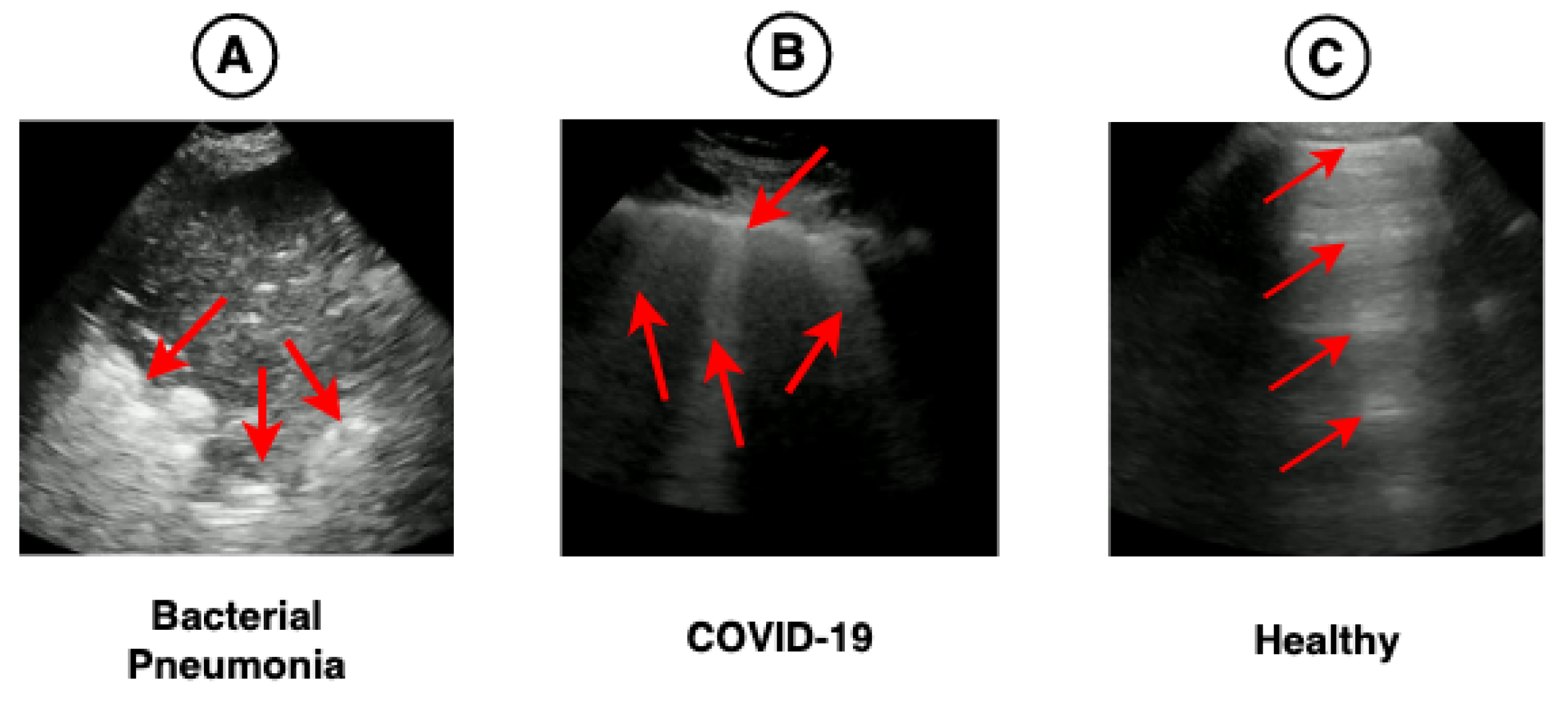
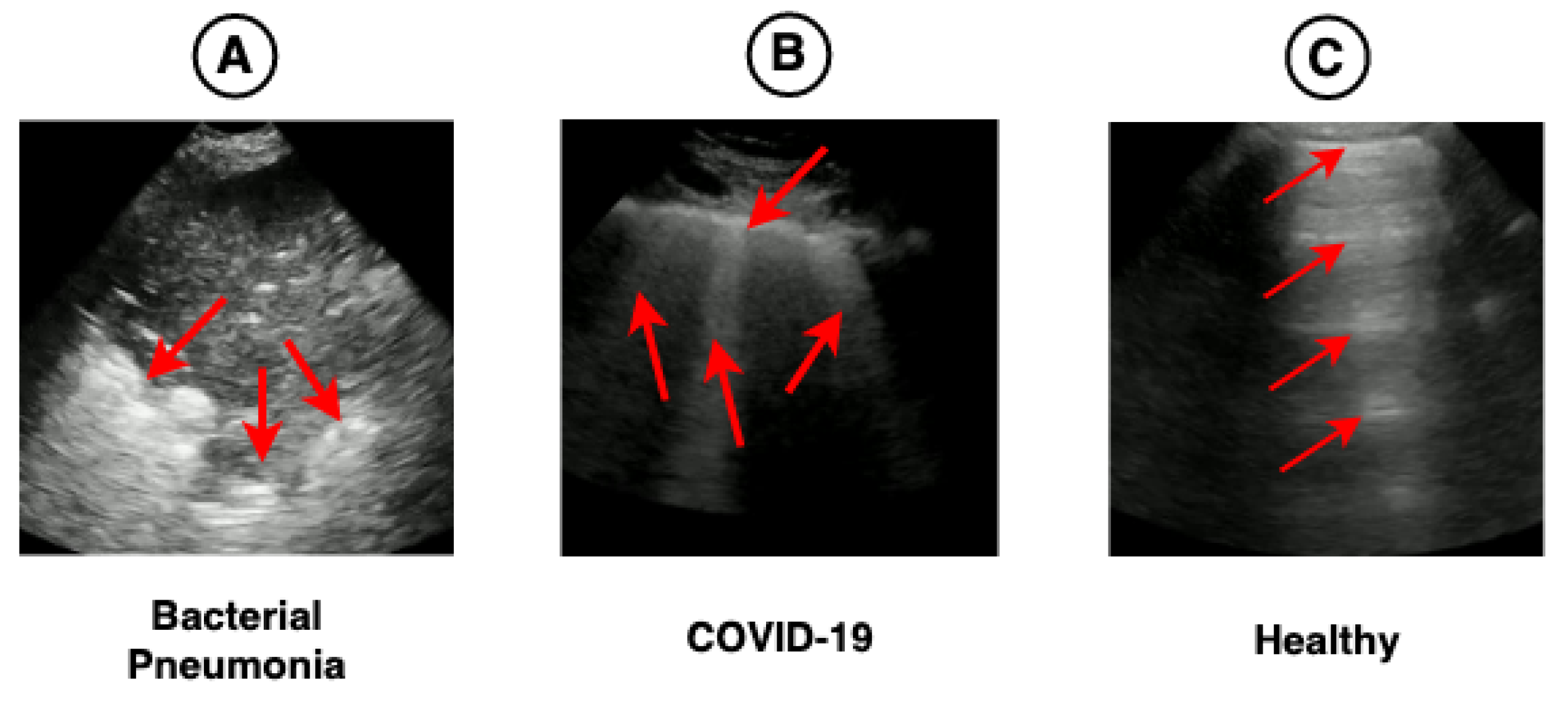
In this sense, this work proposes a hybrid model (CNN-LSTM) of video classification to aid in diagnosing COVID-19, using spatial and temporal features present in 185 LUS videos. Furthermore, this research investigates the impact of using different pre-trained CNN architectures on ImageNet and LUS images to extract spatial features. Finally, we used a technique known as Gradient-weighted Class Activation Mapping (Grad-CAM) capable of providing visual explanations about the most important parts of the images to verify whether these highlighted regions are related to the clinical findings of COVID-19, as shown in
Figure 1.
3. Related Work
Currently, the use of CNNs applied to diagnosing diseases already achieves performances comparable to human experts. Some works related to DL in the medical field have shown great potential and even outperform the metrics achieved by human experts. Among these works, the following applications are highlighted: screening for diabetic retinopathy [
117], classification of skin lesions [
118], detection of lymph node metastases [
119], and classification of pneumonia [
120].
Some studies were carried out with a focus on ultrasound images. In [
121], the authors proposed a CNN trained on short ultrasound videos of pigs with controlled pulmonary conditions to detect five features related to various types of pulmonary diseases: B-lines, merged B-lines, lack of lung sliding, consolidation, and pleural effusion. A total of 2200 LUS videos were collected from 110 exams. The proposed model reached at least 85% sensitivity for these all diseases except for B-lines and 86% specificity.
A CNN was tested to classify the presence of B-lines based on the LUS of a dataset containing 400 videos referring to emergency patients [
122]. The proposed model presented a sensitivity of 93% and specificity of 96% for the classification of B-lines (0–1) [
122].
In [
39], the authors presented an efficient and lightweight network called Mini- COVIDNet based on MobileNets, with a focus on mobile devices. The network was trained on LUS images to classify them into three classes: bacterial pneumonia, COVID-19, and healthy. As a result, the model was able to achieve an accuracy of 83% (best result). The total training time was 24 min, with a size of 51.29 MB, requiring fewer parameters in its configuration.
From data collected at the Royal Melbourne Hospital, 623 videos of LUS, containing 99,209 ultrasound images of 70 patients were used. In addition, a DL model using a Spatial Transformer Network (STN) for the automatic detection of pleural effusion focusing on COVID-19 was proposed in [
123]. The model was trained using supervised and weakly supervised approaches. Both approaches presented an accuracy above 90%, respectively (92% and 91%).
In [
124], a hybrid architecture was proposed that integrates a CNN and an LSTM to predict the severity score of COVID-19 (4 scores) based on 60 LUS videos (39 from convex transducers and 21 from linear transducers) from 29 patients. The result of the proposed model was an average accuracy of 79% for the linear transducers and 68% for the convex transducers.
A CNN model based on STNs was proposed to predict the four disease severity scores and the location of pathological artifacts in a weakly supervised way in [
125]. For the experiments, a dataset containing 277 LUS videos from 35 patients was used, corresponding to a total of 58,924 images, where 45,560 recorded from convex transducers and 13,364 acquired using linear transducers, distributed as follows: 19,973 score 0 (34%), 14,295 score 1 (24%), 18,972 score 2 (32%), 5684 score 3 (10%). The frame-based prediction result for the F1-score was 65% and for video-based prediction 61%. In segmentation, the result presented an accuracy of 96% and a Dice score of 75%. In [
52], the authors performed a study with different types of CNNs suggesting a VGG19 for classification into three classes: bacterial pneumonia, COVID-19, and healthy. The study considered XR, CT, and LUS images from datasets of different publicly available sources. This work highlights the performance of the trained model in LUS images, reaching an accuracy of 86% for training with XR, 100% for ultrasound, and 84% for CT.
Three types of CNNs (VGG-19, Resnet-101, and EfficientNet-B5) for the classification of LUS images according to eight types of clinical stages were used in [
126]. The dataset consisted of 10,350 images collected from different sources. The results showed that the CNN based on the EfficientNet-B5 architecture outperformed the others, presenting on average for classification into the eight types of clinical stages: F1-score 82%, accuracy 95%, sensitivity 82%, specificity 97%, and precision 82%. In addition, other results were presented based on the grouping types (three and four) where the average accuracy was 96% (three types) and 95% (four types).
A CNN model that uses multi-layer feature fusion for the classification of COVID-19 was presented in [
127]. The model was trained based on LUS images from convex transducers. A total of 121 videos were used, 23 with a diagnosis of bacterial pneumonia, 45 with a diagnosis of COVID-19, and 53 with a healthy diagnosis. The proposed method obtained a precision of 93% and an accuracy of 92%.
LUS images with the presence of B-lines of different etiologies were used for training a CNN in [
128]. For training, 612 videos (12,1381 images) of B-lines were used, referring to 243 patients classified into three classes: Acute Respiratory Distress Syndrome (ARDS), COVID-19, and Hydrostatic Pulmonary Edema (HPE). The result obtained showed an ability to discriminate between the three proposed classes, being the area under the receiver operator characteristic (ROC) curve (AUC) achieved: for ARDS 93%, COVID-19 100%, and HPE 100%.
In [
129], the authors proposed a frame-based model for video classification using an ImageNet pre-trained VGG16 in LUS videos. The dataset consisted of 179 videos and 53 images (convex transducers) totaling 3234 frames, where 704 frames belonged to the bacterial pneumonia class, 1204 belonged to the COVID-19 class, and 1326 frames to the healthy class. The model resulted in a mean accuracy of 90%, a sensitivity of 90%, a precision of 92%, an F1-score of 91%, and specificity of 96% for COVID-19.
4. Materials and Methods
In addition to a complete description of the approach used, the input data and the hybrid model proposed in this work were provided to readers, making this article reproducible. The data can be viewed in the open source repository
https://github.com/b-mandelbrot/pulmonary-covid19 (accessed on 9 August 2021).
4.1. Ultrasound Devices
In this work, we used videos captured with a low-frequency convex transducer. They present low resolution but are more suitable for LUS used at the bedside environment. In addition, they have a longer acoustic wavelength and provide better penetration and visualization of deeper structures. This type of transducer is, therefore, best suited for evaluating consolidations and pleural effusions [
27,
130]. On the other hand, high-frequency transducers have a high resolution compared to low-frequency transducers and are more suitable for evaluating the pleural region.
As described in
Section 4.2, due to the nature of the data source, it was impossible to verify details about the manufacturer and model of the ultrasound devices used to capture the videos, except for 20 videos belonging to the manufacturer Butterfly, representing approximately 11% of available videos.
4.2. Building the LUS Dataset
The data set used in this study was constructed based on LUS videos made publicly available by different sources, such as hospitals, medical companies, and scientific publications. This dataset was selected, validated by medical experts, and published in [
129]. The download of data can be performed automatically. The videos were pre-processed, with rulers and other artifacts removed using the scripts provided with the dataset, facilitating the construction of training and test data as described in the article.
In our work, 185 videos captured by convex transducers referring to 131 patients were considered. Videos captured by linear transducers were discarded (22 videos). In addition, videos of viral pneumonia were not included because there were only three videos in such class. A summary of the number of used videos per class is presented in
Table 1.
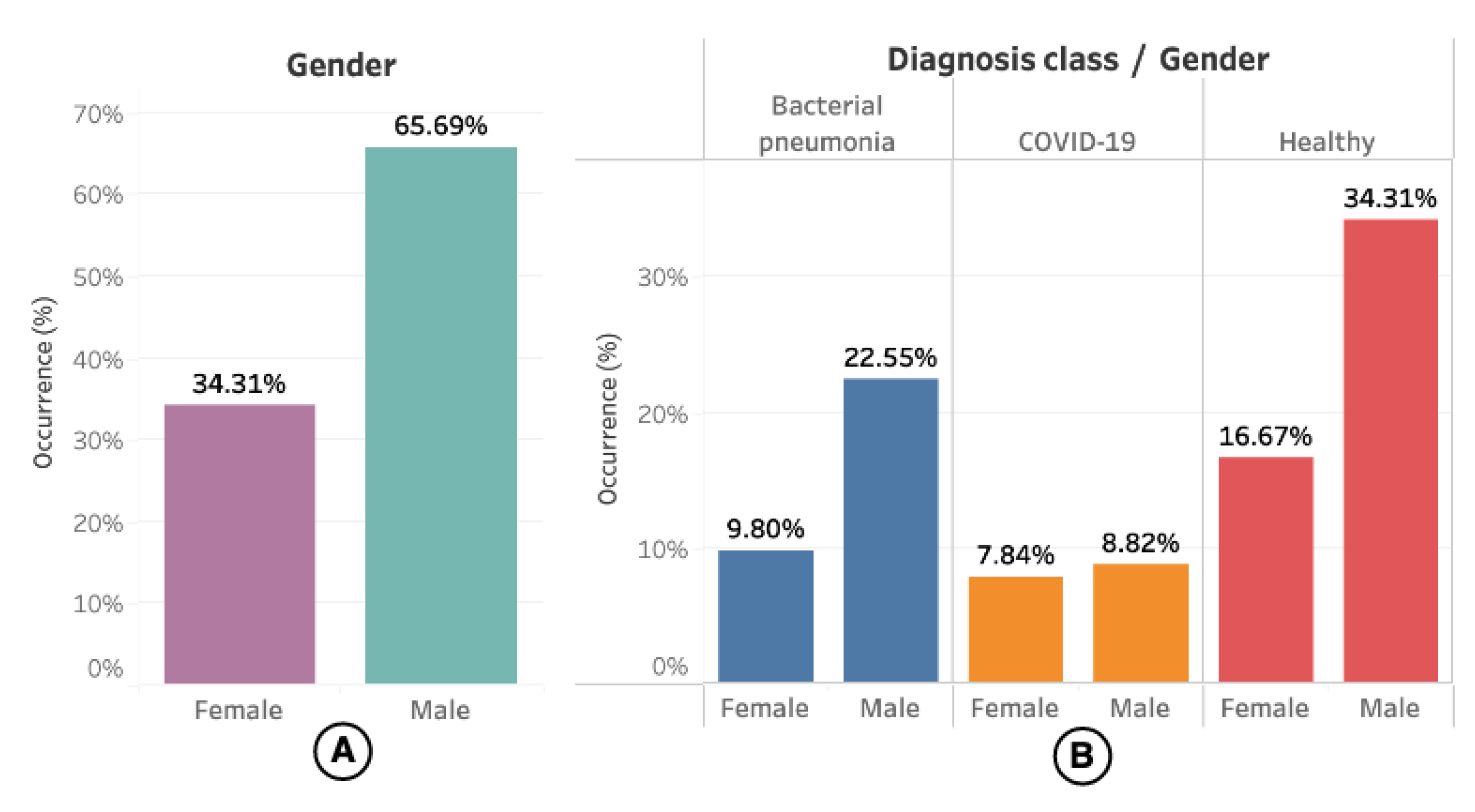
Regarding demographic data, only 67 (51.14%) of them had information about sex and age available. The gender distribution concerning the videos (or US exams) can be seen in
Figure 3, where 102 (55.13%) videos had information about the patient’s gender.
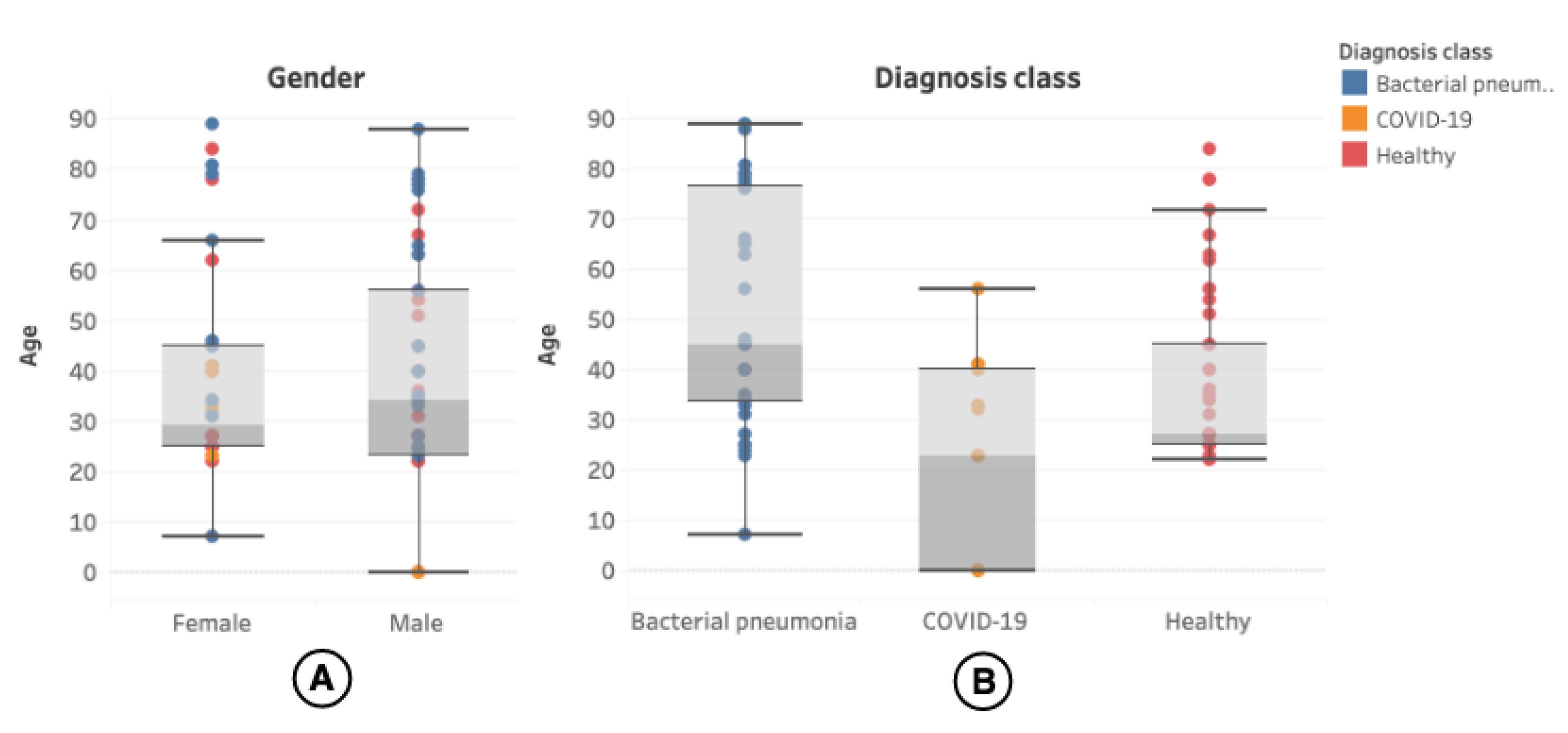
The patient’s age was present in 100 (54.05%) of the videos, and the distribution can be seen in more detail in
Figure 4.
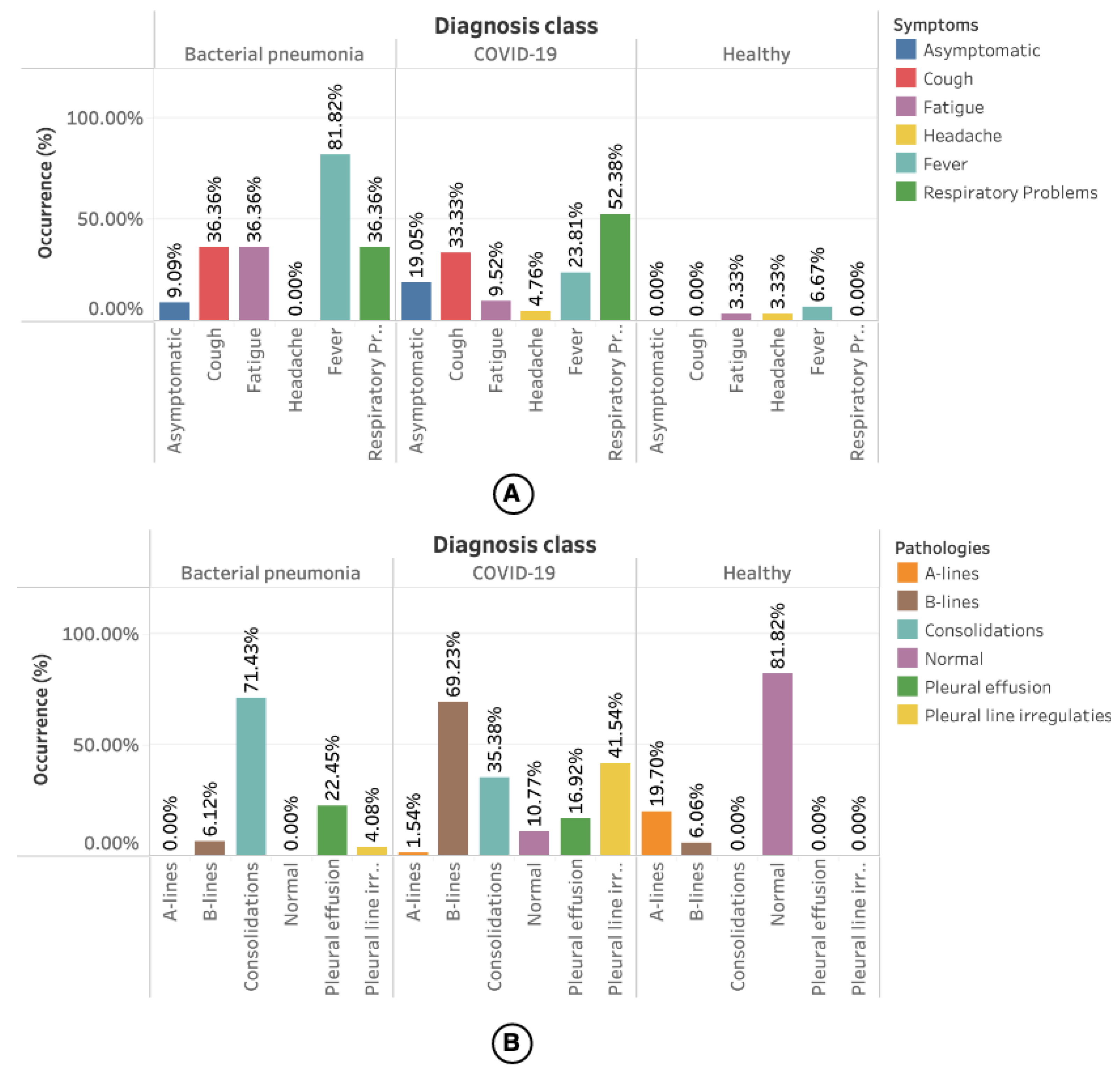
The statistics related to the symptoms presented by the patients and the pathologies related to the LUS videos are presented in
Figure 5. However, only 34% of the videos had information about the symptoms.
Figure 5A shows the occurrence of symptoms by diagnosis class. Most of the symptoms reported for bacterial pneumonia are fever (81.82%). For COVID-19, 52.38% of cases are respiratory problems. In healthy patients, a minimum portion had symptoms such as fatigue (3.33%), headache (3.33%), and fever (6.67%), but without any relationship with the diseases mentioned earlier.
Information about the pathologies found in the videos was available for all videos used in this work. As shown in
Figure 5B, most occurrences for bacterial pneumonia are consolidation (71.43%) followed by pleural effusions (22.45%). Among the pathologies reported for COVID-19 are B-lines (69.23%), followed by pleural line irregularities (41.45%). A-lines (19.70%) followed by a smaller number of B-lines (6.06%) were reported in the videos referring to healthy patients.
4.3. Cross Validation (K-Folds)
To verify the generalization capacity of the optimized models, the K-Folds cross-validation technique was used, in which the dataset is divided into
k partitions [
131]. The training used
partitions, and the test the remaining partition
.
The study used partitions and each model was evaluated for each partition. The final result was expressed by the weighted sum of the model’s performance in each partition. The objective was to balance the results, as the models were trained on all partitions and were also tested on each of the remaining partitions (the last one out from the training data). Therefore, this technique helps combat model overfitting, as it attempts to balance the results using each partition.
The five partitions were stratified according to the distribution of classes, ensuring that all partitions had the same original distribution and there was no overlap of patients between the training and testing partitions. For compatibility of results, we use the open source script provided with the dataset. After executing the script for the partitioning of the data, we obtained the result presented in
Table 2.
4.4. Video Processing
The OpenCV library available for the Python language was used to analyze the number of frames available in the videos. Statistics can be viewed in
Table 3. Each of the 185 videos was processed, and the image related to each frame of the video was extracted and normalized. For the extraction of frames, we adopted a maximum limit equal to the minimum number of available frames: 21 frames.
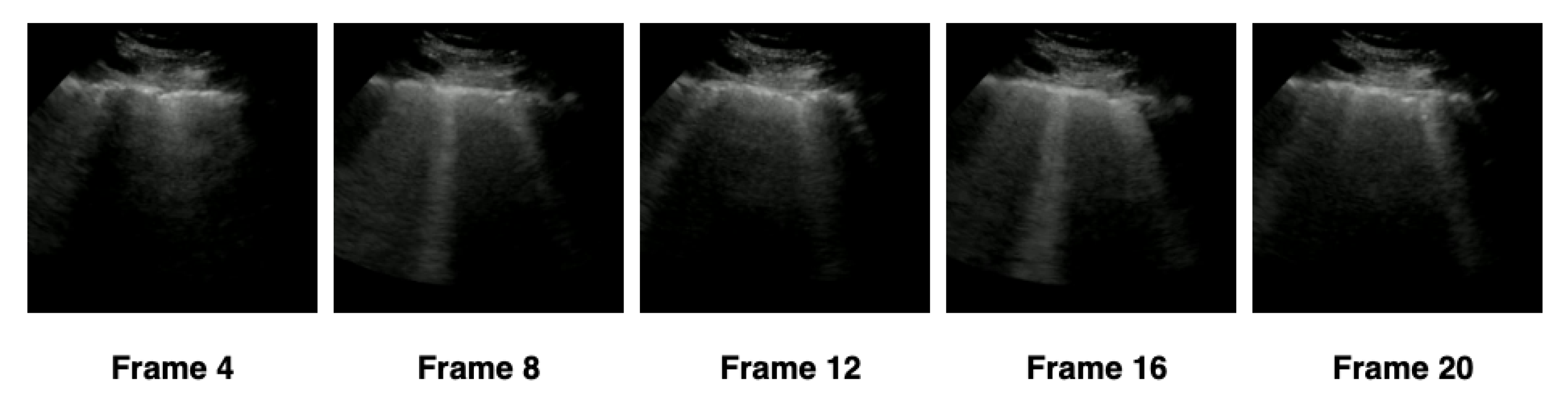
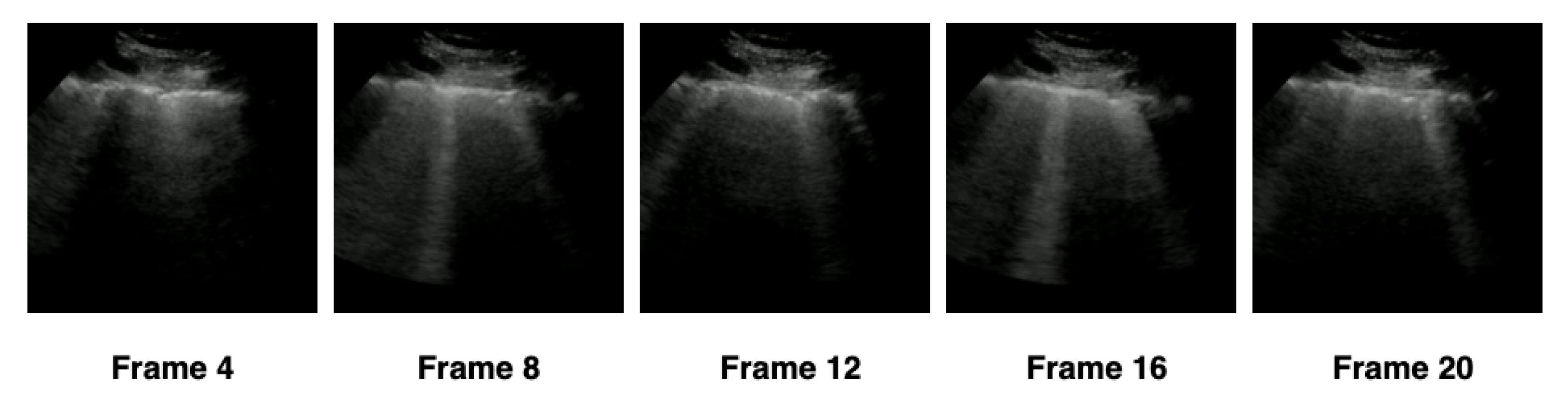
In order to verify the ideal number of frames that the hybrid model should use, we separated the extraction into four configurations—(1) 5 frames, (2) 10 frames, (3) 15 frames, and (4) 20 frames—according to
Table 4. The frames were extracted at constant intervals, based on the number of frames in each configuration. We adopted as a minimum limit the value of 5 frames and the maximum limit of 20 frames, standardizing the settings in intervals of 5 frames. For example, in the first configuration, a video containing 21 frames would have 5 frames extracted with an interval of 4 frames between them, and 16 frames would be discarded, as represented in
Figure 6. The total number of frames extracted by each configuration was presented in
Table 4.
For each of the configurations, the respective frames of each video were extracted. Next, the pixel values of the images were scaled, where the value of each pixel was multiplied by the factor of . Finally, images were resized using the nearest interpolation algorithm to a fixed size of with 3 RGB channels to maintain compatibility with the pre-trained models on ImageNet.
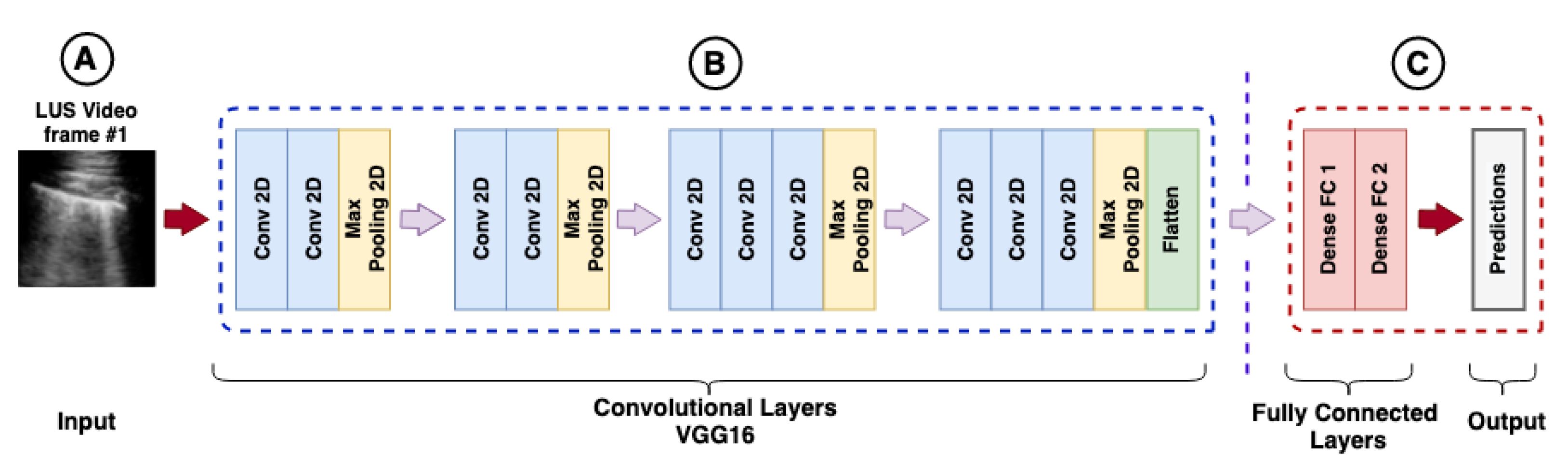
4.5. Feature Extraction with CNNs
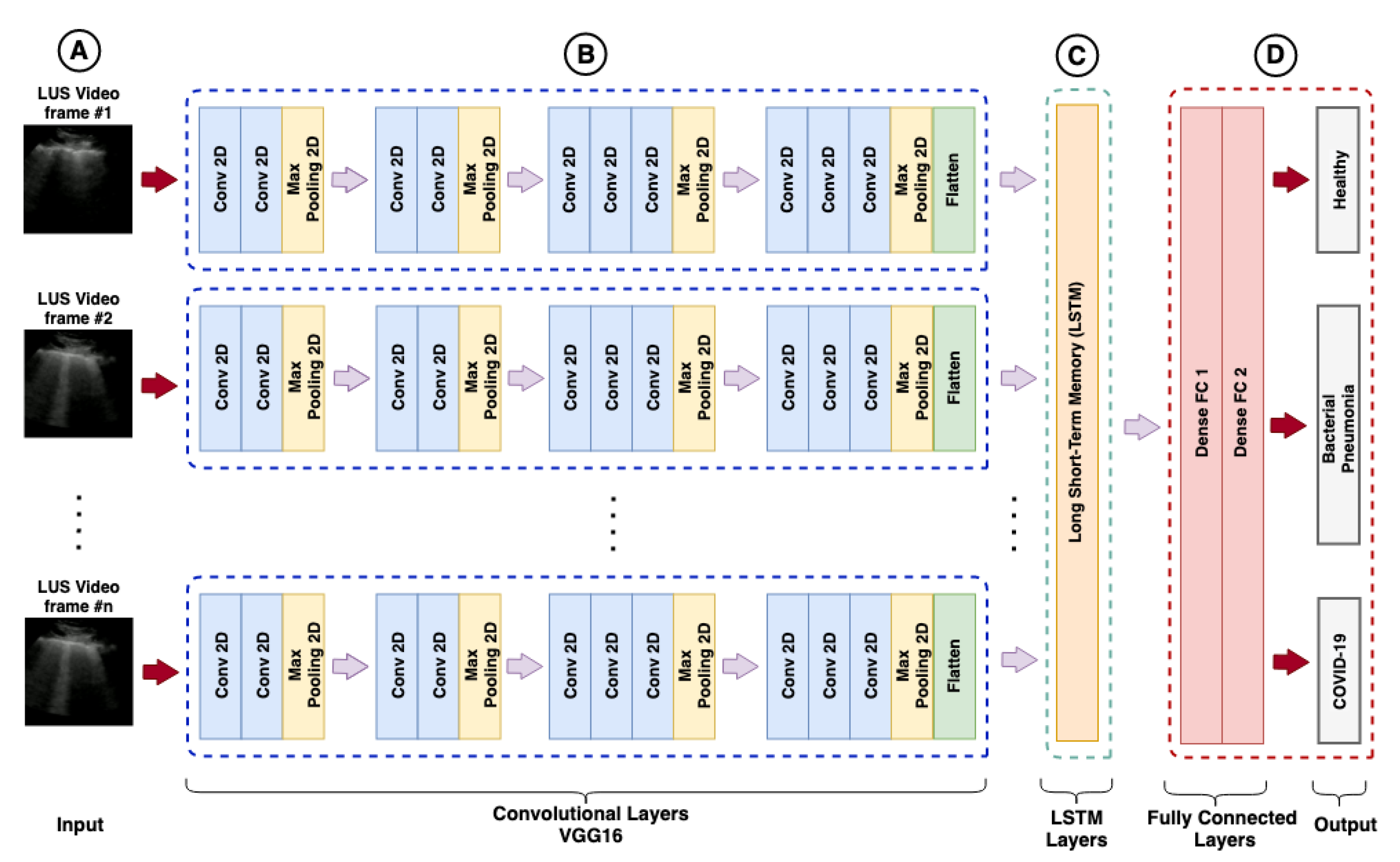
For the extraction of features, different CNN architectures were used according to
Section 2.1.1. The purpose of CNNs was to capture the spatial features of the sequence of images belonging to each video.
In this work, pre-trained models in LUS images containing the diagnosis of COVID-19 provided in [
129] (POCOVID-Net) were used. Furthermore, models based on transfer learning were used with CNNs pre-trained on ImageNet, without any prior training in medical images, as explained in
Section 2.1.4.
The frames extracted from the videos based on each configuration of
Table 4 were submitted to CNNs proposed in this investigation to extract the main features of the three classes of interest: bacterial pneumonia, COVID-19, and healthy. As the networks were already pre-trained, it was not necessary to retrain the CNNs or perform any fine-tuning, for both pre-trained on LUS images or for the models pre-trained on ImageNet. These features were represented by one-dimension vectors extracted from the convolutional layers located in the deeper layers of the networks. Finally, the dense layers were removed as shown in
Figure 2.
Table 5 summarizes the CNN architectures used in our work and the length of the one-dimension vector extracted from the respective convolutional layers. Once these features have been extracted from the frames, they are now ready to be used as input to an LSTM.
4.6. Training Temporal Data with LSTMs
The training of recurrent models aimed to classify the LUS videos, using as input a sequence of features extracted from the images by different CNN models and as output the prediction of the three classes of interest, as shown in
Figure 7.
The RNN training depends on the used CNN architecture and the features configuration. The input layer of RNN models has a different number of elements both for features and numbers of frames used in the video sequence analysis, as shown in
Table 6. Each sequence represents the input layer of an LSTM.
The features extracted by CNNs are part of spatial learning. Each sequence of n frames based on extraction settings and flat feature vectors is used as input to an RNN model. An LSTM for each CNN architecture was trained under sets of hyperparameters tested and varied using an optimization framework.
4.7. Hyperparameter Optimization with Optuna
The training was performed using a framework called Optuna [
132], available as a library for the Python language. Optuna is an open-source software that easily allows the construction of organized experiments, besides providing several algorithms for sampler and pruner. It is possible to run the experiments in a distributed way, and the results are visualized in a web interface (dashboard).
For the sampler, the Tree-structured Parzen Estimator (TPE) algorithm was used [
111] and for pruner, the Hyperband [
115] of
Section 2.2 was adopted. A total of 68 models were optimized, each model corresponded to feature specific configurations and a CNN architecture
. Finally, each model was submitted to 100 trials.
The LSTM architecture was fixed on a single LSTM layer, with two dense layers fully connected with the ReLU activation function before the prediction layer. In addition, the prediction layer (output layer) was configured with the cross-entropy categorical loss function. The parameters chosen for optimization were: (1) the number of units used in the LSTM; (2) the dropout rate; (3) the number of neurons in the fully connected layers; (4) the learning rate (LR), and the batch size to be used in training.
The Adam optimizer was adopted as the standard for training the models, and no other optimizers were used. The optimization process was carried out considering the accuracy of the models in the five partitions, according to
Section 4.3. The average accuracy was used as the value returned by the objective function to be maximized, and the best models were saved so that their accuracies could be compared.
Keras and TensorFlow Python libraries were used to build the CNN and RNN models. The optimization and training process was performed on an NVIDIA DGX-1 machine composed of eight Tesla P-100 GPUs containing 16 GB of memory for each GPU. However, for this experiment, only 1 GPU was used. The optimization and training process took
h. A summary of the values obtained from the hyperparameters by the optimization process can be found in
Table 7.
Table 8 lists all the values referring to the metrics of the models evaluated after the optimization process ordered by accuracy and F1-score (COVID-19) presented in the first and last columns. Although the table lists values with two decimal places of precision, we consider more decimal places in case of ties, as available in
https://github.com/b-mandelbrot/pulmonary-covid19/blob/master/evaluation.csv (accessed on 9 August 2021).
4.8. Visual Explanations with Grad-CAM
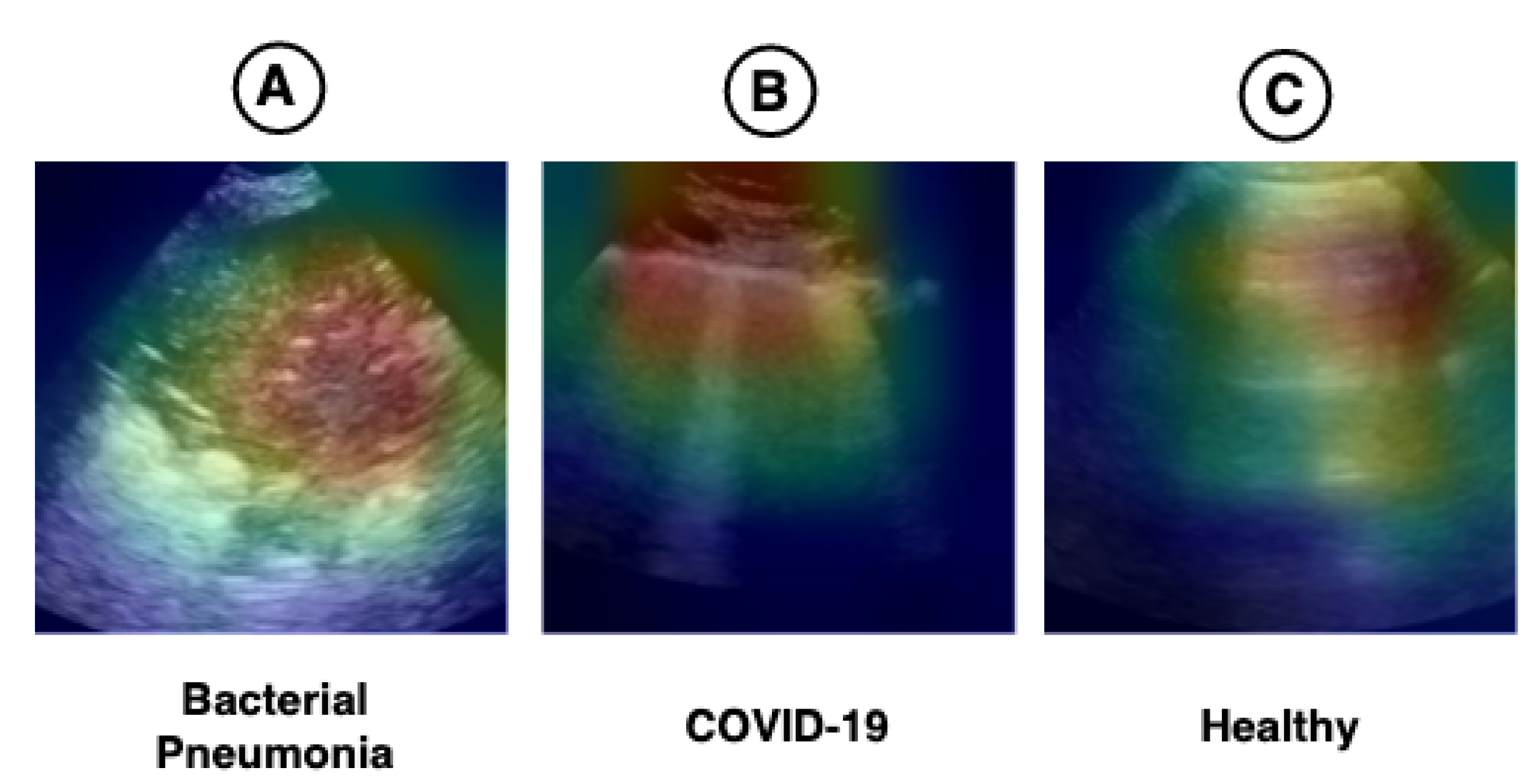
The hybrid model (CNN-LSTM) proposed in this work has an Xception in its convolutional base. Therefore, this technique cannot be fully explained, but the part of the model used to extract spatial features (CNN) can be visualized using this technique. We applied Grad-CAM to verify whether the regions highlighted in the images have any relationship with the pathologies found in the LUS videos. The result can be seen in
Figure 8.
Figure 1 shows the main pathologies found in the LUS videos regarding the diagnoses of bacterial pneumonia, COVID-19, and healthy.
Figure 8A demonstrates that the region of consolidations is highlighted in the heat map. In
Figure 8B, the highlighted regions are coherent with the pathologies known as B-lines and pleural line irregularities present in COVID-19 images. In
Figure 8C, the heat map shows the A-lines, which are found in LUS exams referring to healthy patients. The heat maps presented in
Figure 8 lead us to believe that the model can use the features learned in images outside the application domain (i.e., medical images), such as those from ImageNet, for use in LUS images.
5. Discussion
This work presents a new hybrid model for classifying LUS videos for the diagnosis of COVID-19. The LUS video classification proposed involved two types of data: spatial data, referring to video frames, and temporal data, represented by time-indexed frames. The extraction of spatial features was performed by a CNN, and the temporal dependence between video frames was learned using an LSTM.
In this work, 68 hybrid models (CNN-LSTM) were trained to classify the videos. Each model was composed of a different CNN architecture. The frames referring to the videos were extracted in four configurations (5, 10, 15, and 20 frames). In addition, two types of pre-trained models were tested, the POCOVID-Net [
129], pre-trained on LUS images, and 12 CNN architectures, pre-trained on the ImageNet dataset. Each of these models went through an HPO process, where the best results were stored for comparison, as shown in
Table 7. In order to balance the results and prevent the models from overfitting, the cross-validation technique was used. The average accuracy was used as the value of the objective function to be maximized.
The number of frames used by each model and its hyperparameters varied according to the available configurations. All extraction configurations provided good results, but only two models optimized with the five-frame configuration were between the top 10 best hybrid models. All other models showed better results when using configurations with more than five frames. Regarding the extraction of spatial features, both ImageNet and LUS pre-trained architectures obtained good results. The best model was pre-trained on ImageNet and used a 20-frame extraction configuration.
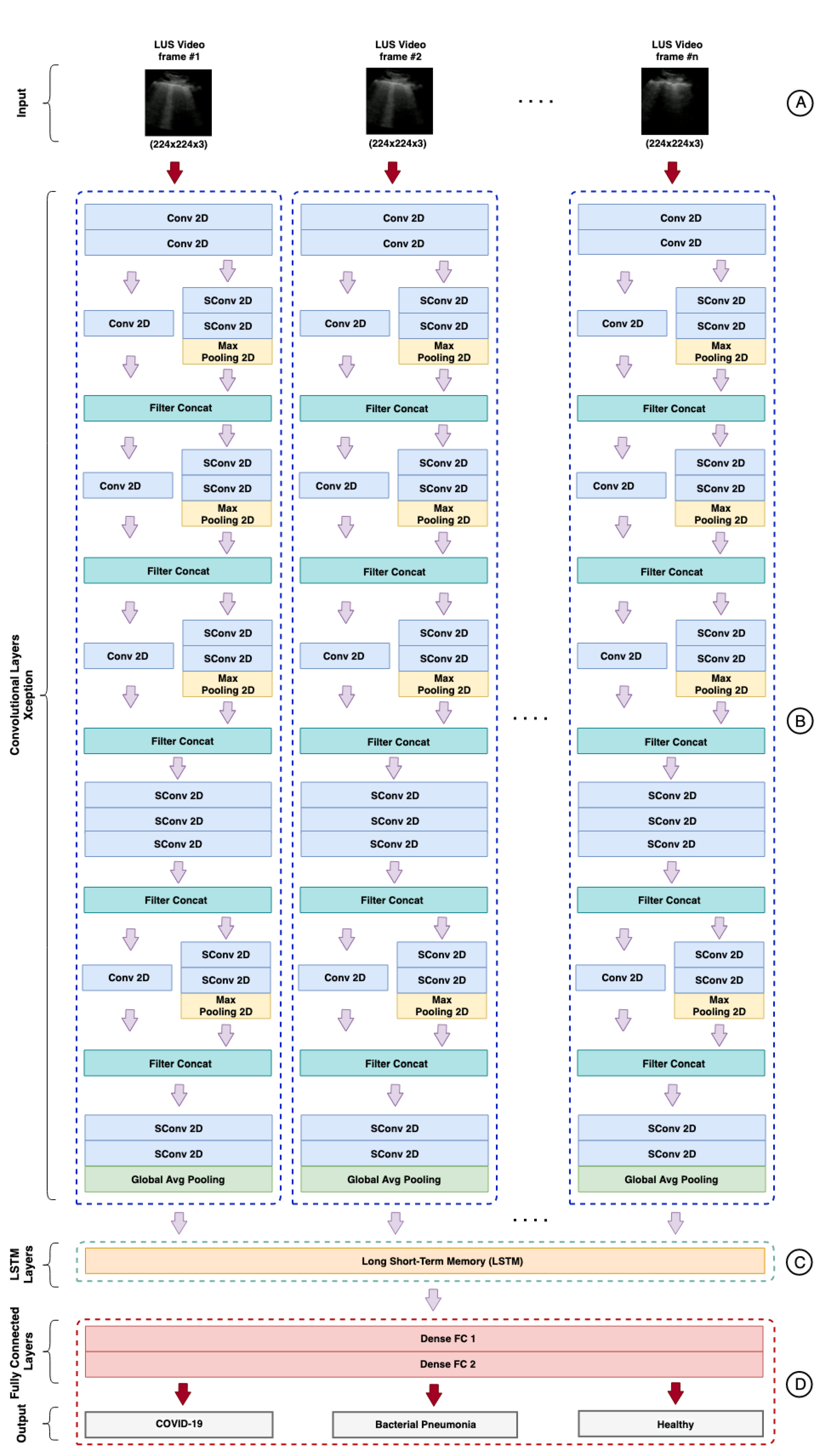
According to the results obtained and presented in
Table 8, the best hybrid model was the Xception-LSTM, composed of a pre-trained Xception on ImageNet and an LSTM containing 512 units, configured with a dropout rate of 0.4 and a sequence of 20 frames in the input layer
. The architecture proposed for the hybrid model can be visualized in
Figure A1,
Appendix A.
Regarding the numeric results, the best model presented an average accuracy of , precision of , sensitivity of , specificity of , and F1-Score of for COVID-19. The POCOVID-Net-3-LSTM model whose convolutional base is pre-trained on LUS images obtained a result very close to the Xception-LSTM pre-trained on ImageNET, an average accuracy of , precision of , sensitivity of , specificity of , and F1-Score of for COVID-19.
This spatiotemporal model outperformed the purely spatial version in all metrics except precision and specificity, with values of
and
versus
and
of the spatial model [
129]. Furthermore, the spatiotemporal version has fewer parameters (837 K) than its spatial version (14.7 M). In this sense, we highlight the NASNetMobile-LSTM that obtained an accuracy of
with the smallest number of parameters among the top 10 models, as seen in the
Table 7.
All models in the top 10 presented results superior to those obtained by human experts according to the study carried out in [
62], where the reported combined sensitivity was 86.4%, and the specificity was 54.6%. Other architectures achieved similar results, such as DenseNet121, DenseNet201, NASNetLarge, and Resnet152V2.
6. Conclusions
The results indicate that the use of hybrid models (CNN-LSTM) can be effective in learning spatiotemporal features, exceeding the performance of models with purely spatial approaches [
39,
129] and even human experts [
62]. However, these results should be interpreted with parsimony. Few data are available on the performance of human experts in LUS imaging for the diagnosis of COVID-19.
Transfer learning with models pre-trained on ImageNet provided comparable results to models pre-trained on LUS images, suggesting that ImageNet can be used in cases where there is limited data for training [
99]. We also show that the use of transfer learning techniques and HPO can facilitate the creation of rapid prototypes for diagnosing diseases, as seen in other studies [
21].
This study provided evidence that the LUS-based imaging technique can be an essential tool in containing COVID-19 and other lung diseases such as bacterial pneumonia. However, there is still room for further experiments.
As future work, it is intended to increase the number of LUS videos, adding new sources so that it is possible to test the models with independent videos. In addition, we plan to carry out new tests with other types of RNNs, such as GRUs. As mentioned in
Section 2.1.3, GRUs are more efficient and, depending on the dataset, can provide results comparable to or even better than LSTMs.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}