
SenseHunger: Machine Learning Approach to Hunger Detection Using Wearable Sensors
 , , , , ,
, , , , , 
Abstract
:1. Introduction
- 1.
- We investigate the use of non-invasive multimodal sensors in the context of hunger and satiety detection and develop a state-of-the-art machine learning model, which learns hunger and satiety patterns from multimodal sensors data and classifies them into hunger and satiety classes.
- 2.
- We analyze and compare wearable devices and sensor channels to select the most relevant physiological signals for an accurate classification of hunger and satiety data.
- 3.
- We perform a comparative analysis of feature extraction approaches and machine learning algorithms to identify the best features in achieving optimal classification results.
- 4.
- We also provide a brief review of related approaches.
2. Related Work
3. Materials and Methods
3.1. Dataset Acquisition
- 1.
- RespiBan (Plux Wireless Biosignals S. A., Lisboa, Portugal) [28]: Subjects wear the respiration belt on the chest, at the level of the thorax, with the electrode connectors facing forward. It contains the Respiration (Resp) sensor and also provides the possibility for connecting to other sensors such as Electrodermal activity (EDA), Electrocardiography (ECG), and Electromyography (EMG), as shown in Figure 2. The description of these sensors is as follows:
- Resp: This sensor measures the respiration rate. It detects chest or abdominal expansion/contraction, and outputs a respiration signal. It is usually worn using a comfortable and flexible length-adjustable belt. It is sampled at 475 Hz.
- EDA [29]: EDA of RespiBan (Eda_RB) consists of two electrodes placed on the front, in the middle of the index finger, and in the middle of the middle finger of subject’s non-dominant hand. This sensor measures the galvanic skin response, i.e., the change in electrical conductivity of skin in response to sweat secretion. It is also sampled at 475 Hz.
- ECG [30]: It consists of three electrodes placed on the subject’s right upper pectoral, left upper pectoral, and at the left bottom thoracic cage. This sensor records the electrical impulses through the heart muscle, and it can also be used to provide information on the heart’s response to physical exertion. It is also sampled at 475 Hz.
- EMG [31]: This sensor is used to assess the electrical activity associated with muscle contractions and respective nerve cells, which control them. It is placed on the subject’s abdomen above the belly button and is also sampled at 475 Hz.
- 2.
- Empatica E4 wristband (Emaptica Inc., Cambridge MA, USA) [32]: It contains photoplethysmogram (PPG), infrared thermopile (Tmp), and EDA sensors that allow measurements of sympathetic nervous system activity and heart rate (HR) variability. The description of these sensors is as follows:
- PPG: This sensor measures blood volume pulse (BVP), which can be used to derive HR and inter-beat interval (IBI). It is sampled at 1 Hz.
- Tmp: This sensor records skin temperature. It is sampled at 5 Hz.
- EDA: EDA of Empatica E4 (Eda_E4) wristband measures the galvanic skin response, which is the change in the electrical conductivity of the skin in response to sweat secretion. It is sampled at 5 Hz.
- 3.
- JINS MEME smart glasses (Jins Inc., Tokyo, Japan) [33]: They can track not only where we look, but how often we blink and even whether we are about to relax or fall asleep. It uses electrooculography (EOG) electrodes placed in three locations on the frame. These electrodes can track blink duration and eye movements in different directions. It is sampled at 20 Hz.
3.2. Pre-Processing
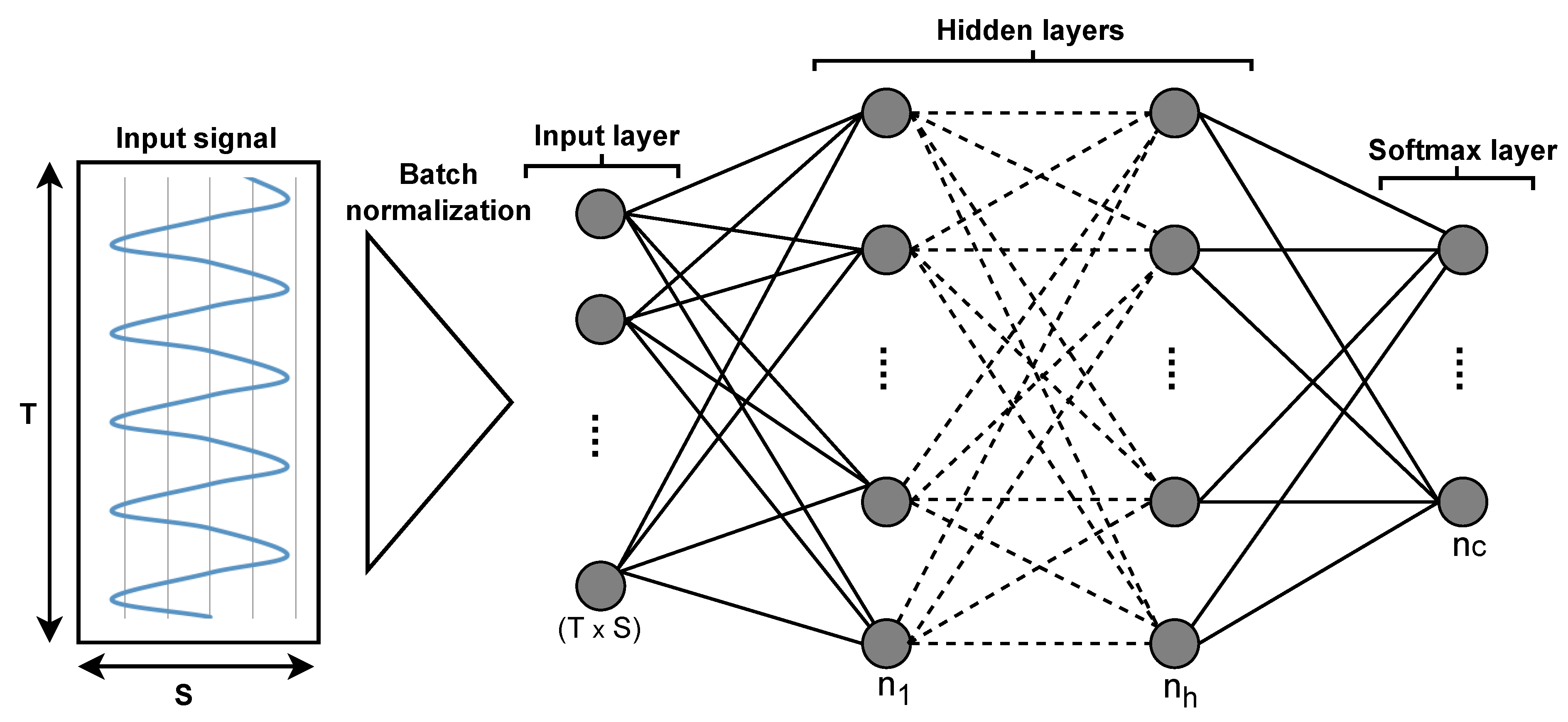
3.3. Feature Extraction and Selection
3.4. Classification
- 1.
- SVM: In pattern recognition, SVM is a supervised learning algorithm, which can be used for classification and regression tasks. Its robust performance on noisy and sparse data makes it a good choice for a variety of applications [42]. In a classification task, the SVM separates the labeled training data with a maximum margin hyperplane. Test data are then mapped to the same space to predict a class label. SVM can also efficiently map high-dimensional data to a high-dimensional dimension feature space to perform nonlinear classification [46].
- 2.
- DT: This is an approach to classification or regression analysis, in which a decision tree is constructed by recursively partitioning the feature space of the training set into smaller and smaller subsets. The final consequence is a tree with decision and leaf nodes. DT aims to find a set of decision rules that instinctively divide the feature space to build a instructive and robust classification model. A decision node has binary or multiple branches. A leaf node indicates a class or outcome. The top decision node in a tree points to the best predictor, which is called the root node [47].
- 3.
- RF: This is a popular ensemble learning method used for various types of classification problems such as activity recognition [35], where multiple DTs are created at training time [48,49,50,51,52]. In RF, each tree casts a unit vote by assigning each input to the most likely class label. RF is fast, robust to noise, and an effective ensemble, which can be used to identify nonlinear patterns in datasets. It can handle both numeric and categorical data. The biggest advantage of RF compared to DT is that it is significantly more resilient to overfitting [53].
3.5. Evaluation
4. Experimental Results
5. Discussion
- One of the main objective of this paper was to develop a machine learning approach to classify hunger and satiety using wearable sensors. Therefore, we used wearable devices like the Empatica E4 wristband, JINS MEME smart glasses, and RespiBan professional with miniaturized sensors that provided sufficient quality data and that could capture physiological signals related to the perception of hunger and satiety in patients or people with occupational constraints, as opposed to invasive [4], gastrointestinal model [19], fMRI-based data [21], and gastric tone signals [23]. Our proposed non-invasive multimodal system with carefully selected sensor channels outperformed previous approaches with an accuracy of 93.43% and an average F1 score of 87.86%.
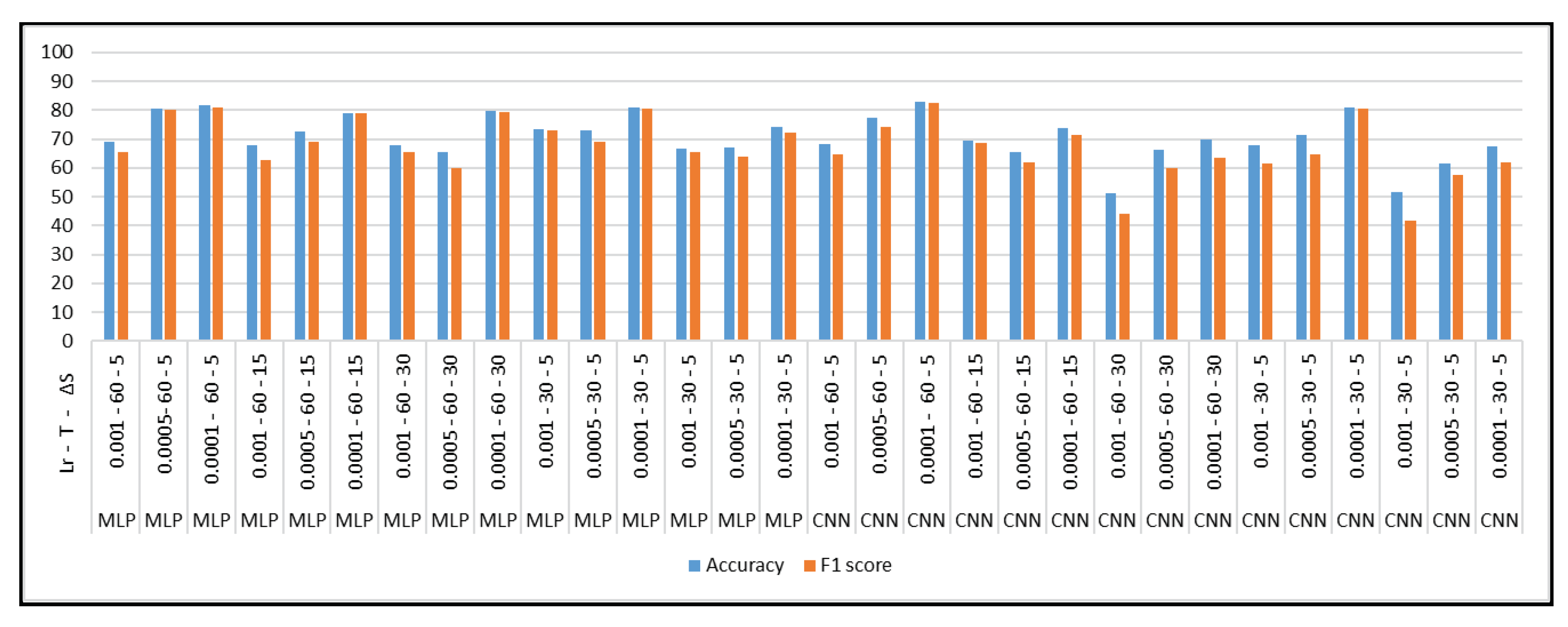
- Each classification algorithm is based on different mathematical models [60], and may produce different results for the same dataset. In order to obtain highly accurate results and to select the best classifier for further experiments, we not only conducted experiments with different classifiers, but also with different window sizes and step sizes. It was found that the RF classifier was best suited for hunger and satiety detection using hand-crafted features, and it outperformed the DT and SVM classifiers in each scenario. It was also observed that the window size of 60 s and the step size of 30 were significant for each classifier.
- In the past, deep learning-based approaches have shown promising results in a variety of application domains such as biology, medicine, and psychology [8,12,13,14,15,42,61]. However, they are computationally expensive and also require a large number of training samples [62] to build successful models compared to traditional approaches using hand-crafted features. To compare the results of feature learning and feature engineering, we also computed 18 features independently for each axis of each sensor channel. They were subsequently concatenated to obtain a feature vector of the size of 18 × sensor (S) axis. It was found that well-engineered features can perform better than deep learning approaches in the case of a limited number of training samples.
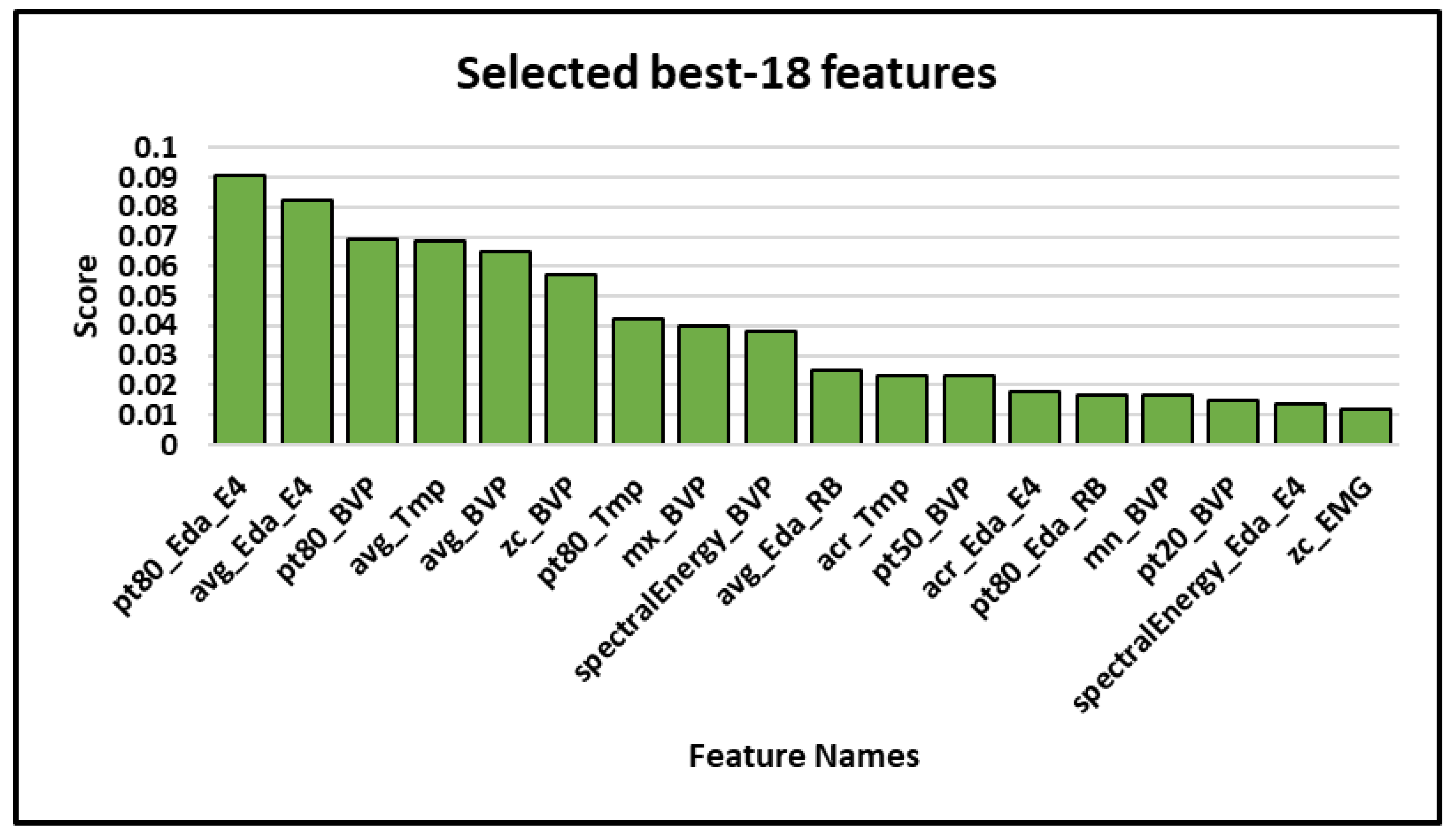
- In this study, we used feature importance ranking (FIR), which measures the contribution of each input feature to the performance of the model. It turned out that the most accurate results can be obtained only with the best 18 hand-crafted features (as shown in Table 7) and the addition of other irrelevant and redundant features can introduce noise into the data, which can reduce the performance of a classifier. It can be pointed out that the top five features come exclusively from three different sensor channels (Eda_E4, BVP, and Tmp) and are either computing the mean or the 80th percentile of the data values. Percentile 80 provides an approximation of the maximum value in a data segment that is less sensitive to noise or outliers than the actual maximum computation. This would indicate that the average and upper data values in Eda_E4, BVP, and Tmp are of high importance to distinguish between hunger and satiety. This feature selection also validates our previous results to identify the importance of each sensor channel (Table 6), and seem to confirm findings from the literature that showed these sensor channels to be relevant in detecting hunger and satiety [24,58,59] (c.f. Figure 5). The overall selected best features can be seen in Figure 7.
- Long-term monitoring with a large number of wearable sensors may be uncomfortable for users [63]. Therefore, eliminating irrelevant sensors can decrease the degree of discomfort and improve the robustness of the classification system by reducing the dimensionality and also save a lot of money [64]. In this work, we compared not only all sensors, but also wearable devices, to determine the most suitable sensors and wearable device for hunger and satiety detection. It was found that PPG (BVP, IBI, and HR), EDA (Empatica E4 and RespiBan), Tmp, and EMG were the appropriate sensor modalities for this study, and Resp, ECG, and EOG were the least appropriate. We also found that the Empatica E4 wristband was the most suitable device compared to the other devices.
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VAS | Visual Analog Scales |
| ANN | Artificial Neural Networks |
| DNN | Deep Neural Networks |
| GSR | Galvanic Skin Response |
| EDA | Electrodermal Activity |
| EEG | Electroencephalography |
| fMRI | Functional Magnetic Resonance Imaging |
| DC | Degree of Centrality |
| ReHo | Regional Homogeneity |
| fALFF | Fractional Amplitude of Low Frequency Fluctuations |
| SF | Spectral Features |
| CDF | Cepstral Domain Features |
| GCC | Gammatone Cepstral Coefficients |
| CFS | Correlation-based Feature Selection |
| ECG | Electrocardiogram |
| EMG | Electromyography |
| PPG | Photoplethysmogram |
| TMP | Thermopile |
| EOG | Electrooculography |
| ML | Machine Learning |
| BVP | Blood Volume Pulse |
| MLP | Multi-layer Perceptrons |
| LSTM | Long Short-term Memory |
| CNN | Convolutional Neural Network |
| ReLU | Rectified Linear Unit |
| SVM | Support Vector Machine |
| DT | Decision Tree |
| RF | Random Forest |
| LOSO | Leave-one-subject-out |
| ADAM | Adaptive Moment Estimation |
| SWS | Sliding Window Segmentation |
| Acc | Accuracy |
| AF1 | Averaged macro F1 score |
Appendix A. Comparison of Manual Feature Selection Approaches

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | FS Algorithm | No. of Best Features | Acc. Hungry | Acc. Satiety | Acc | AF1 Score |
|---|---|---|---|---|---|---|
| RF | RF | 18 | 79.65 | 96.08 | 93.43 | 87.86 |
| RF | Boruta | 108 | 72.53 | 95.89 | 92.86 | 84.21 |
| RF | XGB | 54 | 73.12 | 95.88 | 92.86 | 84.50 |
| XGB | RF | 18 | 69.23 | 94.63 | 90.86 | 81.93 |
| XGB | Boruta | 54 | 53.33 | 93.11 | 88.00 | 73.22 |
| XGB | XGB | 18 | 63.92 | 94.20 | 90.00 | 79.06 |
Appendix B. Hyper-Parameter Selection for Feature Learning Approaches
Appendix C. Demographic Information about the Subjects
| Subject Name | Sex/Gender | Age (in years) | Weight (in kg) |
|---|---|---|---|
| S1 | Female | 23 | 65 |
| S2 | Male | 29 | 71 |
| S3 | Male | 37 | 72 |
| S4 | Male | 26 | 81 |
| S5 | Male | 27 | 75 |
References
- Jauch-Chara, K.; Oltmanns, K.M. Obesity–A neuropsychological disease? Systematic review and neuropsychological model. Prog. Neurobiol. 2014, 114, 84–101. [Google Scholar] [CrossRef]
- Macpherson-Sánchez, A.E. Integrating fundamental concepts of obesity and eating disorders: Implications for the obesity epidemic. Am. J. Public Health 2015, 105, e71–e85. [Google Scholar] [CrossRef] [PubMed]
- WHO. Obesity and Overweight. 2016. Available online: https://www.who.int/news-room/fact-sheets/detail/obesity-and-overweight (accessed on 27 June 2021).
- Krishnan, S.; Hendriks, H.F.; Hartvigsen, M.L.; de Graaf, A.A. Feed-forward neural network model for hunger and satiety related VAS score prediction. Theor. Biol. Med. Model. 2016, 13, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Parker, B.A.; Sturm, K.; MacIntosh, C.; Feinle, C.; Horowitz, M.; Chapman, I. Relation between food intake and visual analogue scale ratings of appetite and other sensations in healthy older and young subjects. Eur. J. Clin. Nutr. 2004, 58, 212–218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sepple, C.; Read, N. Gastrointestinal correlates of the development of hunger in man. Appetite 1989, 13, 183–191. [Google Scholar] [CrossRef]
- Rogers, P.J.; Blundell, J.E. Effect of anorexic drugs on food intake and the micro-structure of eating in human subjects. Psychopharmacology 1979, 66, 159–165. [Google Scholar] [CrossRef]
- Huang, X.; Shirahama, K.; Li, F.; Grzegorzek, M. Sleep stage classification for child patients using DeConvolutional Neural Network. Artif. Intell. Med. 2020, 110, 101981. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of feature learning methods for human activity recognition using wearable sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef] [Green Version]
- Di Lascio, E.; Gashi, S.; Debus, M.E.; Santini, S. Automatic Recognition of Flow During Work Activities Using Context and Physiological Signals. In Proceedings of the 2021 9th International Conference on Affective Computing and Intelligent Interaction (ACII), Nara, Japan, 28 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Liaqat, S.; Dashtipour, K.; Arshad, K.; Ramzan, N. Non invasive skin hydration level detection using machine learning. Electronics 2020, 9, 1086. [Google Scholar] [CrossRef]
- Roy, S.D.; Das, S.; Kar, D.; Schwenker, F.; Sarkar, R. Computer Aided Breast Cancer Detection Using Ensembling of Texture and Statistical Image Features. Sensors 2021, 21, 3628. [Google Scholar] [CrossRef]
- Malmgren, H.; Borga, M. Artificial Neural Networks in Medicine and Biology: Proceedings of the ANNIMAB-1 Conference, Göteborg, Sweden, 13–16 May 2000; Springer Science & Business Media: Berlin, Germany, 2000. [Google Scholar]
- Bustin, S.A. Nucleic acid quantification and disease outcome prediction in colorectal cancer. Pers. Med. 2006, 3, 207–216. [Google Scholar] [CrossRef] [Green Version]
- Patel, J.L.; Goyal, R.K. Applications of artificial neural networks in medical science. Curr. Clin. Pharmacol. 2007, 2, 217–226. [Google Scholar] [CrossRef]
- Rahaman, M.M.; Li, C.; Yao, Y.; Kulwa, F.; Rahman, M.A.; Wang, Q.; Qi, S.; Kong, F.; Zhu, X.; Zhao, X. Identification of COVID-19 samples from chest X-Ray images using deep learning: A comparison of transfer learning approaches. J. X-ray Sci. Technol. 2020, 28, 821–839. [Google Scholar] [CrossRef]
- Shahid, N.; Rappon, T.; Berta, W. Applications of artificial neural networks in health care organizational decision-making: A scoping review. PLoS ONE 2019, 14, e0212356. [Google Scholar] [CrossRef] [PubMed]
- Baxt, W.G. Application of artificial neural networks to clinical medicine. Lancet 1995, 346, 1135–1138. [Google Scholar] [CrossRef]
- Bellmann, S.; Krishnan, S.; de Graaf, A.; de Ligt, R.A.; Pasman, W.J.; Minekus, M.; Havenaar, R. Appetite ratings of foods are predictable with an in vitro advanced gastrointestinal model in combination with an in silico artificial neural network. Food Res. Int. 2019, 122, 77–86. [Google Scholar] [CrossRef] [PubMed]
- Rahman, T.; Czerwinski, M.; Gilad-Bachrach, R.; Johns, P. Predicting “about-to-eat” moments for just-in-time eating intervention. In Proceedings of the 6th International Conference on Digital Health Conference, Montréal, QC, Canada, 11–13 April 2016; pp. 141–150. [Google Scholar]
- Al-Zubaidi, A.; Mertins, A.; Heldmann, M.; Jauch-Chara, K.; Münte, T.F. Machine learning based classification of resting-state fMRI features exemplified by metabolic state (hunger/satiety). Front. Hum. Neurosci. 2019, 13, 164. [Google Scholar] [CrossRef] [Green Version]
- Lakshmi, S.; Kavipriya, P.; Jebarani, M.E.; Vino, T. A Novel Approach of Human Hunger Detection especially for physically challenged people. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 921–927. [Google Scholar]
- Maria, A.; Jeyaseelan, A.S. Development of Optimal Feature Selection and Deep Learning Toward Hungry Stomach Detection Using Audio Signals. J. Control. Autom. Electr. Syst. 2021, 32, 853–874. [Google Scholar] [CrossRef]
- Gogate, U.; Bakal, J. Hunger and stress monitoring system using galvanic skin. Indones. J. Electr. Eng. Comput. Sci. 2019, 13, 861–865. [Google Scholar] [CrossRef]
- Barajas-Montiel, S.E.; Reyes-Garcia, C.A. Identifying pain and hunger in infant cry with classifiers ensembles. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 770–775. [Google Scholar]
- Yu, D.; Seltzer, M.L.; Li, J.; Huang, J.T.; Seide, F. Feature learning in deep neural networks-studies on speech recognition tasks. arXiv 2013, arXiv:1301.3605. [Google Scholar]
- Irshad, M.T.; Nisar, M.A.; Gouverneur, P.; Rapp, M.; Grzegorzek, M. Ai approaches towards Prechtl’s assessment of general movements: A systematic literature review. Sensors 2020, 20, 5321. [Google Scholar] [CrossRef] [PubMed]
- respiBAN. Available online: https://plux.info/biosignalsplux-wearables/313-respiban-professional-820202407.html (accessed on 8 August 2021).
- Electrodermal Activity (EDA). Available online: https://plux.info/sensors/280-electrodermal-activity-eda-820201202.html (accessed on 18 August 2021).
- Electrocardiogram (ECG). Available online: https://plux.info/sensors/277-electrocardiogram-ecg-820201203.html (accessed on 18 August 2021).
- Electromyography (EMG). Available online: https://plux.info/sensors/283-electromyography-emg-820201201.html (accessed on 18 August 2021).
- Empatica Wristband. Available online: https://www.empatica.com/research/e4/ (accessed on 8 August 2021).
- JINS MEME: Eyewear That Sees Your EVERYDAY. Available online: https://jins-meme.com/en/ (accessed on 8 August 2021).
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Amjad, F.; Khan, M.H.; Nisar, M.A.; Farid, M.S.; Grzegorzek, M. A Comparative Study of Feature Selection Approaches for Human Activity Recognition Using Multimodal Sensory Data. Sensors 2021, 21, 2368. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.J.; Krishnan, N.C. Activity learning: Discovering, recognizing, and predicting human behavior from sensor data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Kumar, V. The Top Ten Algorithms in Data Mining; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Nguyen, C.; Wang, Y.; Nguyen, H.N. Random forest classifier combined with feature selection for breast cancer diagnosis and prognostic. J. Biomed. Sci. Eng. 2013, 06, 551–560. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Nahid, A.A.; Mehrabi, M.A.; Kong, Y. Histopathological breast cancer image classification by deep neural network techniques guided by local clustering. Biomed Res. Int. 2018, 2018, 2362108. [Google Scholar] [CrossRef]
- Nisar, M.A.; Shirahama, K.; Li, F.; Huang, X.; Grzegorzek, M. Rank pooling approach for wearable sensor-based ADLs recognition. Sensors 2020, 20, 3463. [Google Scholar] [CrossRef]
- Orhan, U.; Hekim, M.; Ozer, M. EEG signals classification using the K-means clustering and a multilayer perceptron neural network model. Expert Syst. Appl. 2011, 38, 13475–13481. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, G.; Jiang, Y.; Wang, B.; Soleimani, M. Application of deep neural network to the reconstruction of two-phase material imaging by capacitively coupled electrical resistance tomography. Electronics 2021, 10, 1058. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Furey, T.S.; Cristianini, N.; Duffy, N.; Bednarski, D.W.; Schummer, M.; Haussler, D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 2000, 16, 906–914. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards Jr, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Miller, J. Contextual land-cover classification: Incorporating spatial dependence in land-cover classification models using random forests and the Getis statistic. Remote Sens. Lett. 2010, 1, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene classification using Random Forests. ISPRS J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Titapiccolo, J.I.; Ferrario, M.; Cerutti, S.; Barbieri, C.; Mari, F.; Gatti, E.; Signorini, M.G. Artificial intelligence models to stratify cardiovascular risk in incident hemodialysis patients. Expert Syst. Appl. 2013, 40, 4679–4686. [Google Scholar] [CrossRef]
- Chaudhary, A.; Kolhe, S.; Kamal, R. An improved random forest classifier for multi-class classification. Inf. Process. Agric. 2016, 3, 215–222. [Google Scholar] [CrossRef] [Green Version]
- Fatourechi, M.; Ward, R.K.; Mason, S.G.; Huggins, J.; Schloegl, A.; Birch, G.E. Comparison of evaluation metrics in classification applications with imbalanced datasets. In Proceedings of the 2008 seventh international conference on machine learning and applications, San Diego, CA, USA, 11–13 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 777–782. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Takahashi, K.; Yamamoto, K.; Kuchiba, A.; Koyama, T. Confidence interval for micro-averaged F1 and macro-averaged F1 scores. Appl. Intell. 2022, 52, 4961–4972. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mandryk, R.; Klarkowski, M. Physiological measures for game evaluation. In Game Usability; CRC Press: Boca Raton, FL, USA, 2008; pp. 161–187. [Google Scholar]
- He, W.; Boesveldt, S.; Delplanque, S.; de Graaf, C.; De Wijk, R.A. Sensory-specific satiety: Added insights from autonomic nervous system responses and facial expressions. Physiol. Behav. 2017, 170, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Dutta, N.; Subramaniam, U.; Padmanaban, S. Mathematical models of classification algorithm of Machine learning. In International Meeting on Advanced Technologies in Energy and Electrical Engineering; Hamad bin Khalifa University Press (HBKU Press): Doha, Qatar, 2020; Volume 2019, No. 1, p. 3. [Google Scholar]
- Peifer, C.; Pollak, A.; Flak, O.; Pyszka, A.; Nisar, M.A.; Irshad, M.T.; Grzegorzek, M.; Kordyaka, B.; Kożusznik, B. The Symphony of Team Flow in Virtual Teams. Using Artificial Intelligence for Its Recognition and Promotion. Front. Psychol. 2021, 12, 697093. [Google Scholar] [CrossRef]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Sweeney, K.T.; Ward, T.E.; McLoone, S.F. Artifact removal in physiological signals—Practices and possibilities. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 488–500. [Google Scholar] [CrossRef]
- Lan, T.; Erdogmus, D.; Adami, A.; Pavel, M.; Mathan, S. Salient EEG channel selection in brain computer interfaces by mutual information maximization. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 7064–7067. [Google Scholar]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 1–26. [Google Scholar] [CrossRef]
- Sang, X.; Xiao, W.; Zheng, H.; Yang, Y.; Liu, T. HMMPred: Accurate prediction of DNA-binding proteins based on HMM profiles and XGBoost feature selection. Comput. Math. Methods Med. 2020, 2020, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Rudnicki, W.R.; Wrzesień, M.; Paja, W. All relevant feature selection methods and applications. In Feature Selection for Data and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2015; pp. 11–28. [Google Scholar]
- Chang, Y.C.; Chang, K.H.; Wu, G.J. Application of eXtreme gradient boosting trees in the construction of credit risk assessment models for financial institutions. Appl. Soft Comput. 2018, 73, 914–920. [Google Scholar] [CrossRef]





| Study | Sensors/System | Dataset Information | Features | Detection |
|---|---|---|---|---|
| Barajas-Montiel and Reyes-Garcia [25] | Microphone | 1627—samples of hunger and pain cries (acoustic data of infants) | Acoustic features by means of frequencies | Hunger cry, no-hunger cry, pain cry and no-pain cry |
| Krishnan et al. [4] | VAS | 13—subjects plasma concentrations of satiety hormones from blood samples | Feature learning (ANN) | VAS responses from satiety hormone values |
| Bellmann et al. [19] | In vitro gastrointestinal model | Gastric viscosity and intestinal digestion from tiny-TIMagc | - | Fullness vs. Hunger |
| Rahman et al. [20] | Microsoft Band, Affectiva Q sensor, Microphone | 8—subjects (3 female, 5 male) from 26 to 54 years | Statistical features | Time until the next eating event, and about-to-eat |
| Al-Zubaidi et al. [21] | fMRI | 24—male subjects from 20 to 30 years (fMRI data) | 3—features (DC, ReHo and fALFF) | Neuronal resting state alterations changes during hunger and satiety |
| Lakshmi et al. [22] | EEG | EEG signals | - | Hunger, thirst, EEG signals sensations |
| Maria and Jeyaseelan [23] | Microphone | Synthetically collected audio signals through mobile phones | SF, CDF and GCC | Growling vs. Burp sound |
| Gogate and Bakal [24] | EDA | 35—patients ( 20 of them used as control group ) | - | Hunger vs. Stress |
| Hand-Crafted Features | |
|---|---|
| Maximum | Minimum |
| Average | Standard deviation |
| Zero-crossing | Percentile 20 |
| Percentile 50 | Percentile 80 |
| Interquartile | Skewness |
| Kurtosis | Auto-correlation |
| First-order mean | Second-order mean |
| Norm of the first-order mean | Norm of the second-order mean |
| Spectral energy | Spectral entropy |
| Layer Name | Neurons/Dropout Rate | Activation |
|---|---|---|
| Dense | 64 | ReLU |
| Batch Norm | - | - |
| Dense | 16 | ReLU |
| Dropout | 0.5 | - |
| Flatten | - | - |
| Dense | 8 | ReLU |
| Dropout | 0.5 | - |
| Dense | 2 | Softmax |
| Layer Name | No. Kernels (Units) | Kernel (Pool) Size | Stride | Activation |
|---|---|---|---|---|
| Convolutional | 64 | (1,1) | (1,1) | ReLU |
| Batch Norm | - | - | - | - |
| Convolutional | 32 | (1,1) | (1,1) | ReLU |
| Convolutional | 16 | (1,1) | (1,1) | ReLU |
| Flatten | - | - | - | - |
| Dense | 2 | - | - | Softmax |
| Classifier | Win Size (T) | Step Size (S) | Acc. Hungry | Acc. Satiety | Acc | AF1 Score |
|---|---|---|---|---|---|---|
| SVM | 10 | 05 | 20.90 | 70.37 | 56.89 | 45.63 |
| DT | 10 | 05 | 27.94 | 70.40 | 58.04 | 49.17 |
| RF | 10 | 05 | 30.97 | 71.75 | 59.90 | 51.36 |
| SVM | 30 | 15 | 21.61 | 68.86 | 55.43 | 45.24 |
| DT | 30 | 15 | 21.93 | 71.54 | 58.29 | 46.73 |
| RF | 30 | 15 | 38.59 | 73.23 | 62.71 | 55.91 |
| SVM | 60 | 30 | 13.19 | 69.50 | 55.00 | 41.34 |
| DT | 60 | 30 | 18.44 | 79.43 | 67.14 | 48.93 |
| RF | 60 | 30 | 36.36 | 82.05 | 72.00 | 59.21 |
| Sensor | Acc. Hungry | Acc. Satiety | Acc | AF1 Score |
|---|---|---|---|---|
| Tmp | 73.08 | 95.30 | 92.00 | 84.19 |
| Eda_E4 | 70.59 | 94.98 | 91.43 | 82.79 |
| BVP | 67.35 | 94.68 | 90.86 | 81.02 |
| Eda_RB | 62.18 | 92.25 | 87.14 | 77.22 |
| IBI | 43.48 | 91.95 | 85.14 | 67.46 |
| HR | 40.45 | 91.33 | 84.86 | 65.89 |
| EMG | 30.95 | 90.58 | 83.43 | 60.77 |
| Resp | 29.30 | 79.56 | 68.29 | 54.43 |
| EOG | 39.25 | 73.25 | 62.86 | 56.25 |
| ECG | 21.59 | 73.66 | 60.57 | 47.63 |
| No. of Best Features | Acc. Hungry | Acc. Satiety | Acc | AF1 Score |
|---|---|---|---|---|
| 18 | 79.65 | 96.08 | 93.43 | 87.86 |
| 54 | 66.02 | 94.14 | 90.00 | 80.08 |
| 72 | 68.18 | 95.42 | 92.00 | 81.80 |
| 90 | 68.00 | 94.67 | 90.86 | 81.33 |
| 108 | 67.33 | 94.49 | 90.57 | 80.91 |
| Classifier | Acc. Hungry | Acc. Satiety | Acc | AF1 Score |
|---|---|---|---|---|
| MLP | 77.79 | 81.35 | 80.14 | 79.57 |
| CNN | 81.37 | 83.70 | 82.90 | 82.54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Irshad, M.T.; Nisar, M.A.; Huang, X.; Hartz, J.; Flak, O.; Li, F.; Gouverneur, P.; Piet, A.; Oltmanns, K.M.; Grzegorzek, M. SenseHunger: Machine Learning Approach to Hunger Detection Using Wearable Sensors. Sensors 2022, 22, 7711. https://doi.org/10.3390/s22207711
Irshad MT, Nisar MA, Huang X, Hartz J, Flak O, Li F, Gouverneur P, Piet A, Oltmanns KM, Grzegorzek M. SenseHunger: Machine Learning Approach to Hunger Detection Using Wearable Sensors. Sensors. 2022; 22(20):7711. https://doi.org/10.3390/s22207711
Chicago/Turabian StyleIrshad, Muhammad Tausif, Muhammad Adeel Nisar, Xinyu Huang, Jana Hartz, Olaf Flak, Frédéric Li, Philip Gouverneur, Artur Piet, Kerstin M. Oltmanns, and Marcin Grzegorzek. 2022. "SenseHunger: Machine Learning Approach to Hunger Detection Using Wearable Sensors" Sensors 22, no. 20: 7711. https://doi.org/10.3390/s22207711