2.2. The Plug-in Estimator
Perhaps the simplest and most straightforward estimator for the entropy rate is the so-called plug-in estimator. Given a data sequence
of length
n, and an arbitrary string, or “word,”
∈
Aw of length
w < n, let
denote the empirical probability of the word
in
; that is,
is the frequency with which
appears in
. If the data are produced from a stationary and ergodic
†process, then the law of large numbers guarantees that, for fixed
w and large
n, the empirical distribution
will be close to the true distribution
pw, and therefore a natural estimator for the entropy rate based on (1) is:
This is the
plug-in estimator with word-length w. Since the empirical distribution is also the maximum likelihood estimate of the true distribution, this is also often referred to as the
maximum-likelihood entropy estimator.
Suppose the process
X is stationary and ergodic. Then, taking
w large enough for
to beacceptably close to
H in (1), and assuming the number of samples
n is much larger than
w so that the empirical distribution of order
w is close to the true distribution, the plug-in estimator
Ĥn,w,plug−in will produce an accurate estimate for the entropy rate. But, among other difficulties, in practice this leads to enormous computational problems because the number of all possible words of length
w grows
exponentially with
w. For example, even for the simple case of binary data with a modest word-length of
w = 30, the number of possible strings
is 2
30, which in practice means that the estimator would either require astronomical amounts of data to estimate
accurately, or it would be severely undersampled. See also [
43] and the references therein for a discussion of the undersampling problem.
Another drawback of the plug-in estimator is that it is hard to quantify its bias and to correct for it. For any fixed word-length
w, it is easy to see that the bias
E[
Ĥn,w,plug−in] −
) is always negative [
12,
13], whereas the difference between the
wth-order per-symbol entropy and the entropy rate,
) −
H(
X). is always nonnegative. Still, there have been numerous extensive studies on calculating this bias and on developing ways to correct for it; see [
13,
18,
20,
24,
27,
28] and the references therein.
2.3. The Lempel-Ziv Estimators
An intuitively appealing and popular way of estimating the entropy of discrete data with possibly long memory, is based on the use of so-called
universal data compression algorithms. These are algorithms that are known to be able to optimally compress data from an arbitrary process (assuming some broad conditions are satisfied), where optimality means that the compression ratio they achieve is asymptotically equal to the entropy rate of the underlying process – although the statistics of this process are
not assumed to be known
a priori. Perhaps the most commonly used methods in this context are based on a family of compression schemes known as Lempel-Ziv (LZ) algorithms; see, e.g., [
36,
37,
44].
Since the entropy estimation task is simpler than that of actually compressing the data, several modified versions of the original compression algorithms have been proposed and used extensively in practice. All these methods are based on the calculation of the lengths of certain repeating patterns in the data. Specifically, given a data realization
x = (. . . ,
x−1,
x0,
x1,
x2, . . .), for every position
i in
x and any “window length”
n ≥ 1, consider the length
ℓ of the longest segment
in the data starting at
i which also appears in the window
of length
n preceding position
i. Formally, define
as 1+ [that longest match-length]:
Suppose that the process
X is stationary and ergodic, and consider the random match-lengths
. In [
44,
45] it was shown that, for any fixed position
i, the match-lengths grow logarithmically with the window size
n, and in fact,
where
H is the entropy rate of the process. This result suggests that the quantity (log
n)/
can be used as an entropy estimator, and, clearly, in order to make more efficient use of the data and reduce the variance, it would be more reasonable to look at the average value of various match-lengths
taken at different positions
i; see the discussion in [
9]. To that effect, the following two estimators are considered in [
9]. Given a data realization
, a window length
n ≥ 1, and a number of matches
k ≥ 1, the
sliding-window LZ estimator Ĥn,k =
Ĥn,k(
x) =
Ĥn,k(
) is defined by,
Similarly, the
increasing-window LZ estimator Ĥn =
Ĥn(
x) =
Ĥn(
) is defined by,
The difference between the two estimators in (3) and (4) is that Ĥn,k uses a fixed window length, while Ĥn uses the entire history as its window, so that the window length increases as the matching position moves forward.
In [
9] it is shown that, under appropriate conditions, both estimators
Ĥn,k and
Ĥn are consistent, in that they converge to the entropy rate of the underlying process with probability 1, as
n, k → ∞. Specifically, it is assumed that the process is stationary and ergodic, that it takes on only finitely many values, and that it satisfies the
Doeblin Condition (DC). This condition says that there is a finite number of steps, say
r, in the process, such that, after
r time steps, no matter what has occurred before, anything can happen with positive probability:
Doeblin Condition (DC). There exists an integer
r ≥ 1 and a real number
β > 0 such that,
for all
a ∈
A and with probability one in the conditioning, i.e., for almost all semi-infinite realizations of the past
.
Condition (DC) has the advantage that it is not quantitative – the values of r and β can be arbitrary – and, therefore, for specific applications it is fairly easy to see whether it is satisfied or not. But it is restrictive, and, as it turns out, it can be avoided altogether if we consider a modified version of the above two estimators.
To that end, we define two new estimators
and
as follows. Given
x =
,
n and
k as above, define the new sliding-window estimator
,
and the new increasing-window estimator
as,
Below some basic properties of these four estimators are established, and conditions are given for their asymptotic consistency. Parts (i) and (iii) of Theorem 2.1 are new; most of part (ii) is contained in [
9].
Theorem 2.1. [C
onsistency of LZ-
type E
stimators]
- (i)
When applied to an arbitrary
data string, the estimators defined in (3)–(6)
always satisfy,
for any n, k. - (ii)
The estimators Ĥn,k and Ĥn are consistent when applied to data generated by a finite-valued, stationary, ergodic process that satisfies Doeblin’s condition (DC)
. With probability one we have: - (iii)
The estimators and are consistent when applied to data generated by an arbitrary finite-valued, stationary, ergodic process,
even if (DC)
does not hold. With probability one we have:
Note that parts (ii) and (iii) do not specify the manner in which
n and
k go to infinity. The results are actually valid in the following cases:
If the two limits as n and k tend to infinity are taken separately, i.e., first k → ∞ and then n → ∞, or vice versa;
If k → ∞ and n = nk varies with k in such a way that nk → ∞ as k → ∞;
If n → ∞ and k = kn varies with n in such a way that it increases to infinity as n → ∞;
If k and n both vary arbitrarily in such a way that k stays bounded and n → ∞.
Proof. P
art (i). An application of Jensen’s inequality to the convex function
x ↦ 1/
x, with respect to the uniform distribution (1/
k,. . . , 1/
k) on the set {1, 2, . . . ,
k}, yields,
as required. The proof of the second assertion is similar.
P
art (ii). The results here are, for the most part, proved in [
9], where it is established that
Ĥn →
H and
Ĥn,n →
H as
n → ∞, with probability one. So it remains to show that
Ĥn,k →
H as
n, k → ∞ in each of the four cases stated above.
For case 1 observe that, with probability 1,
where (
a) follows from (2). To reverse the limits, we define, for each fixed
n, a new process
by letting
/(log
n) for each
i. Then the process
is itself stationary and ergodic. Recalling also from [
9] that the convergence in (2) takes place not only with probability one but also in
L1, we may apply the ergodic theorem to obtain that, with probability 1,
where (
b) follows by the ergodic theorem and (
c) from the
L1 version of (2).
The proof of case 2 is identical to the case
k =
n considered in [
9]. In case 3, since the sequence {
kn} is increasing, the limit of
Hkn,n reduces to a subsequence of the corresponding limit in case 2 upon considering the inverse sequence {
nk}.
Finally for case 4, recall from (7) that,
for any fixed
k. Therefore the same will hold with a varying
k, as long as it varies among finitely many values.
P
art (iii). The proofs of the consistency results for
and
can be carried out along the same lines as the proofs of the corresponding results in [
9], together with their extensions as in Part (ii) above. The only difference is in the main technical step, namely, the verification of a uniform integrability condition. In the present case, what is needed is to show that,
This is done in the following lemma. ☐
Lemma 2.1. Under the assumptions of part (iii) of the theorem, the L1-domination condition (8) holds true.
Proof. Given a data realization
x = (. . . ,
x−2,
x−1,
x0,
x1,
x2, . . .) and an
m ≥ 1, the recurrence time
Rm is defined as the first time the substring
appears again in the past. More precisely,
Rm is the number of steps to the left of
we have to look in order to find a copy of
:
For any such realization
x and any
n ≥ 1, if we take
m =
, then by the definitions of
Rm and
it follows that,
Rm >
n, which implies,
and thus it is always the case that,
Therefore, to establish (8) it suffices to prove:
To that end, we expand this expectation as,
where
K is an arbitrary integer to be chosen later. Applying Markov’s inequality,
To calculate the expectation of
Rm, suppose that the process
X takes on
α = |
A| possible values, so that there are
αm possible strings
of length
m. Now recall Kac’s theorem [
44] which states that
, from which it follows that,
Combining (10) and (11) yields,
where we choose
K > log
α. This establishes (9) and completes the proof. ☐
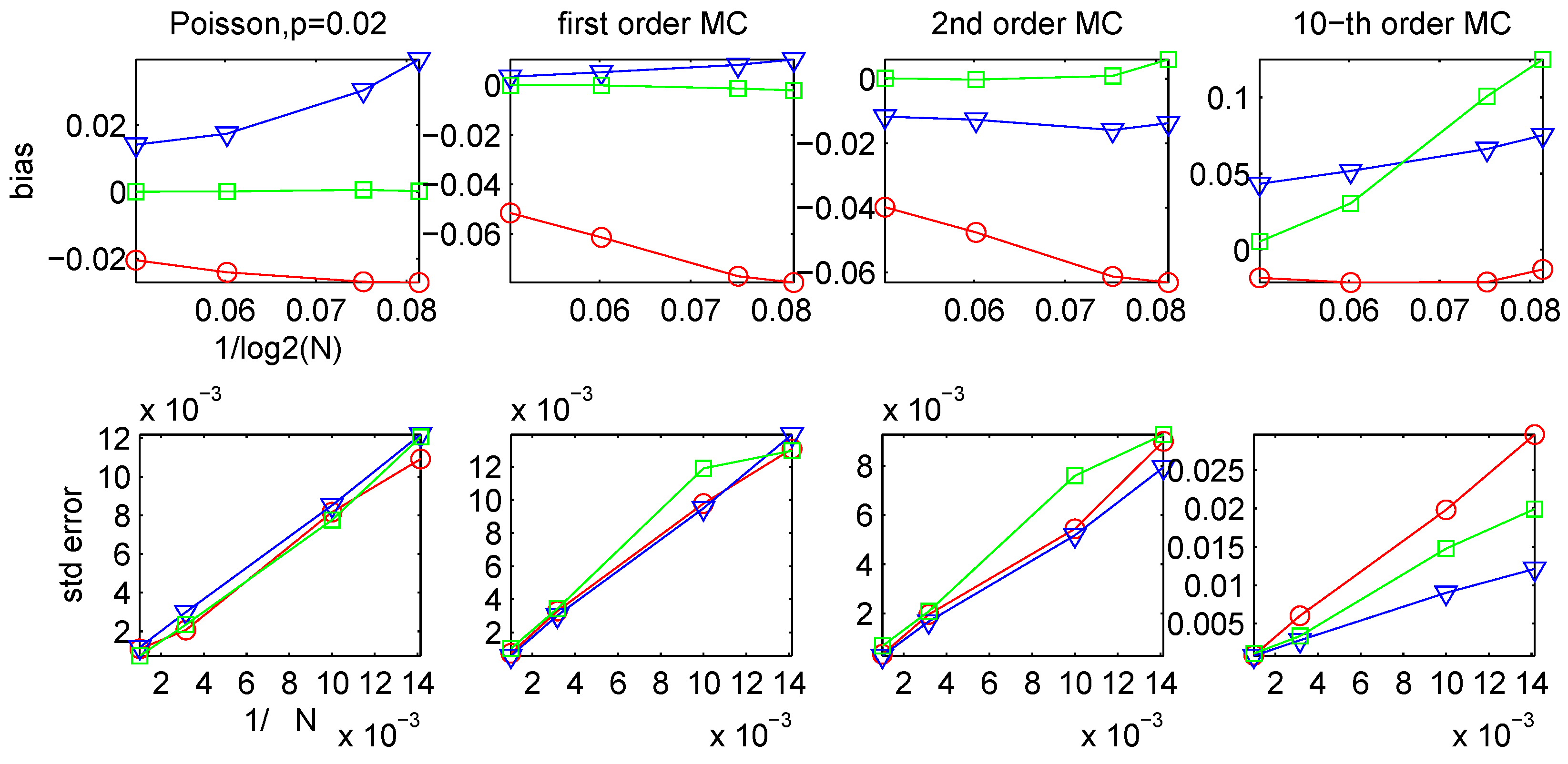
2.4. Bias and Variance of the LZ-based Estimators
In practice, when applying the sliding-window LZ estimators
Ĥn,k or
on finite data strings, the values of the parameters
k and
n need to be chosen, so that
k +
n is approximately equal to the total data length. This presents the following dilemma: Using a long window size
n, the estimators are more likely to capture the longer-term trends in the data, but, as shown in [
46,
47], the match-lengths
starting at different positions
i have large fluctuations. So a large window size
n and a small number of matching positions
k will give estimates with high variance. On the other hand, if a relatively small value for
n is chosen and the estimate is an average over a large number of positions
k, then the variance will be reduced at the cost of increasing the bias, since the expected value of
/log
n is known to converge to 1/
H very slowly [
48].
Therefore
n and
k need to be chosen in a way such that the above bias/variance trade-off is balanced. From the earlier theoretical results of [
46,
47,
48,
49,
50] it follows that, under appropriate conditions, the bias is approximately of the order
O(1/log
n), whereas from the central limit theorem it is easily seen that the variance is approximately of order
O(1/
k). This indicates that the relative values of
n and
k should probably be chosen to satisfy
k ≈
O((log
n)
2).
Although this is a useful general guideline, we also consider the problem of empirically evaluating the relative estimation error on particular data sets. Next we outline a bootstrap procedure, which gives empirical estimates of the variance
Ĥn,k and
; an analogous method was used for the estimator
Ĥn,k in [
21], in the context of estimating the entropy of whale songs.
Let
L denote the sequence of match-lengths
computed directly from the data, as in the definitions of
Ĥn,k and
. Roughly speaking, the proposed procedure is carried out in three steps: First, we sample with replacement from
L in order to obtain many pseudo-time series with the same length as
L; then we compute new entropy estimates from each of the new sequences using
Ĥn,k or
; and finally we estimate the variance of the initial entropy estimates as the sample variance of the new estimates. The most important step is the sampling, since the elements of sequence
are
not independent. In order to maintain the right form of dependence, we adopt a version of the
stationary bootstrap procedure of [
51]. The basic idea is, instead of sampling individual
’s from
L, to sample whole blocks with random lengths. The choice of the distribution of their lengths is made in such a way as to guarantee that they are typically long enough to maintain sufficient dependence as in the original sequence. The results in [
51] provide conditions which justify the application of this procedure.
The details of the three steps above are as follows: First, a random position
j ∈ {1, 2, . . . ,
k} is selected uniformly at random, and a random length
T is chosen with geometric distribution with mean 1/
p (the choice of
p is discussed below). Then the block of match-lengths
copied from
L, and the same process is repeated until the concatenation
L* of the sampled blocks has length
k. This gives the first bootstrap sample. Then the whole process is repeated to generate a total of
B such blocks
L*
1,
L*
2, . . . ,
L*
B, each of length
k. From these we calculate new entropy estimates
Ĥ *(
m) or
*(
m), for
m = 1, 2, . . . ,
B, according to the definition of the entropy estimator being used, as in (3) or (5), respectively; the choice of the number
B of blocks is discussed below. The bootstrap estimate of the variance of
Ĥ is,
where
similarly for
.
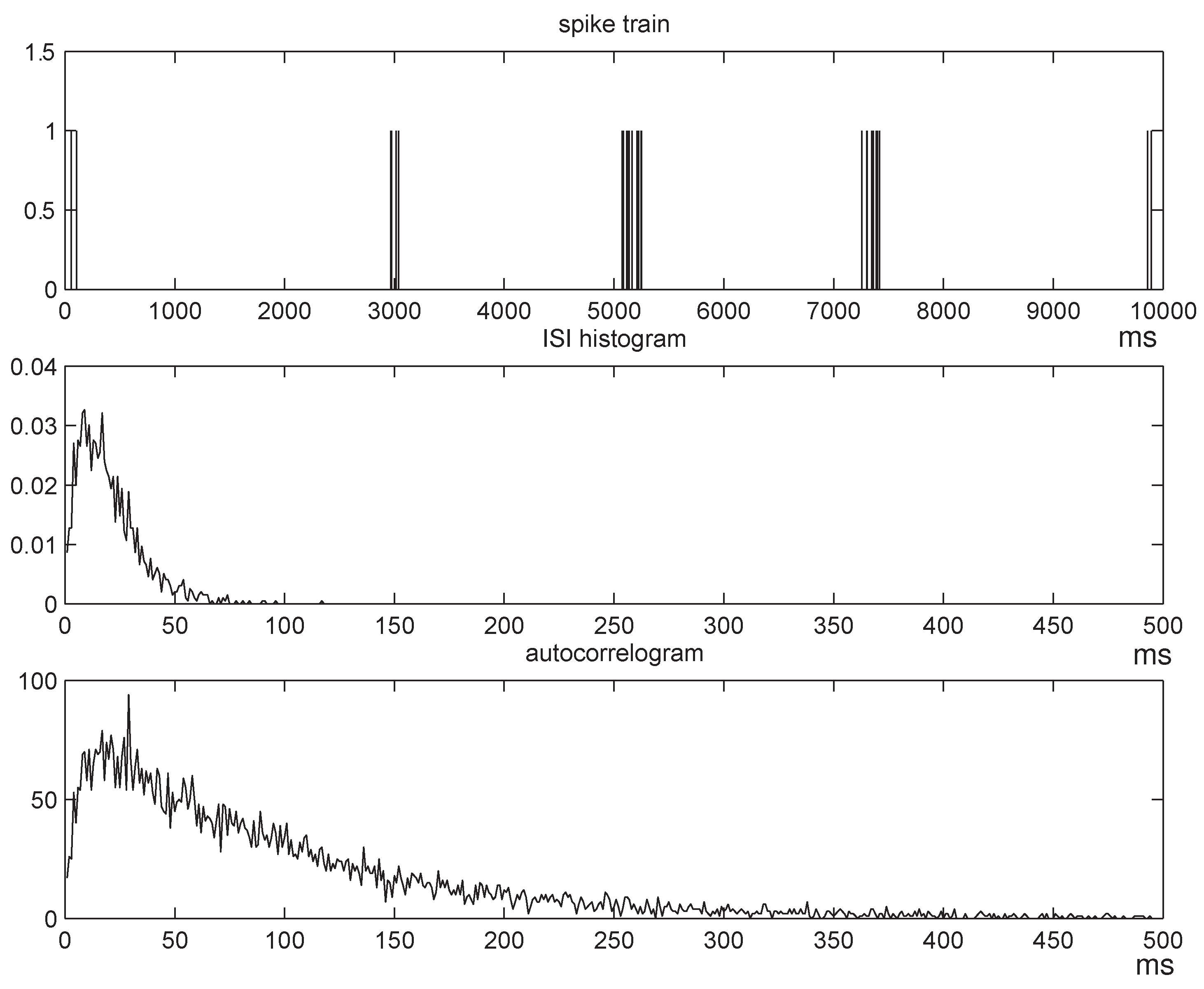
The choice of the parameter
p depends on the length of the memory of the match-length sequence
; the longer the memory, the larger the blocks need to be, therefore, the smaller the parameter
p. In practice,
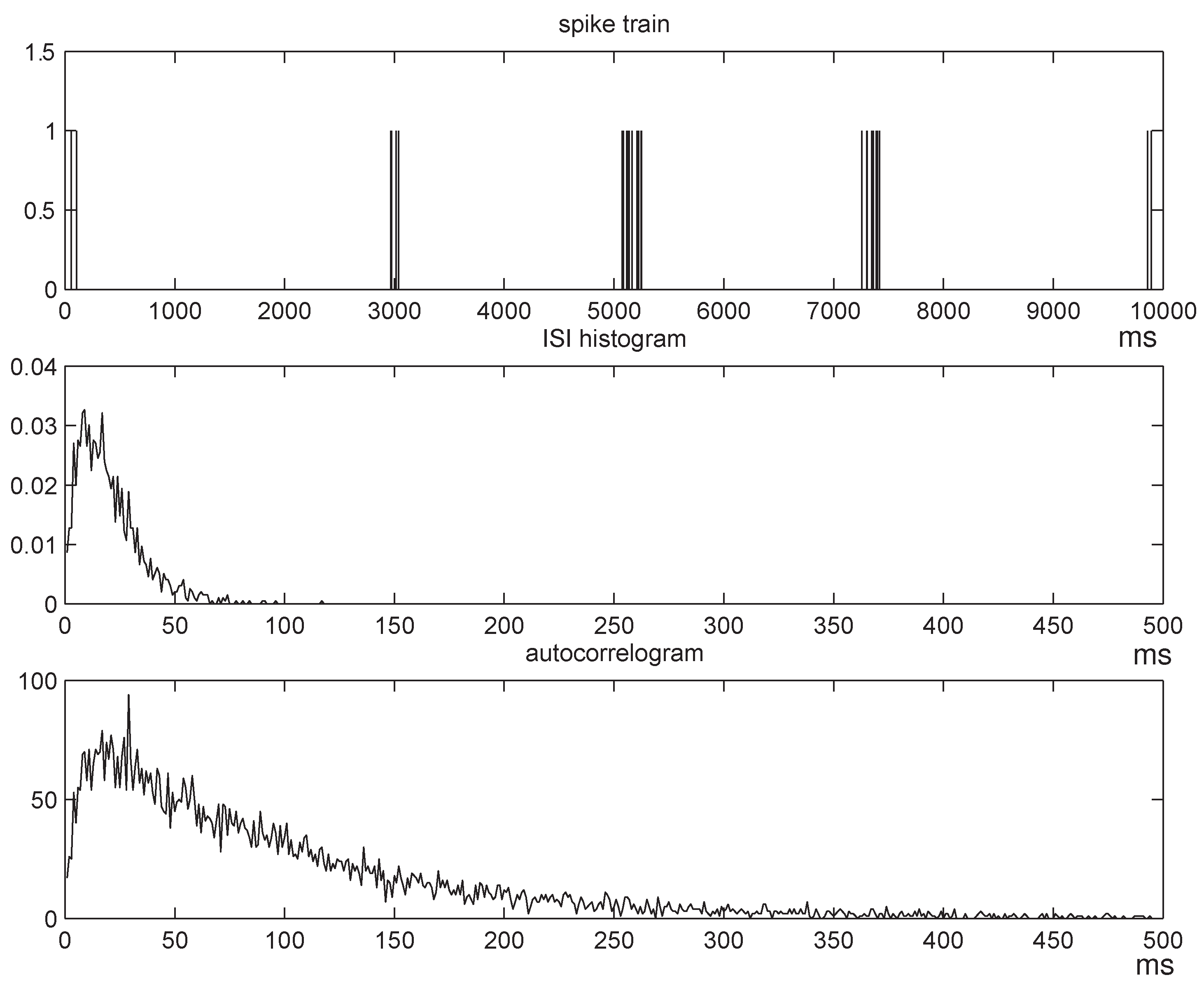
p is chosen by studying the autocorrelogram of
L, which is typically decreasing with the lag: We choose an appropriate cutoff threshold, take the corresponding lag to be the average block size, and choose
p as the reciprocal of that lag. Finally, the number of blocks
B is customarily chosen large enough so that the histogram of the bootstrap samples
Ĥ *(1),
Ĥ *(2), . . . ,
Ĥ *(
B) “looks” approximately Gaussian. Typical values used in applications are between
B = 500 and
B = 1000. In all our experiments in [
33,
34] and in the results presented in the following section we set
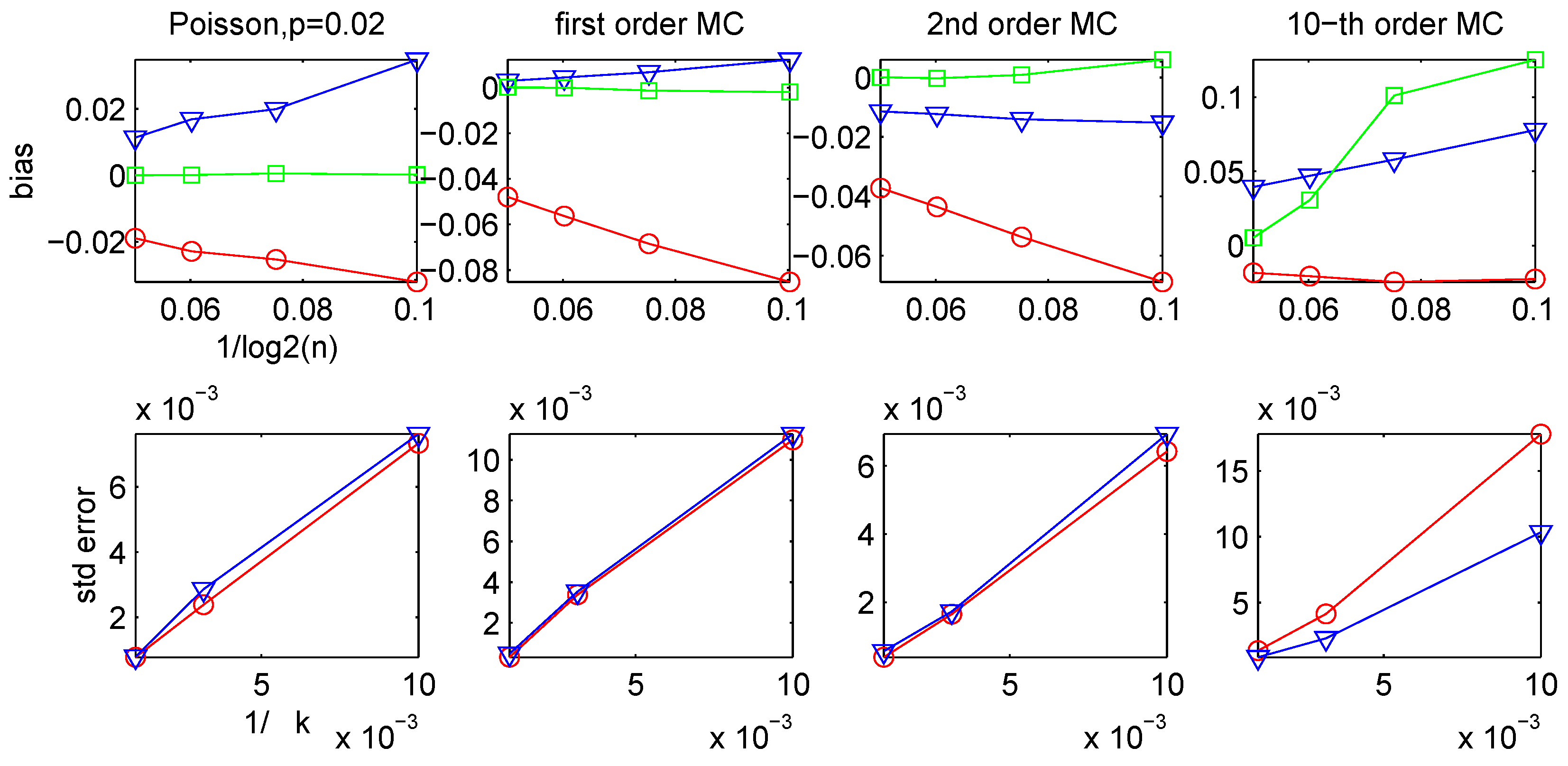
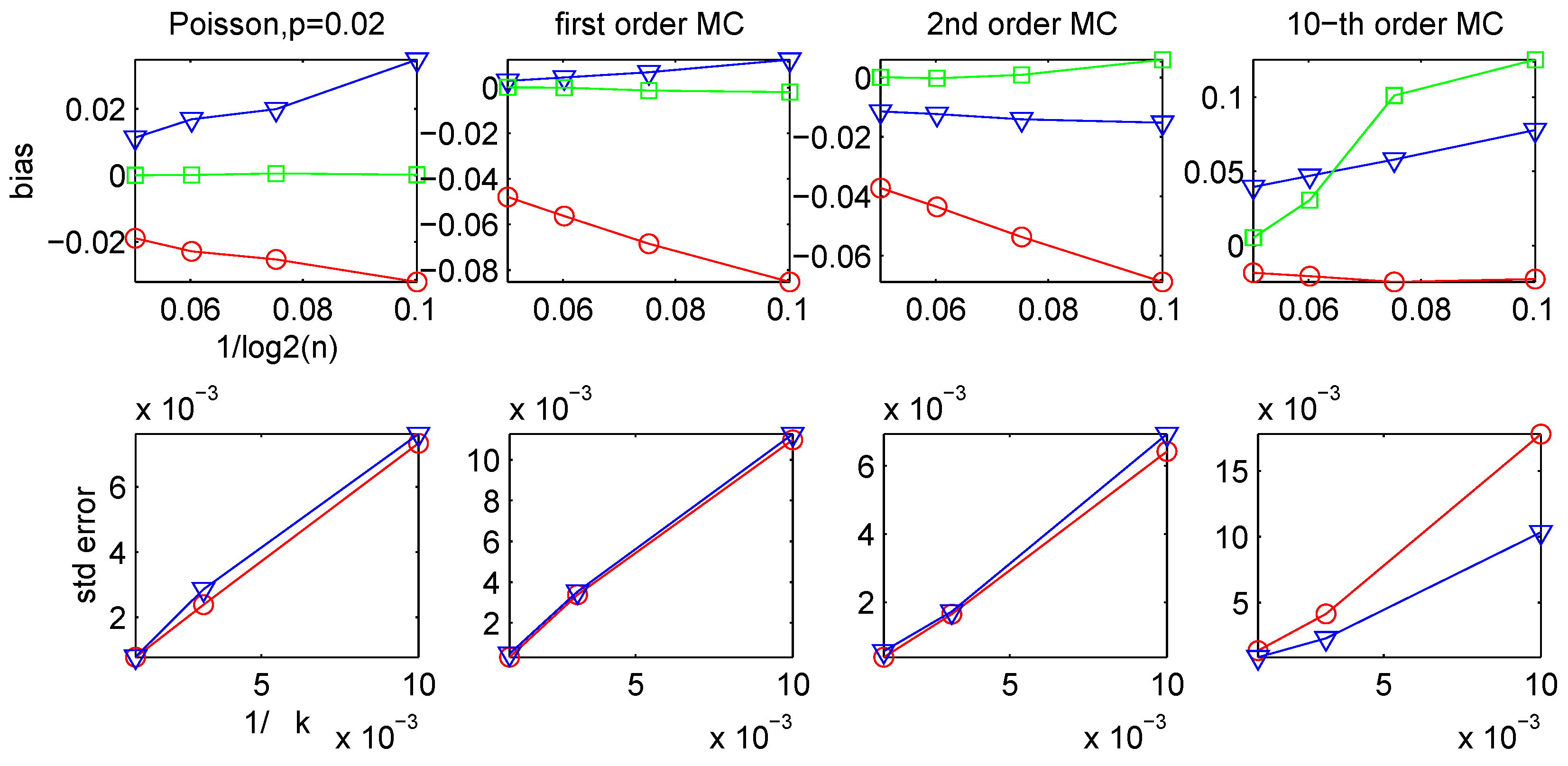
B = 1000, which, as discussed below, appears to have been sufficiently large for the central limit theorem to apply to within a close approximation.
2.5. Context-Tree Weighting
One of the fundamental ways in which the entropy rate arises as a natural quantity, is in the Shannon- McMillan-Breiman theorem [
41]; it states that, for any stationary and ergodic process
with entropy rate
H,
where
denotes the (random) probability of the random string
. This suggests that, one way to estimate
H from a long realization
of
X, is to first somehow estimate its probability and then use the estimated probability
to obtain an estimate for the entropy rate via,
The Context-Tree Weighting (CTW) algorithm [
38,
39,
40] is a method, originally developed in the context of data compression, which can be interpreted as an implementation of hierarchical Bayesian procedure for estimating the probability of a string generated by a binary “tree process.”
‡The details of the precise way in which the CTW operates can be found in [
38,
39,
40]; here we simply give a brief overview of what (and not how) the CTW actually computes. In order to do that, we first need to describe tree processes.
A
binary tree process of depth D is a binary process
X with a distribution defined in terms of a
suffix set S, consisting of binary strings of length no longer than
D, and a parameter vector
θ = (
θs;
s ∈
S), where each
θs ∈ [0, 1]. The suffix set
S is assumed to be complete and proper, which means that any semi-infinite binary string
has exactly one suffix
s is
S, i.e., there exists exactly one
s ∈
S such that
can be written as
s, for some integer
k.
§We write
s =
s(
) ∈
S for this unique suffix.
Then the distribution of
X is specified by defining the conditional probabilities,
It is clear that the process just defined could be thought of simply as a
D-th order Markov chain, but this would ignore the important information contained in
S: If a suffix string
s ∈
S has length
ℓ <
D, then, conditional on any past sequence
which ends in
s, the distribution of
Xn+1 only depends on the most recent
ℓ symbols. Therefore, the suffix set offers an economical way for describing the transition probabilities of
X, especially for chains that can be represented with a relatively small suffix set.
Suppose that a certain string
has been generated by a tree process of depth no greater than
D, but with unknown suffix set
S* and parameter vector
θ* = (
θ*s;
s ∈
S). Following classical Bayesian methodology, we assign a
prior probability
π(
S) on each (complete and proper) suffix set
S of depth
D or less, and, given
S, we assign a prior probability
π(
θ|
S) on each parameter vector
θ = (
θs). A Bayesian approximation to the true probability of
(under
S* and
θ*) is the mixture probability,
where
PS,θ(
) is the probability of
under the distribution of a tree process with suffix set
S and parameter vector
θ. The expression in (14) is, in practice, impossible to compute directly, since the number of suffix sets of depth ≤
D (i.e., the number of terms in the sum) is of order 2
D. This is obviously prohibitively large for any
D beyond 20 or 30.
The CTW algorithm is an efficient procedure for computing the mixture probability in (14), for a specific choice of the prior distributions
π(
S),
π(
θ|
S): The prior on
S is,
where |
S| is the number of elements of
S and
N (
S) is the number of strings in
S with length strictly smaller than
D. Given a suffix set
S, the prior on
θ is the product
-Dirichlet distribution, i.e., under
π(
θ|
S) the individual
θs are independent, with each
θs ∼ Dirichlet
.
The main practical advantage of the CTW algorithm is that it can actually compute the probability in (14) exactly. In fact, this computation can be performed sequentially, in linear time in the length of the string
n, and using an amount of memory which also grows linearly with
n. This, in particular, makes it possible to consider much longer memory lengths
D than would be possible with the plug-in method.
The CTW Entropy Estimator. Thus motivated, given a
binary string
, we define the
CTW entropy estimator Ĥn,D, ctw as,
Where
is the mixture probability in (14) computed by the CTW algorithm. [Corresponding proceedures are similarly described in [
25,
29].] The justification for this definition comes from the discussion leading to equation (13) above. Clearly, if the true probability of
is
P*(
), the estimator performs well when,
In many cases this approximation can be rigorously justified, and in certain cases it can actually be accurately quantified.
Assume that
is generated by an unknown tree process (of depth no greater than
D) with suffix set
S*. The main theoretical result of [
38] states that, for
any string
, of
any finite length
n, generated by
any such process, the difference between the two terms in (16) can be uniformly bounded above; from this it easily follows that,
This nonasymptotic, quantitative bound, easily leads to various properties of
Ĥn,D, ctw:
First, (17) combined with the Shannon-McMillan-Breiman theorem (12) and the pointwise converse source coding theorem [
52,
53], readily implies that
ĤN,D, ctw is consistent, that is, it converges to the true entropy rate of the underlying process, with probability one, as
n → ∞. Also, Shannon’s source coding theorem [
41] implies that the expected value of
Ĥn,D,ctw cannot be smaller than the true entropy rate
H; therefore, taking expectations in (17) gives,
In view of Rissanen’s [
54] well-known universal lower bound, (18) shows that the bias of the CTW is essentially as small as can be. Finally, for the variance, if we subtract
H from both sides of (17), multiply by
, and apply the central-limit refinement to the Shannon-McMillan-Breiman theorem [
55,
56], we obtain that the standard deviation of the estimates
is
, where
is the
minimal coding variance of
X [
57]. This is also optimal, in view of the second-order coding theorem of [
57].
Therefore, for data
generated by an arbitrary tree processes, the bias of the CTW estimator is of order
O(log
n/n), and its variance is
O(1/
n). Compared to the earlier LZ-based estimators, these bounds suggest much faster convergence, and are in fact optimal. In particular, the
O(log
n/n) bound on the bias indicates that, unlike the LZ-based estimators, the CTW can give useful results even on small data sets.
Extensions. An important issue for the performance of the CTW entropy estimator, especially when used on data with potentially long-range dependence, is the choice of the depth
D: While larger values of
D give the estimator a chance to capture longer-term trends, we then pay a price in the algorithm’s complexity and in the estimation bias. This issue will not be discussed further here; a more detailed discussion of this point along with experimental results can be found in [
33,
34].
The CTW algorithm has also been extended beyond finite-memory processes [
40]. The basic method is modified to produce an estimated probability
, without assuming a predetermined maximal suffix depth
D. The sequential nature of the computation remains exactly the same, leading to a corresponding entropy estimator defined analogously to the one in (15), as
. Again it is easy to show that
Ĥn,∞,ctw is consistent with probability one, this time for
every stationary and ergodic (binary) process. The price of this generalization is that the earlier estimates for the bias and variance no longer apply, although they do remain valid is the data actually come from a finite-memory process. In numerous simulation experiments we found that there is no significant advantage in using
Ĥn,D,ctw with a finite depth
D over
Ĥn,∞,ctw, except for the somewhat shorter computation time. For that reason, in all the experimental results in
Section 3.2 and
Section 3.3 below, we only report estimates obtained by
Ĥn,∞,ctw.
Finally, perhaps the most striking feature of the CTW algorithm is that it can be modified to compute the “best” suffix set
S that can be fitted to a given data string, where, following standard statistical (Bayesian) practice, “best” here means the one which is most likely under the posterior distribution. To be precise, recall the prior distributions
π(
S) and
π(
θ|
S) on suffix sets
S and on parameter vectors
θ, respectively. Using Bayes’ rule, the
posterior distribution on suffix sets
S can be expressed,
the suffix set
which maximizes this probability is called the
Maximum A posteriori Probability, or MAP, suffix set. Although the exact computation of
Ŝ is, typically, prohibitively hard to carry out directly, the
Context-Tree Maximizing (CTM) algorithm proposed in [
58] is an efficient procedure (with complexity and memory requirements essentially identical to the CTW algorithm) for computing
Ŝ. The CTM algorithm will not be used or discussed further in this work; see the discussion in [
33,
34], where it plays an important part in the analysis of neuronal data.












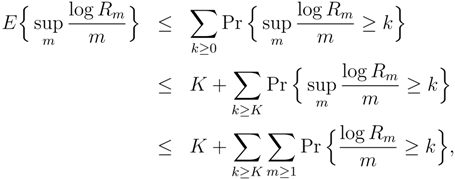





{kind=link}
{kind=link}
{kind=link}