Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables


1
Neural Computation Laboratory, Center for Neuroscience and Cognitive Systems @UniTn, Istituto Italiano di Tecnologia, 38068 Rovereto (TN), Italy
2
Department of Neurobiology, Harvard Medical School, Boston, MA 02115, USA
*
Authors to whom correspondence should be addressed.
Entropy 2017, 19(9), 451; https://doi.org/10.3390/e19090451
Submission received: 27 June 2017
/
Revised: 21 August 2017
/
Accepted: 25 August 2017
/
Published: 28 August 2017
(This article belongs to the Special Issue Information Decomposition of Target Effects from Multi-Source Interactions)
{kind=link}
{kind=link}
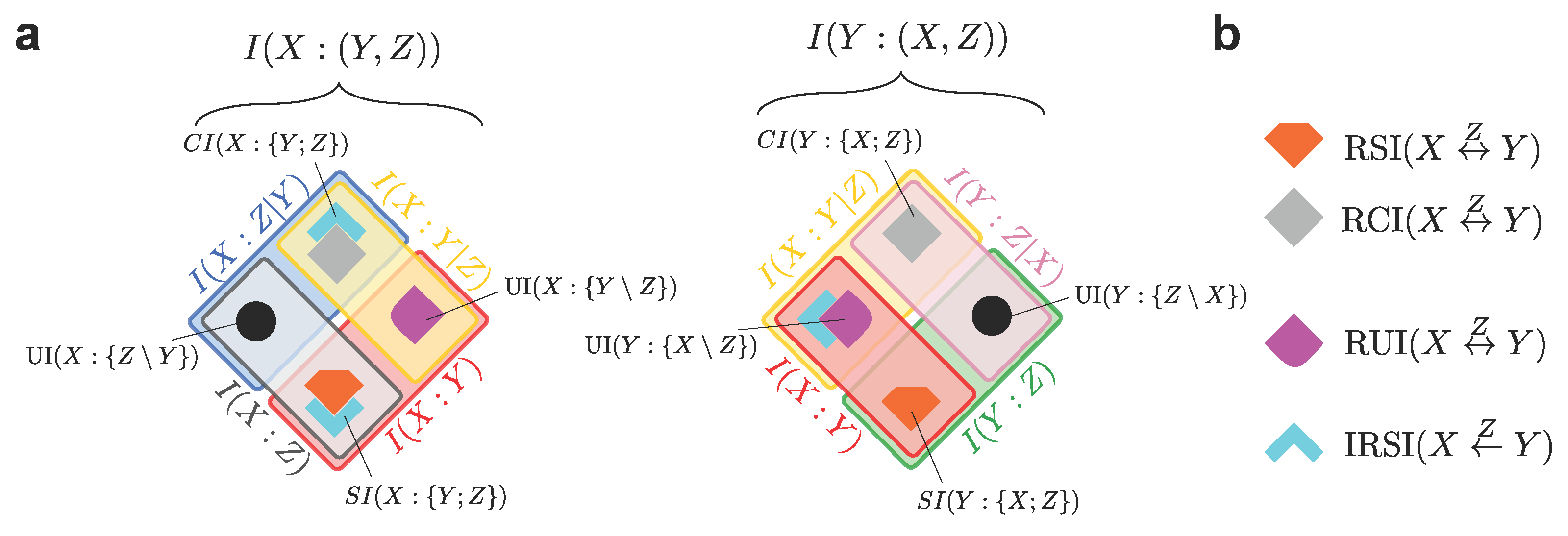{kind=link}
{kind=link}
{kind=link}
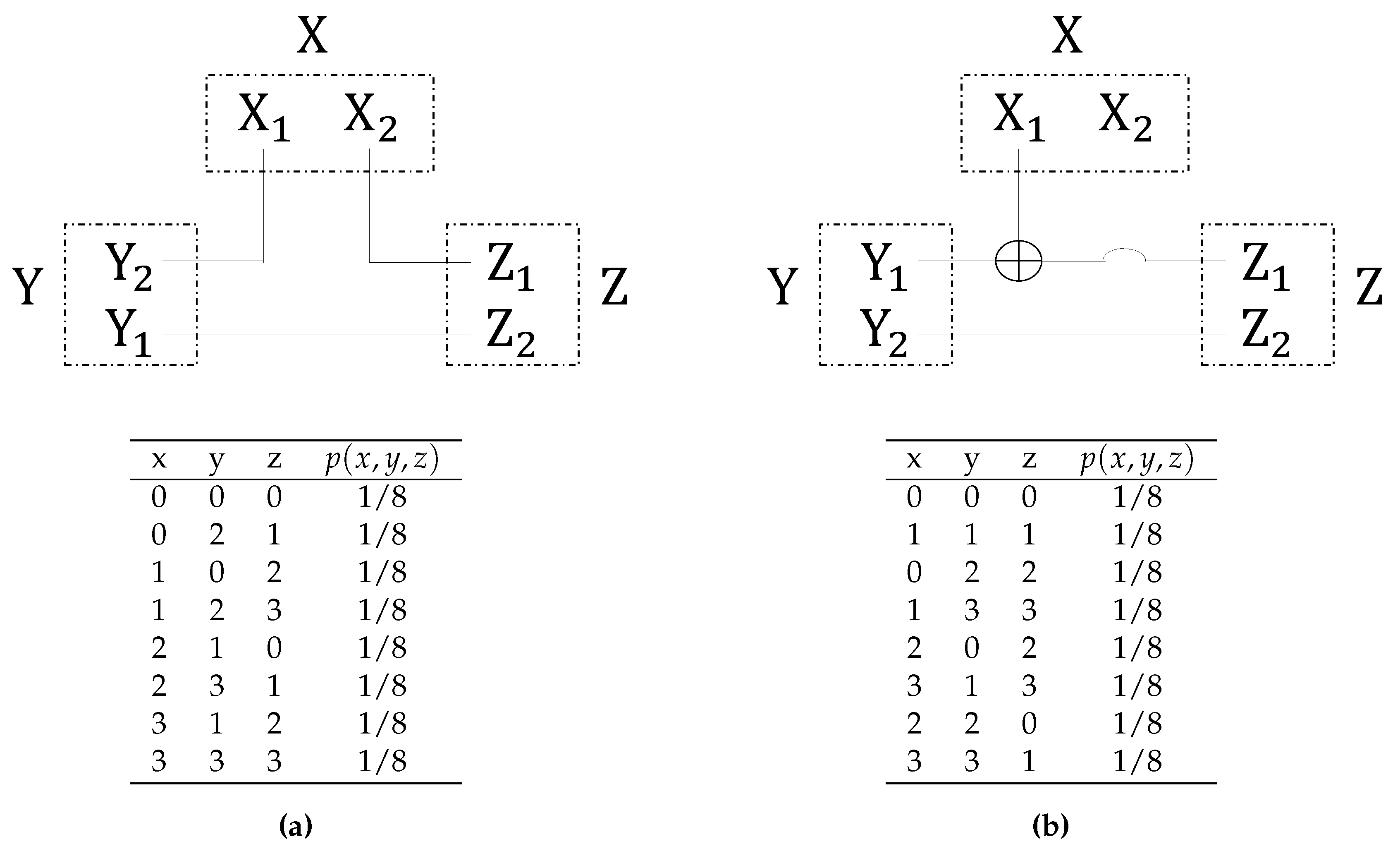{kind=link}
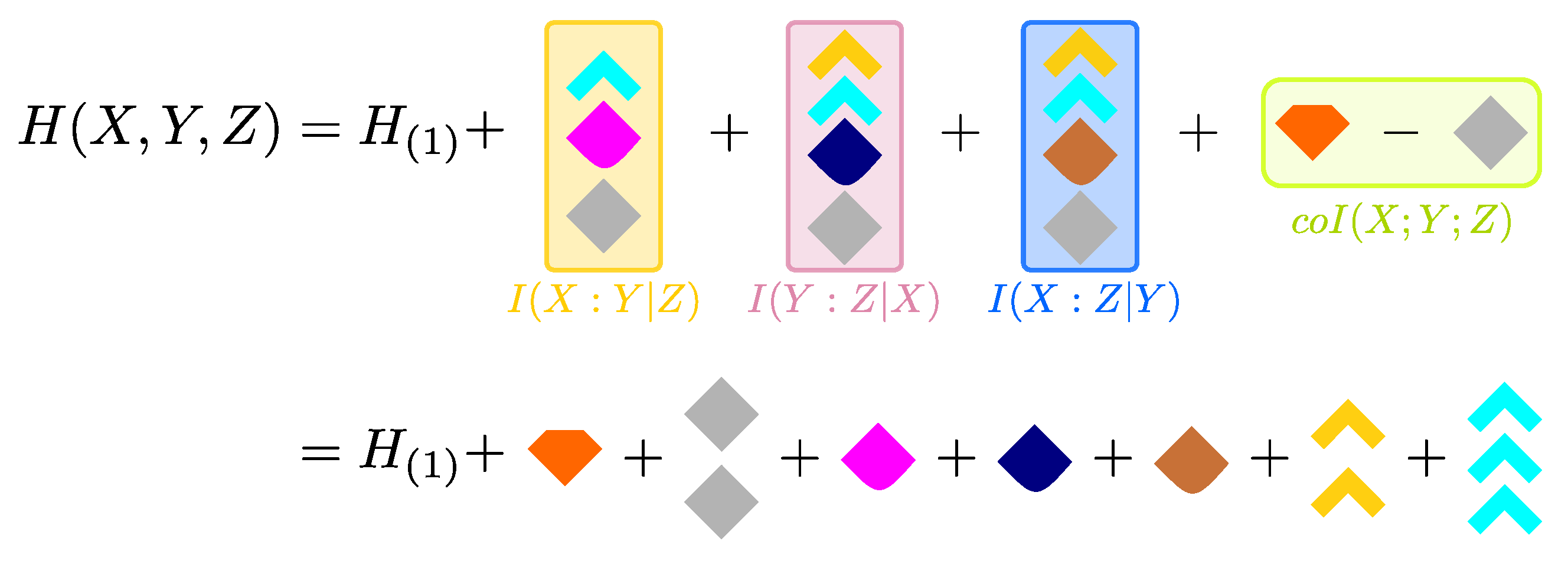{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
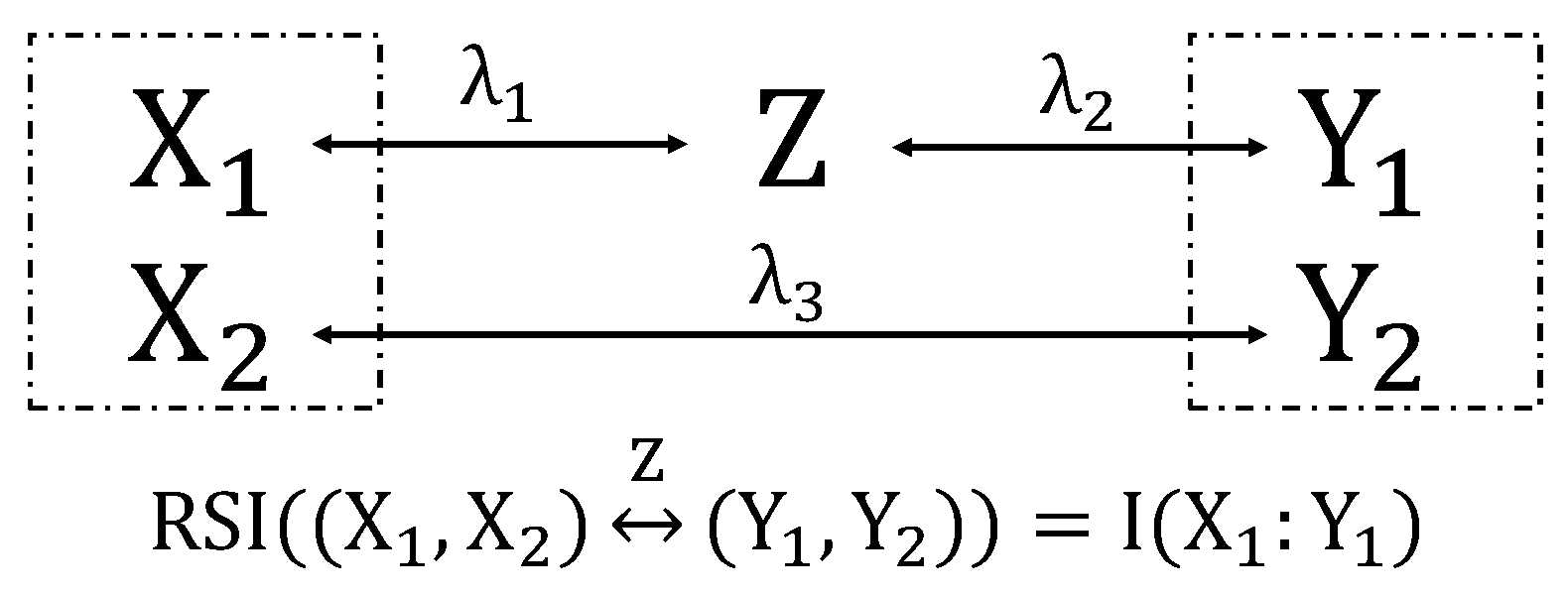{kind=link}
Abstract
:In a system of three stochastic variables, the Partial Information Decomposition (PID) of Williams and Beer dissects the information that two variables (sources) carry about a third variable (target) into nonnegative information atoms that describe redundant, unique, and synergistic modes of dependencies among the variables. However, the classification of the three variables into two sources and one target limits the dependency modes that can be quantitatively resolved, and does not naturally suit all systems. Here, we extend the PID to describe trivariate modes of dependencies in full generality, without introducing additional decomposition axioms or making assumptions about the target/source nature of the variables. By comparing different PID lattices of the same system, we unveil a finer PID structure made of seven nonnegative information subatoms that are invariant to different target/source classifications and that are sufficient to describe the relationships among all PID lattices. This finer structure naturally splits redundant information into two nonnegative components: the source redundancy, which arises from the pairwise correlations between the source variables, and the non-source redundancy, which does not, and relates to the synergistic information the sources carry about the target. The invariant structure is also sufficient to construct the system’s entropy, hence it characterizes completely all the interdependencies in the system.
1. Introduction
Shannon’s mutual information [1] provides a well established, widely applicable tool to characterize the statistical relationship between two stochastic variables. Larger values of mutual information correspond to a stronger relationship between the instantiations of the two variables in each single trial. Whenever we study a system with more than two variables, the mutual information between any two subsets of the variables still quantifies the statistical dependencies between these two subsets; however, many scientific questions in the analysis of complex systems require a finer characterization of how all variables simultaneously interact [2,3,4,5,6]. For example, two of the variables, A and B, may carry either redundant or synergistic information about a third variable C [7,8,9], but considering the value of the mutual information alone is not enough to distinguish these qualitatively different information-carrying modes. To achieve this finer level of understanding, recent theoretical efforts have focused on decomposing the mutual information between two subsets of variables into more specific information components (see e.g., [6,10,11,12]). Nonetheless, a complete framework for the information-theoretic analysis of multivariate systems is still lacking.
Characterizing the fine structure of the interactions among three stochastic variables can improve the understanding of many interesting problems across different disciplines [13,14,15,16]. For instance, this is the case for many important questions in the study of neural information processing. Determining quantitatively how two neurons encode information about an external sensory stimulus [7,8,9] requires describing the dependencies between the stimulus and the activity of the two neurons. Determining how the stimulus information carried by a neural response relates to the animal’s behaviour [17,18,19] requires the analysis of the simultaneous three-wise dependencies among the stimulus, the neural activity and the subject’s behavioral report. More generally, a thorough understanding of even the simplest information-processing systems would require the quantitative description of all different ways two inputs carry information about one output [20].
In systems where legitimate assumptions can be made about which variables act as sources of information and which variable acts as the target of information transmission, the partial information decomposition (PID) [10] provides an elegant framework to decompose the mutual information that one or two (source) variables carry about the third (target) variable into a finer lattice of redundant, unique and synergistic information atoms. However, in many systems the a priori classification of variables into sources and target is arbitrary, and limits the description of the distribution of information within the system [21]. Furthermore, even when one classification is adopted, the PID atoms do not characterize completely all the possible modes of information sharing between the sources and the target. For example, two sources can carry redundant information about the target irrespective of the strength of the correlations between them and, as a consequence, the PID redundancy atom can be larger than zero even if the sources have no mutual information [3,22,23]. Hence, the value of the PID redundancy measure cannot distinguish how the correlations between two variables contribute to the information that they share about a third variable.
In this paper, we address these limitations by extending the PID framework without introducing further axioms or assumptions about the three-variable (or trivariate) structure to analyze. We compare the atoms from the three possible PID lattices that are induced by the three possible choices for the target variable in the system. By tracking how the PID information modes change across different lattices, we move beyond the partial perspective intrinsic to a single PID lattice and unveil the finer structure common to all PID lattices. We find that this structure can be fully described in terms of a unique minimal set of seven information-theoretic quantities, which is invariant to different classifications of the variables. These quantities are derived from the PID atoms based on the relationships between different PID lattices.
The first result of this approach is the identification of two nonnegative subatomic components of the redundant information that any pair of variables carries about the third variable. The first component, that we name source redundancy (), quantifies the part of the redundancy which arises from the correlations of the sources. The second component, that we name non-source redundancy (), quantifies the part of the redundancy which is not related to the source correlations. Interestingly, we find that whenever the non-source redundancy is larger than zero then also the synergy is larger than zero. The second result is that the minimal set induces a unique nonnegative decomposition of the full joint entropy of the system. This allows us to dissect completely the distribution of information of any trivariate system in a general way that is invariant with respect to the source/target classification of the variables. To illustrate the additional insights of this new approach, we finally apply our framework to paradigmatic examples, including discrete and continuous probability distributions. These applications confirm our intuitions and clarify the practical usefulness of the finer PID structure. We also briefly discuss how our methods might be extended to the analysis of systems with more than three variables.
2. Preliminaries and State of the Art
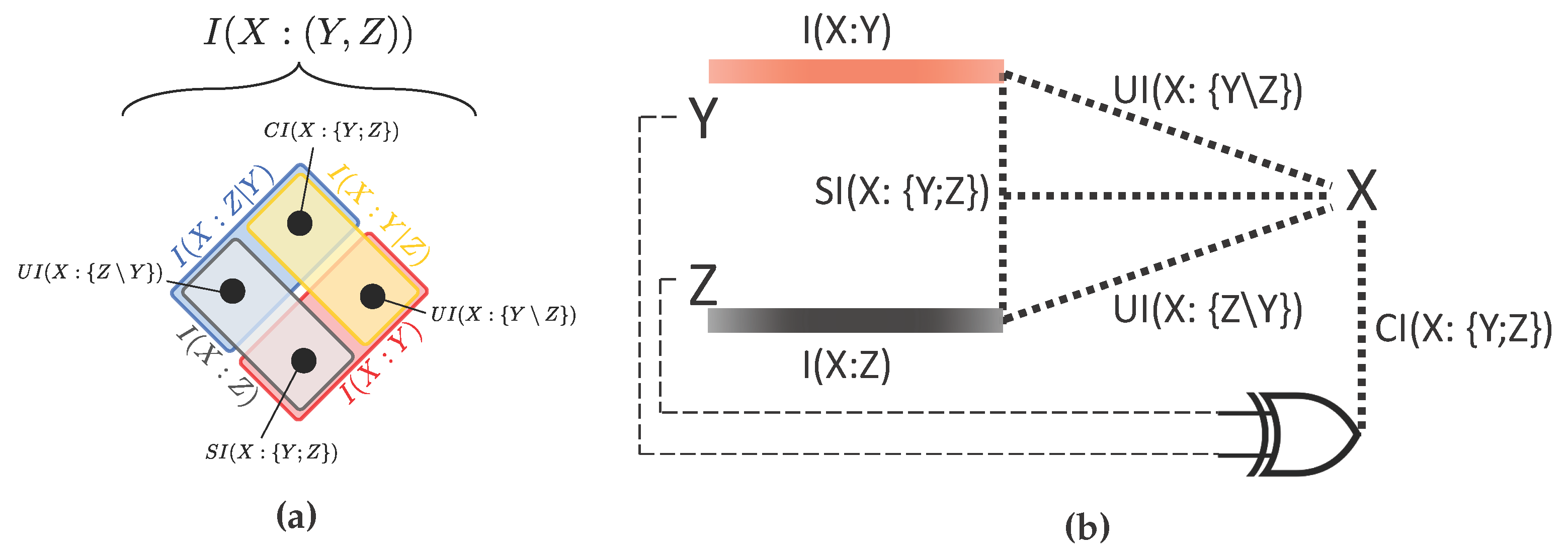
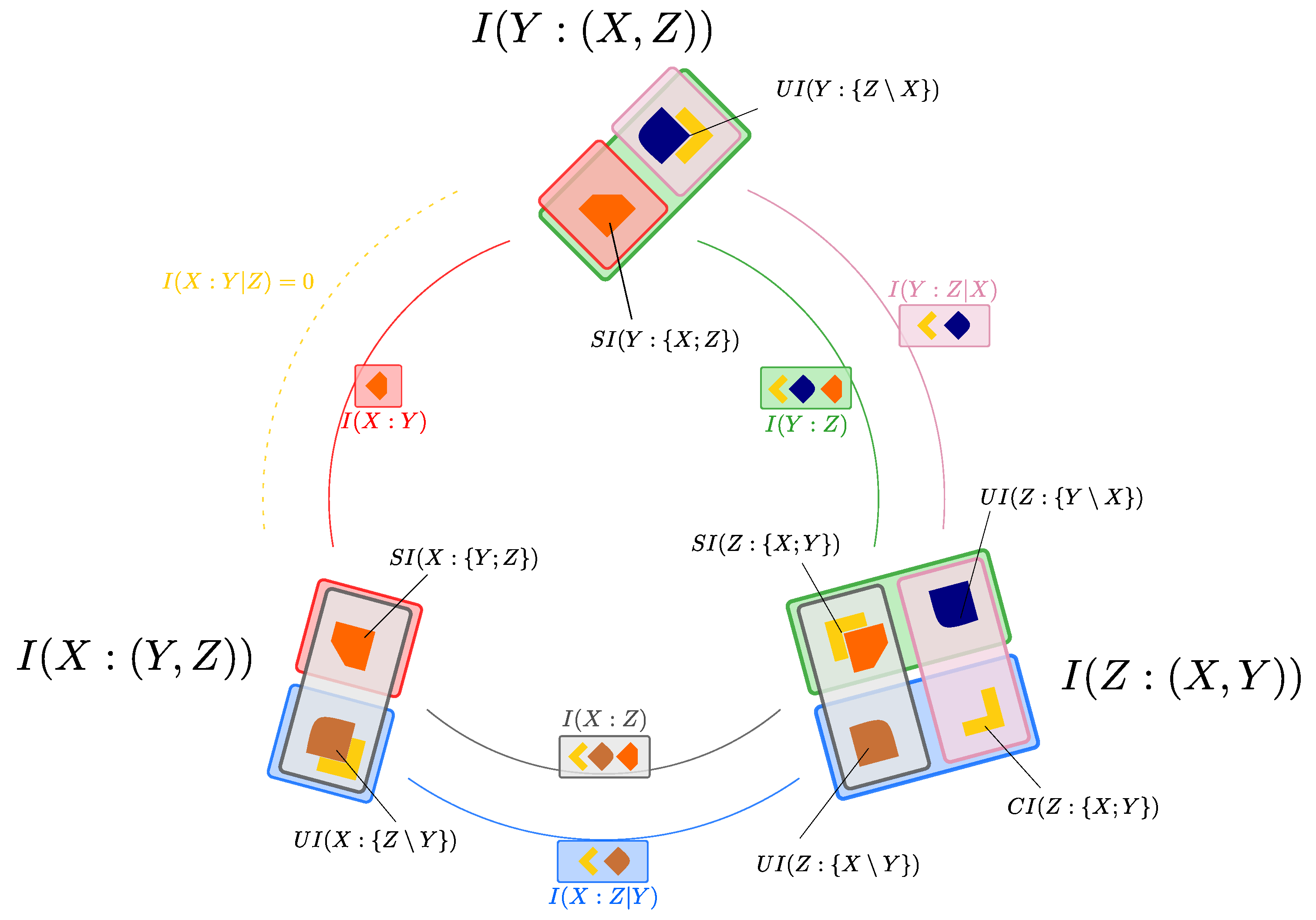
Williams and Beer proposed an influential axiomatic construction that, in the general multivariate case, allows decomposing the mutual information that a set of sources has about a target into a series of redundant, synergistic, and unique contributions to the information. In the bivariate source case, i.e., for a system with two sources, this decomposition can be used to break down the mutual information that two stochastic variables (the sources) carry about a third variable X (the target) into the sum of four nonnegative atoms [10]:
- the Shared Information , which is the information about the target that is shared between the two sources (the redundancy);
- the Unique Informations and , which are the separate pieces of information about the target that can be extracted from one of the sources, but not from the other;
- the Complementary Information , which is the information about the target that is only available when both of the sources are jointly observed (the synergy).
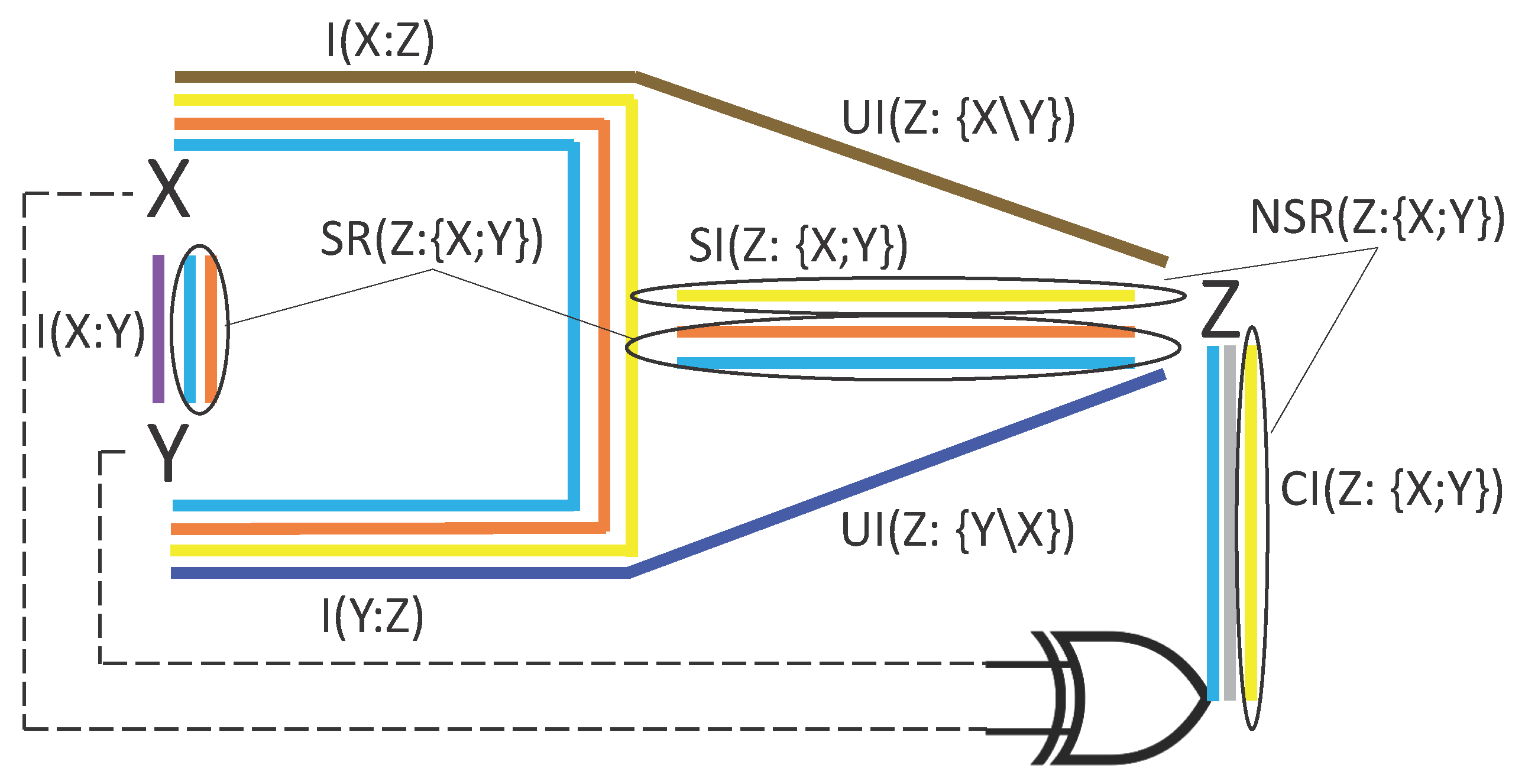
This construction is commonly known as the Partial Information Decomposition (PID). Sums of subsets of the four PID atoms provide the classical mutual information quantities between each of the sources and the target, and , and the conditional mutual information quantities whereby one of the sources is the conditioned variable, and . Such relationships are displayed with a color code in Figure 1.
The PID decomposition of Ref. [10] is based upon a number of axioms that formalize some properties that a measure of redundancy should have. These axioms are expressed in simple terms as follows: the redundancy should be symmetric under any permutation of the sources (weak symmetry); for a single source, the redundancy should equal the mutual information between the source and the target (self-redundancy); the redundancy should not increase if a new source is added (monotonicity) [3,24]. However, these axioms do not determine univocally the value of the four PID atoms. For example, some definitions of redundancy imply that all PID atoms are nonnegative (global positivity) [10,11,22], while some authors have questioned that this property should be always satisfied [25]. Further, the specific redundancy measure proposed in Ref. [10] has been questioned as it can lead to unintuitive results [22], and thus many attempts have been devoted to finding alternative measures [22,25,26,27,28,29,30] compatibly with an extended number of axioms, such as the identity axiom proposed in [22]. Other work has studied in more detail the lattice structure that underpins the PID, indicating the duality between information gain and information loss lattices [12]. Even though there is no consensus on how to build partial information decompositions in systems with more than two sources, for trivariate systems the measures of redundancy, synergy and unique information defined in Ref. [11] have found wide acceptance (as a terminology note, it is common in the literature to refer to PID decompositions for systems containing a target and two sources as bivariate decompositions. That is, while the system is trivariate, the decomposition is sometimes referred to as bivariate based on the number of sources). In this paper, we will in fact make use of these measures when a concrete implementation of the PID will be required.
Even in the trivariate case with two sources and one target, however, there are open problems regarding the understanding of the PID atoms in relation to the interdependencies within the system. First, Harder et al. [22] pointed out that the redundant information shared between the sources about the target can intuitively arise from the following two qualitatively different modes of three-wise interdependence:
- the mechanistic redundancy, which can be larger than zero even if there is no mutual information between the sources.
As pointed out by Harder and colleagues [22], a more precise conceptual and formal separation of these two kinds of redundancy still needs to be achieved, and presents fundamental challenges. The very notion that two statistically independent sources can nonetheless share information about a target was not captured by some earlier definitions of redundancy [31]. However, Ref. [3] provided a game-theoretic argument to show intuitively how independent variables may share information about another variable. Nonetheless, several studies [23,32] described the property that the PID measures of redundancy can be positive even when there are no correlations between the sources as undesired. On a different note, other authors [20] pointed out that the two different notions of redundancy can define qualitatively different modes of information processing in (neural) input-output networks.
Other issues were recently pointed out by James and Crutchfield [21], who indicated that the very definition of the PID lattice prevents its use as a general tool for assessing the full structure of trivariate (let alone multi-variate) statistical dependencies. In particular, Ref. [21] considered dyadic and triadic systems, which underlie quite interesting and common modes of multivariate interdependencies. They showed that, even though the PID atoms are among the very few measures that can distinguish between the two kinds of systems, a PID lattice with two source variables and one target variable cannot allot the full joint entropy of either system. The decomposition of the joint entropy in terms of information components that reflect qualitatively different interactions within the system has also been subject of recent research, that however relies on constructions differing substantially from the PID lattice [29,33].
In summary, the PID framework, in its current form, does not yet provide a satisfactorily fine and complete description of the distribution of information in trivariate systems. The PID atoms do assess trivariate dependencies better than Shannon’s measures, but they cannot quantify interesting finer interdependencies within the system, such as the source redundancy that the sources share about the target and the mechanistic redundancy that even two independent sources can share about the target. In addition, they are limited to describing the dependencies between the chosen sources and target, thus enforcing a certain perspective on the system that does not naturally suit all systems.
3. More PID Diagrams Unveil Finer Structure in the PID Framework
To address the open problems described above, we begin by pointing out the feature of the PID lattice that underlies all the issues in the characterization of trivariate systems outlined in Section 2. As we illustrate in Figure 1a, while a single PID diagram involves the mutual information quantities that one or both of the sources (in the figure, Y and Z) carry about the target X, it does not contain the mutual information between the sources and their conditional mutual information given the target . This precludes the characterization of source redundancy with a single PID diagram, as it prevents any comparison between the elements of the PID and . Moreover, it also signals that a single PID lattice with two sources and one target cannot in general account for the total entropy of the system.
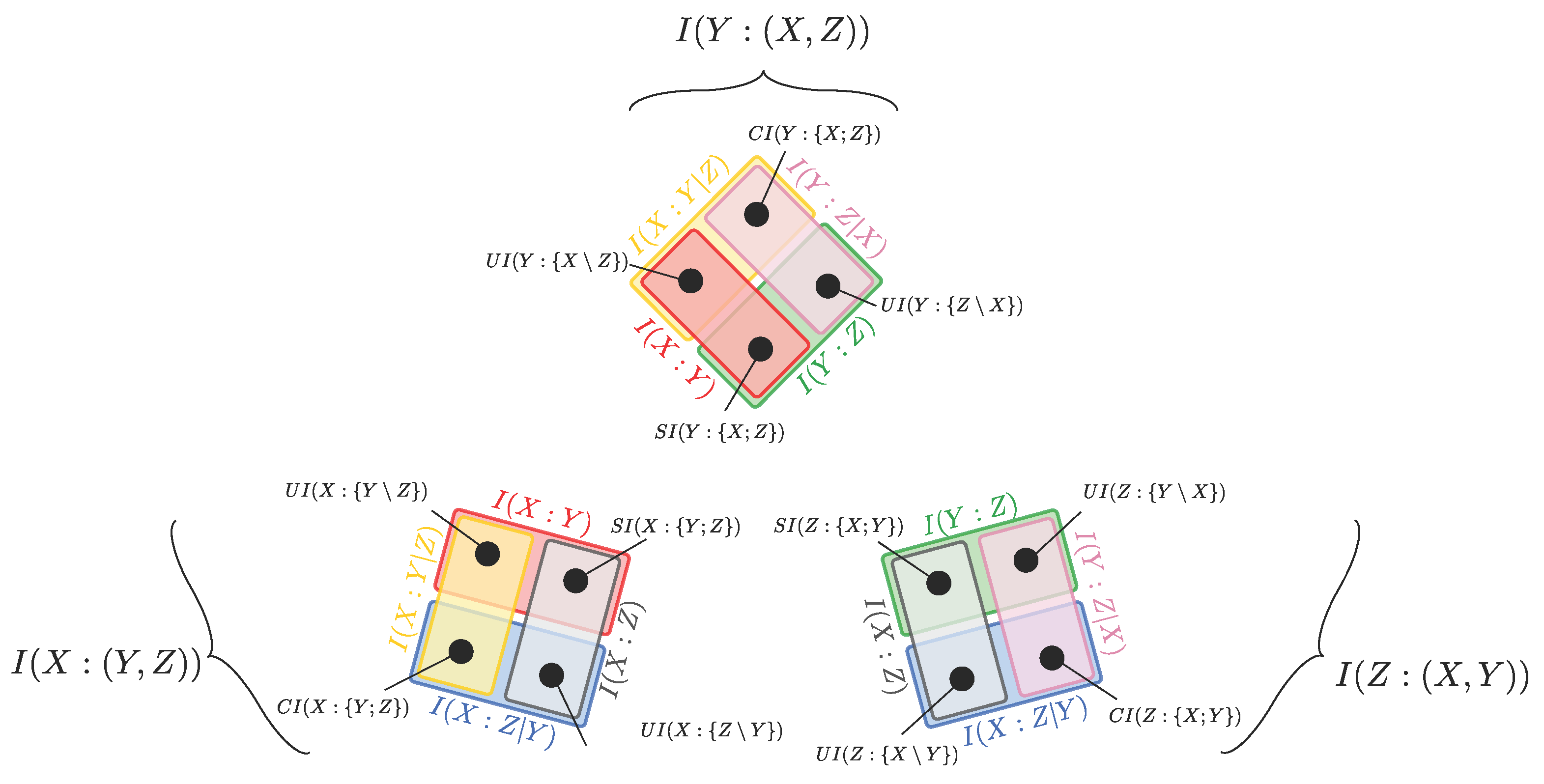
These considerations suggest that the inability of the PID framework to provide a complete information-theoretic description of trivariate systems is not a consequence of the axiomatic construction underlying the PID lattice. Instead, it follows from restricting the analysis to the limited perspective on the system that is enforced by classifying the variables into sources and target when defining a PID lattice. We thus elaborate that significant progress can be achieved, without the addition of further axioms or assumptions to the PID framework, if one just considers, alongside the PID diagram in Figure 1a, the other two PID diagrams that are induced respectively by labeling Y or Z as the target in the system. When considering the resulting three PID diagrams (Figure 2), the previously missing mutual information between the original sources of the left-most diagram is now decomposed into PID atoms of the middle and the right-most diagrams in Figure 2, and the same happens with .
In the following we take advantage of this shift in perspective to resolve the finer structure of the PID diagrams and, at the same time, to generalize its descriptive power going beyond the current limited framework, where only the information that two (source) variables carry about the third (target) variable is decomposed. More specifically, even though the PID relies on setting a partial point of view about the system, we will show that describing how the PID atoms change when we systematically rotate the choice of the PID target variable effectively overcomes the limitations intrinsic to one PID alone.
3.1. The Relationship between PID Diagrams with Different Target Selections
To identify the finer structure underlying all the PID diagrams in Figure 2, we first focus on the relationships between the PID atoms of two different diagrams, with the goal of understanding how to move from one perspective on the system to another. The key observation here is that, for each pair of variables in the system, their mutual information and their conditional mutual information given the third variable appear in two of the PID diagrams. This imposes some constraints relating the PID atoms in two different diagrams. For example, if we consider and , we find that:
where the first and second equality in each equation result from the decomposition of (left-most diagram in Figure 2) and (middle diagram in Figure 2), respectively. From Equation (1) we see that, when the roles of a target and a source are reversed (here, the roles of X and Y), the difference in redundancy is the opposite of the difference in unique information with respect to the other source (here, Z). Similarly, Equation (2) shows that the difference in synergy is the opposite of the difference in unique information with respect to the other source. Combining these two equalities, we also see that the difference in redundancy is equal to the difference in synergy. Therefore, the equalities impose relationships across some PID atoms appearing in two different diagrams.
These relationships are depicted in Figure 3. The eight PID atoms appearing in the two diagrams can be expressed in terms of only six subatoms, due to the constraints of the form of Equations (1) and (2). In particular, to select the smallest nonnegative pieces of information resulting from the constraints, we define:
The above terms are called the Reversible Shared Information of X and Y considering Z (; the orange block in Figure 3), the Reversible Complementary Information of X and Y considering Z (; the gray block in Figure 3), and the Reversible Unique Information of X and Y considering Z (; the magenta block in Figure 3). The attribute reversible highlights that, when we reverse the roles of target and source between the two variables at the endpoints of the arrow in , , or (here, X and Y), the reversible pieces of information are still included in the same type of PID atom (redundancy, synergy, or unique information with respect to the third variable). For example, the orange block in Figure 3 indicates a common amount of redundancy in both PID diagrams: as such, contributes both to redundant information that Y and Z share about X, and to redundant information that X and Z share about Y. By construction, these reversible components are symmetric in the reversed variables. Note that, when we reverse the role of two variables, the third variable (here, Z) remains a source and is thus put in the middle of our notation in Equation (3a)–(3c). We also define the Irreversible Shared Information between X and Y considering Z (the light blue block in Figure 3) as follows:
The attribute irreversible in the above definition indicates that this piece of redundancy is specific to one of the two PIDs alone. More precisely, the uni-directional arrow in indicates that this piece of information is a part of the redundancy with X as a target, but it is not a part of the redundancy with Y as a target (In this paper, directional arrows never represent any kind of causal directionality: the PID framework is only capable to quantify statistical (correlational) dependencies). Correspondingly, at least one between and is always zero. More generally, quantifies asymmetries between two different PIDs: for example, when moving from the left to the right PID in Figure 3, the light blue block indicates an equivalent amount of information that is lost for the redundancy and the synergy atoms, and is instead counted as a part of the unique information atom. In other words, assuming that the two redundancies are ranked as in Figure 3, we find that:
While the coarser Shannon information quantities that are decomposed in both diagrams in Figure 3, namely and , are symmetric under swap of , their PID decompositions (see Equations (1) and (2)) are not: Equation (5) show that quantifies the amount of this asymmetry. More precisely, the PID decompositions of and will preserve the symmetry if and only if . Note that the differences of redundancies, of synergies, and of unique information terms are always constrained by equations such as Equation (5a)–(5c). Hence, unlike for the reversible measures, we do not need to consider independent notions of irreversible synergy or irreversible unique information.
In summary, the four subatoms in Equations (3a)–(3c) and (4), together with the two remaining unique information terms (the black dots in Figure 3), allow us to characterize both PIDs in Figure 3 and to understand how the PID atoms change when moving from one PID to another. We remark that in all cases the subatoms indicate amounts of information, while the same subatom can be interpreted in different ways depending on the specific PID atom to which it contributes. In other words, the fact that two atoms contain the same subatom does not indicate that there is some qualitatively equivalent information contained in both atoms. For example, both the redundancy and the synergy in Figure 3 contain the same subatom , even though the PID construction ensures that the redundancy and the synergy contain qualitatively different pieces of information.
3.2. Unveiling the Finer Structure of the PID Framework
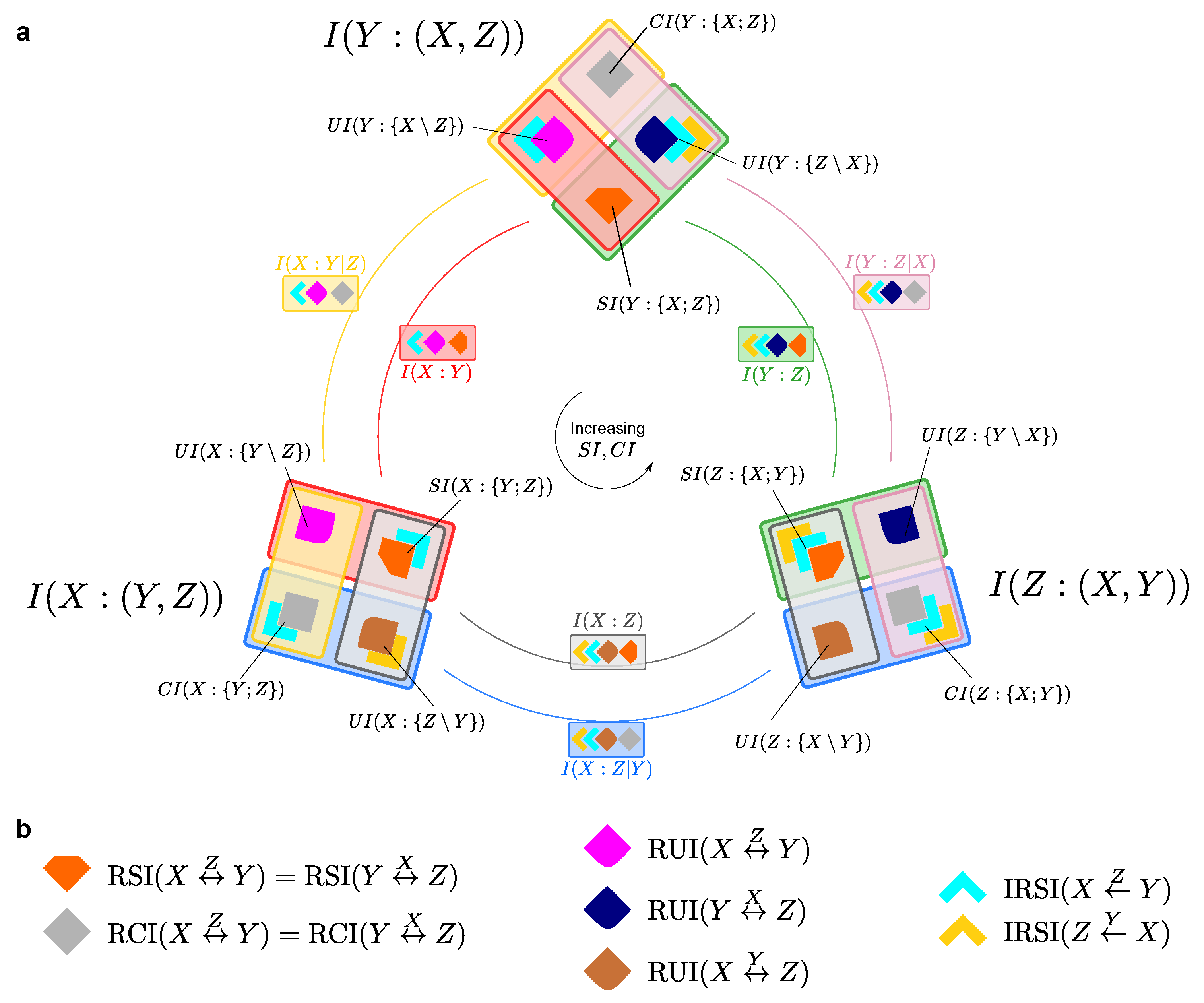
So far we have examined the relationships among the PID atoms corresponding to two different perspectives we hold about the system, whereby we reverse the roles of target and source between two variables in the system. We have seen that the PID atoms of different diagrams are not independent, as they are constrained by equations of the type of Equations (1) and (2). More specifically, the eight PID atoms of two diagrams can be expressed in terms of only six independent quantities, including reversible and irreversible pieces of information. The next question is how many subatoms we need to describe all the three possible PIDs (see Figure 2). Since there are six constraints, three equations of the type of Equation (1) and three equations of the type of Equation (2), one may be tempted to think that the twelve PID atoms of all three PID diagrams can be expressed in terms of only six independent quantities. However, the six constraints are not independent: this is most easily seen from the symmetry of the co-information measure [34], which is defined as the mutual information of two variables minus their conditional information given the third (e.g., Equation (1) minus Equation (2)). The co-information is invariant to any permutation of the variables, and this property highlights that only five of the six constraints are linearly independent. Accordingly, we will now detail how seven subatoms are sufficient to describe the relationships among the atoms of all three PIDs: we call these subatoms the minimal subatoms’ set of the PID diagrams.
In Figure 4 we see how the minimal subatoms’ set builds the PID diagrams. We assume, without loss of generality, that . Then, we consider the three possible instances of Equation (5) for the three possible choices of the target variable, and we find that the same ordering also holds for the synergy atoms: . This property is related to the invariance of the co-information: indeed, Ref. [10] indicated that the co-information can be expressed as the difference between the redundancy and the synergy within each PID diagram, i.e.,
for any assignment of X, Y, Z, to i, j, k.
These ordering relations are enough to understand the nature of the minimal subatoms’ set: we start with the construction of the three redundancies, which can all be expressed in terms of the smallest and two subsequent increments. In Figure 4, these correspond respectively to (orange block), (light blue block) and (yellow block). In parallel, we can construct the three synergies with the smallest and the same increments used for the redundancies. In Figure 4, these correspond respectively to (gray block) and the same two used before. To construct the unique information atoms, it is sufficient to further consider the three independent defined by taking all possible permutations of X, Y and Z in Equation (3c). In Figure 4, these correspond to (magenta block), (brown block), and (blue block). We thus see that, in total, seven minimal subatoms are enough to describe the underlying structure of the three PID diagrams of any system. Among these seven building blocks, five are reversible pieces of information, i.e., they contribute to the same kind of PID atom across different PID diagrams; the other two are irreversible pieces of information, that contribute to different kinds of PID atom across different diagrams. The complete minimal set can only be determined when all three PIDs are jointly considered and compared. That is, after the PID atoms have been evaluated, the subatoms provide a complete description of the structure of the PID atoms. As shown in Figure 3, pairwise PIDs’ comparisons can at most distinguish two subatoms in any redundancy (or synergy), while the three-wise PIDs’ comparison discussed above allowed us to discern three subatoms in (and ; see also Figure 4). The full details of the mathematical construction of the decomposition presented in Figure 4 is described in Appendix A.
Importantly, while the definition of a single PID lattice relies on the specific perspective adopted on the system, which labels two variables as the sources and one variable as the target, the decomposition in Figure 4 is invariant with respect to the classification of the variables. As described above, it only relies on computing all three PID diagrams and then using the ordering relations of the atoms, without any need to classify the variables a priori. As illustrated in Figure 4, the decomposition of the mutual information and conditional mutual information quantities in terms of the subatoms is also independent of the PID adopted. Our invariant minimal set in Figure 4 thus extends the descriptive power of the PID framework beyond the limitations that were intrinsic to considering an individual PID diagram. In the next sections, we will show how the invariant minimal set can be used to identify the part of the redundant information about a target that specifically arises from the mutual information between the sources (the source redundancy), and to decompose the total entropy of any trivariate system.
Remarkably, the decomposition in Figure 4 does not rely on any extension of Williams and Beer’s axioms. We unveiled finer structure underlying the PID lattices just by considering more PID lattices at a time and comparing PID atoms across different lattices. The operation of taking the minimum between different PID atoms that defines the reversible pieces of information in Equation (3a)–(3c) might be reminiscent of the minimum operation that underlies the definition of the redundancy measures in Ref. [10] and in Ref. [22]. However, the minimum in Equation (3a)–(3c) operates on pieces of information about different variables and identifies a common amount of information between different PID atoms, while the minimum in and always operates on pieces of information about the same variable (the target) and aims at identifying information about the target that is qualitatively common between the two sources. We further remark that the decomposition in Figure 4 does not rely in any respect on the specific definition of the PID measures that is used to calculate the PID atoms: it only relies on the axiomatic PID construction presented in Ref. [10].
4. Quantifying Source Redundancy
The structure of the three PID diagrams that was unveiled with the construction in Figure 4 enables a finer characterization of the modes of information distribution among three variables than what has previously been possible. In particular, we will now address the open problem of quantifying the source redundancy, i.e., the part of the redundancy that ’must already manifest itself in the mutual information between the sources’ [22]. Consider for example the redundancy in Figure 4: it is composed by (orange block) and (light blue block). We can check which of these subatoms are shared with the mutual information of the sources . To do this, we have to move from the middle PID diagram in Figure 4, that contains , to any of the other two diagrams, that both contain . Consistently, in these other two diagrams is composed by the same four subatoms (the orange, the light blue, the yellow and the blue block), and the only difference across diagrams is that these subatoms are differently distributed between unique information and redundancy PID atoms. In particular, we can see that both the orange and the light blue block which make up are contained in . Thus, whenever any of them is nonzero, we know at the same time that Y and Z share some information about X (i.e., ) and that there are correlations between Y and Z (i.e., ). Accordingly, in the scenario of Figure 4 the entire redundancy is explained by the mutual information of the sources: all the redundant information that Y and Z share about X arises from the correlations between Y and Z.
If we then consider the redundancy , that coincides with the orange block, we also find that it is totally explained in terms of the mutual information between the corresponding sources , which indeed contains an orange block. However, if we consider the third redundancy , that is composed by an orange, a light blue and a yellow block, we find that only the orange and the light blue block contribute to , while the yellow does not. The source redundancy that X and Y share about Z should thus equal the sum of the orange and the light blue block, that are common to both the redundancy and the mutual information . To quantify in full generality the amounts of information that contribute both to the redundancy and to the mutual information of its sources, we define the source redundancy that two sources and share about a target T as:
One can easily verify that Equation (7) identifies the blocks that contribute to both and in Figure 4, for any choice of sources and target (for instance, , and ). This definition can be justified as follows: each measure in Equation (7) compares with one of the other two redundancies that are contained in the mutual information between the sources (namely, and ). Some of the subatoms included in are contained in one of these two redundancies, but not in the other, as they move to the unique information mode when we change PID. Therefore, by taking the maximum in Equation (7) we ensure that precisely captures all the common subatoms of and , without double-counting. In a complementary way, we can define the non-source redundancy that two sources share about a target:
In particular, if we consider the redundancy in Figure 4, corresponds to the yellow block. As desired, whenever this block is larger than zero, X and Y can share information about Z (i.e., ) even if there is no mutual information between the sources X and Y (i.e., ).
4.1. The Difference between Source and Non-Source Redundancy
Equations (7) and (8) show how we can split the redundant information that two sources share about a target into two nonnegative information components: when the source-redundancy is larger than zero there are also correlations between the sources, while the non-source redundancy can be larger than zero even when the sources are independent. is thus seen to quantify the pairwise correlations between the sources that also produce redundant information about the target: this discussion is pictorially summarized in Figure 5. In particular, the source redundancy is clearly upper-bound by the mutual information between the sources, i.e.,
On the other hand, does not arise from the pairwise correlations between the sources: let us calculate in a paradigmatic example that was proposed in Ref. [22] to remark the subtle possibility that two statistically independent variables can share information about a third variable. Suppose that Y and Z are uniform binary random variables, with , and X is deterministically fixed by the relationship , where ∧ represents the AND logical operation. Here, bits (according to different measures of redundancy [11,22]) even if . Indeed, from our definitions in Equations (7) and (8) we find that, since , here even though . We will comment more extensively on this instructive example in Section 6.
Interestingly, the non-source redundancy is a part of the redundancy that is related to the synergy of the same PID diagram. Indeed, two of the three possible defined in Equation (8) are always zero, and the third can be larger than zero if and only if the yellow block in Figure 4 is larger than zero. From Figure 4 and Figure 5 we can thus see that, whenever we find positive non-source redundancy in a PID diagram, the same amount of information (the yellow block) is also present in the synergy of that diagram. Thus, while there is source redundancy if and only if there is mutual information between the sources, the existence of non-source redundancy is a sufficient (though not necessary) condition for the existence of synergy. We can thus interpret as redundant information about the target that implies that the sources carry synergistic information about the target: we give a graphical characterization of in Figure 5. In particular, the non-source redundancy is clearly upper-bound by the corresponding synergy:
In the specific examples considered in Harder et al. [22], where the underlying causal structure of the system is such that the sources always generate the target, the non-source redundancy can indeed be associated with the notion of ’mechanistic redundancy’ that was introduced in that work: the causal mechanisms connecting the target with the sources induce a non-zero that contributes to the redundancy independently of the correlations between the sources. In general, since the causal structure of the analyzed system is unknown, it is impossible to quantify ’mechanistic redundancy’ with statistical measures, while it is always possible to quantify and interpret the non-source redundancy as described in Section 4.
In Section 6 we will examine concrete examples to show how our definitions of source and non-source redundancy refine the information-theoretic description of trivariate systems, as they quantify qualitatively different ways that two variables can share information about a third.
We conclude this Section with more general comments about our quantification of source redundancy. We note that the arguments used to define the source redundancy in Section 4 can be equally used to study common or exclusive information components of other PID terms. For example, we can identify the magenta subatom as the component of the mutual information between the sources X and Y that cannot be related to their redundant information about Z. Similarly, we could consider which part of a synergy is related to the conditional mutual information between the sources.
5. Decomposing the Joint Entropy of a Trivariate System
Understanding how information is distributed in trivariate systems should also provide a descriptive allotment of all parts of the joint entropy [21,33]. For comparison, Shannon’s mutual information enables a semantic decomposition of the bivariate entropy in terms of univariate conditional entropies and , that quantifies shared fluctuations (or covariations) between the two variables [33]:
However, in spite of recent proposals to decompose the joint entropy [29,33], a univocal descriptive decomposition of the trivariate entropy in terms of nonnegative information-theoretic quantities is still missing to date. Since the PID axioms in Ref. [10] decompose mutual information quantities, one might hope that the PID atoms could also provide a descriptive entropy decomposition. Yet, at the beginning of Section 3, we pointed out that a single PID lattice does not include the mutual information between the sources and their conditional mutual information given the target: this suggests that a single PID lattice with two sources and one target cannot in general contain the full . More concretely, Ref. [21] has recently suggested precise examples of trivariate dependencies, i.e., dyadic and triadic dependencies, where a single PID lattice with two sources and one target cannot account for, and thus describe the parts of, the full .
We will now show how the novel finer PID structure unveiled in Section 3 can be used to decompose the full entropy of any trivariate system in terms of nonnegative information-theoretic quantities. Then, to show the descriptive power of this decomposition, we will analyze the dyadic and triadic dependencies that were considered in Ref. [21], and that are described in Figure 6. Both kinds of dependencies underlie common modes of information sharing among three and more variables, but in both cases the atoms of a single PID diagram only sum up to two of the three bits of the full entropy [21]. We will illustrate how the missing allotment of the third bit of entropy in those systems is not due to intrinsic limitations of the PID axioms, but just to the limitations of considering a single PID diagram at a time—the common practice in the literature so far.
5.1. The Finer Structure of the Entropy
The minimal subatoms’ set that we illustrated in Figure 4 allowed us to decompose all three PID lattices of a generic system. However, to fully describe the distribution of information in trivariate systems, we also wish to find a generalization of Equation (11) to the trivariate case, i.e., to decompose the full trivariate entropy in terms of univariate conditional entropies and PID quantities. With this goal in mind, we first subtract from the terms which describe statistical fluctuations of only one variable (conditioned on the other two). The sum of these terms was indicated as in Ref. [33], and there quantified as
This subtraction is useful because is a part of the total entropy which does not overlap with any of the 12 PID atoms in Figure 2. The remaining entropy was defined as the dual total correlation in Ref. [35] and recently considered in Ref. [33]:
quantifies joint statistical fluctuations of more than one variable in the system. A simple calculation yields
which is manifestly invariant under permutations of X, Y and Z, and shows that can be written as a sum of some of the 12 PID atoms. For example, expressing the co-information as the difference , we can arbitrarily use the four atoms from the left-most diagram in Figure 2 to decompose the sum and then add from the middle diagram to decompose . If we then plug this expression of in Equation (13), we achieve a decomposition of the full entropy of the system in terms of and PID quantities:
which provides a nonnegative decomposition of the total entropy of any trivariate system. However, this decomposition is not unique, since the co-information can be expressed in terms of different pairs of conditional and unconditional mutual informations, according to Equation (6). This arbitrariness strongly limits the descriptive power of this kind of entropy decompositions, because the PID atoms on the RHS can only be interpreted within individual PID perspectives.
To address this issue, we construct a less arbitrary entropy decomposition by using the invariant minimal subatoms’ set that was presented in Figure 4: importantly, that set can be interpreted without specifying an individual, and thus partial, PID point of view that we hold about the system.
Thus, after we name the variables of the system such that , we express the coarser PID atoms in Equation (15) in terms of the minimal set to obtain:
Unlike Equation (15), the entropy decomposition expressed in Equation (16) and illustrated in Figure 7 fully describes the distribution of information in trivariate systems without the need of a specific perspective about the system. Importantly, this decomposition is unique: even though the co-information can be expressed in different ways in terms of conditional and unconditional mutual informations, in terms of the subatoms it is uniquely represented as the orange block minus the gray block (see Figure 7). Similarly, the conditional mutual information terms of Equation (14) are composed by the same blocks independently of the PID, as highlighted in Figure 4.
We remark that the entropy decomposition in Equation (16) does not rely in any respect on the choice of a specific redundancy measure, but it follows directly after the calculation of the minimal subatoms’ set according to any definition of the PID.
5.2. Describing for Dyadic and Triadic Systems
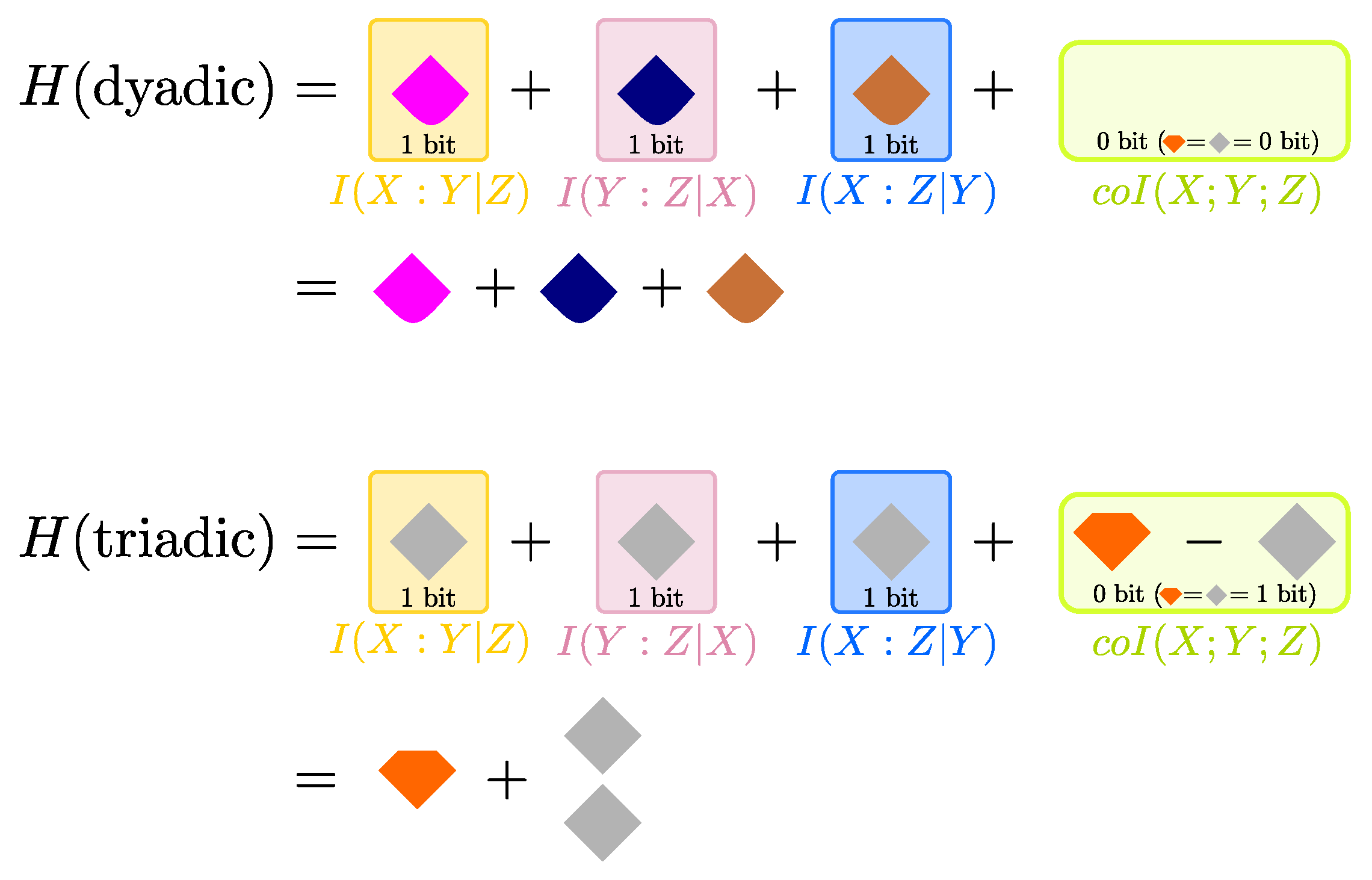
To show an application of the finer entropy decomposition in Equation (16), we now compute its terms for the dyadic and the triadic dependencies considered in Ref. [21] and defined in Figure 6. For this application, we make use of the definitions of PID that were proposed in Ref. [11]. In both cases . For the dyadic system, there are only three positive quantities in the minimal set: the three reversible unique informations bit. For the triadic system, there are only two positive quantities in the minimal set: bit, but is counted twice in the . We illustrate the resulting entropy decompositions, according to Equation (16), in Figure 8.
The decompositions in Figure 8 enable a clear interpretation of how information is finely distributed within dyadic and triadic dependencies. The three bits of the total in the dyadic system are seen to be distributed equally among unique information modes: each variable contains 1 bit of unique information with respect to the second variable about the third variable. Further, these unique information terms are all reversible, which reflects the symmetry of the system under pairwise swapping of the variables. This description provides a simple and accurate summary of the total entropy of the dyadic system, which matches the dependency structure illustrated in Figure 6a.
The three bits of the total in the triadic system consist of one bit of the smallest reversible redundancy and two bits of the smallest reversible synergy, since the latter appears twice in . Again, the reversible nature of these pieces of information reflects the symmetry of the system under pairwise swapping of the variables. Further, the bit of reversible redundancy represents the bit of information that is redundantly available to all three variables, while the two bits of reversible synergy are due to the three-wise XOR structure (see Figure 6b). Why does the XOR structure provide two bits of synergistic information? Because if then the only positive quantity in the set of subatoms in Figure 4b is the smallest , which however appears twice in the entropy . Importantly, these two bits of synergy do not come from the same PID diagram: our entropy decomposition in Equation (16) could account for both bits only because it fundamentally relies on cross-comparisons between different PID diagrams, as illustrated in Figure 4.
6. Applications of the Finer Structure of the PID Framework
The aim of this Section is to show the additional insights that the finer structure of the PID framework, unveiled in Section 3.2 and Figure 4, can bring to the analysis of trivariate systems. We examine paradigmatic examples of trivariate systems and calculate the novel PID quantities of source and non-source redundancy that we described in Section 4. Most of these examples have been considered in the literature [11,22,23,26,33] to validate the definitions, or to suggest interpretations, of the PID atoms. We also discuss how matches the notion of source redundancy introduced in Ref. [22] and discussed in Ref. [20]. Finally, we suggest and motivate a practical interpretation of the reversible redundancy subatom .
The decomposition of the PID lattices in terms of the minimal subatoms’ set that we illustrated in Figure 4 is to be calculated after the traditional PID atoms have been computed. Since it relies only on the lattice relations, the subatomic decomposition can be attained for any of the several measures that have been proposed to underpin the PID [10,11,22,26]. In some cases the value of the atoms can be derived from axiomatic arguments, hence it does not depend on the specific measure selected; in other cases it has to be actually calculated choosing a particular measure, and it can differ for different measures. In the latter cases, our computations rely on the definitions of PID that were proposed in Ref. [11], which are widely accepted in the literature for trivariate systems. Whenever we needed a numerical computation of the PID atoms, we performed it with a Matlab package we specifically developed for this task, which is freely available for download and reuse through Zenodo and Github (https://doi.org/10.5281/zenodo.850362).
6.1. Computing Source and Non-Source Redundancy
6.1.1. Copying—The Redundancy Arises Entirely from Source Correlations
Consider a system where Y and Z are random binary variables that are correlated according to a control parameter [22]. For example, consider a uniform binary random variable W that ’drives’ both Y and Z with the same strength . More precisely, and [22]. This system is completed by taking , i.e., a two-bit random variable that reproduces faithfully the joint outcomes of the generating variables .
We consider the inputs Y and Z as the PID sources and the output X as the PID target, thus selecting the left-most PID diagram in Figure 2. Figure 9a shows our calculations of the full redundancy , the source redundancy and the non-source redundancy , based on the definitions in Ref. [11]. The parameter is varied between , corresponding to , and , corresponding to . Since for any , we interpret that all the redundancy arises from the correlations between Y and Z (which are tuned with ). This property was presented as the identity axiom in Ref. [22], where the authors argued that in the ’copying’ example the entire redundancy should be already apparent in the sources. Indeed, the PID definitions of Ref. [11] that we use here abide by the identity axiom, and these results would not change if we used other PID definitions that still satisfy the identity axiom.
6.1.2. AND Gate: The Redundancy is not Entirely Related to Source Correlations
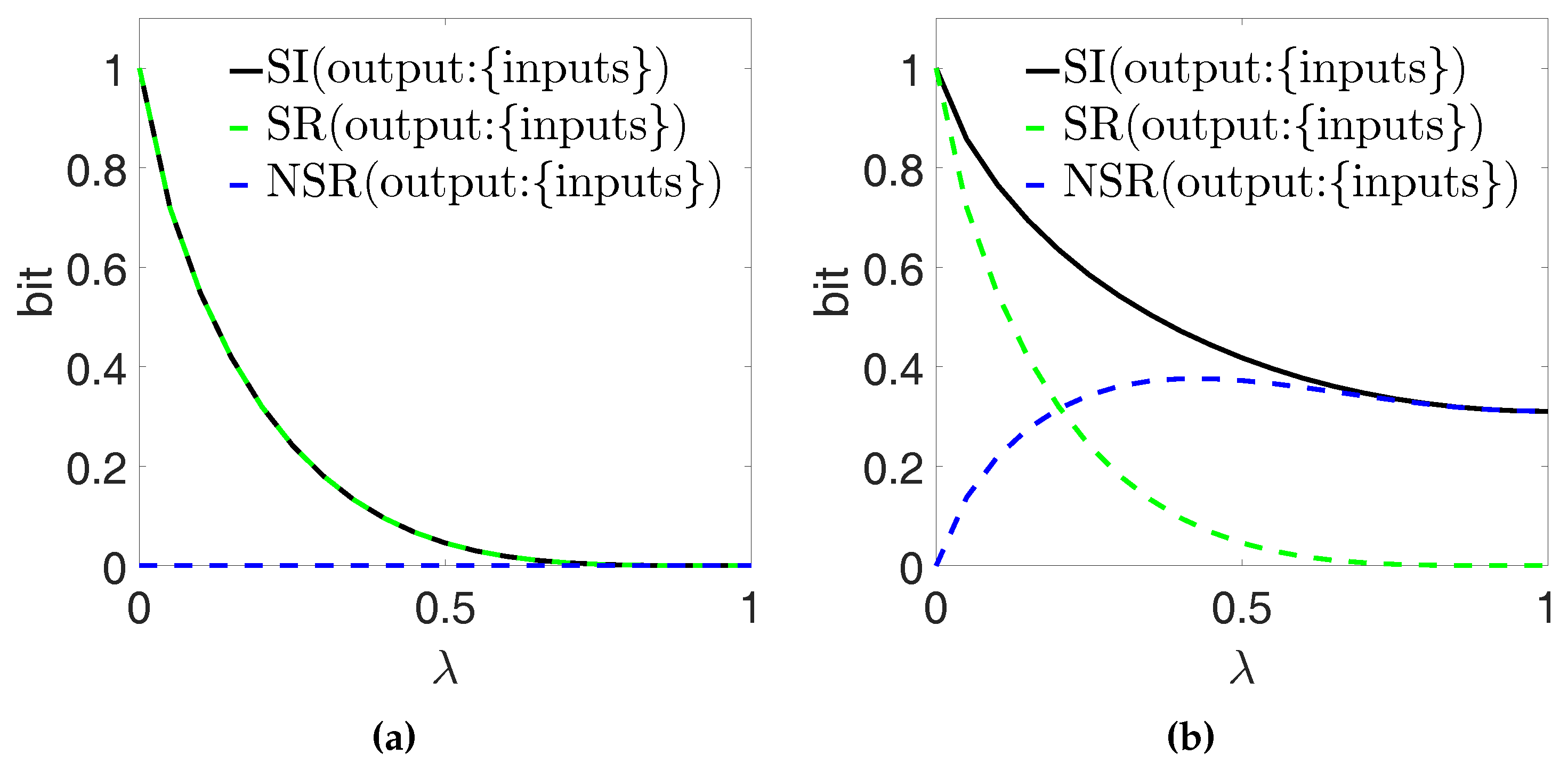
Consider a system where the correlations between two binary random variables, the inputs Y and Z, are described by the control parameter as in Section 6.1.1, but the output X is determined by the function as [22]. As the causal structure of the system would suggest, we consider the inputs Y and Z as the PID sources and the output X as the PID target, thus selecting the left-most PID diagram in Figure 2. Figure 9b shows our calculations of the full redundancy , the source redundancy and the non-source redundancy , based on the definitions in Ref. [11].
and now show a non-trivial behavior as a function of the correlation parameter . If and thus , the full redundancy is made up entirely of source redundancy—trivially, both and equal the mutual information bit. When increases, the full redundancy decreases monotonically to its minimum value of ≈0.311 bits for (when ). Importantly, decreases monotonically as a function of to its minimum value of zero bits when : this behavior is indeed expected from a measure that quantifies correlations between the sources that also produce redundant information about the target (see Section 4). On the other hand, for , and it increases as a function of . When , i.e., when , corresponds to the full redundancy. This is compatible with our description of non-source redundancy (see Section 4) as redundancy that is not related to the source correlations; indeed, implies that the sources also carry synergistic information about the target (here, due to the relationship ). thus also quantifies the notion of mechanistic redundancy that was introduced in Ref. [22] with reference to this scenario.
6.1.3. Dice Sum: Tuning Irreversible Redundancy
Consider a system where Y and Z are two uniform random variables, each representing the outcome of a die throw [22]. A parameter controls the correlations between the two dice: . Thus, for the dice throws always match, for the outcomes are completely independent. Further, the output X combines each pair of input outcomes as z, where . This example was suggested in Ref. [22] specifically to point out the conceptual difficulties in quantifying the interplay between the redundancy and the source correlations, that we addressed with the identification of and (see Section 4).
Harder et al. calculated redundancy by using their own proposed measure , which also abides by the PID axioms in Ref. [10] but is different than the measure introduced in Ref. [11]. However, Ref. [11] also calculated for this example: they showed that the differences between and in this example are only quantitative (and there is no difference at all for some values of ), while the qualitative behaviour of both measures as a function of is very similar.
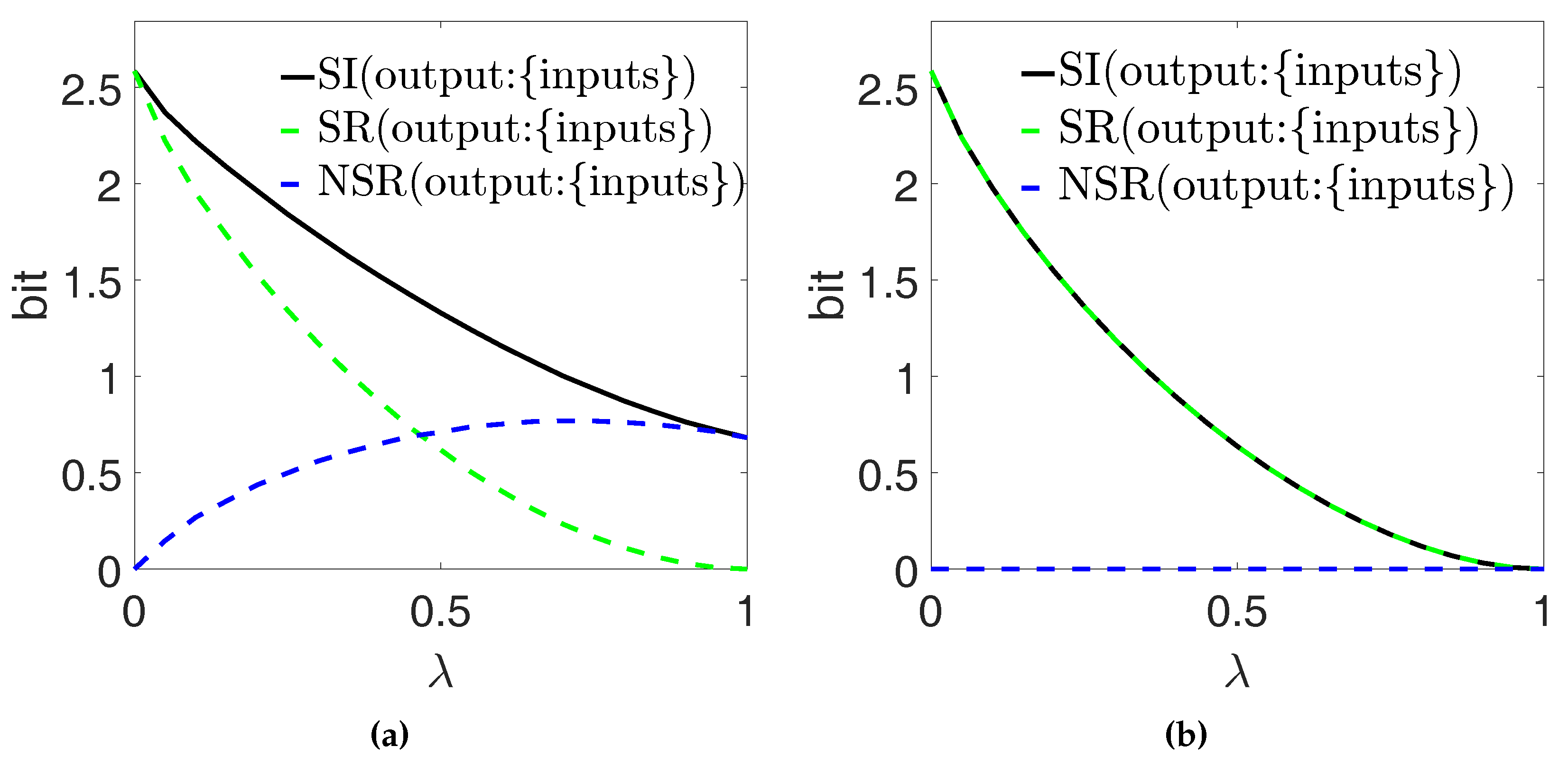
Figure 10 shows our calculations of the full redundancy , the source redundancy and the non-source redundancy , based on the definitions in Ref. [11]. We display the two ‘extreme’ cases , for illustration.
With , X is isomorphic to the joint variable : for any , this implies on one hand , and on the other and thus (see Equation (1)). According to Equation (7), we thus find that the source redundancy saturates, for any , the general inequality in Equation (9): all correlations between the inputs also produce redundant information about X (see Section 4). Further, according to Equation (8), we find for any (see Figure 10b): we thus interpret that all the redundancy arises from correlations between the inputs. Instead, if we fix and decrease , the two inputs are more and more symmetrically combined in the output X: with , the pieces of information respectively carried by each input about the output overlap maximally. Correspondingly, the full redundancy increases [22]. However, keeping fixed does not change the inputs’ correlations. Thus, we expect that the relative contribution of the inputs’ correlations to the full redundancy should decrease proportionally. Indeed, in Figure 10a we find for , which signals that a part of is not related to the inputs’ correlations.
We finally note that also in this paradigmatic example the splitting of the redundancy into and addresses the challenge of separating the two kinds of redundancy outlined in Ref. [22].
6.1.4. Trivariate Jointly Gaussian Systems
Barrett considered in detail the application of the PID to trivariate jointly Gaussian systems in which the target is univariate [23]: he showed that several specific proposals for calculating the PID atoms all converge, in this case, to the same following measure of redundancy:
We note that Equation (17) highlights the interesting property that, in trivariate Gaussian systems with a univariate target, the redundancy is as large as it can be, since it saturates the general inequalities .
Direct application of our definitions in Equations (7) and (8) to such systems yields:
Thus, we find that in these systems the source redundancy is also as large as it can be, since it also saturates the general inequalities (which follow immediately from its definition in Equation (7)). Further, combining Equation (17) with Equation (18) gives:
This identification of source redundancy, which quantifies pairwise correlations between the sources that also produce redundant information about the target (see Section 4), provides more insight about the distribution of information in Gaussian systems. Indeed, the property that source redundancy is maximal indicates that the correlations between any pair of source variables (for example, as considered above) produces as much redundant information as possible about the corresponding target (X as considered above). Accordingly, when , the redundancy also includes some non-source redundancy that implies the existence of synergy, i.e., .
6.2. Quantifies Information between two Variables That also Passes Monotonically Through the Third
In this section, we discuss a practical interpretation of the reversible redundancy subatom defined in Equation (3a). We note that appears both in and in , i.e., it quantifies a common amount of information that Z shares with each of the two other variables about the third variable. We shorten this description into the statement that quantifies ’information between X and Y that also passes through Z’. Reversible redundancy is further characterized by the following Proposition:
Proposition 1.
≥ .
Proof.
Both and [10]. Thus, . ☐
Indeed, the fact that always increases whenever we expand the middle variable corresponds to the increased capacity of the entropy of the middle variable to host information between the endpoint variables. We discuss this interpretation of by examining several examples, where we can motivate a priori our expectations about this novel mode of information sharing.
6.2.1. Markov Chains
Consider the most generic Markov chain , defined by the property that , i.e., that X and Y are conditionally independent given Z. The Markov structure allows us to formulate a clear a priori expectation about the amount of information between the endpoints of the chain, X and Y, that also ’passes through the middle variable Z’: this information should clearly equal , because whatever information is established between X and Y must pass through Z.
Indeed, the Markov property implies, as we see immediately from Figure 2, that . By virtue of Equations (3a) and (4), in accordance with our expectation, we find
which holds true independently of the marginal distributions of X, Y and Z. Notably, the symmetry of under swap of the endpoint variables is also compatible with the property that is a Markov chain if and only if is a Markov chain. In words, whatever information flows from X through Z to Y equals the information flowing from Y through Z to X.
More generally, the Markov property implies that : thus, only four of the seven subatoms of the minimal set in Figure 4 can be larger than zero. Following the procedure illustrated in Section 3.2, we decompose the three PIDs of the system in terms of the minimal subatoms’ set as shown in Figure 11. In particular, we see that also , thus matching our expectation that in the Markov chain the information between X and Z that also passes through Y still equals . We finally note that none of the results regarding Markov chains depends on specific definitions of the PID atoms: they were derived only on the basis of the PID axioms in Ref. [10].
6.2.2. Two Parallel Communication Channels
Consider five binary uniform random variables with three parameters controlling the correlations , (in the same way controls the correlations in Section 6.1.1). We consider the trivariate system () with and (see Figure 12). Given that , we intuitively expect that the information between X and Y that also passes through Z, in this case, should equal , which in general will be smaller than . Indeed, if we use the PID definitions of Ref. [11], implies that [11] and, similarly, . However, from the previous subsection we find that and . Thus, we find that , in agreement with our expectations.
6.2.3. Other Examples
To further describe the interpretation of as information between X and Y that also passes through Z, we here reconsider the examples, among those discussed before Section 6.2, where we can formulate intuitive expectations about this information sharing mode. In the dyadic system described in Figure 6a, our expectation is that there should be no information between two variables that also passes through the other: indeed, in this case. Instead, in the triadic system described in Figure 6b, we expect that the information between two variables that also passes through the other should equal the information that is shared among all three variables, which amounts to 1 bit. Indeed, we find bit. In the ’copying’ example in Section 6.1.1 , thus we expect that corresponds to information between that also passes through X, but also to information between X and Z that also passes through Y. Indeed, . We remark that all the values of in these examples depend on the specific definitions of the PID atoms in Ref. [11].
7. Discussion
The Partial Information Decomposition (PID) pioneered by Williams and Beer has provided an elegant construction to quantify redundant, synergistic, and unique information contributions to the mutual information that a set of sources carries about a target variable [10]. More generally, it has generated considerable interest as it addresses the difficult yet practically important problem of extending information theory beyond the classic bivariate measures of Shannon to fully characterize multivariate dependencies.
However, the axiomatic PID construction, as originally formulated by Williams and Beer, fundamentally relied on the separation of the variables into a target and a set of sources. While this classification was developed to study systems in which it is natural to identify a target, in general it introduces a partial perspective that prevents a complete and general information-theoretic description of the system. More specifically, the original PID framework could not quantify some important modes of information sharing, such as source redundancy [22], and could not allot the system’s full joint entropy [21]. The work presented here addresses these issues focusing on trivariate systems, by extending the original PID framework in two respects. First, we decomposed the original PID atoms in terms of finer information subatoms with a well defined interpretation that is invariant to different variables’ classifications. Then, we constructed an extended framework to completely decompose the distribution of information within any trivariate system.
Importantly, our formulation did not require the addition of further axioms to the original PID construction. We proposed that distinct PIDs for the same system, corresponding to different target selections, should be evaluated and then compared to identify how the decomposition of information changes across different perspectives. More specifically, we identified reversible pieces of information (, , ) that contribute to the same kind of PID atom if we reverse the roles of target and source between two variables. The complementary subatomic components of the PID lattices are the irreversible pieces of information (), that contribute to different kinds of PID atom for different target selections. These subatoms thus measure asymmetries between different decompositions of Shannon quantities pertaining to two different PIDs of the same system, and such asymmetries reveal the additional detail with which the PID atoms assess trivariate dependencies as compared to the coarser and more symmetric Shannon information quantities.
The crucial result of this approach was unveiling the finer structure underlying the PID lattices: we showed that an invariant minimal set of seven information subatoms is sufficient to decompose the three PIDs of any trivariate system. In the remainder of this section, possible uses of these subatoms and their implications for the understanding of systems of three variables are discussed.
7.1. Use of the Subatoms to Map the Distribution of Information in Trivariate Systems
Our minimal subatoms’ set was first used to characterize more finely the distribution of information among three variables. We clarified the interplay between the redundant information shared between two variables A and B about a third variable C, on one side, and the correlations between A and B, on the other. We decomposed the redundancy into the sum of source-redundancy , which quantifies the part of the redundancy which arises from the pairwise correlations between the sources A and B, and non-source redundancy , which can be larger than zero even if the sources A and B are statistically independent. Interestingly, we found that quantifies the part of the redundancy which implies that A and B also carry synergistic information about C. The separation of these qualitatively different components of redundancy promises to be useful in the analysis of any complex system where several inputs are combined to produce an output [20].
Then, we used our minimal subatoms’ set to extend the descriptive power of the PID framework in the analysis of any trivariate system. We constructed a general, unique, and nonnegative decomposition of the joint entropy in terms of information-theoretic components that can be clearly interpreted without arbitrary variable classifications. This construction parallels the decomposition of the bivariate entropy in terms of Shannon’s mutual information . We demonstrated the descriptive power of this approach by decomposing the complex distribution of information in dyadic and triadic systems, which was shown not to be possible within the original PID framework [21].
We gave practical examples of how the finer structure underlying the PID atoms provides more insight into the distribution of information within important and well-studied trivariate systems. In this spirit, we put forward a practical interpretation of the reversible redundancy , and future work will address additional interpretations of the components of the minimal subatoms’ set.
7.2. Possible Extensions of the Formalism to Multivariate Systems with Many Sources
The insights that derive from our extension of the PID framework suggest that the PID lattices could also be useful to characterize the statistical dependencies in multivariate systems with more than two sources. Our approach does not rely on the adoption of specific PID measures, but only on the axiomatic construction of the PID lattice. Thus, it could be extended to the multivariate case by embedding trivariate lattices within larger systems’ lattices [12]: a further breakdown of the minimal subatoms’ set could be obtained if the current system were embedded as part of a bigger system. However, the implementation of these generalizations is left for future work. We anticipate that such generalizations would be computationally as expensive as the implementation of the multivariate PID method proposed by Williams and Beer. Indeed, after the computation of the traditional PID lattices, our approach only requires the comparison of different PID lattices, that relies on computing pairwise minima between PID atoms—a computationally trivial operation.
Further, when systems with more than two sources are considered, the definition of source redundancy might be extended as to determine which subatoms of a redundancy can be explained by dependencies among the sources (for example, by replacing the mutual information between two sources with a measure of the overall dependencies among all sources, such as the total correlation introduced in Ref. [36]). More generally, the idea of comparing different PID diagrams that partially decompose the same information can also be generalized to identify finer structure underlying higher-order PID lattices with different numbers of variables. These identifications might also help addressing specific questions about the distribution of information in complex multivariate systems.
7.3. Potential Implications for Systems Biology and Systems Neuroscience
A common problem in system biology is to characterize how the function of the whole biological system is shaped by the dependencies among its many constituent biological variables. In many cases, ranging from gene regulatory networks [37] to metabolic pathways [14] and to systems neuroscience [38,39,40], an information-theoretic decomposition of how information is distributed and processed within different parts of the system would allow a model-free characterization of these dependencies. The work discussed here can be used to shed more light on these issues by allowing to tease apart qualitatively different modes of interaction, as a first necessary step to understanding the causal structure of the observed phenomena [41].
In systems neuroscience, the decomposition introduced here may be important for studying specific and timely questions about neural information processing. This work can contribute to the study of neural population coding, that is the study of how the concerted activity of many neurons encodes information about ecologically relevant variables such as sensory stimuli [40,42]. In particular, a key characteristic of a neural population code is the degree to which pairwise or higher-order cross-neuron statistical dependencies are used by the brain to encode and process information, in a potentially redundant or synergistic way, across neurons [7,8,9] and across time [43]. Moreover, characterizing different types of redundancy may also be relevant to further study the relation between the information of neural responses and neural connectivity [44]. Our work is also of potential relevance to study another timely issue in neuroscience, that is the relevance for perception of the information about sensory variables carried by neural activity [19,45]. This is a crucial issue to resolve the diatribe about the nature of the neural code, that is the set of symbols used by neurons to encode information and produce brain function [46,47,48]. Addressing this problem requires mapping the information in the multivariate distribution of variables such as the stimuli presented to the subject, the neural activity elicited by the presentation of such stimuli, and the behavioral reports of the subject’s perception. More specifically, it requires characterizing the information between the presented stimulus and the behavioral report of the perceived stimulus that can be extracted from neural activity [19]. It is apparent that developing general decompositions of the information exchanged in multivariate systems, as we did here, is key to succeeding in rigorously addressing these fundamental systems-level questions.
Acknowledgments
We are grateful to members of Panzeri’s Laboratory for useful feedback, and to P. E. Latham, A. Brovelli and C. de Mulatier for useful discussions. This research was supported in part by the Fondation Bertarelli.
Author Contributions
All authors conceived the research; G.P., E.P. and D.C. performed the research; G.P., E.P. and D.C. wrote a first draft of the manuscript; all authors edited and approved the final manuscript; S.P. supervised the research.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Summary of the Relationships Among Distinct PID Lattices
In this Section we report the full set of equations and definitions that determine the finer structure of the three PID diagrams, as described in Section 3.2 and Figure 4 in the main text. Without loss of generality, we assume that
We start by writing down explicitly all the permutations of Equations (1), (2), and (6), relating traditional information quantities to the PID:
By using only the relations above, together with assumption (*) and the definitions of , , and (Equations (3a)–(3c) and (4)), we will now show how all PID elements, and hence all information quantities above, can be decomposed in terms of the minimal set of seven subatoms depicted as elementary blocks in Figure 4.
By applying the definitions of (Equation (3a)) and (Equation (4)), assumption (*) implies the following:
as well as
where the fourth equality follows from Equation (A3), and the fifth from Equation (A2a). Analogously, using Equations (A3) and (A2b), we get
Using the relations above, we can express the atoms of the three PIDs in terms of the and subatoms:
where we used Equation (A4),
where we used Equation (A5), and
where the first equality follows from Equation (A3), the second from Equation (A8) and the third from Equation (A6). Analogously, we can express the atoms in terms of and :
and
Note how the same terms appear in Equations (A8) and (A11), and in Equations (A9) and (A12), in agreement with the invariance of the co-information (Equation (A3)).
Finally, to study the atoms, we observe that, given (*), Equation (A1a) implies , Equation (A1b) implies , and Equation (A1c) implies . These inequalities, in turn, imply that
which we can rewrite as
Hence,
where the first equality follows from Equation (A1a), and the second from Equations (A5) and (A13). Similarly,
where we used Equations (A1b), (A6) and (A14), and
where we used Equations (A1c), (A7), (A9) and (A15).
Equations (A7)–(A18) thus describe all atoms of the three PIDs using the following seven subatoms:
This description is illustrated graphically in Figure 4, where each subatom is represented as a coloured block.
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Ay, N.; Olbrich, E.; Bertschinger, N.; Jost, J. A unifying framework for complexity measures of finite systems. In Proceedings of the European Conference Complex Systems, Oxford, UK, 25–29 September 2006; Volume 6. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared Information—New Insights and Problems in Decomposing Information in Complex Systems. In Proceedings of the Proceedings of the ECCS 2012, Brussels, Belguim, 3–7 September 2012. [Google Scholar]
- Tononi, G.; Sporns, O.; Edelman, G.M. Measures of degeneracy and redundancy in biological networks. Proc. Natl. Acad. Sci. USA 1999, 96, 3257–3262. [Google Scholar] [CrossRef] [PubMed]
- Tikhonov, M.; Little, S.C.; Gregor, T. Only accessible information is useful: Insights from gradient-mediated patterning. R. Soc. Open Sci. 2015, 2, 150486. [Google Scholar] [CrossRef] [PubMed]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef] [PubMed]
- Pola, G.; Thiele, A.; Hoffmann, K.P.; Panzeri, S. An exact method to quantify the information transmitted by different mechanisms of correlational coding. Network 2003, 14, 35–60. [Google Scholar] [CrossRef] [PubMed]
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, redundancy, and independence in population codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [PubMed]
- Latham, P.E.; Nirenberg, S. Synergy, redundancy, and independence in population codes, revisited. J. Neurosci. 2005, 25, 5195–5206. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv, 2010; arXiv:1004.2515. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Chicharro, D.; Panzeri, S. Synergy and Redundancy in Dual Decompositions of Mutual Information Gain and Information Loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Anastassiou, D. Computational analysis of the synergy among multiple interacting genes. Mol. Syst. Biol. 2007, 3, 83. [Google Scholar] [CrossRef] [PubMed]
- Lüdtke, N.; Panzeri, S.; Brown, M.; Broomhead, D.S.; Knowles, J.; Montemurro, M.A.; Kell, D.B. Information-theoretic sensitivity analysis: A general method for credit assignment in complex networks. J. R. Soc. Interface 2008, 5, 223–235. [Google Scholar] [CrossRef] [PubMed]
- Watkinson, J.; Liang, K.C.; Wang, X.; Zheng, T.; Anastassiou, D. Inference of Regulatory Gene Interactions from Expression Data Using Three-Way Mutual Information. Ann. N. Y. Acad. Sci. 2009, 1158, 302–313. [Google Scholar] [CrossRef] [PubMed]
- Faes, L.; Marinazzo, D.; Nollo, G.; Porta, A. An Information-Theoretic Framework to Map the Spatiotemporal Dynamics of the Scalp Electroencephalogram. IEEE Trans. Biomed. Eng. 2016, 63, 2488–2496. [Google Scholar] [CrossRef] [PubMed]
- Pitkow, X.; Liu, S.; Angelaki, D.E.; DeAngelis, G.C.; Pouget, A. How Can Single Sensory Neurons Predict Behavior? Neuron 2015, 87, 411–423. [Google Scholar] [CrossRef] [PubMed]
- Haefner, R.M.; Gerwinn, S.; Macke, J.H.; Bethge, M. Inferring decoding strategies from choice probabilities in the presence of correlated variability. Nat. Neurosci. 2013, 16, 235–242. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Harvey, C.D.; Piasini, E.; Latham, P.E.; Fellin, T. Cracking the Neural Code for Sensory Perception by Combining Statistics, Intervention, and Behavior. Neuron 2017, 93, 491–507. [Google Scholar] [CrossRef] [PubMed]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef] [PubMed]
- James, R.G.; Crutchfield, J.P. Multivariate Dependence Beyond Shannon Information. arXiv, 2016; arXiv:1609.01233v2. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87, 012130. [Google Scholar] [CrossRef] [PubMed]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [PubMed]
- Williams, P.L. Information Dynamics: Its Theory and Application to Embodied Cognitive Systems. Ph.D. Thesis, Indiana University, Bloomington, IN, USA, 2011. [Google Scholar]
- Ince, R.A.A. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Griffith, V.; Koch, C. Quantifying Synergistic Mutual Information. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar]
- Griffith, V.; Chong, E.K.P.; James, R.G.; Ellison, C.J.; Crutchfield, J.P. Intersection Information Based on Common Randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef]
- Banerjee, P.K.; Griffith, V. Synergy, Redundancy and Common Information. arXiv, 2015; arXiv:1509.03706. [Google Scholar]
- Ince, R.A.A. The Partial Entropy Decomposition: Decomposing multivariate entropy and mutual information via pointwise common surprisal. arXiv, 2017; arXiv:1702.01591v2. [Google Scholar]
- Rauh, J.; Banerjee, P.K.; Olbrich, E.; Jost, J.; Bertschinger, N. On extractable shared information. arXiv, 2017; arXiv:1701.07805. [Google Scholar]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. arXiv, 2013; arXiv:1205.4265v3. [Google Scholar]
- Stramaglia, S.; Angelini, L.; Wu, G.; Cortes, J.M.; Faes, L.; Marinazzo, D. Synergetic and Redundant Information Flow Detected by Unnormalized Granger Causality: Application to Resting State fMRI. IEEE Trans. Biomed. Eng. 2016, 63, 2518–2524. [Google Scholar] [CrossRef] [PubMed]
- Rosas, F.; Ntranos, V.; Ellison, C.J.; Pollin, S.; Verhelst, M. Understanding Interdependency Through Complex Information Sharing. Entropy 2016, 18, 38. [Google Scholar] [CrossRef]
- McGill, W.J. Multivariate information transmission. Psychometrika 1954, 19, 97–116. [Google Scholar] [CrossRef]
- Han, T.S. Nonnegative entropy measures of multivariate symmetric correlations. Inf. Control 1978, 36, 133–156. [Google Scholar] [CrossRef]
- Watanabe, S. Information Theoretical Analysis of Multivariate Correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar] [CrossRef]
- Margolin, A.A.; Nemenman, I.; Basso, K.; Wiggins, C.; Stolovitzky, G.; Favera, R.D.; Califano, A. ARACNE: An Algorithm for the Reconstruction of Gene Regulatory Networks in a Mammalian Cellular Context. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Averbeck, B.B.; Latham, P.E.; Pouget, A. Neural correlations, population coding and computation. Nat. Rev. Neurosci. 2006, 7, 358–366. [Google Scholar] [CrossRef] [PubMed]
- Quian, R.Q.; Panzeri, S. Extracting information from neuronal populations: information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Macke, J.H.; Gross, J.; Kayser, C. Neural population coding: combining insights from microscopic and mass signals. Trends Cogn. Sci. 2015, 19, 162–172. [Google Scholar] [CrossRef] [PubMed]
- Pearl, J. Causality: Models, Reasoning and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Shamir, M. Emerging principles of population coding: In search for the neural code. Curr. Opin. Neurobiol. 2014, 25, 140–148. [Google Scholar] [CrossRef] [PubMed]
- Runyan, C.A.; Piasini, E.; Panzeri, S.; Harvey, C.D. Distinct timescales of population coding across cortex. Nature 2017, 548, 92–96. [Google Scholar] [CrossRef] [PubMed]
- Timme, N.M.; Ito, S.; Myroshnychenko, M.; Nigam, S.; Shimono, M.; Yeh, F.C.; Hottowy, P.; Litke, A.M.; Beggs, J.M. High-Degree Neurons Feed Cortical Computations. PLoS Comput. Biol. 2016, 12, e1004858. [Google Scholar] [CrossRef] [PubMed]
- Jazayeri, M.; Afraz, A. Navigating the Neural Space in Search of the Neural Code. Neuron 2017, 93, 1003–1014. [Google Scholar] [CrossRef] [PubMed]
- Gallego, J.A.; Perich, M.G.; Miller, L.E.; Solla, S.A. Neural Manifolds for the Control of Movement. Neuron 2017, 94, 978–984. [Google Scholar] [CrossRef] [PubMed]
- Sharpee, T.O. Optimizing Neural Information Capacity through Discretization. Neuron 2017, 94, 954–960. [Google Scholar] [CrossRef] [PubMed]
- Pitkow, X.; Angelaki, D.E. Inference in the Brain: Statistics Flowing in Redundant Population Codes. Neuron 2017, 94, 943–953. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
The Partial Information Decomposition as defined by Williams and Beer’s axioms [10]. (a) The mutual information of the sources about the target X is decomposed into four atoms: the redundancy , the unique informations , , and the synergy . The colored rectangles represent the linear equations that relate the four PID atoms to four Shannon information quantities; (b) An exploded view of the allotment of information between the sources and the target X: each PID atom of panel (a) corresponds to a thick dotted line, while the colored stripes represent the two pairwise mutual informations between each of the sources and the target (with the same color code as in (a)). Each of the mutual informations splits into the sum of the redundancy with its corresponding unique information. The circuit-diagram symbol for the XOR operation is associated to the synergistic component only for illustration, as XOR is often taken as a paradigmatic example of synergistic interaction between variables.
Figure 1.
The Partial Information Decomposition as defined by Williams and Beer’s axioms [10]. (a) The mutual information of the sources about the target X is decomposed into four atoms: the redundancy , the unique informations , , and the synergy . The colored rectangles represent the linear equations that relate the four PID atoms to four Shannon information quantities; (b) An exploded view of the allotment of information between the sources and the target X: each PID atom of panel (a) corresponds to a thick dotted line, while the colored stripes represent the two pairwise mutual informations between each of the sources and the target (with the same color code as in (a)). Each of the mutual informations splits into the sum of the redundancy with its corresponding unique information. The circuit-diagram symbol for the XOR operation is associated to the synergistic component only for illustration, as XOR is often taken as a paradigmatic example of synergistic interaction between variables.
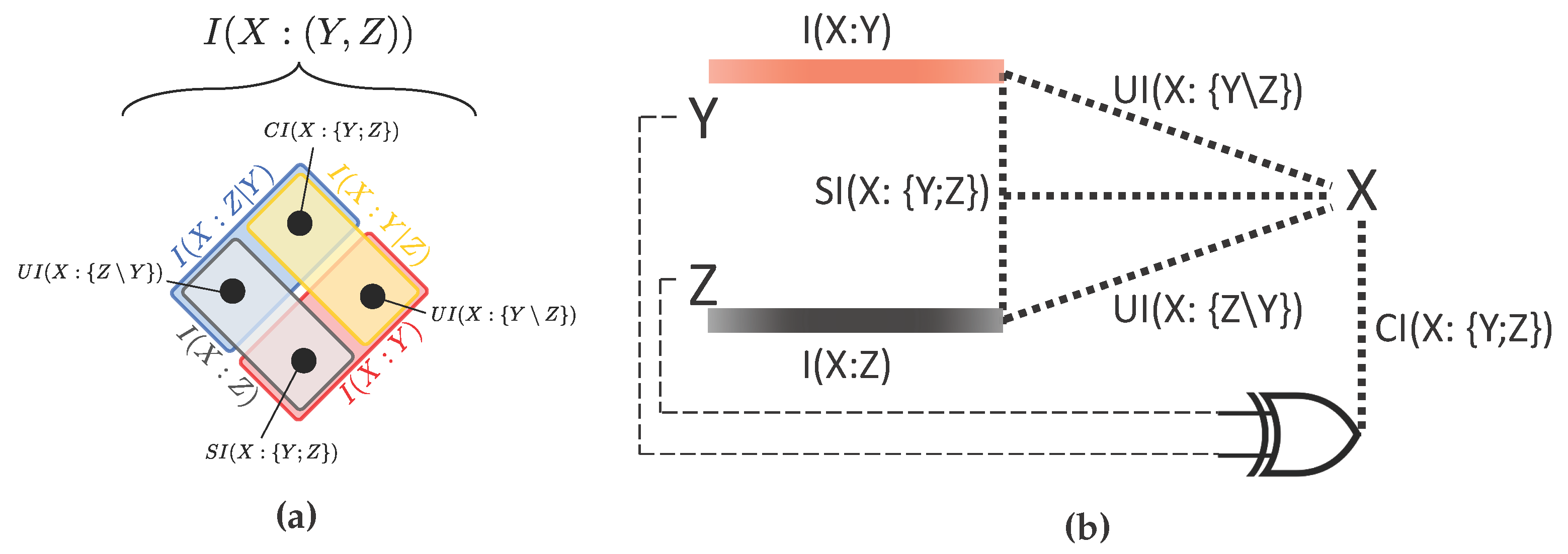
Figure 2.
The three possible PIDs of a trivariate probability distribution that follow from the three possible choices for the target variable: on the left the target is X, in the middle it is Y and on the right it is Z. The coloured rectangles highlight the linear relationships between the twelve PID atoms and the six Shannon information quantities. Note that the orientations of the PIDs for and are rotated with respect to the PID for to highlight their reciprocal relations, as will become more apparent in Figure 4.
Figure 2.
The three possible PIDs of a trivariate probability distribution that follow from the three possible choices for the target variable: on the left the target is X, in the middle it is Y and on the right it is Z. The coloured rectangles highlight the linear relationships between the twelve PID atoms and the six Shannon information quantities. Note that the orientations of the PIDs for and are rotated with respect to the PID for to highlight their reciprocal relations, as will become more apparent in Figure 4.

Figure 3.
(a) The relationships between the PID atoms from two diagrams with different target selections. When we swap a target and a source, the differences in the amount of redundancy, synergy, and unique information with respect to the third variable are not independent due to equations of the type of Equations (1) and (2). Here, we consider the PID diagram of (left) and (right) from Figure 2, under the assumption that ; (b) The reversible pieces of information (orange block), (gray block) and (magenta block) contribute to the same kind of atom across the two PID diagrams. The irreversible piece of information (light blue block) contributes to different kinds of atom across the two PID diagrams. The remaining two unique information atoms (black dots) are not constrained by equations of the type of Equations (1) and (2) when only X or Y are considered as target.
Figure 3.
(a) The relationships between the PID atoms from two diagrams with different target selections. When we swap a target and a source, the differences in the amount of redundancy, synergy, and unique information with respect to the third variable are not independent due to equations of the type of Equations (1) and (2). Here, we consider the PID diagram of (left) and (right) from Figure 2, under the assumption that ; (b) The reversible pieces of information (orange block), (gray block) and (magenta block) contribute to the same kind of atom across the two PID diagrams. The irreversible piece of information (light blue block) contributes to different kinds of atom across the two PID diagrams. The remaining two unique information atoms (black dots) are not constrained by equations of the type of Equations (1) and (2) when only X or Y are considered as target.
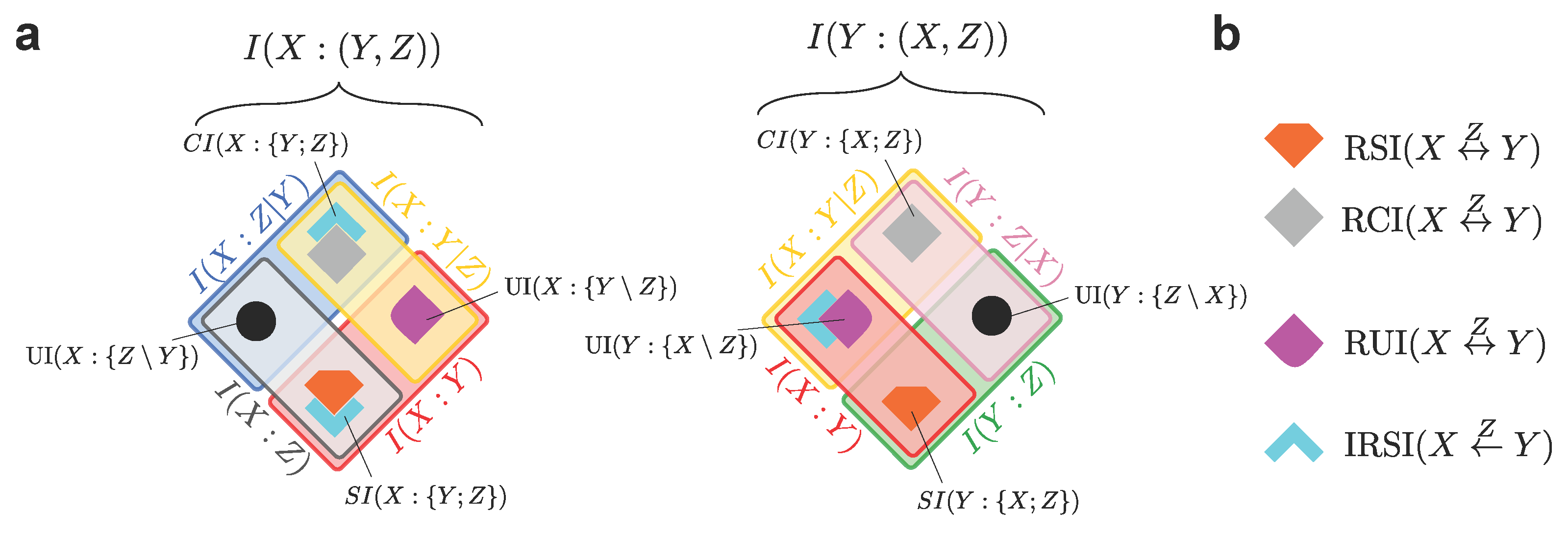
Figure 4.
Constructing the full structure of the three PID diagrams in Figure 2 in terms of a minimal set of information subatoms. (a) All the 12 PID atoms in Figure 2 can be expressed as sums of seven independent PID subatoms that are displayed as coloured blocks in (b) (as in Figure 2, the orientations of the PIDs for and are rotated with respect to the PID for to highlight their reciprocal relations). Five of these subatoms are reversible pieces of information, that are included in the same kind of PID atom across different PID diagrams; the other two subatoms are the irreversible pieces of information, that can be included in different kinds of PID atom across different diagrams. Assuming, without loss of generality, that , the five reversible subatoms are: (orange), (gray), (magenta), (blue), and (brown). The two irreversible subatoms are (light blue) and (yellow).
Figure 4.
Constructing the full structure of the three PID diagrams in Figure 2 in terms of a minimal set of information subatoms. (a) All the 12 PID atoms in Figure 2 can be expressed as sums of seven independent PID subatoms that are displayed as coloured blocks in (b) (as in Figure 2, the orientations of the PIDs for and are rotated with respect to the PID for to highlight their reciprocal relations). Five of these subatoms are reversible pieces of information, that are included in the same kind of PID atom across different PID diagrams; the other two subatoms are the irreversible pieces of information, that can be included in different kinds of PID atom across different diagrams. Assuming, without loss of generality, that , the five reversible subatoms are: (orange), (gray), (magenta), (blue), and (brown). The two irreversible subatoms are (light blue) and (yellow).

Figure 5.
Exploded view of the information that two variables carry about a third variable Z. The mutual informations of each source about the target are decomposed into PID atoms as in Figure 1b, but the PID atoms are now further decomposed in terms of the minimal subatoms’ set: the thick colored lines represent the subatoms with the same colour code as in Figure 4. Here, we assume that the variables are ordered as in Figure 4. The finer structure of the PID atoms allows us to identify the source redundancy (orange line + light blue line) as the part of the full redundancy that is apparent in the mutual information between the sources . Instead, the amount of information in the non-source redundancy (yellow line) also appears in the synergy .
Figure 5.
Exploded view of the information that two variables carry about a third variable Z. The mutual informations of each source about the target are decomposed into PID atoms as in Figure 1b, but the PID atoms are now further decomposed in terms of the minimal subatoms’ set: the thick colored lines represent the subatoms with the same colour code as in Figure 4. Here, we assume that the variables are ordered as in Figure 4. The finer structure of the PID atoms allows us to identify the source redundancy (orange line + light blue line) as the part of the full redundancy that is apparent in the mutual information between the sources . Instead, the amount of information in the non-source redundancy (yellow line) also appears in the synergy .
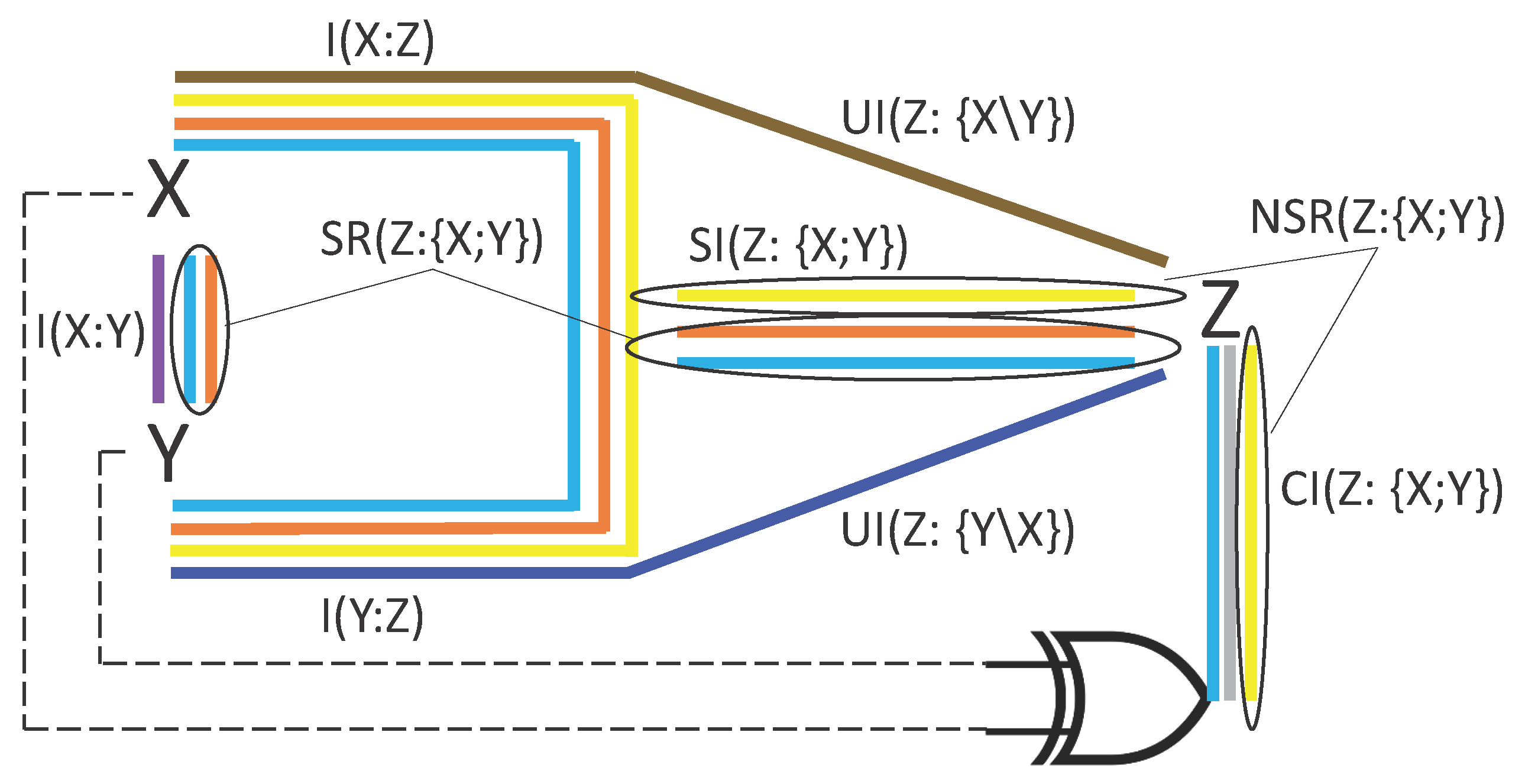
Figure 6.
Dyadic and triadic statistical dependencies in a trivariate system, as defined in Ref. [21]. The tables display the non-zero probability values as a function of the possible outcomes of the three stochastic variables with domain . , , (the symbol ∼ here means ’is distributed as’), where are binary uniform random variables. (a) The underlying rules that give rise to dyadic dependencies are , , ; (b) The underlying rules that give rise to triadic dependencies are , .
Figure 6.
Dyadic and triadic statistical dependencies in a trivariate system, as defined in Ref. [21]. The tables display the non-zero probability values as a function of the possible outcomes of the three stochastic variables with domain . , , (the symbol ∼ here means ’is distributed as’), where are binary uniform random variables. (a) The underlying rules that give rise to dyadic dependencies are , , ; (b) The underlying rules that give rise to triadic dependencies are , .

Figure 7.
The joint entropy of the system is decomposed in terms of the minimal set identified in Figure 4, once the univariate fluctuations quantified with have been subtracted out (see Equation (16)). As in Figure 4, we assume without loss of generality . The finer PID structure unveiled in this work enables a general entropy decomposition in terms of quantities that can be interpreted without relying on a specific PID point of view, even though they have been defined within the PID framework. The colored areas represent the Shannon information quantities that are included in the of Equation (14), with the same color code of Figure 2.
Figure 7.
The joint entropy of the system is decomposed in terms of the minimal set identified in Figure 4, once the univariate fluctuations quantified with have been subtracted out (see Equation (16)). As in Figure 4, we assume without loss of generality . The finer PID structure unveiled in this work enables a general entropy decomposition in terms of quantities that can be interpreted without relying on a specific PID point of view, even though they have been defined within the PID framework. The colored areas represent the Shannon information quantities that are included in the of Equation (14), with the same color code of Figure 2.
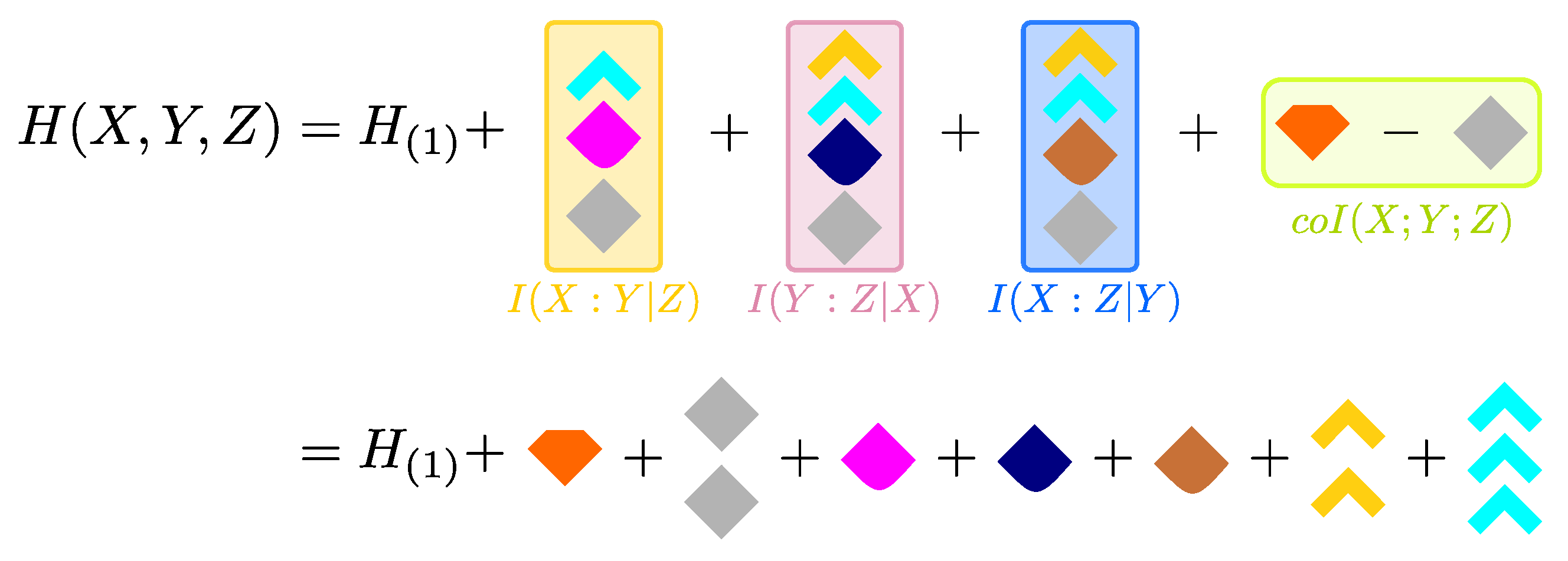
Figure 8.
The joint entropy bits of a dyadic (upper panel) and a triadic (lower panel) system, as defined in Figure 6, is decomposed in terms of the minimal set as illustrated in Figure 7. In the dyadic system, is decomposed into three pieces of (reversible) unique information: each variable contains 1 bit of unique information with respect to the second variable about the third variable. In the triadic system, is decomposed into one bit of information shared among all three variables (the reversible redundancies) and two bits of (reversible) synergistic information due to the three-wise XOR structure.
Figure 8.
The joint entropy bits of a dyadic (upper panel) and a triadic (lower panel) system, as defined in Figure 6, is decomposed in terms of the minimal set as illustrated in Figure 7. In the dyadic system, is decomposed into three pieces of (reversible) unique information: each variable contains 1 bit of unique information with respect to the second variable about the third variable. In the triadic system, is decomposed into one bit of information shared among all three variables (the reversible redundancies) and two bits of (reversible) synergistic information due to the three-wise XOR structure.
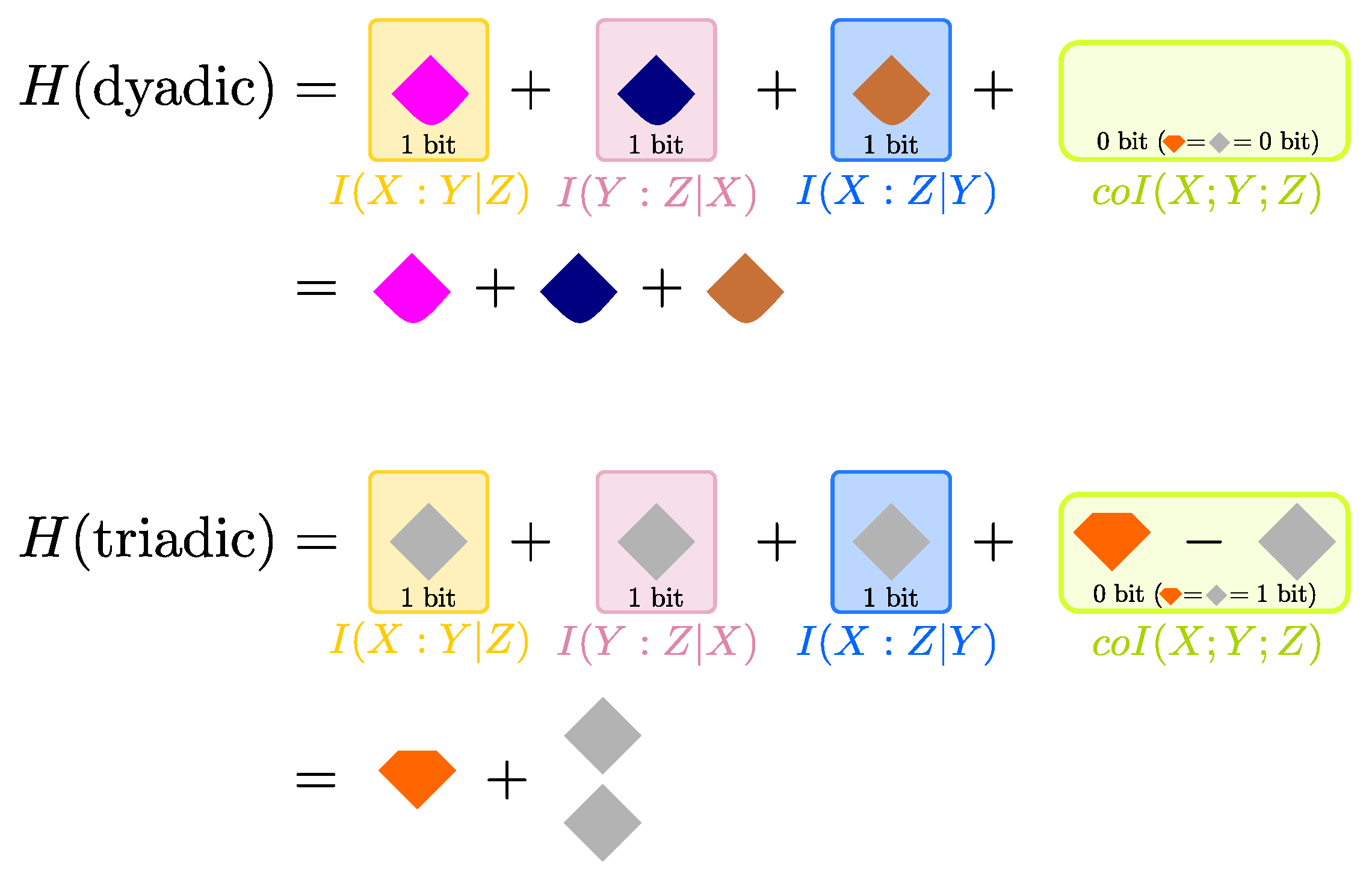
Figure 9.
The binary random variables Y and Z are uniformly distributed inputs that determine the output X as in panel (a) and as in panel (b). Correlations between Y and Z decrease with increasing , from perfect correlation () to perfect independence (). The full redundancy , the source redundancy and the non-source redundancy of the inputs about the output are plotted as a function of . (a) Since the output variable X copies the inputs , all of can only come from the correlations between the inputs, which is reflected in being identically 0 for all values of . (b) For all values of we find , i.e., there is a part of the redundancy which does not arise from the correlations between the inputs Y and Z. Accordingly, also appears in the synergy .
Figure 9.
The binary random variables Y and Z are uniformly distributed inputs that determine the output X as in panel (a) and as in panel (b). Correlations between Y and Z decrease with increasing , from perfect correlation () to perfect independence (). The full redundancy , the source redundancy and the non-source redundancy of the inputs about the output are plotted as a function of . (a) Since the output variable X copies the inputs , all of can only come from the correlations between the inputs, which is reflected in being identically 0 for all values of . (b) For all values of we find , i.e., there is a part of the redundancy which does not arise from the correlations between the inputs Y and Z. Accordingly, also appears in the synergy .
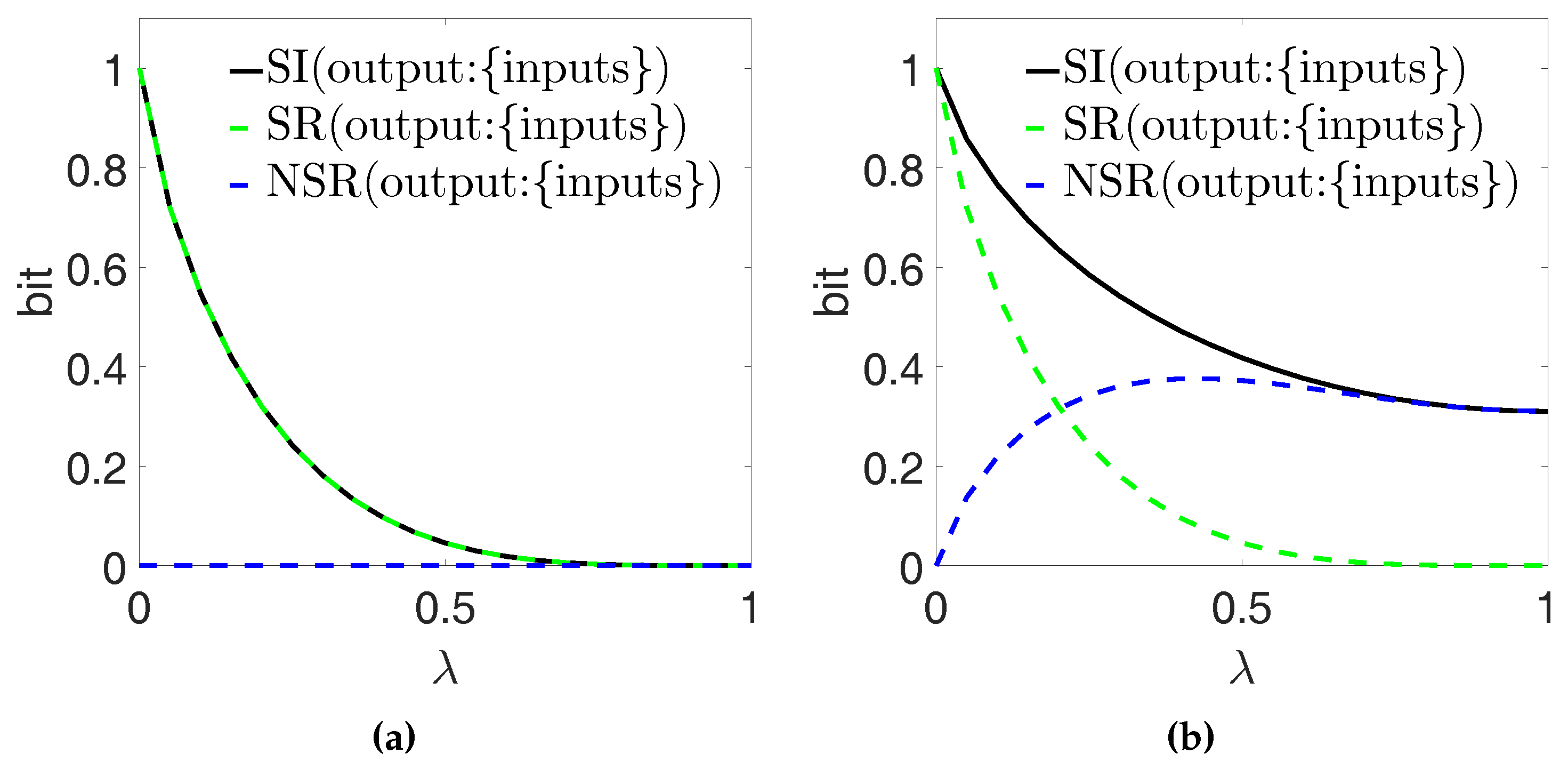
Figure 10.
Two dice with uniformly distributed outcomes ranging from 1 to 6 are the inputs fed to an output third variable X as follows: (a) ; (b) z. The parameter controls the correlations between Y and Z (from complete correlation for to complete independence for ). In panel (a) the inputs are symmetrically combined to determine the output X, while in panel (b) this symmetry is lost: accordingly, for any fixed the full redundancy is larger in (a) than in (b). Since the value of does not change the inputs’ correlations, the relative contribution of the inputs’ correlations to the full redundancy increases from (a) to (b). Indeed, in panel (a) for , while in (b) for any , i.e., the redundancy arises entirely from inputs’ correlations.
Figure 10.
Two dice with uniformly distributed outcomes ranging from 1 to 6 are the inputs fed to an output third variable X as follows: (a) ; (b) z. The parameter controls the correlations between Y and Z (from complete correlation for to complete independence for ). In panel (a) the inputs are symmetrically combined to determine the output X, while in panel (b) this symmetry is lost: accordingly, for any fixed the full redundancy is larger in (a) than in (b). Since the value of does not change the inputs’ correlations, the relative contribution of the inputs’ correlations to the full redundancy increases from (a) to (b). Indeed, in panel (a) for , while in (b) for any , i.e., the redundancy arises entirely from inputs’ correlations.
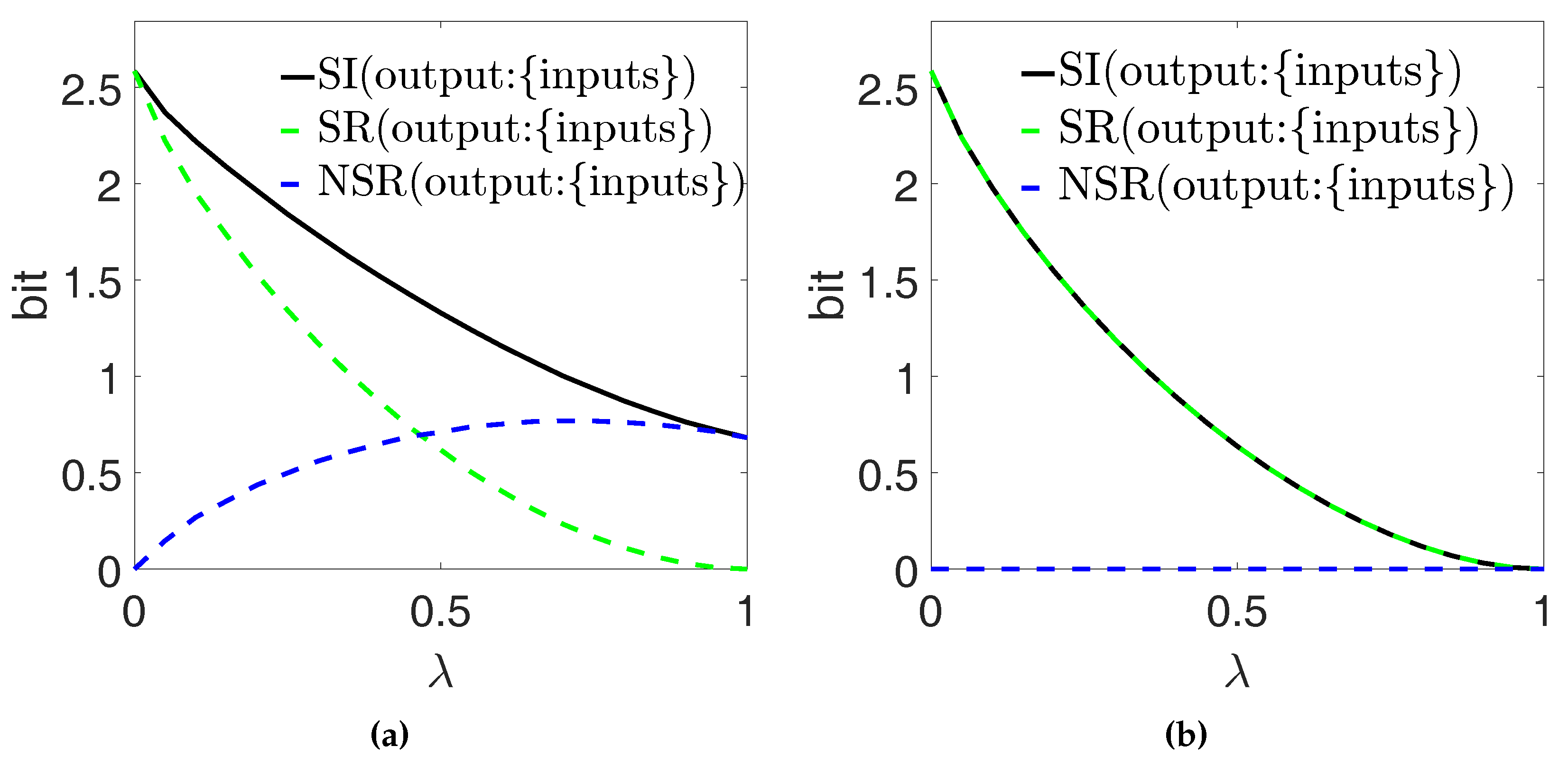
Figure 11.
The finer structure of the three PID diagrams, as defined in Figure 4, in the case of a generic Markov chain . Three of the seven subatoms of the minimal set described in Figure 4 are forced to zero by the Markov property .
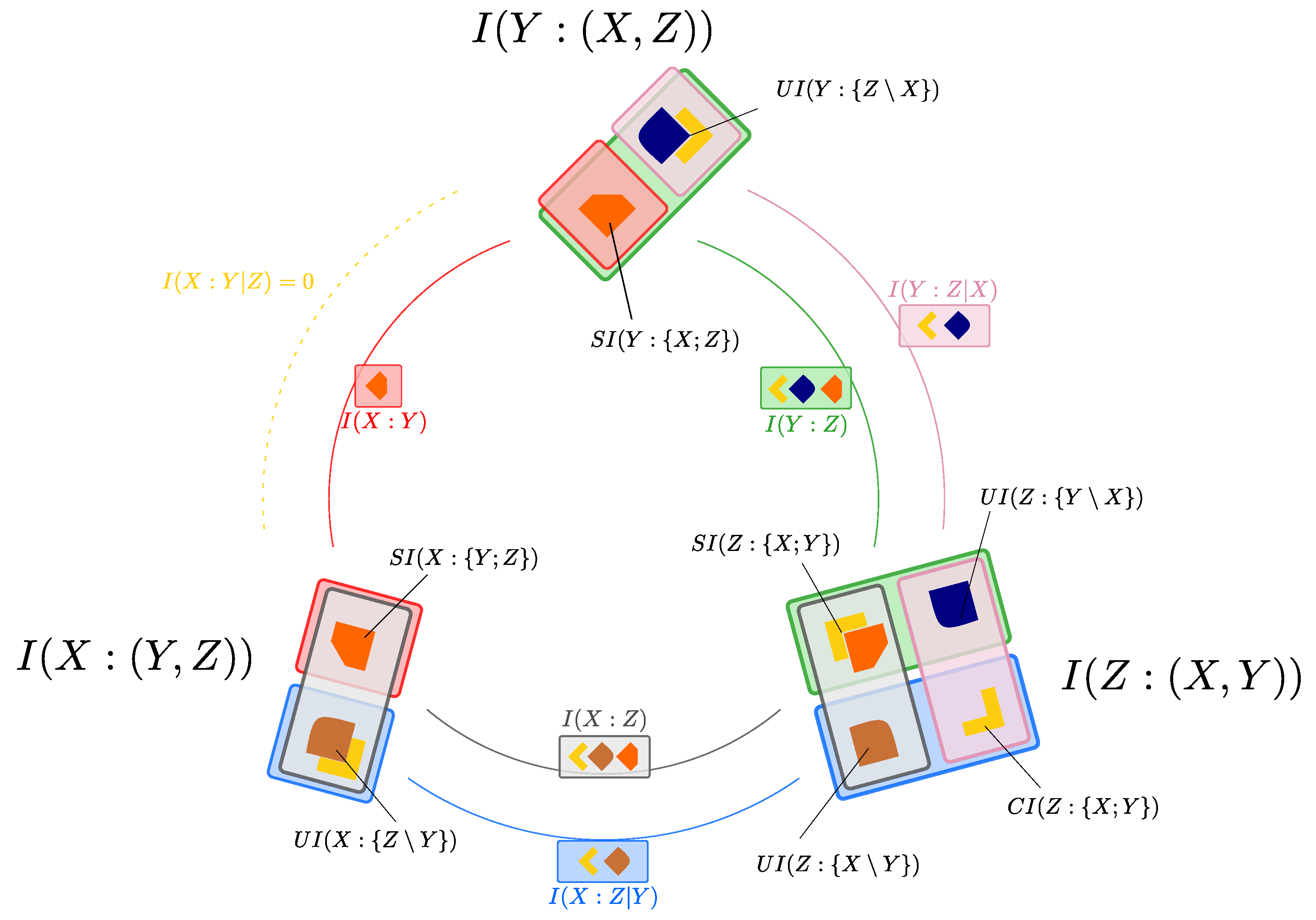
Figure 12.
and share information via two parallel channels: one passes through Z, the other does not. The parameters control the correlations as depicted with the arrows. If we use the PID definitions in Ref. [11], we find that, in agreement with the interpretation in Section 6.2, here quantifies information between X and Y that also passes through Z, as it is equal to .
Figure 12.
and share information via two parallel channels: one passes through Z, the other does not. The parameters control the correlations as depicted with the arrows. If we use the PID definitions in Ref. [11], we find that, in agreement with the interpretation in Section 6.2, here quantifies information between X and Y that also passes through Z, as it is equal to .
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pica, G.; Piasini, E.; Chicharro, D.; Panzeri, S. Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables. Entropy 2017, 19, 451. https://doi.org/10.3390/e19090451
AMA Style
Pica G, Piasini E, Chicharro D, Panzeri S. Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables. Entropy. 2017; 19(9):451. https://doi.org/10.3390/e19090451
Chicago/Turabian StylePica, Giuseppe, Eugenio Piasini, Daniel Chicharro, and Stefano Panzeri. 2017. "Invariant Components of Synergy, Redundancy, and Unique Information among Three Variables" Entropy 19, no. 9: 451. https://doi.org/10.3390/e19090451
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.