Computational Information Geometry for Binary Classification of High-Dimensional Random Tensors †



1
Laboratory of Signals and Systems (L2S), Department of Signals and Statistics, University of Paris-Sud, 91400 Orsay, France
2
Computer Science Department LIX, École Polytechnique, 91120 Palaiseau, France
3
Sony Computer Science Laboratories, Tokyo 141-0022, Japan
*
Author to whom correspondence should be addressed.
†
The results presented in this work have been partially published in the 2017 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017 and the 2017 25th European Association for Signal Processing (EUSIPCO), Kos, Greece, 28 August–2 September 2017.
Entropy 2018, 20(3), 203; https://doi.org/10.3390/e20030203
Submission received: 25 January 2018
/
Revised: 13 March 2018
/
Accepted: 14 March 2018
/
Published: 17 March 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Evaluating the performance of Bayesian classification in a high-dimensional random tensor is a fundamental problem, usually difficult and under-studied. In this work, we consider two Signal to Noise Ratio (SNR)-based binary classification problems of interest. Under the alternative hypothesis, i.e., for a non-zero SNR, the observed signals are either a noisy rank-R tensor admitting a Q-order Canonical Polyadic Decomposition (CPD) with large factors of size , i.e., for , where with converge towards a finite constant or a noisy tensor admitting TucKer Decomposition (TKD) of multilinear -rank with large factors of size , i.e., for , where with converge towards a finite constant. The classification of the random entries (coefficients) of the core tensor in the CPD/TKD is hard to study since the exact derivation of the minimal Bayes’ error probability is mathematically intractable. To circumvent this difficulty, the Chernoff Upper Bound (CUB) for larger SNR and the Fisher information at low SNR are derived and studied, based on information geometry theory. The tightest CUB is reached for the value minimizing the error exponent, denoted by . In general, due to the asymmetry of the s-divergence, the Bhattacharyya Upper Bound (BUB) (that is, the Chernoff Information calculated at ) cannot solve this problem effectively. As a consequence, we rely on a costly numerical optimization strategy to find . However, thanks to powerful random matrix theory tools, a simple analytical expression of is provided with respect to the Signal to Noise Ratio (SNR) in the two schemes considered. This work shows that the BUB is the tightest bound at low SNRs. However, for higher SNRs, the latest property is no longer true.
1. Introduction
1.1. State-of-the-Art and Problem Statement
Evaluating the performance limit for the “Gaussian information plus noise” binary classification problem is a challenging research topic, see for instance [1,2,3,4,5,6,7]. Given a binary hypothesis problem, the Bayes’ decision rule is based on the principle of the largest posterior probability. Specifically, the Bayesian detector chooses the alternative hypothesis if for a given N-dimensional measurement vector or the null hypothesis , otherwise. Consequently, the optimal decision rule can often only be derived at the price of a costly numerical computation of the log posterior-odds ratio [3] since an exact calculation of the minimal Bayes’ error probability is often intractable [3,8]. To circumvent this problem, it is standard to exploit well-known bounds on based on information theory [9,10,11,12,13]. In particular, the Chernoff information [14,15] is asymptotically (in N) relied on the exponential rate of . It turns out that the Chernoff information is very useful in many practically important problems as for instance, distributed sparse detection [16], sparse support recovery [17], energy detection [18], multi-input and multi-output (MIMO) radar processing [19,20], network secrecy [21], angular resolution limit in array processing [22], detection performance for informed communication systems [23], just to name a few. In addition, the Chernoff information bound can be tight for a minimal s-divergence over parameter . Generally, this step requires solving numerically an optimization problem [24] and often leads to a complicated and uninformative expression of the optimal value of s. To circumvent this difficulty, a simplified case of is often used corresponding to the well-known Bhattacharyya divergence [13] at the price of a less accurate prediction of . In information geometry, parameter s is often called , and the s-divergence is the so-called Chernoff -divergence [24].
The tensor decomposition theory is a timely and prominent research topic [25,26]. Confronting the problem of extracting useful information from a massive and multidimentional volume of measurements, it is shown that tensors are extremely relevant. In the standard literature, two main families of tensor decomposition are prominent, namely the Canonical Polyadic Decomposition (CPD) [26] and the Tucker decomposition (TKD)/HOSVD (High-Order SVD) [27,28]. These approaches are two possible multilinear generalization of the Singular Value Decomposition (SVD). A natural generalization to tensors of the usual concept of rank for matrices is called the CPD. The tensorial/canonical rank of a P-order tensor is equal to the minimal positive integer, say R, of unit rank tensors that must be summed up for perfect recovery. A unit rank tensor is the outer product of P vectors. In addition, the CPD has remarkable uniqueness properties [26] and involves only a reduced number of free parameters due to the constraint of minimality on R. Unfortunately, unlike the matrix case, the set of tensors with fixed (tensorial) rank is not close [29,30]. This singularity implies that the problem of the computation of the CPD is mathematically ill-posed. The consequence is that its numerical computation remains non trivial and is usually done using suboptimal iterative algorithms [31]. Note that this problem can sometimes be avoided by exploiting some natural hidden structures in the physical model [32]. The TKD [28] and the HOSVD [27] are two popular decompositions being an alternative to the CPD. Under this circumstance, alternative definition of rank is required, since the tensorial rank based on CPD scenario is no longer appropriate. In particular, stardard definition of multilinear rank defined as the set of positive integers where each integer, , is the usual rank of the p-th mode. Following the Eckart-Young theorem at each mode level [33], this construction is non-iterative, optimal and practical. In real-time computation [34] or adaptively computation [35], it is shown that this approach is suitable. However, in general, the low (multilinear) rank tensor based on this procedure is suboptimal [27]. More precisely, for tensors of order strictly greater than two, a generalization of the Eckart-Young theorem does not exist.
The classification performance of a multilinear tensor following the CPD and TKD can be derived and studied. It is interesting to note that the classification theory for tensors is very under studied. Based on our knowledge on the topic, only the publication [36] tackles this problem in the context of radar multidimensional data detection. A major difference with this publication is that their analysis is based on the performance of a low rank detection after matched filtering.
More precisely, we consider two cases where the observations are either (1) a noisy rank-R tensor admitting a Q-order CPD with large factors of size , i.e., for , with converging towards a finite constant, or (2) a noisy tensor admitting a TKD of multilinear -rank with large factors of size , i.e., for , where with converging towards a finite constant. A standard approach for zero-mean independent Gaussian core and noise tensors, is to define the Signal to Noise Ratio by where and are the variances of the vectorized core and noise tensors, respectively. So, the binary classification can be described in the following way:
Under the null hypothesis , , meaning that the observed tensor contains only noise. Conversely, the alternative hypothesis is based on , meaning that there exists a multilinear signal of interest. First note that there exists a lack of contribution dealing with classification performance for tensors. Since the exact derivation of the error probability is intractable, the performance of the classification of the core tensor random entries is hard to evaluate. To circumvent this audible difficulty, based on computational information geometry theory, we consider the Chernoff Upper Bound (CUB), and the Fisher information in the context of massive measurement vectors. The error exponent can be minimized at , which corresponds to the reachable tightest CUB. In general, due to the asymmetry of the s-divergence, the Bhattacharyya Upper Bound (BUB)—Chernoff Information calculated at —cannot solve this problem effectively. As a consequence, we rely on a costly numerical optimization strategy to find . However, with respect to different Signal to Noise Ratios (SNR), we provide simple analytical expressions of , thanks to the so-called Random Matrix Theory (RMT). For low SNR, analytical expressions of the Fisher information are given. Note that the analysis of the Fisher information in the context of the RMT has been only studied in recent contributions [37,38,39] for parameter estimation. For larger SNR, analytic and simple expression of the CUB for the CPD and the TKD are provided.
We note that Random Matrix Theory (RMT) has attracted both mathematicians and physicists since they were first introduced in mathematical statistics by Wishart in 1928 [40]. When Wigner [41] introduced the concept of statistical distribution of nuclear energy levels, the subject has started to earn prominence. However, it took until 1955 before Wigner [42] introduced ensembles of random matrices. Since then, many important results in RMT were developed and analyzed, see for instance [43,44,45,46] and the references therein. In the last two decades, research on RMT has been constantly published.
Finally, let us underline that many arguments of this paper differ from the works presented in [47,48]. In [47], we tackled the problem of detection using Chernoff Upper Bound in data of type matrix in the double asymptotic regime. In [48], we established the detection problem in tensor data by analyzing the Chernoff Upper Bound. In [48], we assumed that the tensor follows the Canonical Polyadic Decomposition (CPD), we gave some analysis of Chernoff Upper Bound when the rank of the tensor is much smaller than the dimensions of the tensor. Since [47,48] are conference papers, some proofs have been omitted due to limited space. Therefore, this full paper may share the ideas in [47,48] on Information Geometry (s-divergence, Chernoff Upper Bound, Fisher Information, etc.), but completes [48] in a more general asymptotic regime. Moreover, in this work, we give new analysis in both scenarios (SNR small and large) whereas [48] did not, and the important and difficult new tensor scenario of the Tucker decomposition is considered. This is in our view the main difference because the CPD is a particular case of the more general decomposition of TucKer. Indeed, in the CPD, the core tensor is assumed to be diagonal.
1.2. Paper Organisation
The organization of the paper is as follows: In the second section, we introduce some definitions, tensor models, and the Marchenko-Pastur distribution from random matrix theory. The third section is devoted to present Chernoff Information for binary hypothesis test. The fourth section gives the main results on Fisher Information and the Chernoff bound. The numerical simulation results are given in the fifth section. We conclude our work by giving some perspectives in the Section 6. Finally, several proofs of the paper can be found in the appendix.
2. Algebra of Tensors and Random Matrix Theory (RMT)
In this section, we introduce some useful definitions from tensor algebra and from the spectral theory of large random matrices.
2.1. Multilinear Functions
2.1.1. Preliminary Definitions
Definition 1.
The Kronecker product of matrices and of size and , respectively is given by
We have .
Definition 2.
The vectorization of a tensor is a vector defined as
where .
Definition 3.
The q-mode product denoted by between a tensor and a matrix is denoted by with
where .
Definition 4.
The q-mode unfolding matrix of size denoted by of a tensor is defined according to
where .
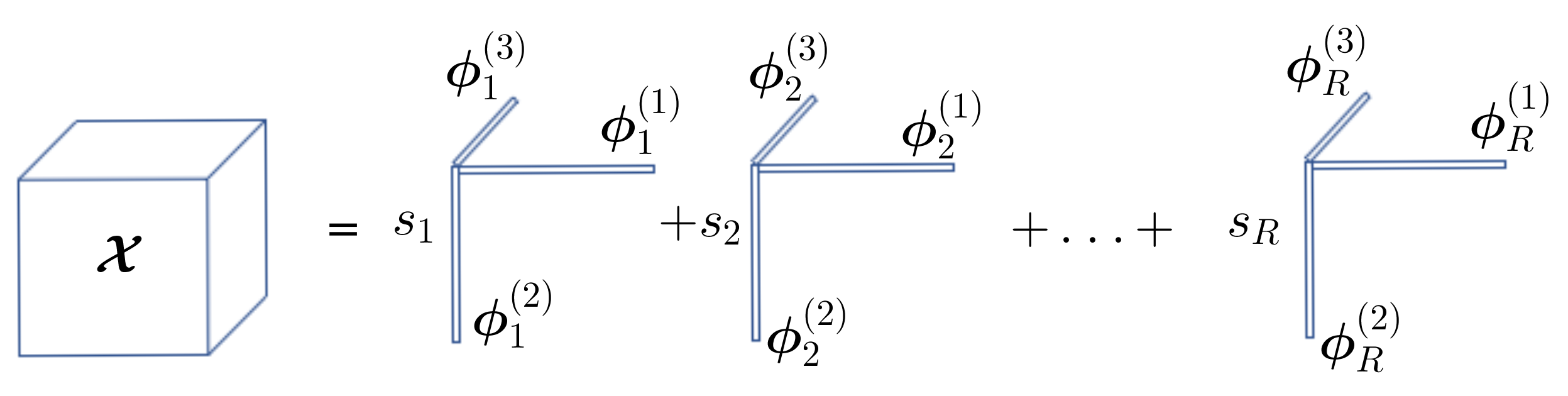
2.1.2. Canonical Polyadic Decomposition (CPD)
The rank-R CPD of order Q is defined according to
where ○ is the outer product [25], and is a real scalar.
An equivalent formulation using the q-mode product defined in Definition 3 is
where is the diagonal core tensor with and is the q-th factor matrix of size .
The q-mode unfolding matrix for tensor is given by
where with and ⊙ stands for the Khatri-Rao product [25].
2.1.3. Tucker Decomposition (TKD)
The Tucker tensor model of order Q is defined according to
where , and is a real scalar.
The q-mode product of is similar to CPD case, however the q-mode unfolding matrix for tensor is slightly different
where the q-mode unfolding matrix of tensor , and ⊗ stands for Kronecker product. See Figure 1.
Following the definitions, we note that the CPD and TKD scenarios imply that vector in Equation (11) is related either to the structured linear system or .
2.2. The Marchenko-Pastur Distribution
The Marchenko-Pastur distribution was introduced half a century ago [45] in 1967, and plays a key role in a number of high-dimensional signal processing problems. To help the reader, in this section, we introduce some fundamental results concerning large empirical covariance matrices. Let a sequence of i.i.d zero mean Gaussian random M-dimensional vectors for which . We consider the empirical covariance matrix
which can be also written as
where matrix is defined by . is thus a Gaussian matrix with independent identically distributed entries. When while M remains fixed, matrix converges towards in the spectral norm sense. In the high dimensional asymptotic regime defined by
it is well understood that does not converge towards 0. In particular, the empirical distribution of the eigenvalues of does not converge towards the Dirac measure at point . More precisely, we denote by the Marchenko-Pastur distribution of parameters defined as the probability measure
with and . Then, the following result holds.
Theorem 1
([45]). The empirical eigenvalue value distribution converges weakly almost surely towards when both M and N converge towards in such a way that converges towards . Moreover, it holds that
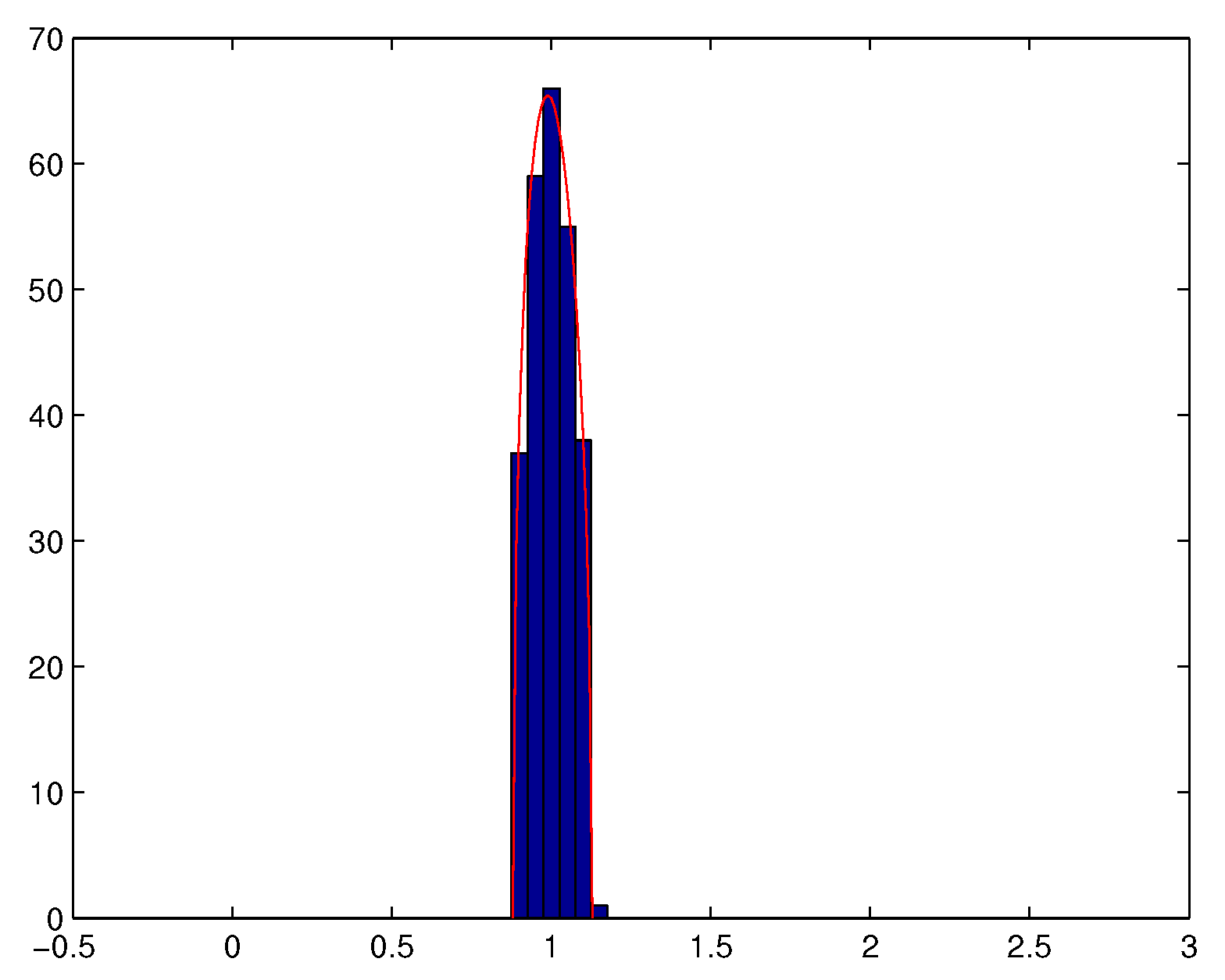
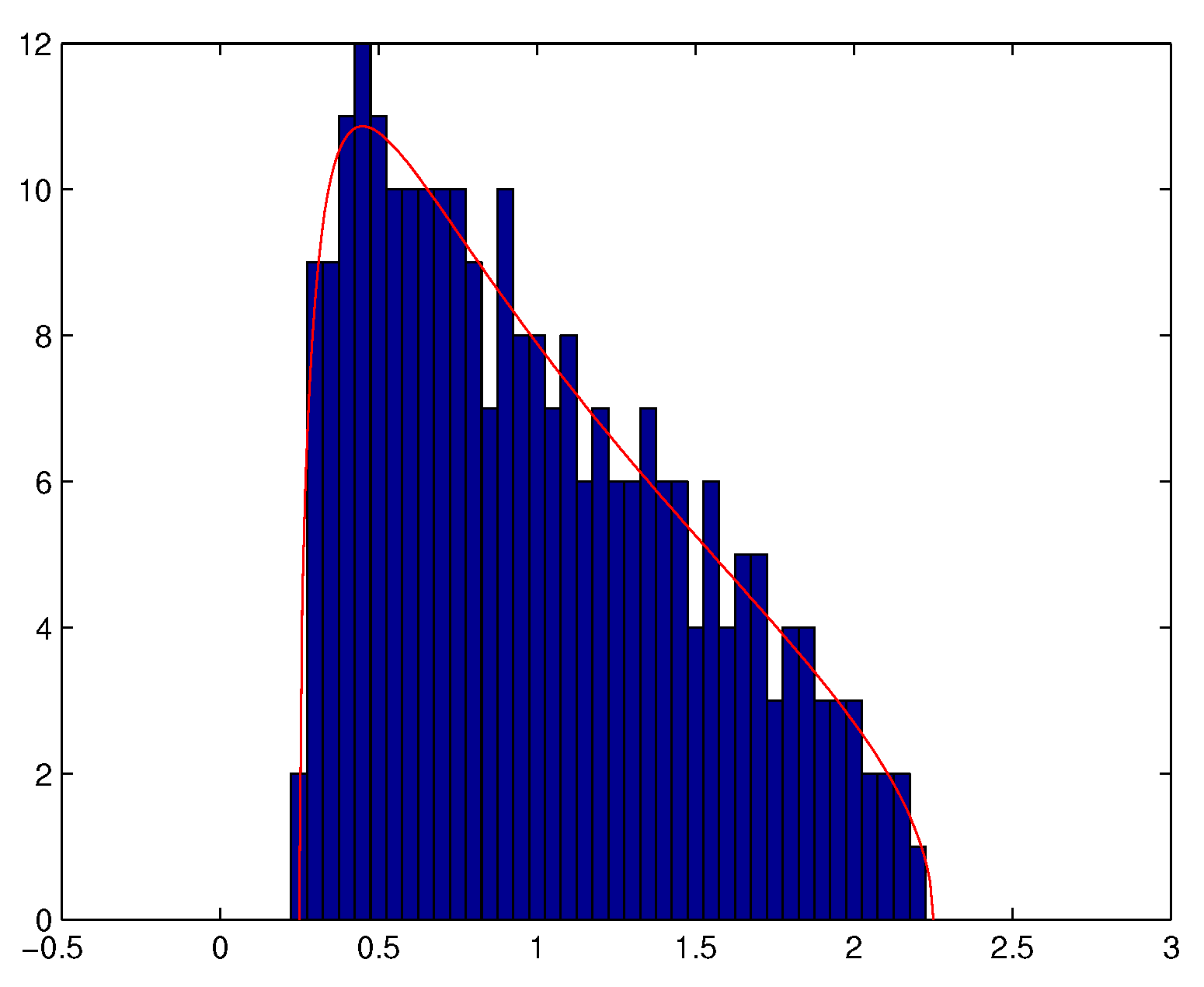
We also observe that Theorem 1 remains valid if is not necessarily a Gaussian matrix whose i.i.d. elements have a finite fourth order moment (see e.g., [43]). Theorem 1 means that when ratio is not small enough, the eigenvalues of the empirical spatial covariance matrix of a temporally and spatially white noise tend to spread out around the variance of the noise, and that almost surely, for N large enough, all the eigenvalues are located in a neighbourhood of interval . See Figure 2 and Figure 3.
3. Classification in a Computational Information Geometry (CIG) Framework
3.1. Formulation Based on a -Type Criterion
We denote by and with . The binary classification of the random signal based on the equi-probable binary hypothesis test, , is
where and . The null hypothesis data-space () is defined as where
is the alternative hypothesis () data-space. Following the above expression, the log-likelihood ratio test and the binary classification threshold are given by
where and are respectively the determinant and the natural logarithm.
3.2. The Expected Log-likelihood Ratio in Geometry Perspective
We note that the estimated hypothesis is associated to . Therefore, the expected log-likelihood ratio is defined by
where
is the Kullback-Leibler Divergence (KLD) [10]. The expected log-likelihood ratio test admits to a simple geometric characterization based on the difference of two KLDs [8]. However, it is often difficult to evaluate the performance of the test via the minimal Bayes’ error probability , since its expression cannot be determined analytically in closed-form [3,8].
The minimal Bayes’ error probability conditionally to vector is defined as
where .
3.3. CUB
According to [24], the relation between the Chernoff Upper Bound and the (average) minimal Bayes’ error probability is given by
where the (Chernoff) s-divergence for is given by
in which is the moment generating function (mgf) of variable X. The error exponent, denoted by , is given by the Chernoff information which is an asymptotic characterization on the exponentially decay of the minimal Bayes’ error probability. The error exponent is derived thanks to the Stein’s lemma according to [13]
As parameter is free, the CUB can be tightened by minimizing this parameter:
Finally, using Equations (5) and (7), the Chernoff Upper Bound (CUB) is obtained. Instead of solving Equation (7), the Bhattacharyya Upper Bound (BUB) is calculated by Equation (5) and by fixing . Therefore we have the following relation of order:
Lemma 1.
The log-moment generating function given by Equation (6) for test of Equation (4) is given by
Proof.
See Appendix A. ◻
From now on, to simplify the presentation and the numerical results later on, we denote by
for all , the opposites of the log-moment generating function and its limit.
Remark 1.
The functions are negative, since the s-divergence is positive for all .
3.4. Fisher Information
In the small deviation regime, we assume that is a small deviation of the SNR. The new binary hypothesis test is
where The s-divergence in the small deviation scenario is written as
Lemma 2.
The s-divergence in the small deviation regime can be approximated according to
where the Fisher information [3] is given by
Proof.
See Appendix B. ◻
According to Lemma 2, the optimal s-value at low is . At contrary, the optimal s-value for larger is given by the following lemma.
Lemma 3.
In case of large , we have
where are the eigenvalues of .
Proof.
See Appendix C. ◻
4. Computational Information Geometry for Classification
4.1. Formulation of the Observation Vector as a Structured Linear Model
The measurement tensor follows a noisy Q-order tensor of size can be expressed as
where is the noise tensor whose entries are assumed to be centered i.i.d. Gaussian, i.e., and the core tensor follows either CPD or TKD given by Section 2.1.2 and Section 2.1.3, respectively. The vectorization of Equation (10) is given by
where and . Note that , and are respectively the first unfolding matrices given by Definition 4 of tensors and ,
- When tensor follows a Q-order CPD with a canonical rank of M, we havewhere is a structured matrix and where , i.i.d. and .
- When tensor follows a Q-order TKD of multilinear rank of , we havewhere is a structured matrix with and is the vectorization of tensor where , i.i.d.
4.2. The CPD Case
We recall that in the CPD case, matrix and are matrices of size . In the following, we assume that matrices are random matrices with Gaussian variate entries. We evaluate the behavior of when converge towards at the same rate and that converges towards a non zero limit.
Result 1.
In the asymptotic regime where converge towards at the same rate and where in such a way that converges towards a finite constant , it holds that
with standing for “almost sure convergence” and
with where .
Proof.
See Appendix D. ◻
Remark 2.
In [49], the Central Limit Theorem (CLT) for the linear eigenvalue statistics of the tensor version of the sample covariance matrix of type is established, for , i.e., the tensor order is .
4.2.1. Small Deviation Scenario
In this section, we assume that is small. Under this regime, we have the following result:
Result 2.
In the small scenario, the Fisher information for CPD is given as
Proof.
Using Lemma 2, we can notice that
and that
converges a.s towards the second moment of the Marchenko-Pastur distribution which is (see for instance [43]). ◻
Note that is the error exponent related to the Bhattacharyya divergence.
4.2.2. Large Deviation Scenario
Result 3.
In case of large , the minimizer of Chernoff Information is given by
Proof.
It is straightforward to notice that
The last equality can be obtained as in [50]. Using Lemma 3, we get immediately Equation (14). ◻
Remark 3.
It is interesting to note that for or 1, the optimal s-value follows the same approximated relation given by
as long as or equivalently a in dB much larger than 4 dB.
Proof.
It is straightforward to note that
Using Equation (14) and condition , the desired result is proved. ◻
4.2.3. Approximated Analytical Expressions for and Any
In the case of low rank CPD where its rank R is supposed to be small compared to N, it is realistic to assume since .
Result 4.
Under this regime, the error exponent can be approximated as follows:
Proof.
See Appendix E. ◻
It is easy to notice that the second-order derivative of is strictly positive. Therefore, is a strictly convex function over interval . As a consequence, admits at most one global minimum. We denote by , the global minimizer and obtained by zeroing the first-order derivative of the error exponent. This optimal value is expressed as
The two following scenarios can be considered:
- At low , we denote by , the error exponent associated with the tightest CUB, coincides with the error exponent associated with the BUB. To see this, when , we derive the second-order approximation of the optimal value in Equation (47)Result 1 and the above approximation allow us to get the best error exponent at low and ,
- Contrarily, when , . As a consequence, the optimal error exponent in this regime is not the BUB anymore. Assuming that , Equation (15) in Result 4 provides the following approximation of the optimal error exponent for large
4.3. The TKD Case
In the TKD case, we recall that matrix , with are dimensional matrices. We still assume that matrices are random matrices with Gaussian entries.
Result 5.
In the asymptotic regime where and converge towards at the same rate such that , where , it holds
where are Marchenko-Pastur distributions of parameters defined as in Equation (1).
Proof.
See Appendix F. ◻
Remark 4.
We can notice that for , the result 5 is similar to result 1. However, when , the integrals in Equation (16) are not tractable in a closed-form expression. For instance, let , we consider the integral
where . We can notice that this integral is characterized by elliptic integral (see e.g., [51]). As a consequence, it cannot be expressed in closed-form. However, numerical computations can be exploited to solve efficiently the minimization problem of Equation (7).
4.3.1. Large Deviation Scenario
Result 6.
In case of large , the minimizer of Chernoff Information for TKD is given by
Proof.
We have that
Using Lemma 3, we get immediately Equation (17). ◻
4.3.2. Small Deviation Scenario
Under this regime, we have the following results
Result 7.
For small deviation, the Chernoff information for the TKD is given by
Proof.
Using Lemma 2, we can notice that
Each term in the product converges a.s towards the second moment of Marchenko-Pastur distributions which are and converges to . This proves the desired result. ◻
Remark 5.
Contrary to the Remark 3, it is interesting to note that for and or 1, the optimal s-value follows different approximated relation given by
which does not depend on Q, and
which depends on Q.
In practice, when c is close to 1, we have to carefully check if Q is in the neighbourhood of . As we can see that, when or , following the above approximation, .
5. Numerical Illustrations
In this section, we consider cubic tensors of order with following a CPD and for the TKD, respectively.
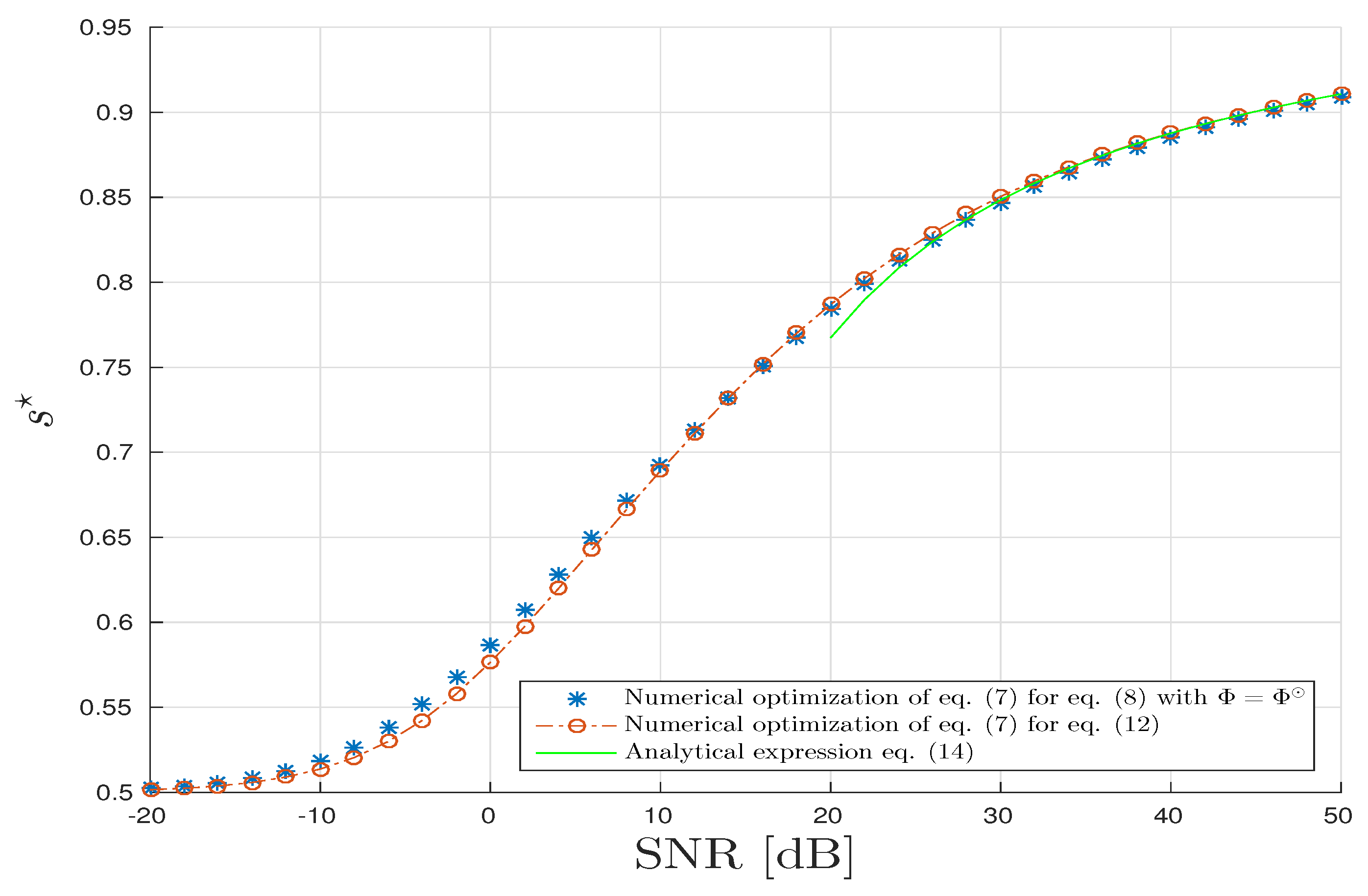
Firstly, for the CPD model, in Figure 4, parameter is drawn with respect to the in dB. The parameter is obtained thanks to three different methods. The first one is based on the brute force/exhaustive computation of the CUB by minimizing the expression in Equation (8) with . This approach has a very high computational cost especially in our asymptotic regime (for a standard computer with Intel Xeon E5-2630 2.3 GHz and 32 GB RAM, it requires 183 h to establish 10,000 simulations). The second approach is based on the numerical optimization of the closed-form expression of given in Result 4. In this scenario, the drawback in terms of the computational cost is largely mitigated since it consists of a minimization of a univariate regular function. Finally, under the hypothesis that is large, typically >30 dB, the optimal s-value, , is derived by an analytic expression given by Equation (15). We can check that the proposed semi-analytic and analytic expressions are in good agreement with the brute-force method for a lowest computational cost. Moreover, we compute the mean square relative error where L = 10,000 the number of samples for Monte–Carlo process and where and . It turns out that the mean square relative errors are in mean of order dB. We can conclude that the estimator is a consistent estimator of .
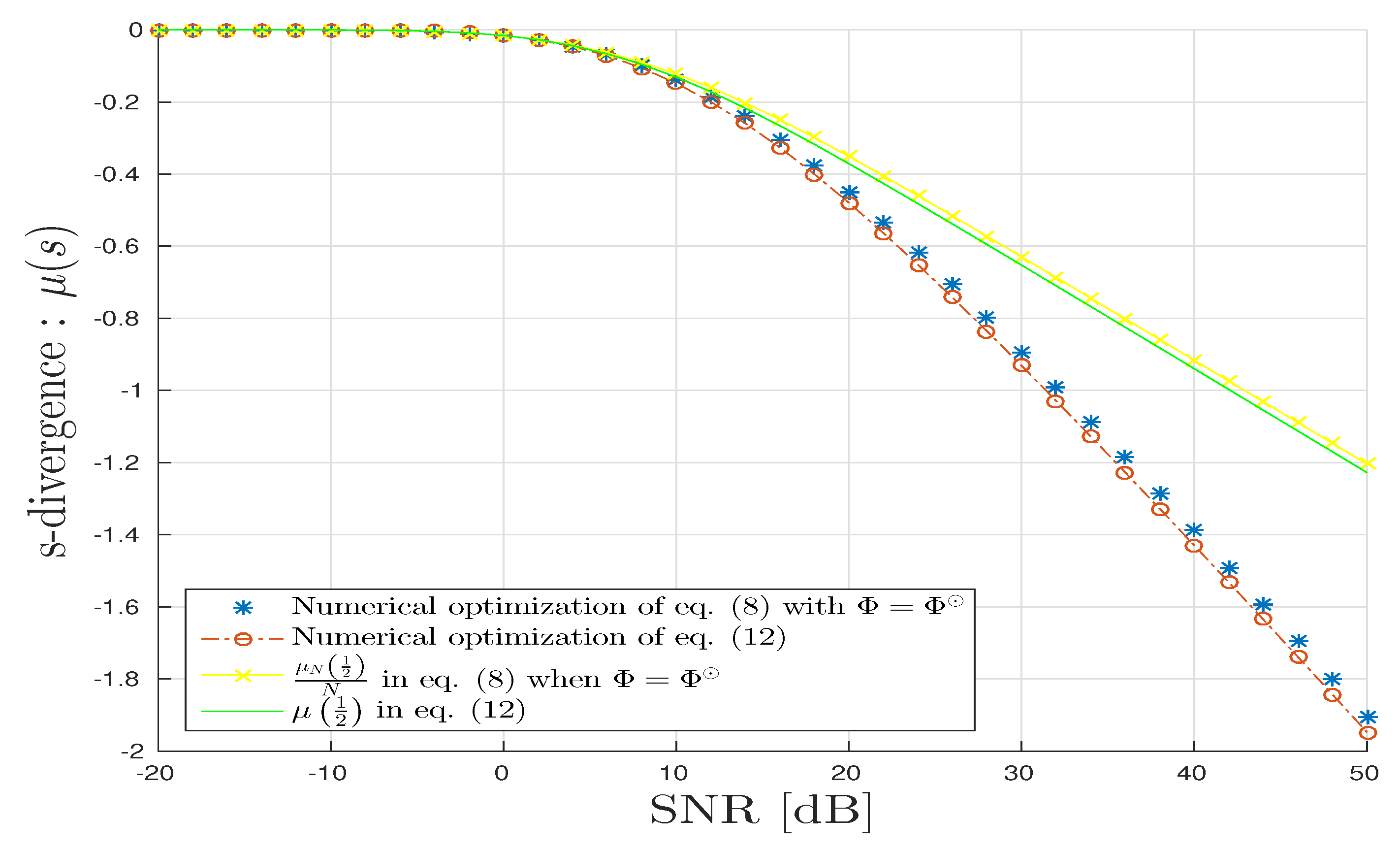
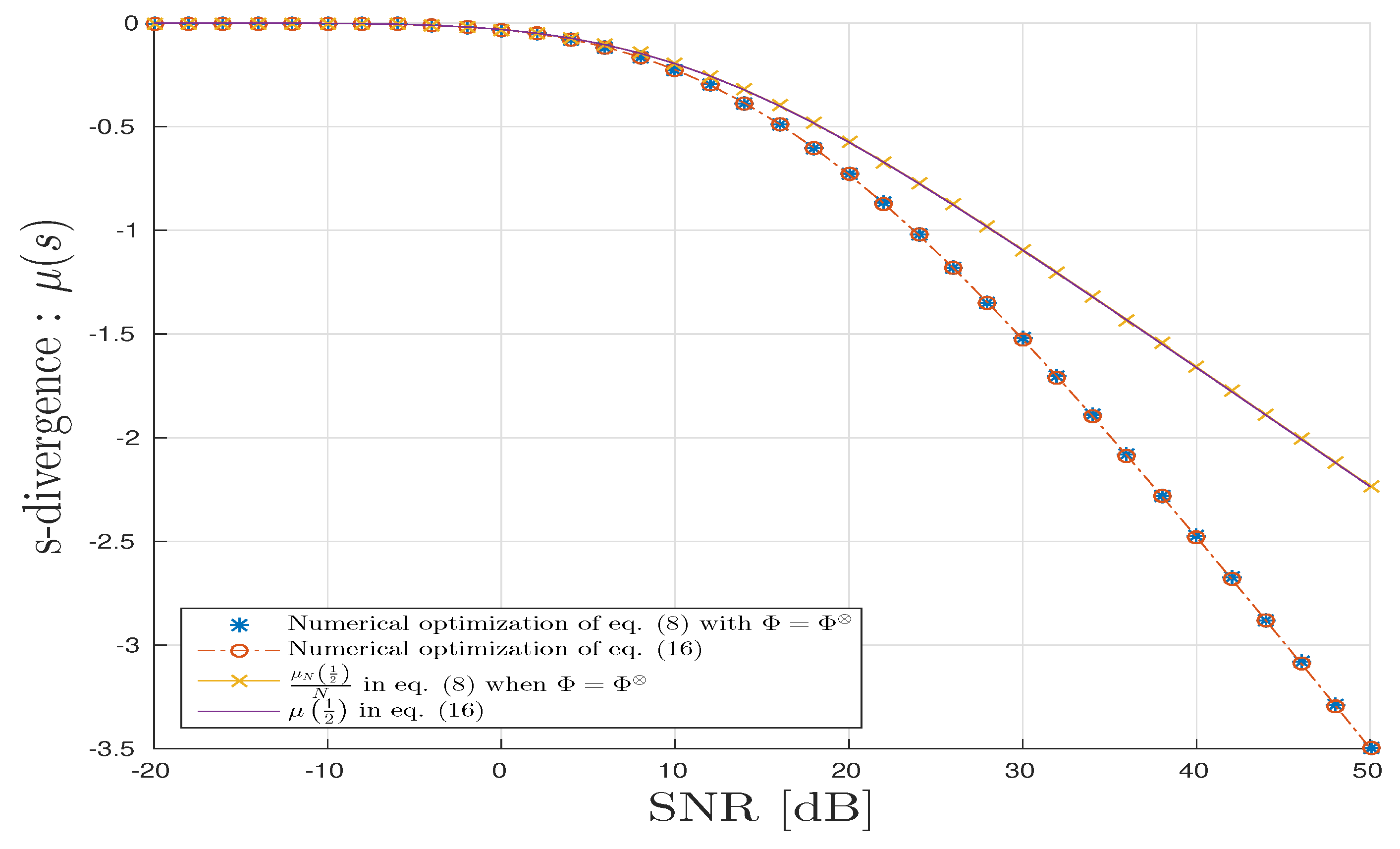
In Figure 5, we draw various s-divergences: . We can observe the good agreement with the proposed theoretical results. The s-divergence obtained by fixing is accurate only at small but degrades when grows large.
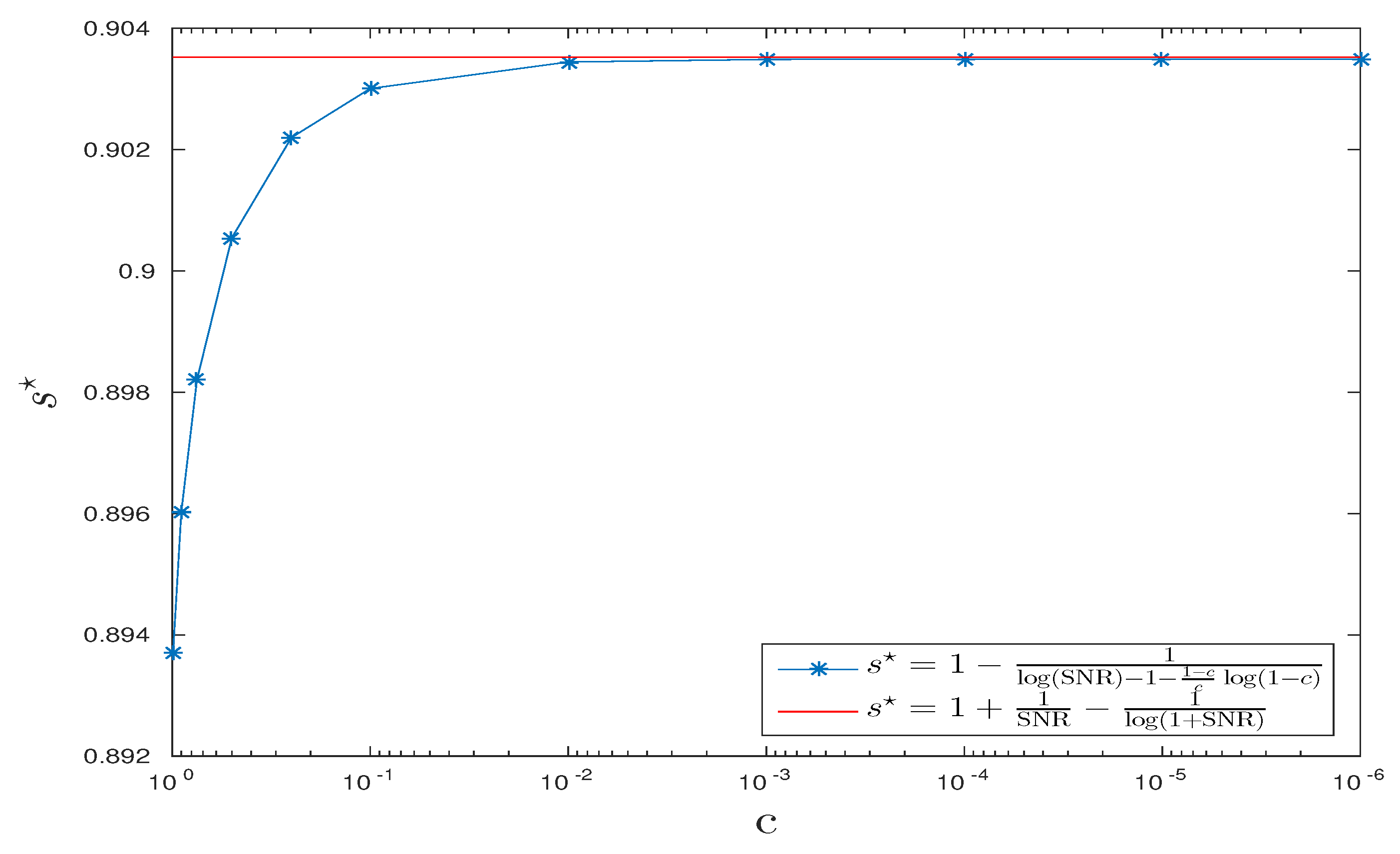
In Figure 6, we fix dB and draw obtained by Equation (14) versus values of and the expression obtained by Equation (15). The two curves approach each other as c goes to zero as predicted by our theoretical analysis.
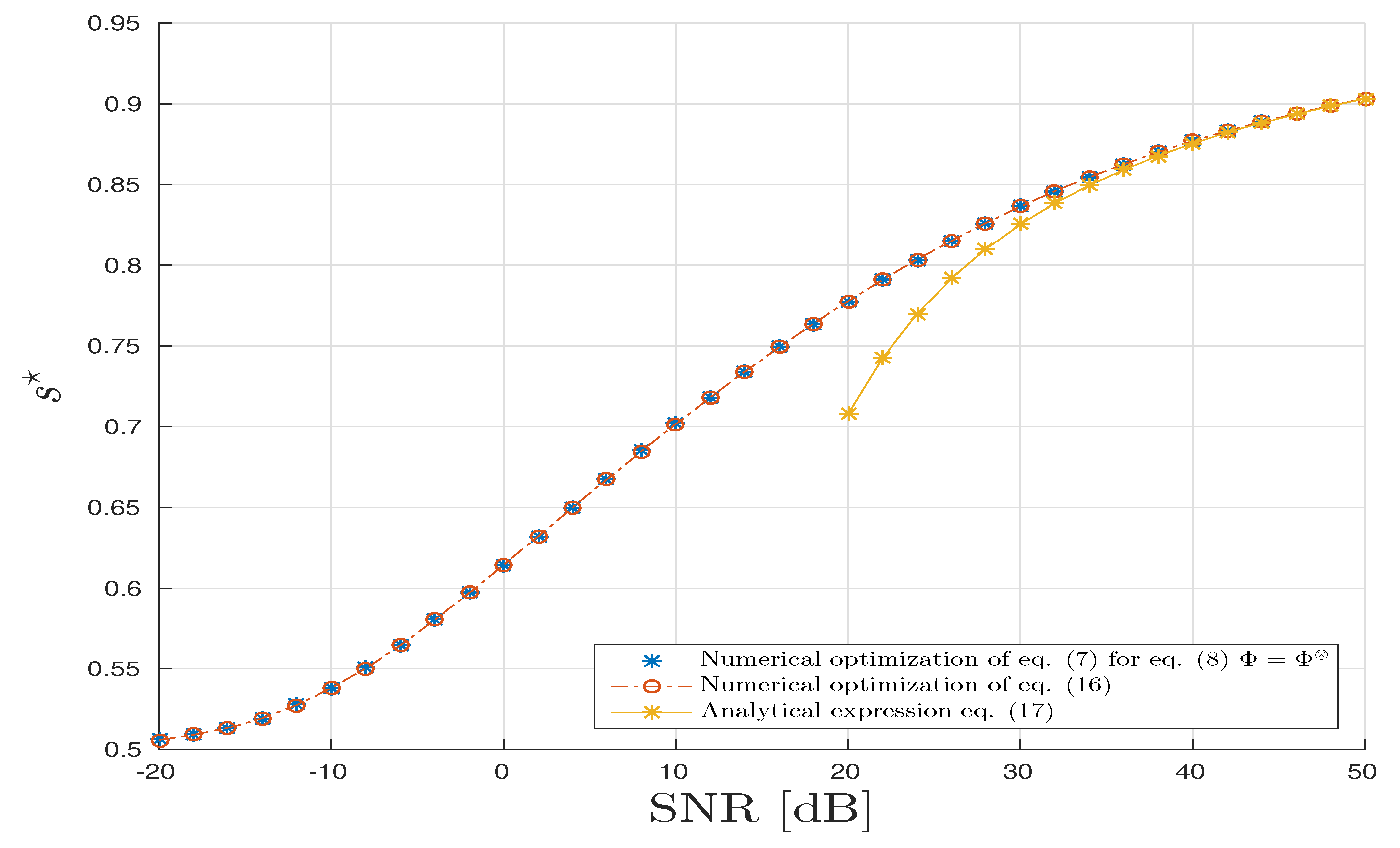
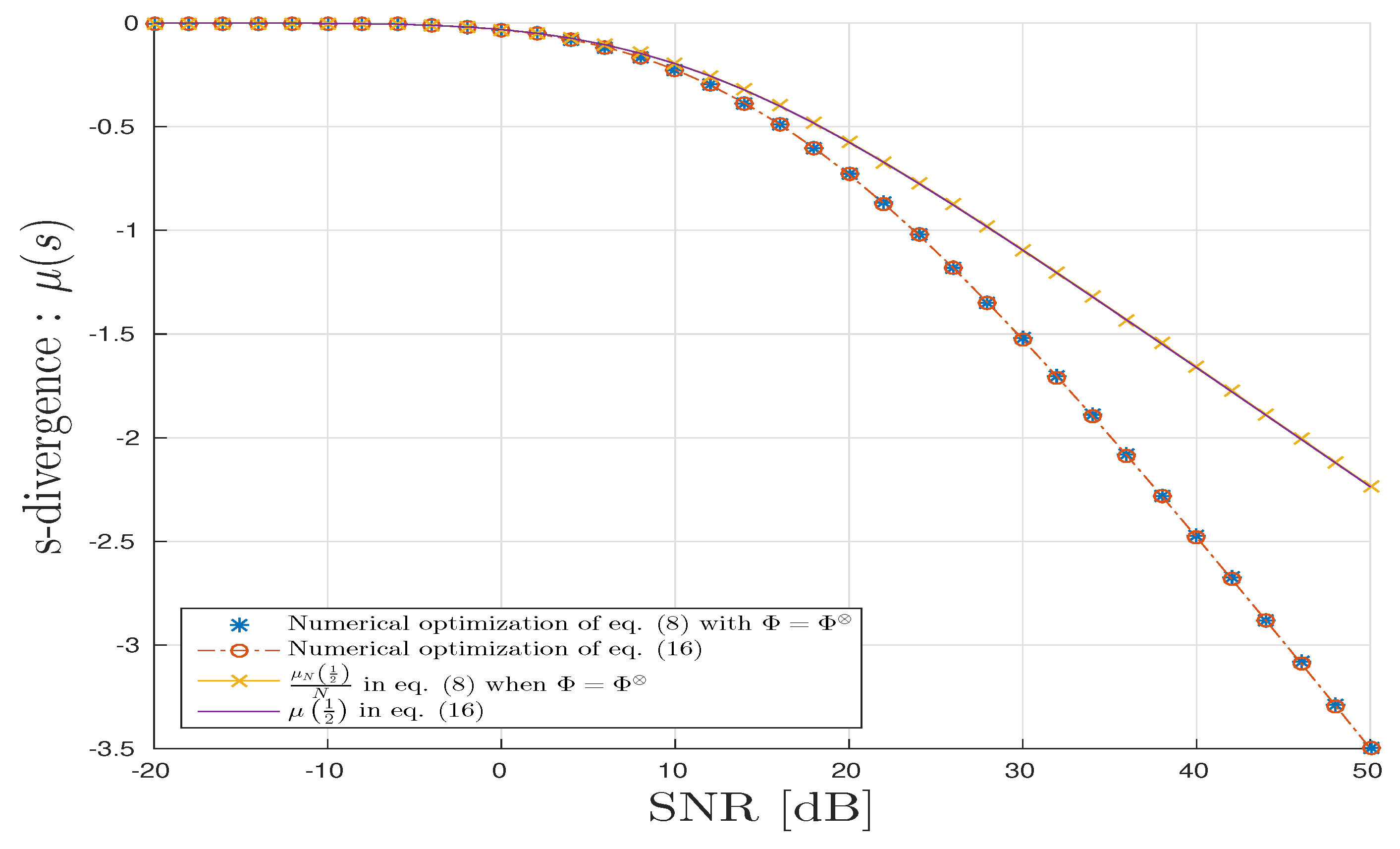
For the TKD scenario, we follow the same methodology as above for CPD, Figure 7 and Figure 8 all agree with the analysis provided in Section 4.3.
For TKD scenario, the mean square relative error is in mean of order dB. So, we check numerically the consistency of the estimator of the optimal s-value.
We can also notice that the convergence of towards its deterministic equivalent in the case TKD is faster than in the case CPD, since the dimension of matrix is () which is much larger than the dimension of ().
6. Conclusions
In this work, we derived and studied the limit performance in terms of minimal Bayes’ error probability for the binary classification of high-dimensional random tensors using both the tools of Information Geometry (IG) and of Random Matrix Theory (RMT). The main results on Chernoff Bounds and Fisher Information are illustrated by Monte–Carlo simulations that corroborated our theoretical analysis.
For future work, we would like to study the rate of convergence and the fluctuation of the statistics and .
Acknowledgments
The authors would like to thank Philippe Loubaton (UPEM, France) for the fruitful discussions. This research was partially supported by Labex DigiCosme (project ANR-11-LABEX-0045-DIGICOSME) operated by ANR (The French National Research Agency) as part of the program “Investissement d’Avenir” Idex Paris-Saclay (ANR-11-IDEX-0003-02).
Author Contributions
Gia-Thuy Pham, Rémy Boyer and Frank Nielsen contributed to the research results presented in this paper. Gia-Thuy Pham and Rémy Boyer performed the numerical experiments. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Lemma 1
Using the expressions of the covariance matrices and , the numerator in Equation (A1) is given by
and the two terms at its numerator are and
Using the above expressions, is given by Equation (8).
Appendix B. Proof of Lemma 2
If we note then the following expression holds:
Using the above expression, the s-divergence is given by
Now, using Equation (8), and the following approximation:
we obtain
where the Fisher information for is given by [3]:
Appendix C. Proof of Theorem 3
The first step of the proof is based on the derivation of an alternative expression of given by Equation (A1) involving the inverse of the covariance matrices and . Specifically, we have
The second step is to derive a closed-form expression in the high SNR regime using the following the approximation (see [52] for instance): where is an orthogonal projector such as and . The numerator in Equation (A2) is given by
As is a rank-K projector matrix scaled by factor , its eigen-spectrum is given by . In addition, as the rank-N identity matrix and the scaled projector can be diagonalized in the same orthonormal basis matrix, the n-th eigenvalue of the inverse of matrix is given by
with . Using the above property, we obtain
In addition, we have
Finally, thanks to Equation (A2), we have
Finally, to obtain in Equation (9), we solve .
Appendix D. Proof of Result 1
The asymptotic behavior of when for each , in such a way that converge towards a non zero constant for each can be obtained thanks to large random matrix theory. We suppose that converge towards at the same rate (i.e., converge towards a non zero constant for each ), and converges towards a constant . Under this regime, the empirical eigenvalue distribution of covariance matrix is known to converge towards the so-called Marcenko–Pastur distribution. By Section 2.2, we recall that the Marcenko–Pastur distribution is defined as
where and . We define the Stieltjes transform of . We have that satisfies the equation
When , i.e., , with , it is well known that is given by
It was established for the first time in [45] that if represents a random matrix with zero mean and variance i.i.d. entries, and if represent the eigenvalues of arranged in decreasing order, then , the empirical eigenvalue distribution of converges weakly almost surely towards , under the regime , , . In addition, we have the following property, for each continuous function
Practically, when K and P are large enough, the histogram of the eigenvalues of each realization of accumulates around the graph of the probability density of .
The columns of are vectors , which are mutually independent, identically distributed, and satisfy . However, since the components of each column are not independent, it results in that the entries of are not mutually independent. Applying the results of [53] (see also [54]), we can establish that the empirical eigenvalue distribution of still converges almost surely towards , under the asymptotic regime . For continuous function , we apply Equation (A4), can be expressed in terms of given by Equation (A3) (see e.g., [50]), we finish the proof.
Appendix E. Proof of Result 4
We have and , , Using the above first-order approximations, Equation (13) is
Using the above approximation and Equation (12), we obtain Result 4.
Appendix F. Proof of Result 5
We first denote the eigenvalues of , , for . We can notice that the eigenvalues of are . Moreover, in the asymptotic regime, where , such that , , for all , we have that if and the empirical distribution of the eigenvalues behaves as Marchenko-Pastur distributions of parameters . Recalling that , , we obtain immediately that
and that
Similarly, we have that
We obtain easily Result 5.
References
- Besson, O.; Scharf, L.L. CFAR matched direction detector. IEEE Trans. Signal Process. 2006, 54, 2840–2844. [Google Scholar] [CrossRef]
- Bianchi, P.; Debbah, M.; Maida, M.; Najim, J. Performance of Statistical Tests for Source Detection using Random Matrix Theory. IEEE Trans. Inf. Theory 2011, 57, 2400–2419. [Google Scholar] [CrossRef] [Green Version]
- Kay, S.M. Fundamentals of Statistical Signal Processing, Volume II: Detection Theory; PTR Prentice-Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Loubaton, P.; Vallet, P. Almost Sure Localization of the Eigenvalues in a Gaussian Information Plus Noise Model. Application to the Spiked Models. Electron. J. Probab. 2011, 16, 1934–1959. [Google Scholar] [CrossRef]
- Mestre, X. Improved Estimation of Eigenvalues and Eigenvectors of Covariance Matrices Using Their Sample Estimates. IEEE Trans. Inf. Theory 2008, 54, 5113–5129. [Google Scholar] [CrossRef]
- Baik, J.; Silverstein, J. Eigenvalues of large sample covariance matrices of spiked population models. J. Multivar. Anal. 2006, 97, 1382–1408. [Google Scholar] [CrossRef]
- Silverstein, J.W.; Combettes, P.L. Signal detection via spectral theory of large dimensional random matrices. IEEE Trans. Signal Process. 1992, 40, 2100–2105. [Google Scholar] [CrossRef]
- Cheng, Y.; Hua, X.; Wang, H.; Qin, Y.; Li, X. The Geometry of Signal Detection with Applications to Radar Signal Processing. Entropy 2016, 18, 381. [Google Scholar] [CrossRef]
- Ali, S.M.; Silvey, S.D. A General Class of Coefficients of Divergence of One Distribution from Another. J. R. Stat. Soc. Ser. B (Methodol.) 1966, 28, 131–142. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Kailath, T. The Divergence and Bhattacharyya Distance Measures in Signal Selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar]
- Nielsen, F. Hypothesis Testing, Information Divergence and Computational Geometry; Geometric Science of Information; Springer: Berlin, Germany, 2013; pp. 241–248. [Google Scholar]
- Sinanovic, S.; Johnson, D.H. Toward a theory of information processing. Signal Process. 2007, 87, 1326–1344. [Google Scholar] [CrossRef]
- Chernoff, H. A Measure of Asymptotic Efficiency for Tests of a Hypothesis Based on the sum of Observations. Ann. Math. Stat. 1952, 23, 493–507. [Google Scholar] [CrossRef]
- Nielsen, F. Chernoff information of exponential families. arXiv, 2011; arXiv:1102.2684. [Google Scholar]
- Chepuri, S.P.; Leus, G. Sparse sensing for distributed Gaussian detection. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- Tang, G.; Nehorai, A. Performance Analysis for Sparse Support Recovery. IEEE Trans. Inf. Theory 2010, 56, 1383–1399. [Google Scholar] [CrossRef]
- Lee, Y.; Sung, Y. Generalized Chernoff Information for Mismatched Bayesian Detection and Its Application to Energy Detection. IEEE Signal Process. Lett. 2012, 19, 753–756. [Google Scholar]
- Grossi, E.; Lops, M. Space-time code design for MIMO detection based on Kullback-Leibler divergence. IEEE Trans. Inf. Theory 2012, 58, 3989–4004. [Google Scholar] [CrossRef]
- Sen, S.; Nehorai, A. Sparsity-Based Multi-Target Tracking Using OFDM Radar. IEEE Trans. Signal Process. 2011, 59, 1902–1906. [Google Scholar] [CrossRef]
- Boyer, R.; Delpha, C. Relative-entropy based beamforming for secret key transmission. In Proceedings of the 2012 IEEE 7th Sensor Array and Multichannel Signal Processing Workshop (SAM), Hoboken, NJ, USA, 17–20 June 2012. [Google Scholar]
- Tran, N.D.; Boyer, R.; Marcos, S.; Larzabal, P. Angular resolution limit for array processing: Estimation and information theory approaches. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012. [Google Scholar]
- Katz, G.; Piantanida, P.; Couillet, R.; Debbah, M. Joint estimation and detection against independence. In Proceedings of the Annual Conference on Communication Control and Computing (Allerton), Monticello, IL, USA, 30 September–3 October 2014; pp. 1220–1227. [Google Scholar]
- Nielsen, F. An information-geometric characterization of Chernoff information. IEEE Signal Process. Lett. 2013, 20, 269–272. [Google Scholar] [CrossRef]
- Cichocki, A.; Mandic, D.; De Lathauwer, L.; Zhou, G.; Zhao, Q.; Caiafa, C.; Phan, H.A. Tensor decompositions for signal processing applications: From two-way to multiway component analysis. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef]
- Comon, P. Tensors: A brief introduction. IEEE Signal Process. Mag. 2014, 31, 44–53. [Google Scholar] [CrossRef]
- De Lathauwer, L.; Moor, B.D.; Vandewalle, J. A Multilinear Singular Value Decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Comon, P.; Berge, J.T.; De Lathauwer, L.; Castaing, J. Generic and Typical Ranks of Multi-Way Arrays. Linear Algebra Appl. 2009, 430, 2997–3007. [Google Scholar] [CrossRef] [Green Version]
- De Lathauwer, L. A survey of tensor methods. In Proceedings of the IEEE International Symposium on Circuits and Systems, ISCAS 2009, Taipei, Taiwan, 24–27 May 2009. [Google Scholar]
- Comon, P.; Luciani, X.; De Almeida, A.L.F. Tensor decompositions, alternating least squares and other tales. J. Chemom. 2009, 23, 393–405. [Google Scholar] [CrossRef] [Green Version]
- Goulart, J.H.D.M.; Boizard, M.; Boyer, R.; Favier, G.; Comon, P. Tensor CP Decomposition with Structured Factor Matrices: Algorithms and Performance. IEEE J. Sel. Top. Signal Process. 2016, 10, 757–769. [Google Scholar] [CrossRef]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar]
- Badeau, R.; Richard, G.; David, B. Fast and stable YAST algorithm for principal and minor subspace tracking. IEEE Trans. Signal Process. 2008, 56, 3437–3446. [Google Scholar] [CrossRef]
- Boyer, R.; Badeau, R. Adaptive multilinear SVD for structured tensors. In Proceedings of the 2006 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’06), Toulouse, France, 14–19 May 2006. [Google Scholar]
- Boizard, M.; Ginolhac, G.; Pascal, F.; Forster, P. Low-rank filter and detector for multidimensional data based on an alternative unfolding HOSVD: Application to polarimetric STAP. EURASIP J. Adv. Signal Process. 2014, 2014, 119. [Google Scholar] [CrossRef]
- Bouleux, G.; Boyer, R. Sparse-Based Estimation Performance for Partially Known Overcomplete Large-Systems. Signal Process. 2017, 139, 70–74. [Google Scholar] [CrossRef]
- Boyer, R.; Couillet, R.; Fleury, B.-H.; Larzabal, P. Large-System Estimation Performance in Noisy Compressed Sensing with Random Support—A Bayesian Analysis. IEEE Trans. Signal Process. 2016, 64, 5525–5535. [Google Scholar] [CrossRef]
- Ollier, V.; Boyer, R.; El Korso, M.N.; Larzabal, P. Bayesian Lower Bounds for Dense or Sparse (Outlier) Noise in the RMT Framework. In Proceedings of the 2016 IEEE Sensor Array and Multichannel Signal Processing Workshop (SAM 16), Rio de Janerio, Brazil, 10–13 July 2016. [Google Scholar]
- Wishart, J. The generalized product moment distribution in samples. Biometrika 1928, 20A, 32–52. [Google Scholar] [CrossRef]
- Wigner, E.P. On the statistical distribution of the widths and spacings of nuclear resonance levels. Proc. Camb. Philos. Soc. 1951, 47, 790–798. [Google Scholar] [CrossRef]
- Wigner, E.P. Characteristic vectors of bordered matrices with infinite dimensions. Ann. Math. 1955, 62, 548–564. [Google Scholar]
- Bai, Z.D.; Silverstein, J.W. Spectral Analysis of Large Dimensional Random Matrices, 2nd ed.; Springer Series in Statistics; Springer: Berlin, Germany, 2010. [Google Scholar]
- Girko, V.L. Theory of Random Determinants; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1990. [Google Scholar]
- Marchenko, V.A.; Pastur, L.A. Distribution of eigenvalues for some sets of random matrices. Math. Sb. (N.S.) 1967, 72, 507–536. [Google Scholar]
- Voiculescu, D. Limit laws for random matrices and free products. Invent. Math. 1991, 104, 201–220. [Google Scholar] [CrossRef]
- Boyer, R.; Nielsen, F. Information Geometry Metric for Random Signal Detection in Large Random Sensing Systems. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Boyer, R.; Loubaton, P. Large deviation analysis of the CPD detection problem based on random tensor theory. In Proceedings of the 2017 25th European Association for Signal Processing (EUSIPCO), Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Lytova, A. Central Limit Theorem for Linear Eigenvalue Statistics for a Tensor Product Version of Sample Covariance Matrices. J. Theor. Prob. 2017, 1–34. [Google Scholar] [CrossRef]
- Tulino, A.M.; Verdu, S. Random Matrix Theory and Wireless Communications; Now Publishers Inc.: Hanover, MA, USA, 2004; Volume 1. [Google Scholar]
- Milne-Thomson, L.M. “Elliptic Integrals” (Chapter 17). In Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, 9th printing; Abramowitz, M., Stegun, I.A., Eds.; Dover Publications: New York, NY, USA, 1972; pp. 587–607. [Google Scholar]
- Behrens, R.T.; Scharf, L.L. Signal processing applications of oblique projection operators. IEEE Trans. Signal Process. 1994, 42, 1413–1424. [Google Scholar] [CrossRef]
- Pajor, A.; Pastur, L.A. On the Limiting Empirical Measure of the sum of rank one matrices with log-concave distribution. Stud. Math. 2009, 195, 11–29. [Google Scholar] [CrossRef]
- Ambainis, A.; Harrow, A.W.; Hastings, M.B. Random matrix theory: Extending random matrix theory to mixtures of random product states. Commun. Math. Phys. 2012, 310, 25–74. [Google Scholar] [CrossRef]
Figure 1.
Canonical Polyadic Decomposition (CPD).
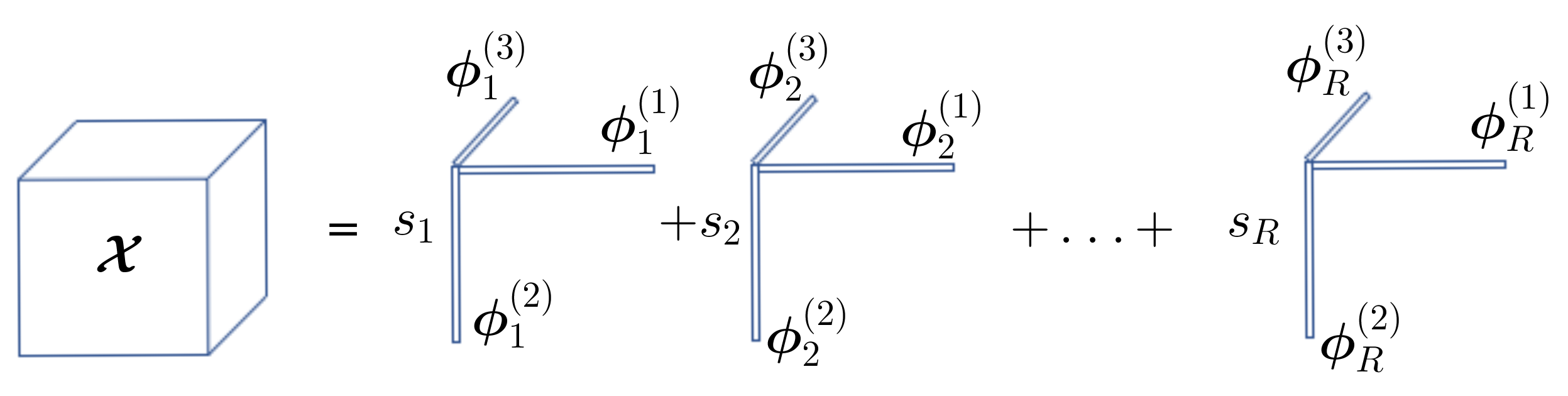
Figure 2.
Histogram of the eigenvalues of (with , ).
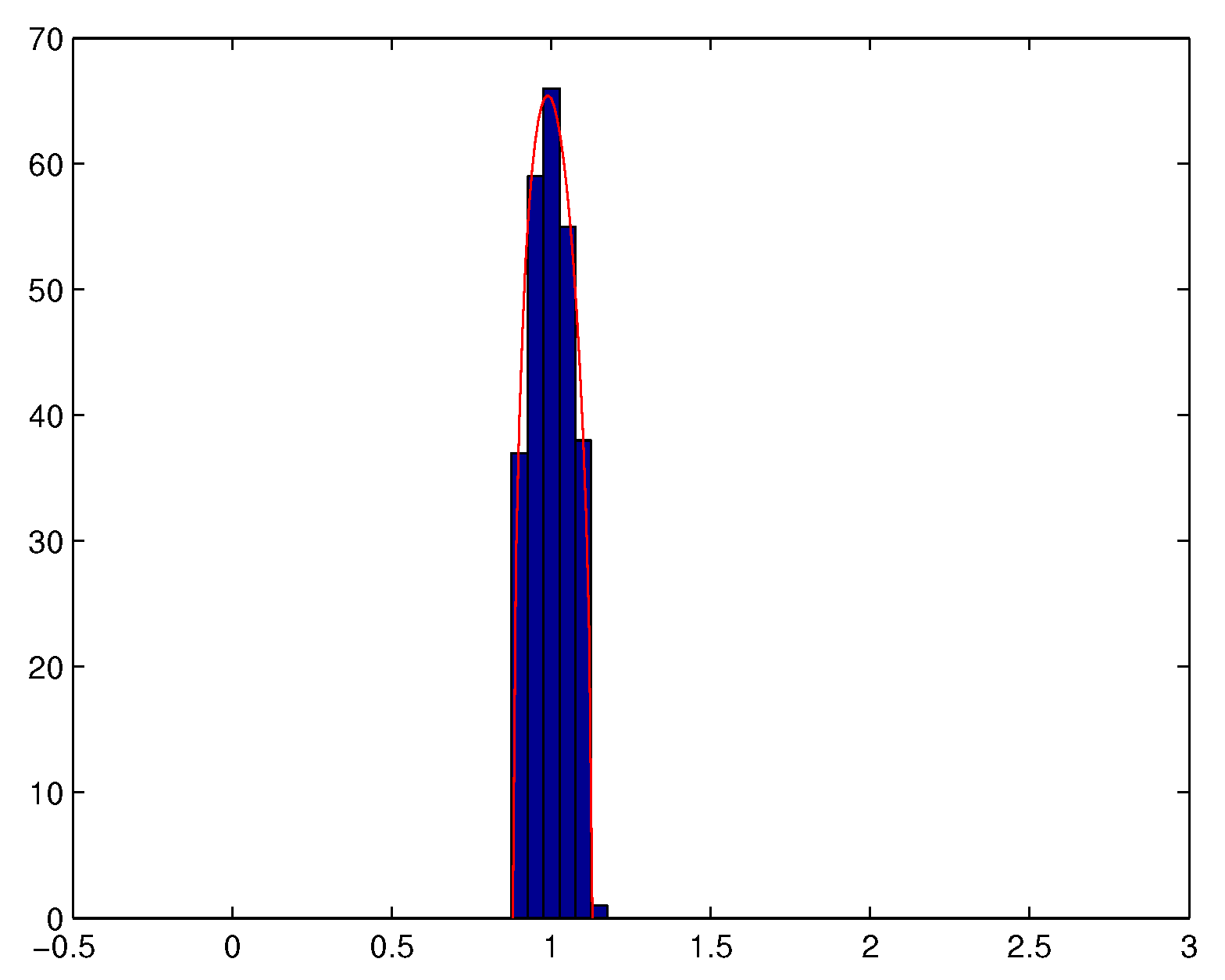
Figure 3.
Histogram of the eigenvalues of (with , ).
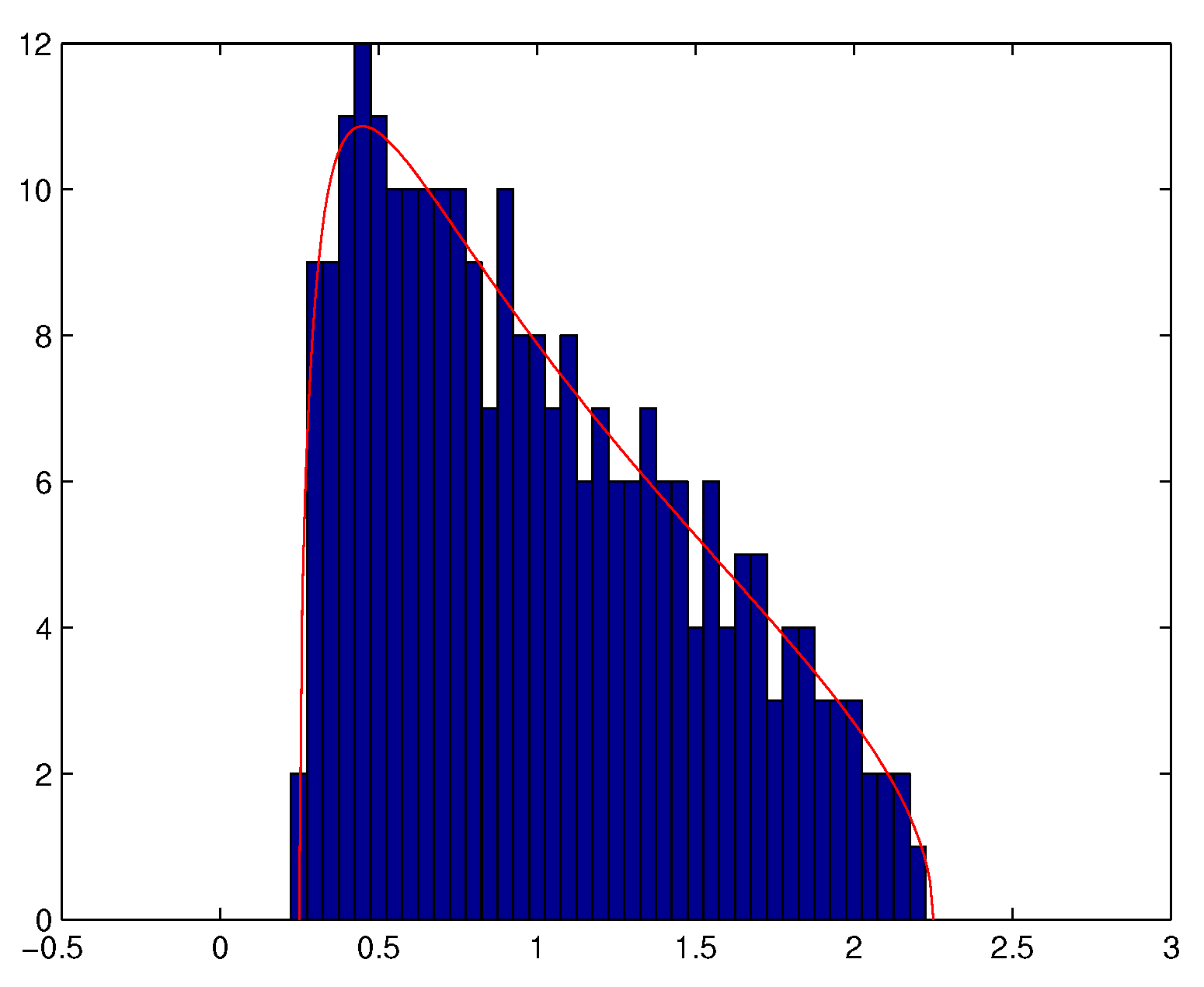
Figure 4.
Canonical Polyadic Decomposition (CPD) scenario: Optimal s-parameter versus Signal to Noise Ratio (SNR) in dB.
Figure 4.
Canonical Polyadic Decomposition (CPD) scenario: Optimal s-parameter versus Signal to Noise Ratio (SNR) in dB.
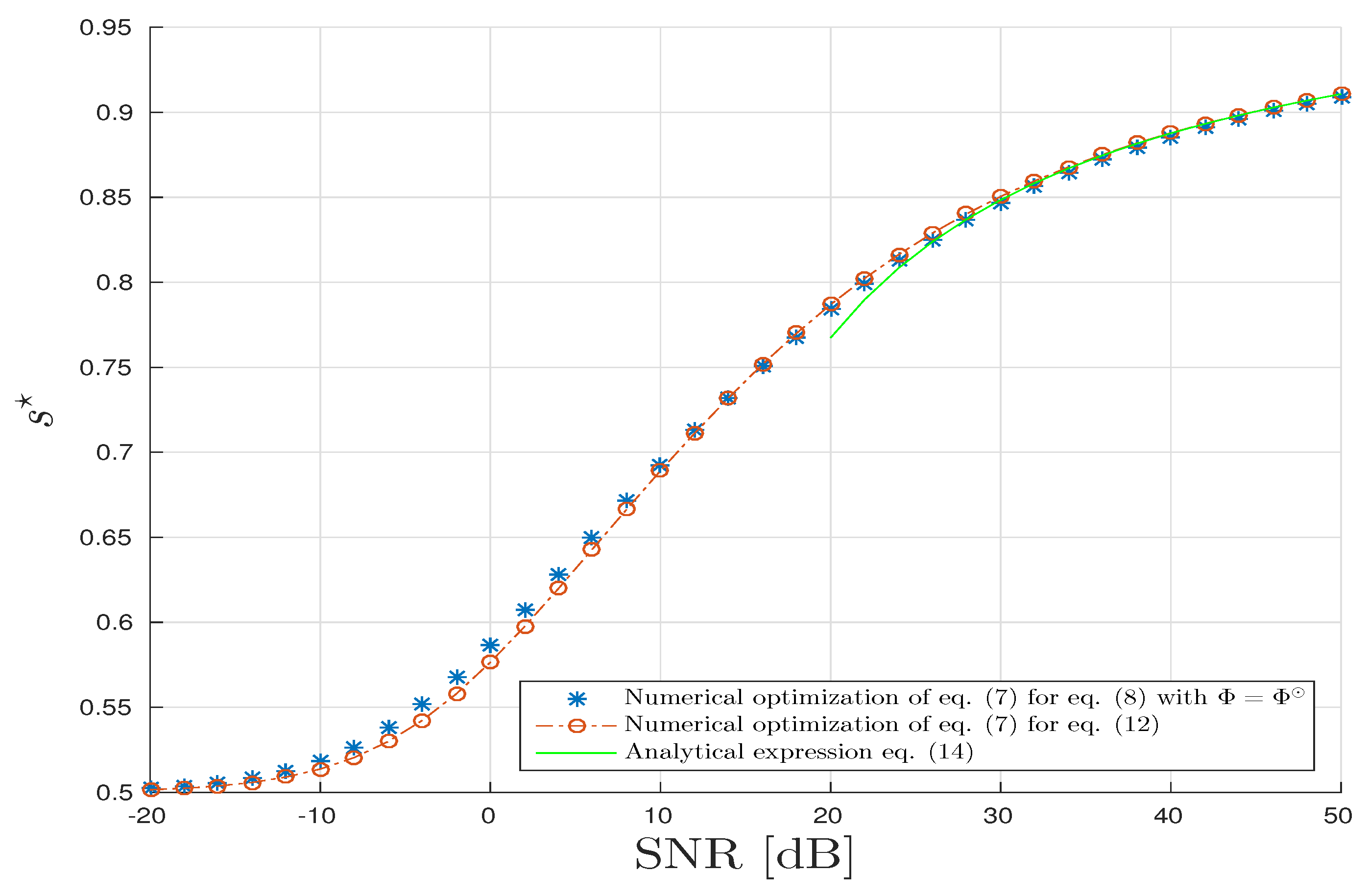
Figure 5.
CPD scenario: s-divergence vs. in dB.

Figure 6.
CPD scenario: vs. c , dB.

Figure 7.
TucKer Decomposition (TKD) scenario: Optimal s-parameter vs. in dB.
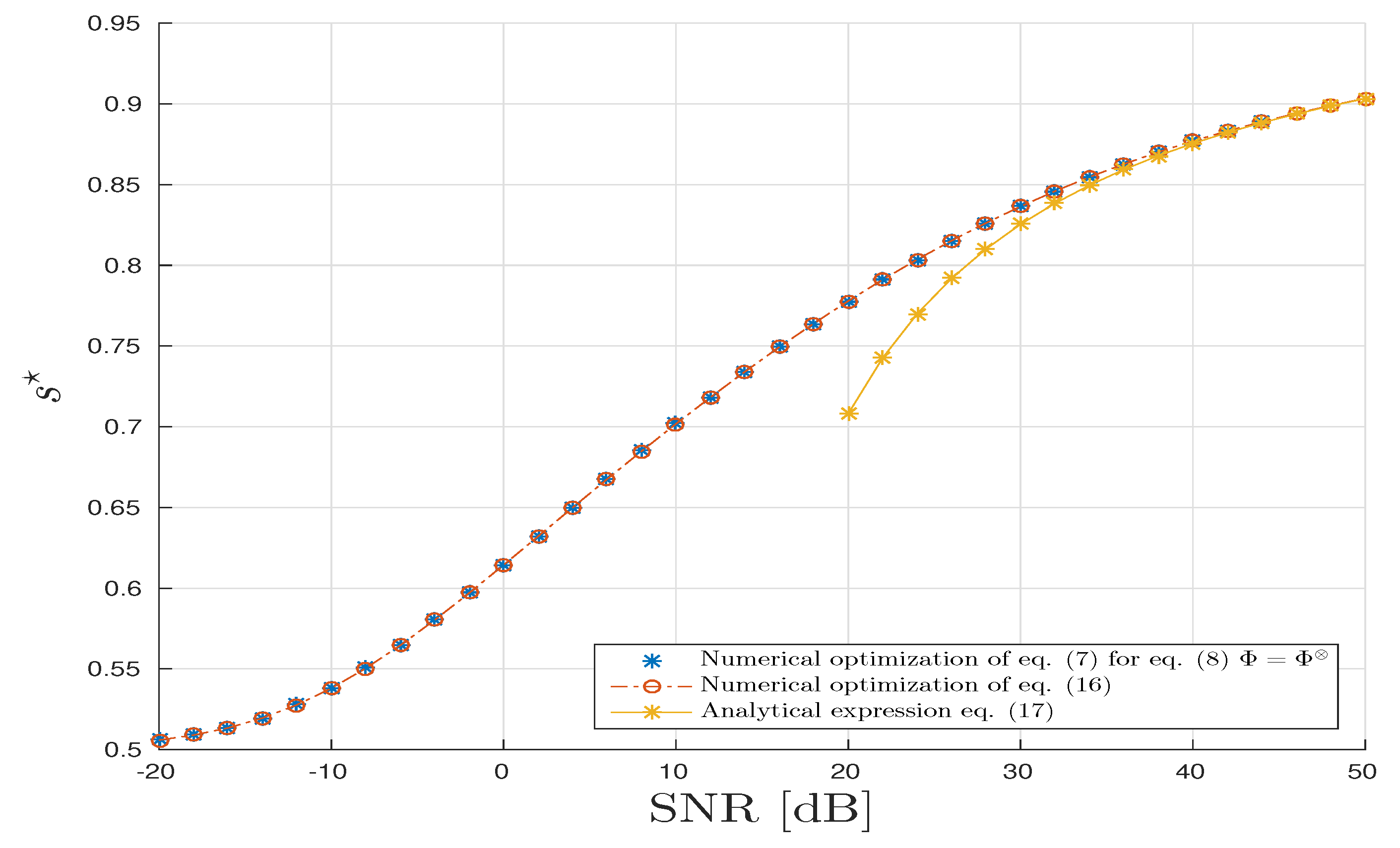
Figure 8.
TKD scenario: s-divergence vs. in dB.
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pham, G.-T.; Boyer, R.; Nielsen, F. Computational Information Geometry for Binary Classification of High-Dimensional Random Tensors. Entropy 2018, 20, 203. https://doi.org/10.3390/e20030203
AMA Style
Pham G-T, Boyer R, Nielsen F. Computational Information Geometry for Binary Classification of High-Dimensional Random Tensors. Entropy. 2018; 20(3):203. https://doi.org/10.3390/e20030203
Chicago/Turabian StylePham, Gia-Thuy, Rémy Boyer, and Frank Nielsen. 2018. "Computational Information Geometry for Binary Classification of High-Dimensional Random Tensors" Entropy 20, no. 3: 203. https://doi.org/10.3390/e20030203
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.