Abstract
A recently proposed product quantization method is efficient for large scale approximate nearest neighbor search, however, its performance on unstructured vectors is limited. This paper introduces residual vector quantization based approaches that are appropriate for unstructured vectors. Database vectors are quantized by residual vector quantizer. The reproductions are represented by short codes composed of their quantization indices. Euclidean distance between query vector and database vector is approximated by asymmetric distance, i.e., the distance between the query vector and the reproduction of the database vector. An efficient exhaustive search approach is proposed by fast computing the asymmetric distance. A straight forward non-exhaustive search approach is proposed for large scale search. Our approaches are compared to two state-of-the-art methods, spectral hashing and product quantization, on both structured and unstructured datasets. Results show that our approaches obtain the best results in terms of the trade-off between search quality and memory usage.1. Introduction
Approximate nearest neighbor search (ANN) is proposed to tackle the curse of the dimensionality problem [1,2] in exact nearest neighbor (NN) searching. The key idea is to find the nearest neighbor with high probability. ANN is a fundamental primitive in computer vision applications such as keypoint matching, object retrieval, image classification and scene recognition [3]. In many computer vision applications, the data-points are high-dimensional vectors that are embedded in Euclidean space, and the memory usage for storing and searching high-dimensional vectors is a key criterion for problems involving large amount of data.
The state-of-the-art approaches such as tree-based methods (e.g., KD-tree [4], hierarchical k-means (HKM) [5], FLANN [6]) and hash-based methods (e.g., Exact Euclidean Locality-Sensitive Hashing (E2LSH) [7,8]) involve indexing structures to improve the performance. The memory usage of indexing structure may even be higher than the original data when processing large scale data. Moreover, FLANN and E2LSH need a final re-ranking based on exact Euclidean distance, which means the original vector should be stored in main memory, this requirement seriously limits the databases’ scale. Binary index methods such as [9–11] simplify the indexing structure by using binary code to index the space partitions. However, these methods also need the original vector for final re-ranking.
Recently proposed hamming embedding methods compress the vectors into short codes and approximate the Euclidiean distance between two vectors by the hamming distance between their codes. These methods include hamming embedding [12], miniBOF [13], small hashing code [14], small binary code [15] and spectral hashing [16]. These methods make it possible to store large scale data in main memory. One weakness of these methods is the discrimination limitation of hamming distance as the total number of possible hamming distance is limited by code length. [17] introduced product quantization to compress the vector into several bytes and proposed a more accurate distance approximation. However, its search quality is limited on unstructured vector data.
Objectives of the paper are comparable to those of [16,17]: (1) storing millions of high-dimensional vectors in memory and (2) quickly finding similar vectors to a target vector. In contrast with product quantization, we focus on the performance for unstructured vector data. We introduce residual vector quantization, which is appropriate for unstructured data, for the vector encoding. An efficient exhaustive search method is proposed based on fast distance computing. A non-exhaustive search method is proposed to improve the efficiency for large scale search. Our approaches are compared to two state-of-the-art methods, spectral hashing and product quantization, on both structured and unstructured datasets. Results show that our approaches obtain the best results in terms of accuracy and speed.
Our paper is organized as follows: Section 2 presents the residual vector quantization and Section 3 introduces our exhaustive and non-exhaustive search methods that are based on the residual vector quantization. Section 4 evaluates the search performance and compares our approaches with two state-of-the-art methods. Section 5 discusses the results and Section 6 is the conclusion.
2. Residual Vector Quantization
A K-point vector quantizerQ maps a vector x∈RD into its nearest centroidin codebook C = {ci, i = 1..K} ⊂ RD:
The performance of quantizer Q is measured by mean squared error (MSE):
Residual vector quantization [19,20] is a common technique to reduce the quantization error with several low complexity quantizers. Residual vector quantization approximate the quantization error by another quantizer instead of discard it. Several stage-quantizers, each has its corresponding stage-codebook, are connected sequentially. Each stage-quantizer approximates preceding stage’s residual vector by one of centroids in the stage-codebook and generates a new residual vector for succeeding quantization stage. Block diagrams of a two stages residual vector quantization are shown in Figure 1. In the learning phase (Figure 1(a)), a training vector set X is provided and the first stage-codebook C1 is generated by k-means clustering method. The entire training set is then quantized by the first stage-quantizer Q1 which is defined by C1. The difference between X and its first stage quantization outputs, which is the first residual vector set E1, is used for learning the second stage-codebook C2. In quantizing phase (Figure 1(b)), the input vector x is quantized by first stage-quantizer Q1, which is defined by first stage-codebook C1. The difference between x and its first stage quantization output, which is the first residual vector ɛ1, is quantized by second stage-quantizer Q2. The second residual vector ɛ2 is discarded. The first two quantization outputs are used to approximate the input vector:

For L stages residual vector quantization, a vector x is approximated by the sum of its L stages’ quantization outputs while the last stage’s quantization error is discarded:
The quantization performance of ith stage-quantizer is:
Considering the optimization problem of finding a vector y to minimize the objection function:
By differentiating the objection function J with respect to y and setting derivative equal to zero, it is easy to obtain the minimizing y:
With the observations that and , we obtain the inequality:
3. Using Residual Vector Quantization for ANN
3.1. Exhaustive Search by Fast Distance Computation
In [17] the exact Euclidean distance between two vectors is approximated by asymmetric distance, i.e., the distance between a vector and a reproduction of another vector:
Asymmetric distance reduces the quantization noise and improves the search quality [17]. We have proposed fast asymmetric distance computation based on residual vector quantization. Suppose a database vector y is quantized by L × K residual vector quantizer, its indices of quantization output are {uj, 1 ≤ uj ≤ K, j =1..L}, and the reproduction of y is constructed by the sum of corresponding centroids:
The squared asymmetric distance can then be efficiently estimated by several table lookups:
If we only consider the order of distance, term ||x|| is a constant for all database vector and can be ignored in asymmetric distance computation. R nearest neighbors are selected based on the estimated squared asymmetric distances.
3.2. Non-Exhaustive Search by Rough Approximation
Exhaustive search has to scan quantization codes of all database vectors. In problems such as bag-of-features-based large scale image retrieval, billions of images are represented by hundreds of local feature vectors per image, and it is prohibitive to scan the feature vector database, even with fast asymmetric distance computation.
In [17] the authors proposed a non-exhaustive search method for large scale datasets. A coarse quantizer is involved to filter out farther database vectors, and then a product quantizer is used for fine search. In contrast with using an external coarse quantizer, we propose a straight forward non-exhaustive search approach based on the approximating sequence of database vector y that is generated by residual vector quantization:
Our exhaustive search approach uses only the most accurate item ỹ(L) to approximate the y. In non-exhaustive search, the first L1 quantization outputs generate a rough approximation:
The rough asymmetric distances between database vectors and the target vector are then evaluated by table lookups for coarse search:
The database vectors which have large rough distances are pruned and the remaining database vectors are used to evaluate more accurate distances to the target vector by their most accurate approximations as in Equation (13).
The total number of possible rough approximations is KL1, thus an inverted file system is used to improve the search performance. Each inverted list corresponds to a possible rough approximation. When encoding database vectors by L × K residual vector quantization, each vector’s first L1 indices are used to determine which inverted list it should be inserted in, then the L1 indices are discarded and only the last L2 = L − L1 indices and its vector id are stored in the inverted list. A query vector first evaluated its distances to the KL1 possible rough approximations by Equation (18). The W nearest rough approximations are selected and corresponding W inverted lists are scanned to evaluate more accurate distance to query vector:
Equation (19) shows the squared asymmetric distances which are computed in fine search can be updated by squared rough distance in the coarse search and only L2 table lookups per vector are involved. The term ||ỹ(L)||2 – ||ỹ(L1)||2 is pre-calculated and stored in offline quantization stage. By fast table lookups and distance update scheme, both coarse and fine search are efficient. R nearest neighbors are selected based on the squared asymmetric distances that are estimated in fine search.
4. Experiments and Results
4.1. Dataset
Three public available datasets were used to evaluate the performances of ANN methods: the structured SIFT descriptor dataset [21], semi-structured GIST descriptor dataset [21] and unstructured VLAD descriptor dataset [22]. SIFT descriptor codes small image patch while GIST descriptor and VLAD descriptor code entire image. SIFT descriptor is a histogram of oriented gradients that extracted from gray image patch. GIST descriptor is similar to SIFT applied to the entire image. It applies an oriented Gabor filter over different scales and averages the filter energy in each bin. The VLAD descriptor is constructed by first aggregating images’ SIFT descriptors’ quantization residual vectors locally and then reducing their dimensions by PCA.
The SIFT dataset and GIST dataset have three subsets: learning set, database set, and query set. The learning set is used for learning the model and evaluating quantization performance, the database and query sets are used for evaluating ANN search performance. For the SIFT dataset, the learning set is extracted from Flicker images [12] and the database and query descriptors are from INRIA Holidays images [23]. For GIST, the learning set consists of a subset of the tiny image set of [24]. The database set is the Holidays image set combined with Flicker1M used in [12]. The query vectors are from the Holidays image queries [23]. VLAD dataset is generated by public package and public local image descriptors [22] which are extracted from Holiday image dataset [23]. The dataset has 1,491 128-dimensional vectors and was divided into 500 groups. The first descriptor of each group is the query image and the correct retrieval results are the other images of the group. Total vectors in dataset are used as training set and database set. All these descriptors are high-dimensional float vectors. Scales of these datasets are summarized in Table 1.

4.2. Quantization Performance
This section investigates the quantization performance of our approach by evaluating the influence of parameters over quantization error. K is the number of centroids of stage-quantizer, L is the total number of stage-quantizers. The code length, i.e., L log2 K, is regarded as a metric of storage.
Figure 2 shows the trade-offs between quantization accuracy and memory. It is clear that the quantization error is reduced by increase either K or L. For a fixed number of bits, the residual vector quantizer which has fewer stage-codebooks and more centroids in each stage-codebook is more accurate than the residual vector quantizer which has more stage-codebooks and fewer centroids in each stage-codebook.
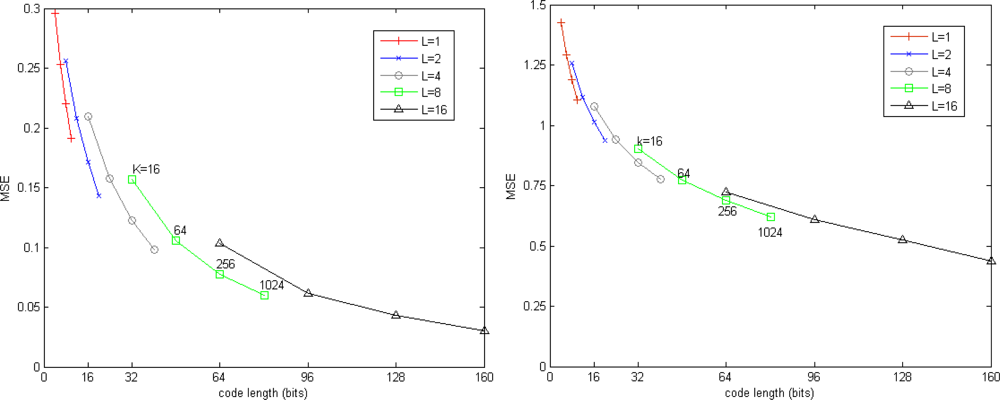
4.3. Parameters’ Influences on Search Accuracy
The performances of our approaches are measured by two metrics: recall@R and ratio of distance errors (RDE). Recall@R is defined in [17] as the proportion of query vectors for which the nearest neighbor is randked in the first R positions. Values of recall@R close to 1 indicate high quality of search results. RDE [11] is defined as:
Figure 3 and 4 show the performance of our exhaustive search method. Figure 3 shows the trade-off between recall@R and code length for SIFT and GIST datasets. When the code length is fixed, the residual vector quantizer which has fewer codebooks and more centroids in each codebook is more accurate than the residual vector quantizer which has more codebooks and fewer centroids in each codebook. It seems a good choice to use 8 × 256 residual vector quantization for SIFT descriptor and 16 × 256 residual vector quantization for GIST descriptor.
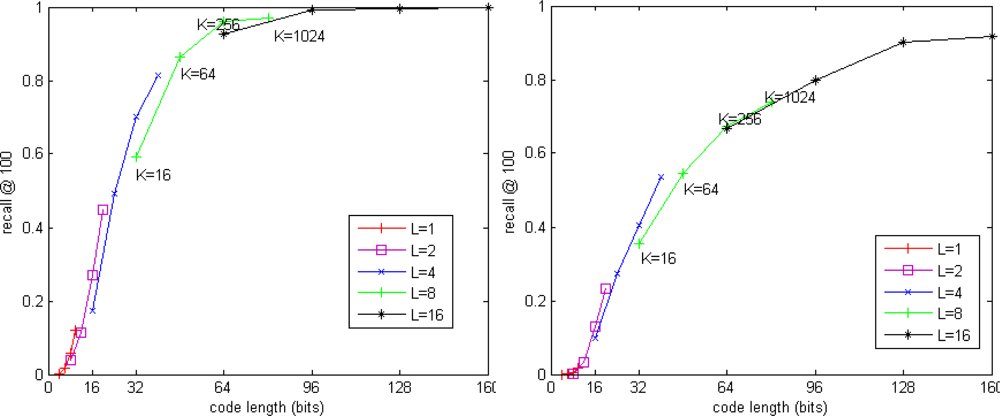
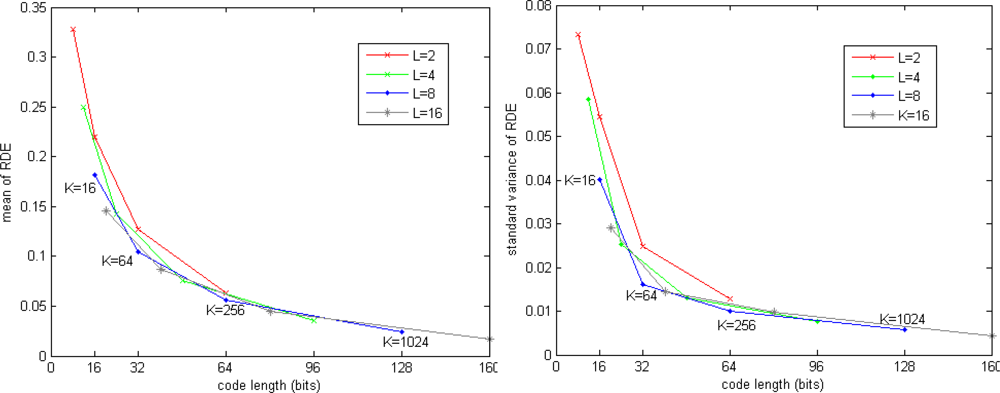
Figure 4 shows the RDE for SIFT dataset. The mean of RDE is tending to 0 when increasing code length. The standard variance of RDE is also significant reduced when increasing code length, which means the query results are more stable when more bits are used to encode the vectors.
Figure 5 shows impact of the parameters for our non-exhaustive search method. K = 256, L1 ∈ {1,2} and L2 ∈ {1,2,4,8,16} are the numbers of stage-quantizers used for coarse search and fine search, W is the number of candidate inverted lists for fine search. The total number of inverted lists is KL1. The code length L2 log2 K is regarded as a metric of storage. Results of our exhaustive search method are also plotted in dash line for comparison. For simplicity, our exhaustive search and non-exhaustive search methods are respectively denoted as RVQ and IVFRVQ. We observed that the performance of IVFRVQ strongly depends on W which determines the fraction of inverted lists that are scanned. When a small fraction of inverted lists are scanned, increasing the code length is useless for improving the performance. When sufficient inverted lists are scanned, performance of IVFRVQ is comparable to even better than RVQ.
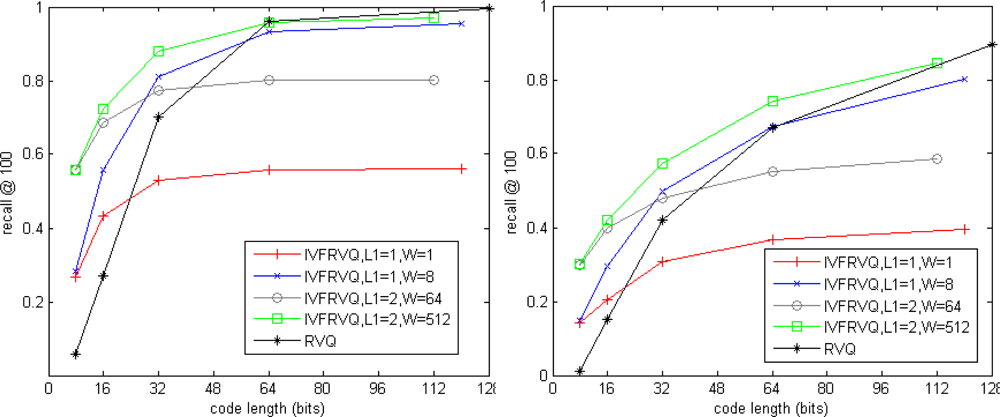
Tables 2 and 3 show comparisons of search efficiency. Both RVQ and IVFRVQ encode the vector into 64-bit code. It is clear that the pruning strategy significantly reduces the search time. It is noticed that it has to increase the W for search accuracy when L1 = 2, but the frequent inverted lists access reduces the search performance.
4.4. Compared with the State of the Art
In this section we compare our approach with two state-of-the-art methods: spectral hashing (SH) and product quantization. The performance of product quantization is sensitive to the grouping order of vector components. The natural product quantization groups the consecutive components while the structured product quantization groups related components together based on the prior knowledge of vector’s structure. Experimental results in [17] show that the natural product quantization is appropriate for SIFT descriptor while the structured product quantization is appropriate for GIST descriptor. For simplicity, the natural product quantization method is denoted as PQ while the structured product quantization method is denoted as PQ*, their non-exhaustive version are denoted as IVFPQ and IVFPQ* respectively. Vectors are compressed into 64-bit binary codes. Eight 256-point quantizers are used for PQ and a 1024-point quantizer is used as the coarse quantizer for IVFPQ. We use L = 8, K = 256 for RVQ and L1 = 1, L2 = 8, K = 256 for IVFRVQ.
Figure 6 compares the search qualities on SIFT and GIST datasets. On the benchmark SIFT, our approaches significantly outperform spectral hashing and are slightly better than product quantization methods. On the benchmark GIST, our approaches significantly outperform spectral hashing and natural product quantization methods and are comparable to structured product quantization methods.
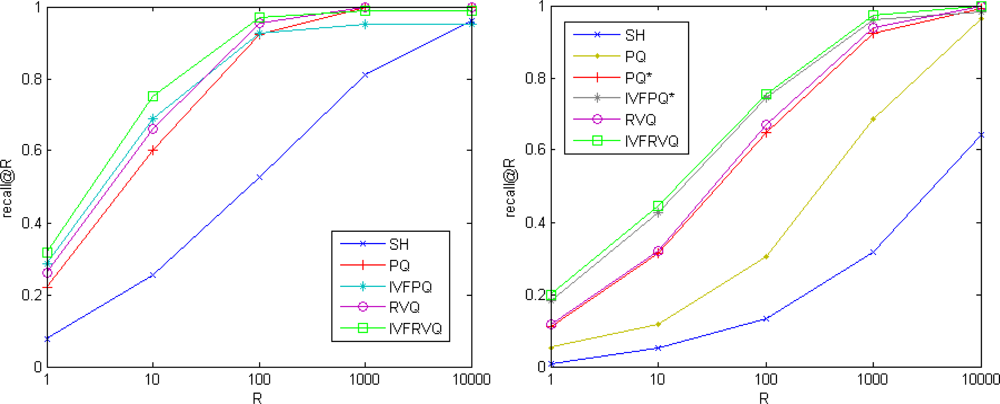
The VLAD dataset is used for evaluating the accuracy of ANN methods on unstructured vectors. The performance is measured by mean average precision (mAP) [22] which is defined as the area of recall-precision curve, a larger value of mAP indicate a better retrieval performance. Table 4 shows the accuracies obtained by different methods (spectral hashing, product quantization and our approach) and different code length configurations (32 bits, 64 bits, 128 bits). Both product quantizer and our residual vector quantizer are constructed by 256-point vector quantizer. The code length of spectral hashing is directly assigned while those of product quantization and our approach are controlled by the number of quantizers. We use a 1024-point quantizer as the coarse quantizer for IVFPQ. We only test the 32-bit and 64-bit configurations for our approaches because the stage-quantization errors are too small to be handled by our single precision implementation when 16 stage-quantizers are used. It is clear that our approach is significant outperform spectral hashing and product quantization. Equivalently, our method obtains a comparable search quality with only half the code length of product quantization.
4.5. Speed Comparison
Table 5 compares the search time of different methods on the SIFT dataset. Spectral hashing and product quantization use the public available Matlab packages. Our approaches are implemented in Matlab. Both the hamming distance computation for spectral hashing and the asymmetric distance computation for product quantization and our approaches are optimized by C. All methods compress SIFT descriptors 64-bit binary code. The time is measured on a 2.2 GHz CPU laptop with 3 GB of RAM. The approaches RVQ, PQ and SH have similar rum times because they all scan the whole database and compute the distances by table lookups. Non-exhaustive search methods significant improve the performance. IVFRVQ is more efficient than IVFPQ for equal search accuracy because IVFPQ calculates W look-up tables for individual candidate inverted list while IVFRVQ only calculates one look-up table.
5. Discussion
5.1. Advantages of Residual Vector Quantization
The advantage of residual vector quantization is quantizing the whole vector in original space. Product quantization is based on the assumption that the subspaces are statistically mutual independent such that the original space can be represented by the production of these subspaces. But vectors in real data do not all meet that assumption. Moreover, the vector’s structure determines the quantization parameters and makes product quantization inflexible. In contrast, residual vector quantization processes the whole vector in original space, and the parameters are not limited by the structure of vector.
5.2. Link between Residual Vector Quantization and Hierarchical k-means
Residual vector quantization can be regarded as a simplified hierarchical k-means (HKM). When generating a new quantization level, HKM performs k-means clustering in each previous level’s cluster and generate a new partition for each previous level’s cluster. In contrast, residual vector quantization generates a global partition and then embeds it into each previous level’s cluster. It is similar to the hamming embedding (HE) method, while HE involves two levels and uses the orthogonal partition in each cluster. The simplified structure makes it possible to have more quantization levels and each level have more centroids for fine division of space. The method that transforming tree-like structure to flat structure, which has been used in ferns classifier [25], significant reduces the complexity of index structure while maintaining a fine-grained division of space.
5.3. Complexity
Processing vectors in original high dimensional space causes negative implications for complexity. Operations such as finding the nearest centroid or generating residual vectors are performed in high dimensional space while product quantization process subvectors in the low dimensional subspace. The memory usage of codebook is negligible when compared to the memory occupied by a codeddatabase. The complexity of look-up table computation is also negligible when compared with the complexity of scanning the database’s codes. The drawback is the computational complexities of learning and quantization stage of residual vector quantization are linear times of the complexities of product quantization. Our feature work will focus on reducing the complexities of learning and quantization stage.
6. Conclusions
We have introduced residual vector quantization for approximate nearest neighbor search. Two efficient search approaches are proposed based on residual vector quantization. The non-exhaustive search method significantly improves the performance. We evaluate the performance on two structured datasets and one unstructured dataset, and compare our approaches with spectral hashing and product quantization. Our approaches obtain the best results in terms of the trade-off between accuracy, speed and memory usage. Results on structured datasets show our approaches slightly outperform product quantization. For unstructured data, our approaches significant outperform the product quantization.
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments. This research is supported by the National Natural Science Foundation of China (NSFC) under Grant No. 60903095 and by the Postdoctoral Science Foundation Funded Project of China under Grant No. 20080440941.
References
- Beyer, K; Goldstein, J; Ramakrishnan, R; Shaft, U. When is “nearest neighbor” meaningful? Proceedings of Database Theory—ICDT’99, Jerusalem, Israel, January 1999; pp. 217–235.
- Böhm, C; Berchtold, S; Keim, D. Searching in high-dimensional spaces: Index structures for improving the performance of multimedia databases. ACM Comput. Surv. (CSUR) 2001, 33, 322–373. [Google Scholar]
- Duan, LY; Guan, T; Yang, B. Registration combining wide and narrow baseline feature tracking techniques for markerless AR systems. Sensors 2009, 9, 10097–10116. [Google Scholar]
- Silpa-Anan, C; Hartley, R; Machines, S; Canberra, A. Optimised KD-trees for fast image descriptor matching. Proceedings of IEEE CVPR 2008, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Nister, D; Stewenius, H. Scalable recognition with a vocabulary tree. Proceedings of IEEE CVPR 2006, New York, NY, USA, 17–22 June 2006; pp. 2161–2168.
- Muja, M; Lowe, DG. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration; Insticc-Inst Syst Technologies Information Control & Communication: Setubal, Portugal, 2009; pp. 331–340. [Google Scholar]
- Datar, M; Immorlica, N; Indyk, P; Mirrokni, V. Locality-sensitive hashing scheme based on p-stable distributions. Proceedings of 20th Annual ACM Symposium on Computational Geometery, New York, NY, USA, June 2004; pp. 253–262.
- Shakhnarovich, G; Darrell, T; Indyk, P. Nearest-Neighbor Methods in Learning and Vision: Theory and Practice; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Weber, R; Schek, H; Blott, S. A quantitative analysis and performance study for similarity—search methods in high-dimensional spaces. Proceedings of 24th VLDB Conference, New York, NY, USA, 24–27 August 1998; pp. 194–205.
- Koudas, N; Ooi, B; Shen, H; Tung, A. LDC: Enabling search by partial distance in a hyper-dimensional space. Proceedings of ICDE 2004, Boston, MA, USA, 30 March–2 April 2004; pp. 6–17.
- Cui, B; Shen, H; Shen, J; Tan, K. Exploring bit-difference for approximate KNN search in high-dimensional databases. Proceedings of ADC 2005, Newcastle, Australia, 31 January–3 February 2005; pp. 165–174.
- Jegou, H; Douze, M; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. Proceedings of Computer Vision—ECCV 2008, Marseille, France, 12–18 October 2008; pp. 304–317.
- Jégou, H; Douze, M; Schmid, C. Packing bag-of-feature. Proceedings of ICCV’09, Kyoto, Japan, 29 September–2 October 2009; pp. 2357–2364.
- Wang, B; Li, Z; Li, M; Ma, W. Large-scale duplicate detection for web image search. Proceedings of IEEE ICME 2006, Toronto, Canada, 9–12 July 2006; pp. 353–356.
- Torralba, A; Fergus, R; Weiss, Y. Small codes and large image databases for recognition. Proceedings of IEEE CVPR 2008, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Weiss, Y; Torralba, A; Fergus, R. Spectral hashing. Adv Neural Inf Process Syst 2009, 21, 1753–1760. [Google Scholar]
- Jégou, H; Douze, M; Schmid, C. Product quantization for nearest neighbor search. IEEE Trans. Patt. Anal. Mach. Int. in press.
- Jegou, H; Douze, M; Schmid, C; Perez, P. Aggregating local descriptors into a compact image representation. Proceedings of IEEE Conference on Computer Vision & Pattern Recognition 2010, San Francisco, CA, USA, 13–18 June 2010.
- Juang, BH; Gray, AH. Multiple stage vector quantization for speech coding. Proceedings of IEEE International Conference on Acoustics, Speech, and Singal Processing, Paris, France, April 1982; pp. 597–600.
- Gray, R; Neuhoff, D. Quantization. IEEE Trans InformTheory 1998, 44, 2325–2383. [Google Scholar]
- The ANN Evaluation Dataset, Available online: http://www.irisa.fr/texmex/people/jegou/ann.php (accessed on 19 June 2010).
- Matlab Package of Aggregating Local Descriptors into a Compact Representation, Available online: http://www.irisa.fr/texmex/people/jegou/src/compactimgcodes/index.php (accessed on 25 August 2010).
- The INRIA Holidays Dataset, Available online: http://lear.inrialpes.fr/people/jegou/data.php#holidays (accessed on 27 July 2010).
- Torralba, A; Fergus, F; Freeman, WT. 80 million tiny images: A large database for non-parametric object and scene recognition. IEEE Trans Patt Anal Mach Int 2008, 30, 1958–1970. [Google Scholar]
- Ozuysal, M; Fua, P; Lepetit, V. Fast keypoint recognition in ten lines of code. Proceedings of CVPR 2007, Minneapolis, MN, USA, 18–23 June 2007.
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).