Categorization of Indoor Places Using the Kinect Sensor

Abstract
: The categorization of places in indoor environments is an important capability for service robots working and interacting with humans. In this paper we present a method to categorize different areas in indoor environments using a mobile robot equipped with a Kinect camera. Our approach transforms depth and grey scale images taken at each place into histograms of local binary patterns (LBPs) whose dimensionality is further reduced following a uniform criterion. The histograms are then combined into a single feature vector which is categorized using a supervised method. In this work we compare the performance of support vector machines and random forests as supervised classifiers. Finally, we apply our technique to distinguish five different place categories: corridors, laboratories, offices, kitchens, and study rooms. Experimental results show that we can categorize these places with high accuracy using our approach.
1. Introduction
An important capability for service robots working in indoor environments is their ability to categorize the different places where they are located. Place categorization has many applications in service robots. It is mainly used in semantic mapping, where acquired maps of the environment are extended with information about the type of each place allowing high level conceptual representations of environments [1–6]. In addition, the information about the type of a place can be used as prior or context information to improve the detection of objects [7, 8]. Moreover, whenever a robot has information about the type of a place, it can determine the possible actions to be carried out in that area [9–11].
In the task of place categorization a robot assigns a label to the place where it is located according to the information gathered with its sensors. The labels assigned by the robot to the different places are usually the same that people would use to refer to those places such as office, kitchen, or laboratory. In this way the communication with humans is improved [12, 13].
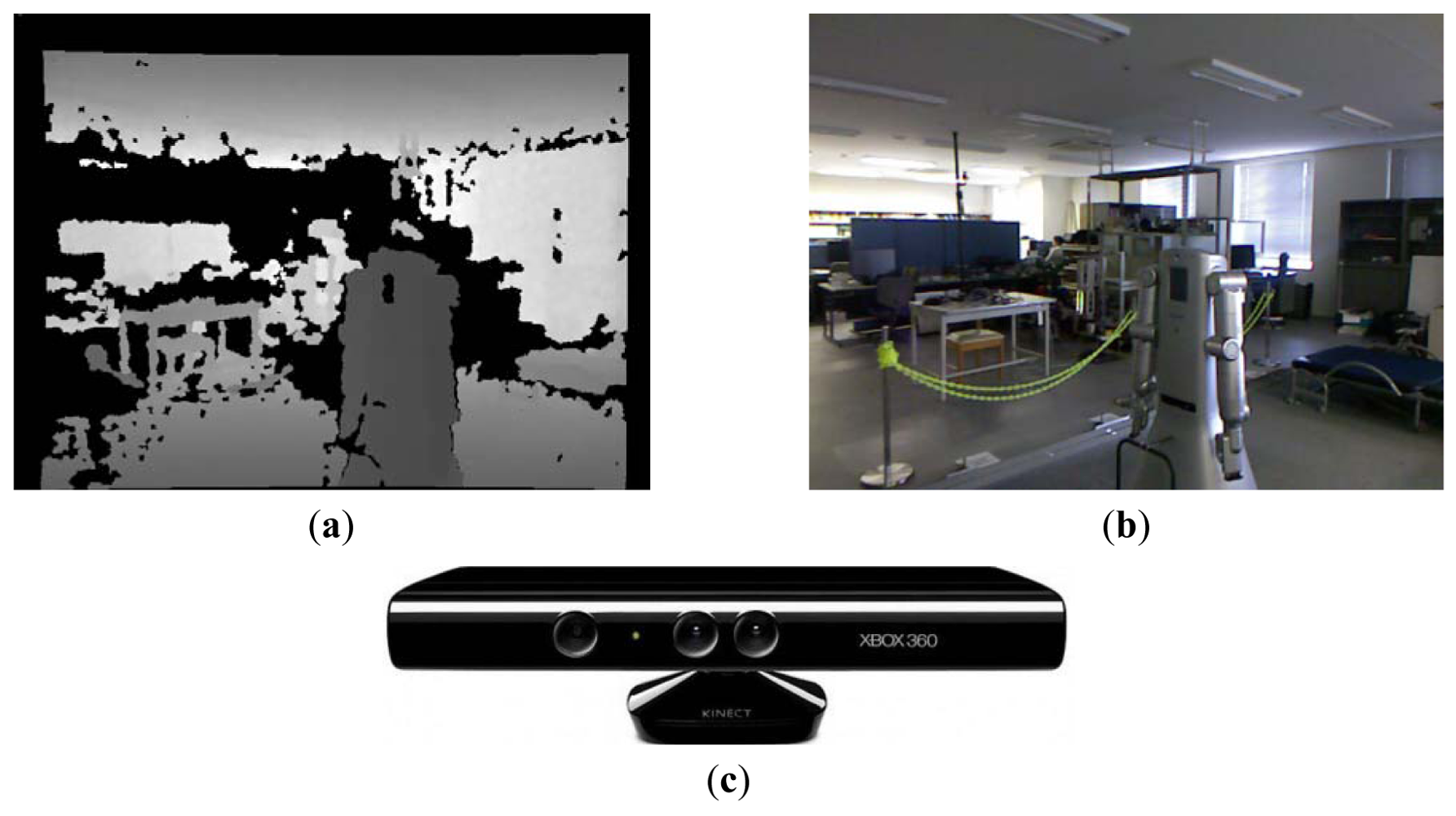
In this paper we present a new approach to categorize indoor places using a RGB-D sensor, in particular the Kinect camera [14]. The Kinect sensor is able to provide RGB and depth images simultaneously at high rates. Moreover, this sensor is getting popular in the robotics community due to its low cost. Figure 1 shows the Kinect sensor together with example depth and RGB images taken in a laboratory.
The main idea of our approach consists of transforming the image and depth information from the Kinect camera into feature vectors using histograms of local binary patterns (LBPs) whose dimensionality is reduced using a uniform criterion [15]. In order to obtain LBPs from RGB images they should first be transformed into grey scale images since the LBP operator ignores color information. The goal of this work is to distinguish categories of places, i.e., places with similar structural and spatial properties, and for this reason we have selected a descriptor that does not take color properties into consideration. Previous works on place categorization [16, 17] also support the premise of ignoring color information for general categorization of indoor places.
The final feature vectors are combined and used as input to a supervised classifier. In this paper we compare the perform ance of support vector machines (SVMs) [18] and random forests (RFs) [19] as classification methods. We apply our method to sequences of images corresponding to five different place categories namely corridors, laboratories, offices, kitchens, and study rooms, and obtain average correct classification rates above 92%. This result demonstrates that it is possible to categorize indoor places using a Kinect sensor with high accuracy. Finally, we show the improvement of our categorization approach when using both modalities simultaneously (depth and grey images) in comparison with single modalities.
The rest of the paper is organized as follows: after presenting related work in Section 2, we introduce the local binary pattern transformation for grey scale and depth images in Section 3. In Section 4 we describe the combined feature vector used to represent the grey scale and depth images corresponding to the same scene. The supervised classifiers used for the categorization are presented in Section 5. We introduce our dataset in Section 6. Finally, experimental results are presented in Section 7.
2. Related Work
The problem of place recognition by mobile robots has gained much attention during recent years. Some previous works use 2D laser scans to represent different places in the environment. For example, in [20] 2D scans obtained with a laser range finder are transformed into feature vectors representing their geometrical properties. These feature vectors are categorized into several places using Boosting. The work in [21] uses similar feature vectors to represent locations in a Voronoi Random Field. Moreover, in [22] sub-maps from indoor environments are obtained by clustering feature vectors representing the different 2D laser scans. Finally, the work in [23] introduces the classification of a single scan into different semantic labels instead of assigning a single label to the whole scan.
Vision sensors have also been applied to categorize places indoors using mobile robots. In [16] the CENTRIST descriptor is applied to images representing different rooms in several houses. The descriptors are later classified using support vector machines. Moreover, in the PLISS system for place categorization introduced in [17] images are represented by bag of words using the SIFT descriptor. Similar images are grouped together by locating change-points in the sequences. In [7] local and global features from images taken by a wearable camera are classified using a hidden Markov model.
Finally, combinations of different modalities have been also applied to robot place recognition. The work in [24] combines 2D laser scans with visual object detection to categorize places indoors. Moreover, in [25] multiple visual and laser-based cues are combined using support vector machines for recognizing places indoors.
In contrast to these works, we use the new Kinect sensor which has the advantage of simultaneously providing visual and depth information. We apply a combination of image and depth images which allows us to integrate richer information about the visual appearance and the 3D structure of each place.
3. Local Binary Patterns
The local binary pattern (LBP) operator introduced in [15, 26] has been originally used for analysis and classification of grey scale images. The LBP is a local transformation that contains the relations between pixel values in a neighborhood of a reference pixel. In the next sections we explain how to calculate the LBP transformation for the RGB and depth images obtained with the Kinect sensor.
3.1. LPB Transformation for RGB Images
To apply the LBP transformation to RGB images they should be converted first into grey scale images because LBPs ignore color information and work only with intensity values. Then for each pixel pi in the grey scale image we calculate the corresponding LBP value following the approach presented in [15]. In particular, given a pixel pi with image coordinates (xi, yi), we compare its value v(pi) with the values corresponding to the 8-neighboring pixels pj ∈ N8(pi). For each neighboring pixel pj we obtain a binary value bj ∈ {0, 1} indicating whether the value v(pi) of the reference pixel pi is bigger than the value v(pj) of the neighboring pixel pj as:
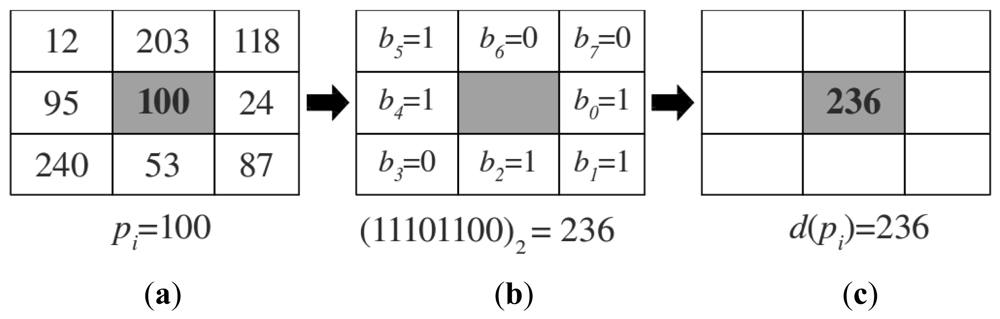
The binary values in the neighborhood are concatenated into a string in some specific order. In this work we use a clockwise order starting with the value v(ps) of the pixel which is on the right of the center pixel pi, that is, ps = (xi + 1, py). The obtained binary string is then converted into the corresponding decimal value d(pi) ∈ [0, 255]. An example of this process is shown in Figure 2. The final LBP is obtained after applying the previous transformation to every pixel in the image, obtaining a final transformed image Tgrey. Figure 3 (upper row) shows the result of applying the LBP transformation to a RGB image obtained with the Kinect camera.
The abovementioned LBP operator is equivalent to the LBP8,1 operator of [15] with the solely difference that we do not interpolate values at the diagonals. Moreover, it is equivalent to the Census Transform presented in [27].
3.2. LPB Transformation for Depth Images
Pixels in depth images provided by the Kinect sensor represent the distance of objects to the sensor (see Figure 1(a)). To obtain the LBP transformation of depth images we apply the same process as for grey images (Section 3.1) but using the depth values. However, since the Kinect camera has a limited working depth range, the pixels representing depth values outside this range appear as undefined values in the corresponding depth image. In addition, we obtain similar undefined values when the camera is pointing to reflective surfaces, or when the pixels represent positions close to the borders of objects. Examples of these cases are presented in Figure 1(a) where undefined pixels are shown in black. To integrate undefined pixels when calculating the LBP transformation we propose to extend the range of resulting decimal values with the extra value 256 to represent these undefined cases. In addition, when calculating the LBP value for a given pixel in the depth image we also take into account neighboring pixels with undefined values as follows. For a given pixel pi in the original depth image we assign it the decimal value 256 if its depth value is undefined or there exists some undefined value in its 8-neighborhood N8(pi). Otherwise we apply the standard LBP procedure of Section 3.1. Formally:
4. Multi-Modal Representation of Places
In our approach places are represented by depth and color images taken by a Kinect camera. In this section we explain how to combine both modalities to obtain a global feature vector which will be later categorized using different supervised methods.
The transformed images Tgrey and Tdepth obtained by following the steps of Section 3 are further represented by histograms Hgrey and Hdepth respectively. Each bin in these histograms contains the frequency of appearance of the different LBP transformed values. In the case of grey images the range of LBP transformed values d(pi) is [0, 255] and the corresponding histogram Hgrey contains 256 bins, one bin for each value. In the case of depth images the range of values d+(pi) is [0, 256] and the corresponding histogram Hdepth contains 257 bins (c.f. Section 3).
LBPs define local structures in images and histograms of LBPs represent the distribution in the scene of these local structures, and thus give a general representation of the images which in our case represent different place categories. Similar histograms may represent different places but these places should share a similar global structure. This is in fact an advantage in our approach since our objective is to classify places with similar global structure into the same category, e.g., different corridors should be include in the general category “corridor”, in the same way different offices should be detected as pertaining to the same category “office”. Histograms of local features have been successfully used in previous works to classify images into different place categories [16, 17, 28].
In our approach we further reduce the dimensionality of each histogram by selecting a subset of their LPBs using a uniformity measurement U introduced in [15] which indicates the number of transitions between 0/1 values of the binary representation of the decimal value d as:
As explained above LBPs represent local structure in the image (see Figure 2). Moreover, some of these local structures appear with different frequencies in different places, and also present different discriminative properties. In this paper we want to study the discriminative properties of these different local structures when they are applied to the problem of place categorization. For this purpose we use the uniformity measurement U to select different subsets of LBPs, i.e., different local structures. In the experiments we will see that the selection of subsets of LBPs according to the uniformity measurement U improves the categorization results. A side effect of this selection is the reduction on the dimensionality in the final feature vectors representing different place categories; however, as the experiments will demonstrate, this reduction improves the classification results. We think this is due to the elimination of LBPs containing poor discrimination properties for place categorization. For example, when the threshold θ is high we allow LBPs corresponding to local structures with many local changes that can correspond to noise, while low thresholds maintain only more defined local structures like for example corners or lines as in Figure 2(b).
Using the uniformity measurement U the final histograms are composed of the subsets of bins representing the selected LBPs as:
Finally, the multi-modal feature vector xθ describing a particular place is obtained by concatenating the reduced histograms corresponding to both modalities:
5. Classification
The multi-modal feature vector obtained in the previous section is used as input to a supervised method for categorization purposes. In this paper we compare two state-of-the-art classification methods: support vector machines, and random forests.
5.1. Support Vector Machines
The first supervised classification method is based on a support vector machine (SVM) [29, 30]. During the training phase, a support vector machine takes as input a set of N feature vectors xi together with their binary labels yi ∈ {1, −1}. The idea behind SVMs is to find the hyperplane that maximizes the distance between the examples of the two classes. This is done by finding a solution to the optimization problem:
In the test step new examples xt are labeled according to:
SVMs were originally designed to solve binary classification problems. In the case of multi-class classification different approaches can be used to manage several classes. In our case we apply the “one-against-one” approach [31] which implies to learn a SVM for each pair of categories, resulting in a total of k(k-1)/2 classifiers for k categories.
In our experiments we use the implementation given by the LIBSVM library [32]. Moreover, the parameters C and γ are selected by grid-search using cross-validation in the ranges C ∈ [2−5, …, 215] and γ ∈ [2−12, …, 23] as described in [33]. Finally, the input feature vectors are first normalized in the range [0, 1].
5.2. Random Forests
The second type of supervised classifier used in this work is the random forest [19]. The idea behind this classifier is to use M classification trees each of which assigns a label to the input vector x. The final label is obtained by a majority vote over the labels assigned by all trees.
In this approach, each tree is trained as follows. First, using the original training data with N feature vectors, a new training set is created by random sampling of N samples with replacement. Second, during the creation of each node in the tree a subset of l ≪ L features from the total feature vector x∈ℝL is randomly selected. Finally, the tree is constructed without pruning. In our approach we use the random forest implementation of WEKA [34] which is based on [19].
6. Place Dataset
To test our approach we have created a dataset of places by collecting data in different buildings at the University of Kyushu (this dataset is available at [35]). The dataset contains RGB and depth images acquired by a Kinect sensor which was mounted on a mobile platform at a height of 125 cm. We collected data from five different place categories: “corridor”, “kitchen”, “laboratory”, “office”, and “study room”. Each category contains RGB and depth images from several places that pertain to that category. For example the category “laboratory” contains data from four different laboratories. In each place we obtained one sequence of images while controlling the platform manually. The trajectory at each place has a different length and thus contains a different number of images. Table 1 presents a summary of the information contained in the dataset. For obtaining the place data we used the Robot Operating System framework (ROS) on a laptop equipped with an Intel core i5. In our experiments we simultaneously recorded depth images, 3D point clouds and RGB images. Since the Kinect camera does not provide hardware synchronization of RGB and depth images, we use the closest timestamp to match images of both modalities. The elapsed times between depth and RGB images ranged between 5 ms and 10 ms. Examples of RGB and depth images for each place in our dataset are shown in Figure 4.
7. Experiments
To evaluate the performance of our approach we conducted several experiments using our dataset of places. To create the different test and training sets for the experiments we applied the following procedure. Each test set was created by randomly selecting one place from each category, i.e., each test set contains always five sequences of grey scale and depth images each of which corresponds to one category. Example test sets are {corridor 1, kitchen 2, laboratory 4, study room 1, office 2} or {corridor 2, kitchen 2, laboratory 3, study room 2, office 2}. The rest of places are used as training data. The idea behind this selection is that the test sets contain always sequences of places that do not appear in the training set, in this way we test the behavior of our method when applied to previously unseen places. Finally, for each experiment we repeated the previous process 10 times and obtained the average confusion matrices for the five categories.
We first show categorization results using our proposed approach in which we combined reduced histograms of LBP for grey scale and depth images that are classified using a SVM. In addition, we compare our approach with results in which the histograms of LBPs are not reduced.
Moreover, we show the improvement of the performance when using the combination of both modalities in comparison with single modalities only. We also present classification results applying spatial pyramids [28], a well known technique used in computer vision to improve classification results of scenes. Finally, we study the performance of our combined descriptor when used with support vector machines in comparison to random forests. In all the experiment the RGB images were first converted into grey scale.
7.1. Categorization of Places with Combined Histograms of LBP and SVMs
In the first experiment we study the performance of our approach when using histograms of reduced local binary patterns together with support vector machines. The final combined modality feature vectors x representing each pair of grey and depth images were obtained following the method of Section 4. In addition we apply different thresholds θ for the uniformity measurement and compare their classification results. As explained above, we repeated 10 experiments using different training and test sets. The support vector machines for each of the 10 experiments were trained using RBF kernels whose parameters were found by grid-search (see Section 5.1).
Table 2 presents the overall classification results for the 10 experiments. Results are averaged over the 10 experiments and are accompanied by the corresponding standard deviations. As Table 2 suggests best results are obtained with threshold θ = 4. In this case not only the average classification rate improves but also the uncertainty (represented by the standard deviation) is reduced. When θ = 8 there is no reduction in the histograms of LBPs and the final descriptor is equivalent to CENTRIST [16].
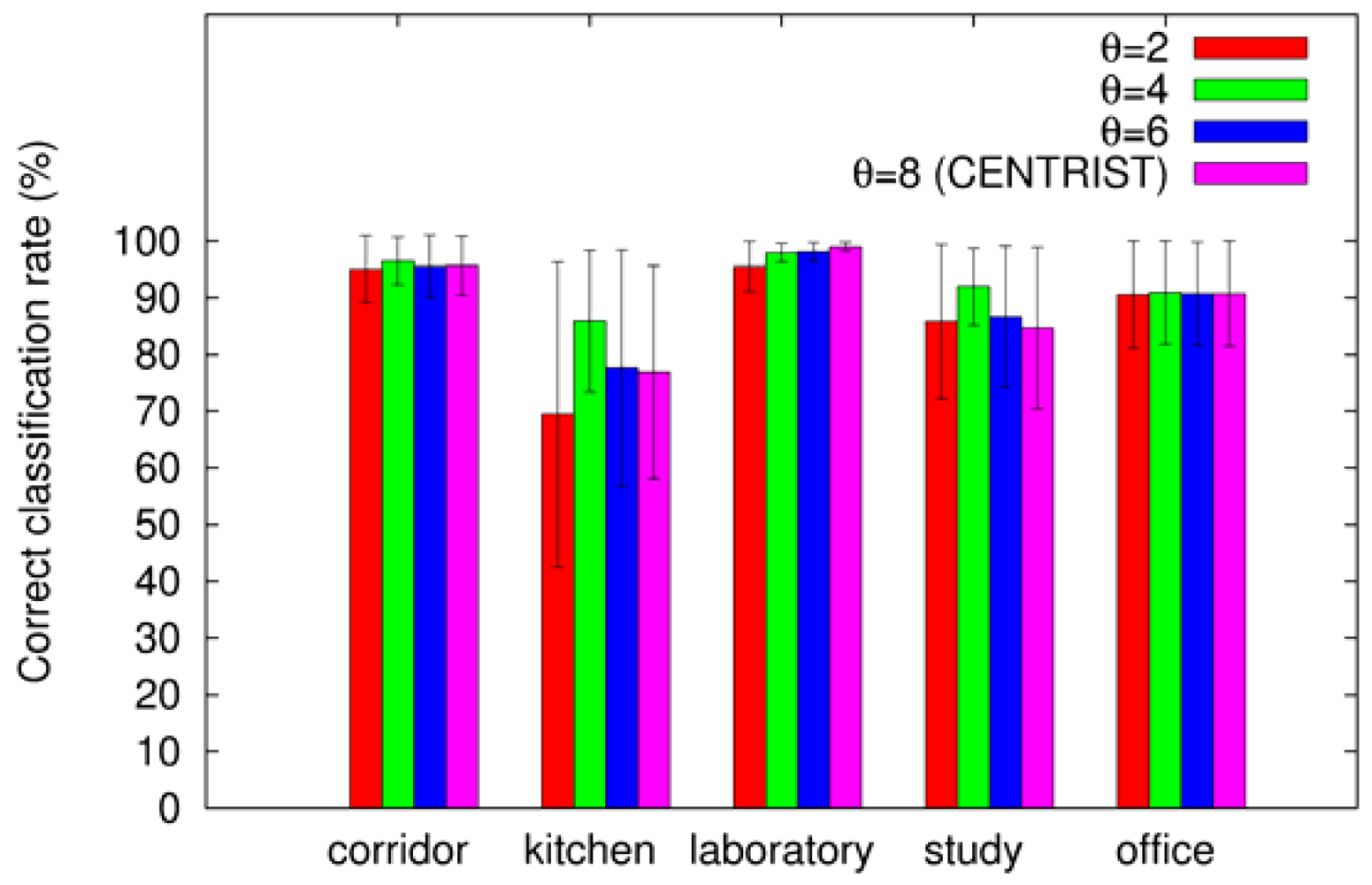
In addition, Figure 5 plots the average correct classification rates for each category. As shown in the plot best results are obtained almost always when θ = 4. In particular, the performance greatly improves in the most difficult categories which are “kitchen” and “study room”.
Finally, we present the details of the previous experiments using confusion matrices which indicate the predicted classification for the actual place. The value of each cell in the confusion matrix is the average and standard deviation over the 10 experiments. The confusion matrices for different values of the uniformity threshold θ are shown in Table 3.
7.2. Multiple Modalities vs. Single Modalities
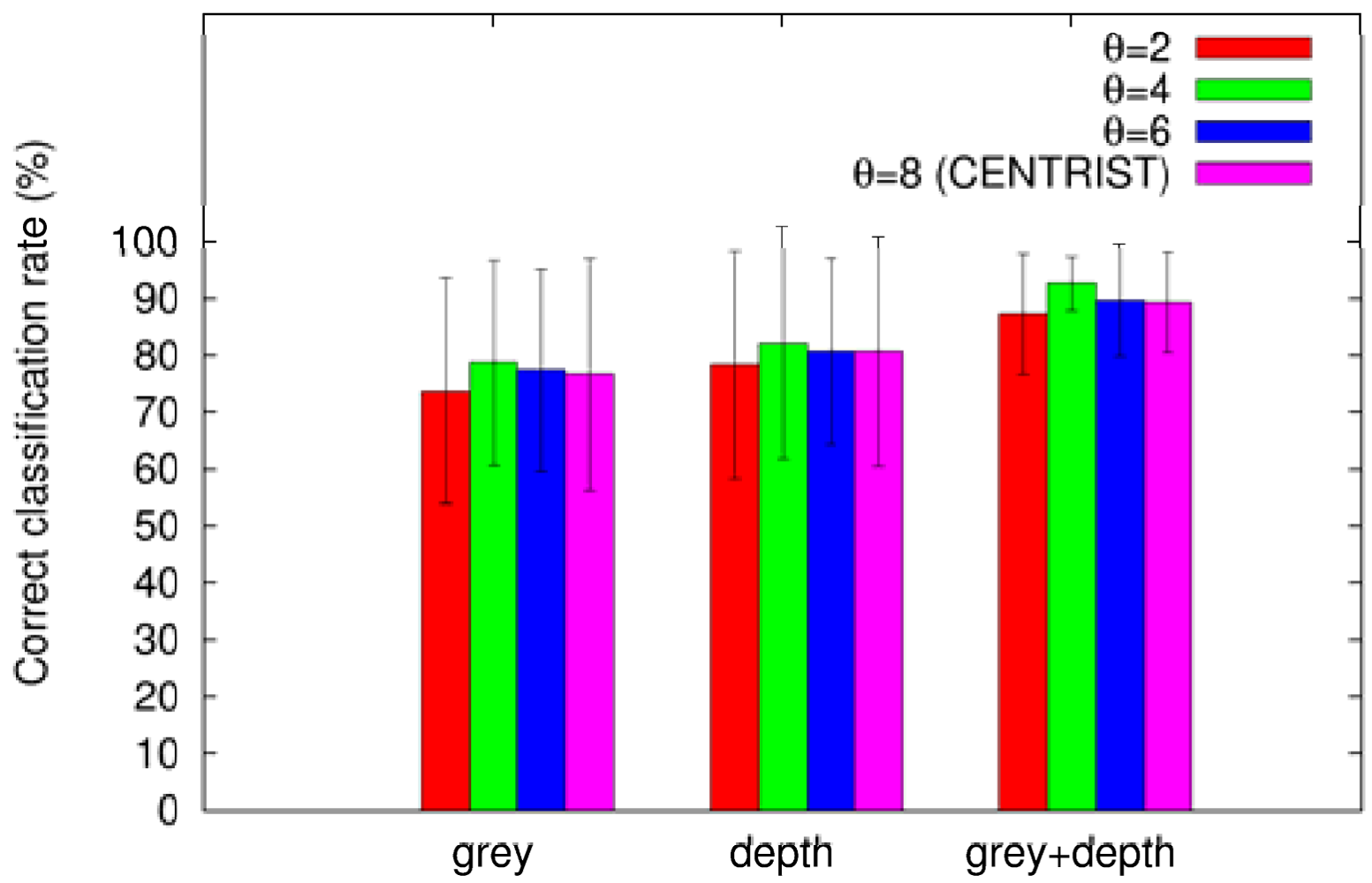
In this section we study the improvement on the categorization of places when using the combined modalities (grey and depth images) in comparison with single modalities only (grey or depth image). We repeated the experiments of the previous section using different data each time: grey images only, depth images only, and grey + depth images. Similar to the previous section we used SVMs as classifiers. Figure 6 compares the overall categorizations using different uniformity thresholds for each modality. As we can conclude from the plot, the combination of grey and depth images outperforms the categorization using single modalities only. We also can appreciate that combining the modalities the uncertainty (represented by the error bars) is drastically reduced. Moreover, in all modalities the reduced histograms using θ = 4 perform best.
Another conclusion that can be obtained from these results is that categorization using only depth information is slightly better than the categorization using grey images only. This can be due to the fact that depth information encodes general structures of indoor places and it is invariant to changes in illumination.
7.3. Categorization Using Spatial Pyramids
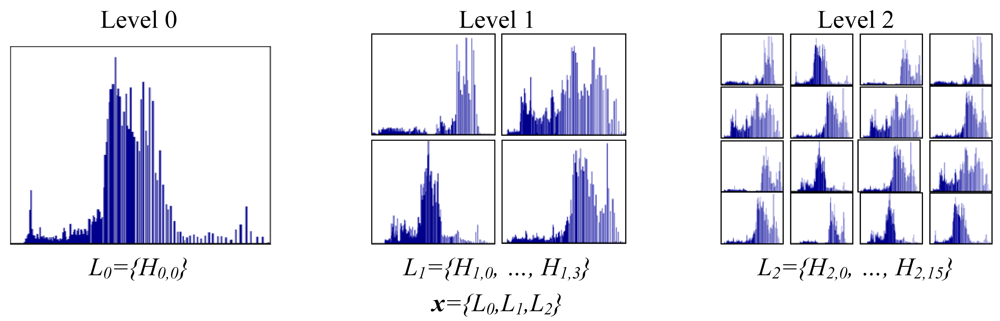
In this section we study the performance of our categorization system when applying spatial pyramids [28]. Spatial pyramids is a well known technique that is used to capture the structure of an image at different locations. The idea behind a spatial pyramid is to divide the original image into different parts. Each local part is treated as an individual image and their respective histogram is calculated. This process is applied at different levels. The final feature vector is obtained by concatenating the local histograms from all levels. A graphical example of this technique is given in Figure 7. At each level i we generate 2i × 2i histograms. The final feature vector x is obtained by concatenating the histograms of all levels.
We applied spatial pyramids using the data from our previous 10 experiments using SVM as classifiers and compare different modalities and uniformity thresholds. A final summary of categorization results is shown in Table 4 showing overall average correct categorization results and standard deviation for the 10 experiments. The results in Table 4 show that the combination of modalities outperforms single ones in almost all cases. We also can see that the best result in the combined modality is obtained in level 0. Previous literature reported better results when applying spatial pyramids to image categorization. From Table 4 we can see that this is also the case when using individual modalities, i.e., grey scale images or depth images only, however the combination of both does not improve the categorization at further levels in our particular dataset and experiments. We want to study this behavior in future work.
7.4. Classification Using Random Forests
In this section we compare the performance of our approach when using random forests in the categorization step. We compare the performance with the best results obtained using SVMs with reduced feature vectors using uniform measurement threshold θ = 4. Table 5 shows a summary of this comparison. As we can see the use of support vector machines outperforms random forest at different levels of spatial pyramids. In this table we can also see that results using random forest improve as the levels of spatial pyramids increase; however we do not observe this behavior when using the multi-class implementation of SVM provided in libsvm [32].
8. Conclusions
In this paper we have presented a method to classify places in indoor environments using RGB and depth images obtained by a Kinect camera. Our approach uses a combination of both modalities to create a feature vector that is categorized using different supervised methods. Moreover, we have introduced the uniform measurement to reduce the combined feature vectors and to improve the final categorization results. In addition, we compared the categorization results using SVMs and random forests. The results indicated that SVMs are more appropriate for our particular case. Finally, the results in all our experiments demonstrated that the combination of depth and image information outperforms the use of single modalities individually.
In this work, we did not apply any extra reduction of dimensionality in the final combined feature vectors used for categorization. However, when using spatial pyramids at different levels the dimension of the feature vectors grows exponentially and the application of some reduction technique such as PCA can improve results at subsequent levels [16]. As future work we want to study different methods to further reduce the dimensionality of the feature vectors at different levels and compare these results to the ones presented in this paper. We also want to study new ways of combining vectors from different modalities.
Acknowledgments
The authors want to thank Uchida, Taniguchi, and Morooka for granting us access to their laboratories and offices. This work has been partially supported by Grant-in-Aid for Foreign Fellows from the Japan Society for the Promotion of Science (22-00362), by Grant-in-Aid for Scientific Research (B) (22300069), and by a Grant-in-Aid for Scientific Research (B) (23360115).
References
- Martinez, Mozos O. Semantic Place Labeling with Mobile Robots; Springer-Verlag: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Pronobis, A.; Jensfelt, P.; Sjöö, K.; Zender, H.; Kruijff, G.-J.M.; Mozos, O.M.; Burgard, W. Semantic Modelling of Space. In Cognitive Systems, 1st ed.; Christensen, H.I., Sloman, A., Kruijff, G.-J.M., Wyatt, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 165–221. [Google Scholar]
- Zender, H.; Mozos, O.M.; Jensfelt, P.; Kruijff, G.-J.M.; Burgard, W. Conceptual spatial representations for indoor mobile robots. Robot. Auton. Syst. 2008, 56, 493–502. [Google Scholar]
- Wolf, D.F.; Sukhatme, G.S. Semantic mapping using mobile robots. IEEE Trans. Robot. 2008, 24, 245–258. [Google Scholar]
- Nüchter, A.; Hertzberg, J. Towards semantic maps for mobile robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar]
- Galindo, C.; Saffiotti, A.; Coradeschi, S.; Buschka, P.; Fernandez-Madrigal, J.A.; Gonzalez, J. Multi-Hierarchical Semantic Maps for Mobile Robotics. Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, Alberta, Canada; 2005; pp. 2278–2283. [Google Scholar]
- Torralba, A.; Murphy, K.P.; Freeman, W.T.; Rubin, M.A. Context-Based Vision System for Place and Object Recognition. Proceedings of the International Conference on Computer Vision, Nice, France; 2003; pp. 273–280. [Google Scholar]
- Kollar, T.; Roy, N. Utilizing Object-Object and Object-Scene Context when Planning to Find Things. Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan; 2009; pp. 2168–2173. [Google Scholar]
- Stachniss, C.; Mozos, O.M.; Burgard, W. Speeding-Up Multi-Robot Exploration by Considering Semantic Place Information. Proceedings of the IEEE International Conference on Robotics and Automation, Orlando, FL, USA; 2006; pp. 1692–1697. [Google Scholar]
- Zender, H.; Jensfelt, P.; Kruijff, G.-J. Human- and Situation-Aware People Following. Proceedings of the IEEE International Symposium on Robot and Human Interactive Communication, Jeju, Korea; 2007; pp. 1131–1136. [Google Scholar]
- Galindo, C.; Fernández-Madrigal, J.A.; González, J.; Saffiotti, A. Robot task planning using semantic maps. Robot. Auton. Syst. 2008, 56, 955–966. [Google Scholar]
- Kruijff, G.-J.M.; Zender, H.; Jensfelt, P.; Christensen, H.I. Situated dialogue and spatial organization: What, where…and why? Int. J. Adv. Robot. Syst. 2007, 4, 125–138. [Google Scholar]
- Topp, E.A.; Hüttenrauch, H.; Christensen, H.I.; Severinson Eklundh, K. Acquiring a Shared Environment Representation. Proceedings of the 1st ACM Conference on Human-Robot Interaction, Salt Lake City, UT, USA; 2006; pp. 361–362. [Google Scholar]
- Microsoft Kinect. Available online: http://www.xbox.com/en-us/kinect/ (access on 11 April 2012).
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar]
- Wu, J.; Rehg, J.M. CENTRIST: A visual descriptor for scene categorization. IEEE T. Pattern Anal. 2011, 33, 1489–1501. [Google Scholar]
- Ranganathan, A. PLISS: Detecting and Labeling Places Using Online Change-Point Detection. Proceedings of the Robotics: Science and Systems, Zaragoza, Spain; 2010. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Mozos, O.M.; Stachniss, C.; Burgard, W. Supervised Learning of Places from Range Data Using Adaboost. Proceedings of the IEEE International Conference on Robotics and Automation, Barcelona, Spain; 2005; pp. 1742–1747. [Google Scholar]
- Friedman, S.; Pasula, H.; Fox, D. Voronoi Random Fields: Extracting the Topological Structure of Indoor Environments via Place Labeling. Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India; 2007. [Google Scholar]
- Brunskill, E.; Kollar, T.; Roy, N. Topological Mapping Using Spectral Clustering and Classification. Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA; 2007; pp. 3491–3496. [Google Scholar]
- Shi, L.; Kodagoda, S.; Dissanayake, G. Laser Range Data Based Semantic Labeling of Places. Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan; 2010; pp. 5941–5946. [Google Scholar]
- Rottmann, A.; Martinez-Mozos, O.; Stachniss, C.; Burgard, W. Semantic Place Classification of Indoor Environments with Mobile Robots Using Boosting. Proceedings of the National Conference on Artificial Intelligence, Pittsburgh, PA, USA; 2005; pp. 1306–1311. [Google Scholar]
- Pronobis, A.; Mozos, O.M.; Caputo, B.; Jensfelt, P. Multi-modal semantic place classification. Int. J. Robot. Res. 2010, 29, 298–320. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar]
- Zabih, R.; Woodfill, J. Non-Pparametric Local Transforms for Computing Visual Correspondence. Proceedings of the European Conference of Computer Vision, Stockholm, Sweden; 1994; pp. 151–158. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA; 2006; pp. 2169–2178. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector network. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Knerr, S.; Personnaz, L.; Dreyfus, G. Single-layer Learning Revisited: A Stepwise Procedure for Building and Training a Neural Network. In Neurocomputing: Algorithms, Architectures and Applications; Fogelman, F., Hérault, J., Eds.; Springer-Verlag: Berlin, Germany, 1990; Volume F68 of NATO ASI Series, pp. 41–50. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. [Google Scholar]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification. Available online: http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (access on 1 October 2011).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar]
- RGB-D Place Dataset. http://robotics.ait.kyushu-u.ac.jp/~kurazume/r-cv-e.html#c10 (accessed on 21 May 2012).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Place | RGB and depth images |
|---|---|---|
| Corridor | Corridor 1 | 68 |
| Corridor 2 | 42 | |
| Corridor 3 | 70 | |
| Corridor 4 | 99 | |
| Total | 279 | |
| Kitchen | Kitchen 1 | 73 |
| Kitchen 2 | 65 | |
| Kitchen 3 | 53 | |
| Total | 191 | |
| Laboratory | Laboratory 1 | 99 |
| Laboratory 2 | 99 | |
| Laboratory 3 | 81 | |
| Laboratory 4 | 78 | |
| Total | 357 | |
| Study Room | Study Room 1 | 71 |
| Study Room 2 | 70 | |
| Study Room 3 | 49 | |
| Study Room 4 | 62 | |
| Total | 252 | |
| Office | Office 1 | 57 |
| Office 2 | 45 | |
| Office 3 | 47 | |
| Total | 149 | |
| θ = 2 | θ = 4 | θ = 6 | θ = 8 (CENTRIST) |
| 87.27 ± 10.71 | 92.61 ± 4.78 | 89.71 ± 9.92 | 89.37 ± 8.85 |
| θ = 2 | Predicted Class | |||||
|---|---|---|---|---|---|---|
| % | Corridor | Kitchen | Laboratory | Study room | Office | |
| Actual class | Corridor | 95.05 ± 7.02 | 0.20 ± 0.63 | 3.84 ± 6.25 | 0.91 ± 1.93 | 0.00 ± 0.00 |
| Kitchen | 2.64 ± 3.99 | 69.43 ± 30.68 | 4.15±7.96 | 22.64 ± 25.32 | 1.13 ± 2.97 | |
| Laboratory | 0.25 ± 0.78 | 1.24 ± 3.90 | 95.51 ± 6.45 | 2.26 ± 2.97 | 0.75 ± 1.94 | |
| Study Room | 0.00 ± 0.00 | 3.29 ± 4.61 | 10.57 ± 11.15 | 85.82 ± 14.66 | 0.32 ± 1.02 | |
| Office | 0.00 ± 0.00 | 4.39 ± 4.69 | 5.09 ± 5.57 | 0.00 ± 0.00 | 90.53 ± 10.10 | |
| θ = 4 | Predicted Class | |||||
|---|---|---|---|---|---|---|
| % | Corridor | Kitchen | Laboratory | Study room | Office | |
| Actual class | Corridor | 96.47 ± 5.15 | 0.91 ± 1.53 | 2.02 ± 4.04 | 0.61 ± 1.59 | 0.00 ± 0.00 |
| Kitchen | 2.64 ± 2.38 | 85.88 ± 14.04 | 1.51 ± 2.48 | 7.89 ± 9.83 | 2.08 ± 2.87 | |
| Laboratory | 0.00 ± 0.00 | 0.20 ± 0.42 | 97.91 ± 2.49 | 0.77 ± 0.89 | 1.12 ± 2.69 | |
| Study Room | 0.00 ± 0.00 | 5.14 ± 5.47 | 2.29 ± 3.37 | 91.93 ± 8.00 | 0.65 ± 2.03 | |
| Office | 0.00 ± 0.00 | 3.51 ± 4.60 | 5.61 ± 6.65 | 0.00 ± 0.00 | 90.88 ± 9.63 | |
| θ = 6 | Predicted Class | |||||
|---|---|---|---|---|---|---|
| % | Corridor | Kitchen | Laboratory | Study room | Office | |
| Actual class | Corridor | 95.53 ± 5.51 | 2.23 ± 2.85 | 2.23 ± 3.39 | 0.00 ± 0.00 | 0.00 ± 0.00 |
| Kitchen | 2.57 ± 2.25 | 77.62 ± 20.82 | 2.07 ± 2.94 | 14.51 ± 16.30 | 3.21 ± 3.80 | |
| Laboratory | 0.00 ± 0.00 | 0.22 ± 0.44 | 98.08 ± 1.64 | 0.94 ± 0.65 | 0.75± 1.46 | |
| Study Room | 0.00 ± 0.00 | 8.13 ± 9.03 | 4.89 ± 4.64 | 86.64 ± 12.47 | 0.32 ± 0.95 | |
| Office | 0.00 ± 0.00 | 3.86 ± 4.42 | 5.45 ± 5.80 | 0.00 ± 0.00 | 90.68 ± 9.15 | |
| θ = 8 (CENTRIST) | Predicted Class | |||||
|---|---|---|---|---|---|---|
| % | Corridor | Kitchen | Laboratory | Study room | Office | |
| Actual class | Corridor | 95.66 ± 5.92 | 2.02 ± 2.65 | 2.32 ± 3.81 | 0.00 ± 0.00 | 0.00 ± 0.00 |
| Kitchen | 2.45 ± 2.36 | 76.85 ± 21.45 | 3.21 ± 4.79 | 12.40 ± 14.50 | 5.10 ± 5.18 | |
| Laboratory | 0.00 ± 0.00 | 0.12 ± 0.38 | 99.02 ± 1.13 | 0.23 ± 0.48 | 0.63 ± 0.88 | |
| Study Room | 0.00 ± 0.00 | 8.86 ± 11.81 | 5.57 ± 6.78 | 84.64 ± 18.04 | 0.93 ± 2.13 | |
| Office | 0.00 ± 0.00 | 3.51 ± 4.60 | 5.79 ± 6.77 | 0.00 ± 0.00 | 90.70 ± 9.85 | |
| Grey | Depth | Grey + Depth | ||
|---|---|---|---|---|
| θ = 2 | Level 0 | 73.72 ± 19.84 | 78.37 ± 20.03 | 87.27 ± 10.71 |
| Level 1 | 80.93 ± 21.79 | 83.22 ± 16.40 | 85.53 ± 19.46 | |
| Level 2 | 82.21 ± 23.26 | 84.93 ± 17.18 | 82.46 ± 23.67 | |
| θ = 4 | Level 0 | 78.75 ± 18.01 | 82.15 ± 20.53 | 92.61 ± 4.78 |
| Level 1 | 78.56 ± 23.13 | 89.02 ± 10.77 | 88.10 ± 15.75 | |
| Level 2 | 78.87 ± 22.80 | 86.67 ± 16.28 | 88.95 ± 14.18 | |
| θ = 6 | Level 0 | 77.38 ± 17.73 | 80.70 ± 16.40 | 89.71 ± 9.92 |
| Level 1 | 80.33 ± 17.44 | 85.08 ± 12.58 | 87.18 ± 12.4 | |
| Level 2 | 78.33 ± 18.18 | 82.18 ± 15.55 | 80.69 ± 15.32 | |
| θ = 8 (CENTRIST) | Level 0 | 76.60 ± 20.43 | 80.72 ± 20.14 | 89.37 ± 8.85 |
| Level 1 | 79.47 ± 21.78 | 85.11 ± 17.52 | 85.68 ± 17.88 | |
| Level 2 | 82.18 ± 18.30 | 83.14 ± 20.13 | 84.59 ± 19.69 | |
| Level | SVM | Random Forest |
|---|---|---|
| 0 | 92.61 ± 4.78 | 85.74 ± 11.82 |
| 1 | 88.10 ± 15.76 | 87.57 ± 14.23 |
| 2 | 88.95 ± 14.18 | 88.43 ± 12.79 |
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Mozos, O.M.; Mizutani, H.; Kurazume, R.; Hasegawa, T. Categorization of Indoor Places Using the Kinect Sensor. Sensors 2012, 12, 6695-6711. https://doi.org/10.3390/s120506695
Mozos OM, Mizutani H, Kurazume R, Hasegawa T. Categorization of Indoor Places Using the Kinect Sensor. Sensors. 2012; 12(5):6695-6711. https://doi.org/10.3390/s120506695
Chicago/Turabian StyleMozos, Oscar Martinez, Hitoshi Mizutani, Ryo Kurazume, and Tsutomu Hasegawa. 2012. "Categorization of Indoor Places Using the Kinect Sensor" Sensors 12, no. 5: 6695-6711. https://doi.org/10.3390/s120506695